Vivimos tempos emocionantes, con anuncios sobre tecnoloxía de punta cada semana. OpenAI acaba de lanzar o modelo de vangarda texto a imaxe DALLE 2.
Só unhas poucas persoas obtiveron acceso anticipado a un novo sistema de IA que pode xerar gráficos realistas a partir de descricións en linguaxe natural. Aínda está pechado ao público.
Estabilidade AI lanzou entón o Difusión estable modelo, unha variante de código aberto de DALLE2. Este lanzamento cambiou todo. A xente de toda Internet publicaba resultados rápidos e estaba sorprendido pola arte realista.
Que é a difusión estable?
Difusión estable é un modelo de aprendizaxe automática capaz de crear imaxes a partir de texto, cambiar imaxes dependendo do texto e encher os detalles en imaxes de baixa resolución ou pouco detalle.
Foi adestrado en miles de millóns de fotos e pode ofrecer resultados equivalentes a DALL-E2 Media viaxe. Estabilidade AI inventouno e fíxose público o 22 de agosto de 2022.
Pero con recursos computacionais locais limitados, o modelo de difusión estable leva moito tempo crear imaxes de alta calidade. Executar o modelo en liña mediante un provedor de nube ofrécenos recursos computacionais case infinitos e permítenos adquirir excelentes resultados moito máis rápido.
Aloxar o modelo como un microservizo tamén permite que outras aplicacións creativas exploten máis facilmente o potencial do modelo sen ter que xestionar as complexidades de executar modelos de ML en liña.
Nesta publicación, tentaremos demostrar como desenvolver un modelo de difusión estable e implementalo en AWS.
Construír e implementar Stable Diffusion
BentoML e Amazon Web Services EC2 son dúas opcións para aloxar o modelo Stable Diffusion en liña. BentoML é un marco de código aberto para escalar aprendizaxe de máquina Servizos. Con BentoML, crearemos un servizo de dispersión fiable e implantaremos en AWS EC2.
Preparación do entorno e descarga do modelo de difusión estable
Instala os requisitos e clona o repositorio.
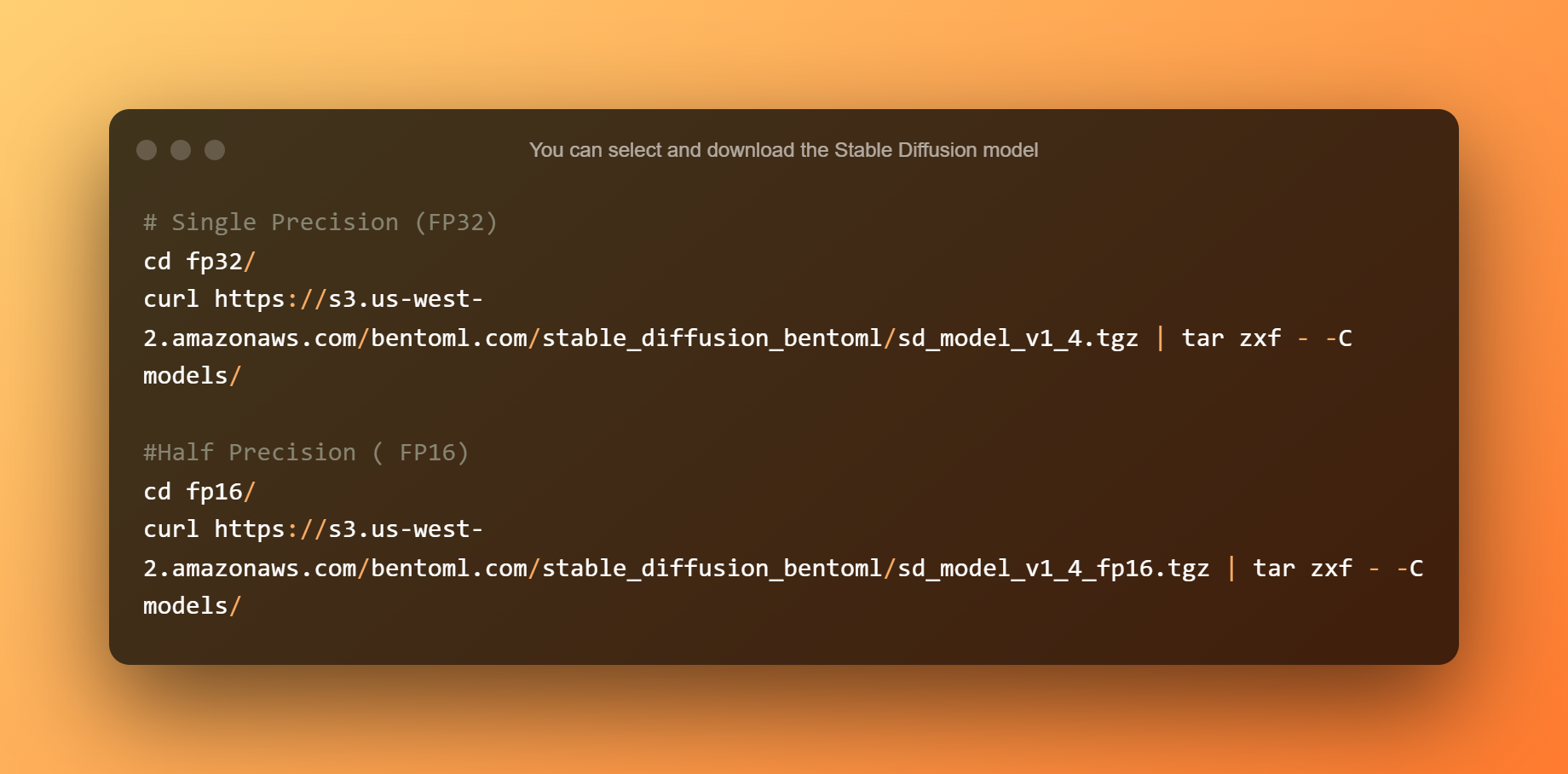
Pode seleccionar e descargar o modelo Stable Diffusion. A precisión única é adecuada para CPU ou GPU con máis de 10 GB de VRAM. A media precisión é ideal para GPU con menos de 10 GB de VRAM.
