Ettevõtted koguvad rohkem andmeid kui kunagi varem, kuna nad toetuvad neile üha enam oluliste äriotsuste tegemisel, tootepakkumiste täiustamisel ja parema klienditeeninduse pakkumisel.
Kuna andmeid luuakse eksponentsiaalse kiirusega, pakub pilv andmetöötluse ja -analüütika jaoks mitmeid eeliseid, sealhulgas mastaapsust, töökindlust ja saadavust.
Pilveökosüsteemis on ka mitmeid andmetöötluse ja -analüütika tööriistu ja tehnoloogiaid. Kõige sagedamini kasutatavad kahte tüüpi suurandmete salvestusstruktuurid on andmelaod ja andmejärved.
Kuigi andmejärve kasutamine on vähem atraktiivne, kuna te ei saa mudeli ja andmete kohta päringuid teha, kui need on endiselt asjakohased, on andmehoidla kasutamine andmesalvestuse voogesitamiseks raiskav.

Wmillist tüüpi pilvearhitektuuri me valime?
Kas peaksime kaaluma andmejärvehoone uuemaid kontseptsioone või peaksime rahulduma lao või järve piirangutega?
Uudne andmesalvestusarhitektuur, mida nimetatakse "andmete järvehooneks", ühendab andmejärvede kohandatavuse andmeladude andmehaldusega.
Erinevate suurandmete salvestamise meetodite mõistmine on oluline ärianalüüsi (BI), andmeanalüütika ja usaldusväärse andmesalvestuskonveieri loomiseks. masinõpe (ML) töökoormused, olenevalt teie ettevõtte nõudmistest.
Selles postituses vaatleme üksikasjalikult Data Warehouse'i, Data Lake'i ja Data Lakehouse'i koos nende eeliste, piirangute ning plusside ja miinustega. Alustagem.
Mis on andmeladu?
Andmeladu on tsentraliseeritud andmehoidla, mida organisatsioon kasutab tohutute andmemahtude hoidmiseks paljudest allikatest. Andmeladu toimib organisatsiooni ainsa "andmete tõesuse" allikana ning on aruandluse ja ärianalüütika jaoks hädavajalik.
