Table des matières[Cacher][Montrer]
La façon dont nous communiquons avec les machines et autres gadgets a été complètement transformée par le développement du logiciel de reconnaissance vocale IA.
Il convertit les mots parlés en texte imprimé avec une précision et une efficacité étonnantes à l'aide d'algorithmes d'intelligence artificielle. Cette technologie a des applications dans de nombreux secteurs, des soins de santé et du service client à l'éducation et au divertissement.
Ces dernières années, il y a eu une augmentation considérable de la demande pour une conversion parole-texte précise et efficace.
Les entreprises et les particuliers constatent l'énorme utilité des logiciels de reconnaissance vocale IA compte tenu de la croissance rapide de la technologie et de la dépendance croissante à la communication numérique.
Ce besoin découle de la volonté d'améliorer la productivité, de rationaliser les procédures et d'accroître l'accessibilité pour les personnes handicapées.
Afin de conserver les dossiers des patients et de permettre une prestation efficace des soins de santé, une transcription précise et rapide des dictées médicales est essentielle dans des secteurs comme la santé.
En automatisant le processus de transcription, en éliminant le besoin de saisie manuelle des données et en améliorant la précision et la vitesse, le logiciel de reconnaissance vocale IA est apparu.
De plus, les divisions du service client utilisent cette technologie pour accélérer les temps de réponse et offrir des expériences personnalisées.
Les entreprises peuvent détecter des modèles, améliorer leurs services et faire des choix basés sur les données en transcrivant les appels des clients et en glanant des informations pertinentes à partir de ces interactions.
Une autre industrie qui bénéficie des logiciels de reconnaissance vocale IA est l'éducation car elle permet de créer des outils pédagogiques de pointe.
Un environnement d'apprentissage plus dynamique et immersif peut être favorisé en permettant aux étudiants de dicter leurs devoirs ou d'interagir avec des instructeurs virtuels via la voix.
Le secteur du divertissement a également adopté la technologie de reconnaissance vocale de l'IA, ouvrant la voie aux produits intelligents à commande vocale et aux assistants virtuels qui améliorent l'expérience utilisateur.
Avec des commandes vocales pour la lecture multimédia et des moteurs de recherche activés par la voix, cette technologie permet de profiter facilement et facilement du divertissement.
Dans cet article, nous examinerons le meilleur logiciel de reconnaissance vocale AI.
1. Tour
Rev est un programme de reconnaissance vocale basé sur le cloud qui est devenu plus populaire parmi les entreprises et les personnes à la recherche de services de transcription précis et efficaces pour les données audio et vidéo. L'utilisation par Rev d'algorithmes d'intelligence artificielle de pointe pour la conversion parole-texte le rend unique.
Pour convertir correctement les mots prononcés en texte écrit, ces algorithmes complexes utilisent les atouts de machine learning et le traitement du langage naturel.
Une grande variété d'accents, de dialectes et de langues peuvent être reconnus et interprétés par les algorithmes d'IA de Rev, car ils ont été entraînés sur d'énormes volumes de données.
En conséquence, Rev peut fournir des services de transcription extrêmement précis qui peuvent également être personnalisés pour répondre à des besoins linguistiques spécifiques. Le programme peut gérer une variété de types de fichiers audio, y compris des podcasts, des conférences, des interviews et des vidéos.
Rev donne la priorité à l'efficacité plutôt qu'à la précision, offrant des délais d'exécution rapides sans sacrifier la qualité. Le programme peut traiter rapidement d'énormes quantités de données audio et vidéo grâce à son flux de travail optimisé et à son infrastructure évolutive.
La gamme de services de transcription de Rev va au-delà de la simple traduction parole-texte.
De plus, le programme offre des choix pour le formatage, l'identification du locuteur et l'horodatage.
L'horodatage donne au texte transcrit une référence chronologique et l'identification du locuteur facilite la distinction entre les participants à la conversation distincts.
Les choix de mise en forme offrent aux clients la possibilité d'ajuster la présentation et la mise en page de la transcription en fonction de leurs propres besoins.
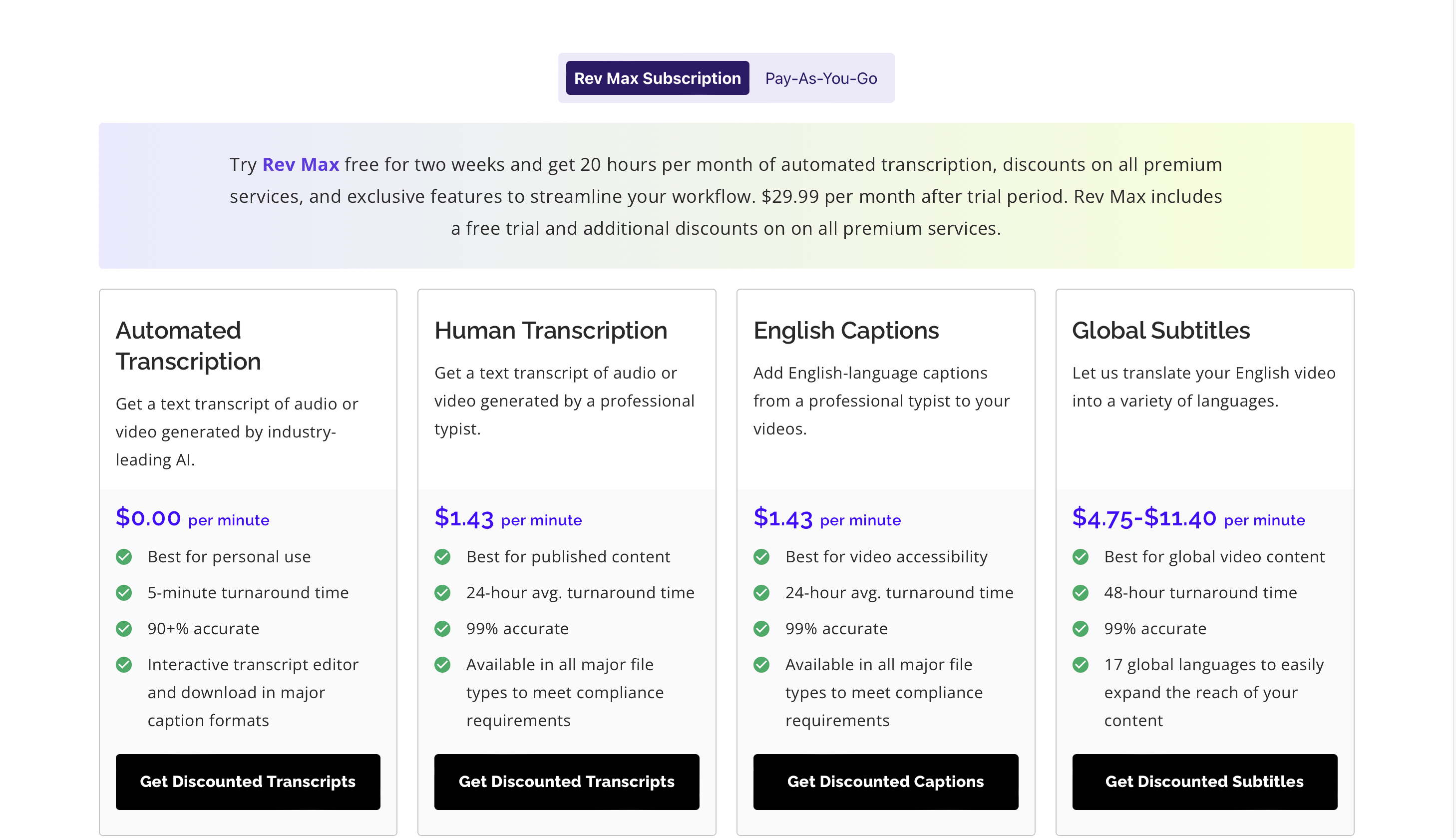
Prix
Vous pouvez essayez Rev Max gratuitement pendant 2 semaines, et le prix premium commence à partir de 29.99 $/mois.
