Webbskrapning har blivit en avgörande metod för att få insiktsfull data från internetplattformar i dagens datadrivna samhälle.
Som en extremt populär webbplats för sociala medier tillhandahåller Instagram mycket användargenererat material. Och dessa genererade data kan användas för marknadsföring, forskning och andra skäl.
Användare kan extrahera data från Instagram med lätthet och effektivitet tack vare Bright Datas funktionsrika Instagram-skrapor, en ledande webbskrapning verktyg. I det här inlägget kommer vi att ge en grundlig, steg-för-steg-genomgång av Instagram-skrapningsprocessen.
Så låt oss se stegen för hur vi kan skrapa data från Instagram.
Förstå Instagram-skrapor från Bright Data
Med hjälp av två allsidiga webbskrapor och en förkompilerad datauppsättning tillhandahåller Bright Data en mängd olika Instagram-skrapningstjänster. Dessa teknologier erbjuder mångsidighet i dataextraktion och anpassar sig till olika krav.
Låt oss undersöka vart och ett av dessa val mer detaljerat:
a. Skrapande webbläsare
Den innovativa tekniken känd som Scraping Browser skapades för att uppfylla kraven för dataskrapningsprojekt. Den erbjuder allt som krävs för att skrapa i stor skala inuti en enda webbläsare. Den sticker ut tack vare sin integrerade webbblockeringsautomatisering, vilket gör den till den enda webbläsaren i sitt slag i hela världen.
Scraping Browser ger användare tillgång till robusta funktioner som går utöver automatiserade och huvudlösa webbläsare, vilket gör att de kan ta sig bortom även de svåraste skripten och webbplatsbarriärerna för botdetektering.
Dataskrapning är mer effektiv och problemfri på grund av dess automatiska justeringsfunktioner, som enkelt hanterar nya block, CAPTCHA-lösningar, fingeravtryck och återförsök, och framstår som en äkta användare.
Använder AI för att överlista botdetekteringssystem
Genom att använda banbrytande AI-teknik kan Scraping Browser överlista botdetekteringssystem och ständigt anpassa sig till deras skiftande strategier. För att bättre låsa upp webbsidor lär sig Scraping Browser av dessa systems försök att upptäcka och blockera skrapningsförsök och ändrar dess beteende på lämpligt sätt.
Den överträffar effektiviteten hos konventionella proxyservrar genom att imitera beteendet hos en webbläsare som används av en riktig användare. Som ett resultat kan kunderna koncentrera sig på sina mål för dataskrapning utan att behöva ta itu med svårigheten och kostnaden för pågående bot-detekteringsprocedurer.
b. Web Scraper IDE
Web Scraper IDE är ett robust webbskrapverktyg skapat för utvecklare och kan hantera komplexa skrapningsuppgifter. Den sänker utvecklingstiden avsevärt samtidigt som den ger oändlig skalbarhet tack vare sin helt värdbaserade lösning och förbyggda skrapningsfunktioner. Applikationen möjliggör snabb och skalbar konstruktion av onlineskrapor genom att tillhandahålla kodmallar och färdiga JavaScript-funktioner från populära webbplatser.
Allt som krävs för framgångsrik webbskrapning tillhandahålls av Web Scraper IDE. Det är en komplett lösning för onlinedataextraktion eftersom integrationsalternativ gör det möjligt för kunder att planera genomsökningar eller starta dem via API och länka till huvudlagringssystem.
Hur man använder det? – Handledning
Navigera först till användarinstrumentpanelen på webbplatsen.

Låt oss börja med våra steg för att skrapa Instagram.
1- Navigera till Dashboard och klicka på avsnittet Dataset & Web Scraper IDE.
