Talaan ng nilalaman[Tago][Ipakita]
Ang mga kumpanya ay kumukuha ng mas maraming data kaysa dati habang sila ay lalong umaasa dito upang ipaalam ang mahahalagang desisyon sa negosyo, pagandahin ang mga alok ng produkto, at magbigay ng mas mahusay na serbisyo sa customer.
Sa dami ng data na nalilikha sa isang exponential rate, nag-aalok ang cloud ng ilang mga pakinabang para sa pagproseso at analytics ng data, kabilang ang scalability, dependability, at availability.
Sa cloud ecosystem, mayroon ding ilang mga tool at teknolohiya para sa pagproseso ng data at analytics. Ang dalawang uri ng malalaking istruktura ng imbakan ng data na pinakamadalas na ginagamit ay mga bodega ng data at lawa ng data.
Bagama't hindi gaanong kaakit-akit ang paggamit ng data lake dahil hindi mo maaaring i-query ang modelo at data habang ito ay may kaugnayan pa, ang paggamit ng data warehouse para sa streaming data storage ay aksaya.

Wanong uri ng cloud architecture ang pipiliin natin?
Dapat ba nating isaalang-alang ang mga mas bagong konsepto para sa data lakehouse, o dapat ba tayong makuntento sa mga hadlang ng warehouse o sa mga paghihigpit ng lawa?
Ang isang nobelang arkitektura ng imbakan ng data na tinatawag na "data lakehouse" ay pinagsasama ang kakayahang umangkop ng mga lawa ng data sa pamamahala ng data ng mga warehouse ng data.
Ang pag-unawa sa iba't ibang paraan ng pag-iimbak ng malalaking data ay mahalaga para sa pagbuo ng isang maaasahang pipeline ng pag-iimbak ng data para sa business intelligence (BI), data analytics, at machine learning (ML) na mga workload, depende sa mga hinihingi ng iyong kumpanya.
Sa post na ito, titingnan nating mabuti ang Data Warehouse, Data Lake, at Data Lakehouse, na may mga benepisyo, limitasyon pati na rin ang mga kalamangan at kahinaan ng mga ito. Magsimula tayo.
Ano ang Data Warehouse?
Ang data warehouse ay isang sentralisadong imbakan ng data na ginagamit ng isang organisasyon upang maghawak ng napakalaking dami ng data mula sa maraming mapagkukunan. Ang isang warehouse ng data ay gumaganap bilang nag-iisang pinagmumulan ng "katotohanan ng data" ng isang organisasyon at ito ay mahalaga sa pag-uulat at analytics ng negosyo.
Karaniwan, pinagsasama ng mga warehouse ng data ang mga hanay ng relational na data mula sa ilang pinagmumulan, gaya ng data ng aplikasyon, negosyo, at transaksyonal, upang mag-imbak ng makasaysayang data. Bago i-load sa warehousing system, ang data ay binago at nililinis sa mga data warehouse upang magamit ito bilang isang pinagmumulan ng katotohanan ng data.