2. Nuance Dragon Professionnel
Nuance Dragon Professional est un logiciel de reconnaissance vocale leader sur le marché qui fournit un ensemble complet de fonctionnalités et de capacités pour permettre aux professionnels d'une grande variété de secteurs.
Grâce à ses fonctions de commande vocale sophistiquées, vous pouvez utiliser votre ordinateur en mode mains libres tout en naviguant dans les applications et en dictant des documents, ce qui augmente l'efficacité et la productivité. Le programme a un niveau exceptionnel de précision de transcription, de sorte que les mots prononcés sont convertis de manière fiable en forme écrite.
En proposant des vocabulaires spécialisés et modèles de langage, Nuance Dragon Professional répond aux exigences d'industries particulières. Grâce à l'utilisation de dictionnaires spécialisés et de choix de vocabulaire, les professionnels de secteurs tels que la santé, le droit et la finance peuvent augmenter leur productivité et produire des transcriptions plus précises.
De plus, le programme peut reconnaître différents modèles de parole et dialectes grâce à des profils vocaux personnalisables par l'utilisateur.
Les professionnels de la santé peuvent enregistrer les notes des patients, les données médicales et les ordonnances avec une précision remarquable à l'aide de Nuance Dragon Professional dans le secteur de la santé, ce qui réduit les contraintes administratives et améliore les soins aux patients.
Ses fonctions de reconnaissance vocale peuvent être utilisées par les juristes pour préparer rapidement et efficacement des documents judiciaires et créer des notes de cas.
Le programme simplifie également les procédures de documentation dans les secteurs de la banque et de l'assurance, permettant aux experts de rédiger rapidement et précisément des communications, des réclamations et des rapports.
Au-delà de la simple dictée, les capacités de commande vocale avancées du logiciel vous permettent d'utiliser des invites vocales pour exécuter des instructions sophistiquées, gérer des programmes et effectuer des tâches informatiques. Les personnes ayant des problèmes de mobilité ou celles qui préfèrent un fonctionnement mains libres trouveront cette fonctionnalité particulièrement utile.
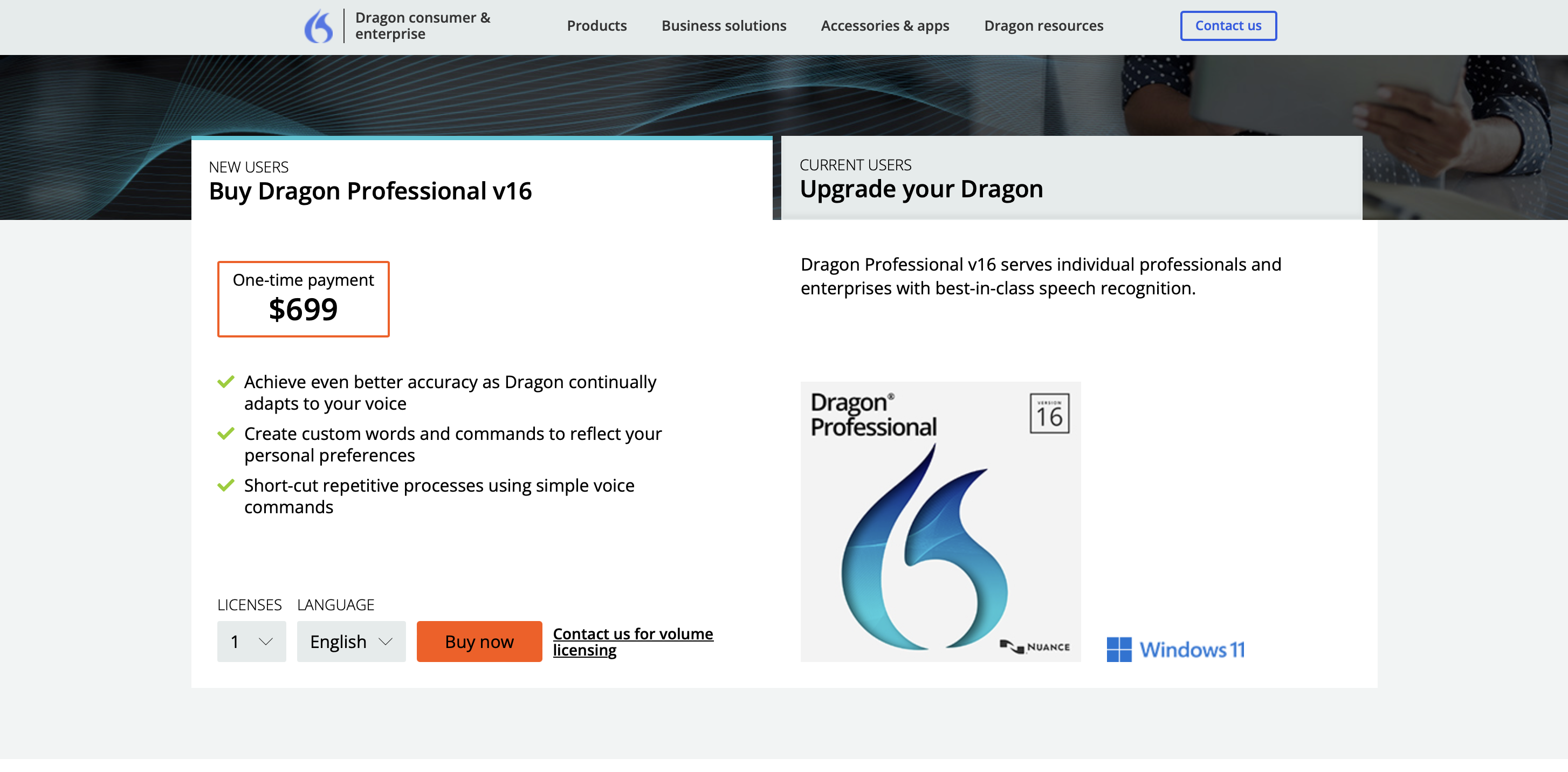
Prix
Le prix premium du logiciel à acheter est de 699 $.