Construción de difusión estable
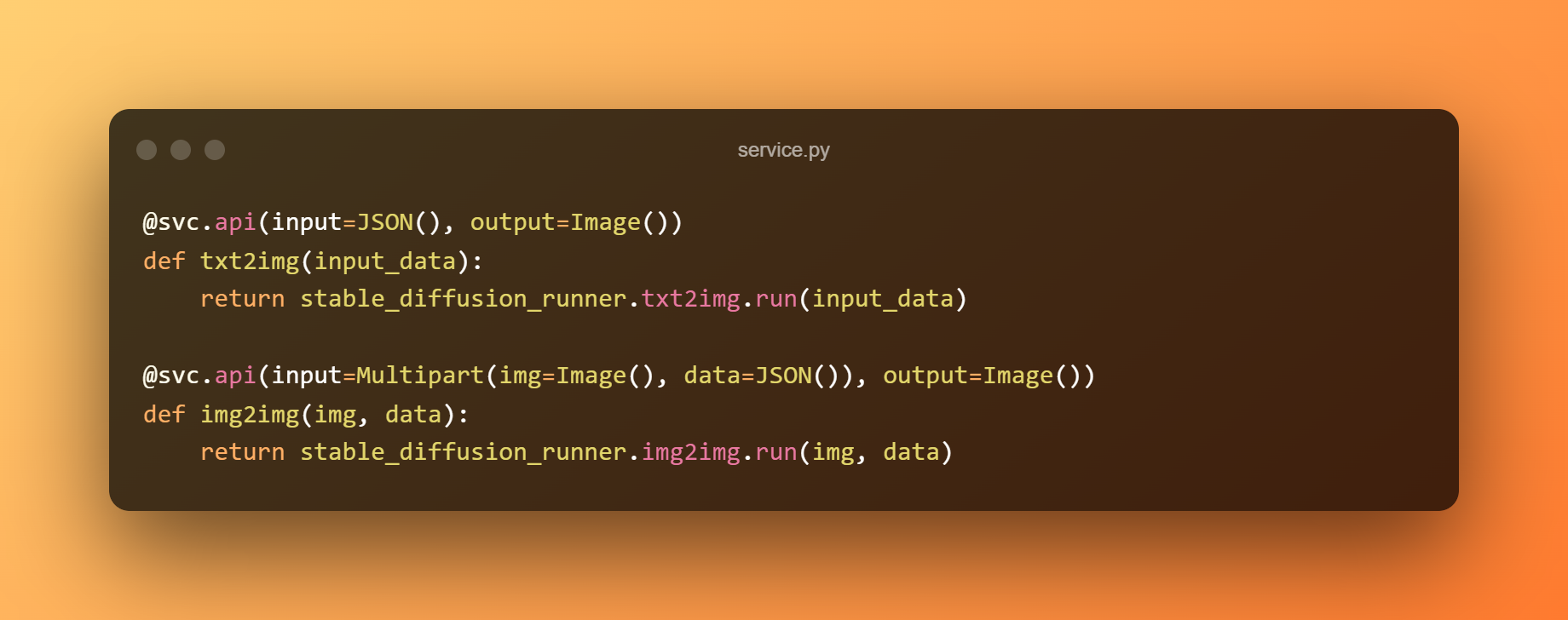
Construiremos un servizo BentoML para servir o modelo detrás dun API RESTful. O seguinte exemplo usa o modelo de precisión única para a predición e o módulo service.py para conectar o servizo á lóxica empresarial. Podemos expoñer as funcións como API etiquetándoas con @svc.api.
Ademais, podemos definir os tipos de entrada e saída das API nos parámetros. O punto final txt2img, por exemplo, recibe unha entrada JSON e produce unha saída de imaxe, mentres que o punto final img2img acepta unha entrada de imaxe e JSON e devolve unha saída de imaxe.
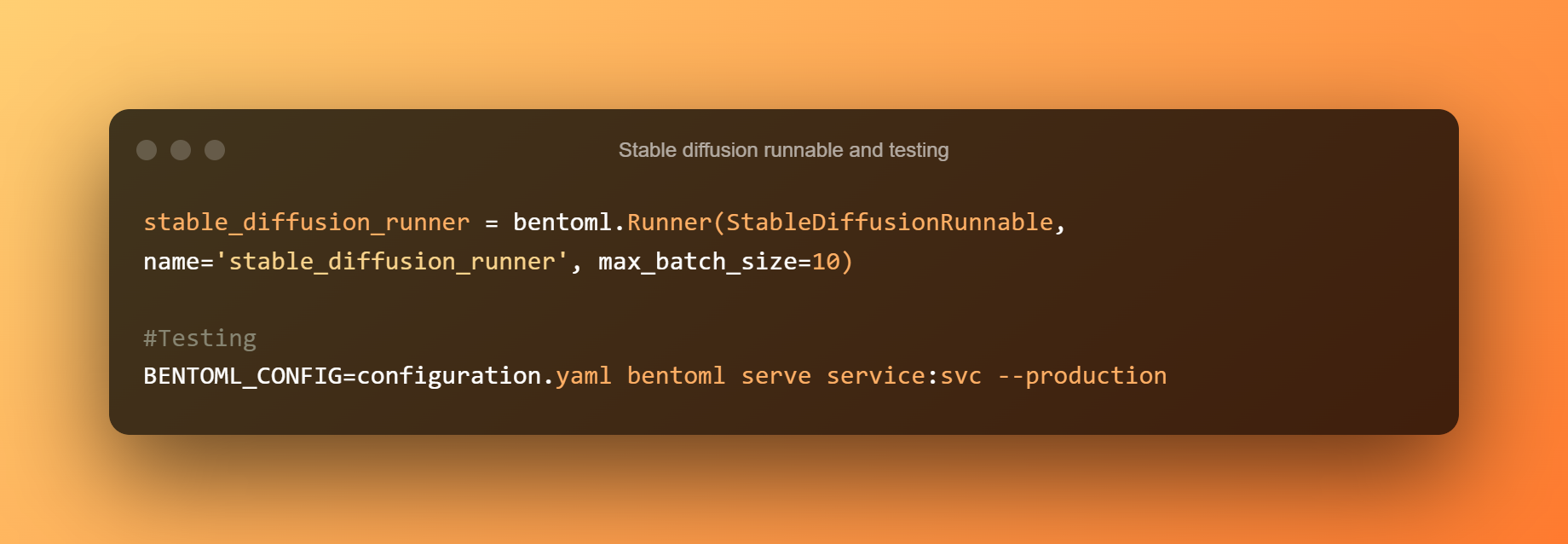
Un StableDiffusionRunnable define a lóxica de inferencia esencial. O executable encárgase de executar os métodos de canalización txt2img do modelo e de enviar as entradas relevantes. Para executar a lóxica de inferencia do modelo nas API, constrúese un Runner personalizado a partir de StableDiffusionRunnable.
