Tartalomjegyzék[Elrejt][Előadás]
A jövő itt van. És ebben a jövőben a gépek ugyanúgy felfogják az őket körülvevő világot, mint az emberek. A számítógépek vezethetik az autókat, diagnosztizálhatnak betegségeket, és pontosan előre jelezhetik a jövőt.
Ez sci-finak tűnhet, de a mély tanulási modellek valósággá teszik.
Ezek a kifinomult algoritmusok felfedik a titkait mesterséges intelligencia, lehetővé téve a számítógépek számára az önálló tanulást és fejlődést. Ebben a bejegyzésben a mély tanulási modellek birodalmába ásunk bele.
És megvizsgáljuk, milyen hatalmas potenciál rejlik bennük életünk forradalmasítására. Készüljön fel az emberiség jövőjét megváltoztató élvonalbeli technológia megismerésére.

Mik is pontosan a mély tanulási modellek?
Játszottál már olyan játékot, amelyben meg kell találnod a különbségeket két kép között?
Ez azonban szórakoztató, de nehéz is lehet, nem? Képzelje el, hogy képes megtanítani egy számítógépet arra, hogy játsszon ezzel a játékkal, és minden alkalommal nyerjen. A mély tanulási modellek éppen ezt érik el!
A mélytanulási modellek hasonlóak a szuperintelligens gépekhez, amelyek nagyszámú képet képesek megvizsgálni, és meghatározni, mi a közös bennük. Ezt úgy érik el, hogy szétszedik a képeket, és mindegyiket külön-külön tanulmányozzák.
Ezután alkalmazzák a tanultakat, hogy azonosítsák a mintákat, és jóslatokat készítsenek olyan friss képekről, amelyeket korábban soha nem láttak.

A mélytanulási modellek olyan mesterséges neurális hálózatok, amelyek képesek megtanulni és kinyerni a bonyolult mintákat és jellemzőket hatalmas adatkészletekből. Ezek a modellek összekapcsolt csomópontok vagy neuronok több rétegéből állnak, amelyek elemzik és módosítják a bejövő adatokat a kimenet létrehozása érdekében.
A mély tanulási modellek különösen jól illeszkednek a nagy pontosságot és precizitást igénylő munkákhoz, mint például a képazonosítás, a beszédfelismerés, a természetes nyelv feldolgozása és a robotika.
Az önvezető autóktól kezdve az orvosi diagnosztikán át az ajánlórendszerekig mindenben felhasználták őket prediktív elemzés.
Íme a vizualizáció egyszerűsített változata az adatáramlás szemléltetésére egy mély tanulási modellben.
A bemeneti adatok a modell bemeneti rétegébe áramlanak, amely aztán számos rejtett rétegen továbbítja az adatokat, mielőtt kimeneti előrejelzést adna.
Minden rejtett réteg matematikai műveletek sorozatát hajtja végre a bemeneti adatokon, mielőtt átadná azokat a következő rétegnek, amely a végső előrejelzést adja.
Most pedig nézzük meg, melyek azok a mély tanulási modellek, és hogyan használhatjuk őket az életünkben.
1. Konvolúciós neurális hálózatok (CNN-ek)
A CNN-ek egy mély tanulási modell, amely átalakította a számítógépes látás területét. A CNN-eket képek osztályozására, objektumok felismerésére és képek szegmentálására használják. Az emberi látókéreg szerkezete és funkciója befolyásolta a CNN-ek tervezését.
Hogyan működnek ezek?
A CNN számos konvolúciós rétegből, pooling rétegből és teljesen összekapcsolt rétegből áll. A bemenet egy kép, a kimenet pedig a kép osztálycímkéjének előrejelzése.
A CNN konvolúciós rétegei a bemeneti kép és a szűrőkészlet között pontszorzatot hoznak létre egy jellemzőtérképen. A gyűjtőrétegek csökkentik a tereptérkép méretét a mintavételezés csökkentésével.
Végül a jellemzőtérképet használják a teljesen összekapcsolt rétegek a kép osztálycímkéjének megjósolására.

