Seoses andmeanalüütika ja andmehalduse tähtsuse suurenemisega ettevõtetele on andmeplatvormide Snowflake ja Databricks võrdlus tänapäeva turu jaoks vajalik.
Organisatsioonid vajavad mehhanismi, et koguda kõik hindamiseks vajalikud andmed ühte kohta, kus see oleks valmis andmekaeveks, kuna uuritavate andmete hulk järk-järgult kasvab.
Kahtlemata on tunnustatud pilvepõhised andmesüsteemid Snowflake ja Databricks mõlemad tööstusharu liidrid. Milline andmeplatvorm on aga teie ettevõtte jaoks ideaalne?
Koguse, kiiruse ja kvaliteedi, mida äriteabe rakendused nõuavad, pakuvad Snowflake ja Databricks.
Kuigi on erinevusi, on ka palju paralleele. Neil on selge suund, mis on tähelepanelikul kontrollimisel ilmne.
Apache Sparki asutajad asutasid ettevõtte tarkvaraäri Databricks.
See on tuntud andmejärvede parimate aspektide ühendamise poolest ja andmehoidlad järvehoone arhitektuuriks.
Andmelaoäri Snowflake pakub pilvepõhiseid salvestus- ja juurdepääsuteenuseid minimaalse vaevaga. See kinnitab oma staatust lahendusena, mis pakub turvalist juurdepääsu teie andmetele, nõudes samal ajal peaaegu vähe hooldust.
See artikkel pakub teile üksikasjalikku võrdlust Snowflake vs. Koostab ja selgitab iga toote eeliseid, et saaksite otsustada, milline on teie ettevõtte jaoks parim. Alustame nende tutvustusega.
Mis on Lumehelves?
Snowflake on täielikult hallatav teenus, mis pakub klientidele peaaegu piiramatut samaaegsete töökoormuste skaleeritavust andmete lihtsaks integreerimiseks, laadimiseks, analüüsimiseks ja jagamiseks.
Andmejärved, andmetehnoloogia, andmerakenduste arendus, andmeteadus ja jagatud andmete ohutu tarbimine on mõned selle tüüpilised kasutusalad.

Arvutustööd ja salvestamine on loomulikult eraldatud Snowflake'i eripärase disainiga.
Selle arhitektuuri abil saate praktiliselt anda kõigile oma kasutajatele ja andmekoormusele juurdepääsu oma andmete ühele koopiale, ilma et see kannataks negatiivsete toimivusmõjude all.
Järjepideva kasutuskogemuse tagamiseks võimaldab Snowflake teil oma andmelahendust nähtamatult kasutada erinevates asukohtades ja pilvedes.
Eemaldades aluseks olevate pilveinfrastruktuuride keerukuse, muudab Snowflake selle teostatavaks.
Snowflake Data Marketplace, mis pakub tuhandete Snowflake'i klientidega suhtlemiseks palju võimalusi, võimaldab teil pääseda juurde ka jagatud andmekogumitele ja andmeteenustele.
FUNKTSIOONID
- Tõhusam andmepõhine otsuste tegemine: Snowflake'i abil saate kaotada andmehoidlad ja pakkuda kõigile ettevõttes osalejatele juurdepääsu kasulikele teadmistele. See on esmatähtis samm partnersuhete tugevdamisel, hinnakujunduse optimeerimisel, tegevusega seotud kulude vähendamisel, müügiefektiivsuse suurendamisel ja paljudel muudel asjadel.
- Parandage Analyticsi kiirust ja kvaliteeti: saate Snowflake'i abil oma analüüsikonveieri tugevdada, kui lülitate öistelt partiide laadimistelt reaalajas andmevoogudele. Lubades kõigile oma ettevõtte töötajatele turvalise, samaaegse ja kontrollitud juurdepääsu oma andmelaole, saate parandada tööanalüüsi kvaliteeti. See vähendab kulusid ja käsitsitööd, võimaldades ettevõtetel ressursse optimaalselt jaotada, et maksimeerida tulu.