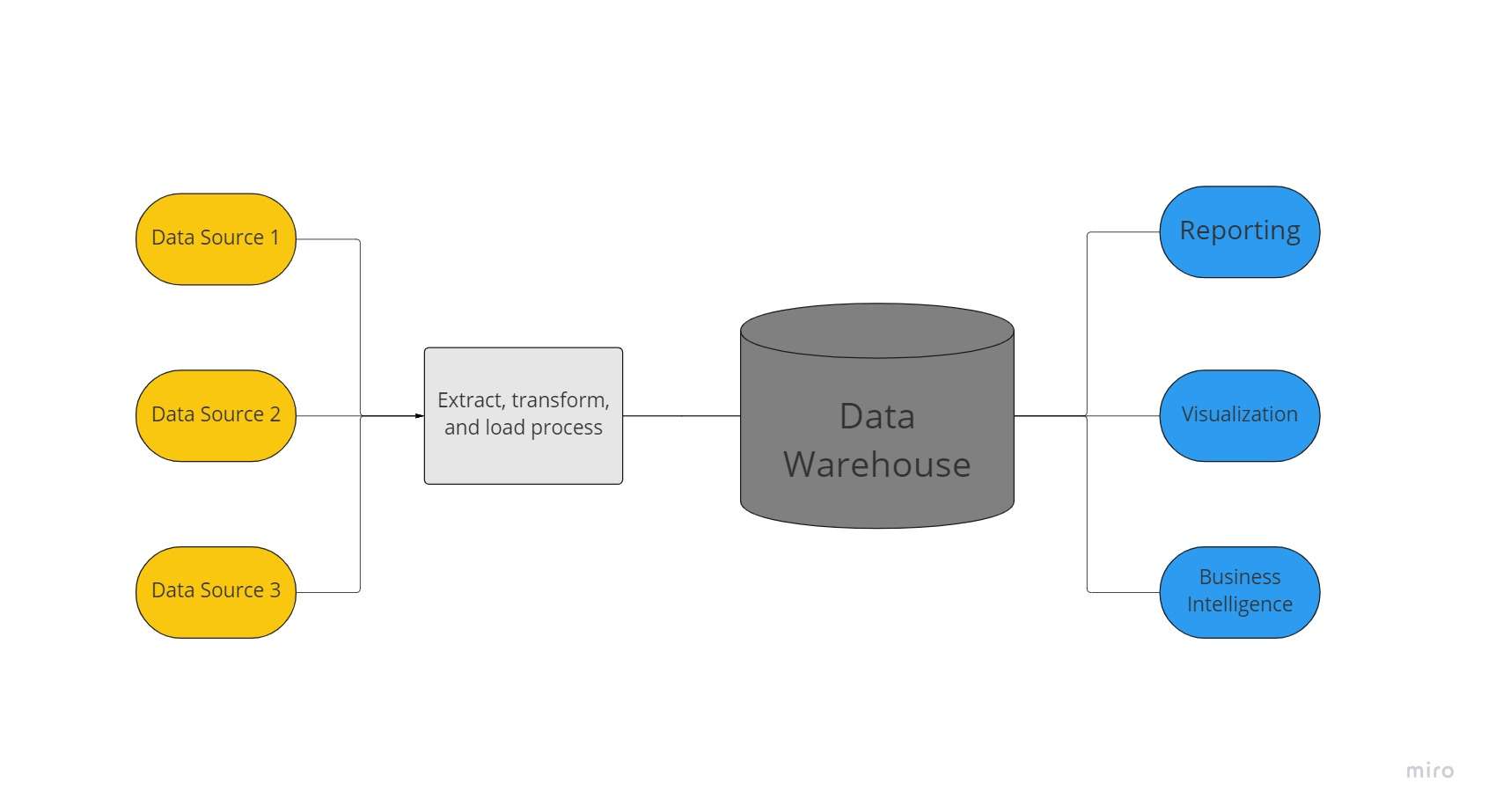
Dahil sa kanilang kapasidad na mabilis na mag-alok ng mga insight sa negosyo mula sa lahat ng bahagi ng kumpanya, namumuhunan ang mga negosyo sa mga data warehouse. Sa paggamit ng mga tool ng BI, mga kliyente ng SQL, at iba pang hindi gaanong sopistikadong (ibig sabihin, hindi-data science) na mga solusyon sa analytics, analyst ng negosyo, mga inhinyero ng data, at mga gumagawa ng desisyon ay maaaring mag-access ng data mula sa mga warehouse ng data.
Mahal ang pagpapanatili ng isang warehouse na may patuloy na pagtaas ng dami ng data, at ang isang data warehouse ay hindi maaaring humawak ng hilaw o hindi nakabalangkas na data. Bukod pa rito, hindi ito ang perpektong opsyon para sa mga sopistikadong diskarte sa pagsusuri ng data tulad ng machine learning o predictive modeling.