3. Google Cloud Speech-to-Text
Google Cloud Speech-to-Text est un programme de reconnaissance vocale IA bien connu doté de pouvoirs et de compétences technologiques exceptionnels.
C'est une option incontournable pour les entreprises et les développeurs à la recherche d'une conversion précise de la parole en texte, car il s'agit d'un composant de Google Cloud Platform et offre une gamme complète de fonctionnalités.
Une qualité unique du programme est sa grande précision, qui utilise des algorithmes d'apprentissage automatique pour convertir des mots prononcés en texte écrit avec une précision étonnante.
De plus, Google Cloud Speech-to-Text offre une large gamme de compatibilité linguistique, vous permettant de traduire l'audio dans une variété de langues, de dialectes et d'accents. C'est un outil utile pour les sociétés multinationales et les applications qui utilisent plusieurs langues en raison de sa couverture linguistique étendue.
Le programme convient aux applications à forte demande de transcription car il peut gérer rapidement d'énormes quantités de données audio en utilisant la puissance du cloud.
Grâce à l'architecture basée sur le cloud de Google Cloud Speech-to-Text, les développeurs peuvent facilement l'intégrer à d'autres services et API Google Cloud pour créer des applications entièrement pilotées par la voix.
Le programme offre également d'autres fonctionnalités qui améliorent la précision et l'utilité de la transcription, telles que l'enregistrement du locuteur, la ponctuation automatisée et la compréhension contextuelle.
Alors que l'enregistrement d'un orateur permet de reconnaître et de distinguer plusieurs orateurs dans une discussion, la ponctuation automatique apporte clarté et structure à la sortie.
La compréhension contextuelle aide à l'interprétation et à la transcription de l'audio en fonction de domaines particuliers ou du jargon des affaires.
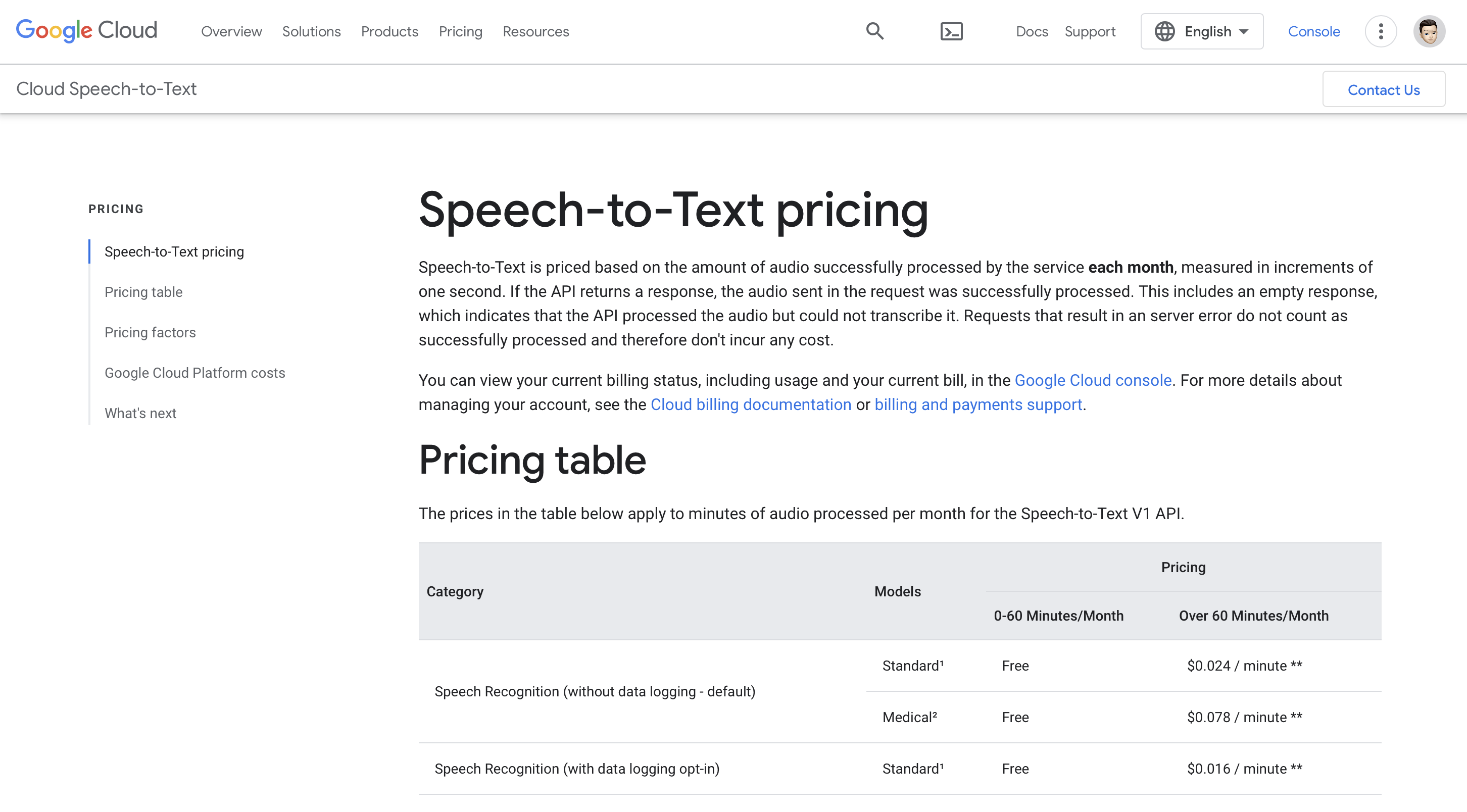
Prix
Son utilisation est gratuite pendant 0 à 60 minutes/mois et la tarification premium commence à partir de 60 minutes/mois, soit 0.024 $/minute.
4. Services de reconnaissance vocale Microsoft Azure
Microsoft Azure Speech Services est une technologie de reconnaissance vocale révolutionnaire qui a transformé nos interactions avec les machines et les gadgets. Ses compétences de transcription sophistiquées permettent de convertir des mots parlés en texte écrit avec précision et efficacité.
Par conséquent, les opérations peuvent être rationalisées et l'accessibilité est améliorée tout en permettant aux organisations et aux personnes d'obtenir des informations pertinentes à partir des données audio. Il va au-delà de la simple reconnaissance vocale en incluant des fonctionnalités de compréhension du langage naturel (NLU).
Il peut comprendre les intentions de l'utilisateur et donner des réponses plus adaptées au contexte en examinant le contexte et la signification des mots prononcés. En facilitant la communication avec les applications et les assistants virtuels, cette capacité de compréhension du langage naturel améliore l'expérience utilisateur.
De plus, les développeurs peuvent développer des applications entièrement pilotées par la voix grâce aux possibilités d'intégration fluide de Microsoft Azure Speech Services avec d'autres services et API Azure.
