Ang paggalaw at imbakan ng data ay lumago sa kahalagahan bilang resulta ng patuloy na pagpapalawak ng industriya ng IT at ang milyun-milyong puntos ng data na ginagawa bawat segundo.
Bilang karagdagan, ang data na ito ay dapat na malinaw at simpleng maunawaan upang suportahan ang tumpak na paggawa ng desisyon.
Upang mapanatili ang pagiging mapagkumpitensya at makamit ang pangmatagalang tagumpay, ang iyong kumpanya ay dapat na mag-imbak at maglipat ng data gamit ang pinakamahuhusay na solusyon na magagamit.
Dahil dito, mas maraming negosyo ang gumagamit ng mga tela ng data. Ang isa sa pinakamagagandang paraan para makatipid ng iyong oras, pera, at mga mapagkukunan ay ang paggamit ng data fabric para iproseso ang data at paganahin ang AI machine learning.
Sa artikulong ito, titingnan natin nang malalim ang Data Fabric, kasama ang mga gamit nito, mga pangunahing bahagi, mga pakinabang, at iba pang mahahalagang detalye.
Kaya, ano ang Data Fabric?
Saan man sila matatagpuan, pamahalaan at bantayan ang iyong data at mga app. Sa kaibuturan nito, ang data fabric ay isang pinagsama-samang arkitektura ng data na ligtas, maraming nalalaman, at madaling ibagay.
Ang isang tela ng data, na pinagsasama ang pinakamahusay sa cloud, core, at edge, ay sa maraming paraan ay isang bagong madiskarteng diskarte sa iyong pagpapatakbo ng storage ng negosyo.
Habang nasa gitnang kontrol, maaari itong maabot kahit saan, kabilang ang mga on-premise, pampubliko at pribadong ulap, pati na rin ang mga edge at IoT device.
Ang mga data silo na kasing laki ng mga skyscraper at magkakaibang, hindi konektadong mga imprastraktura ay isang bagay ng nakaraan. Ang isang data fabric ay batay sa isang komprehensibong koleksyon ng mga tool sa pamamahala ng data na ginagarantiyahan ang pagkakapare-pareho sa iyong mga naka-link na kapaligiran.
Sa pamamagitan ng automation, pinapabilis ang pamamahala sa pag-uubos ng oras, pinapabilis ang pag-develop, pagsubok, at pag-deploy, at pinoprotektahan ang iyong mga asset sa lahat ng oras.
Saanman matatagpuan ang iyong data at app, masusubaybayan mo ang mga gastos sa storage, performance, at kahusayan mula sa iisang platform.
Maaari kang mabilis (at, sa ilang mga kaso, awtomatikong) gumawa ng mga pagbabago sa iyong hybrid na imprastraktura ng cloud kapag mayroon ka nang naaaksyunan na kaalaman tungkol dito, gaya ng pag-aayos ng mga error, pagtugon sa mga isyu sa seguridad at pagsunod, at pag-scale up at down na computing.
Sa madaling sabi, pinapabuti ng Data Fabric ang pag-deploy ng imprastraktura at kahusayan sa pagpapanatili, pinapababa ang mga gastos, at pinatataas ang pagganap.
Bakit kailangan mong gumamit ng Data Fabric?
Ang anumang data-centric na kumpanya ay nangangailangan ng isang komprehensibong diskarte na lumalampas sa mga hadlang tulad ng oras, espasyo, iba't ibang uri ng software, at lokasyon ng data. Ang data ay hindi dapat itago sa likod ng mga firewall o ikalat sa ilang lugar ngunit dapat na available sa mga taong nangangailangan nito.
Upang magtagumpay, nangangailangan ang mga negosyo ng solusyon sa data na patunay sa hinaharap, at isang ligtas, epektibo, pinag-isang kapaligiran. Magagawa ito gamit ang isang data fabric.
Ang mga pangangailangan ng mga modernong negosyo para sa real-time na koneksyon, self-service, automation, at mga pangkalahatang pagbabago ay hindi matutugunan ng tradisyonal na pagsasama ng data.
Bagama't kadalasang hindi isyu ang pangangalap ng data mula sa maraming source, maraming negosyo ang nahihirapang isama, iproseso, i-curate, at i-transform ang data gamit ang data mula sa iba pang source.
Upang magbigay ng malalim na pag-unawa sa mga consumer, kasosyo, at mga produkto, dapat maganap ang kritikal na hakbang na ito sa proseso ng pamamahala ng data. Dahil sa kanilang kakayahang i-upgrade ang kanilang mga system, mas mahusay na pagsilbihan ang mga customer, at gamitin ang cloud computing, ang mga kumpanya ay nakakakuha ng competitive edge bilang resulta.
