Innehållsförteckning[Dölj][Visa]
Företag fångar in mer data än någonsin eftersom de i allt högre grad förlitar sig på den för att informera viktiga affärsbeslut, förbättra produktutbudet och ge bättre kundservice.
Med mängden data som skapas i en exponentiell hastighet erbjuder molnet flera fördelar för databearbetning och analys, inklusive skalbarhet, pålitlighet och tillgänglighet.
I molnets ekosystem finns också flera verktyg och teknologier för databehandling och analys. De två typerna av stordatalagringsstrukturer som används mest är datalager och datasjöar.
Även om det är mindre tilltalande att använda en datasjö eftersom du inte kan fråga efter modellen och data medan de fortfarande är relevanta, är det slösaktigt att använda ett datalager för strömmande datalagring.

Wvilken typ av molnarkitektur väljer vi?
Ska vi överväga nyare koncept för datasjöhuset, eller ska vi nöja oss med lagrets begränsningar eller sjöns begränsningar?
En ny datalagringsarkitektur som kallas "datasjöhus" kombinerar datasjöarnas anpassningsförmåga med datahanteringen i datalager.
Att förstå de olika metoderna för lagring av stora data är avgörande för att bygga en tillförlitlig datalagringspipeline för business intelligence (BI), dataanalys och maskininlärning (ML) arbetsbelastning, beroende på ditt företags krav.
I det här inlägget kommer vi att titta närmare på Data Warehouse, Data Lake och Data Lakehouse, med fördelar, begränsningar samt för- och nackdelar med dem. Låt oss börja.
Vad är Data Warehouse?
Ett datalager är ett centraliserat datalager som används av en organisation för att hålla enorma mängder data från många källor. Ett datalager fungerar som en organisations enda källa till "datasanning" och är avgörande för rapportering och affärsanalys.
Vanligtvis kombinerar datavaruhus relationsdata från flera källor, såsom applikations-, affärs- och transaktionsdata, för att lagra historisk data. Innan data laddas in i lagersystemet omvandlas och rensas data i datalager så att de kan användas som en enda källa till datasanning.
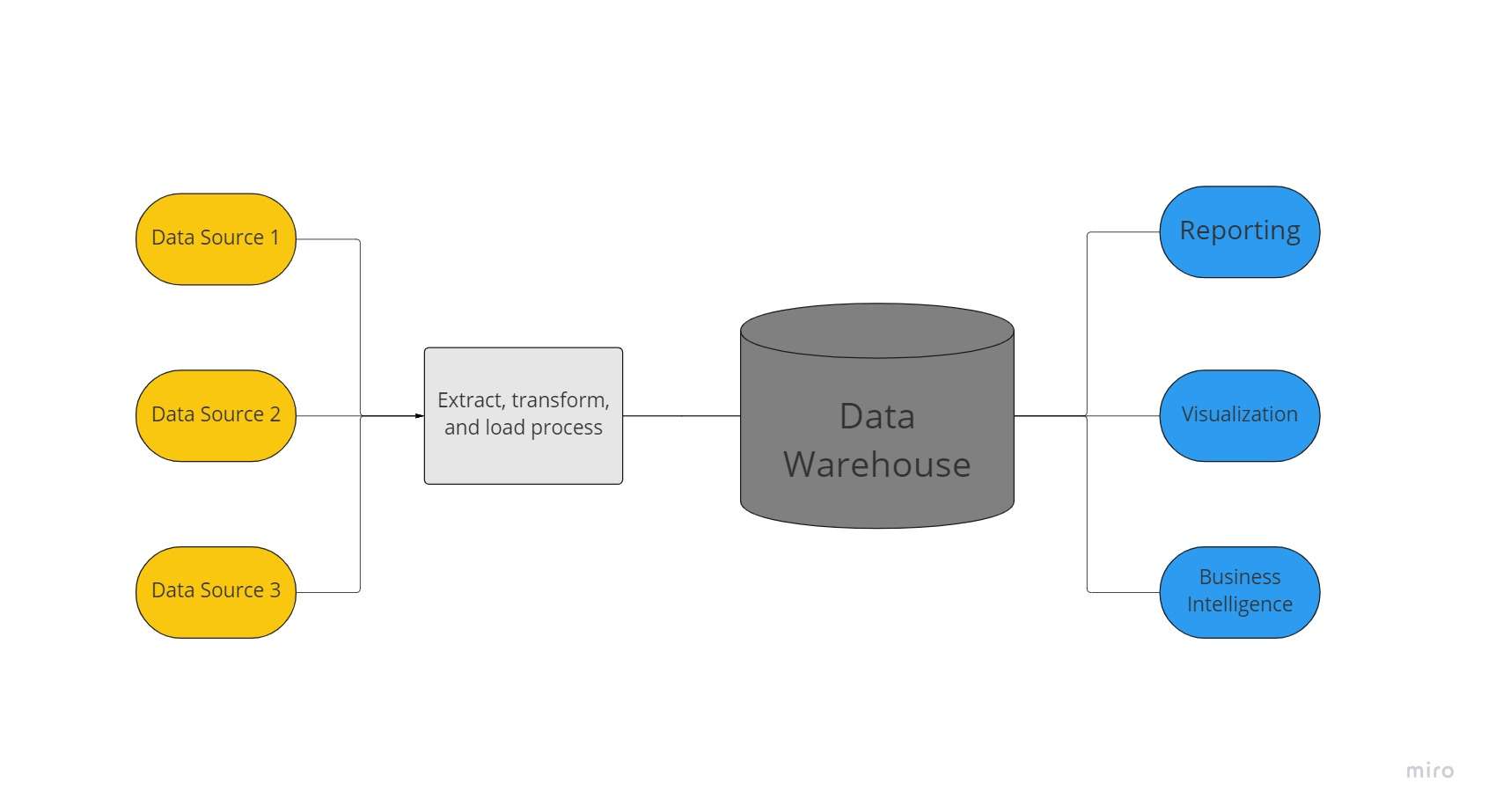
På grund av sin förmåga att snabbt erbjuda affärsinsikter från alla delar av företaget, investerar företag i datalager. Med användning av BI-verktyg, SQL-klienter och andra mindre sofistikerade (dvs icke-datavetenskapliga) analyslösningar, affärsanalytiker, dataingenjörer och beslutsfattare kan komma åt data från datalager.
