在当今数据驱动的社会中,网络抓取已成为从互联网平台获取有见地数据的重要方法。
作为一个极受欢迎的社交媒体网站,Instagram 提供了大量用户生成的素材。 而且,这些生成的数据可用于营销、研究和其他原因。
得益于 Bright Data 功能丰富的 Instagram 抓取工具,用户可以轻松有效地从 Instagram 提取数据 网络抓取 工具。 在这篇文章中,我们将对 Instagram 抓取过程进行全面、逐步的演练。
那么,让我们看看如何从 Instagram 抓取数据的步骤。
从 Bright Data 了解 Instagram 爬虫
在两个通用网络抓取工具和一个预编译数据集的帮助下,Bright Data 提供了各种 Instagram 抓取服务。 这些技术提供了数据提取的多功能性并适应各种需求。
让我们更详细地检查这些选择中的每一个:
a. 抓取浏览器
被称为 Scraping Browser 的创新技术是为了满足数据抓取项目的需求而创建的。 它提供了在单个浏览器内大规模抓取所需的一切。 由于其集成的网站解锁自动化,它脱颖而出,这使其成为全球同类浏览器中唯一的。
Scraping Browser 使用户能够访问超越自动化和无头浏览器的强大功能,使他们能够超越最困难的脚本和网站机器人检测障碍。
数据抓取更有效、更省心,因为它具有自动调整功能,可以轻松管理新鲜块、验证码解决方案、指纹和重试,并显示为真实用户。
使用 AI 战胜机器人检测系统
通过利用尖端的 AI 技术,Scraping Browser 可以智取机器人检测系统并不断调整以适应其不断变化的策略。 为了更好地解锁网页,抓取浏览器从这些系统的尝试中学习,以检测和阻止抓取尝试并适当地修改其行为。
