Datarörelse och lagring har vuxit i betydelse som ett resultat av IT-branschens ständiga expansion och de miljontals datapunkter som produceras varje sekund.
Dessutom måste denna information vara tydlig och enkel att förstå för att stödja exakt beslutsfattande.
För att bibehålla konkurrenskraften och nå långsiktig framgång måste ditt företag lagra och flytta data med hjälp av de mest effektiva lösningarna som finns.
På grund av detta använder fler företag dataväv. Ett av de bästa sätten att spara tid, pengar och resurser är att använda ett datatyg för att bearbeta data och möjliggöra maskininlärning av AI.
I den här artikeln tar vi en djup titt på Data Fabric, inklusive dess användningsområden, huvudkomponenter, fördelar och andra viktiga detaljer.
Så, vad är Data Fabric?
Oavsett var de befinner sig, hantera och se över din data och appar. Kärnan är en dataväv en integrerad dataarkitektur som är säker, mångsidig och anpassningsbar.
En dataväv, som kombinerar det bästa från molnet, kärnan och kanten, är på många sätt ett nytt strategiskt tillvägagångssätt för din verksamhetslagring.
Samtidigt som den är centralt styrd kan den nå överallt, inklusive lokala, offentliga och privata moln, såväl som edge- och IoT-enheter.
Datasilos storleken på skyskrapor och olika, oanslutna infrastrukturer är ett minne blott. En dataväv är baserad på en omfattande samling av datahanteringsverktyg som garanterar konsistens i dina länkade miljöer.
Genom automatisering effektiviserar du tidskrävande hantering, påskyndar utveckling, testning och driftsättning och skyddar dina tillgångar dygnet runt.
Oavsett var dina data och appar finns kan du spåra lagringskostnader, prestanda och effektivitet från en enda plattform.
Du kan snabbt (och, i vissa fall, automatiskt) göra ändringar i din hybridmolninfrastruktur när du har praktisk kunskap om den, som att åtgärda fel, åtgärda säkerhets- och efterlevnadsproblem och skala upp och ned datoranvändning.
Kort sagt, Data Fabric förbättrar driftsättningen av infrastrukturen och effektiviteten i underhållet, sänker kostnaderna och ökar prestandan.
Varför ska du använda ett datatyg?
Alla datacentrerade företag behöver en heltäckande strategi som tar sig över hinder som tid, utrymme, olika mjukvarutyper och dataplatser. Data ska inte döljas bakom brandväggar eller spridas på flera ställen utan bör vara tillgänglig för personer som behöver det.
För att lyckas kräver företag en framtidssäker datalösning och en säker, effektiv, enhetlig miljö. Detta kan göras med en dataväv.
Moderna företags behov av anslutning i realtid, självbetjäning, automatisering och universella förändringar kan inte tillgodoses med traditionell dataintegration.
Även om det ofta inte är ett problem att samla in data från många källor, kämpar många företag med att integrera, bearbeta, kurera och transformera data med data från andra källor.
För att ge en djupgående förståelse för konsumenter, partners och varor måste detta kritiska steg i datahanteringsprocessen ske. På grund av deras förmåga att uppgradera sina system, bättre betjäna kunder och använda sig av cloud computing, får företag en konkurrensfördel som ett resultat.
Var organisationens användare än befinner sig kan dataväven föreställas som ett tyg som är utbrett globalt. I detta nätverk kan användaren vara på vilken plats som helst och fortfarande ha obegränsad tillgång till data i realtid på vilken annan plats som helst.
Kärnkomponenter i datatyg
Kärnkomponenterna som utgör en dataväv kan väljas från och samlas in på en mängd olika sätt. Dataväven kan således implementeras på en mängd olika sätt. Låt oss titta på en datavävs primära element.
- Förstärkt datakatalog
- Persistenslager
- Kunskap Diagram
- Motor för insikter och rekommendationer
- Dataförberedelse och dataleveranslager
- Orkesterering och dataoperationer
Du kan ta en titt på nyckelpelarna i Data Fabric-arkitektur enligt Gartner.