Tavaliselt ühendavad andmelaod ajalooliste andmete salvestamiseks relatsiooniandmekogumeid mitmest allikast, näiteks rakendus-, äri- ja tehinguandmed. Enne laosüsteemi laadimist muundatakse ja puhastatakse andmed andmeladudes, et neid saaks kasutada ühtse andmetõe allikana.
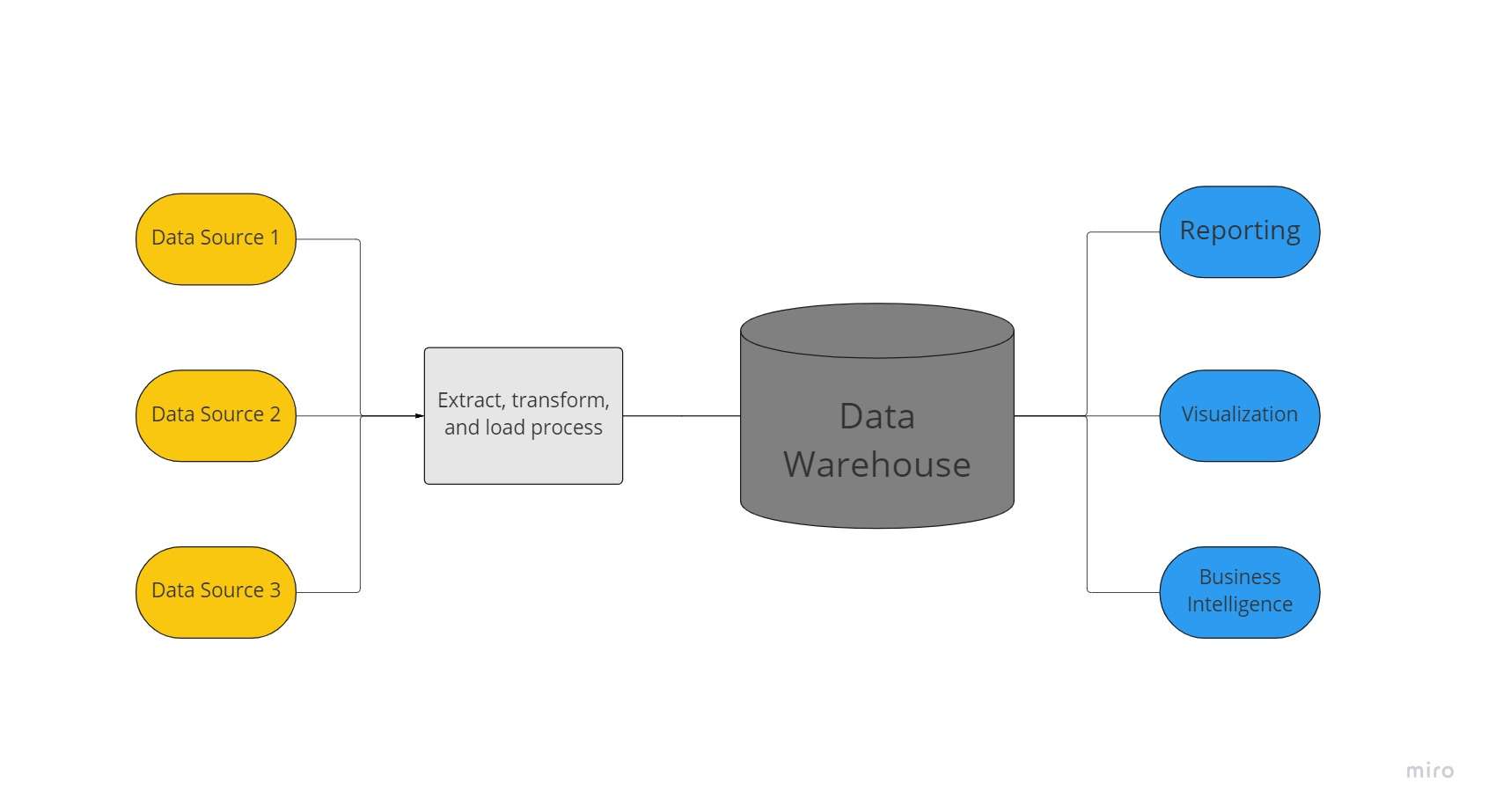
Tänu oma võimele pakkuda kiiresti äriteavet ettevõtte kõigist valdkondadest, investeerivad ettevõtted andmeladudesse. Kasutades BI-tööriistu, SQL-i kliente ja muid vähem keerukaid (st mitte-andmeteaduslikke) analüüsilahendusi, ärianalüütikud, saavad andmeinsenerid ja otsustajad juurdepääsu andmeladude andmetele.
Üha suureneva andmemahuga lao pidamine on kulukas ning andmeladu ei suuda töödelda toor- ega struktureerimata andmeid. Lisaks ei ole see ideaalne valik keerukate andmeanalüüsi tehnikate jaoks, nagu masinõpe või ennustav modelleerimine.
Seetõttu pakub andmeladu kiiremaid vastuseid päringule ja kvaliteetsemaid andmeid. Google Big Query, Amazon Redshift, Azure SQL Data warehouse ja Snowflake on pilveteenused, mis on saadaval andmeladudele.
Andmelao eelised
- Ärianalüüsi ja andmeanalüütika töökoormuse tõhususe ja kiiruse suurendamine: Andmelaod lühendavad andmete ettevalmistamiseks ja analüüsimiseks kuluvat aega. Nad saavad hõlpsasti linkida andmeanalüütika ja äriteabe tööriistadega, kuna andmelaost pärinevad andmed on usaldusväärsed ja järjepidevad. Lisaks säästavad andmelaod andmete kogumiseks vajalikku aega ja annavad meeskondadele võimaluse kasutada andmeid aruannete, armatuurlaudade ja muude analüüsinõuete jaoks.
- Andmete järjepidevuse, kvaliteedi ja standardimise suurendamine: organisatsioonid koguvad andmeid erinevatest allikatest, sealhulgas kasutaja-, müügi- ja tehinguandmeid. Ettevõte saab andmeid ärinõuete täitmiseks usaldada, sest andmehoidla koondab ettevõtte andmed ühtsesse standardvormingusse, mis võib toimida andmete tõesuse ühtse allikana.
