为了从网站收集信息用于分析、研究或营销目标,网络抓取是一项关键技术。 幸运的是,有许多工具同时支持无头浏览器和有头浏览器,它们都对网络抓取很有用。
有头浏览器带有图形用户界面 (GUI),而无头浏览器则没有。 这些技术既可以手动也可以自动从网页中提取数据,这使它们非常有用。
在处理大量数据时,无头浏览器是最佳选择。 要自动化您的数据提取过程,您将需要这些工具,它们将为您节省大量时间和工作。
此外,它们还可以帮助您提高数据提取的精度和有效性,这可能会带来更丰硕的整体结果。
这些工具还可以帮助降低手动复制和粘贴数据时出现错误的可能性,因为它们能够以有组织的方式提取数据。
简单地说,如果您从事网络抓取,没有同时支持无头和有头浏览器的工具是不可能工作的。
在本文中,我们将了解用于网络抓取的顶级无头和有头浏览器。
1. 明亮的数据
Bright Data 是一个网络抓取程序,为企业和个人提供数据收集的选择。 与早期的在线抓取系统不同,Bright Data 预装了许多浏览器,但作为无头浏览器运行。
尽管它在后端作为无头浏览器运行,但这表明用户可以通过图形用户界面 (GUI) 与其进行交互,从而使其更易于访问和用户友好。
此功能对于那些不太了解编码或想要更简单的网络抓取方法的人特别有用。 由于 Bright Data 的 headful 浏览器,用户可以通过类似人类的交互快速浏览复杂的网站。