Miért fontosak a CNN-ek?
A CNN-ek nélkülözhetetlenek, mert megtanulhatnak olyan mintákat és jellemzőket észlelni a képeken, amelyeket az emberek nehezen vehetnek észre. A CNN-ek nagy adatkészletek segítségével megtaníthatók olyan jellemzők felismerésére, mint az élek, sarkok és textúrák. Miután megtanulta ezeket a tulajdonságokat, a CNN felhasználhatja őket a friss fényképeken lévő objektumok azonosítására. A CNN-ek élvonalbeli teljesítményt mutattak számos képazonosító alkalmazásban.
Hol használjuk a CNN-eket?
Az egészségügy, az autóipar és a kiskereskedelem csak néhány olyan ágazat, amely CNN-eket alkalmaz. Az egészségügyi ágazatban hasznosak lehetnek betegségek diagnosztizálásában, gyógyszerfejlesztésben és orvosi képelemzésben.
Az autóiparban segítik a sávfelismerést, tárgy észleléseés autonóm vezetés. A kiskereskedelemben is nagymértékben használják vizuális keresésre, képalapú termékajánlásra és készletellenőrzésre.
Például; A Google számos alkalmazásban alkalmazza a CNN-eket, többek között Google Lens, egy kedvelt képazonosító eszköz. A program CNN-eket használ a fényképek értékelésére és a felhasználók tájékoztatására.
A Google Lens például képes felismerni a képeket a képen, és részleteket kínál róluk, például a virág típusát.

A képből kinyert szöveget több nyelvre is lefordíthatja. A Google Lens hasznos információkat tud nyújtani a fogyasztóknak, mivel a CNN-ek segítséget nyújtanak az elemek pontos azonosításában és a jellemzők fotókból való kiemelésében.
2. Hosszú rövid távú memória (LSTM) hálózatok
A hosszú rövid távú memória (LSTM) hálózatokat a rendszeres visszatérő neurális hálózatok (RNN-ek) hiányosságainak kiküszöbölésére hozták létre. Az LSTM hálózatok ideálisak olyan feladatokhoz, amelyek az adatsorozatok időbeli feldolgozását igénylik.
Egy adott memóriacella és három kapuzási mechanizmus alkalmazásával működnek.
Szabályozzák az információáramlást a sejtbe és kifelé. A bemeneti kapu, a felejtési kapu és a kimeneti kapu a három kapu.
A bemeneti kapu szabályozza az adatok áramlását a memóriacellába, a felejtési kapu szabályozza az adatok törlését a cellából, a kimeneti kapu pedig az adatáramlást a cellából.
Mi a jelentőségük?
Az LSTM hálózatok azért hasznosak, mert sikeresen képesek reprezentálni és előre jelezni a hosszú távú kapcsolatokkal rendelkező adatsorozatokat. Rögzíthetik és megőrizhetik a korábbi bemenetekkel kapcsolatos információkat, lehetővé téve számukra, hogy pontosabb előrejelzéseket készítsenek a jövőbeli bemenetekről.
A beszédfelismerés, a kézírás-felismerés, a természetes nyelvi feldolgozás és a képaláírás csak néhány az LSTM-hálózatokat használó alkalmazások közül.
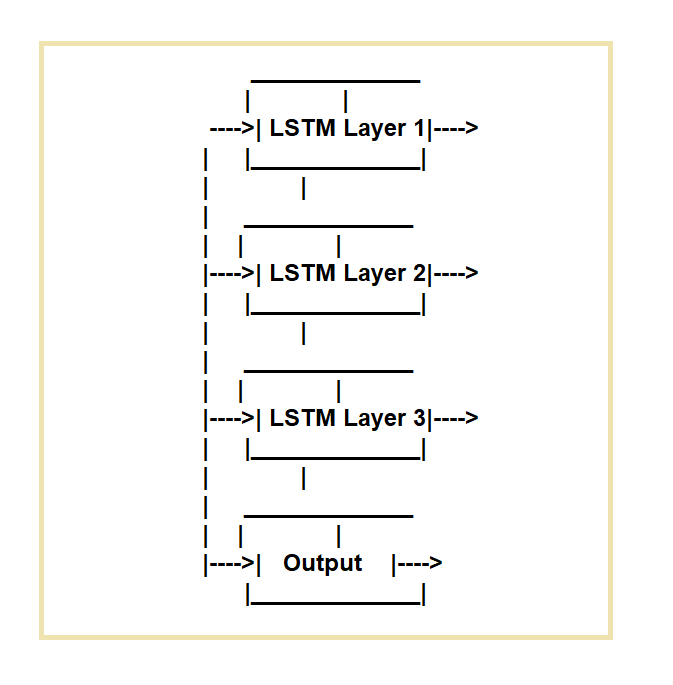
Hol használjuk az LSTM hálózatokat?
