Ang web scraping ay naging isang mahalagang paraan para sa pagkuha ng insightful data mula sa mga internet platform sa kasalukuyang data-driven na lipunan.
Bilang isang napaka-tanyag na social media site, ang Instagram ay nagbibigay ng maraming materyal na binuo ng gumagamit. At, ang mga nabuong data na ito ay maaaring gamitin para sa marketing, pananaliksik, at iba pang mga dahilan.
Maaaring kunin ng mga user ang data mula sa Instagram nang madali at epektibo salamat sa mga scraper ng Instagram na mayaman sa feature ng Bright Data, isang nangungunang web scraping kasangkapan. Sa post na ito, magbibigay kami ng masusing, hakbang-hakbang na walkthrough ng proseso ng pag-scrape ng Instagram.
Kaya, tingnan natin ang mga hakbang kung paano tayo makakapag-scrape ng data mula sa Instagram.
Pag-unawa sa Instagram Scraper mula sa Bright Data
Sa tulong ng dalawang all-purpose web scraper at isang paunang pinagsama-samang dataset, ang Bright Data ay nagbibigay ng iba't ibang mga serbisyo sa pag-scrap ng Instagram. Nag-aalok ang mga teknolohiyang ito ng versatility sa pagkuha ng data at umangkop sa iba't ibang pangangailangan.
Suriin natin ang bawat isa sa mga pagpipiliang ito nang mas detalyado:
a. Pag-scrape ng Browser
Ang makabagong teknolohiya na kilala bilang Scraping Browser ay nilikha upang matupad ang mga hinihingi ng mga proyekto sa pag-scrape ng data. Nag-aalok ito ng lahat ng kailangan para sa pag-scrape nang malaki sa loob ng isang browser. Namumukod-tangi ito salamat sa pinagsama-samang pag-unblock ng automation ng website, na ginagawa itong nag-iisang browser na katulad nito sa buong mundo.
Ang Scraping Browser ay nagbibigay sa mga user ng access sa mga mahuhusay na feature na higit pa sa mga automated at walang ulo na browser, na nagbibigay-daan sa kanila na malampasan kahit ang pinakamahirap na script at mga hadlang sa website para sa pag-detect ng bot.
Ang pag-scrape ng data ay mas epektibo at walang problema dahil sa mga tampok na awtomatikong pagsasaayos nito, na madaling namamahala ng mga bagong bloke, mga solusyon sa CAPTCHA, fingerprint, at muling pagsubok, at lumalabas bilang isang tunay na user.
Paggamit ng AI para madaig ang mga bot-detection system
Sa pamamagitan ng paggamit ng makabagong teknolohiya ng AI, maaaring linlangin ng Scraping Browser ang mga sistema ng pag-detect ng bot at patuloy na mag-adjust sa kanilang mga diskarte sa paglilipat. Upang mas mahusay na i-unlock ang mga webpage, natututo ang Scraping Browser mula sa mga pagtatangka ng mga system na ito na tuklasin at harangan ang mga pagtatangka sa pag-scrape at binago ang pag-uugali nito nang naaangkop.
Nahihigitan nito ang kahusayan ng mga karaniwang proxy sa pamamagitan ng paggaya sa gawi ng isang browser na ginagamit ng isang tunay na user. Bilang resulta, maaaring tumutok ang mga customer sa kanilang mga layunin para sa pag-scrape ng data nang hindi kailangang harapin ang kahirapan at gastos ng mga patuloy na pamamaraan sa pag-detect ng bot.
b. Web Scraper IDE
Isang mahusay na tool sa pag-scrape ng web na nilikha para sa mga developer, ang Web Scraper IDE ay maaaring humawak ng mga kumplikadong gawain sa pag-scrape. Lubos nitong pinabababa ang oras ng pag-develop habang nagbibigay ng walang katapusang scalability salamat sa ganap nitong naka-host na solusyon at mga pre-built na feature sa pag-scrape. Ang application ay nagbibigay-daan sa mabilis at nasusukat na pagbuo ng mga online scraper sa pamamagitan ng pagbibigay ng mga template ng code at mga yari na JavaScript function mula sa mga sikat na website.
Lahat ng kailangan para sa matagumpay na web scraping ay ibinibigay ng Web Scraper IDE. Ito ay isang kumpletong solusyon para sa online na pagkuha ng data dahil ang mga pagpipilian sa pagsasama ay nagbibigay-daan sa mga customer na magplano ng mga pag-crawl o ilunsad ang mga ito sa pamamagitan ng API at mag-link sa mga pangunahing storage system.