通过模仿真实用户使用的浏览器的行为,它优于传统代理的效率。 因此,客户可以专注于他们的数据抓取目标,而不必处理正在进行的机器人检测程序的困难和费用。
b. Web 抓取工具 IDE
Web Scraper IDE 是为开发人员创建的强大的网络抓取工具,可以处理复杂的抓取任务。 由于其完全托管的解决方案和预构建的抓取功能,它大大缩短了开发时间,同时提供了无限的可扩展性。 该应用程序通过提供来自流行网站的代码模板和现成的 JavaScript 函数,可以快速和可扩展地构建在线抓取工具。
Web Scraper IDE 提供了成功进行网络抓取所需的一切。 它是在线数据提取的完整解决方案,因为集成选项使客户能够计划爬网或通过 API 启动它们并与主存储系统链接。
如何使用它? - 教程
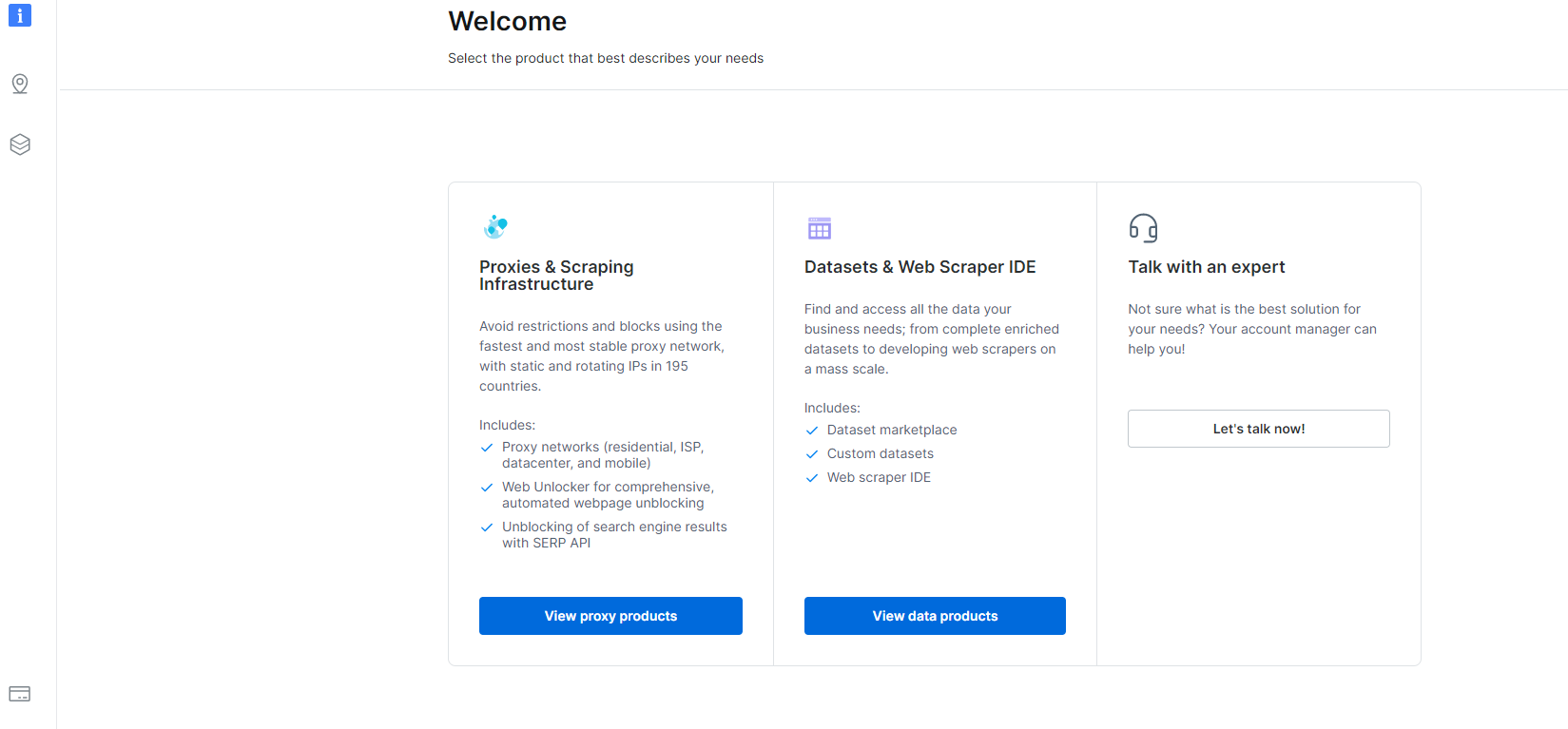
首先,导航到网站上的用户仪表板。

让我们从抓取 Instagram 的步骤开始。
1- 导航到 卖家专用后台 然后单击数据集和 Web Scraper IDE 部分。
2- 到达那里后,单击“我的刮板”。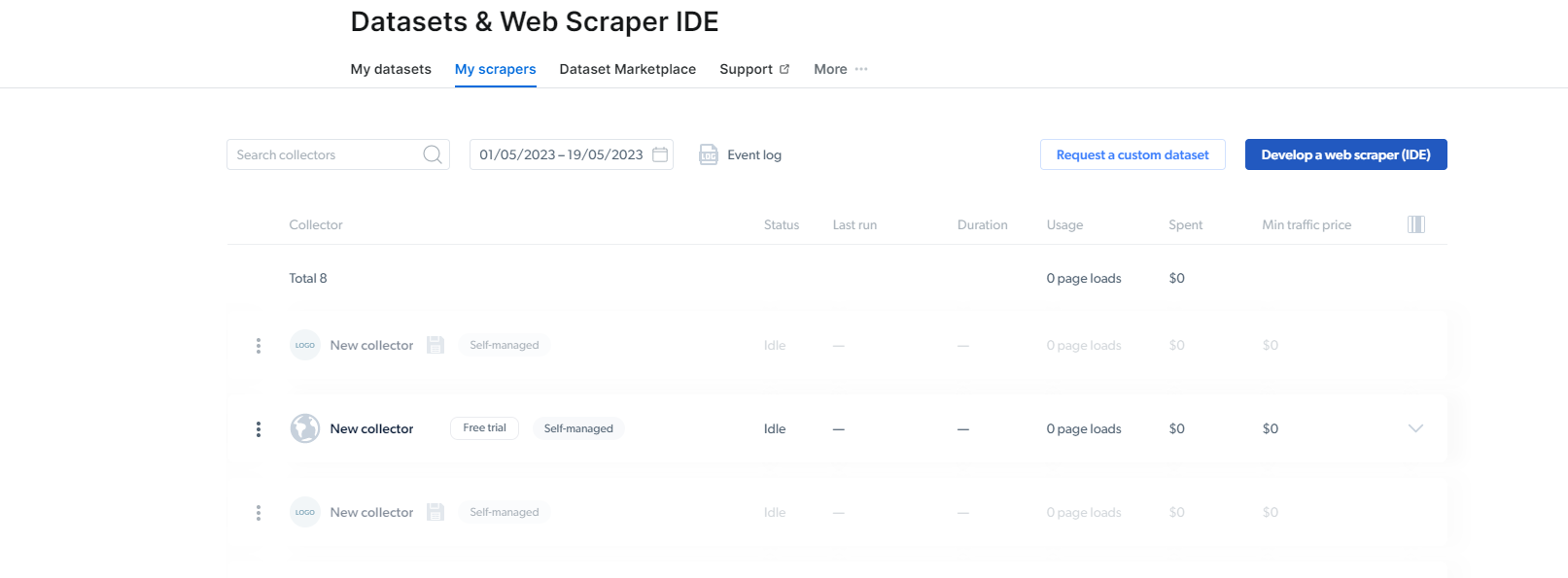
在这里,您需要点击“开发网络抓取工具(IDE)”。 在这里,我们将为 Instagram 创建我们的抓取工具。
3-现在,我们需要开发一个新的网络抓取工具。 就此示例而言,我选择抓取“NASA”帐户。 这只是为了这个例子。
所以,我的代码将如下所示:
/ Click the 'play' button in the top right to run this code:
// 1. Go to the page where you want to start
