Índice del contenido[Esconder][Espectáculo]
Un marco para el aprendizaje profundo consta de una combinación de interfaces, bibliotecas y herramientas para definir y entrenar modelos de aprendizaje automático de forma rápida y precisa.
Debido a que el aprendizaje profundo utiliza una gran cantidad de datos no textuales no estructurados, necesita un marco que controle la interacción entre las "capas" y acelere el desarrollo del modelo aprendiendo de los datos de entrada y tomando decisiones autónomas.
Si está interesado en aprender sobre el aprendizaje profundo en 2021, considere usar uno de los marcos que se indican a continuación. Recuerda elegir uno que te ayude a alcanzar tus metas y visión.
1. TensorFlow

Cuando se habla de aprendizaje profundo, TensorFlow es a menudo el primer marco mencionado. Muy popular, este marco no solo es utilizado por Google, la empresa responsable de su creación, sino también por otras empresas como Dropbox, eBay, Airbnb, Nvidia y muchas otras.
TensorFlow se puede usar para desarrollar API de alto y bajo nivel, lo que le permite ejecutar aplicaciones en casi cualquier tipo de dispositivo. Aunque Python es su lenguaje principal, se puede acceder a la interfaz de Tensoflow y controlarla usando otros lenguajes de programación como C++, Java, Julia y JavaScript.
Al ser de código abierto, TensorFlow le permite realizar varias integraciones con otras API y obtener asistencia y actualizaciones rápidas de la comunidad. Su dependencia de "gráficos estáticos" para el cálculo le permite realizar cálculos inmediatos o guardar operaciones para acceder a ellas en otro momento. Estas razones, sumadas a la posibilidad de que puedas “observar” el desarrollo de tu red neuronal a través de TensorBoard, hacen de TensorFlow el framework más popular para el aprendizaje profundo.
Principales Caracteristicas
- De código abierto
- Flexibilidad
- Depuración rápida
2. PyTorch
PyTorch es un framework desarrollado por Facebook para soportar el funcionamiento de sus servicios. Desde que se convirtió en código abierto, este marco ha sido utilizado por otras empresas además de Facebook, como Salesforce y Udacity.
Este marco opera gráficos actualizados dinámicamente, lo que le permite realizar cambios en la arquitectura de su conjunto de datos a medida que lo procesa. Con PyTorch es más sencillo desarrollar y entrenar una red neuronal, incluso sin experiencia en aprendizaje profundo.
Al ser de código abierto y estar basado en Python, puede realizar integraciones simples y rápidas en PyTorch. También es un marco simple para aprender, usar y depurar. Si tiene preguntas, puede contar con el excelente soporte y las actualizaciones de ambas comunidades: la comunidad de Python y la comunidad de PyTorch.
Principales Caracteristicas
- Fácil de aprender
- Soporta GPU y CPU
- Amplio conjunto de API para ampliar las bibliotecas
3. Apache MXnet

Debido a su alta escalabilidad, alto rendimiento, resolución rápida de problemas y soporte avanzado de GPU, Apache creó este marco para su uso en grandes proyectos industriales.
MXNet incluye la interfaz Gluon que permite a los desarrolladores de todos los niveles empezar con el aprendizaje profundo en la nube, en dispositivos perimetrales y en aplicaciones móviles. En solo unas pocas líneas de código Gluon, puede crear regresión lineal, redes convolucionales y LSTM recurrentes para detección de objetos, reconocimiento de voz, recomendación y personalización.
MXNet se puede usar en varios dispositivos y es compatible con varios lenguajes de programación como Java, R, JavaScript, Scala y Go. Aunque la cantidad de usuarios y miembros en su comunidad es baja, MXNet tiene una documentación bien escrita y un gran potencial de crecimiento, particularmente ahora que Amazon ha seleccionado este marco como la herramienta principal para Machine Learning en AWS.
Principales Caracteristicas
- 8 enlaces de idiomas
- Capacitación distribuida, compatible con sistemas multi-CPU y multi-GPU
- Front-end híbrido, que permite cambiar entre modos imperativo y simbólico
4. Kit de herramientas cognitivas de Microsoft
Si está pensando en desarrollar aplicaciones o servicios que se ejecuten en Azure (servicios en la nube de Microsoft), Microsoft Cognitive Toolkit es el marco que debe seleccionar para sus proyectos de aprendizaje profundo. Es de código abierto y está respaldado por lenguajes de programación como Python, C++, C#, Java, entre otros. Este marco está diseñado para "pensar como el cerebro humano", por lo que puede procesar grandes cantidades de datos no estructurados, al tiempo que ofrece un entrenamiento rápido y una arquitectura intuitiva.
Al seleccionar este marco, el mismo detrás de Skype, Xbox y Cortana, obtendrá un buen rendimiento de sus aplicaciones, escalabilidad y una integración simple con Azure. Sin embargo, en comparación con TensorFlow o PyTorch, se reduce la cantidad de miembros en su comunidad y soporte.
El siguiente video ofrece una introducción completa y ejemplos de aplicación:
Principales Caracteristicas
- Documentación clara
- Soporte del equipo de Microsoft
- Visualización directa de gráficos
5. Keras