Det är dyrt att underhålla ett lager med den ständigt ökande datamängden, och ett datalager kan inte hantera rå eller ostrukturerad data. Dessutom är det inte det perfekta alternativet för sofistikerade dataanalystekniker som maskininlärning eller prediktiv modellering.
Ett datalager ger därför snabbare frågesvar och data av högre kvalitet. Google Big Query, Amazon Redshift, Azure SQL Data warehouse och Snowflake är molntjänster som är tillgängliga för datalager.
Fördelar med Data Warehouse
- Öka effektiviteten och hastigheten för arbetsbelastningar för affärsintelligens och dataanalys: Datalager förkortar tiden som behövs för databeredning och analys. De kan enkelt länka till dataanalys- och business intelligence-verktyg eftersom data från datalagret är tillförlitliga och konsekventa. Dessutom sparar datalager den tid som behövs för datainsamling och ger teamen möjlighet att använda data för rapporter, instrumentpaneler och andra analyskrav.
- Öka konsistensen, kvaliteten och standardiseringen av data: Organisationer samlar in data från en mängd olika källor, inklusive användar-, försäljnings- och transaktionsdata. Företaget kan lita på uppgifterna för affärskrav eftersom datalager sammanställer företagsdata till ett enhetligt, standardiserat format som kan fungera som en enda källa till datasanning.
- Förbättra beslutsfattandet i allmänhet: Datalager underlättar bättre beslutsfattande genom att erbjuda en centraliserad butik för både färsk och gammal data. Genom att bearbeta data i datalager för exakta insikter kan beslutsfattare bedöma risker, förstå kundens önskemål och förbättra varor och tjänster.
- Tillhandahåller bättre affärsintelligens: Datalager överbryggar gapet mellan massiva rådata, som ofta samlas in rutinmässigt som en självklarhet, och den kurerade data som ger insikter. De fungerar som grunden för en organisations datalagring, vilket gör det möjligt för den att svara på komplicerade frågor om sin data och använda svaren för att fatta försvarbara affärsbeslut.
Begränsningar för Data Warehouse
- Brist på dataflexibilitet: Även om datalager utmärker sig på att hantera strukturerad data, kan semistrukturerade och ostrukturerade dataformat som logganalys, streaming och sociala medier vara utmanande för dem. Detta gör att rekommendera datalager för användningsfall som involverar maskininlärning och artificiell intelligens svår.