- Andmevahetus koos kohandamisega: saate luua oma andmevahetuse Snowflake'iga, mis võimaldab teil edastada reaalajas reguleeritud andmeid turvalisel viisil. Lisaks on see motivatsioon arendada tugevamaid andmesidemeid partnerite, klientide ja muude äriüksustega. See saavutab selle, hankides teie tarbijast 360-kraadise vaate, mis pakub teavet klientide oluliste omaduste, sealhulgas huvide, ameti ja palju muu kohta.
- Suurem toote- ja kasutajakogemus: Kui Snowflake on paigas, saate kasutaja käitumisest ja tootekasutusest paremini aru. Lisaks saate kasutada kogu andmekogumit, et rahuldada kliente, täiustada oluliselt oma tootevalikut ja edendada andmeteaduse innovatsiooni.
- Tugev turvalisus: Kõik vastavus- ja küberturvalisuse andmed saab koondada turvalisse andmejärve. Kiire intsidendireaktsiooni tagavad lumehelveste andmejärved. Suure hulga logiandmete ühendamine ühes kohas ja aastatepikkuse logiandmete kiire hindamine võimaldab teil saada sündmusest täieliku pildi. Poolstruktureeritud logid ja struktureeritud ettevõtteandmed saab nüüd ühendada ühte andmejärves. Ilma indekseerimiseta võimaldab Snowflake teil oma jala ukse vahele jätta, tehes samal ajal pärast importimist andmete redigeerimise ja muutmise lihtsaks.
Mis on Andmebaasid?
Databricks on pilvepõhine andmeplatvorm, mida juhib Apache Spark. See keskendub peamiselt suurandmete analüüsile ja koostööle.
Saate pakkuda täielikku Data Science'i tööruumi Ärianalüütikud, andmeteadlased ja andmeinsenerid, et suhelda Databricksi masinõppe käitusaja, juhitud ML-voo ja koostöömärkmikega.

Andmeraamid ja Spark SQL teegid, mis võimaldavad teil käsitleda struktureeritud andmeid, asuvad Databricksis.
Lisaks sellele, et aidata teil luua Tehisintellekt lahendusi, muudab Databricks teie praeguste andmete põhjal järelduste tegemise lihtsaks.
Lisaks pakub Databricks mitmesuguseid teeke masinõpe, sealhulgas Tensorflow, Pytorch ja teised, masinõppemudelite loomiseks ja treenimiseks.
Paljud ärikliendid kasutavad Databricksi tohutute tootmisprotsesside läbiviimiseks väga erinevates kasutusjuhtudes ja sektorites, sealhulgas tervishoid, meedia ja meelelahutus, finantsteenused, jaemüük ja palju muud.
FUNKTSIOONID
- Delta järv: Databricksil on avatud lähtekoodiga tehingute salvestuskiht, mis on mõeldud kasutamiseks kogu andmete elutsükli jooksul. Seda kihti saab kasutada teie praeguse andmejärve andmete skaleeritavuse ja usaldusväärsuse tagamiseks.
- Interaktiivsed märkmikud: saate kiiresti oma andmetele juurde pääseda, neid analüüsida, teistega mudeleid koostada ja värskeid kasulikke teadmisi jagada, kui teil on õiged tööriistad ja keel. Scala, R, SQL ja Python on vaid mõned keeltest, mida Databricks toetab.
- Masinõpe: Tipptasemel raamistike, nagu Tensorflow, Scikit-Learn ja Pytorch, abil annab Databricks ühe klõpsuga juurdepääsu eelkonfigureeritud masinõppekeskkondadele. Saate jagada ja jälgida katseid, hallata koos mudeleid ja paljundada käitamist ühest kesksest hoidlast.
- Täiustatud sädemootor: Apache Sparki uusimad versioonid saate hankida Databricksi abil. Databricksiga saab sujuvalt integreerida ka mitmesuguseid avatud lähtekoodiga teeke. Saate kiiresti seadistada klastreid ja luua täielikult hallatava Apache Sparki keskkonna, kui teil on juurdepääs mitme pilveteenuse pakkuja saadavusele ja skaleeritavusele. Klastreid saab Databricksiga konfigureerida, seadistada ja peenhäälestada, ilma et oleks vaja pidevat jälgimist, et säilitada optimaalne jõudlus ja töökindlus.