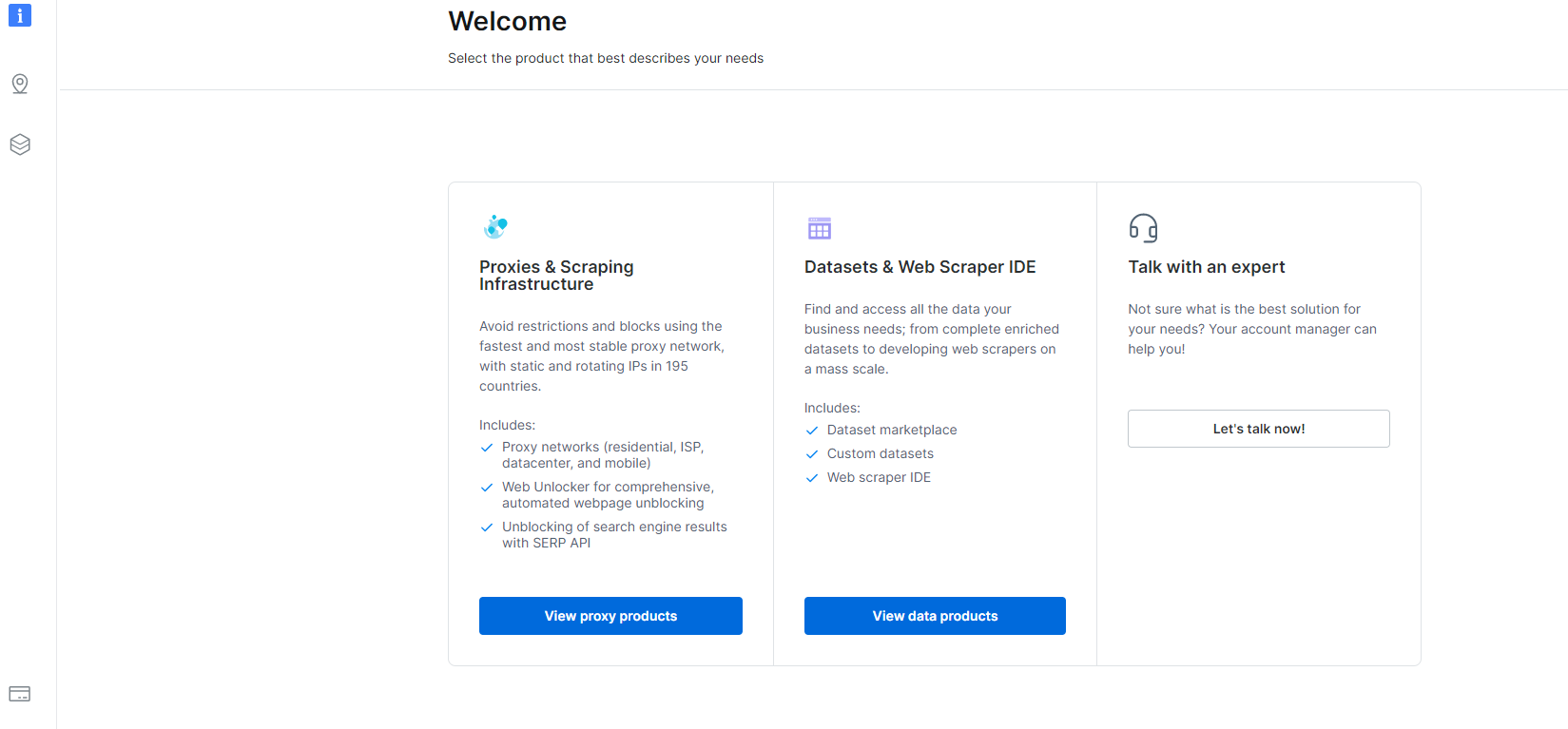
2- När du väl är där, klicka på Mina skrapor.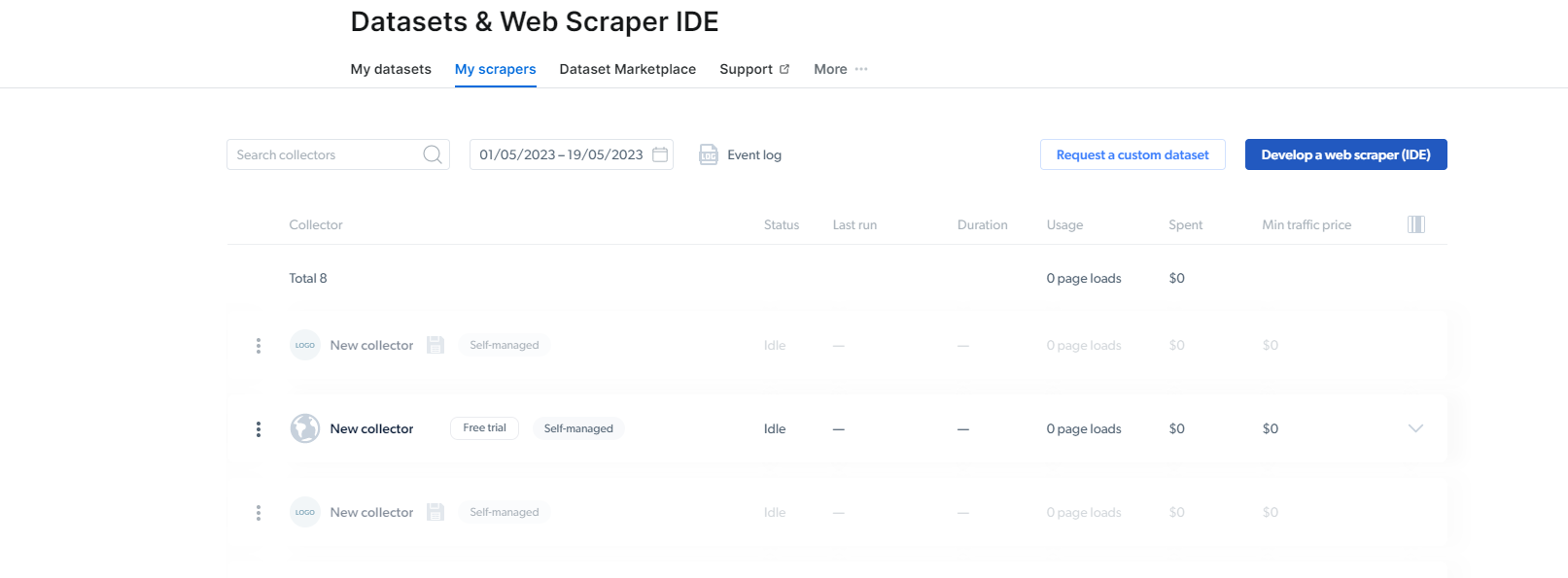
Här måste du klicka på "Utveckla en webbskrapa (IDE)". Här kommer vi att skapa vår skrapa för Instagram.
3-Nu måste vi utveckla en ny webbskrapa. Bara för det här exemplet väljer jag att skrapa "NASA"-kontot. Detta är bara för detta exempels skull.
Så min kod kommer att se ut så här:
/ Click the 'play' button in the top right to run this code:
// 1. Go to the page where you want to start
navigate('https://www.instagram.com/nasa/');
// 2. Add anything else you need to do on the page.
// For example: (see the help box for all command docs).
// click('.some-button')
// type('.some-input', 'shoes')
// wait('.some-lazy-loaded-element')
// 3. Once the browser page has the data you want, call parse() to get the data
// and call collect() to add a record to your final dataset
let data = parse();
collect({
url: new URL(location.href),
title: "Nasa Account",
links: data.links,
});
Du måste klicka på "spela"-knappen uppe till höger för att köra den här koden.