为了让您保持匿名和不被发现,它还提供了 IP 轮换、浏览器指纹识别和用户代理伪造等尖端功能。 通过使用 AI,Scraping Browser 将能够超越最先进的机器人检测保护。
事实上,Scraping Browser 非常复杂,它甚至可以模拟真实用户浏览器的操作,为您提供更成功的结果和精确的数据。
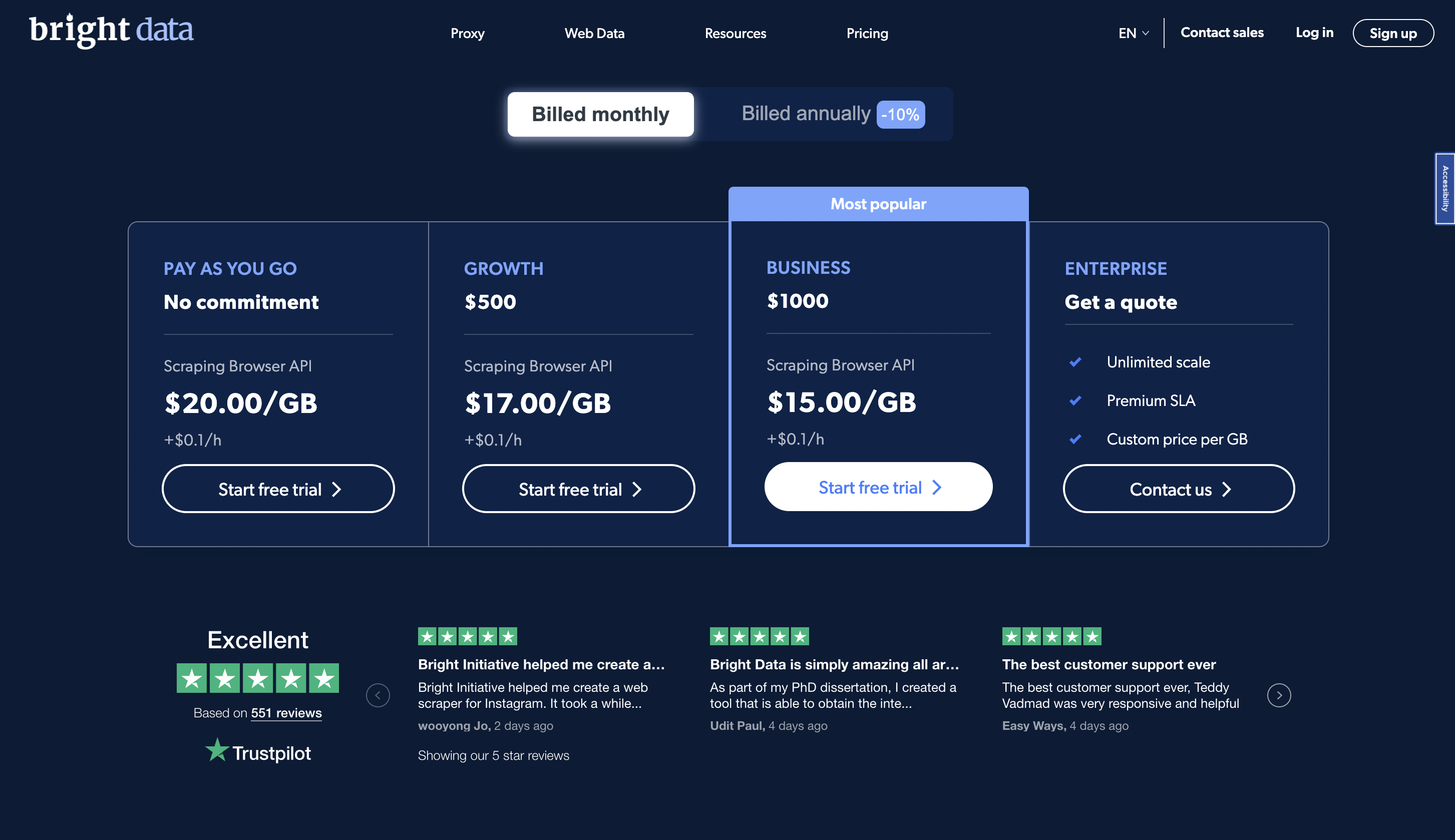
定价
您可以免费试用该平台,在即用即付计划中,高级定价从 20 美元/GB 起。
2. 合特
作为在线抓取工具的供应商,Zyte(以前称为 Scrapinghub)允许公司大规模捕获和分析互联网数据。
Zyte 的在线抓取平台旨在处理最复杂和动态的网站,它包括各种尖端功能,如自动 IP 轮换、浏览器指纹识别和用户代理欺骗,以确保您的抓取操作保持私密和不被注意。
Zyte 的网络抓取平台同时支持无头和有头冲浪模式这一事实是其独特的优势之一。 浏览器在后台以无头模式运行,没有图形用户界面,这提高了它进行大量抓取操作的效率。
但是,浏览器以 headful 模式使用 GUI 运行,当您需要从具有复杂用户界面的网站中提取数据时,这可能是有利的。
此外,由于 Zyte 的平台基于免费和开源的 Scrapy 基础,它可以根据您的特定需求进行调整,并且具有极高的可配置性。 您可以使用 Zyte 快速简单地检索您想要的数据,为您的业务提供竞争优势。
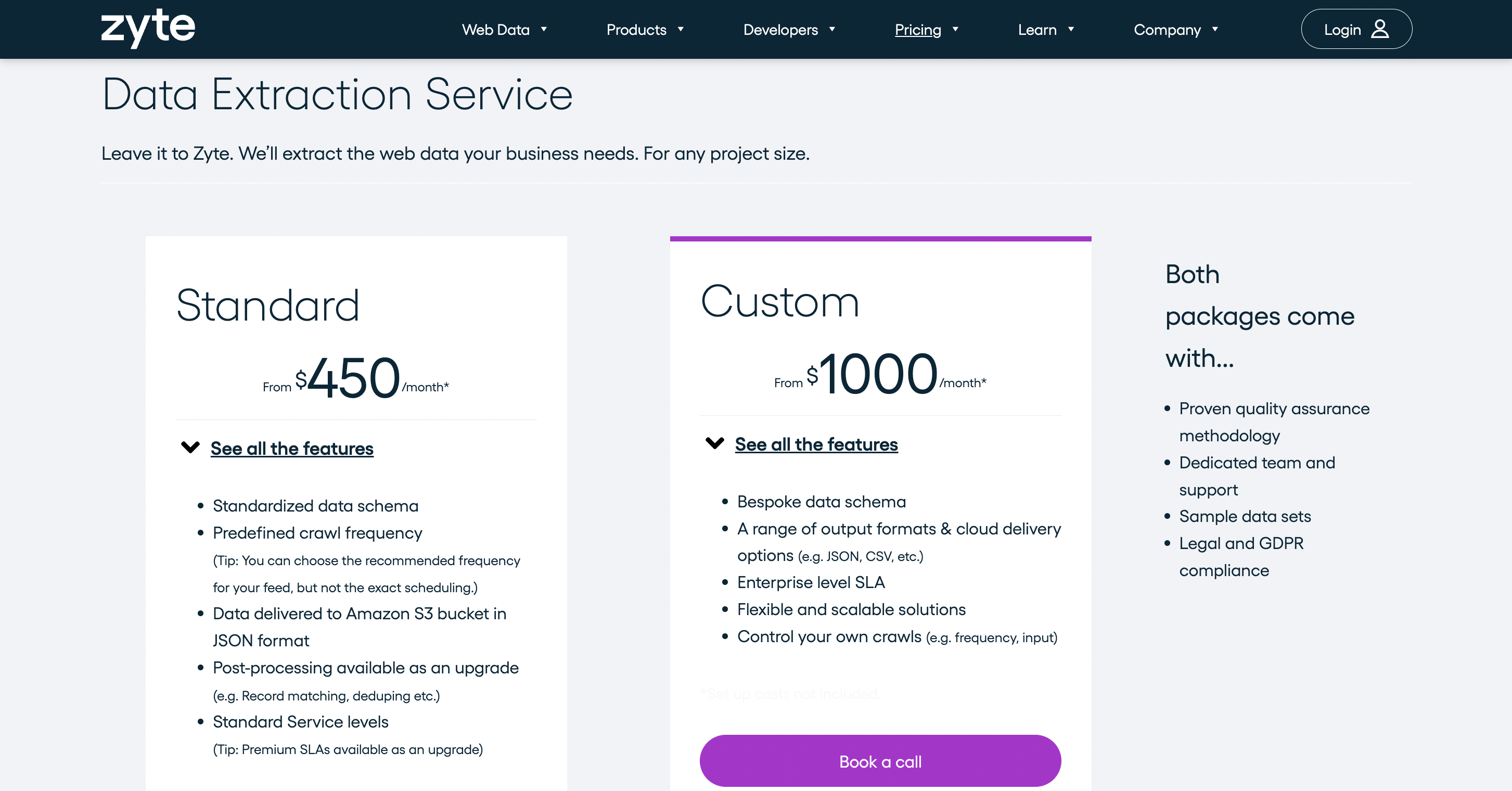
定价
它提供多种定价方案,数据提取服务收费 450 美元/月。