Peamised erinevused Snowflake'i ja Databricksi vahel
Arhitektuur
Snowflake on ANSI SQL-il põhinev serverita süsteem, millel on täiesti erinevad salvestus- ja arvutustöötluskihid.
Iga Snowflake'i virtuaalne ladu (st arvutusklaster) salvestab kogu andmekomplekti alamhulga kohapeal, kasutades päringute tegemiseks massiliselt paralleelset töötlemist (MPP).
Andmete sisemiseks korraldamiseks ja optimeerimiseks tihendatud veeruvormingusse, mida saab pilve salvestada, kasutab Snowflake mikrosektsioone.
Asjaolu, et Snowflake säilitab kõik andmehalduse aspektid, sealhulgas faili suurus, tihendamine, struktuur, metaandmed, statistika ja muud andmeüksused, mis pole kasutajatele kohe nähtavad ja millele pääseb juurde ainult SQL-päringute kaudu, võimaldab seda kõike teha. automaatselt.
Virtuaalladusid, mis on arvutuslikud klastrid, mis koosnevad paljudest MPP-sõlmedest, kasutatakse kogu töötlemiseks Snowflake'is.
Snowflake ja Databricks on mõlemad SaaS-i lahendused, kuid Databricksi arhitektuur on väga erinev, kuna see on üles ehitatud Sparkile.
Pilve saab installida mitmekeelse mootori nimega Spark ja see põhineb üksikutel sõlmedel või klastritel. Databricks kasutab praegu sarnaselt Snowflake'iga AWS-i, GCP-d ja Azure'i.
Juhttasand ja andmetasand moodustavad selle struktuuri. Kõik töödeldud andmed sisalduvad andmetasandil, samas kui kõik Databricksi serverita andmetöötluse hallatavad taustateenused asuvad juhttasandil.
Serverita andmetöötlus võimaldab administraatoritel luua serverita SQL-i lõpp-punkte, mida täielikult haldab Databricks ja mis pakuvad kohest andmetöötlust.
Kui enamiku muude Databricksi arvutuste arvutusressursse jagatakse pilvekontol või traditsioonilisel andmetasandil, siis neid ressursse jagatakse serverita andmetasandil.
Databricksi arhitektuur koosneb mitmest olulisest osast:
- Databricks Delta järv
- Databricks Delta mootor
- MLFlow
Andmete struktuur
Nii poolstruktureeritud kui ka struktureeritud faile saab Snowflake'i abil salvestada ja üles laadida, ilma et oleks vaja ETL-tööriista, mis enne andmete EDW-sse importimist korraldaks.
Snowflake teisendab andmete esitamisel andmed koheselt oma sisemisse organiseeritud vormingusse. Erinevalt Data Lake'ist ei pea Snowflake enne laadimist ja nendega suhtlemist struktureerimata andmetele struktuuri lisama.
Kõiki andmetüüpe saab kasutada koos Databricksiga nende algses vormingus. Struktureerimata andmestruktuuri loomiseks nii, et seda saaksid kasutada ka muud tööriistad, nagu Snowflake, võite isegi kasutada Databricksi ETL-i tööriistana..
Databricksi ja Snowflake'i vahelises debatis on Databricks andmestruktuuri osas ülekaalus Snowflake'i ees.
Andmete omandiõigus
Töötlemis- ja salvestuskihid on Snowflake'is eraldatud, võimaldades neil pilves iseseisvalt kasvada. See näitab, et need kõik saavad teie vajaduste alusel pilves iseseisvalt skaleerida.
Sellest võidavad teie rahandused. Lisaks säilitatakse mõlema kihi omandiõigus. Snowflake tagab juurdepääsu andmetele ja masinaressurssidele rollipõhise juurdepääsukontrolli (RBAC) tehnika abil.