- Üldise otsustusvõime parandamine: Andmehoidla hõlbustab paremate otsuste tegemist, pakkudes tsentraliseeritud poodi nii värskete kui ka vanade andmete jaoks. Töödeldes andmeid andmeladudes täpse ülevaate saamiseks, saavad otsustajad hinnata riske, mõista kliendi soove ning täiustada kaupu ja teenuseid.
- Parema äriteabe pakkumine: Andmeladu loob silla tohutute algandmete, mida kogutakse sageli rutiinselt, ja kureeritud andmete vahel, mis pakuvad teadmisi. Need toimivad organisatsiooni andmesalvestuse alusena, võimaldades tal vastata keerulistele küsimustele oma andmete kohta ja kasutada vastuseid kaitstud äriotsuste tegemiseks.
Andmelao piirangud
- Andmete paindlikkuse puudumine: Kuigi andmelaod on struktureeritud andmete haldamisel suurepärased, võivad poolstruktureeritud ja struktureerimata andmevormingud, nagu logianalüütika, voogesitus ja sotsiaalmeedia andmed, olla nende jaoks väljakutseid. See muudab andmeladude soovitamise masinõppe- ja kasutusjuhtudeks tehisintellekti raskusi.
- Paigaldamine ja hooldamine kulukas: Andmeladude paigaldamine ja hooldamine võib olla kulukas. Lisaks ei ole andmeladu sageli staatiline; see vananeb ja vajab sagedast hooldust, mis on kallis.
Plusse
- Andmeid on lihtne leida, hankida ja päringuid teha.
- Kuni andmed on juba puhtad, on SQL-andmete ettevalmistamine lihtne.
Miinused
- Olete sunnitud kasutama ainult ühte analüüsimüüjat.
- Struktureerimata või voolavate andmete analüüsimine ja säilitamine on üsna kulukas.
Mis on Data Lake?
Andmejärved lubavad ja võimaldavad igat tüüpi andmeid. Kasulik on, kui andmed asuvad kättesaadaval viisil tsentraalselt ja lugemiseks kättesaadavad.
Andmejärv on tsentraliseeritud, äärmiselt kohandatav salvestusruum, kus hoitakse tohutul hulgal organiseeritud ja struktureerimata andmeid töötlemata, muutmata ja vormindamata kujul.