3. 八度分析
使用基于云的网络抓取应用程序 Octoparse,您无需编写任何代码即可从网页收集数据。 得益于用户友好的界面,任何想要抓取文本、照片或视频的人都可以轻松选择它们。
Octoparse 是一个灵活的工具,支持无头浏览和有头浏览,它是任何规模和复杂性的网络抓取项目的最佳选择。 能够抓取动态和交互式网页,这对于许多其他网络抓取程序来说可能很困难,这是它最强大的特性之一。
您可以创建具有多个阶段、条件语句和循环的复杂抓取过程,从而提高抓取的灵活性和可定制性。 Excel、CSV 和 SQL 只是 Octoparse 提供的几种导出格式,这使得在其他程序中使用提取的数据变得简单。
此外,Octoparse 具有一个集成的代理池,可确保匿名抓取并帮助避免 IP 禁令。
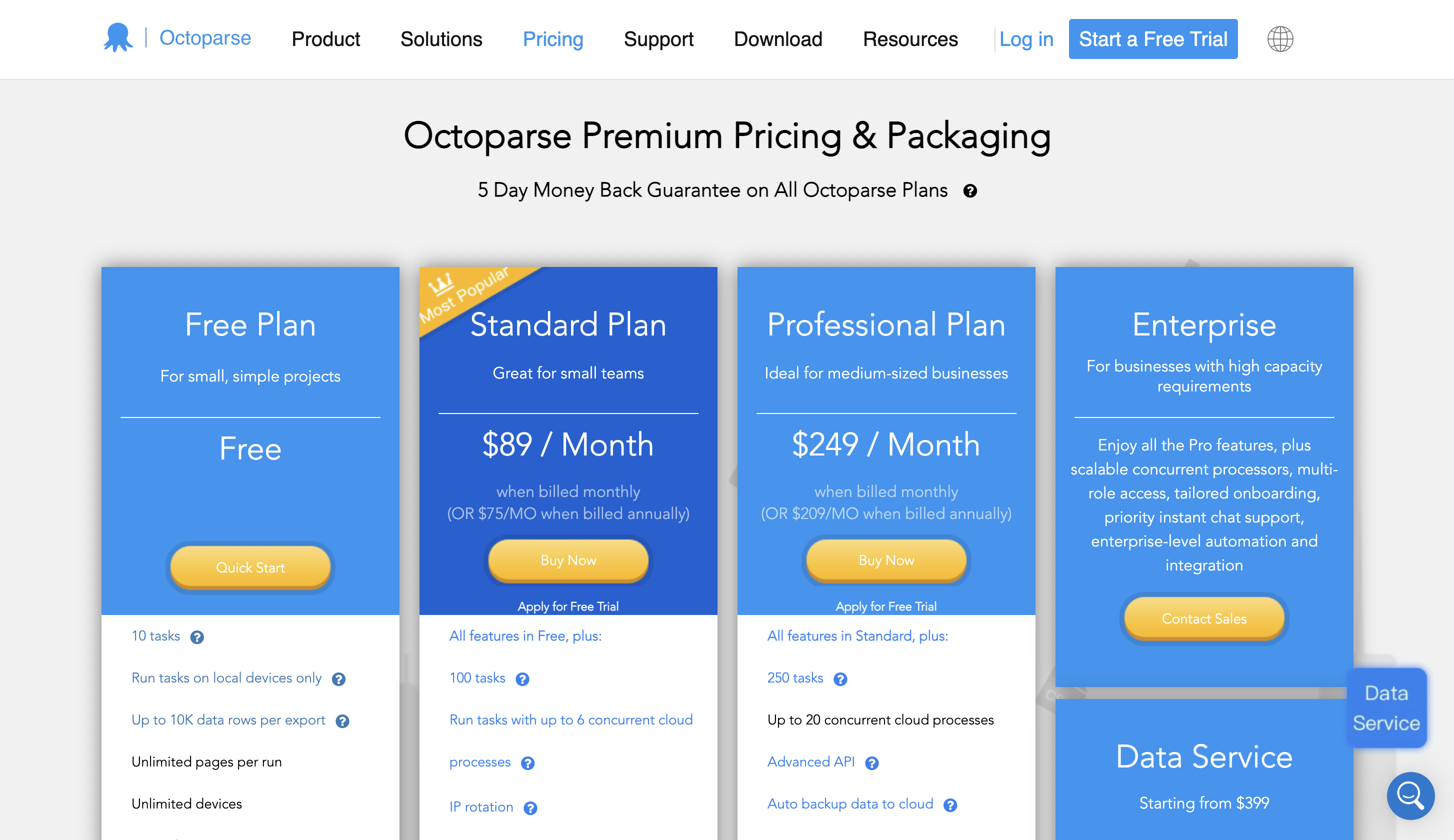
定价
您可以开始免费使用它,高级定价从每月 89 美元起。
4. 阿皮菲
Apify 是一个网络抓取和自动化一体化平台,提供各种强大的功能。 它同时支持无头和有头浏览器,并具有直观的用户界面,即使是非技术用户也可以轻松创建抓取任务。
Apify 处理困难的抓取工作的能力、对多种语言的支持以及扩展以处理大型抓取项目的能力是它的一些最佳功能。
此外,Apify 提供了进入广阔的现成刮刀市场的途径,这些刮刀可以快速定制以满足您的独特需求。