Al igual que PyTorch, Keras es una biblioteca basada en Python para proyectos de uso intensivo de datos. La API de keras funciona a un alto nivel y permite integraciones con API de bajo nivel como TensorFlow, Theano y Microsoft Cognitive Toolkit.
Algunas ventajas de usar keras son su simplicidad de aprendizaje, ya que es el marco recomendado para principiantes en aprendizaje profundo; su velocidad de despliegue; teniendo un gran apoyo de la comunidad de python y de las comunidades de los demás frameworks con los que se integra.
Keras contiene varias implementaciones del bloques de construcción de redes neuronales como capas, funciones objetivo, funciones de activación y optimizadores matemáticos. Su código está alojado en GitHub y hay foros y un canal de soporte de Slack. Además del soporte para estándar redes neuronales, Keras ofrece soporte para redes neuronales convolucionales y redes neuronales recurrentes.
Keras permite modelos de aprendizaje profundo para generarse en teléfonos inteligentes tanto en iOS como en Android, en una máquina virtual Java o en la web. También permite el uso de entrenamiento distribuido de modelos de aprendizaje profundo en clústeres de unidades de procesamiento de gráficos (GPU) y unidades de procesamiento de tensores (TPU).
Principales Caracteristicas
- Modelos pre-entrenados
- Soporte de back-end múltiple
- Soporte de la comunidad grande y fácil de usar
6. Apple CoreML
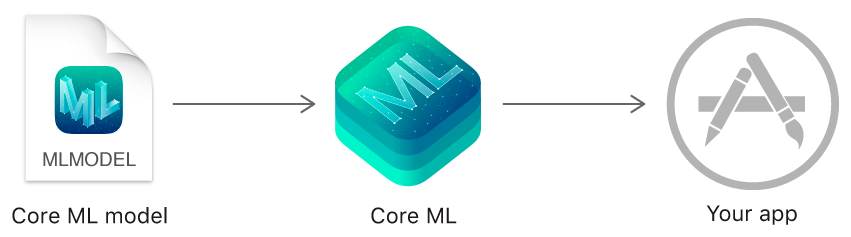
Apple desarrolló Core ML para respaldar su ecosistema: IOS, Mac OS y iPad OS. Su API funciona a bajo nivel, haciendo buen uso de los recursos de CPU y GPU, lo que permite que los modelos y aplicaciones creados sigan funcionando incluso sin conexión a Internet, lo que reduce la "huella de memoria" y el consumo de energía del dispositivo.
La forma en que Core ML logra esto no es exactamente creando otra biblioteca de aprendizaje automático optimizada para ejecutarse en iPhones/iPads. En cambio, Core ML es más como un compilador que toma las especificaciones del modelo y los parámetros entrenados expresados con otro software de aprendizaje automático y los convierte en un archivo que se convierte en un recurso para una aplicación de iOS. Esta conversión a un modelo Core ML ocurre durante el desarrollo de la aplicación, no en tiempo real mientras se usa la aplicación, y es facilitada por la biblioteca de Python coremltools.
Core ML ofrece un rendimiento rápido con una fácil integración de máquina de aprendizaje modelos en aplicaciones. Admite el aprendizaje profundo con más de 30 tipos de capas, así como árboles de decisión, máquinas de vectores de soporte y métodos de regresión lineal, todo construido sobre tecnologías de bajo nivel como Metal y Accelerate.
Principales Caracteristicas
- Fácil de integrar en aplicaciones
- Uso óptimo de los recursos locales, sin necesidad de acceso a Internet
- Privacidad: los datos no tienen que salir del dispositivo
7. ONNX

El último marco de nuestra lista es ONNX. Este marco surgió de una colaboración entre Microsoft y Facebook, con el objetivo de simplificar el proceso de transferencia y construcción de modelos entre diferentes marcos, herramientas, tiempos de ejecución y compiladores.
ONNX define un tipo de archivo común que puede ejecutarse en múltiples plataformas, al tiempo que aprovecha los beneficios de las API de bajo nivel, como las de Microsoft Cognitive Toolkit, MXNet, Caffe y (usando convertidores) Tensorflow y Core ML. El principio detrás de ONNX es entrenar un modelo en una pila e implementarlo usando otras inferencias y predicciones.
La Fundación LF AI, una suborganización de la Fundación Linux, es una organización dedicada a construir un ecosistema para apoyar De código abierto innovación en inteligencia artificial (IA), aprendizaje automático (ML) y aprendizaje profundo (DL). Agregó ONNX como un proyecto de posgrado el 14 de noviembre de 2019. Este movimiento de ONNX bajo el paraguas de la Fundación LF AI fue visto como un hito importante en el establecimiento de ONNX como un estándar de formato abierto independiente del proveedor.
ONNX Model Zoo es una colección de modelos preentrenados en Deep Learning disponibles en formato ONNX. Para cada modelo hay Cuadernos Jupyter para entrenar modelos y realizar inferencias con el modelo entrenado. Los cuadernos están escritos en Python y contienen enlaces a la conjunto de datos de entrenamiento y referencias al documento científico original que describe la arquitectura del modelo.
Principales Caracteristicas
- Interoperabilidad del marco
- Optimización de hardware
Conclusión
Este es un resumen de los mejores frameworks para deep learning. Hay varios marcos para este propósito, gratuitos o de pago. Para seleccionar lo mejor para su proyecto, primero sepa para qué plataforma desarrollará su aplicación.
Los marcos generales como TensorFlow y Keras son las mejores opciones para comenzar. Pero si necesita usar ventajas específicas del sistema operativo o del dispositivo, Core ML y Microsoft Cognitive Toolkit podrían ser las mejores opciones.
Hay otros marcos destinados a dispositivos Android, otras máquinas y propósitos específicos que no se han mencionado en esta lista. Si este último grupo le interesa, le sugerimos que busque su información en Google u otros sitios de aprendizaje automático.





Deje un comentario