Ang isang data warehouse, samakatuwid, ay nagbibigay ng mas mabilis na mga tugon sa query at data na may mas mataas na kalidad. Ang Google Big Query, Amazon Redshift, Azure SQL Data warehouse, at Snowflake ay mga serbisyo sa cloud na available para sa mga data warehouse.
Mga Benepisyo ng Data Warehouse
- Pagtaas ng kahusayan at bilis ng business intelligence at data analytics workload: Ang mga data warehouse ay nagpapaikli sa oras na kailangan para sa paghahanda at pagsusuri ng data. Madali silang makakapag-link sa data analytics at business intelligence tool dahil maaasahan at pare-pareho ang data mula sa data warehouse. Bukod pa rito, ang mga data warehouse ay nakakatipid sa oras na kailangan para sa pangongolekta ng data at nagbibigay sa mga team ng kakayahang gumamit ng data para sa mga ulat, dashboard, at iba pang mga kinakailangan sa analytics.
- Pagtaas ng pare-pareho, kalidad, at standardisasyon ng data: Kinokolekta ng mga organisasyon ang data mula sa iba't ibang mapagkukunan, kabilang ang data ng user, benta, at transaksyon. Mapagkakatiwalaan ng kumpanya ang data para sa mga kinakailangan sa negosyo dahil ang data warehousing ay nagtitipon ng data ng kumpanya sa isang pare-pareho, standardized na format na maaaring kumilos bilang isang solong mapagkukunan ng katotohanan ng data.
- Pagpapahusay sa paggawa ng desisyon sa pangkalahatan: Pinapadali ng data warehousing ang mas mahusay na paggawa ng desisyon sa pamamagitan ng pag-aalok ng isang sentralisadong tindahan para sa parehong kamakailan at lumang data. Sa pamamagitan ng pagpoproseso ng data sa mga warehouse ng data para sa mga tumpak na insight, masusuri ng mga gumagawa ng desisyon ang mga panganib, mauunawaan ang mga gusto ng kliyente, at mapahusay ang mga produkto at serbisyo.
- Nagbibigay ng mas mahusay na katalinuhan sa negosyo: Tinutulay ng data warehousing ang agwat sa pagitan ng napakalaking raw data, na madalas na kinokolekta bilang isang bagay, at ang na-curate na data na nagbibigay ng mga insight. Nagsisilbi silang pundasyon para sa pag-iimbak ng data ng isang organisasyon, na nagbibigay-daan dito na sagutin ang mga kumplikadong tanong tungkol sa data nito at gamitin ang mga tugon upang makagawa ng mga mapagtatanggol na desisyon sa negosyo.
Mga Limitasyon ng Data Warehouse
- Kakulangan ng flexibility ng data: Bagama't mahusay ang mga data warehouse sa paghawak ng structured data, maaaring maging mahirap para sa kanila ang mga semi-structured at unstructured na format ng data tulad ng log analytics, streaming, at data ng social media. Ginagawa nitong nagrerekomenda ng mga data warehouse para sa mga kaso ng paggamit na kinasasangkutan ng machine learning at artificial intelligence mahirap.
- Mahal ang pag-install at pagpapanatili: Maaaring magastos ang pag-install at pagpapanatili ng mga data warehouse. Higit pa rito, ang data warehouse ay madalas na hindi static; tumatanda ito at nangangailangan ng madalas na pangangalaga, na mahal.
Mga kalamangan
- Ang data ay madaling hanapin, kunin, at i-query.
- Hangga't ang data ay malinis na, ang paghahanda ng data ng SQL ay simple.
Kahinaan
- Napipilitan kang gumamit lamang ng isang analytics vendor.
- Ang pagsusuri at pag-iimbak ng hindi nakabalangkas o dumadaloy na data ay medyo magastos.
Ano ang Data Lake?
Ang bawat uri ng data ay ipinangako at ginawang posible ng mga lawa ng data. Ito ay kapaki-pakinabang na magkaroon ng data sa paraang naa-access sa gitnang lokasyon at magagamit para sa pagbabasa.