A continuación, use o seguinte comando para iniciar un servizo BentoML para probalo. Execución local Modelo de difusión estable a inferencia sobre as CPU é bastante lenta. Cada solicitude tardará uns 5 minutos en procesarse.
Texto a imaxe
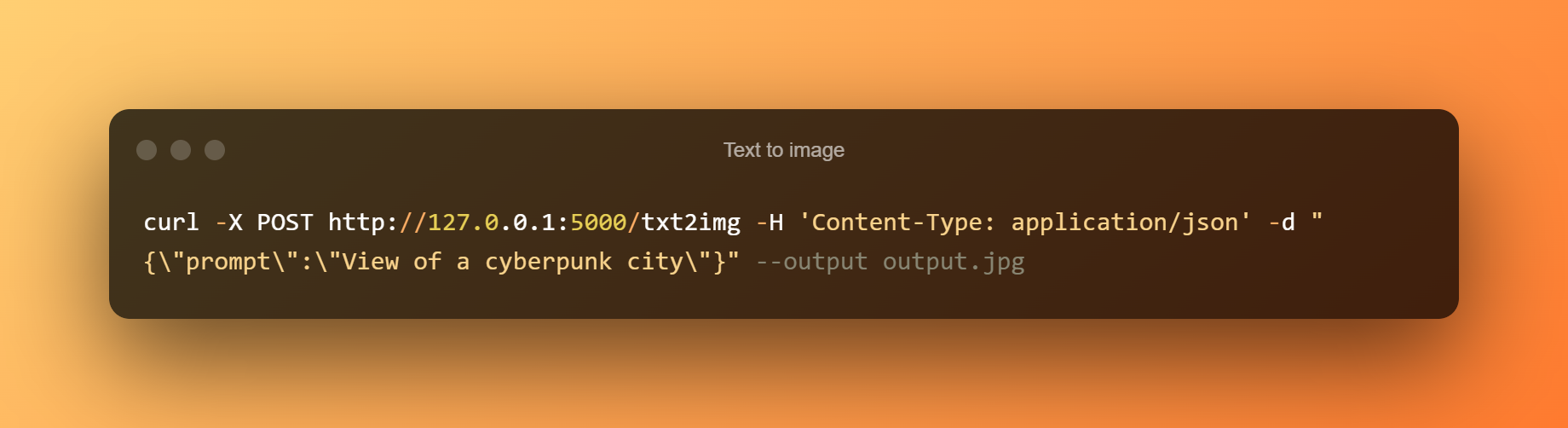
Saída de texto a imaxe

O ficheiro bentofile.yaml define os ficheiros e dependencias necesarios.