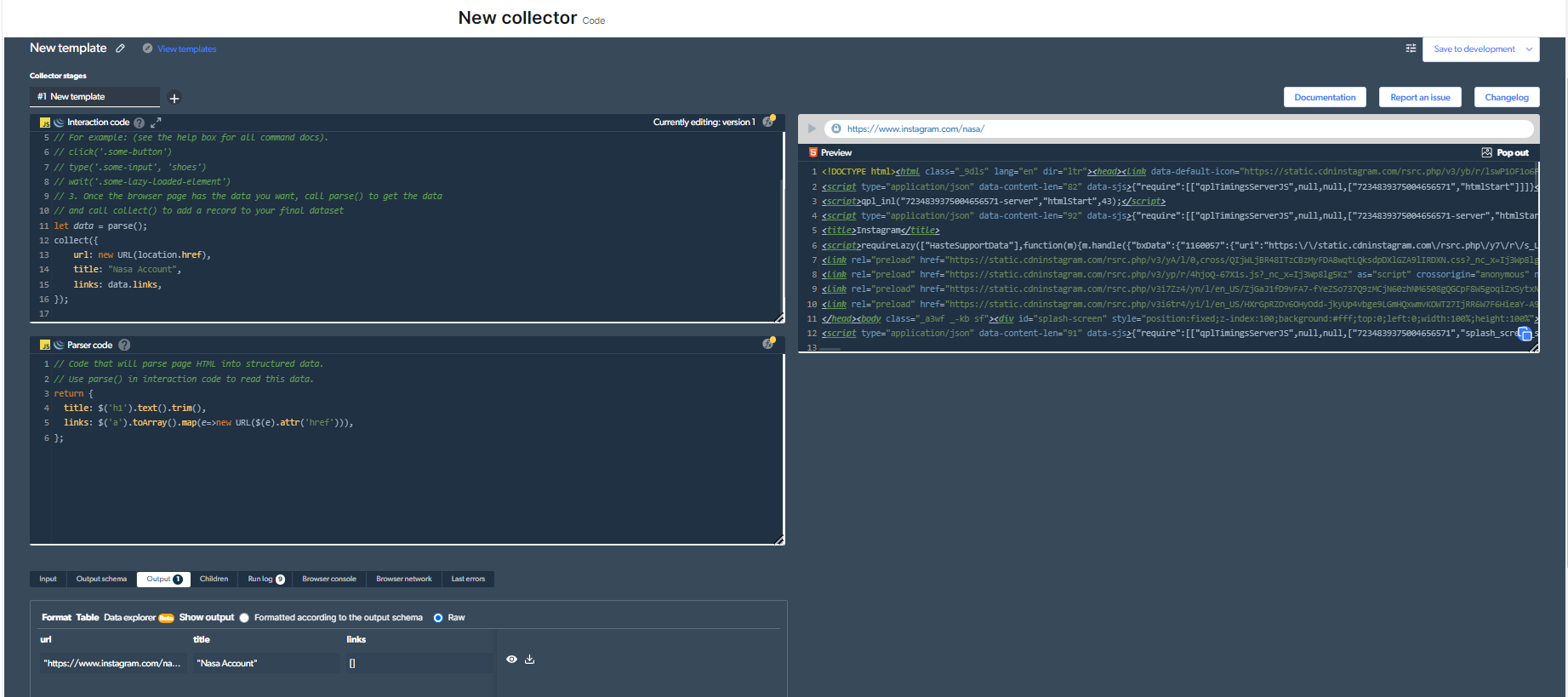
4- Nu kommer vi att ha en utgång.
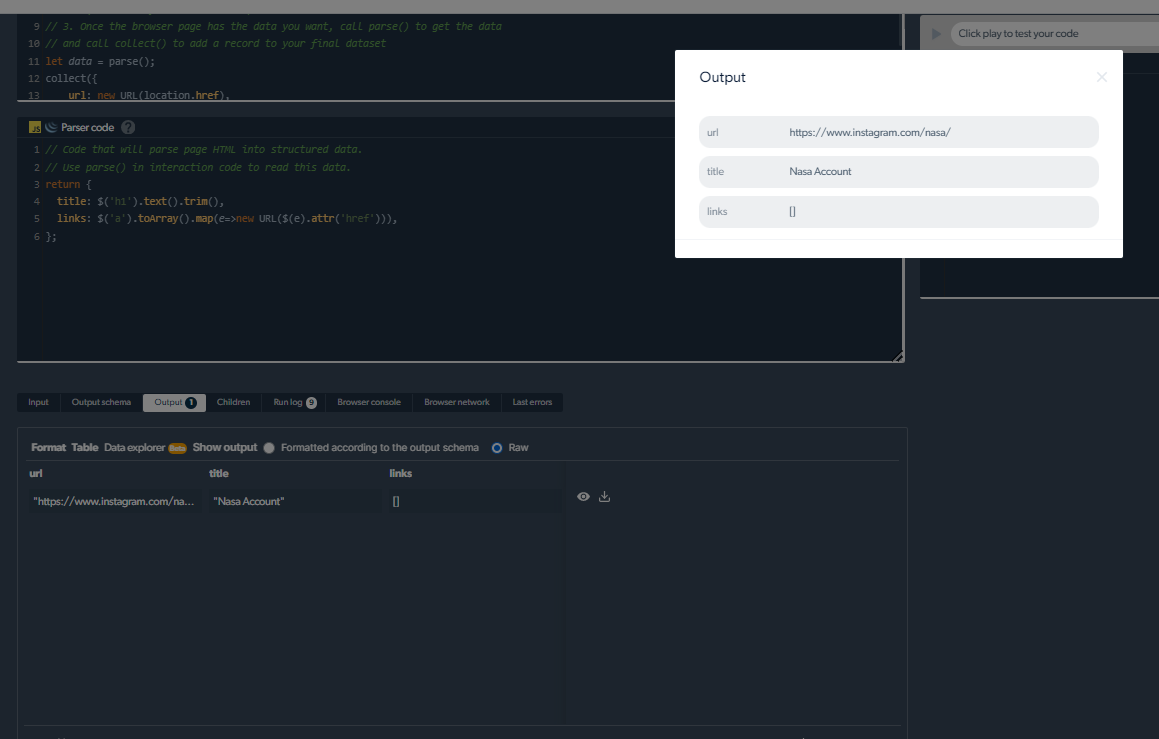
Hantera skrapningsproblem
Instagram-inlägg med "visa mer-knappen" kan vara svåra för skrapor att fånga. Men Instagram-skrapor från Bright Data är gjorda för att hantera sådan komplexitet framgångsrikt. Dessa skrapor har banbrytande färdigheter för att gå igenom pagineringen och laddningen av ytterligare knappar.
Bright Datas Instagram-skrapor hanterar effektivt dessa svårigheter för att möjliggöra grundlig dataextraktion, vilket gör att du kan samla in hela samlingen av information som krävs för din analys eller studie.
Du kan komma runt utmaningarna från Instagram-inläggens dynamiska karaktär genom att använda dessa skrapverktyg.
c. Förinsamlad datauppsättning
Bright Data förstår att inte alla vill köra sin skrapa. De tillhandahåller en förinsamlad datauppsättning för Instagram för att tilltala sådana konsumenter.
Denna datauppsättning erbjuder en mängd användbar information, såsom följare, profiler, inlägg och mer.