Ang data lake ay isang sentralisado, lubhang madaling ibagay na espasyo sa imbakan kung saan ang napakalaking dami ng organisado at hindi nakabalangkas na data ay pinananatili sa kanilang hindi pinroseso, hindi binago, at hindi naka-format na mga anyo.
Ang isang data lake ay gumagamit ng isang patag na arkitektura at mga bagay na nakaimbak sa hindi pa naprosesong estado nito upang mag-imbak ng data, kumpara sa mga warehouse ng data, na nagse-save ng relational data na dati nang "nalinis."
Ang mga lawa ng data, kumpara sa mga warehouse ng data, na nahihirapan sa paghawak ng data sa format na ito, ay madaling ibagay, maaasahan, at abot-kaya at nagbibigay-daan sa mga negosyo na makakuha ng pinahusay na insight mula sa hindi nakaayos na data.
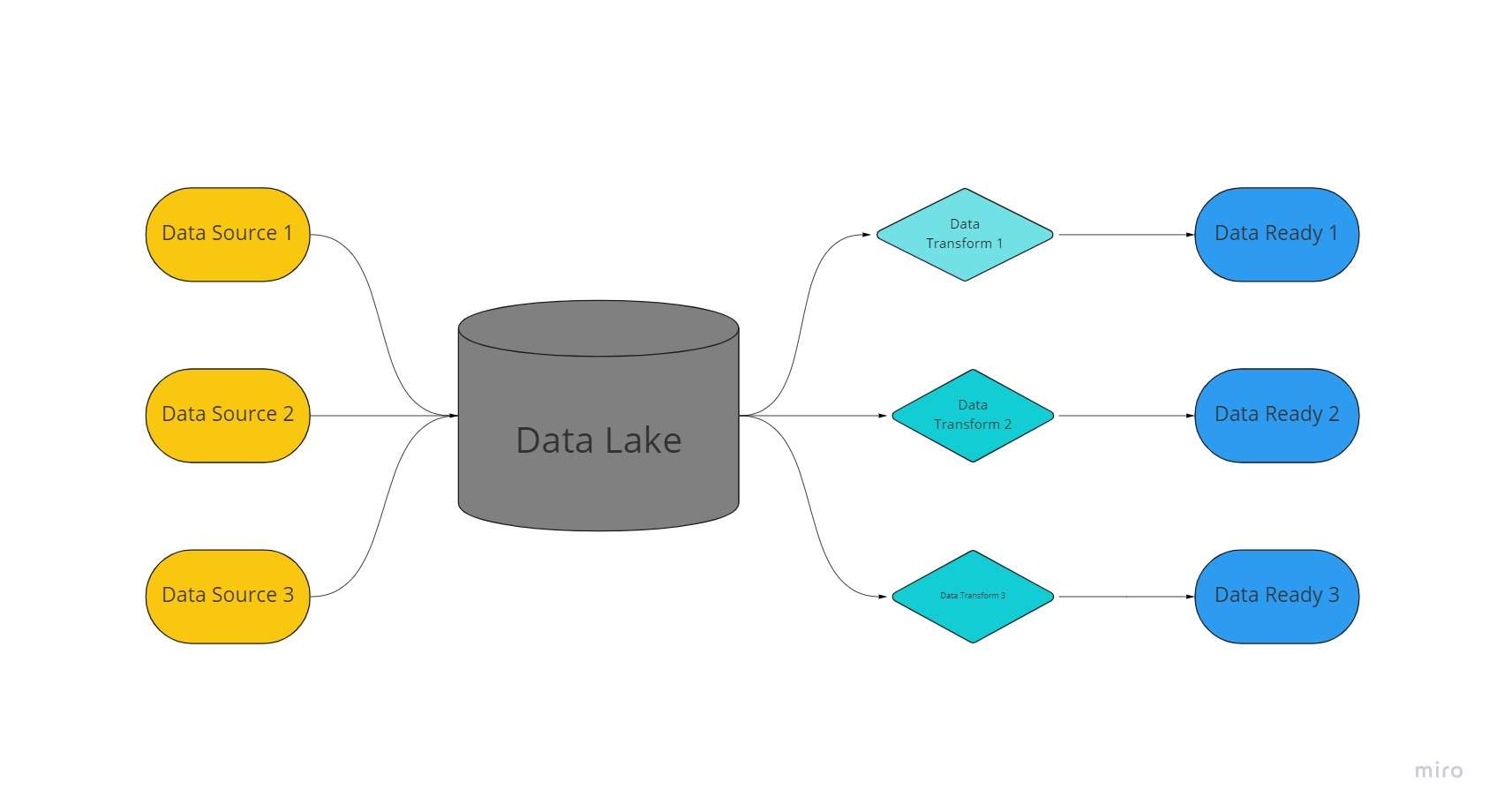
Sa mga lawa ng data, kinukuha, nilo-load, at binago (ELT) ang data para sa mga layuning pang-analytical sa halip na magkaroon ng schema o data na itinatag sa oras ng pangangalap ng data.