凭借对无头浏览器的支持,Apify 可以导航具有挑战性的用户界面并从动态网站中抓取数据,同时快速有效地从海量数据中提取信息。
Apify 是各种在线抓取应用程序的有用工具,包括潜在客户生成、竞争分析、市场研究和内容聚合。
Apify 通过自动化数据提取过程来提高准确性和效率,同时节省时间和精力。 由于其功能和用户友好的设计,它是技术和非技术用户的强大工具。
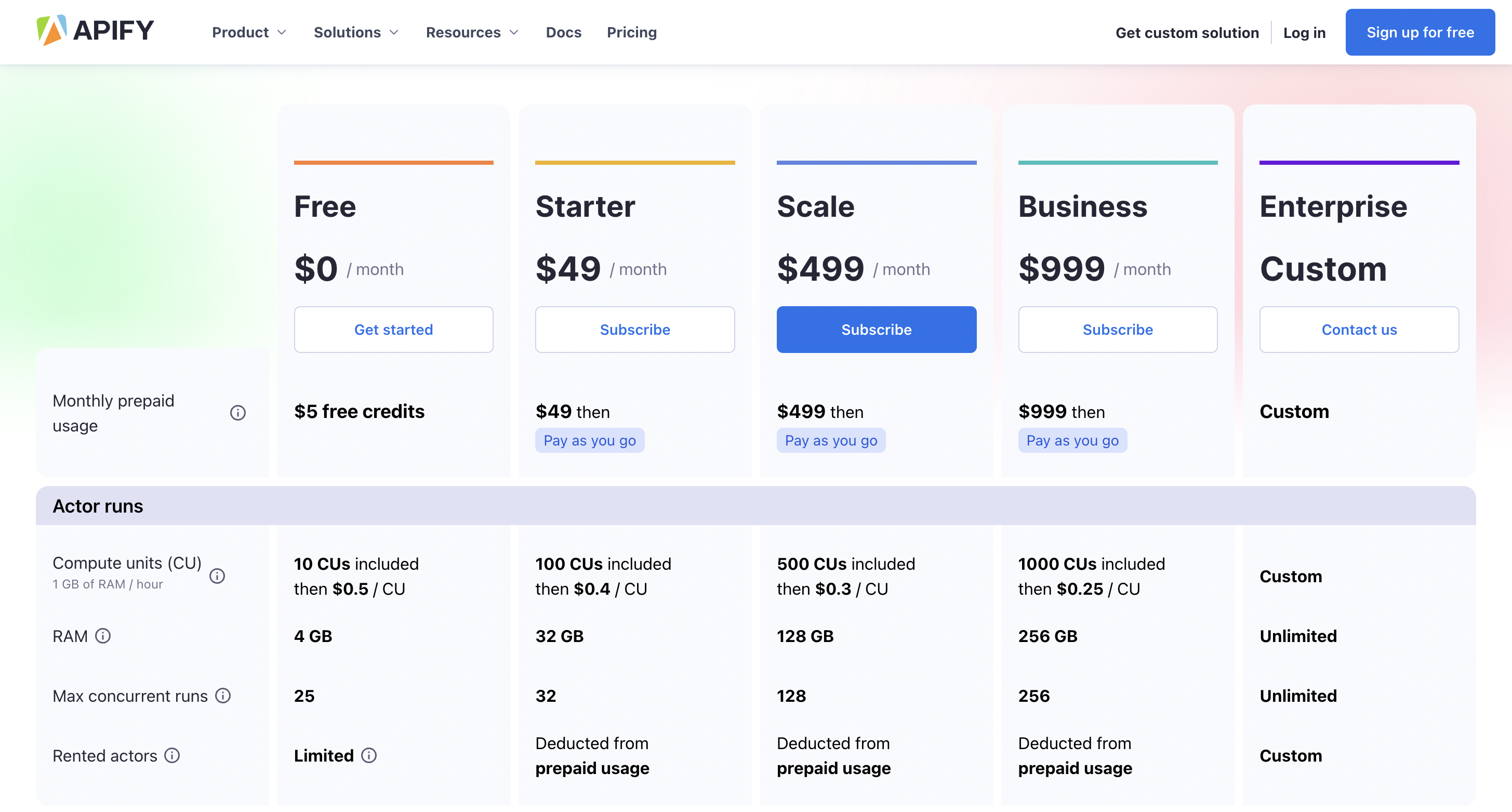
定价
您可以开始免费使用它,高级定价从每月 49 美元起。
5. 蜜蜂
出色的在线抓取应用程序 ScrapingBee 使从网站自动提取数据过程变得简单。
它的功能,例如处理 JavaScript 渲染、CAPTCHA 解析和用户代理轮换的功能,可以绕过网站的反抓取防御。 因此使其成为网络抓取任务的绝佳选择。
用户使用此工具有很大的自由度,因为它适用于无头浏览器和有头浏览器。 需要指出的是,ScrapingBee 默认使用无头浏览器,这非常适合自动检索海量数据。
为了与具有复杂界面的网站互动,用户可能会切换到有头脑的浏览器。 为了确保有效的数据提取,ScrapingBee 还维护了一个定期检查和更改的地理定位代理池。
用户可以通过使用 ScrapingBee 作为无头或有头浏览器来减少网络抓取的时间和精力,同时仍然保证检索数据的正确性和完整性。 它还具有许多有用的功能,如数据格式化、代理轮换和 API 连接,使其成为公司和学生的便捷工具。