- Dyrt att installera och underhålla: Datalager kan vara dyra att installera och underhålla. Dessutom är datalagret ofta inte statiskt; det åldras och behöver ofta underhåll, vilket är dyrt.
Fördelar
- Data är enkelt att hitta, hämta och fråga.
- Så länge som data redan är rena är SQL-dataförberedelser enkel.
Nackdelar
- Du tvingas använda endast en analysleverantör.
- Att analysera och lagra ostrukturerad eller flödande data är ganska kostsamt.
Vad är Data Lake?
Varje typ av data utlovas och möjliggörs av datasjöar. Det är fördelaktigt att ha data på ett tillgängligt sätt centralt placerad och tillgänglig för läsning.
En datasjö är ett centraliserat, extremt anpassningsbart lagringsutrymme där enorma volymer av organiserad och ostrukturerad data förvaras i sina obearbetade, oförändrade och oformaterade former.
En datasjö använder en platt arkitektur och objekt lagrade i dess obearbetade tillstånd för att lagra data, till skillnad från datalager, som sparar relationsdata som tidigare har "rensats".
Datasjöar, till skillnad från datalager, som har svårt att hantera data i detta format, är anpassningsbara, tillförlitliga och prisvärda och gör det möjligt för företag att få ökad insikt från ostrukturerad data.
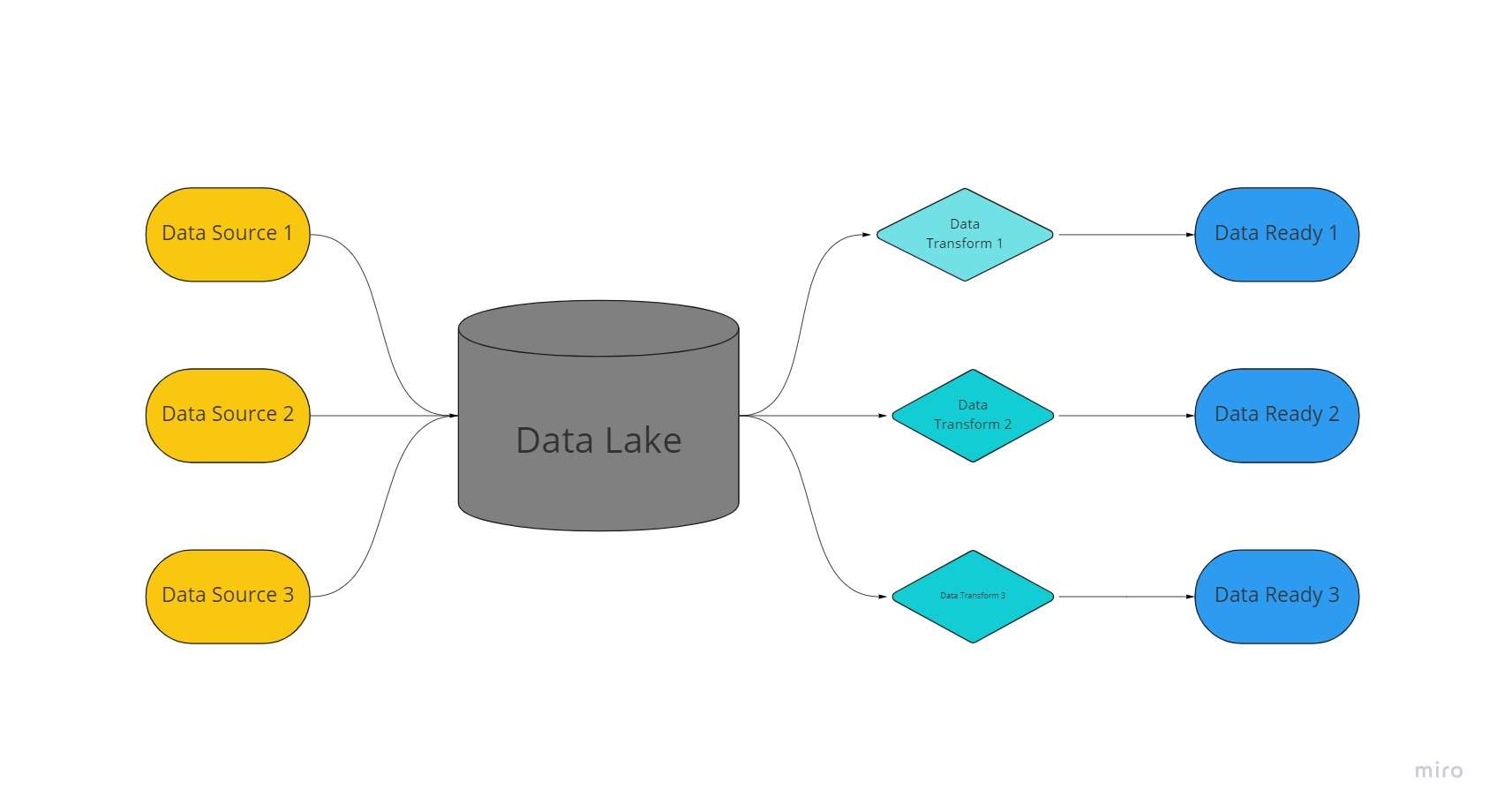
I datasjöar extraheras, laddas och transformeras data (ELT) för analytiska ändamål snarare än att ha schemat eller data etablerade vid tidpunkten för datainsamling.