navigate('https://www.instagram.com/nasa/');
// 2. Add anything else you need to do on the page.
// For example: (see the help box for all command docs).
// click('.some-button')
// type('.some-input', 'shoes')
// wait('.some-lazy-loaded-element')
// 3. Once the browser page has the data you want, call parse() to get the data
// and call collect() to add a record to your final dataset
let data = parse();
collect({
url: new URL(location.href),
title: "Nasa Account",
links: data.links,
});
您需要单击右上角的“播放”按钮才能运行此代码。
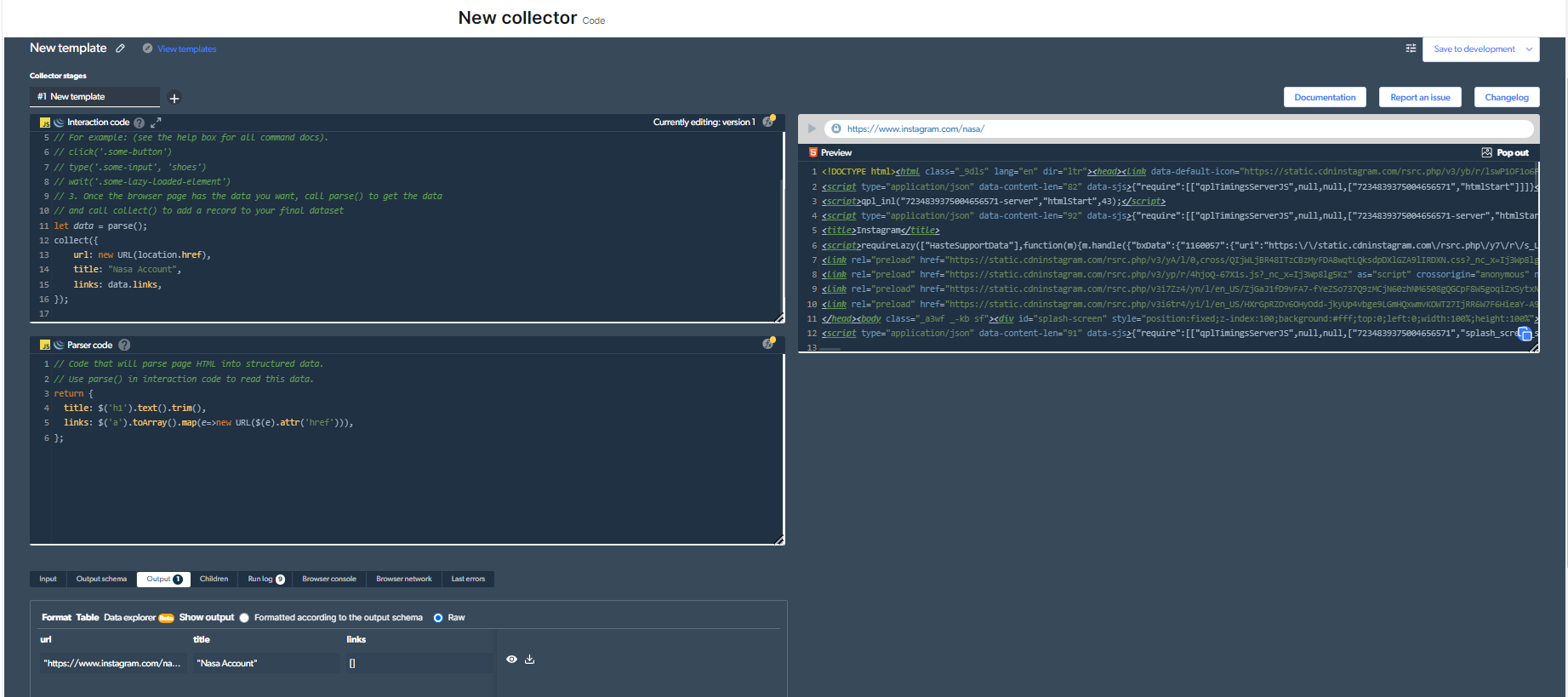
4- 现在,我们将有一个输出。
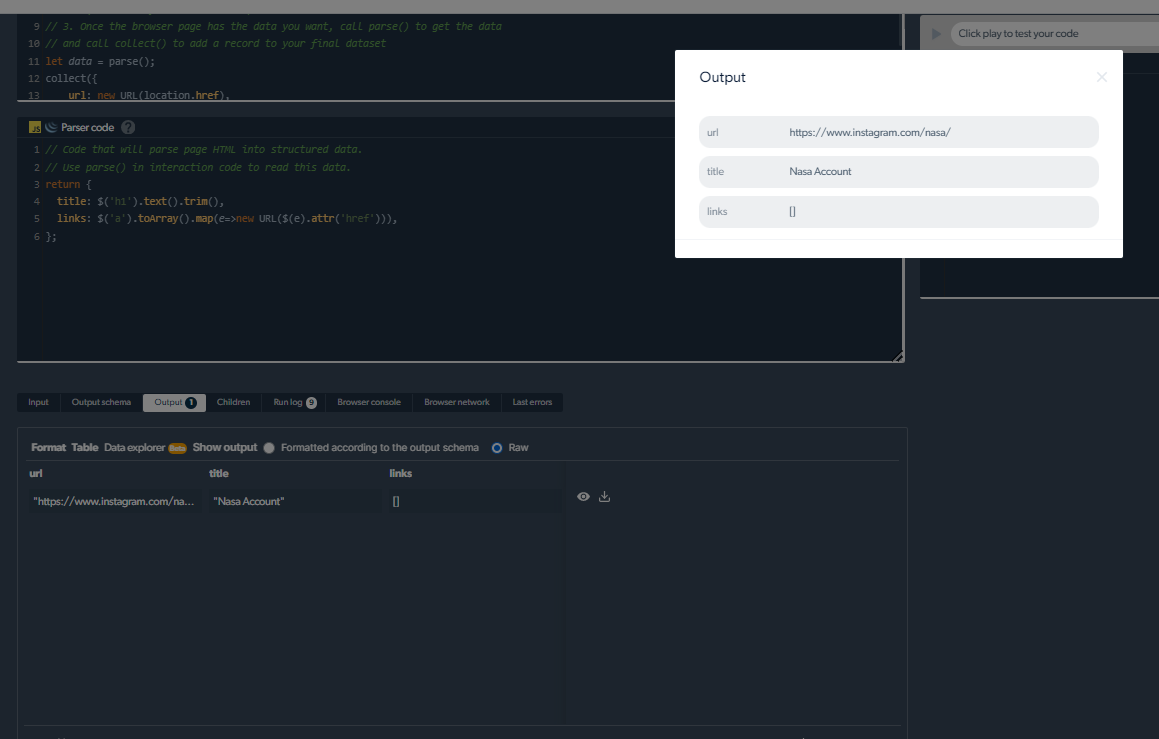
管理抓取问题
带有“显示更多按钮”的 Instagram 帖子可能很难被抓取。 然而,来自 Bright Data 的 Instagram 抓取工具就是为成功处理这种复杂性而设计的。 这些爬虫具有尖端的技能来遍历分页和加载额外的按钮。