Il propose des kits de développement logiciel (SDK) et des API qui permettent une intégration simple avec des applications et des systèmes déjà existants, et il prend en charge un certain nombre de langages de programmation.
Microsoft Azure Speech Services fournit des fonctionnalités telles que la synthèse vocale, la reconnaissance du locuteur, la traduction et la compréhension du langage naturel en plus de la transcription et de la NLU.
Un niveau supérieur de sécurité et de personnalisation est offert grâce à la reconnaissance du locuteur, qui permet d'identifier et de valider certains locuteurs.
La communication multilingue est facilitée par les technologies de traduction linguistique qui permettent la traduction vocale en temps réel dans de nombreuses langues.
De plus, la synthèse vocale améliore la qualité des applications et des services basés sur la voix en produisant un discours qui ressemble à un discours humain.
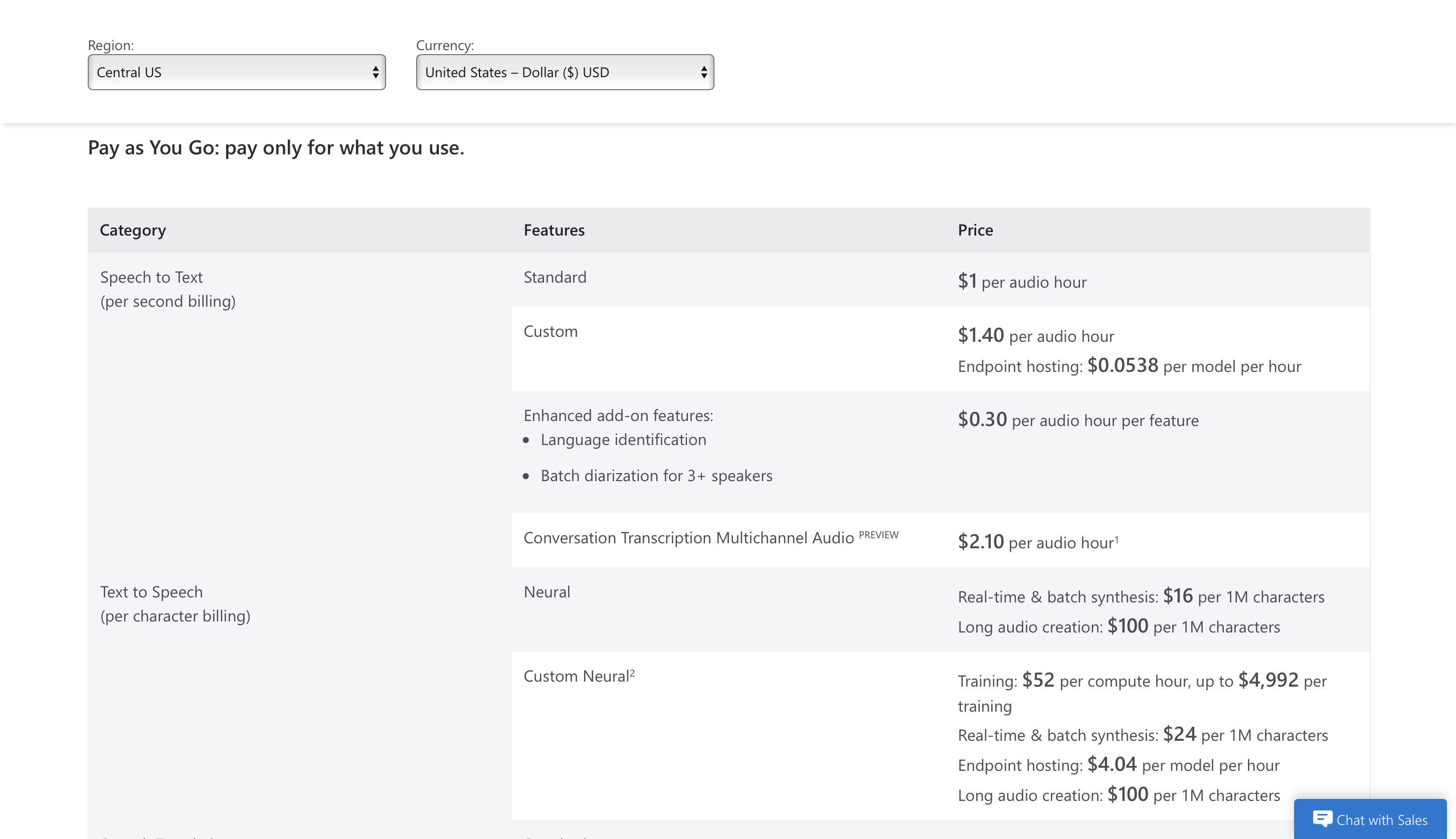
Prix
Vous pouvez commencer à l'utiliser gratuitement pendant 5 heures audio gratuites par mois et les tarifs premium commencent à partir de 1 $ par heure audio.
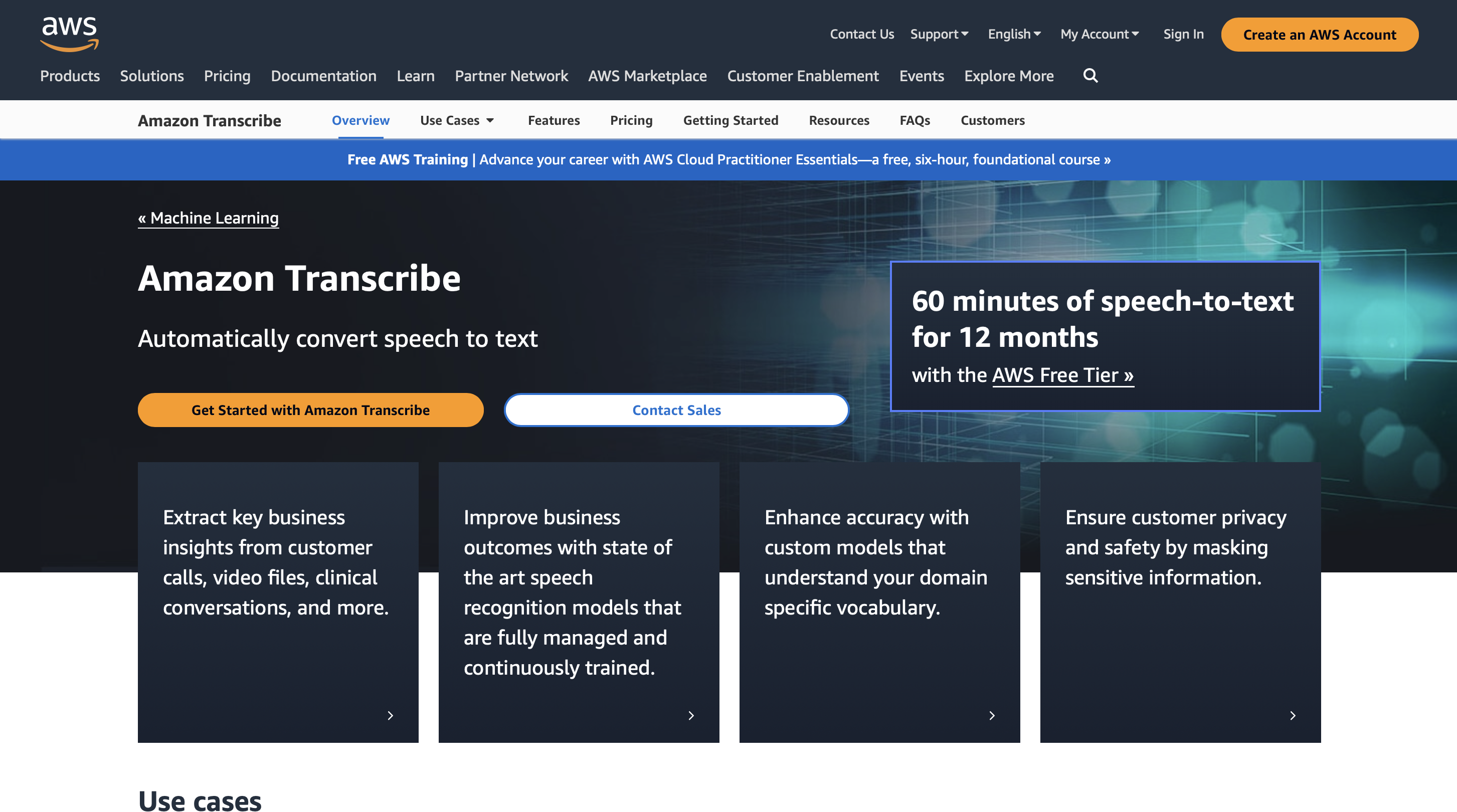
5. Amazon Transcribe
Amazon Transcribe est une application très utile qui offre plusieurs avantages lorsqu'il s'agit de convertir efficacement la voix en texte et la reconnaissance vocale.