Att använda teknik för många datatyper från IoT-enheter, sociala medier, och strömmande data möjliggör datasjöar maskininlärning och prediktiv analys.
Dessutom kan en datavetare som kan bearbeta rådata använda datasjön. Ett datalager är å andra sidan lättare för företag att använda. Den är perfekt för användarprofilering, prediktiv analys, maskininlärning och andra uppgifter.
Även om datasjöar löser flera problem med datalager, är deras datakvalitet dålig och deras frågehastighet är otillräcklig. Dessutom krävs det extra verktyg för företagsanvändare att utföra SQL-frågor. En datasjö som är dåligt strukturerad kan uppleva problem med datastagnation.
Fördelar med Data Lake
- Stöd för ett brett utbud av applikationsfall för maskininlärning och datavetenskap Det är enklare att använda en annan maskin och algoritmer för djupinlärning för att hantera data i datasjöar eftersom data hålls på ett öppet, rått sätt.
- Data lakes mångsidighet, som gör att du kan lagra data i vilket format eller media som helst utan krav på ett förinställt schema, är en stor fördel. Framtida dataanvändningsfall kan stödjas och mer data kan analyseras om data lämnas i sitt ursprungliga tillstånd.
- För att undvika att behöva lagra båda typerna av data i olika sammanhang kan datasjöar innehålla både strukturerad och ostrukturerad data. För lagring av olika typer av organisationsdata erbjuder de en enda plats.
- Jämfört med traditionella datalager är datasjöar billigare eftersom de är byggda för att hållas på billig råvaruhårdvara, såsom objektlagring, som ofta är inriktad på en lägre kostnad per lagrad gigabyte.
Begränsningar för Data Lake
- Användningsfall för dataanalys och business intelligence får dåliga resultat: Datasjöar kan bli oorganiserade om de inte underhålls tillräckligt, vilket gör det svårt att länka dem till business intelligence och analysverktyg. Dessutom, när det är nödvändigt för rapportering och analys användningsfall, en brist på konsekvent data struktur och ACID (atomicitet, konsistens, isolering och hållbarhet) transaktionsstöd kan leda till suboptimal frågeprestanda.
- Datasjöarnas inkonsekvens gör det omöjligt att upprätthålla datatillförlitlighet och säkerhet, vilket resulterar i en brist på båda. Det kan vara svårt att utveckla lämpliga datasäkerhets- och styrningsstandarder för att tillgodose känsliga datatyper, eftersom datasjöar kan hantera vilken dataform som helst.
Fördelar
- Lösningar som är prisvärda för alla typer av data.
- Kan hantera data som är både organiserad och semistrukturerad.
- Idealisk för komplicerad databehandling och streaming.
Nackdelar
- Behöver en sofistikerad pipeline byggas.
- Ge data lite tid att bli frågebara.
- Det tar tid att garantera datatillförlitlighet och kvalitet.
Vad är Data Lakehouse?
En ny lagringsarkitektur för stora data som kallas ett "datasjöhus" kombinerar de största aspekterna av datasjöar och datalager. All din data, oavsett om den är strukturerad, semi-strukturerad eller ostrukturerad, kan lagras på en plats med de bästa möjliga maskininlärnings-, affärsintelligens- och streamingmöjligheter tack vare ett datasjöhus.
Datasjöar av alla slag är ofta utgångspunkten för datasjöhus; efter det omvandlas data till Delta Lake-format (ett lagringslager med öppen källkod som ger datasjöar tillförlitlighet).