Databricksi andmetöötlus- ja salvestuskihid on erinevalt Snowflake'i lahtisidestatud kihtidest täielikult eraldatud.
Kasutajad saavad oma andmed paigutada ükskõik kuhu ja mis tahes vormingus ning Databricks tegeleb nendega tõhusalt, kuna selle peamine eesmärk on andmerakendus.
Databricks on Databricksi ja Snowflake'i vahelises arutelus selge võitja, kuna saate seda lihtsalt andmete töötlemiseks kasutada.
Andmekaitse
Time Travel ja Fail-safe on kaks Snowflake'i eripära. Snowflake'i ajarännakute funktsioon hoiab andmeid enne värskendamist olekus.
Kui ettevõtte kliendid saavad valida ajavahemikuks kuni 90 päeva, siis ajarännak on sageli piiratud ühe päevaga. Seda võimalust saavad kasutada andmebaasid, skeemid ja tabelid.
Kui ajareisi säilitamise tähtaeg saab läbi, algab 7-päevane tõrkekindel periood, mis on mõeldud varasemate andmete kaitsmiseks ja taastamiseks.
Andmekivid Sarnaselt sellele, kuidas töötab Snowflake'i ajarände funktsioon, toimib seda ka Delta Lake's. Delta Lake'is hoitavad andmed versioonitakse automaatselt, mis võimaldab kasutajatel hankida varasemaid andmeversioone edaspidiseks kasutamiseks.
Databricks töötab Sparkis ja kuna Spark on ehitatud objekti tasemel salvestusruumile, ei salvesta Databricks kunagi andmeid.
See on selle üks peamisi eeliseid. See tähendab ka seda, et Databricks võib käsitleda kohapealsete süsteemide kasutusjuhtumeid.
TURVALISUS
Kõik andmed krüpteeritakse automaatselt Snowflake'i puhkeolekus.
Kogu side juhttasandi ja andmetasandi vahel toimub pilveteenuse pakkuja privaatvõrgus ja kõik Databricksi salvestatud andmed on kaitstud.
Mõlemad valikud pakuvad RBAC-i (rollipõhine juurdepääsukontroll). Snowflake ja Databricks järgivad mitmeid seadusi ja sertifikaate, sealhulgas SOC 2 Type II, ISO 27001, HIPAA ja GDPR.
Kuna Databricks töötab aga objektitasemel salvestusruumil, nagu AWS S3, Azure Blob Storage, Google Cloud Salvestus jne, sellel puudub erinevalt Snowflake'ist säilituskiht.
jõudlus
Jõudluse poolest on Snowflake ja Databricks nii radikaalselt erinevad lahendused, et nende võrdlemine on üsna keeruline.
Iga võrdlusalust on võimalik muuta, et esitada veidi erinev lugu. Täiuslik näide sellest on hiljutine uuring läbi Databricks TPC-DS võrdlusaluse kohta.
Võrdluses toetavad Snowflake ja Databricks veidi erinevaid kasutusjuhtumeid ning ükski neist pole oma olemuselt parem kui teine.
Snowflake võib siiski olla interaktiivsete päringute jaoks eelistatud valik, kuna see optimeerib kogu salvestusruumi andmetele juurdepääsuks sissevõtmise hetkel.
Kasuta Case'it
BI- ja SQL-i kasutusjuhtumeid toetavad hästi Databricks ja Snowflake.
Snowflake pakub JDBC- ja ODBC-draivereid, mida on lihtne muu tarkvaraga integreerida.
Arvestades, et kliendid ei pea programmi administreerima, on see peamiselt tuntud oma BI-s kasutatavate juhtumite ja ettevõtete jaoks, kes valivad lihtsa analüütilise platvormi.
Databricksi välja antud avatud lähtekoodiga Delta Lake lisab vahepeal nende Data Lake'ile täiendava stabiilsuse. Kliendid saavad Delta Lake'ile suurepärase jõudlusega SQL-päringuid saata.