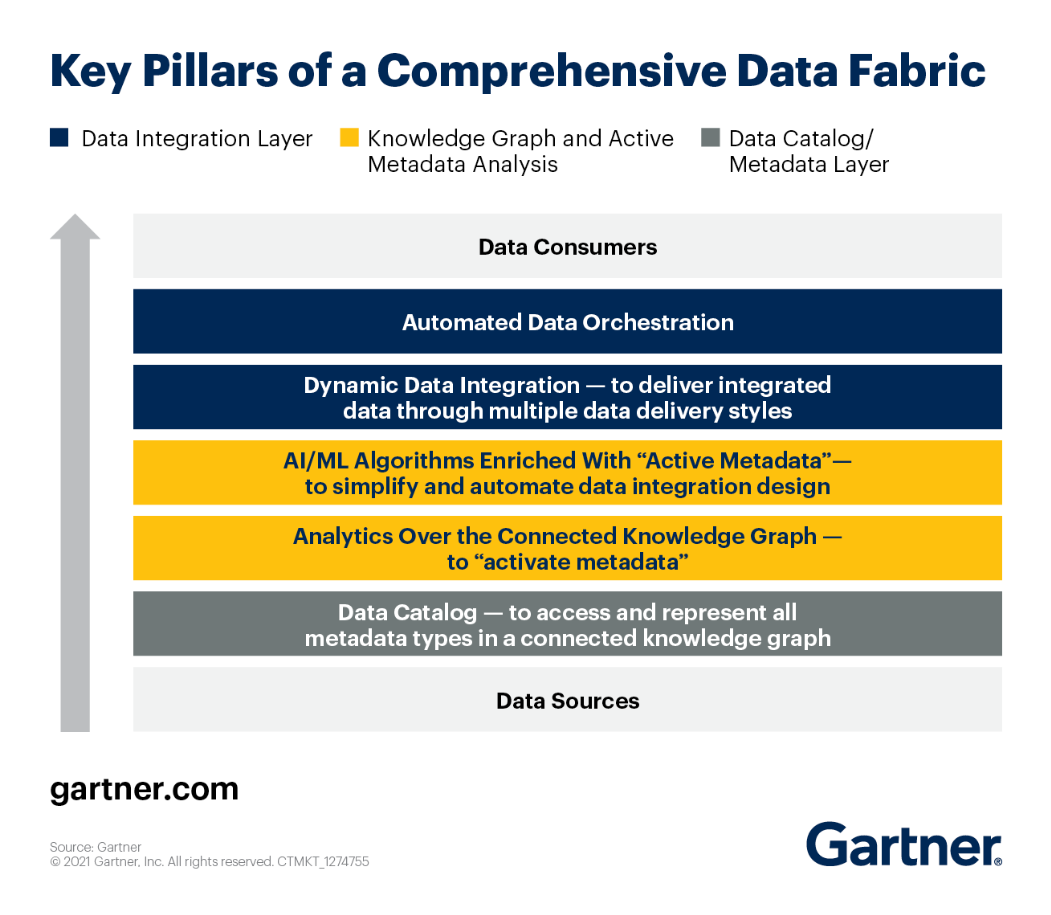
Låt oss titta närmare på var och en av dem.
- Förstärkt datakatalog – ger användarna tillgång till alla typer av metadata genom en stark kunskapsgraf. Dessutom utvecklar den distinkta associationer mellan befintlig information och visar den visuellt på ett begripligt sätt. Genom att använda maskininlärning För att länka datatillgångar med organisatorisk terminologi skapar förbättrade datakataloger det affärssemantiska lagret för dataväven.
- Persistenslager – Beroende på användningsfallet kan en mängd olika relationella och icke-relationella modeller användas för att dynamiskt lagra data.
- Aktiv metadata – en distinkt del av en dataväv. ger dataväven möjligheten att samla in, dela och analysera många typer av metadata. I motsats till passiv metadata spårar aktiv metadata system och människors pågående användning av data (designbaserad metadata och körtidsmetadata).
- Kunskap Diagram – Ytterligare en grundläggande enhet för dataväv. De använder standard-ID:n, anpassningsbara scheman, etc. för att visa en länkad datamiljö. Kunskapsdiagram gör dataväven sökbar och hjälper till att förstå.
- Motor för insikter och rekommendationer – bygger pålitliga, starka datapipelines för både operativa och analytiska användningsfall.
- Dataförberedelse och dataleveranslager – Data kan hämtas från vilken källa som helst och skickas till alla mål med vilken mekanism som helst, inklusive ETL (bulk), meddelandehantering, CDC, virtualisering och API.
- Orkesterering och dataoperationer – Den här komponenten använder data för att koordinera alla uppgifter i varje steg av arbetsflödet från början till slut. Det låter dig välja när och hur ofta du vill köra pipelines samt hur du ska hantera data som dessa pipelines producerar.
Fördelar
Hälsosam data i ett distribuerat sammanhang är tillgängligt, laddat, integrerat och delat över en dataväv. Genom att göra detta kan företag påskynda den digitala övergången och maximera värdet av sin data.
Nedan beskrivs de viktigaste fördelarna med datavävmodellen.
Effektivitet:
En dataväv kan kompilera resultat från tidigare frågor, vilket gör det möjligt för systemet att skanna den aggregerade tabellen snarare än rådata i backend.