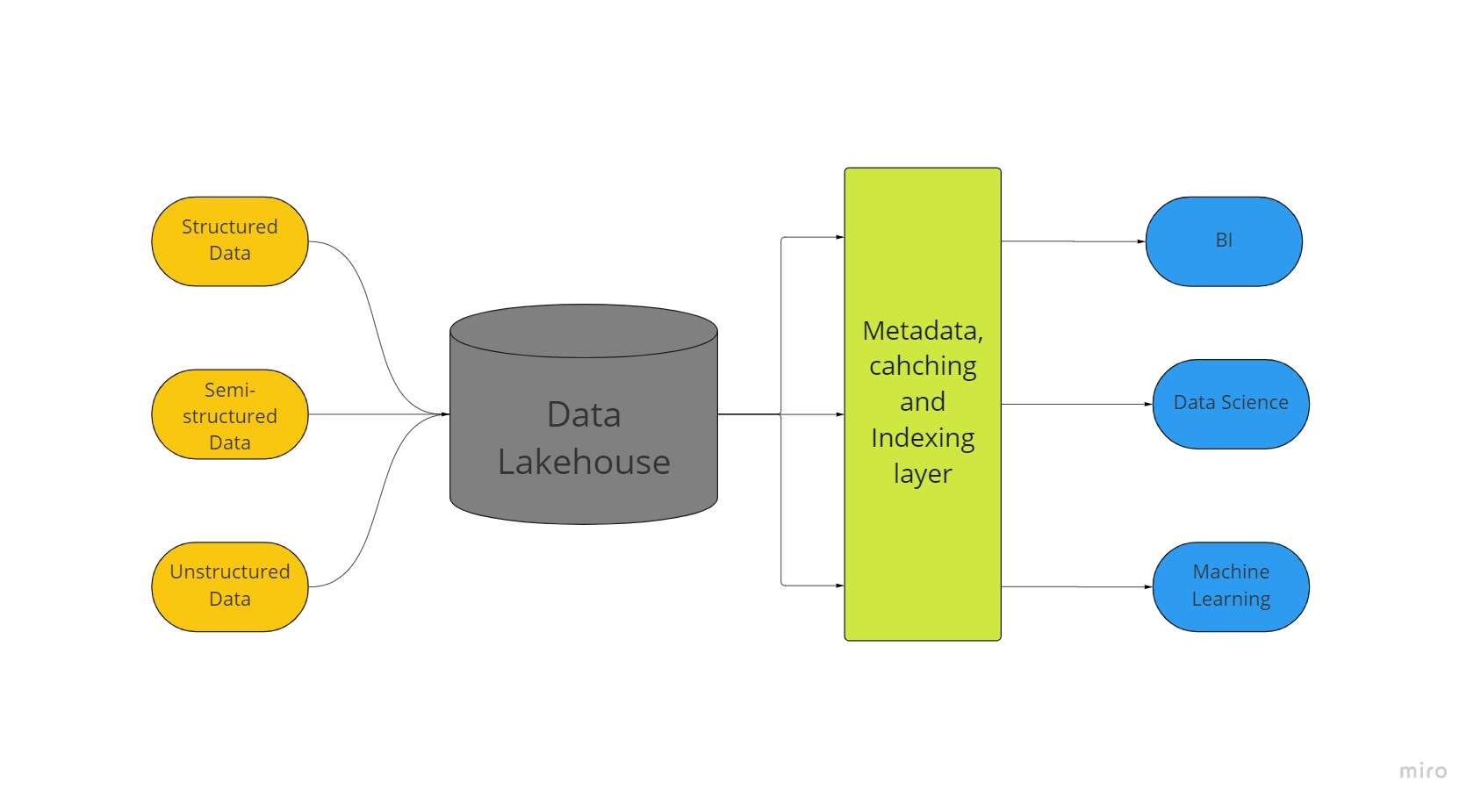
Datasjöar med deltasjöar möjliggör ACID-transaktionsprocedurer från konventionella datalager. I huvudsak använder lakehouse-systemet billig lagring för att upprätthålla enorma mängder data i sina ursprungliga former, ungefär som datasjöar.
Att lägga till metadatalagret ovanpå butiken ger också datastruktur och ger datahanteringsverktyg som de som finns i datalager.
Detta gör det möjligt för många team att få tillgång till all företagsdata genom ett enda system för en mängd olika initiativ, såsom datavetenskap, maskininlärning och business intelligence.