Grâce à l'évolutivité exceptionnelle de cette solution basée sur le cloud d'Amazon Web Services (AWS), les entreprises peuvent gérer efficacement d'énormes quantités de données audio.
Amazon Transcribe est capable de s'adapter facilement à l'évolution des exigences de transcription, qu'il s'agisse de réunions, d'entretiens ou d'appels au service client. Les entreprises peuvent obtenir des informations précieuses à partir d'informations audio en utilisant des transcriptions précises qui sont régulièrement fournies par la technologie de reconnaissance vocale automatique.
L'utilisation d'algorithmes d'apprentissage automatique sophistiqués, qui apprennent et s'améliorent continuellement au fil du temps, améliore considérablement la précision d'Amazon Transcribe.
Il s'intègre à d'autres services Web Amazon sans aucun problème. Grâce à cette connexion, les organisations peuvent rapidement ajouter des capacités de reconnaissance vocale à leur infrastructure AWS actuelle, réduisant ainsi les processus et augmentant l'efficacité globale.
De plus, Amazon Transcribe propose des métadonnées supplémentaires, telles que des horodatages, vous permettant de parcourir et de rechercher plus facilement dans le texte transcrit.
Il peut analyser et transcrire efficacement n'importe quelle taille de fichier audio. Les entreprises peuvent utiliser Amazon Transcribe pour gérer la charge, en garantissant des transcriptions rapides et précises, qu'elles aient quelques minutes ou plusieurs heures d'audio à transcrire.
Prix
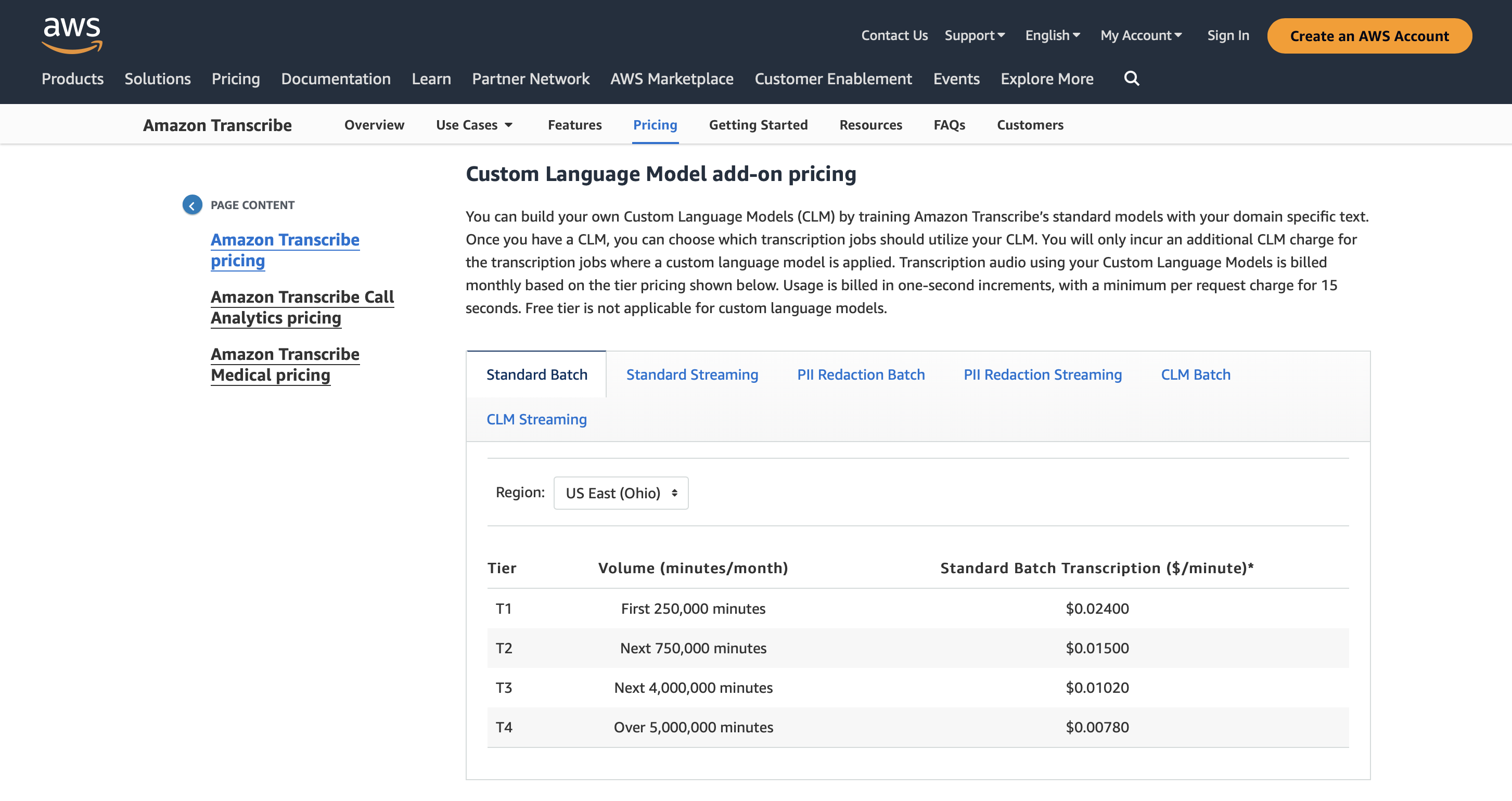
Vous pouvez utiliser Amazon Transcribe pendant 60 minutes par mois pendant 12 mois et les tarifs premium commencent à partir de 0.02400 USD/minute
6. IBM Watson parole-texte
IBM Watson Speech to Text est un outil robuste de reconnaissance vocale et de transcription qui comprend une variété de fonctionnalités avancées et de choix de personnalisation. La langue parlée est traduite avec précision en texte écrit à l'aide de ce service basé sur le cloud, qui utilise une technologie de pointe comme l'apprentissage en profondeur et le traitement du langage naturel.
