Índice analítico[Ocultar][Mostrar]
A nova e mellorada IA mellorou as habilidades, a comprensión e a capacidade de producir imaxes de maior resolución. Quizais te atopes ultimamente con imaxes estrañas e divertidas flotando por internet.
Un can Shiba Inu leva unha boina e un pescozo negro. E unha lontra mariña ao xeito do pintor holandés Vermeer "A rapaza cun pendente de perla". E hai unha cunca de sopa que semella un monstro lanudo.
Estas imaxes non foron creados por un artista humano.
En cambio, DALL-E 2, un novo sistema de intelixencia artificial que pode converter descricións textuais en imaxes, creounas.
Simplemente escribe o que queres ver e a IA crearao para ti: con detalles vivos, gran calidade e, nalgúns casos, inventiva xenuína. Nesta publicación, analizaremos en profundidade o último estudo de OpenAI, DALL.E 2, así como o seu funcionamento e moito máis. Imos comezar.
Entón, que é exactamente DALLE 2?
DALL-E 2 é un "modelo xerativo", un tipo de algoritmo de aprendizaxe automática que xera resultados complicados en lugar de realizar tarefas de predición ou clasificación sobre datos de entrada.
Proporcionas a DALL-E 2 unha descrición escrita e crea unha imaxe que lle corresponde. Ao combinar conceptos, calidades e estilos, DALLE 2 de OpenAI pode producir gráficos e arte innovadores e realistas a partir dunha descrición lingüística básica.
Dise que a última versión, DALLE 2, é máis versátil, capaz de facer imaxes a partir de subtítulos con resolucións máis altas e nun espectro máis amplo de estilos creativos. Por exemplo, as imaxes de abaixo (da publicación do blog DALL-E 2) son creadas pola descrición "Un astronauta montando a cabalo".
Unha descrición conclúe, "como un bosquexo a lapis", mentres que a outra conclúe, "dunha forma fotorrealista".

Tamén pode cambiar as fotografías existentes cunha precisión sorprendente. Así, pode engadir ou eliminar elementos mantendo as cores, os reflexos e as sombras, mantendo o aspecto da imaxe orixinal.
Como funciona?
DALL-E 2 fai uso de modelos CLIP e de difusión, dous sofisticados aprendizaxe profunda enfoques desenvolvidos nos últimos anos. Non obstante, baséase na mesma noción que todos os demais profundos redes neuronais: aprendizaxe da representación. CLIP adestra dous simultáneamente redes neuronales en imaxes e subtítulos.
Unha rede aprende as representacións visuais da imaxe, mentres que a outra aprende as representacións do texto. Durante o adestramento, as dúas redes intentan modificar os seus parámetros para que imaxes e descricións comparables resulten en incorporacións similares.
A "difusión", un tipo de modelo xerativo que aprende a facer imaxes facendo ruído gradualmente e eliminando ruído das súas mostras de adestramento, é o outro enfoque de aprendizaxe automática que se utiliza en DALL-E 2. Os modelos de difusión son similares aos codificadores automáticos xa que transforman os datos de entrada nun representación de incrustación e, a continuación, use a información de incrustación para recrear os datos orixinais.
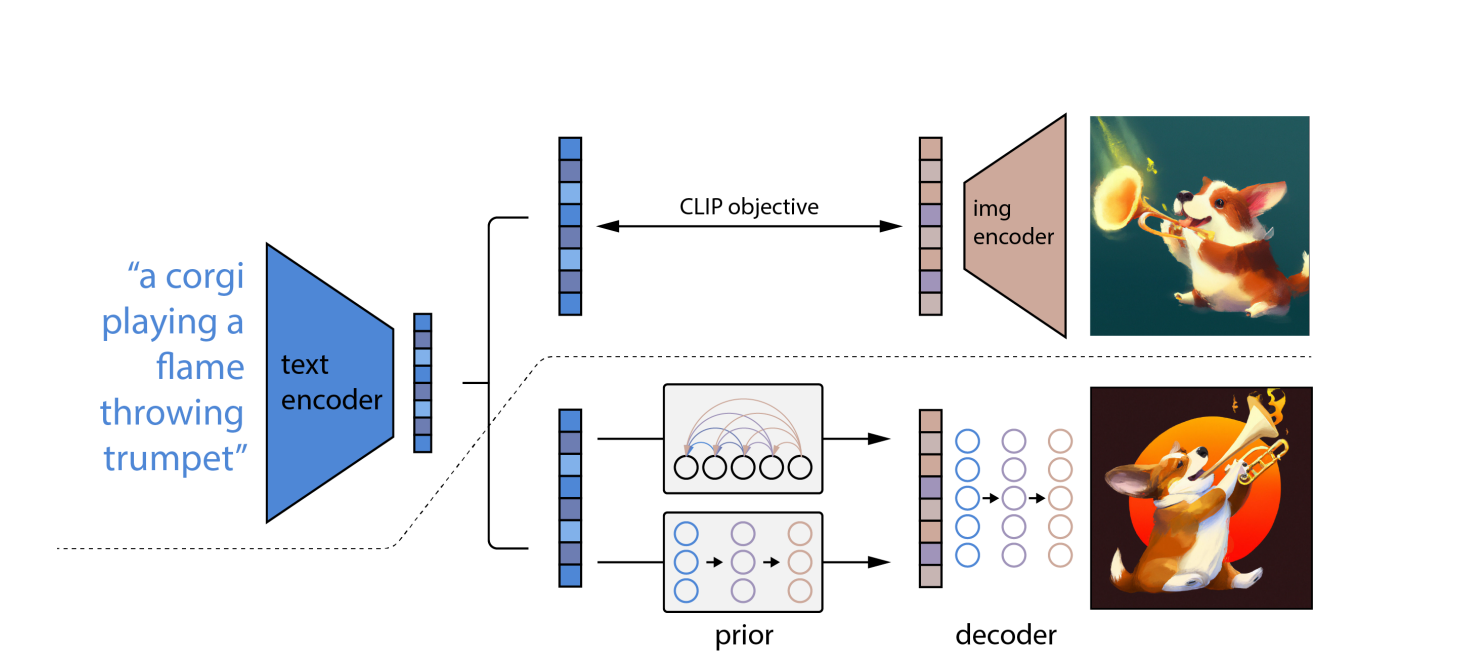
Usando OpenAI modelo lingüístico CLIP, que pode conectar descricións textuais con fotografías, primeiro traduce a solicitude escrita nunha forma intermedia que incorpora as propiedades cruciais que debería ter unha imaxe para coincidir con esa indicación (segundo CLIP).