Arvestades nende mitmekesisust ja paremat tehnoloogiat, on Databricks hästi tuntud oma kasutusjuhtumite poolest, mis minimeerivad müüja lukustumist, sobivad paremini ML-töökoormuse jaoks ja abistavad tehnoloogiahiiglasi.
hinnapoliitika
Klientidel on Snowflake'iga juurdepääs neljale ettevõtte tasemel vaatele. Standard, Enterprise, Business Critical ja Virtual Private Snowflake on saadaval neli versiooni. Kogu hinnainfo on saadaval siin.
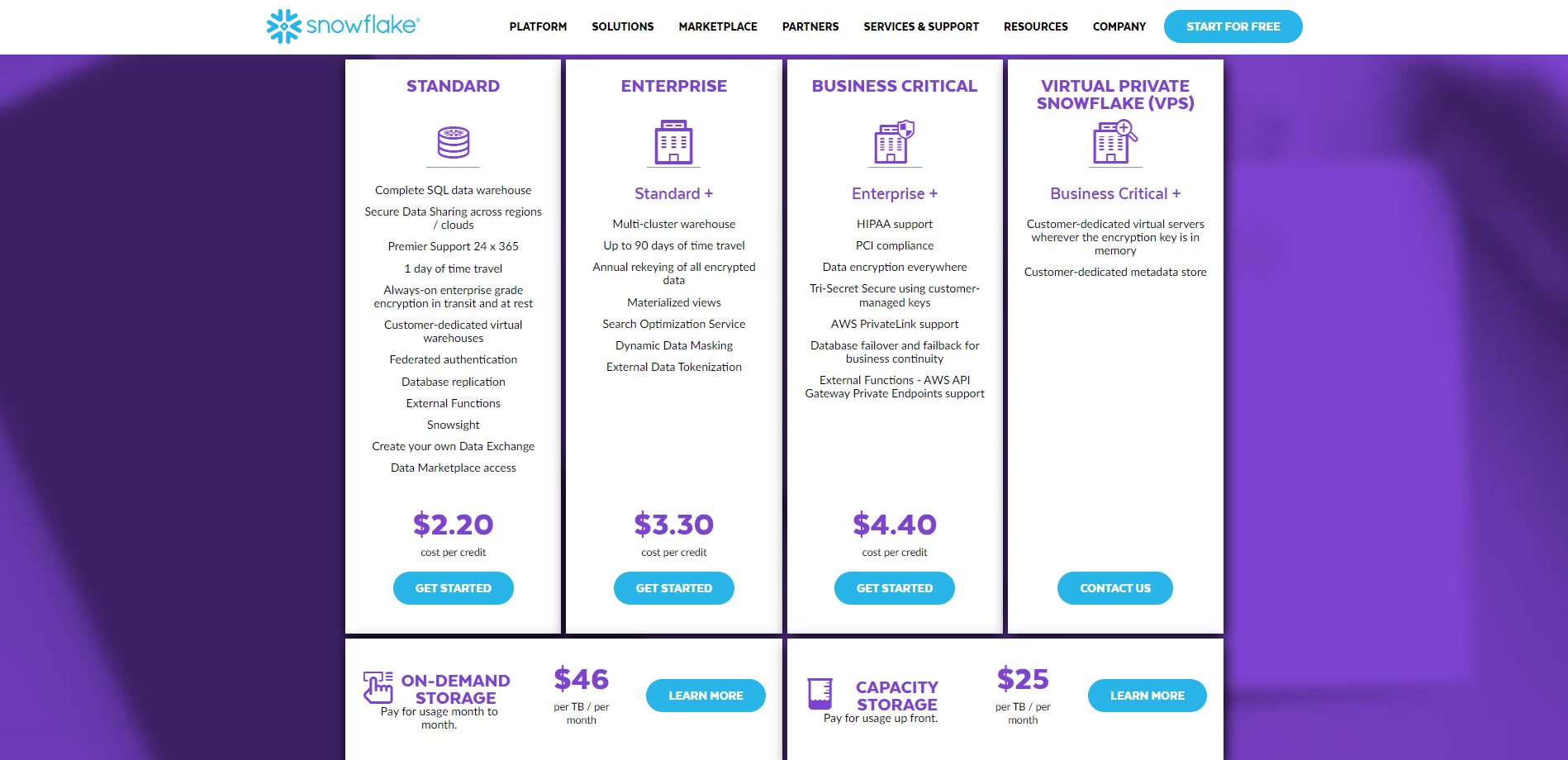
Teisest küljest on Databricksi pakutavad kolm kaubanduslikku hinnataset põhi-, lisatasu- ja ettevõttehinnad. Saate vaadata kogu hinnakirja paremalt siin.