Grâce à sa prise en charge linguistique complète, les utilisateurs peuvent transcrire l'audio dans une variété de langues et de dialectes. Pour les entreprises qui font des affaires à l'international ou qui ont besoin de services de transcription multilingues, cette adaptabilité en fait un outil inestimable.
De plus, IBM Watson Speech to Text propose des modèles et des vocabulaires spécialisés pour un certain secteur afin de s'adapter à ses exigences.
IBM Watson Speech to Text peut s'adapter aux besoins spécifiques de nombreuses entreprises, qu'elles soient dans les secteurs juridique, financier ou de la santé.
La capacité d'IBM Watson Speech to Text à gérer l'audio en mode batch ou en temps réel vous offre une flexibilité en fonction de vos propres besoins. Alors que la transcription par lots fonctionne bien pour les fichiers audio préenregistrés, la transcription en temps réel est préférable pour des applications telles que l'analyse de la parole et le sous-titrage en direct.
De plus, IBM Watson Speech to Text dispose de puissantes fonctionnalités de diarisation des locuteurs qui permettent la reconnaissance et la séparation de différents locuteurs au sein d'une source audio.
Lorsque de nombreux orateurs sont présents, comme lors d'enregistrements de conférences ou d'interviews, cette fonction est très utile. Grâce à sa connexion transparente avec d'autres services et API IBM Watson, les développeurs peuvent créer rapidement et facilement des applications vocales robustes.
Prix
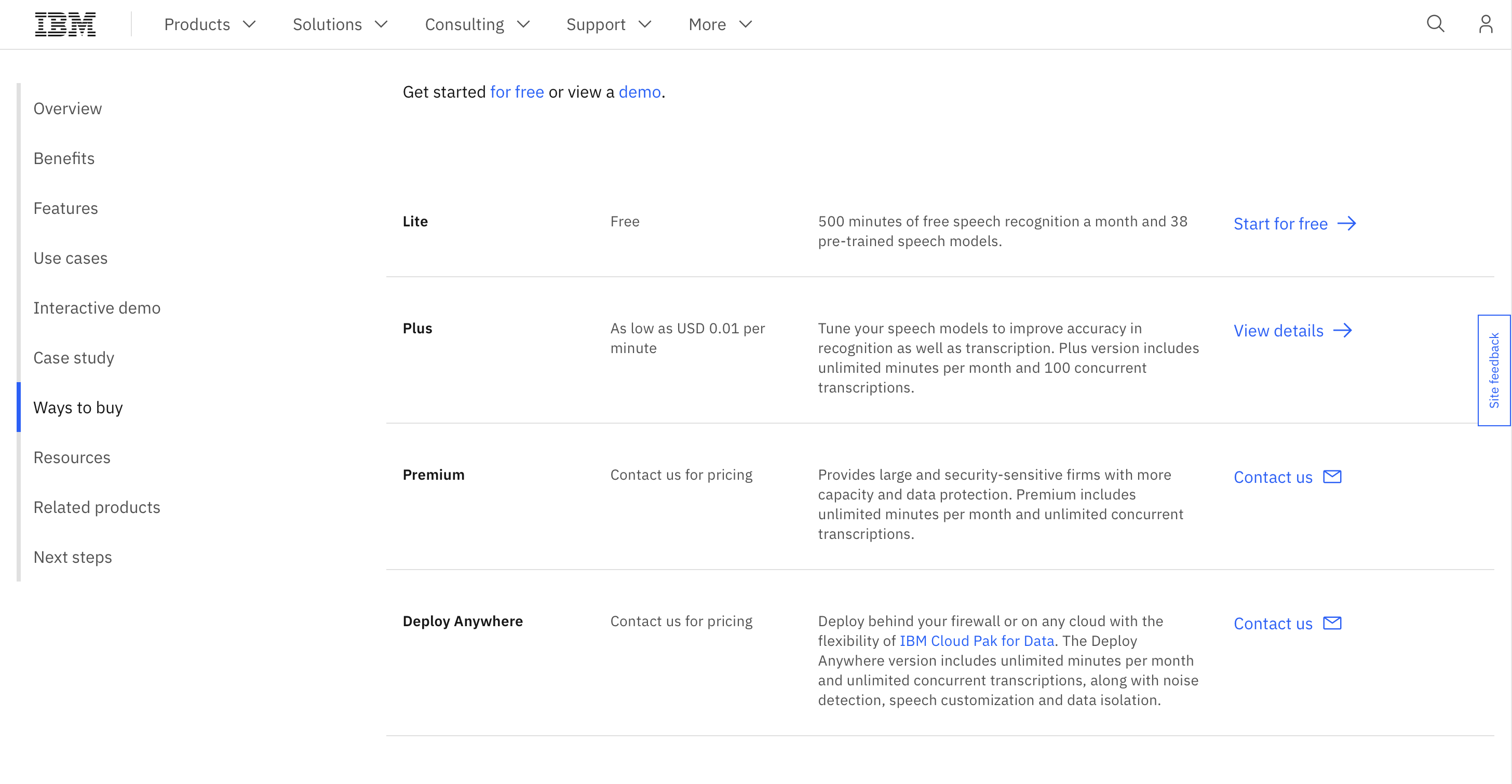
Vous pouvez utiliser le service pendant 500 minutes de reconnaissance vocale gratuite par mois et les tarifs premium commencent à partir de 0.01 $/minute.
7. Murmure OpenAI
OpenAI Whisper est une API de reconnaissance vocale de pointe qui utilise des technologies de pointe pour atteindre des performances exceptionnelles. Whisper est une solution fiable pour les organisations et les développeurs car elle convertit avec précision le langage parlé en texte écrit grâce à ses solides modèles d'apprentissage automatique.
Cette API se distingue par ses capacités multilingues, qui lui permettent de traduire du contenu audio dans d'autres langues, dialectes et accents, au service d'une base d'utilisateurs diversifiée.
