Innehållsförteckning[Dölj][Visa]
Vi kan nu beräkna utrymmets vidd och de små krångligheterna hos subatomära partiklar tack vare datorer.
Datorer slår människor när det gäller att räkna och räkna, samt följa logiska ja/nej-processer, tack vare elektroner som färdas med ljusets hastighet via dess kretsar.
Men vi ser dem inte ofta som "intelligenta" eftersom datorer tidigare inte kunde utföra någonting utan att läras (programmeras) av människor.
Maskininlärning, inklusive djupinlärning och artificiell intelligens, har blivit ett modeord i vetenskapliga och tekniska rubriker.
Maskininlärning verkar vara allestädes närvarande, men många människor som använder ordet skulle kämpa för att adekvat definiera vad det är, vad det gör och vad det bäst används för.
Den här artikeln försöker förtydliga maskininlärning samtidigt som den ger konkreta, verkliga exempel på hur tekniken fungerar för att illustrera varför den är så fördelaktig.
Sedan kommer vi att titta på de olika maskininlärningsmetoderna och se hur de används för att hantera affärsutmaningar.
Slutligen kommer vi att konsultera vår kristallkula för några snabba förutsägelser om framtiden för maskininlärning.
Vad är maskininlärning?
Maskininlärning är en disciplin inom datavetenskap som gör det möjligt för datorer att härleda mönster från data utan att explicit lära sig vad dessa mönster är.
Dessa slutsatser är ofta baserade på att använda algoritmer för att automatiskt bedöma de statistiska egenskaperna hos datan och utveckla matematiska modeller för att skildra förhållandet mellan olika värden.
Jämför detta med klassisk beräkning, som är baserad på deterministiska system, där vi uttryckligen ger datorn en uppsättning regler att följa för att den ska kunna utföra en viss uppgift.
Detta sätt att programmera datorer är känt som regelbaserad programmering. Maskininlärning skiljer sig från och överträffar regelbaserad programmering genom att den kan härleda dessa regler på egen hand.
Anta att du är en bankchef som vill avgöra om en låneansökan kommer att misslyckas på deras lån.
I en regelbaserad metod skulle bankchefen (eller andra specialister) uttryckligen informera datorn om att om den sökandes kreditvärdighet är under en viss nivå bör ansökan avslås.
Ett maskininlärningsprogram skulle dock helt enkelt analysera tidigare data om kunders kreditbetyg och låneresultat och bestämma vad denna tröskel bör vara på egen hand.
Maskinen lär sig av tidigare data och skapar sina egna regler på detta sätt. Naturligtvis är detta bara en primer om maskininlärning; Verkliga maskininlärningsmodeller är betydligt mer komplicerade än en grundläggande tröskel.
Icke desto mindre är det en utmärkt demonstration av potentialen för maskininlärning.
Hur fungerar a Maskinen lära sig?
För att göra saker enkelt så "lär sig" maskiner genom att upptäcka mönster i jämförbar data. Betrakta data som information som du samlar in från omvärlden. Ju mer data en maskin matas desto "smartare" blir den.
Men alla data är inte desamma. Anta att du är en pirat med ett livssyfte att avslöja de begravda rikedomarna på ön. Du kommer att behöva en betydande mängd kunskap för att hitta priset.
Denna kunskap, liksom data, kan antingen ta dig på rätt eller fel sätt.
Ju större information/data som samlas in, desto mindre otydlighet är det och vice versa. Som ett resultat är det viktigt att överväga vilken typ av data du matar din maskin att lära av.
Men när en betydande mängd data tillhandahålls kan datorn göra förutsägelser. Maskiner kan förutse framtiden så länge den inte avviker mycket från det förflutna.
Maskiner "lär sig" genom att analysera historiska data för att avgöra vad som sannolikt kommer att hända.
Om den gamla informationen liknar den nya informationen, kommer det du kan säga om den tidigare informationen sannolikt att gälla för den nya datan. Det är som om du blickar bakåt för att se framåt.