Paggamit ng mga teknolohiya para sa maraming uri ng data mula sa mga IoT device, social media, at streaming ng data, ang mga data lakes ay nagbibigay-daan sa machine learning at predictive analytics.
Bilang karagdagan, ang isang data scientist na maaaring magproseso ng raw data ay maaaring gumamit ng data lake. Ang data warehouse, sa kabilang banda, ay mas madaling gamitin ng mga negosyo. Ito ay perpekto para sa profile ng gumagamit, mahuhulain analytics, machine learning, at iba pang gawain.
Bagama't tinutugunan ng mga data lakes ang ilang isyu sa mga data warehouse, mahina ang kalidad ng data nito at hindi sapat ang bilis ng query nila. Bilang karagdagan, nangangailangan ng mga karagdagang tool para sa mga gumagamit ng negosyo upang magsagawa ng mga query sa SQL. Ang isang data lake na hindi maganda ang pagkakaayos ay maaaring makaranas ng isyu sa pag-stagnation ng data.
Mga Pakinabang ng Data Lake
- Suporta para sa malawak na hanay ng machine learning at data science application cases Mas simple ang paggamit ng ibang machine at deep learning algorithm para pangasiwaan ang data sa mga data lakes dahil ang data ay pinananatiling bukas at hilaw na paraan.
- Ang versatility ng data lakes, na nagbibigay-daan sa iyong mag-imbak ng data sa anumang format o media nang walang kinakailangan para sa isang preset na schema, ay isang malaking kalamangan. Maaaring suportahan ang mga kaso ng paggamit ng data sa hinaharap, at mas maraming data ang maaaring masuri kung maiiwan ang data sa orihinal nitong estado.
- Upang maiwasan ang pag-imbak ng parehong uri ng data sa iba't ibang konteksto, ang mga lawa ng data ay maaaring maglaman ng parehong structured at unstructured na data. Para sa pag-iimbak ng iba't ibang uri ng data ng organisasyon, nag-aalok sila ng isang lokasyon.
- Kung ikukumpara sa mga tradisyunal na warehouse ng data, mas mura ang mga data lakes dahil itinayo ang mga ito para manatili sa murang commodity hardware, gaya ng object storage, na kadalasang nakatutok sa mas mababang halaga sa bawat gigabyte na nakaimbak.
Mga Limitasyon ng Data Lake
- Mahina ang marka ng data analytics at business intelligence use cases: Maaaring maging hindi organisado ang mga data lakes kung hindi maayos na pinapanatili ang mga ito, na nagpapahirap sa pag-link sa mga ito sa business intelligence at mga tool sa analytics. Bukod pa rito, kapag kinakailangan para sa pag-uulat at mga kaso ng paggamit ng analytics, kakulangan ng pare-pareho mga kaayusan ng data at ACID (atomicity, consistency, isolation, and durability) transactional support ay maaaring humantong sa suboptimal na pagganap ng query.
- Dahil sa hindi pagkakapare-pareho ng data lakes, imposibleng ipatupad ang pagiging maaasahan at seguridad ng data, na nagreresulta sa kakulangan ng pareho. Maaaring mahirap bumuo ng naaangkop na mga pamantayan sa seguridad ng data at pamamahala upang matugunan ang mga sensitibong uri ng data, dahil ang mga lawa ng data ay maaaring humawak ng anumang form ng data.