Le système OpenAI Whisper peut reconnaître et comprendre une variété de modèles et de variations de la parole car il est construit sur un grand ensemble de données de formation.
Murmure réseaux de neurones profonds ont été formés sur d'énormes volumes de données audio grâce auxquelles il est désormais capable de reconnaître et de transcrire des phrases parlées avec une précision étonnante.
Il offre des services de transcription précis et efficaces et trouve une utilisation dans des secteurs tels que la santé, le service client et les médias. Whisper peut faciliter la dictée médicale dans le secteur de la santé, en aidant les experts à maintenir des données patient correctes.
Il permet de retranscrire les interactions des consommateurs dans le service client, améliorant l'analyse et le contrôle de la qualité. Afin d'améliorer l'accessibilité et la découverte de contenu, les organisations médiatiques peuvent également utiliser Whisper pour transcrire des interviews, des podcasts et du matériel vidéo.
La grande précision d'OpenAI Whisper est le produit de son apprentissage et de son développement continus. Les capacités de transcription de Whisper sont améliorées grâce aux modèles qu'il utilise, qui changent à mesure que davantage de données sont traitées et que des entrées sont reçues.
Cette amélioration constante garantit que l'API reste à la pointe de la technologie de reconnaissance vocale, offrant aux consommateurs les meilleurs résultats.
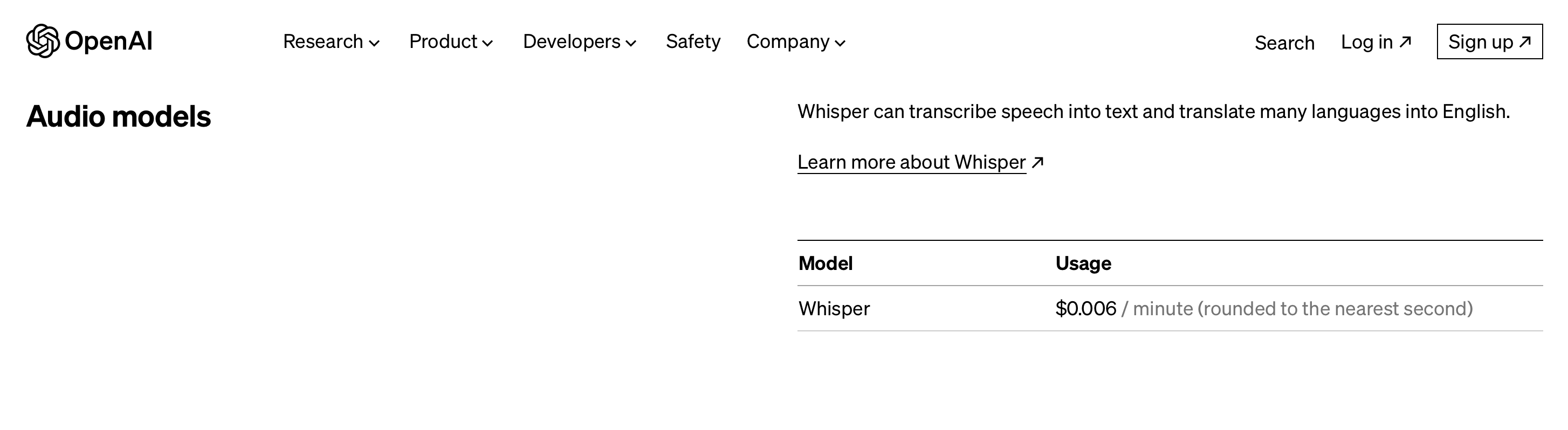
Prix
Le prix premium du modèle commence à partir de 0.006 $/minute.
8. Speechmatics
Speechmatics est un leader du marché de la technologie de reconnaissance vocale, fournissant une API de synthèse vocale puissante et précise. Speechmatics excelle dans la conversion précise du langage parlé en texte écrit en utilisant des algorithmes de pointe et des méthodes d'apprentissage en profondeur.
C'est un outil utile pour une variété d'applications, y compris le sous-titrage multimédia, centre de contact l'analyse et l'indexation de contenu grâce à ses capacités de transcription précises.
Speechmatics peut transcrire de manière fiable des informations audio à partir d'une variété d'origines linguistiques grâce à sa large prise en charge linguistique, qui comprend les dialectes et les accents régionaux.
Quelle que soit la langue prononcée, vous serez en mesure de copier et de comprendre avec précision le texte parlé grâce à cette capacité multilingue. Speechmatics fournit des résultats fiables et précis, que ce soit pour l'anglais, l'espagnol, le mandarin ou d'autres langues.
La technologie sous-jacente de Speechmatics est continuellement améliorée et apprise, ce qui lui permet de s'adapter à divers modèles de parole, accents et facteurs ambiants.
L'engagement de Speechmatics envers l'innovation continue garantit qu'il continuera à diriger le domaine de la technologie de reconnaissance vocale et à offrir à ses clients la conversion parole-texte la plus précise.
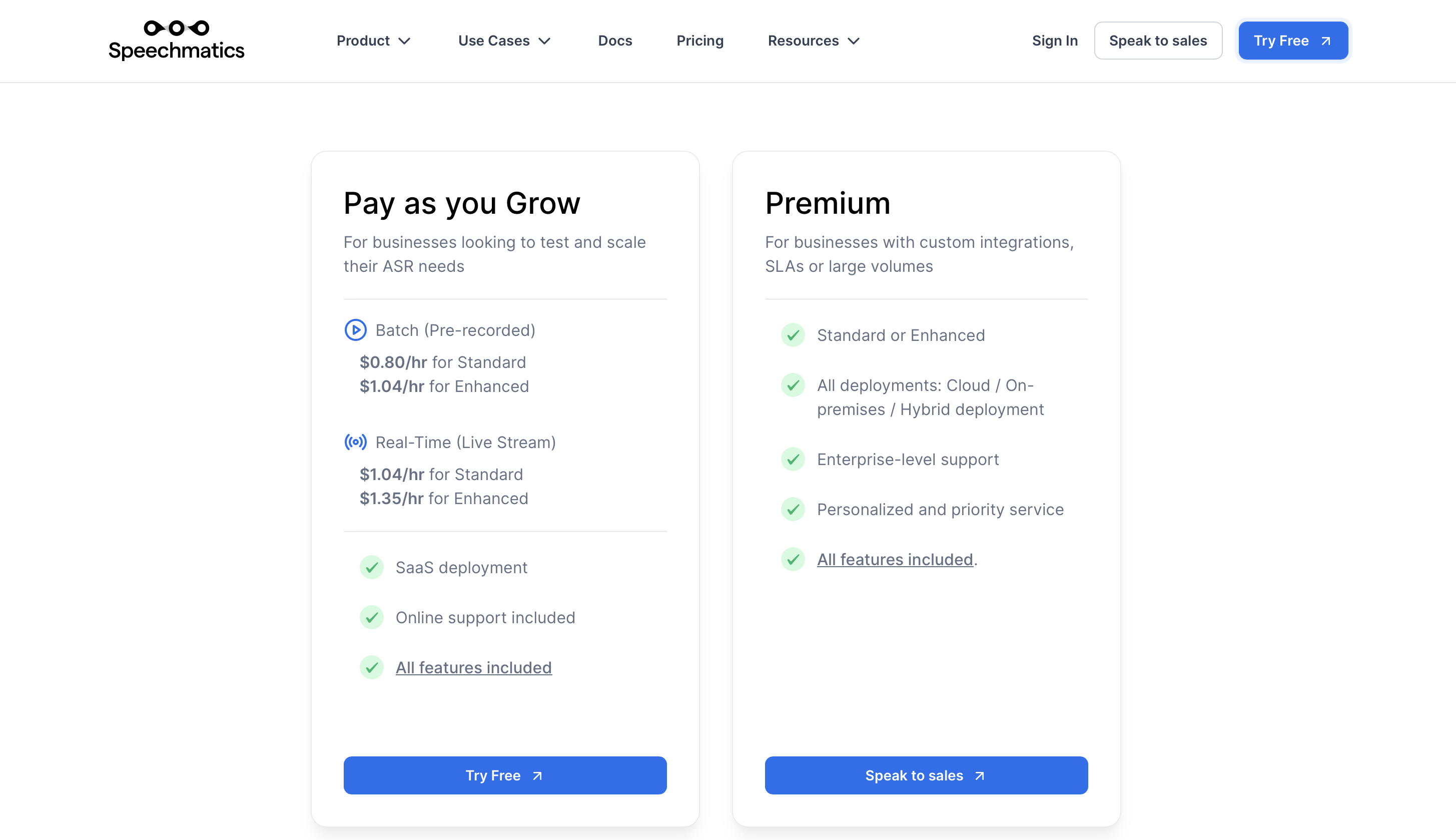
Prix
Le prix premium commence à partir de 0.80 $/h par lot (préenregistré) et de 1.04 $/h pour le temps réel (direct).