Vilka typer av maskininlärning finns det?
Algoritmer för maskininlärning klassificeras ofta i tre breda typer (även om andra klassificeringsscheman också används):
- Övervakad inlärning
- Oövervakat lärande
- Förstärkningslärande
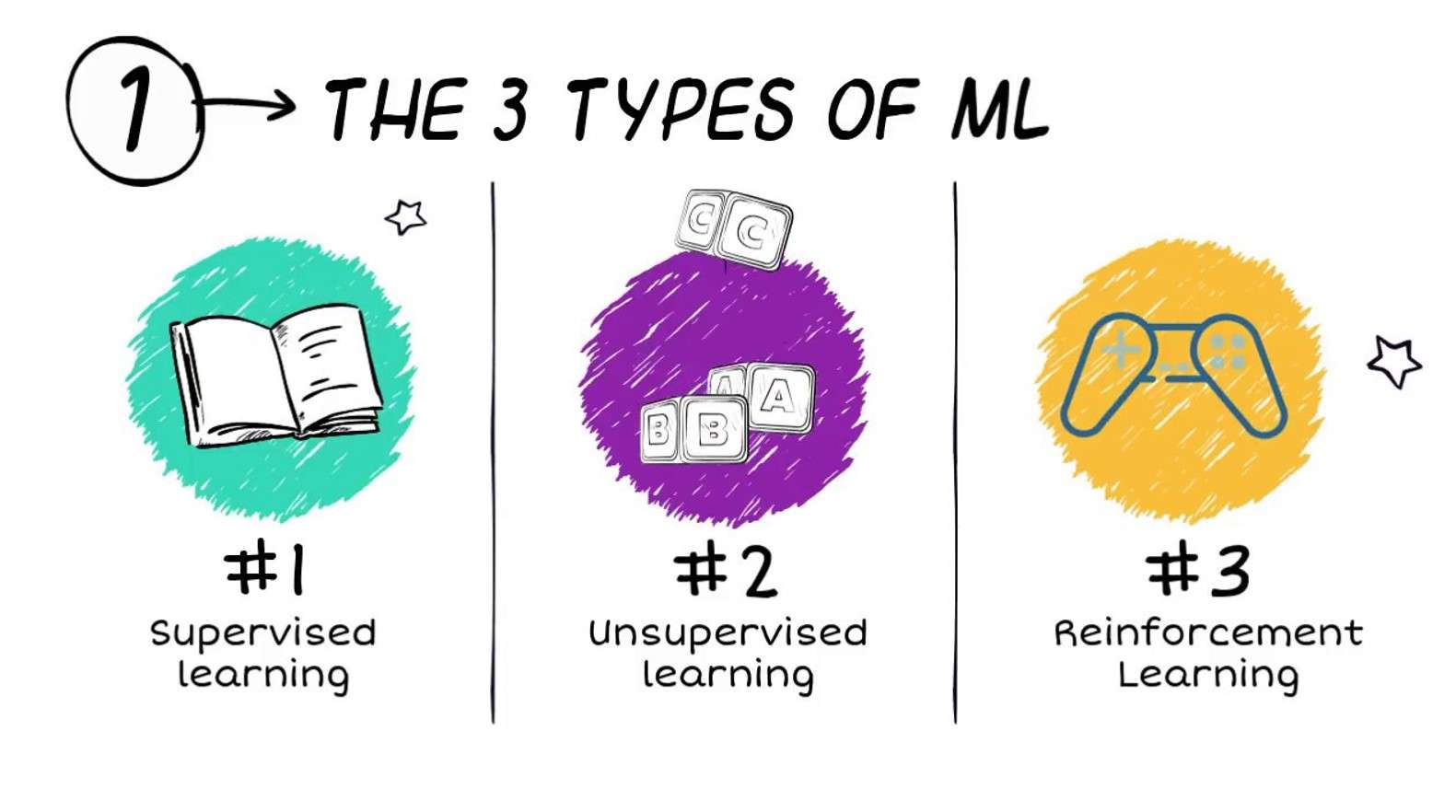
Övervakad inlärning
Övervakad maskininlärning hänvisar till tekniker där maskininlärningsmodellen ges en samling data med explicita etiketter för kvantiteten av intresse (denna kvantitet kallas ofta för svaret eller målet).