Bright Data erbjuder anpassningsalternativ för att anpassa datasetet efter dina behov, oavsett om du vill ha en hel datamängd eller en undergrupp av specialiserad data. Detta tillvägagångssätt undviker att konstruera och hantera en skrapa, vilket ger dig färdiga data för analys och insikter.
Låt oss nu kontrollera infrastrukturen som gör dessa verktyg så effektiva: proxyinfrastrukturen och Web Unlocker.
Släpp lös kraften hos proxyservrar
Använda proxies är avgörande under webbskrapning för att garantera att dina handlingar förblir obemärkta.
Bright Data ger ett brett urval av proxytjänster som är anpassade efter dina krav. Du kan välja från Bostadsfullmakt, som erbjuder mer än 72 miljoner IP-adresser roterade från real-peer-enheter i 195 länder.
Du kan välja ISP Proxies, som erbjuder 700,000 770,000+ riktiga hem-IP:er över hela världen för långvarig användning; Datacenterproxies, som har 3 4+ delade IP-adresser från vilken geolokalisering som helst; och Mobile Proxies, som bildar det största real-peer 7,000,000G/XNUMXG-mobilnätverket med över XNUMX XNUMX XNUMX IP-adresser.
Med användningen av dessa proxyservrar kan man enkelt samla in data samtidigt som man utger sig för att vara en auktoriserad användare på många ställen.