Andmejärv kasutab andmete salvestamiseks lamedat arhitektuuri ja töötlemata olekus talletatud objekte, erinevalt andmeladudest, mis salvestavad eelnevalt puhastatud relatsiooniandmeid.
Andmejärved, erinevalt andmeladudest, millel on raskusi selles vormingus andmete käsitlemisega, on kohandatavad, usaldusväärsed ja taskukohased ning võimaldavad ettevõtetel saada struktureerimata andmetest paremat ülevaadet.
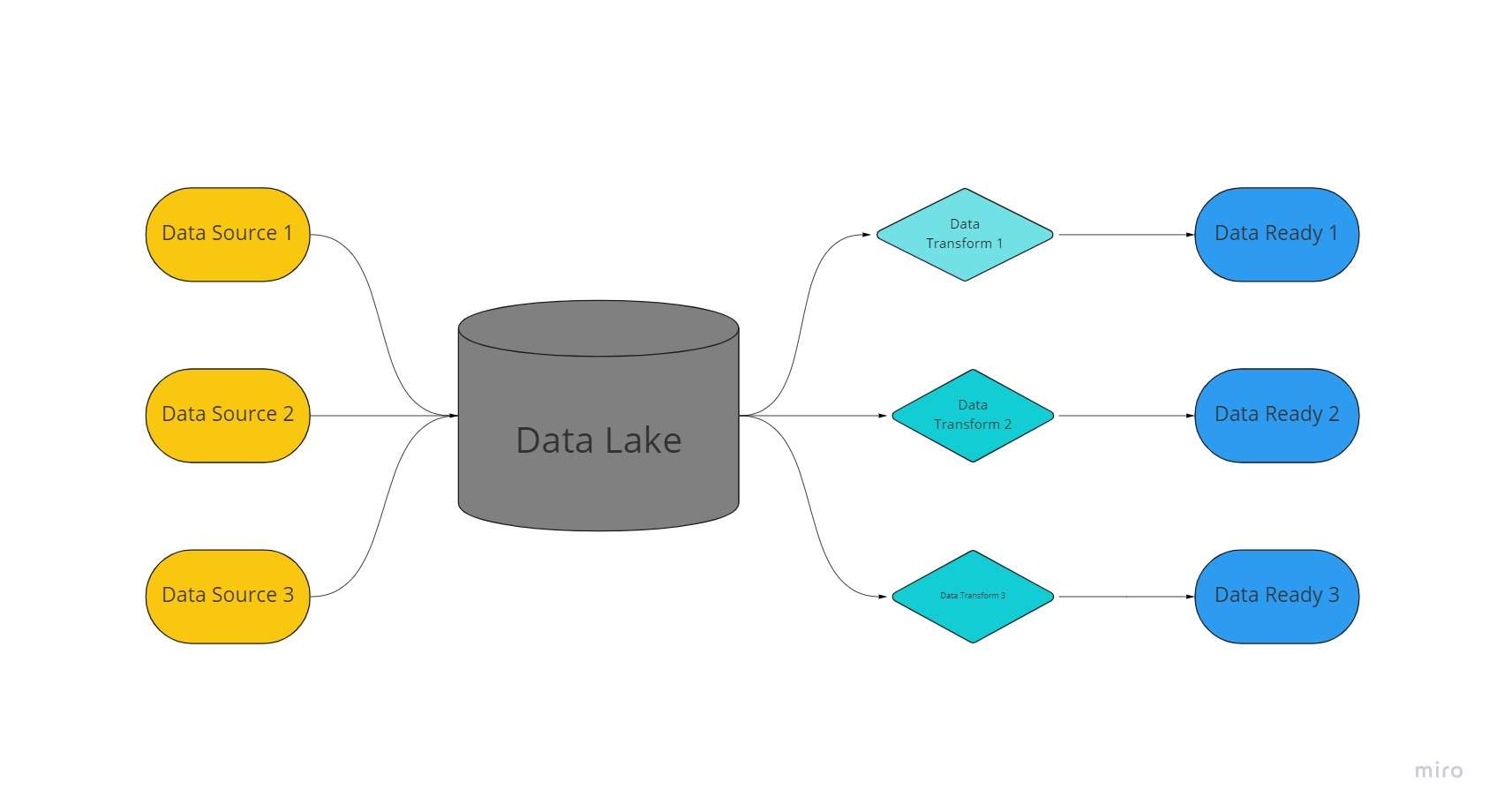
Andmejärvedes ekstraheeritakse, laaditakse ja teisendatakse andmeid (ELT) pigem analüütilistel eesmärkidel kui andmete kogumise ajal skeemi või andmete loomisel.
Tehnoloogiate kasutamine paljude asjade Interneti-seadmete andmetüüpide jaoks, Sotsiaalse meediaja andmete voogedastus, andmejärved võimaldavad masinõpet ja ennustavat analüüsi.
Lisaks saab andmejärve kasutada andmeteadlane, kes suudab töötlemata andmeid töödelda. Andmeladu seevastu on ettevõtetel lihtsam kasutada. See sobib suurepäraselt kasutajate profiilide koostamiseks, ennustav analüüs, masinõpe ja muud ülesanded.
Kuigi andmejärved lahendavad mitmeid andmeladudega seotud probleeme, on nende andmekvaliteet halb ja päringu kiirus ebapiisav. Lisaks vajavad ärikasutajad SQL-päringute tegemiseks lisatööriistu. Halvasti struktureeritud andmejärves võib tekkida andmete seiskumise probleem.
Data Lake'i eelised
- Paljude masinõppe ja andmeteaduse rakendusjuhtumite tugi Andmejärvedes olevate andmete käsitlemiseks on lihtsam kasutada erinevaid masin- ja süvaõppe algoritme, kuna andmeid hoitakse avatud ja töötlemata kujul.
- Andmejärvede mitmekülgsus, mis võimaldab salvestada andmeid mis tahes vormingus või meediumis ilma eelseadistatud skeemi nõudmiseta, on suur eelis. Tulevasi andmete kasutamise juhtumeid saab toetada ja rohkem andmeid saab analüüsida, kui andmed jäetakse algsesse olekusse.