Bright Data 的 Instagram 抓取工具有效地解决了这些困难,以实现彻底的数据提取,使您能够收集分析或研究所需的全部信息。
通过使用这些抓取工具,您可以解决 Instagram 帖子的动态特性带来的挑战。
c. 预先收集的数据集
Bright Data 明白并不是每个人都想运行他们的爬虫。 他们为 Instagram 提供预先收集的数据集以吸引此类消费者。
该数据集提供了大量有用的信息,例如关注者、个人资料、帖子等。
Bright Data 提供了自定义选项来根据您的需要对数据集进行个性化设置,无论您需要整个数据集还是专业数据的子集。 这种方法避免了构建和管理爬虫,为您提供随时可用的数据以供分析和洞察。
现在,让我们检查使这些工具如此有效的基础架构:代理基础架构和 Web Unlocker。
释放代理的力量
运用 代理 在网络抓取期间至关重要,以确保您的行为不被注意。
Bright Data 提供了广泛的选择 代理服务 是根据您的要求定制的。 你可以选择 住宅代理,提供超过 72 万个 IP,这些 IP 从 195 个国家/地区的真实对等设备轮换而来。
可选择ISP Proxies,提供全球700,000+真实家庭IP供长期使用; 数据中心代理,拥有来自任何地理位置的 770,000 多个共享 IP; 和移动代理,它们构成了拥有 3 多个 IP 的最大的真实对等 4G/7,000,000G 移动网络。
通过使用这些代理,可以在许多地方冒充授权用户轻松收集数据。

Proxy Manager:让代理管理更简单
管理多个代理可能很困难,但代理管理器使它变得容易。
这个开源界面使您能够从一个平台管理所有代理。 告别手动设置和切换代理。 Proxy Manager 简化了程序并节省了您的时间和精力。
代理浏览器扩展:轻松更改您的位置