En segundo lugar, DALL-E 2 crea un modelo compatible con CLIP imaxe utilizando un modelo de difusión, que é unha rede neuronal.
En fotos distorsionadas con píxeles aleatorios, apréndense modelos de difusión. Aprenden a restaurar a forma orixinal das fotos. Os modelos de difusión poden producir imaxes sintéticas de alta calidade, especialmente cando se usan xunto cun enfoque orientador que prioriza a precisión sobre a diversidade.
Como consecuencia, o modelo de difusión toma os píxeles aleatorios e usa CLIP para convertelos nunha nova imaxe que coincida coa palabra prompt. Debido ao concepto de difusión, DALL-E 2 pode producir imaxes de maior resolución máis rápido que DALL-E.
Caso de uso DALL.E 2
Nos últimos vinte anos, visión por computador a tecnoloxía pasou dunha simple noción a un gran avance. A pesar destes avances, os modelos de recoñecemento de imaxes e obxectos aínda se enfrontan a importantes obstáculos na vida cotiá. A ausencia de conxuntos de datos é un dos inconvenientes máis significativos do recoñecemento de imaxes e da visión por ordenador. Debido a que hai unha escaseza de datos en ambos os extremos, adestrar modelos de recoñecemento de imaxes para dar resultados 100 por cento precisos é case difícil.
Afortunadamente, o novo modelo de aprendizaxe automática de OpenAI pode salvar a brecha na tecnoloxía. DALLE 2 é capaz de xerar imaxes sorprendentes baseadas en descricións de texto. Esta produción de imaxes falsas pode proporcionar datos aos modelos de recoñecemento de imaxes en función dos seus requisitos. A ausencia de datos é un obstáculo importante para a identificación de obxectos e imaxes.
Na era dixital, os conxuntos de datos son omnipresentes, aínda que aínda estamos buscando atallos para alimentar o modelo de IA, para que poida proporcionar bos resultados. Non obstante, non é sinxelo adestrar un modelo de recoñecemento de imaxes. Necesita un gran número de conxuntos de datos con pequenas diferenzas, que quizais non puidésemos recuperar de forma sinxela.
Entón, cal é a resposta: a resposta é DALLE 2. O xerador de imaxes OpenAI, coa súa capacidade para producir imaxes a partir de textos e cambiar os existentes, pode axudar a salvar a diferenza. Isto axudará á xeración de datos adicionais de formación ao mesmo tempo que reducirá a cantidade de etiquetaxe humana necesaria. A pesar do beneficio significativo, debes ter en conta as producións de imaxes fraudulentas e as imaxes que exclúen a inclusión. Isto pode levar a que os métodos de detección de imaxes produzan resultados sesgados.
Limitacións
DALL.E 2 pode ter unha influencia prexudicial se cae en mans equivocadas, segundo OpenAI. No mundo actual de falsificacións profundas, o modelo podería usarse facilmente para difundir información falsa ou imaxes racistas, polo que OpenAI só permite aos desenvolvedores usar DALL.2 por invitación. A modelo debe cumprir unha restrición de contido rigorosa para todas as suxestións que reciba.
Para excluír o potencial de DALL.E 2 para crear imaxes hostís ou violentas, o conxunto de datos creouse sen ningún tipo de armamento mortal. Aínda que OpenAI afirmou que planea transformalo nunha API no futuro, no caso de DALL.E 2, está disposto a proceder con precaución.
Conclusión
DALL-E 2 é outro descubrimento interesante de investigación de OpenAI que abre a porta a novas aplicacións.
Un exemplo é a creación de conxuntos de datos masivos para satisfacer un dos principais pescozos de botella da visión por ordenador: os datos. Aínda que o caso económico de moitas aplicacións baseadas en DALL-E estará determinado polo prezo e as políticas que OpenAI estableza para os seus usuarios de API, sen dúbida todas elas farán avanzar a produción de imaxes.





Deixe unha resposta