- Selleks, et vältida mõlemat tüüpi andmete salvestamist erinevates kontekstides, võivad andmejärved sisaldada nii struktureeritud kui ka struktureerimata andmeid. Erinevat tüüpi organisatsiooniandmete salvestamiseks pakuvad nad ühte asukohta.
- Võrreldes tavapäraste andmeladudega on andmejärved odavamad, kuna need on ehitatud nii, et neid hoitakse odava kauba riistvaral, näiteks objektide salvestusruumil, mis on sageli suunatud madalamale salvestatud gigabaidi hinnale.
Data Lake'i piirangud
- Andmeanalüütika ja äriteabe kasutusjuhtumite tulemused on halvad: andmejärved võivad muutuda korrastamata, kui neid ei hooldata piisavalt, mis muudab nende sidumise äriteabe ja -analüütika tööriistadega keeruliseks. Lisaks, kui see on vajalik aruandluse ja analüütika kasutamise juhtumite jaoks, puudub järjepidevus andmestruktuurid ja ACID (aatomilisus, järjepidevus, isolatsioon ja vastupidavus) tehingutugi võib viia päringu ebaoptimaalse jõudluseni.
- Andmejärvede ebajärjekindlus muudab andmete töökindluse ja turvalisuse jõustamise võimatuks, mille tulemuseks on mõlema puudumine. Tundlike andmetüüpide jaoks sobivate andmeturbe- ja haldusstandardite väljatöötamine võib olla keeruline, kuna andmejärved saavad hakkama mis tahes andmevormiga.
Plusse
- Lahendused, mis on taskukohased igat tüüpi andmete jaoks.
- Suudab käsitleda andmeid, mis on nii organiseeritud kui ka poolstruktureeritud.
- Ideaalne keeruliseks andmetöötluseks ja voogedastuseks.
Miinused
- Vajab keerukat torujuhtme ehitamist.
- Andke andmetele aega, et need muutuksid päringuteks.
- Andmete töökindluse ja kvaliteedi tagamine võtab aega.
Mis on Data Lakehouse?
Uudne suurandmete salvestusarhitektuur, mida nimetatakse "andmete järvehooneks", ühendab andmejärvede ja andmeladude parimad aspektid. Kõik teie andmed, olenemata sellest, kas need on struktureeritud, poolstruktureeritud või struktureerimata, saab tänu andmekeskusele salvestada ühes kohas parima masinõppe, äriteabe ja voogesituse võimalustega.