På grund av de snabbare svarstiderna för individuella förfrågningar, löser det också problemet med flera samtidiga förfrågningar att låta förfrågningar komma åt mindre datauppsättningar istället för att behöva skanna hela butikens rådata.
Företag kan svara snabbt på pressande förfrågningar på grund av datavävens förmåga att avsevärt minska svarstiderna för frågor.
Smart integration
För att integrera data över olika datatyper och slutpunkter använder datatyger sig av semantiska kunskapsgrafer, metadatahantering och maskininlärning.
Detta hjälper datahanteringsteam att gruppera relevanta datamängder och införliva helt nya datakällor i ett företags dataekosystem.
Den här funktionen automatiserar delar av datauppgiftshanteringen, vilket resulterar i de produktivitetsbesparingar som anges ovan, men den hjälper också till att bryta ned datasystemsilos, centralisera datastyrningsprocedurer och förbättra den övergripande datakvaliteten.
Effektivare datasäkerhet
Det innebär inte heller att offra datasäkerhet och integritetsskydd för att utöka dataåtkomsten.
I själva verket kräver det åtstramning av skyddsräcken för åtkomstkontroll och implementering av fler datastyrningsåtgärder för att garantera att vissa roller är de enda som har tillgång till en given uppsättning data.
Dessutom möjliggör datavävsarkitekturer tekniska och säkerhetsteam för att implementera datamaskering och kryptering kring konfidentiell och känslig information, vilket minskar sannolikheten för datadelning och systemhack.
Demokratisering av data
Självbetjäningsapplikationer underlättas av datavävsdesigner, vilket utökar räckvidden för dataåtkomst bortom mer teknisk personal som dataingenjörer, utvecklare och dataanalysteam.
Genom att tillåta företagsanvändare att göra snabbare affärsval och genom att släppa tekniska användare att prioritera aktiviteter som bäst utnyttjar deras kompetenser, leder elimineringen av dataflaskhalsar till en ökning av produktiviteten.
Användningsfall
En datavävsarkitektur är avsedd att erbjuda en övergripande struktur för att hantera alla former av den lagrade informationen så att den kan göras användbar vid behov.
Den här typen av data kan användas för allt från en försäljningsförutsägelse till en rapport om tillståndet för en organisations IT-infrastruktur eller användarslutpunkter.
Användningsfall för datavävsarkitektur är identiska med användningsfall för alla andra typer av data i ett företag, inklusive försäljning, marknadsföring, IT, cybersäkerhet och mer.
Data i en organisation är dock ofta organiserad, semi-strukturerad eller ostrukturerad i nästan alla användningsfall. En relationsdatabas kan lagra strukturerad data och snabbt användas, såsom databasposter.
Data som inte har rensats eller kategoriserats kallas ostrukturerad data och måste förberedas för användning vid behov.
Flera former av ostrukturerad data som många företag kan förvärva och lagra för framtida användning inkluderar maskininlärning, analys, sensordata, cloud computing och produktivitetsappar.
I semistrukturerade data, som inkluderar data av ett erkänt slag som sparats med ostrukturerad data (som zip-filer, webbsidor och e-postmeddelanden), finns båda aspekterna.
Många möjliga användningsfall baserade på datavävens kapacitet att hjälpa företag att komma åt och använda deras data snabbare och mer effektivt kan hittas genom att undersöka dess användning.
Typiska exempel inkluderar:
- Spårning av bedrägerier
- IoT-analys
- Försörjningskedjans logistik
- Dataanalys i realtid
- Kundinformation
- Ökar operativ effektivitet
- Analys av förebyggande underhåll
- Dessutom riskmodeller för återgång till arbete
- Säkra transaktioner med kreditkort
- Churn-förutsägelse, bedrägeriupptäckt och kreditvärdering
Slutsats
Sammanfattningsvis måste datasilor successivt sönderfalla när våra dataanvändningsnivåer ökar för att ge plats åt anslutna företag.
Utbyggnaden av datastrukturer representerar ett betydande framsteg på denna väg, och rankas bland de mest banbrytande upptäckterna sedan utvecklingen av relationsdatabaser på 1970-talet.
Detta beror på att dataväv är mer än en teknik eller ett enda föremål.
Data och affärsverksamhet är intrikat sammanflätade genom design av arkitektur, ett systematiskt förfarande och en mentalitetsförändring.
Data Fabric minskar kostnaderna, höjer prestanda och underlättar mer effektiv driftsättning och underhåll av infrastruktur. Det kan vara nyckelkomponenten för att säkerställa att varje process, applikation och affärsbeslut är datadriven.





Kommentera uppropet