您需要从多个地区收集网络数据吗? 我们的代理浏览器扩展涵盖了您。 您只需单击一下即可更改浏览位置,以获取特定区域的信息。
利用从多个区域收集数据的灵活性和简单性,无需任何技术复杂性。
它是如何工作的? - 教程
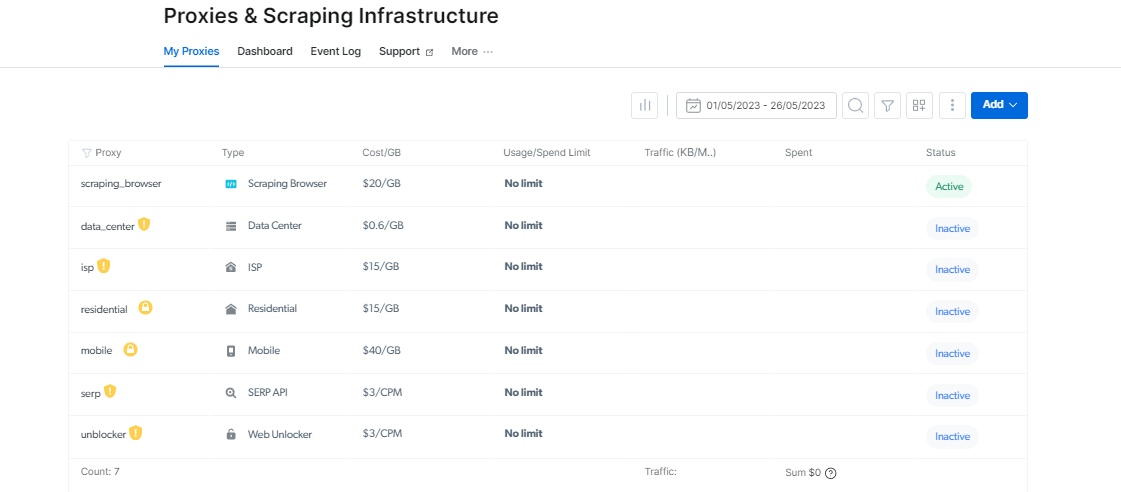
您可以找到您的 抓取浏览器 访问参数页面上的登录信息,将在您启动新的浏览器会话时使用。
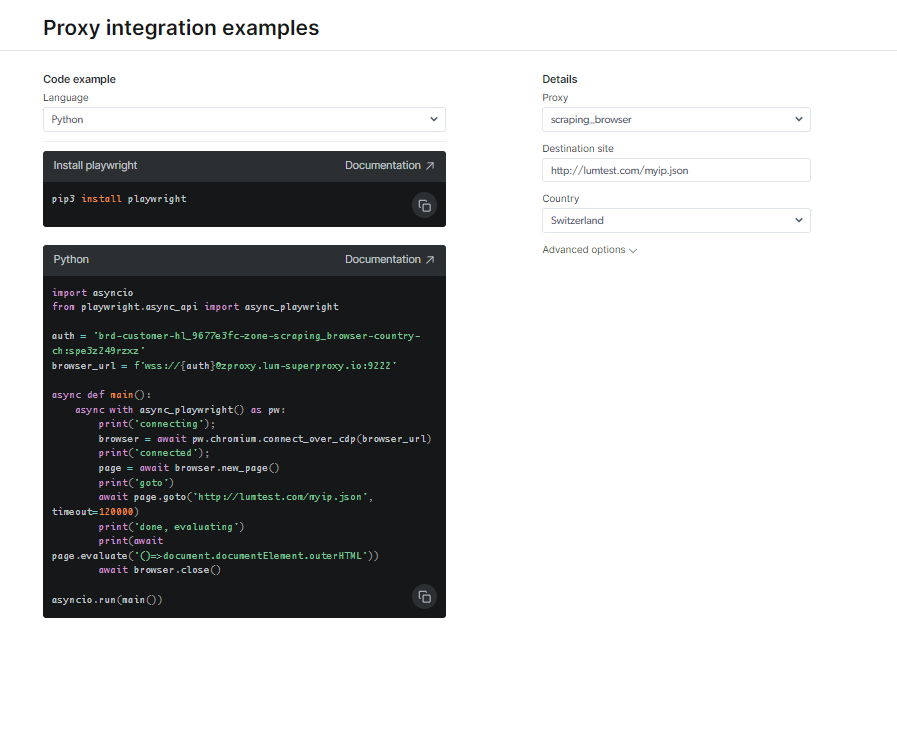
查看文档和代码示例,包括随时可用的全功能示例脚本,或观看简短的入门说明视频。 例如; 这里有一个 Python代码 集成示例:
需要帮助吗? 要与其中一位专家对话,您可以单击聊天图标。
请记住,在使用 Scraping Browser 时,您可以完全控制浏览器会话,并且可以执行 Puppeteer、Playwright 或直接使用 Chrome DevTools 协议支持的任何操作。
无障碍网站解锁
Scraping Browser 可以根据需要大规模运行。 您无需担心被禁止; 您可以根据需要启动任意数量的浏览器会话。
这种能力与代理的力量相结合,保证了持续的数据收集,使您能够有效地获取所需的数据。
抓取浏览器内置的解锁技巧和强大的代理网络可帮助您节省时间、提高生产力并发现新机会。
您还可以直接从同一页面查看统计信息。
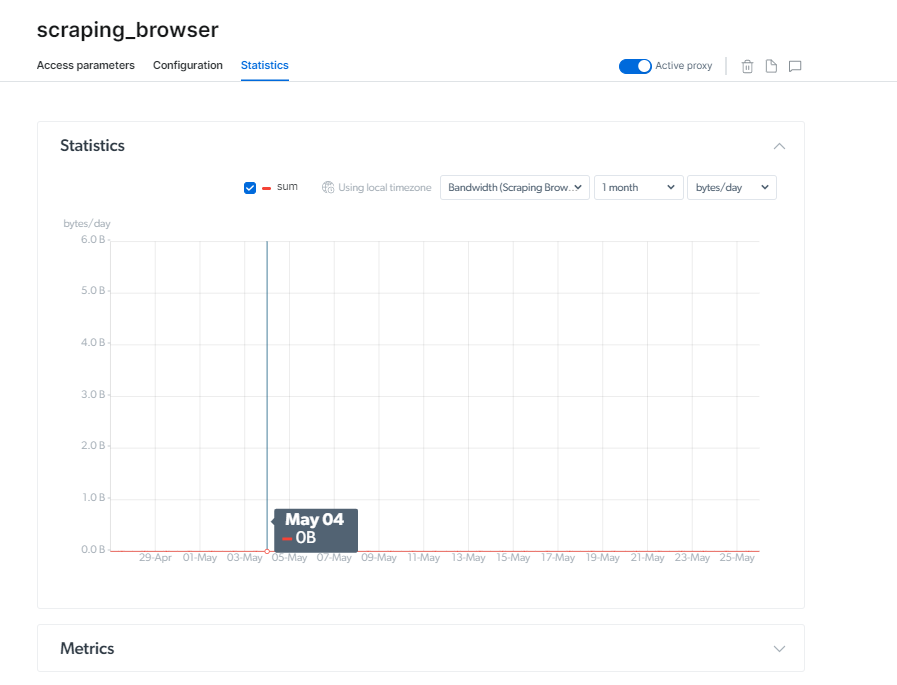
抓取浏览器定价
Bright Data 提供可定制的定价选择以满足各种目的。 您可以选择每月或每年的计费周期。
Pay as You Go 选项允许您只为使用的内容付费,无需承诺,起价为 20.00 美元/GB 和 0.1 美元/小时。