Nasaan man ang mga user ng organisasyon, ang data fabric ay maaaring isipin bilang isang tela na nakakalat sa buong mundo. Sa network na ito, ang user ay maaaring nasa anumang lokasyon at mayroon pa ring hindi pinaghihigpitan, real-time na access sa data sa anumang iba pang lokasyon.
Mga Pangunahing Bahagi ng Data Fabric
Ang mga pangunahing bahagi na bumubuo sa isang tela ng data ay maaaring piliin at ipunin sa iba't ibang paraan. Ang tela ng data ay maaaring ipatupad sa iba't ibang paraan. Tingnan natin ang mga pangunahing elemento ng tela ng data.
- Pinahusay na Catalog ng Data
- Layer ng Pagtitiyaga
- Kaalaman Graph
- Engine ng Mga Insight at Rekomendasyon
- Paghahanda ng Data at Layer ng Paghahatid ng Data
- Orkestrasyon at Data Ops
Maaari mong tingnan ang mga pangunahing haligi ng arkitektura ng Data Fabric ayon sa Gartner.
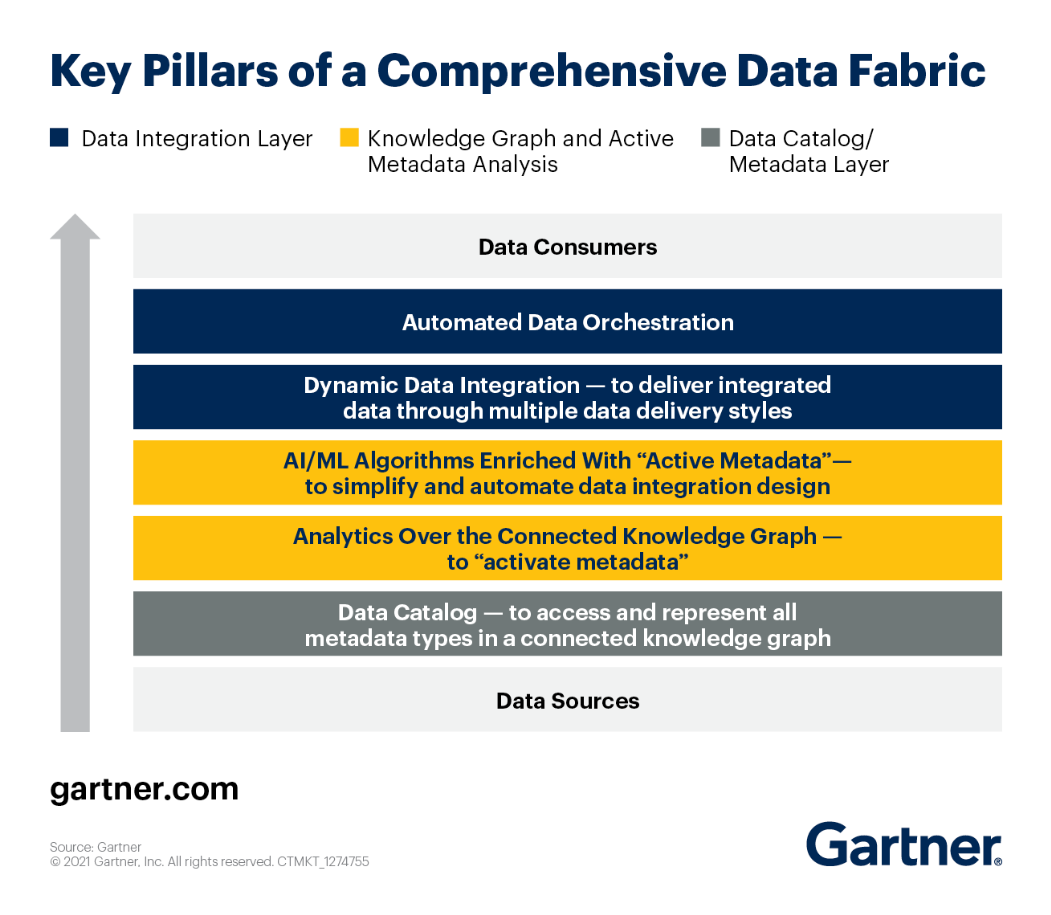
Tingnan natin ang bawat isa sa kanila nang maigi.