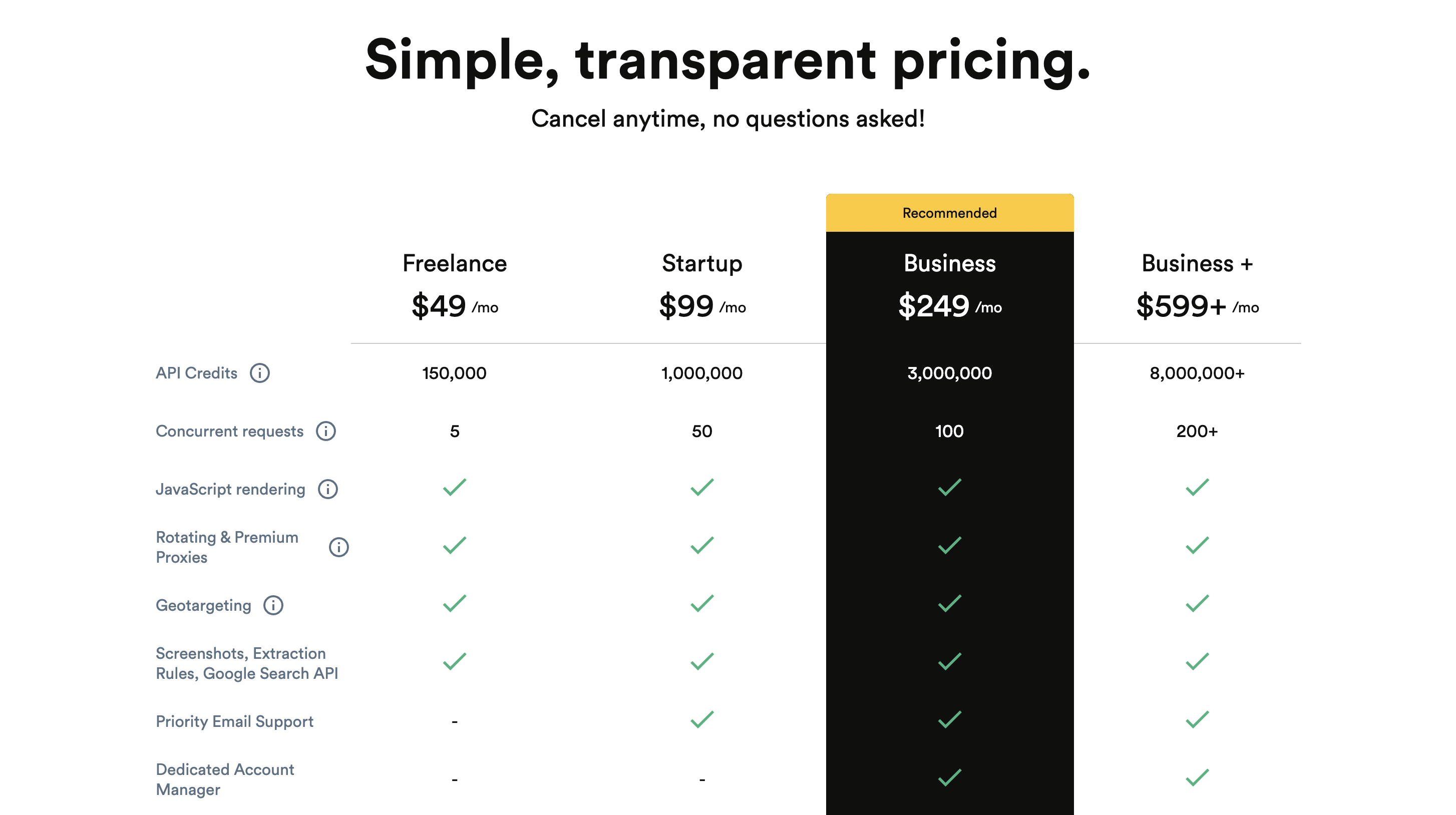
定价
溢价定价从 49 美元/月起。
6. 解析中心
无需技术专业知识,用户可以使用网络抓取应用程序 ParseHub 从网站收集数据。 它最大的特点之一是使用起来非常简单。 用户可以通过单击项目来选择他们想要抓取的数据。
此外,它还具有自动识别分页的能力,使用户可以轻松地从多个页面中抓取信息。 为了从具有基本或复杂用户界面的网站上抓取数据,ParseHub 支持无头和有头浏览器。
此外,它还提供自动 IP 轮换,使网站更难识别和禁止抓取活动。 ParseHub 保证在其广泛的数据格式化功能的帮助下以有组织的方式提取数据,从而使分析和系统集成更加简单。
此外,ParseHub 有一个智能模式,可以自动识别和收集来自类似网站的信息。 ParseHub 可以识别和收集具有相似结构的网站的数据,例如电子商务网站,使用 人工智能 (人工智能)。 此功能通过减少工作量和节省时间来提高准确性和生产率。
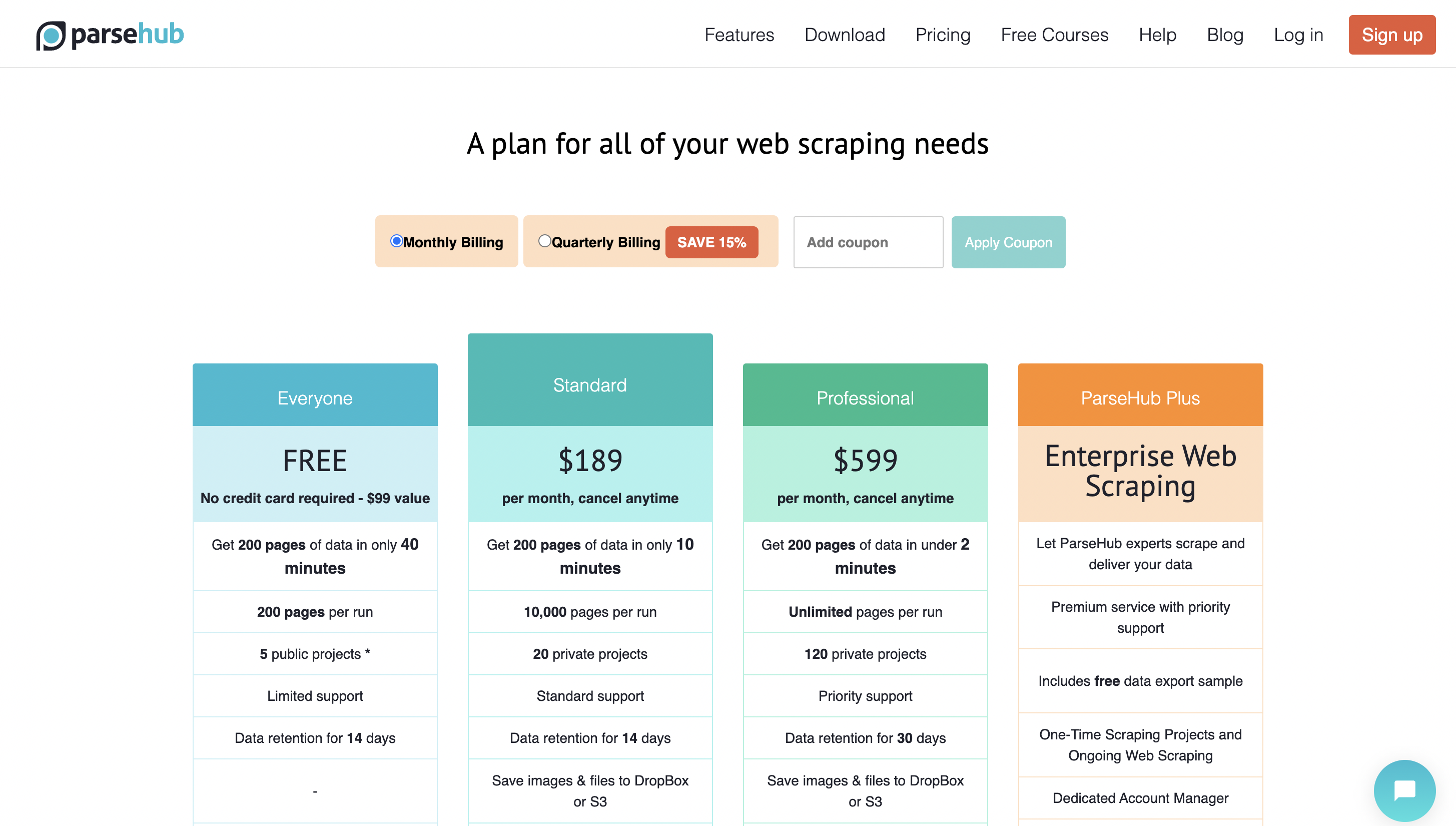
定价
您可以开始免费使用它,高级定价从每月 189 美元起。
7. Web哈维
WebHarvy 是一种强大的在线抓取工具,使组织能够快速、准确、高效地从网站抓取数据。 它用于从许多网站上抓取信息,包括搜索引擎、社交媒体、电子商务网站和目录。