Számos szoftver és technológiai alkalmazás alkalmaz LSTM hálózatokat, beleértve a beszédfelismerő rendszereket, a természetes nyelveket feldolgozó eszközöket, mint pl hangulat elemzés, gépi fordítórendszerek, valamint szöveg- és képgeneráló rendszerek.
Felhasználták önvezető autók és robotok létrehozásában, valamint a pénzügyi ágazatban a csalások felderítésére és előrejelzésére. részvénypiac mozgásokat.
3. Generatív ellenséges hálózatok (GAN-ok)
A GAN-ok a mély tanulás technika, amelyet egy adott adatkészlethez hasonló új adatminták létrehozására használnak. A GAN-ok kettőből állnak neurális hálózatok: amelyik megtanul új mintákat készíteni, és amelyik megtanulja megkülönböztetni a valódi és a generált mintákat.
Hasonló megközelítésben ezt a két hálózatot együtt képezik, amíg a generátor nem tud olyan mintákat generálni, amelyek megkülönböztethetetlenek a ténylegesektől.
Miért használunk GAN-okat?
A GAN-ok azért jelentősek, mert képesek kiváló minőséget előállítani szintetikus adatok amelyek különféle alkalmazásokhoz használhatók, beleértve a kép- és videókészítést, a szöveggenerálást, sőt a zenegenerálást is.
A GAN-okat adatbővítésre is használták, ami a szintetikus adatok a valós adatok kiegészítésére és a gépi tanulási modellek teljesítményének javítására.
Ezenkívül a modellek betanítására és a kísérletek utánzására használható szintetikus adatok létrehozásával a GAN-ok képesek átalakítani az olyan ágazatokat, mint az orvostudomány és a gyógyszerfejlesztés.

A GAN-ok alkalmazásai
A GAN-ok kiegészíthetik az adatkészleteket, új képeket vagy filmeket hozhatnak létre, sőt szintetikus adatokat is generálhatnak tudományos szimulációkhoz. Ezenkívül a GAN-ok számos alkalmazásban alkalmazhatók, a szórakoztatástól az orvosiig.
korok és videók. Az NVIDIA StyleGAN2-jét például hírességekről és műalkotásokról készült kiváló minőségű fényképek készítésére használták.
4. Deep Belief Networks (DBN-ek)
A Deep Belief Networks (DBN) olyan mesterséges intelligencia olyan rendszerek, amelyek megtanulják észrevenni az adatok mintáit. Ezt úgy érik el, hogy az adatokat egyre kisebb darabokra szegmentálják, és minden szinten alaposabban átlátják azokat.
A DBN-k anélkül tanulhatnak az adatokból, hogy tájékoztatnák őket arról, hogy miről van szó (ezt „felügyelet nélküli tanulásnak” nevezik). Ez rendkívül értékessé teszi őket az adatok olyan mintáinak felderítésére, amelyeket egy személy nehezen vagy lehetetlennek találna felismerni.
Mitől jelentősek a DBN-k?
A DBN-ek azért fontosak, mert képesek megtanulni a hierarchikus adatreprezentációkat. Ezek a reprezentációk különféle alkalmazásokhoz használhatók, például osztályozáshoz, anomáliák észleléséhez és méretcsökkentéshez.