- Pinahusay na Catalog ng Data – nagbibigay ng access sa mga user sa lahat ng uri ng metadata sa pamamagitan ng isang malakas na graph ng kaalaman. Bukod pa rito, ito ay bumubuo ng mga natatanging ugnayan sa pagitan ng umiiral na impormasyon at biswal na ipinapakita ito sa isang naiintindihan na paraan. Sa pamamagitan ng paggamit machine learning upang i-link ang mga asset ng data sa terminolohiya ng organisasyon, ang mga pinahusay na katalogo ng data ay gumagawa ng semantic layer ng negosyo para sa fabric ng data.
- Layer ng Pagtitiyaga – Depende sa kaso ng paggamit, maaaring gamitin ang iba't ibang modelong relational at non-relational para dynamic na mag-imbak ng data.
- Aktibong Metadata – isang natatanging bahagi ng isang data fabric. nagbibigay sa data fabric ng kakayahang mangalap, magbahagi, at magsuri ng maraming uri ng metadata. Sa kaibahan sa passive metadata, sinusubaybayan ng aktibong metadata ang patuloy na paggamit ng data ng mga system at tao (base sa disenyo at run-time na metadata).
- Kaalaman Graph – Isa pang pangunahing yunit para sa mga tela ng data. Gumagamit sila ng mga karaniwang ID, naaangkop na mga schema, atbp. upang magpakita ng naka-link na kapaligiran ng data. Ang mga graph ng kaalaman ay ginagawang mahahanap ang tela ng data at nakakatulong sa pag-unawa nito.
- Engine ng Mga Insight at Rekomendasyon – bubuo ng maaasahan at malakas na pipeline ng data para sa parehong operational at analytical na mga kaso ng paggamit.
- Paghahanda ng Data at Layer ng Paghahatid ng Data – Maaaring makuha ang data mula sa anumang pinagmulan at ipadala sa anumang target gamit ang anumang mekanismo, kabilang ang ETL (bulk), pagmemensahe, CDC, virtualization, at API.
- Orkestrasyon at Data Ops – Gumagamit ang bahaging ito ng data para i-coordinate ang lahat ng gawain sa bawat yugto ng end-to-end na daloy ng trabaho. Binibigyang-daan ka nitong pumili kung kailan at gaano kadalas tatakbo ang mga pipeline pati na rin kung paano pamahalaan ang data na ginagawa ng mga pipeline na iyon.
Mga Benepisyo
Ang malusog na data sa isang nakabahaging konteksto ay naa-access, na-load, isinama, at ibinabahagi sa isang fabric ng data. Sa paggawa nito, mapapabilis ng mga negosyo ang digital transition at i-maximize ang halaga ng kanilang data.
Sa ibaba ay nakabalangkas ang mga pangunahing bentahe ng data fabric model.
Kahusayan:
Ang tela ng data ay maaaring mag-compile ng mga resulta mula sa mga naunang query, na nagbibigay-daan sa system na i-scan ang pinagsama-samang talahanayan sa halip na ang raw data sa backend.
Dahil sa mas mabilis na mga oras ng pagtugon ng mga indibidwal na kahilingan, ang pagbibigay-daan sa mga kahilingan na ma-access ang mas maliliit na dataset sa halip na i-scan ang buong hilaw na data ng tindahan ay malulutas din ang isyu ng ilang kasabay na kahilingan.
Ang mga negosyo ay maaaring tumugon nang mabilis sa pagpindot sa mga katanungan dahil sa kakayahan ng data fabric na makabuluhang bawasan ang mga oras ng pagtugon sa query.
Smart integration
Upang isama ang data sa magkakaibang uri ng data at endpoint, ginagamit ng mga fabric ng data ang mga semantic knowledge graph, pamamahala ng metadata, at machine learning.
Nakakatulong ito sa mga pangkat ng pamamahala ng data na pagsama-samahin ang mga nauugnay na dataset at isama ang mga bagong mapagkukunan ng data sa ecosystem ng data ng kumpanya.
Ang feature na ito ay nag-o-automate ng mga bahagi ng data task management, na nagreresulta sa productivity savings na nakasaad sa itaas, ngunit nakakatulong din ito sa pag-break down ng data system silo, pagsentro sa mga pamamaraan ng pamamahala ng data, at pagpapahusay ng pangkalahatang kalidad ng data.
Mas epektibong seguridad ng data
Hindi rin ito nagpapahiwatig ng pagsasakripisyo sa seguridad ng data at mga proteksyon sa privacy para sa kapakanan ng pagpapalawak ng pag-access ng data.
Sa katunayan, kailangan nito ang paghihigpit ng mga guardrail ng access control at ang pagpapatupad ng higit pang mga hakbang sa pamamahala ng data upang matiyak na ang ilang partikular na tungkulin ay ang tanging may access sa isang ibinigay na hanay ng data.