由于其用户友好的界面,无需任何编码经验,用户就可以毫不费力地探索和创建抓取作业。 WebHarvy 的最大特点之一是它能够从由 JavaScript 和 AJAX 提供支持的网页中检索其他抓取工具可能无法访问的数据。
此外,它还提供了一个点击界面,可以轻松地从您希望抓取的网页中选择信息。 WebHarvy 有无头和有头浏览模式。 为了更快、更有效地抓取数据,它可以在无头模式下运行。
在处理需要用户输入的复杂网站时,Headful 模式很有用。 它还可以在多个页面之间导航并填写表单,这在从具有多个页面的网站中提取数据时非常有用。
定价
单用户许可证的高级定价从 129 美元起。

8. 数据流套件
使用强大的在线抓取工具 Dataflow Kit,可以从各种网站收集和分析数据,包括 社交网络 网站、搜索引擎、电子商务网站和新闻网站。 它的最佳功能之一是能够快速有效地从复杂的动态网站收集数据。
它非常适合抓取使用其他方法难以访问的网站,因为它使用起来非常简单。 无头浏览器和有头浏览器都适用于 Dataflow Kit。 提供代理和用户代理轮换、IP 阻塞避免和反机器人检测等高级功能以确保有效抓取。
此外,它还提供了一个用户友好的界面,使客户无需任何编程经验即可创建、计划和管理他们的抓取活动。 对于大型网络抓取应用程序,其有效的抓取引擎是一个极好的解决方案,因为它经过优化可以快速有效地处理数据。
抓取的数据可以简单地导出为各种格式,包括 CSV、JSON 和 XML,允许您以您认为合适的方式分析和利用它。 此外,Dataflow Kit 提供了多种接口选项,包括 API 和 Zapier,以帮助您简化工作流程并自动化数据提取过程。