Andmejärvede lähtepunktiks on sageli kõikvõimalikud andmejärved; pärast seda muudetakse andmed Delta Lake'i vormingusse (avatud lähtekoodiga salvestuskiht, mis toob andmejärvede töökindluse).
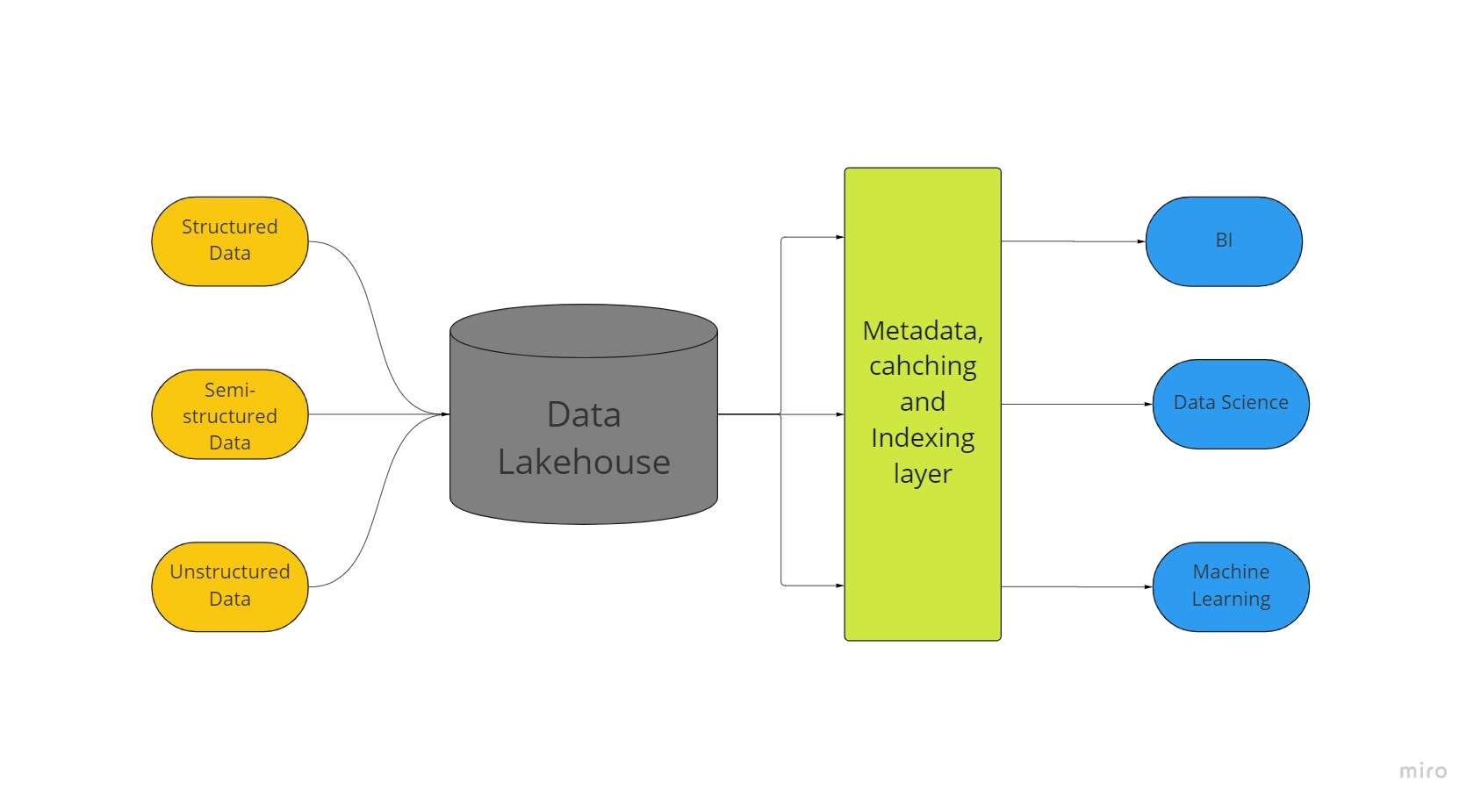
Deltajärvedega andmejärved võimaldavad ACID-i tehinguprotseduure tavalistest andmeladudest. Sisuliselt kasutab Lakehouse süsteem odavat salvestusruumi, et säilitada tohutul hulgal andmemahtusid nende algsel kujul, nagu andmejärved.
Metaandmete kihi lisamine poe kohale annab ka andmestruktuuri ja annab võimaluse andmehaldustööriistadeks, nagu need, mida leidub andmeladudes.
See võimaldab paljudel meeskondadel pääseda ühe süsteemi kaudu juurde kõikidele ettevõtte andmetele erinevate algatuste jaoks, nagu andmeteadus, masinõpe ja äriteave.
Data Lakehouse'i eelised
- Suurema hulga töökoormuste tugi: keerukate analüüside hõlbustamiseks annavad andmemajad kasutajatele otsese juurdepääsu mõnele kõige populaarsemale ärianalüüsi tööriistale (Tableau, PowerBI). Lisaks saavad andmeteadlased ja masinõppeinsenerid andmeid hõlpsasti kasutada, kuna andmekeskused kasutavad avatud andmevorminguid (nt Parquet) koos API-de ja masinõppe raamistikega, nagu Python/R.
- Kulutõhusus: Data Lakehouses kasutavad andmejärvede kulutõhusate salvestusomaduste rakendamiseks odavaid objektide salvestamise lahendusi. Ühtset lahendust pakkudes kaotavad andmejärved ka erinevate andmesalvestussüsteemide haldamisega kaasnevad kulud ja ajakulu.
- Data Lakehouse'i disain tagab skeemi ja andmete terviklikkuse, muutes tõhusate andmeturbe- ja haldussüsteemide loomise lihtsamaks. Lihtsus andmete versioonimine, valitsemine ja turvalisus.