Fördelar med Data Lakehouse
- Stöd för ett större utbud av arbetsbelastningar: För att underlätta sofistikerade analyser ger datasjöhus användarna direkt tillgång till några av de mest populära affärsinformationsverktygen (Tableau, PowerBI). Dessutom kan datavetare och maskininlärningsingenjörer enkelt använda data eftersom datasjöhus använder öppna dataformat (som Parquet) tillsammans med API:er och ramverk för maskininlärning, som Python/R.
- Kostnadseffektivitet: Data lakehouses använder billiga objektlagringslösningar för att implementera datasjöars kostnadseffektiva lagringsegenskaper. Genom att erbjuda en enda lösning slipper datasjöhus också utgifterna och tiden för att hantera olika datalagringssystem.
- Data Lakehouse-design säkerställer schema och dataintegritet, vilket gör det enklare att bygga effektiva datasäkerhets- och styrsystem. Lätthet av dataversionering, styrning och säkerhet.
- Data lakehouses erbjuder en enda, mångsidig datalagringsplattform som kan tillgodose alla företagets databehov, vilket minskar dataduplicering. Majoriteten av företag väljer en hybridlösning på grund av fördelarna med både datalagret och datasjön. Denna strategi kan under tiden resultera i kostsamma dataduplicering.
- Stöd för öppna format. Öppna format är filtyper som kan användas av många program och vars specifikationer är allmänt tillgängliga. Enligt rapporter kan Lakehouses lagra data i vanliga filformat som Apache Parquet och ORC (Optimized Row Columnar).
Begränsningar för Data Lakehouse
En datasjöhus största nackdel är att det fortfarande är en ung och utvecklande teknik. Det är osäkert om det kommer att uppfylla sina åtaganden som ett resultat. Innan datasjöhus kan konkurrera med etablerade lagringssystem för stora data kan det ta år.
Men med tanke på den takt med vilken modern innovation sker, är det svårt att säga om ett annat datalagringssystem inte i slutändan kommer att ersätta det.
Fördelar
- En plattform har all data, vilket innebär att det finns färre värdnamn att underhålla.
- Atomicitet, konsistens, isolering och seghet påverkas inte.
- Det är betydligt billigare.
- En plattform har all data, vilket innebär att det finns färre värdnamn att underhålla.
- Enkel att hantera och snabb att åtgärda eventuella problem
- Gör det enklare att bygga en pipeline
Nackdelar
- Installationen kan ta lite tid.
- Det är för ungt och för långt borta för att kvalificera sig som ett etablerat lagringssystem.
Data Warehouse vs Data Lake vs Data Lakehouse
Datalagret har en lång historia inom företagsintelligens, rapportering och analysapplikationer och är den första stordatalagringsteknologin.
Datalager är å andra sidan dyra och har problem med att hantera olika och ostrukturerade data, som strömmande data. För maskininlärning och datavetenskap arbetsbelastningar utvecklades datasjöar för att hantera rådata i olika former på prisvärd lagring.
Även om datasjöar är effektiva med ostrukturerad data, saknar de ACID-transaktionskapaciteten hos datalager, vilket gör det utmanande att garantera datakonsistens och tillförlitlighet.
Den senaste datalagringsarkitekturen, känd som "datasjöhuset", kombinerar tillförlitligheten och konsekvensen hos datalager med överkomliga och anpassningsbara datasjöar.
Slutsats
Sammanfattningsvis kan det vara svårt att bygga ett datasjöhus från grunden. Dessutom kommer du med största sannolikhet att använda en plattform utformad för att möjliggöra en sjöbyggnadsarkitektur för öppen data.
Var därför försiktig med att undersöka de många funktionerna och implementeringarna av varje plattform innan du gör ett köp. Företag som letar efter en mogen, strukturerad datalösning med fokus på affärsintelligens och användningsfall för dataanalys kan överväga ett datalager.
Företag som letar efter en skalbar, prisvärd big data-lösning för att driva arbetsbelastningar för datavetenskap och maskininlärning på ostrukturerad data bör dock överväga datasjöar.
Tänk på att ditt företag behöver mer data än vad datalagret och datasjötekniken kan tillhandahålla, eller att du letar efter en lösning för att integrera sofistikerad analys och maskininlärning i din data. A data lakehouse är ett vettigt alternativ i situationen.





Kommentera uppropet