500 美元的增长计划适合成长型企业,折扣费用为 15.30 美元/GB 和 0.1 美元/小时。
商务包, 价格为 1000 美元,是最受欢迎的选项,Scraping Browser API 的价格为 13.50 美元/GB 和 0.1 美元/小时。
通过直接联系 Bright Data 团队,企业用户可以享受无限扩展和个性化定价。 立即开始免费试用,发现 Bright Data 的 Scraping Browser 的潜力并改变您的在线数据采集工作。
网站解锁器
Web Unlocker 是一种强大的工具,旨在超越网站限制并提供轻松的数据收集。 它通过利用自动化程序克服了多项挑战,包括 cookie、特定于站点的浏览器用户代理和验证码解决方案。
通过使用自动 IP 地址轮换,Web Unlocker 的用户可以不断抓取目标网站,确保对重要数据的持续访问。
增强开发人员请求之旅
多项功能使 Web Unlocker 在开发人员中很受欢迎。 该程序通过自动识别每个网站所需的用户代理来简化数据收集过程,从而节省宝贵的时间和资源。
Web Unlocker 实时调整以避免检测,以响应阻止机器人使用的不断变化的策略,确保持续访问感兴趣的网站。 该平台的机器学习算法可以快速解决验证码,这是数据收集计划的常见障碍。

Web Unlocker 的定价
Web Unlocker 起价约为每千次请求 2.03 美元 (CPM),提供多种价格选择以满足各种需求。 用户可以享受 7 天的免费试用,让他们开始使用并让他们在提交之前测试 Web Unlocker 的功能。
Web Unlocker 具有支持各种使用模式的适应性,无论消费者是想要现收现付的方法还是需要适合其特定需求的定制计划。 此外,那些选择长期价格计划的人可以节省 32%。