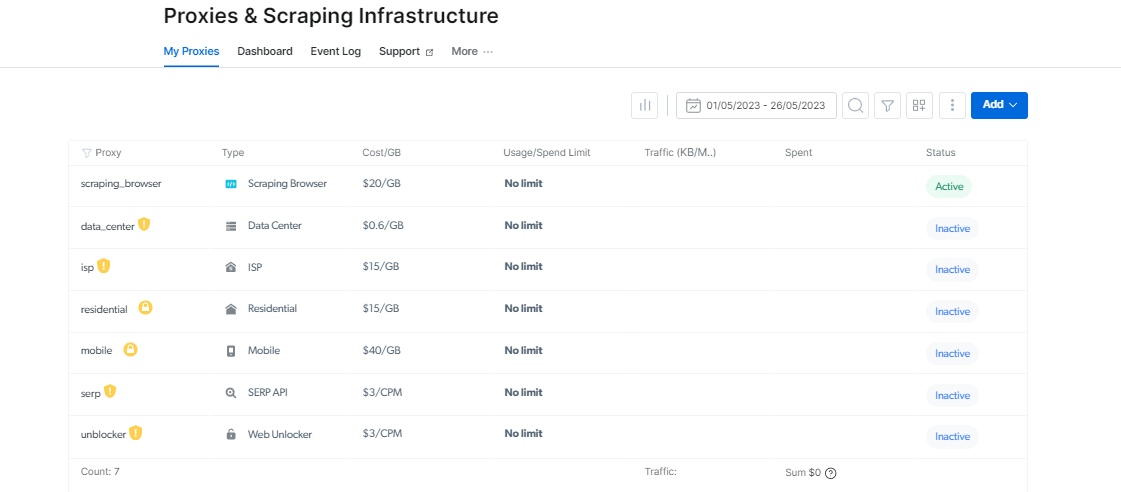
Proxy Manager: Gör proxyhantering enklare
Att hantera flera proxyservrar kan vara svårt, men Proxy Manager gör det enkelt.
Detta gränssnitt med öppen källkod gör att du kan hantera alla dina proxyservrar från en enda plattform. Säg adjö till att manuellt ställa in och byta proxy. Proxy Manager förenklar proceduren och sparar tid och ansträngning.
Proxy-webbläsartillägg: Ändra din plats enkelt
Behöver du samla in webbdata från flera regioner? Du omfattas av vår Proxy Browser Extension. Du kan ändra din webbläsarplats med ett enda klick för att få regionspecifik information.
Dra fördel av flexibiliteten och enkelheten att samla in data från flera regioner utan några tekniska komplikationer.
Hur fungerar det? – Handledning
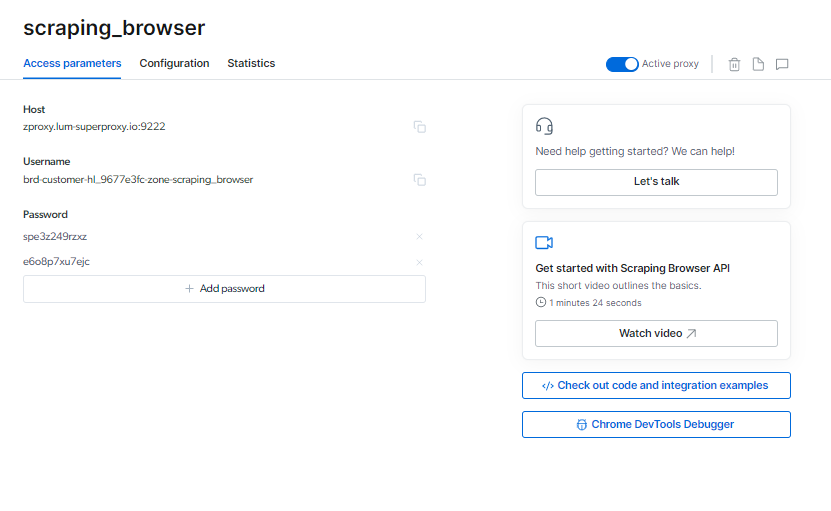
Du kan hitta din Skrapande webbläsare inloggningsinformation på sidan Accessparametrar, som kommer att användas när du startar en ny webbläsarsession.