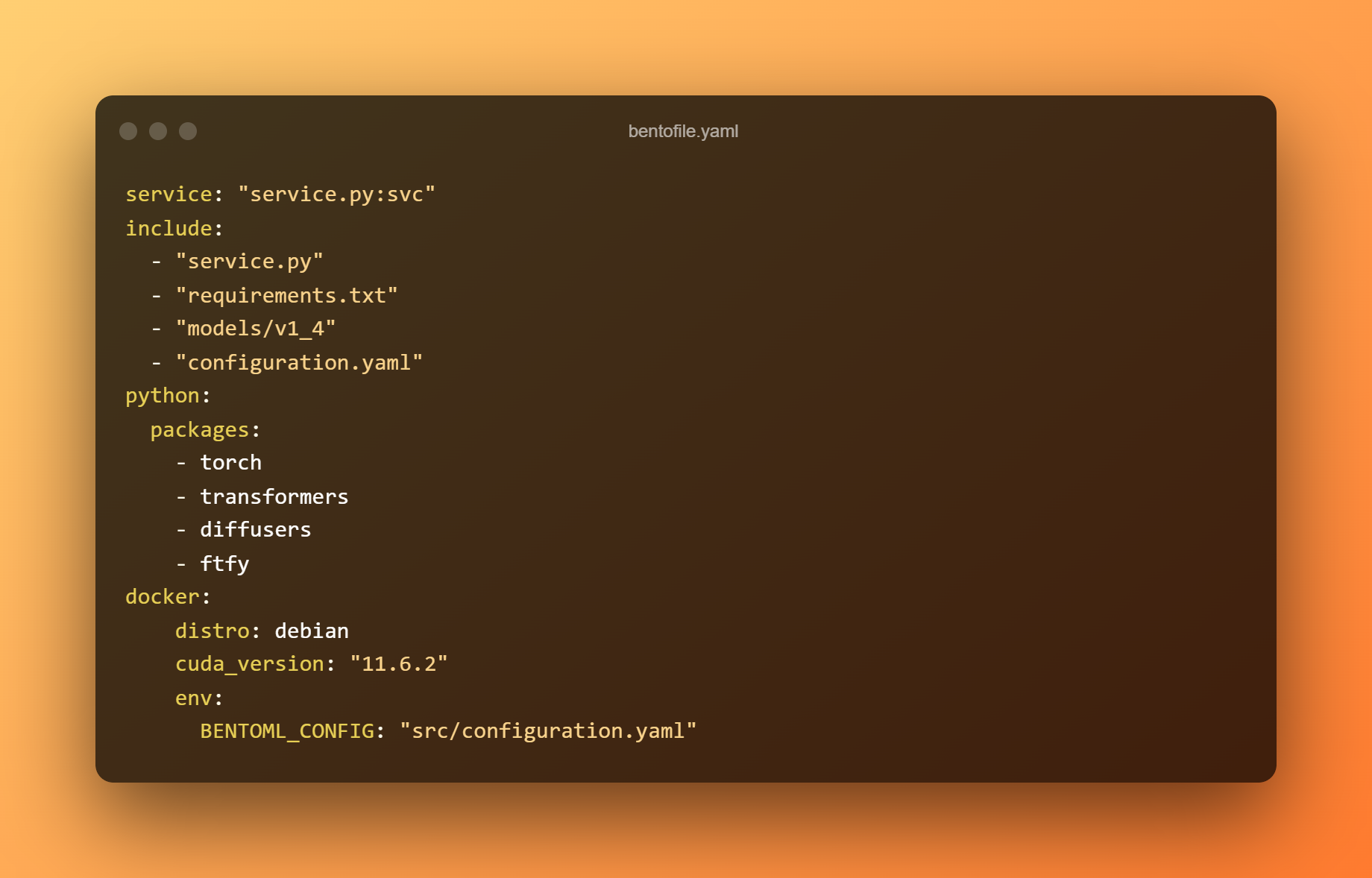
Use o seguinte comando para construír un bento. Un Bento é o formato de distribución para un servizo BentoML. É un arquivo autónomo que contén todos os datos e configuracións necesarios para iniciar o servizo.

Rematou o bento de Difusión estable. Se non puideches xerar correctamente o bento, non te asustes; pode descargar o modelo preconstruído usando os comandos que se indican na seguinte sección.