Mga kalamangan
- Mga solusyon na abot-kaya para sa lahat ng uri ng data.
- May kakayahang pangasiwaan ang data na parehong organisado at semi-structured.
- Tamang-tama para sa kumplikadong pagproseso ng data at streaming.
Kahinaan
- Kailangan ng isang sopistikadong pipeline na itatayo.
- Bigyan ang data ng ilang oras upang maging queryable.
- Kailangan ng oras upang magarantiya ang pagiging maaasahan at kalidad ng data.
Ano ang Data Lakehouse?
Pinagsasama-sama ng isang nobelang big-data storage architecture na tinatawag na "data lakehouse" ang pinakamagagandang aspeto ng data lakes at data warehouse. Ang lahat ng iyong data, structured man, semi-structured, o unstructured, ay maaaring iimbak sa isang lokasyon na may pinakamahusay na machine learning, business intelligence, at mga kakayahan sa streaming na posible salamat sa isang data lakehouse.
Ang lahat ng uri ng data lake ay kadalasang ang panimulang punto para sa mga data lakehouse; pagkatapos nito, ang data ay binago sa format na Delta Lake (isang open-source na layer ng storage na nagdudulot ng pagiging maaasahan sa mga lawa ng data).
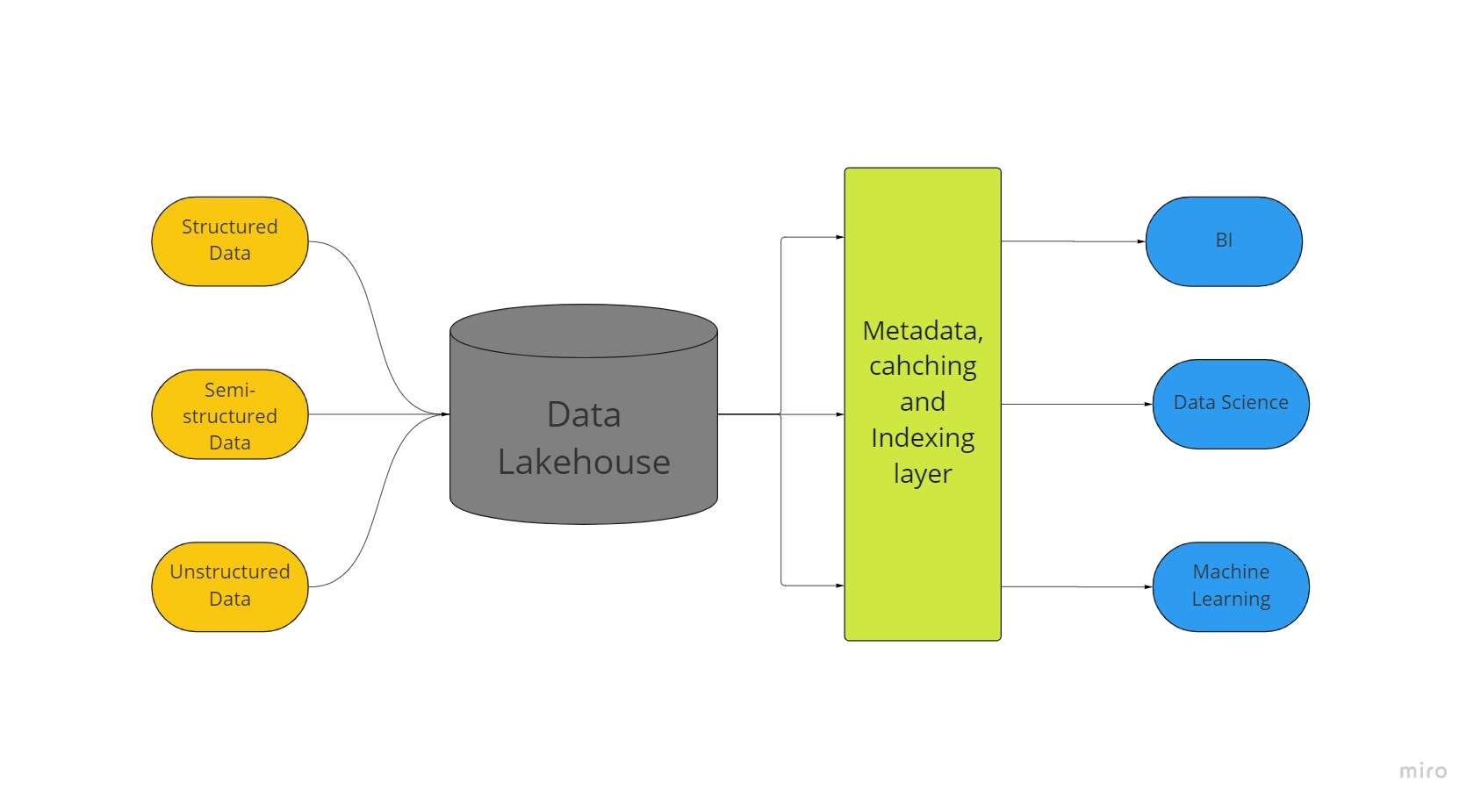
Ang mga lawa ng data na may mga delta lakes ay nagbibigay-daan sa mga pamamaraan ng transaksyon ng ACID mula sa mga kumbensyonal na warehouse ng data. Sa esensya, ang sistema ng lakehouse ay gumagamit ng murang imbakan upang mapanatili ang napakalaking dami ng data sa kanilang mga orihinal na anyo, katulad ng mga lawa ng data.
Ang pagdaragdag ng metadata layer sa itaas ng store ay nagbibigay din ng istraktura ng data at nagbibigay-kapangyarihan sa mga tool sa pamamahala ng data tulad ng mga matatagpuan sa mga warehouse ng data.