9. Deepgramme
Deepgram, un pionnier de la reconnaissance vocale et de la technologie de transcription, fournit une base solide pour une conversion audio-texte extrêmement précise en utilisant modèles d'apprentissage profond.
Les modèles d'apprentissage en profondeur intégrés à la plate-forme peuvent comprendre et composer une grande variété de modèles et de variations de la parole, car ils ont été formés sur d'énormes quantités de données.
La grande précision et la capacité de Deepgram à capter les subtilités subtiles du contenu parlé sont toutes deux le résultat de sa formation intensive. En raison de la polyvalence de la plate-forme, les transcriptions sont plus précises car elle peut gérer une variété d'accents, de langues et de termes spécifiques à l'industrie.
Il peut produire des résultats précis même dans des circonstances moins qu'idéales grâce à ses modèles d'apprentissage en profondeur, qui lui permettent également de gérer les situations auditives difficiles et le bruit de fond.
De plus, un certain nombre de capacités technologiques sont disponibles sur la plateforme de reconnaissance et de transcription vocales de Deepgram pour améliorer l'expérience utilisateur..
Vous pouvez recevoir des transcriptions immédiates de conversations ou d'événements en direct grâce à ses capacités de traitement en temps réel. Deepgram permet également le traitement par lots, permettant de transcrire efficacement de grands ensembles de données audio.
Prix
Vous pouvez commencer à l'utiliser gratuitement et les tarifs premium commencent à partir de 4 XNUMX $ / an.
10. Siri
Siri a gagné en popularité en tant que l'une des applications logicielles de reconnaissance vocale les plus reconnaissables et les plus couramment utilisées accessibles aujourd'hui. Assistant virtuel préféré de millions de propriétaires d'appareils Apple dans le monde, Siri est connu pour sa conception conviviale et ses interactions vocales.
Siri est un assistant à commande vocale qui peut effectuer diverses opérations avec une seule commande vocale, notamment créer des rappels, envoyer des messages, passer des appels téléphoniques et même répondre à des questions sur les connaissances générales.
L'intégration transparente de Siri avec les produits Apple, tels que les iPhones, iPads, Mac et HomePods, est ce qui le distingue des autres assistants numériques.

Vous pouvez accéder à Siri à l'aide de différents appareils grâce à cette intégration, qui garantit une expérience utilisateur pratique et cohérente. Siri est disponible à tout moment, que vous travailliez sur votre Mac ou sur un iPhone lorsque vous êtes en déplacement.
On ne peut nier l'utilité et l'adaptabilité de Siri dans la vie quotidienne. Avec juste leur voix, vous pouvez utiliser Siri pour gérer leurs horaires, envoyer des e-mails, parcourir des cartes et utiliser des gadgets intelligents pour la maison. Vous pouvez continuer à être connecté et productif lors de vos déplacements grâce à cette méthode mains libres, qui permet également de gagner du temps.
De plus, Siri se développe et s'améliore constamment. Apple modifie souvent les capacités de Siri, augmentant sa capacité d'interprétation et de traitement du langage naturel, élargissant sa base de connaissances et ajoutant de nouvelles fonctions.
En maintenant son leadership dans la technologie de reconnaissance vocale grâce à un développement continu, Siri peut continuer à vous offrir une expérience fluide et personnalisée.
Prix
Son utilisation est gratuite pour tout le monde.
Conclusion
En conclusion, les logiciels de reconnaissance vocale alimentés par l'IA ont complètement changé la façon dont nous interagissons avec la technologie et sont devenus un outil crucial pour de nombreux secteurs différents.
La variété des possibilités, de Microsoft Azure Speech Services et OpenAI Whisper à Google Cloud Speech-to-Text et Nuance Dragon Professional, démontre le développement et l'adaptabilité de ces systèmes.
J'exhorte les lecteurs à rechercher et à analyser en profondeur leurs souhaits et leurs exigences individuels avant de sélectionner le logiciel de reconnaissance vocale IA qui répond le mieux à leurs objectifs, car chaque logiciel possède une variété de fonctionnalités et de capacités spéciales.
Vous pouvez atteindre de nouveaux niveaux de productivité, d'efficacité et d'expérience utilisateur dans vos efforts personnels et professionnels en adoptant cette puissante technologie.





J'ai fait des comparaisons pour le travail, il y a quelques choses que vous voudrez peut-être corriger.
1. Siri n'est pas comparable aux autres. Siri n'est pas un outil de développement.
2. La tarification de Rev que vous avez partagée concerne la transcription humaine, tandis que d'autres sont purement basées sur la transcription automatique. Si vous regardez la transcription automatique de Rev, son prix est également compétitif. https://www.rev.ai/pricing
3. Il vous manque Picovoice qui propose le seul modèle sur appareil qui fonctionne comme une offre de service. Normalement, les solutions sur appareil comme Whisper ne sont pas accompagnées d'un support technique et la personnalisation est très difficile. Ils offrent un excellent support et la personnalisation est super facile. https://picovoice.ai/platform/cat/