- Data Lakehouses pakuvad ühtset mitmeotstarbelist andmesalvestusplatvormi, mis suudab rahuldada ettevõtte kõiki andmenõudeid, mis vähendab andmete dubleerimist. Enamik ettevõtteid valib hübriidlahenduse nii andmelao kui ka andmejärve eeliste tõttu. Vahepeal võib see strateegia kaasa tuua kuluka andmete dubleerimise.
- Avatud vormingute tugi. Avatud vormingud on failitüübid, mida saavad kasutada paljud tarkvararakendused ja mille spetsifikatsioonid on avalikult kättesaadavad. Aruannete kohaselt on Lakehouses võimeline salvestama andmeid tavalistes failivormingutes, nagu Apache Parquet ja ORC (Optimized Row Columnar).
Data Lakehouse'i piirangud
Data Lakehouse'i suurim puudus on see, et see on endiselt noor ja arenev tehnoloogia. Ei ole kindel, kas ta täidab selle tulemusena oma kohustused. Enne kui andmejärved suudavad konkureerida väljakujunenud suurandmete salvestussüsteemidega, võib kuluda aastaid.
Arvestades aga kaasaegse innovatsiooni toimumise kiirust, on raske öelda, kas seda ei asenda mõni muu andmesalvestussüsteem.
Plusse
- Ühel platvormil on kõik andmed, mis tähendab, et hooldatavaid hostinimesid on vähem.
- Aatomilisus, konsistents, isoleeritus ja sitkus ei muutu.
- See on oluliselt soodsam.
- Ühel platvormil on kõik andmed, mis tähendab, et hooldatavaid hostinimesid on vähem.
- Lihtne hallata ja kiiresti kõik probleemid lahendada
- Muutke torujuhtme ehitamine lihtsamaks
Miinused
- Seadistamine võib veidi aega võtta.
- See on liiga noor ja liiga kaugel, et kvalifitseeruda väljakujunenud salvestussüsteemiks.
Andmeladu vs Data Lake vs Data Lakehouse
Andmelaol on ettevõtte luure-, aruandlus- ja analüütikarakendustes pikk ajalugu ning see on esimene suurandmete salvestamise tehnoloogia.
Andmelaod seevastu on kallid ja neil on raskusi mitmekesiste ja struktureerimata andmete (nt voogesitusandmete) käsitlemisega. Masinõppe ja andmeteaduse töökoormuste jaoks töötati välja andmejärved, et hallata algandmeid erineval kujul taskukohasel salvestusruumil.
Kuigi andmejärved on struktureerimata andmetega tõhusad, puuduvad neil andmeladude ACID-tehinguvõimalused, mistõttu on andmete järjepidevuse ja töökindluse tagamine keeruline.
Uusim andmesalvestusarhitektuur, mida tuntakse andmejärvedena, ühendab andmeladude töökindluse ja järjepidevuse andmejärvede taskukohasuse ja kohandatavusega.
Järeldus
Kokkuvõttes võib andmete järvehoone nullist ülesehitamine olla keeruline. Lisaks kasutate peaaegu kindlasti platvormi, mis on loodud võimaldama avatud andmete järvehoone arhitektuuri.
Seetõttu olge enne ostu sooritamist ettevaatlik, et uurida iga platvormi paljusid funktsioone ja rakendusi. Ettevõtted, kes otsivad küpset, struktureeritud andmelahendust, mis keskenduvad äriteabe ja andmeanalüütika kasutusjuhtudele, võivad kaaluda andmelao kasutamist.
Ettevõtted, kes otsivad skaleeritavat ja taskukohast suurandmete lahendust andmeteaduse ja struktureerimata andmete masinõppe töökoormuse suurendamiseks, peaksid aga kaaluma andmejärvi.
Võtke arvesse, et teie ettevõte vajab rohkem andmeid, kui andmeladu ja andmejärve tehnoloogiad suudavad pakkuda, või et otsite lahendust keeruka analüüsi ja masinõppe toimingute integreerimiseks oma andmetesse. A andmete järvemaja on antud olukorras mõistlik variant.





Jäta vastus