A DBN-ek azon képessége, hogy felügyelet nélküli előképzést végezzenek, ami minimális címkézett adatokkal növelheti a mély tanulási modellek teljesítményét, jelentős előny.

Mik a DBN-k alkalmazásai?
Az egyik legjelentősebb alkalmazás az tárgy észlelése, amelyben a DBN-eket bizonyos típusú dolgok, például repülőgépek, madarak és emberek felismerésére használják. Használják továbbá képgenerálásra és osztályozásra, filmek mozgásérzékelésére és a hangfeldolgozáshoz a természetes nyelv megértésére.
Ezenkívül a DBN-eket gyakran használják adatkészletekben az emberi testtartás értékelésére. A DBN-ek nagyszerű eszközt jelentenek számos iparág számára, beleértve az egészségügyet és a bankszektort, valamint a technológiát.
5. Mélyen megerősítő tanulási hálózatok (DRL)
Mély Erősítő tanulás A hálózatok (DRL-ek) a mély neurális hálózatokat megerősítő tanulási technikákkal integrálják, hogy lehetővé tegyék az ügynökök számára, hogy bonyolult környezetben, próba és hiba útján tanuljanak.
A DRL-eket arra használják, hogy megtanítsák az ügynököknek, hogyan optimalizálják a jutalomjelet a környezetükkel való interakció és a hibáikból való tanulás révén.
Mi teszi őket figyelemre méltóvá?
Hatékonyan használták számos alkalmazásban, beleértve a játékokat, a robotikát és az autonóm vezetést. A DRL-ek azért fontosak, mert közvetlenül tanulhatnak a nyers érzékszervi bemenetből, lehetővé téve az ügynökök számára, hogy a környezettel való interakcióik alapján hozzanak döntéseket.
Fontos alkalmazások
A DRL-eket valós körülmények között alkalmazzák, mert képesek kezelni a nehéz problémákat.
A DRL-eket számos kiemelkedő szoftver és technológiai platform tartalmazza, beleértve az OpenAI Gym-et, A Unity ML-ügynökeiés a Google DeepMind Lab. AlphaGo, amelyet a Google épített DeepMindpéldául DRL-t alkalmaz a Go társasjáték világbajnoki szinten való játékához.

A DRL másik felhasználási területe a robotika, ahol a robotkarok mozgásának vezérlésére használják olyan feladatok végrehajtására, mint például a dolgok megfogása vagy a blokkok egymásra rakása. A DRL-eknek számos felhasználási területük van, és ezek hasznos eszközei képzési ügynökök tanulni és bonyolult körülmények között hozzon döntéseket.
6. Automatikus kódolók
Az automatikus kódolók egy érdekes típus neurális hálózat ami felkeltette mind a tudósok, mind az adatkutatók érdeklődését. Alapvetően arra szolgálnak, hogy megtanulják az adatok tömörítését és visszaállítását.
A bemeneti adatok a rétegek egymásutánján keresztül vannak betáplálva, amelyek fokozatosan csökkentik az adatok dimenzióját, amíg egy szűk keresztmetszetű rétegbe tömörülnek, kevesebb csomóponttal, mint a bemeneti és kimeneti réteg.
Ezt a tömörített reprezentációt azután az eredeti bemeneti adatok újbóli létrehozására használják olyan rétegek sorozatával, amelyek fokozatosan visszaemelik az adatok eredeti alakját.
Miért fontos?
Az automatikus kódolók kulcsfontosságú összetevői mély tanulás mert lehetővé teszik a jellemzők kinyerését és az adatok csökkentését.
Képesek azonosítani a bejövő adatok kulcsfontosságú elemeit, és lefordítani azokat egy tömörített formára, amelyet aztán más feladatokra, például osztályozásra, csoportosításra vagy új adatok létrehozására lehet alkalmazni.