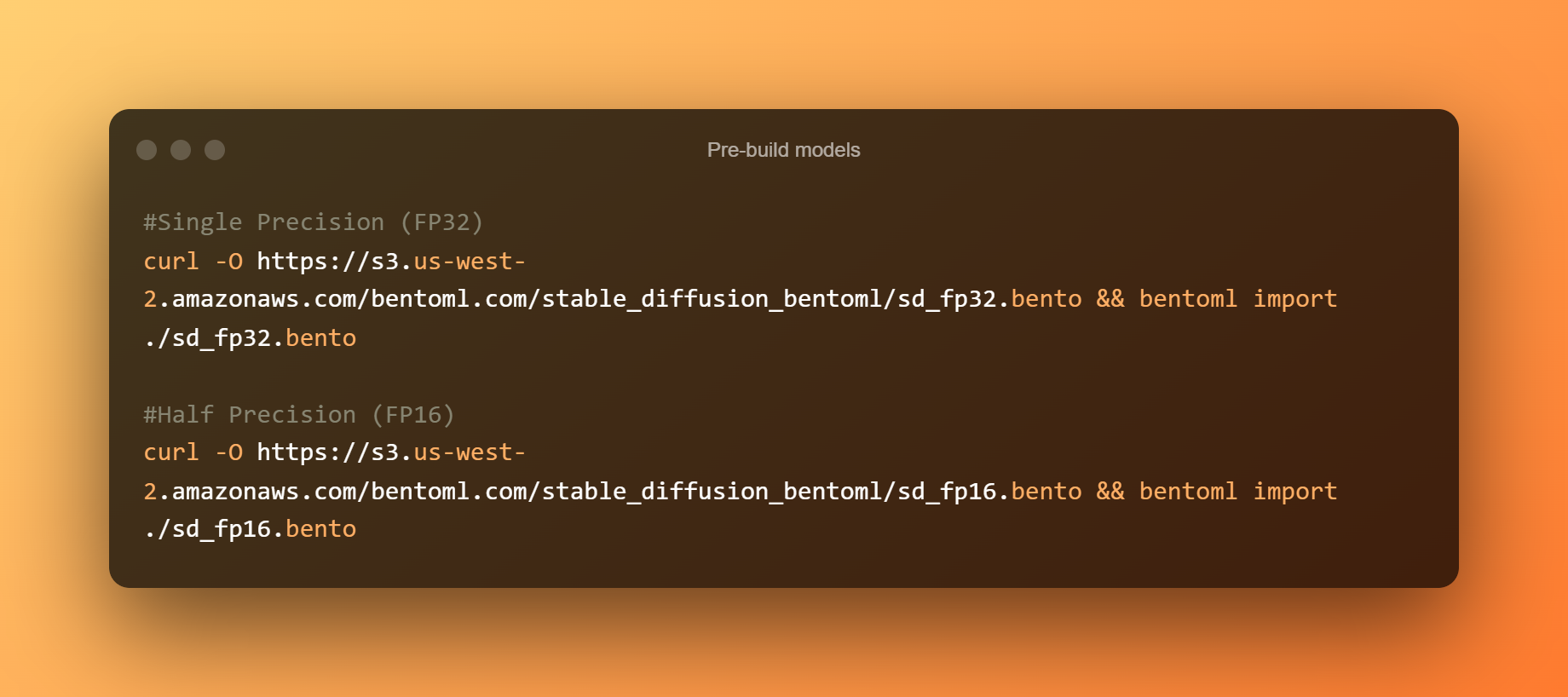
Modelos preconstruídos
A continuación móstranse os modelos previos á construción:
Implementar o modelo de difusión estable para EC2
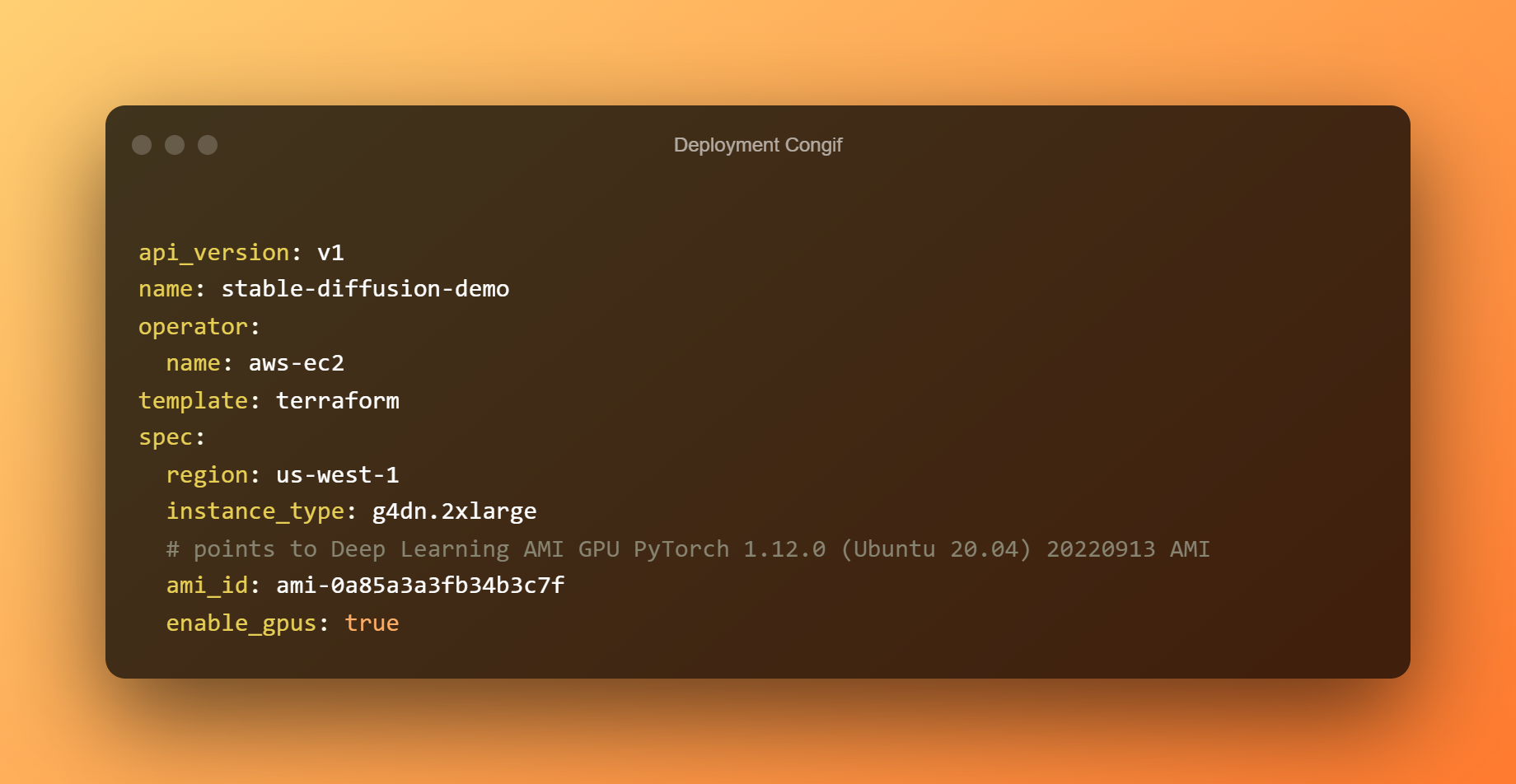
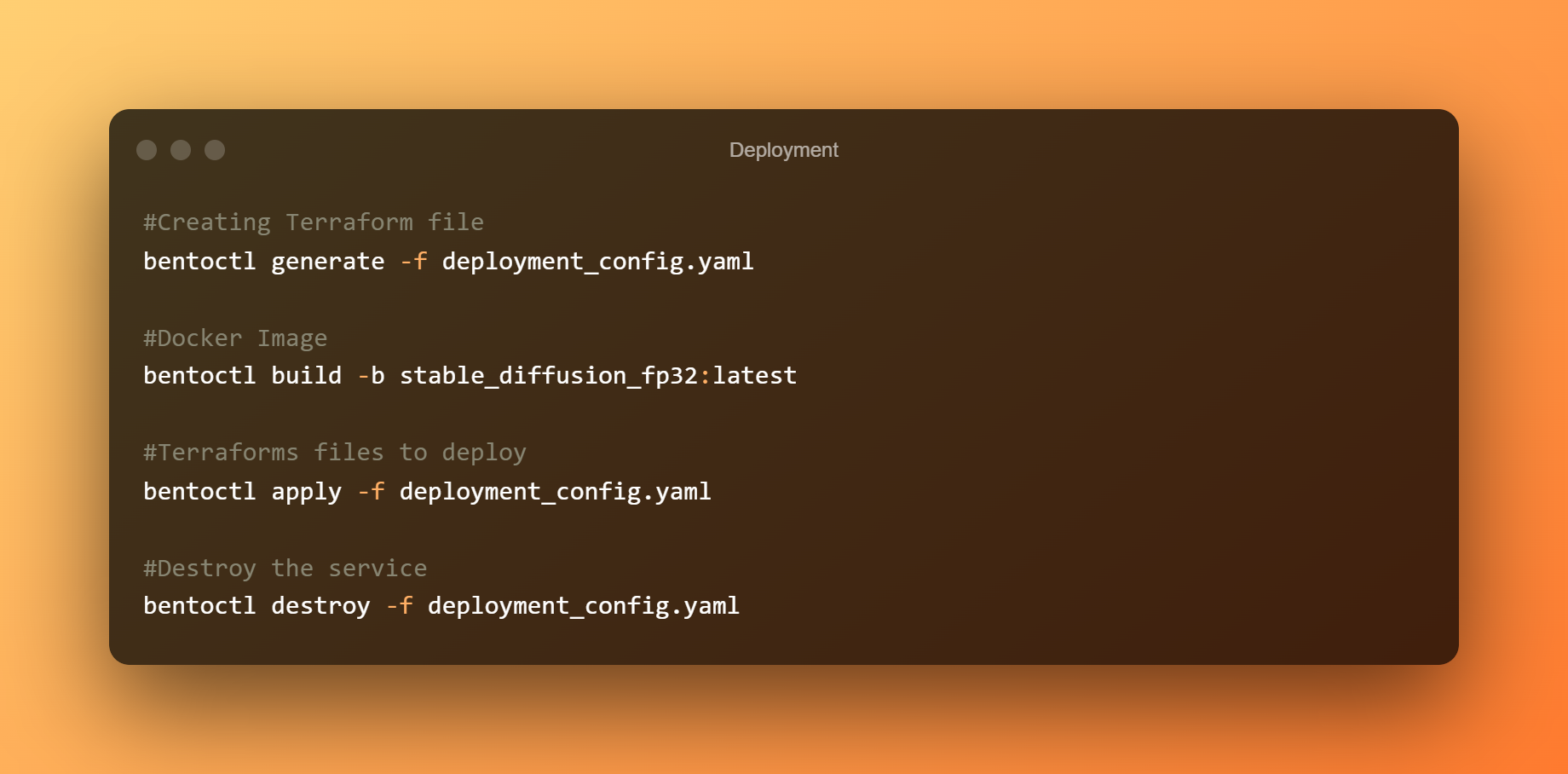
Para implementar o bento a EC2, usaremos bentoctl. bentoctl pode permitirche implementar os teus bentos en calquera plataforma na nube usando Terraform. Para crear e aplicar ficheiros Terraform, instale o operador AWS EC2.

No ficheiro config.yaml de implementación, a implementación xa se configurou. Non dubides en editar segundo os teus requisitos. O