Ginagawa nitong posible para sa maraming team na ma-access ang lahat ng data ng kumpanya sa pamamagitan ng iisang sistema para sa iba't ibang mga hakbangin, gaya ng data science, machine learning, at business intelligence.
Mga Benepisyo ng Data Lakehouse
- Suporta para sa mas malaking hanay ng mga workload: Upang mapadali ang mga sopistikadong pagsusuri, binibigyan ng mga data lakehouse ang mga user ng direktang access sa ilan sa mga pinakasikat na tool sa intelligence ng negosyo (Tableau, PowerBI). Bukod pa rito, madaling magamit ng mga data scientist at machine learning engineer ang data dahil gumagamit ang mga data lakehouse ng mga open-data na format (gaya ng Parquet) kasama ng mga API at machine learning frameworks, gaya ng Python/R.
- Cost-effectiveness: Gumagamit ang mga data lakehouse ng murang mga solusyon sa pag-iimbak ng bagay upang ipatupad ang mga katangian ng cost-effective na storage ng mga data lakes. Sa pamamagitan ng pag-aalok ng isang solong solusyon, ang mga data lakehouse ay natatanggal din ang mga gastos at oras na nauugnay sa pamamahala ng iba't ibang mga sistema ng pag-iimbak ng data.
- Tinitiyak ng disenyo ng data lakehouse ang schema at integridad ng data, na ginagawang mas simple ang pagbuo ng epektibong data security at mga sistema ng pamamahala. Dali ng bersyon ng data, pamamahala, at seguridad.
- Nag-aalok ang mga data lakehouse ng isang solong, multipurpose data storage platform na kayang tumanggap ng lahat ng hinihingi ng data ng kumpanya, na binabawasan ang pagdoble ng data. Pinipili ng karamihan ng mga negosyo ang isang hybrid na solusyon dahil sa mga benepisyo ng parehong data warehouse at data lake. Ang diskarte na ito, samantala, ay maaaring magresulta sa magastos na pagdoble ng data.