Web Unlocker 与自我管理代理的比较
Web Unlocker 比自我管理的代理提供了许多即时的好处。 为了顺利实施,它提供了一种广泛的集成技术,结合了超级代理和代理管理器功能。 用户可以通过无限数量的并发连接有效地扩展他们的数据收集操作。
Web Unlocker 提供自动解锁、解决验证码并成功管理目标网站上的标记修改。
该平台通过实施自动重试系统并对某些域进行异步调用来保证连续可靠的数据提取。 此外,Online Unlocker 不断增加的 HTTP 标头请求、特定于站点的浏览器 cookie 和模拟小工具的集合使用户能够保持不被发现,同时使他们能够实时获取在线数据。
最后的想法和要记住的重要事情
最后,在使用 Bright Data 进行 Instagram 抓取时,牢记几个要点至关重要。
请注意,根据道德规范,他们的抓取能力仅限于公开可用的数据。
您应该始终遵守 Instagram 的服务条款和隐私政策。 数据采集应该以合乎道德和负责任的方式进行,不得侵犯用户的权利或违反任何法律。
其次,定期更新和微调您的抓取参数,以确保检索数据的准确性和相关性。 Instagram 的平台和算法可能会发生变化,因此您必须相应地改变您的抓取策略。
最后,使用 Bright Data 平台的帮助和资源来优化您的 Instagram 抓取工作的成功。 参与他们的文档、教程和客户服务,以提高您对他们的抓取工具的了解。
通过遵循这些最佳实践并利用 Bright Data 的 Instagram 抓取功能的优势,您可以获得有用的见解,影响明智的决策,并在 Instagram 平台上成功实施数据驱动的计划。





发表评论