Bukod pa rito, pinapagana ng mga arkitektura ng tela ng data ang teknikal at mga security team para ipatupad ang data masking at pag-encrypt sa paligid ng kumpidensyal at sensitibong impormasyon, na binabawasan ang posibilidad ng pagbabahagi ng data at pag-hack ng system.
Demokratisasyon ng datos
Ang mga self-service na application ay pinapadali ng mga disenyo ng tela ng data, na nagpapalawak sa abot ng pag-access ng data nang higit pa sa higit pang mga teknikal na tauhan tulad ng mga inhinyero ng data, mga developer, at mga pangkat ng data analytics.
Sa pamamagitan ng pagpayag sa mga user ng negosyo na gumawa ng mas mabilis na mga pagpipilian sa negosyo at sa pamamagitan ng pagpapalaya sa mga teknikal na user na unahin ang mga aktibidad na pinakamahusay na gumagamit ng kanilang mga hanay ng kasanayan, ang pag-aalis ng mga bottleneck ng data ay humahantong sa pagtaas ng produktibidad.
Paggamit ng mga kaso
Ang arkitektura ng tela ng data ay inilaan upang mag-alok ng isang pangkalahatang istraktura para sa paghawak ng lahat ng anyo ng nakaimbak na impormasyon upang magamit ang mga ito kapag kinakailangan.
Ang mga uri ng data na ito ay maaaring gamitin para sa anumang bagay mula sa isang hula sa pagbebenta hanggang sa isang ulat sa estado ng IT infrastructure o mga endpoint ng user ng isang organisasyon.
Ang mga kaso ng paggamit ng arkitektura ng tela ng data ay magkapareho sa mga kaso ng paggamit para sa anumang iba pang uri ng data sa isang negosyo, kabilang ang mga benta, marketing, IT, cybersecurity, at higit pa.
Gayunpaman, ang data sa isang organisasyon ay madalas na organisado, semi-structured, o hindi nakabalangkas sa halos lahat ng mga kaso ng paggamit. Ang isang relational database ay maaaring mag-imbak ng structured data at agad na magamit, tulad ng mga database record.
Ang data na hindi pa nalilinis o nakategorya ay tinutukoy bilang unstructured data at kailangang ihanda para sa paggamit kapag kinakailangan.
Kasama sa ilang mga anyo ng hindi nakabalangkas na data na maaaring makuha at maiimbak ng maraming kumpanya para magamit sa hinaharap machine learning, analytics, data ng sensor, cloud computing, at productivity app.
Sa semi-structured na data, na kinabibilangan ng data ng isang kinikilalang uri na naka-save na may unstructured data (tulad ng mga zip file, web page, at email), parehong aspeto ay naroroon.
Maraming posibleng mga kaso ng paggamit batay sa kapasidad ng data fabric upang tulungan ang mga kumpanya sa pag-access at paggamit ng kanilang data nang mas mabilis at epektibong makikita sa pamamagitan ng pagsasaliksik sa paggamit nito.
Kasama sa mga karaniwang halimbawa ang:
- Pagtuklas ng pandaraya
- Pagsusuri ng IoT
- Logistics ng supply chain
- Real-time na data analytics
- Katalinuhan ng customer
- Pagtaas ng kahusayan sa pagpapatakbo
- Pagsusuri ng preventative maintenance
- Bukod pa rito, ang mga modelo ng panganib na bumalik sa trabaho
- Pag-secure ng mga transaksyon gamit ang mga credit card
- Paghula ng Churn, pagtuklas ng panloloko, at pagmamarka ng kredito
Konklusyon
Bilang konklusyon, dapat na unti-unting maghiwa-hiwalay ang mga data silo habang tumataas ang mga antas ng paggamit ng data para magbigay ng puwang para sa mga konektadong kumpanya.
Ang pag-deploy ng mga tela ng data ay kumakatawan sa isang makabuluhang pag-unlad sa landas na ito, na nagraranggo sa mga pinaka-groundbreaking na pagtuklas mula noong pagbuo ng mga relational database noong 1970s.
Ito ay dahil ang data fabric ay higit pa sa isang teknolohiya o isang solong item.
Ang data at pagpapatakbo ng negosyo ay masalimuot na pinagsama sa pamamagitan ng disenyo ng arkitektura, isang sistematikong pamamaraan, at isang pagbabago sa kaisipan.
Binabawasan ng Data Fabric ang mga gastos, pinapalakas ang pagganap, at pinapadali ang mas epektibong pag-deploy at pagpapanatili ng imprastraktura. Maaaring ito ang pangunahing bahagi sa pagtiyak na ang bawat proseso, aplikasyon, at desisyon ng negosyo ay batay sa data.





Mag-iwan ng Sagot