För att träna AI-modeller använder semi-övervakad inlärning en blandning av märkta och omärkta data.
Om du arbetar med omärkta data måste du utföra vissa datamärkningar.
Märkning är processen att märka prover för att underlätta träna en maskininlärning modell. Märkning görs i första hand av människor, vilket kan vara kostsamt och tidskrävande. Det finns dock tekniker för att automatisera märkningsprocessen.
Situationen för låneansökan vi diskuterade tidigare är en utmärkt illustration av handled inlärning. Vi hade historiska uppgifter om tidigare lånesökandes kreditvärdighet (och kanske inkomstnivåer, ålder och så vidare) samt specifika etiketter som berättade för oss om personen i fråga misslyckades med sitt lån eller inte.
Regression och klassificering är två undergrupper av övervakade inlärningstekniker.
- Klassificering – Den använder sig av en algoritm för att kategorisera data korrekt. Spamfilter är ett exempel. "Spam" kan vara en subjektiv kategori – gränsen mellan skräppost och icke-spam-kommunikation är suddig – och spamfilteralgoritmen förfinar sig hela tiden beroende på din feedback (vilket betyder e-post som människor markerar som spam).
- Regression – Det är till hjälp för att förstå sambandet mellan beroende och oberoende variabler. Regressionsmodeller kan förutsäga numeriska värden baserat på flera datakällor, såsom uppskattningar av försäljningsintäkter för ett visst företag. Linjär regression, logistisk regression och polynomregression är några framträdande regressionstekniker.
Oövervakat lärande
I oövervakat lärande får vi omärkta data och letar bara efter mönster. Låt oss låtsas att du är Amazon. Kan vi hitta några kluster (grupper av liknande konsumenter) baserat på kundens köphistorik?
Även om vi inte har explicita, avgörande uppgifter om en persons preferenser, i det här fallet, genom att helt enkelt veta att en specifik uppsättning konsumenter köper jämförbara varor kan vi komma med köpförslag baserat på vad andra individer i klustret också har köpt.
Amazons "du kanske också är intresserad av"-karusell drivs av liknande teknologier.
Oövervakat lärande kan gruppera data genom klustring eller association, beroende på vad du vill gruppera ihop.
- Kluster – Oövervakat lärande försöker övervinna denna utmaning genom att söka efter mönster i data. Om det finns ett liknande kluster eller grupp kommer algoritmen att kategorisera dem på ett visst sätt. Att försöka kategorisera kunder utifrån tidigare köphistorik är ett exempel på detta.
- Förening – Oövervakat lärande försöker ta itu med denna utmaning genom att försöka förstå de regler och betydelser som ligger bakom olika grupper. Ett vanligt exempel på ett associationsproblem är att fastställa ett samband mellan kundköp. Butiker kan vara intresserade av att veta vilka varor som köptes tillsammans och kan använda denna information för att ordna placeringen av dessa produkter för enkel åtkomst.
Förstärkningslärande
Förstärkningsinlärning är en teknik för att lära ut maskininlärningsmodeller för att fatta en serie målinriktade beslut i en interaktiv miljö. Spelanvändningsfallen som nämns ovan är utmärkta illustrationer av detta.
Du behöver inte mata in AlphaZero tusentals tidigare schackspel, vart och ett med ett "bra" eller "dåligt" drag märkt. Lär den helt enkelt spelets regler och målet och låt den sedan prova slumpmässiga handlingar.
Positiv förstärkning ges till aktiviteter som tar programmet närmare målet (som att utveckla en solid pantposition). När handlingar har motsatt effekt (som att för tidigt flytta kungen) får de negativ förstärkning.