Järeldus
Suurepäraste andmeanalüüsi tööriistade hulka kuuluvad Snowflake ja Databricks.
Igal neist on eelised ja puudused. Kasutusmustrid, andmemahud, töökoormused ja andmestrateegia võtavad kõik arvesse, kui otsustate, milline platvorm sobib teie ettevõtte jaoks ideaalselt.
Snowflake sobib paremini neile, kes on kogenud SQL-i ning tüüpilise andmete teisendamise ja analüüsi jaoks.
Voogesituse, ML, AI ja andmeteaduse töökoormused sobivad Databricksi jaoks paremini selle Spark-mootori tõttu, mis toetab paljude keelte kasutamist.
Teistele keeltele järele jõudmiseks on Snowflake võtnud kasutusele Pythoni, Java ja Scala toe.
Mõned väidavad, et Snowflake minimeerib salvestusruumi sissevõtmise ajal, seega on see interaktiivsete päringute jaoks parem.
Lisaks on see suurepärane aruannete ja armatuurlaudade koostamiseks ning BI töökoormuse haldamiseks. Andmelao osas toimib see hästi.
Mõned kasutajad on aga märkinud, et see kannatab suurte andmemahtude tõttu, näiteks voogesitusrakendustes. Lumehelbeke triumfeerib andmeladustamisoskustele tuginevas otseses konkurentsis.
Databricks pole aga tegelikult andmeladu. Selle andmeplatvorm on laiahaardelisem ja sellel on paremad ELT, andmeteaduse ja masinõppe võimalused kui Snowflake.
Kasutajad ei kontrolli hallatavate objektide talletamise kulusid, kuhu nad oma andmeid salvestavad. Peamised teemad on andmejärv ja andmetöötlus.
Kuid see on spetsiaalselt suunatud andmeteadlastele ja äärmiselt kvalifitseeritud analüütikutele.
Kokkuvõtteks võib öelda, et Databricks võidab tehnilise publiku jaoks. Nii tehniliselt teadlikud kui ka mittetehnilised kasutajad saavad Snowflake'i hõlpsalt kasutada.
Peaaegu kõik andmehaldusfunktsioonid, mida Snowflake pakub, on saadaval Databricksi ja palju muu kaudu. Kuid seda on keerulisem kasutada, see hõlmab kõrget õppimiskõverat ja vajab rohkem hooldamist.
Siiski saab see hakkama palju suurema hulga andmekoormuse ja keeltega. Ja need, kes on Apache Sparkiga tuttavad, kalduvad Databricksi poole.
Snowflake sobib paremini klientidele, kes soovivad kiiresti installida hea andmelao ja analüüsiplatvormi, ilma et peaks takerduma seadistustesse, andmeteaduse üksikasjadesse või käsitsi seadistamisse.
See ei tähenda ka väidet, et Snowflake on lihtne tööriist või uutele kasutajatele. Sugugi mitte.
See pole nii kõrgetasemeline kui Databricks; see platvorm sobib paremini keerukate andmetöötluse, ETL-i, andmeteaduse ja voogedastusrakenduste jaoks.
Snowflake on analüütika andmeladu, mis salvestab tootmisandmeid. Lisaks on see kasulik nii inimestele, kes soovivad alustada väikesest ja järk-järgult üles tõusta, kui ka algajatele.





Jäta vastus