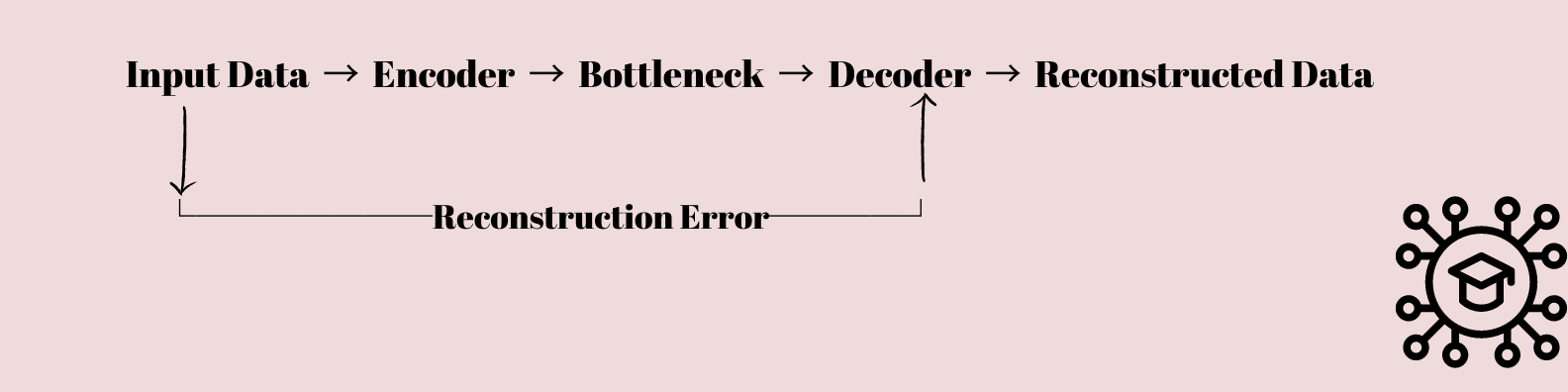
Hol használjunk automatikus kódolókat?
Anomália észlelése, természetes nyelvi feldolgozása, ill számítógépes látás Ez csak néhány olyan tudományág, ahol az automatikus kódolókat használják. Az automatikus kódolók például használhatók képtömörítésre, képzajtalanításra és képszintézisre a számítógépes látásban.
Az automatikus kódolókat olyan feladatokban használhatjuk, mint a szövegalkotás, a szöveg kategorizálása és a szövegösszegzés a természetes nyelvi feldolgozás során. Az anomália azonosításában a normától eltérő adatokban képes azonosítani a rendellenes tevékenységet.
7. Kapszula hálózatok
A Capsule Networks egy új mély tanulási architektúra, amelyet a konvolúciós neurális hálózatok (CNN-ek) helyettesítésére fejlesztettek ki.
A kapszulahálózatok azon az elgondoláson alapulnak, hogy olyan agyi egységeket csoportosítanak, amelyeket kapszuláknak neveznek, és amelyek felelősek egy bizonyos elem létezésének felismeréséért a képen, és annak attribútumait, például az orientációt és a pozíciót, kimeneti vektoraikba kódolják. A kapszulahálózatok ezért jobban tudják kezelni a térbeli interakciókat és a perspektivikus ingadozásokat, mint a CNN-ek.
Miért választjuk a kapszulahálózatokat a CNN-ekkel szemben?
A kapszulahálózatok hasznosak, mert leküzdik a CNN nehézségeit a képeken szereplő elemek közötti hierarchikus kapcsolatok rögzítésében. A CNN-ek különféle méretű dolgokat képesek felismerni, de nehezen tudják felfogni, hogy ezek az elemek hogyan kapcsolódnak egymáshoz.
A Capsule Networks viszont megtanulhatja felismerni a dolgokat és darabjaikat, valamint azt, hogy hogyan helyezkednek el térben egy képen, így életképes versenyzővé válhatnak a számítógépes látási alkalmazások számára.
Alkalmazási területek
A Capsule Networks már számos alkalmazásban ígéretes eredményeket mutatott fel, beleértve a képosztályozást, az objektumazonosítást és a képszegmentálást.
Arra használták őket, hogy megkülönböztessék a dolgokat az orvosi fotókon, felismerjék az embereket a filmekben, és még 3D-s modelleket is készítsenek 2D-s képekből.