定价
10 数据流积分的高级定价从 2000 美元起,您可以根据需要使用。
9. 导入
借助基于云的网络抓取工具 Import.io,用户无需任何编程经验即可从网站抓取数据。 使用简单是 Import.io 最吸引人的特点之一; 您所要做的就是指向并单击以查找要抓取的数据。
由于其强大的可视化功能,用户可以实时评估提取的数据。 Import.io 是一种无头浏览器,它模仿网络浏览器并以与人相同的方式连接到网站,但不需要图形用户界面。
这提高了网络抓取效率,并允许用户从需要用户参与才能显示信息的动态网站中抓取数据。 其 AI 驱动的 Extractor 允许用户只需点击几下即可提取数据。 Extractor 还可以识别数据模式并从众多来源中提取可比较的数据。
用户可以自动化他们的抓取工作,并通过其全面的计划功能接收他们想要的数据的频繁更新。 Import.io 通过允许您链接到 Google 表格和 Zapier 等流行工具,使在其他应用程序中使用提取的数据变得简单。
定价
定价未在网站上列出,请与专家讨论。
10. 德西
借助强大的网络抓取工具 Dexi.io,数据提取非常简单。 由于其用户友好的界面和自动化的可能性,您可以使用此工具从网站收集数据而无需任何编码经验。
它最好的特性之一是它能够从许多来源(包括网页、API 和数据库)抓取和组合数据。 得益于 Dexi.io 的并行处理能力,您可以快速有效地抓取海量数据。