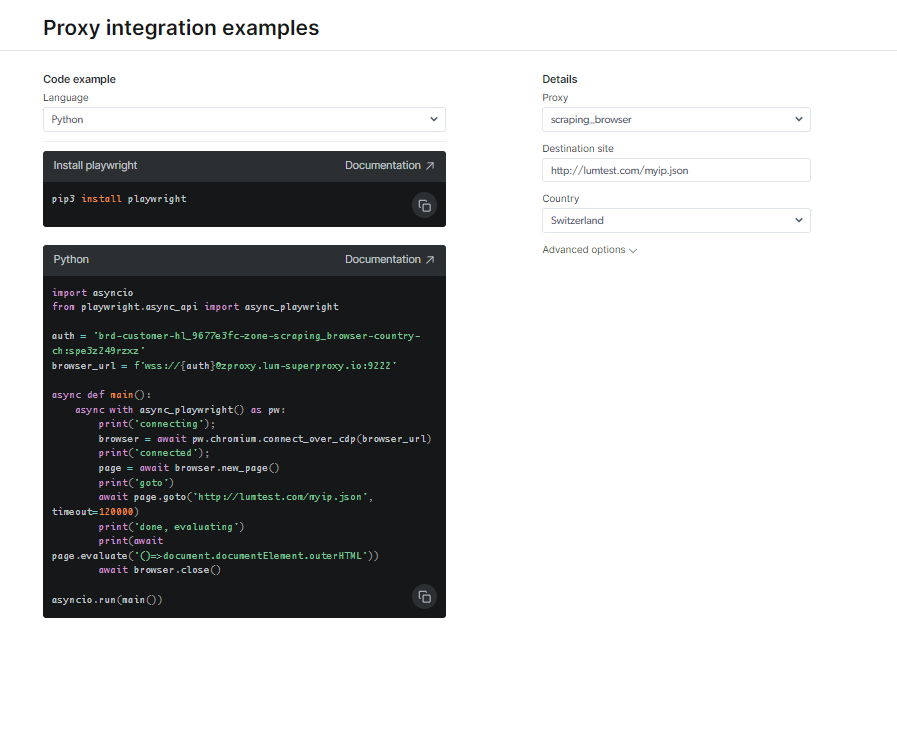
Kolla in dokumentation och kodexempel, inklusive ett fullt fungerande exempelskript som är klart att använda, eller titta på en kort startinstruktionsvideo. Till exempel; här är en Python-kod exempel för integration:
Vill du ha hjälp? För en konversation med en av specialisterna kan du klicka på chattikonen.
Tänk på att du har fullständig kontroll över webbläsarsessionerna när du använder Scraping Browser och kan utföra alla åtgärder som stöds av Puppeteer, Playwright eller direkt användning av Chrome DevTools Protocol.
Upplåsning av webbplats utan block
Scraping Browser är gjord för att fungera i stor skala och efter behov. Du behöver inte oroa dig för att bli förbjuden; du kan starta så många webbläsarsessioner du behöver.
Denna kapacitet, tillsammans med styrkan hos proxyservrar, garanterar kontinuerlig datainsamling, vilket gör att du effektivt kan få den data du vill ha.
Scraping Browsers inbyggda upplåsningsfärdigheter och robusta proxynätverk hjälper dig att spara tid, förbättra produktiviteten och upptäcka nya möjligheter.
Du kan också kolla statistiken från samma sida direkt.
Prissättning av Scraping Browser
Bright Data tillhandahåller anpassningsbara prisval för att möta en mängd olika ändamål. Du kan välja antingen en månatlig eller årlig faktureringsperiod.
Pay as You Go-alternativet låter dig betala bara för det du använder, utan förpliktelser, från 20.00 USD/GB och 0.1 USD/timme.
Tillväxtplanen på $500 är lämplig för växande företag, med en rabatterad avgift på $15.30/GB och $0.1/timme.
Smakämnen Företagspaket, som kostar $1000, är det mest populära alternativet, med Scraping Browser API som kostar $13.50/GB och $0.1/timme.
Genom att kontakta Bright Data-teamet direkt kan företagsanvändare njuta av oändlig skalning och personliga priser. Starta en gratis provperiod idag för att upptäcka potentialen i Bright Datas Scraping Browser och ändra dina online-skrapningsinsatser.