A teljesítményük növelése érdekében a kapszulahálózatokat más mély tanulási architektúrákkal kombinálták, mint például a Generatív Adversarial Networks (GAN) és a Variational Autoencoder (VAE). A kapszulahálózatok az előrejelzések szerint egyre fontosabb szerepet fognak játszani a számítógépes látástechnológiák fejlesztésében, ahogy a mély tanulás tudománya fejlődik.
Például; Nibabel egy jól ismert Python eszköz a neuroimaging fájltípusok olvasására és írására. A képszegmentáláshoz Capsule Networks-t alkalmaz.
8. Figyelem alapú modellek
A figyelem alapú modellekként ismert mély tanulási modellek, más néven figyelemmechanizmusok arra törekszenek, hogy növeljék a tanulás pontosságát. gépi tanulási modellek. Ezek a modellek úgy működnek, hogy a bejövő adatok bizonyos jellemzőire koncentrálnak, ami hatékonyabb és eredményesebb feldolgozást eredményez.
A természetes nyelvi feldolgozási feladatokban, mint például a gépi fordítás és a hangulatelemzés, a figyelemfelkeltő módszerek meglehetősen sikeresnek bizonyultak.
Mi a jelentőségük?
A figyelem alapú modellek azért hasznosak, mert lehetővé teszik a bonyolult adatok hatékonyabb és hatékonyabb feldolgozását.
Hagyományos neurális hálózatok minden bemeneti adatot egyformán fontosnak értékel, ami lassabb feldolgozást és csökkent pontosságot eredményez. A figyelemfelhívó folyamatok a bemeneti adatok döntő szempontjaira összpontosítanak, lehetővé téve a gyorsabb és pontosabb előrejelzéseket.

Felhasználási területek
A mesterséges intelligencia területén a figyelemfelkeltő mechanizmusok széles körben alkalmazhatók, beleértve a természetes nyelvi feldolgozást, a kép- és hangfelismerést, sőt a vezető nélküli járműveket is.
A figyelemfelkeltő módszerek például használhatók a gépi fordítás javítására a természetes nyelvi feldolgozásban azáltal, hogy lehetővé teszik a rendszer számára, hogy bizonyos szavakra vagy kifejezésekre összpontosítson, amelyek elengedhetetlenek a kontextushoz.
Az autonóm autókban alkalmazott figyelemfelkeltő módszerek segíthetik a rendszert abban, hogy a környezetében lévő bizonyos elemekre vagy kihívásokra összpontosítson.
9. Transzformátorhálózatok
A transzformátor hálózatok mély tanulási modellek, amelyek adatsorozatokat vizsgálnak és állítanak elő. Úgy működnek, hogy a bemeneti sorozatot elemenként feldolgozzák, és azonos vagy eltérő hosszúságú kimeneti sorozatot állítanak elő.
A transzformátorhálózatok, ellentétben a szabványos szekvencia-szekvencia modellekkel, nem dolgoznak fel szekvenciákat ismétlődő neurális hálózatok (RNN-ek) segítségével. Ehelyett önfigyelési folyamatokat alkalmaznak, hogy megtanulják a szekvencia darabjai közötti kapcsolatokat.
Mi a transzformátor hálózatok jelentősége?
A transzformátorhálózatok népszerűsége az elmúlt években nőtt a természetes nyelvi feldolgozási feladatokban nyújtott jobb teljesítményük eredményeként.
Különösen alkalmasak olyan szövegalkotási feladatokra, mint a nyelvi fordítás, szövegösszegzés és beszélgetés létrehozása.
A transzformátorhálózatok számítási szempontból lényegesen hatékonyabbak, mint az RNN-alapú modellek, így előnyös választás a nagyszabású alkalmazásokhoz.

Hol találhat transzformátor hálózatokat?
A transzformátorhálózatokat széles körben alkalmazzák az alkalmazások széles körében, különösen a természetes nyelvi feldolgozásban.