Bento está implantado por defecto nun host g4dn.xlarge co Aprendizaxe profunda AMI GPU PyTorch 1.12.0 (Ubuntu 20.04) AMI na rexión us-west-1.
Crea agora os ficheiros Terraform. Cree a imaxe de Docker e cárguea a AWS ECR. Dependendo do teu ancho de banda, a carga de imaxes pode levar moito tempo. Ao implementar o bento en AWS EC2, use os ficheiros Terraform.
Para acceder á IU de Swagger, conéctese á consola EC2 e abra o enderezo IP público nun navegador. Finalmente, se xa non se precisa o servizo Stable Diffusion BentoML, elimine a implantación.
Conclusión
Deberías poder ver o fascinantes e poderosos que son os modelos SD e os seus complementarios. O tempo dirá se seguiremos iterando o concepto ou pasamos a enfoques máis sofisticados.
Non obstante, actualmente hai iniciativas en marcha para adestrar modelos máis grandes con axustes para comprender mellor a contorna e as instrucións. Tentamos desenvolver o servizo Stable Diffusion usando BentoML e implantámolo en AWS EC2.
Puidemos executar o modelo Stable Diffusion en hardware máis potente, crear imaxes con baixa latencia e estender máis aló dun único ordenador mediante a implantación do servizo en AWS EC2.





Deixe unha resposta