Programvaran kan i slutändan bemästra spelet med den här metoden.
Förstärkningslärande används ofta inom robotteknik för att lära robotar för komplicerade och svårkonstruerade handlingar. Det används ibland i samband med väginfrastruktur, såsom trafiksignaler, för att förbättra trafikflödet.
Vad kan man göra med maskininlärning?
Användningen av maskininlärning i samhället och industrin resulterar i framsteg inom ett brett spektrum av mänskliga ansträngningar.
I vårt dagliga liv styr maskininlärning nu Googles sök- och bildalgoritmer, vilket gör att vi kan matchas mer exakt med den information vi behöver när vi behöver den.
Inom medicin, till exempel, tillämpas maskininlärning på genetisk data för att hjälpa läkare att förstå och förutsäga hur cancer sprider sig, vilket gör det möjligt att utveckla mer effektiva terapier.
Data från rymden samlas in här på jorden via massiva radioteleskop – och efter att ha analyserats med maskininlärning hjälper det oss att reda ut de svarta hålens mysterier.
Maskininlärning i detaljhandeln länkar köpare till saker de vill köpa online och hjälper också butiksanställda att skräddarsy den service de tillhandahåller till sina kunder i tegel-och-murbruksvärlden.
Maskininlärning används i kampen mot terror och extremism för att förutse beteendet hos dem som vill skada de oskyldiga.
Natural language processing (NLP) syftar på processen att låta datorer förstå och kommunicera med oss på mänskligt språk genom maskininlärning, och det har resulterat i genombrott inom översättningstekniken såväl som de röststyrda enheter vi använder i allt större utsträckning varje dag, som t.ex. Alexa, Google dot, Siri och Google Assistant.
Utan tvekan visar maskininlärning att det är en transformationsteknik.
Robotar som kan arbeta tillsammans med oss och stärka vår egen originalitet och fantasi med sin felfria logik och övermänskliga hastighet är inte längre en science fiction-fantasi – de håller på att bli verklighet inom många sektorer.
Användningsfall för maskininlärning
1. Cybersäkerhet
I takt med att nätverken har blivit mer komplicerade har cybersäkerhetsspecialister arbetat outtröttligt för att anpassa sig till det ständigt växande utbudet av säkerhetshot.
Att motverka snabbt utvecklande skadlig programvara och hackingtaktik är tillräckligt utmanande, men spridningen av Internet of Things (IoT)-enheter har i grunden förändrat cybersäkerhetsmiljön.
Attacker kan inträffa när som helst och var som helst.
Tack och lov har maskininlärningsalgoritmer gjort det möjligt för cybersäkerhetsoperationer att hänga med i denna snabba utveckling.
Prediktiv analys möjliggör snabbare upptäckt och begränsning av attacker, medan maskininlärning kan analysera din aktivitet i ett nätverk för att upptäcka avvikelser och svagheter i befintliga säkerhetsmekanismer.
2. Automatisering av kundservice
Att hantera ett ökande antal kundkontakter online har ansträngt mycket organisation.
De har helt enkelt inte tillräckligt med kundtjänstpersonal för att hantera mängden förfrågningar de får, och det traditionella tillvägagångssättet att lägga ut frågor till en kontaktcenter är helt enkelt oacceptabelt för många av dagens kunder.
Chatbots och andra automatiserade system kan nu möta dessa krav tack vare framsteg inom maskininlärningsteknik. Företag kan frigöra personal för att ta sig an mer kundsupport på hög nivå genom att automatisera vardagliga och lågprioriterade aktiviteter.
När den används på rätt sätt kan maskininlärning i företag hjälpa till att effektivisera problemlösning och ge konsumenterna den typ av hjälpsam support som gör att de blir engagerade varumärkesmästare.
3. kommunikation
Att undvika fel och missuppfattningar är avgörande i alla typer av kommunikation, men mer så i dagens affärskommunikation.