A GPT (Generative Pre-trained Transformer) sorozat egy kiemelkedő transzformátor alapú modell, amelyet olyan feladatokhoz használtak, mint a nyelvi fordítás, szövegösszegzés és chatbot generálás.
A BERT (Bidirectional Encoder Representations from Transformers) egy másik elterjedt transzformátor-alapú modell, amelyet természetes nyelvi megértési alkalmazásokhoz, például kérdések megválaszolásához és hangulatelemzéshez használnak.
Mindkét GPT és a BERT együtt jött létre PyTorch, egy nyílt forráskódú mélytanulási keretrendszer, amely népszerű volt a transzformátor alapú modellek fejlesztésében.
10. Korlátozott Boltzmann-gépek (RBM-ek)
A korlátozott Boltzmann-gépek (RBM) egyfajta felügyelet nélküli neurális hálózat, amely generatív módon tanul. Tanulási képességük és a nagy dimenziós adatokból alapvető jellemzők kinyerésére való képességük miatt széles körben alkalmazzák őket a gépi tanulás és a mély tanulás területén.
Az RBM-ek két rétegből állnak, látható és rejtett, és mindegyik réteg neuronok csoportjából áll, amelyeket súlyozott élek kapcsolnak össze. Az RBM-eket úgy tervezték, hogy megtanuljanak egy valószínűségi eloszlást, amely leírja a bemeneti adatokat.
Mik azok a korlátozott Boltzmann gépek?
Az RBM-ek generatív tanulási stratégiát alkalmaznak. Az RBM-ekben a látható réteg tükrözi a bemeneti adatokat, míg az eltemetett réteg a bemeneti adatok jellemzőit kódolja. A látható és a rejtett rétegek súlya a kapcsolat erősségét mutatja.
Az RBM-ek a kontrasztív divergenciának nevezett technikával állítják be a súlyokat és a torzításokat a rétegek között edzés közben. A kontrasztos divergencia egy nem felügyelt tanulási stratégia, amely maximalizálja a modell előrejelzési valószínűségét.
Mi a Korlátozott Boltzmann-gépek jelentősége?
Az RBM-ek jelentősek gépi tanulás és mély tanulás, mert nagy mennyiségű adatból tanulhatnak és vonhatnak ki releváns jellemzőket.
Nagyon hatékonyak a kép- és beszédfelismerésben, és számos alkalmazásban alkalmazták őket, például ajánlórendszerekben, anomáliák észlelésében és méretcsökkentésben. Az RBM-ek hatalmas adatkészletekben találhatnak mintákat, ami kiváló előrejelzéseket és betekintést eredményez.

Hol használhatók a korlátozott Boltzmann gépek?
Az RBM-ek alkalmazásai között szerepel a méretcsökkentés, az anomália-észlelő és az ajánlórendszer. Az RBM-ek különösen hasznosak a hangulatelemzésben és témamodellezés a természetes nyelvi feldolgozás keretében.
A mélyhitű hálózatok, egyfajta neurális hálózatok, amelyeket hang- és képfelismerésre használnak, szintén RBM-eket alkalmaznak. A Deep Belief Network eszköztár, TensorFlowés Theano néhány konkrét példa az RBM-eket használó szoftverre vagy technológiára.
Wrap Up
A mélytanulási modellek egyre fontosabbá válnak számos iparágban, beleértve a beszédfelismerést, a természetes nyelvi feldolgozást és a számítógépes látást.
A konvolúciós neurális hálózatok (CNN-ek) és az ismétlődő neurális hálózatok (RNN-ek) bizonyultak a legígéretesebbnek, és széles körben használják őket számos alkalmazásban, azonban minden mélytanulási modellnek megvannak a maga előnyei és hátrányai.
A kutatók azonban továbbra is vizsgálják a korlátozott Boltzmann-gépeket (RBM) és a Deep Learning modellek más fajtáit, mivel ezek is különleges előnyökkel rendelkeznek.
Várhatóan új és kreatív modellek jönnek létre, ahogy a mély tanulás területe tovább fejlődik a nehezebb problémák kezelése érdekében





Hagy egy Válaszol