- Ang suporta ng mga bukas na format. Ang mga bukas na format ay mga uri ng file na maaaring gamitin ng maraming software application at ang mga detalye ay available sa publiko. Ayon sa mga ulat, ang Lakehouses ay may kakayahang mag-imbak ng data sa karaniwang mga format ng file tulad ng Apache Parquet at ORC (Optimized Row Columnar).
Mga Limitasyon ng Data Lakehouse
Ang pinakamalaking disbentaha ng isang data lakehouse ay na ito ay bata pa at umuunlad na teknolohiya. Hindi tiyak kung tutuparin nito ang mga pangako bilang resulta. Bago ang mga data lakehouse ay maaaring makipagkumpitensya sa mga naitatag na malaking-data storage system, maaaring tumagal ito ng mga taon.
Gayunpaman, dahil sa rate kung saan nagaganap ang modernong pagbabago, mahirap sabihin kung hindi ito mapapalitan ng ibang sistema ng pag-iimbak ng data.
Mga kalamangan
- Ang isang platform ay may lahat ng data, na nangangahulugan na may mas kaunting mga hostname na dapat panatilihin.
- Ang atomicity, consistency, isolation, at toughness ay hindi naaapektuhan.
- Ito ay makabuluhang mas abot-kaya.
- Ang isang platform ay may lahat ng data, na nangangahulugan na may mas kaunting mga hostname na dapat panatilihin.
- Simpleng pamahalaan, at mabilis na malutas ang anumang mga isyu
- Gawing mas simple ang paggawa ng pipeline
Kahinaan
- Maaaring magtagal ang pagse-set up.
- Masyado pa itong bata at napakalayo para maging kuwalipikado bilang isang naitatag na sistema ng imbakan.
Data Warehouse Vs Data Lake Vs Data Lakehouse
Ang data warehouse ay may mahabang kasaysayan sa corporate intelligence, pag-uulat, at mga aplikasyon ng analytics at ito ang unang teknolohiya sa pag-imbak ng malaking data.
Ang mga data warehouse, sa kabilang banda, ay mahal at may problema sa paghawak ng magkakaibang at hindi nakaayos na data, tulad ng streaming data. Para sa machine learning at data science workloads, ang mga data lakes ay binuo upang pamahalaan ang raw data sa magkakaibang anyo sa abot-kayang storage.
Bagama't epektibo ang mga data lakes sa hindi nakabalangkas na data, kulang ang mga ito sa ACID transactional capabilities ng mga data warehouse, na ginagawang hamon ang paggarantiya ng pagkakapare-pareho at pagiging maaasahan ng data.
Pinagsasama ng pinakabagong arkitektura ng pag-iimbak ng data, na kilala bilang "data lakehouse," ang pagiging maaasahan at pagkakapare-pareho ng mga warehouse ng data sa pagiging affordability at adaptability ng mga data lakes.
Konklusyon
Sa konklusyon, ang pagbuo ng data lakehouse mula sa simula ay maaaring mahirap. Higit pa rito, halos tiyak na gagamit ka ng isang platform na idinisenyo upang paganahin ang open data lakehouse architecture.
Samakatuwid, mag-ingat na siyasatin ang maraming feature at pagpapatupad ng bawat platform bago bumili. Maaaring isaalang-alang ng mga kumpanyang naghahanap ng mature, structured data solution na may pagtuon sa business intelligence at data analytics na mga kaso ng paggamit ng data warehouse.
Gayunpaman, dapat isaalang-alang ng mga negosyong naghahanap ng scalable, abot-kayang solusyon sa malaking data para sa mga workload para sa agham ng data at machine learning sa hindi nakabalangkas na data.
Isaalang-alang na ang iyong negosyo ay nangangailangan ng mas maraming data kaysa sa maibibigay ng data warehouse at mga teknolohiya ng data lake, o na naghahanap ka ng solusyon para pagsamahin ang mga sopistikadong operasyon ng analytics at machine learning sa iyong data. A data lakehouse ay isang makatwirang opsyon sa sitwasyon.





Mag-iwan ng Sagot