Dexi.io 让您可以选择最适合您的抓取需求的替代方案,因为它既可以作为无头浏览器,也可以作为有头浏览器。 虽然有头浏览器选项允许您像使用典型浏览器一样查看网站并与之交互,但无头浏览器选项允许您在不在浏览器中显示页面的情况下抓取数据。
这使得修复任何抓取问题并根据您的喜好调整抓取程序变得简单。 您可以以各种格式(例如 CSV、JSON 和 Excel)快速导出从 Dexi.io 抓取的数据,以进行额外分析或与其他应用程序交互。
此外,它还为您抓取的数据提供可靠且安全的云托管,确保其安全性和可访问性。
定价
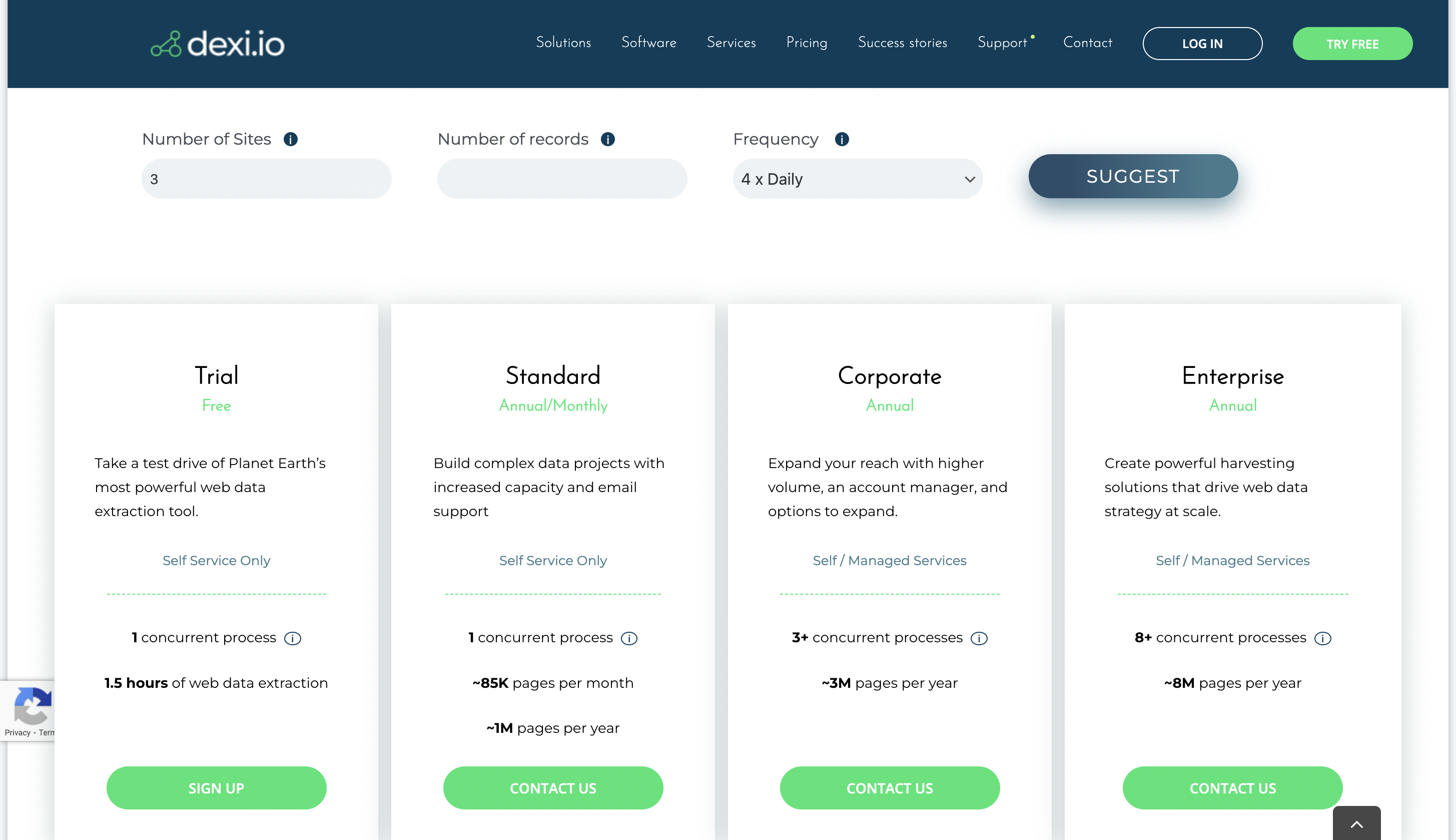
您可以通过其免费试用计划试用该平台,并联系团队了解其定价。
结论
总之,市场上有多种网络抓取解决方案,每种都具有特定的优势和功能。 有许多数据替代方案可供选择,从 Bright Data 和 ScrapingBee 等一体化解决方案到 Apify 和 ParseHub 等更专业的工具。
这些系统通常具有无头浏览、IP 轮换、用户代理欺骗和浏览器指纹识别等功能,以提高在线抓取的有效性、可靠性和保密性。
Web 抓取工具可以让您快速简单地访问大量信息,无论您是试图调查竞争对手的小企业主、寻求数据支持工作的研究人员,还是寻求深入了解消费者行为的数据分析师.
可以减少错误和不一致的可能性,同时您可以通过自动化数据收集过程来节省时间和金钱。





发表评论