Enkla grammatiska misstag, felaktig ton eller felaktiga översättningar kan orsaka en rad svårigheter vid e-postkontakt, kundutvärderingar, videokonferenser, eller textbaserad dokumentation i många former.
Maskininlärningssystem har avancerad kommunikation långt bortom Microsofts Clippys berusande dagar.
Dessa maskininlärningsexempel har hjälpt individer att kommunicera enkelt och exakt genom att använda naturlig språkbehandling, språköversättning i realtid och taligenkänning.
Även om många individer ogillar autokorrigeringsfunktioner, värdesätter de också att skyddas från pinsamma misstag och felaktig ton.
4. Objektigenkänning
Medan tekniken för att samla in och tolka data har funnits ett tag, har det visat sig vara en bedrägligt svår uppgift att lära datorsystem att förstå vad de tittar på.
Objektigenkänningsfunktioner läggs till i ett ökande antal enheter på grund av maskininlärningsapplikationer.
En självkörande bil, till exempel, känner igen en annan bil när den ser en, även om programmerare inte gav den ett exakt exempel på den bilen att använda som referens.
Denna teknik används nu i detaljhandeln för att påskynda kassaprocessen. Kameror identifierar produkterna i konsumenternas kundvagnar och kan automatiskt fakturera deras konton när de lämnar butiken.
5. Digital marknadsföring
Mycket av dagens marknadsföring sker online, med hjälp av en rad digitala plattformar och program.
När företag samlar in information om sina konsumenter och deras köpbeteenden kan marknadsföringsteam använda den informationen för att skapa en detaljerad bild av sin målgrupp och upptäcka vilka människor som är mer benägna att söka efter deras produkter och tjänster.
Maskininlärningsalgoritmer hjälper marknadsförare att förstå all denna data och upptäcka betydande mönster och attribut som tillåter dem att noggrant kategorisera möjligheter.
Samma teknik möjliggör stor digital marknadsföringsautomatisering. Annonssystem kan ställas in för att upptäcka nya potentiella konsumenter dynamiskt och tillhandahålla relevant marknadsföringsinnehåll till dem vid rätt tid och plats.
Framtiden för maskininlärning
Maskininlärning vinner verkligen popularitet när fler företag och stora organisationer använder tekniken för att ta itu med specifika utmaningar eller driva på innovation.
Denna fortsatta investering visar en förståelse för att maskininlärning ger avkastning på investeringen, särskilt genom några av de ovan nämnda etablerade och reproducerbara användningsfallen.
När allt kommer omkring, om tekniken är tillräckligt bra för Netflix, Facebook, Amazon, Google Maps och så vidare, är chansen stor att den också kan hjälpa ditt företag att få ut det mesta av sin data.
Som ny maskininlärning modeller utvecklas och lanseras kommer vi att se en ökning av antalet applikationer som kommer att användas inom olika branscher.
Detta händer redan med ansiktsigenkänning, som en gång var en ny funktion på din iPhone men som nu implementeras i ett brett utbud av program och applikationer, särskilt de som är relaterade till allmän säkerhet.
Nyckeln för de flesta organisationer som försöker komma igång med maskininlärning är att se förbi de ljusa futuristiska visionerna och upptäcka de verkliga affärsutmaningarna som tekniken kan hjälpa dig med.
Slutsats
I den postindustrialiserade tidsåldern har forskare och proffs försökt skapa en dator som beter sig mer som människor.
Den tänkande maskinen är AI:s viktigaste bidrag till mänskligheten; den fenomenala ankomsten av denna självgående maskin har snabbt förändrat företagets driftregler.
Självkörande fordon, automatiserade assistenter, autonoma tillverkningsanställda och smarta städer har på sistone visat lönsamheten hos smarta maskiner. Maskininlärningsrevolutionen, och framtiden för maskininlärning, kommer att vara med oss under lång tid.





Kommentera uppropet