Webbplatsupplåsning
Web Unlocker är ett kraftfullt verktyg skapat för att komma bortom webbplatsbegränsningar och ge enkel datainsamling. Den övervinner flera utmaningar, inklusive cookies, webbplatsspecifika webbläsaranvändaragenter och captcha-lösningar, genom att använda automatiserade procedurer.
Genom att använda automatisk IP-adressrotation kan användare av Web Unlocker kontinuerligt skrapa målwebbplatser, vilket säkerställer konstant tillgång till viktig data.
Förbättra resor med utvecklareförfrågningar
Flera funktioner gör Web Unlocker populär bland utvecklare. Programmet effektiviserar datainsamlingsprocessen genom att automatiskt identifiera de användaragenter som behövs för varje webbplats, vilket sparar värdefull tid och resurser.
Web Unlocker anpassar sig i realtid för att undvika upptäckt som svar på de ständigt föränderliga strategierna som används av blockerande bots, vilket säkerställer kontinuerlig åtkomst till webbplatserna av intresse. Plattformens maskininlärningsalgoritmer kan snabbt lösa captchas, ett frekvent hinder för datainsamlingsinitiativ.

Prissättning av Web Unlocker
Med start på cirka 2.03 USD per tusen förfrågningar (CPM), erbjuder Web Unlocker flera prisalternativ för att möta olika krav. En 7-dagars gratis provperiod är tillgänglig för användare för att få dem igång och låta dem testa Web Unlockers funktioner innan de bestämmer sig.
Web Unlocker har anpassningsförmågan att stödja olika användningsmönster, oavsett om konsumenterna vill ha en pay-as-you-go-metod eller behöver en skräddarsydd plan anpassad till deras specifika krav. Dessutom kan de som väljer långsiktiga prisplaner spara 32 %.
Jämförelse mellan Web Unlocker med självhanterade proxyservrar
Web Unlocker erbjuder många omedelbara fördelar jämfört med självhanterade proxyservrar. För smidig implementering erbjuder den en omfattande integrationsteknik som kombinerar superproxy- och proxyhanterarefunktioner. Användare kan effektivt skala upp sin datainsamlingsverksamhet med ett oändligt antal samtidiga anslutningar.
Web Unlocker levererar automatisk avblockering, löser CAPTCHAs och hanterar framgångsrikt uppmärkningsändringar på målwebbplatser.
Plattformen garanterar kontinuerlig och pålitlig dataextraktion genom att implementera ett automatiskt försök igen och göra asynkrona anrop för vissa domäner. Dessutom låter online Unlockers växande samling av HTTP-header-förfrågningar, webbplatsspecifika webbläsarcookies och simulerade prylar användare förbli oupptäckta samtidigt som de gör det möjligt för dem att skaffa onlinedata i realtid.
Sista tankar och viktiga saker att komma ihåg
Slutligen, när du använder Bright Data för Instagram-skrapning, är det viktigt att ha några viktiga punkter i åtanke.
Observera att deras skrapningsmöjligheter är begränsade till allmänt tillgängliga data, av etisk praxis.
Du bör alltid följa Instagrams användarvillkor och sekretesspolicyer. Skrapning bör göras etiskt och ansvarsfullt, utan att inkräkta på användarnas rättigheter eller bryta mot några lagar.
För det andra, uppdatera och finjustera dina skrapningsparametrar regelbundet för att säkerställa noggrannheten och relevansen för de hämtade data. Instagrams plattform och algoritmer kan ändras, därför måste du ändra dina skrapningsstrategier i enlighet med detta.
Slutligen, använd Bright Datas plattforms hjälp och resurser för att optimera framgången för dina Instagram-skrapningsinsatser. Engagera dig med deras dokumentation, handledningar och kundtjänst för att förbättra din kunskap om deras skrapverktyg.
Du kan få användbara insikter, påverka klokt beslutsfattande och lyckas med dina datadrivna initiativ på Instagram-plattformen genom att följa dessa bästa praxis och utnyttja styrkan i Bright Datas Instagram-skrapningsfunktioner.





Kommentera uppropet