Paano Ito Gamitin? - Pagtuturo
Una, mag-navigate sa dashboard ng user sa website.

Magsimula tayo sa ating mga hakbang sa pag-scrape ng Instagram.
1- Mag-navigate sa Tapalodo at mag-click sa seksyong Datasets & Web Scraper IDE.
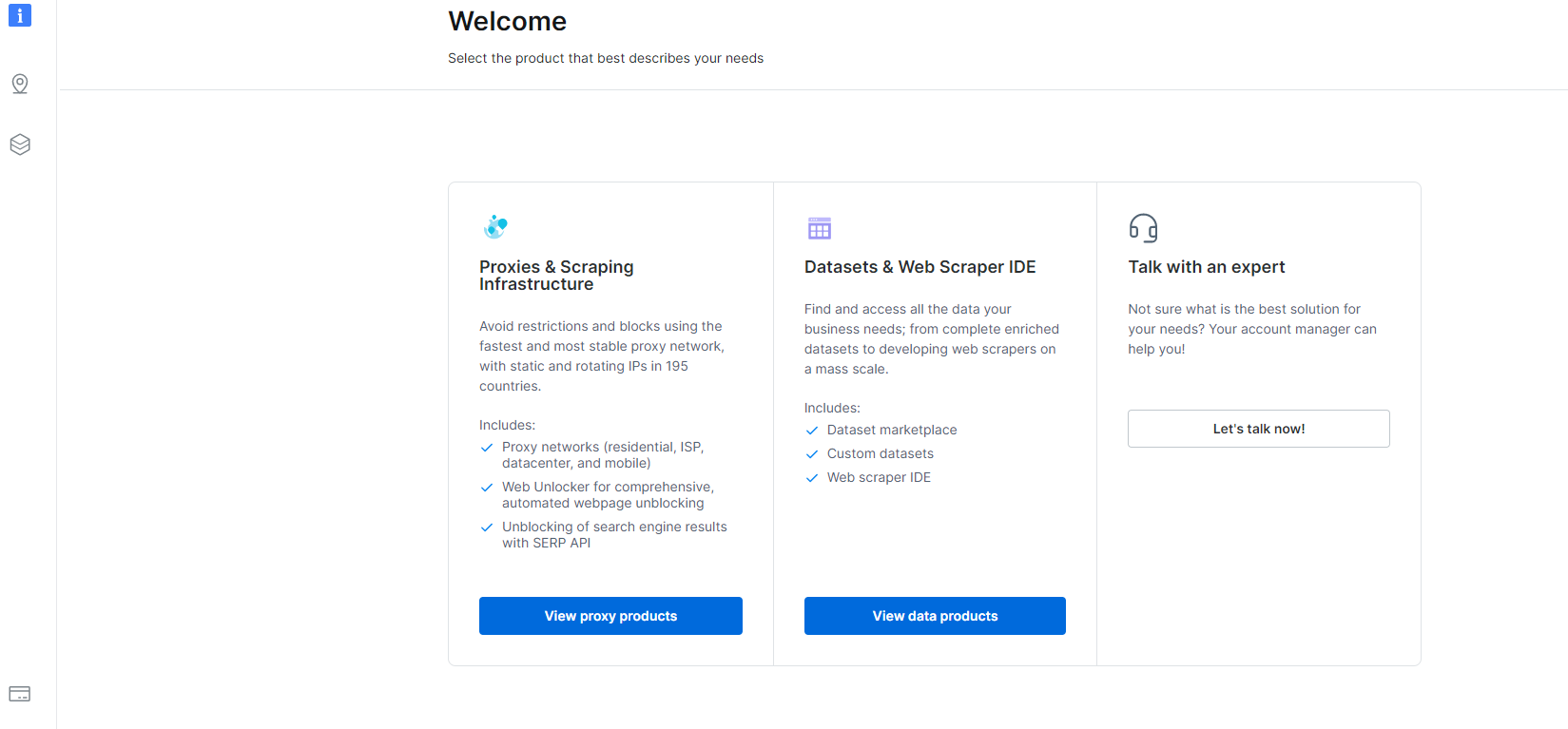
2- Kapag, nandoon ka na, i-click ang My Scrapers.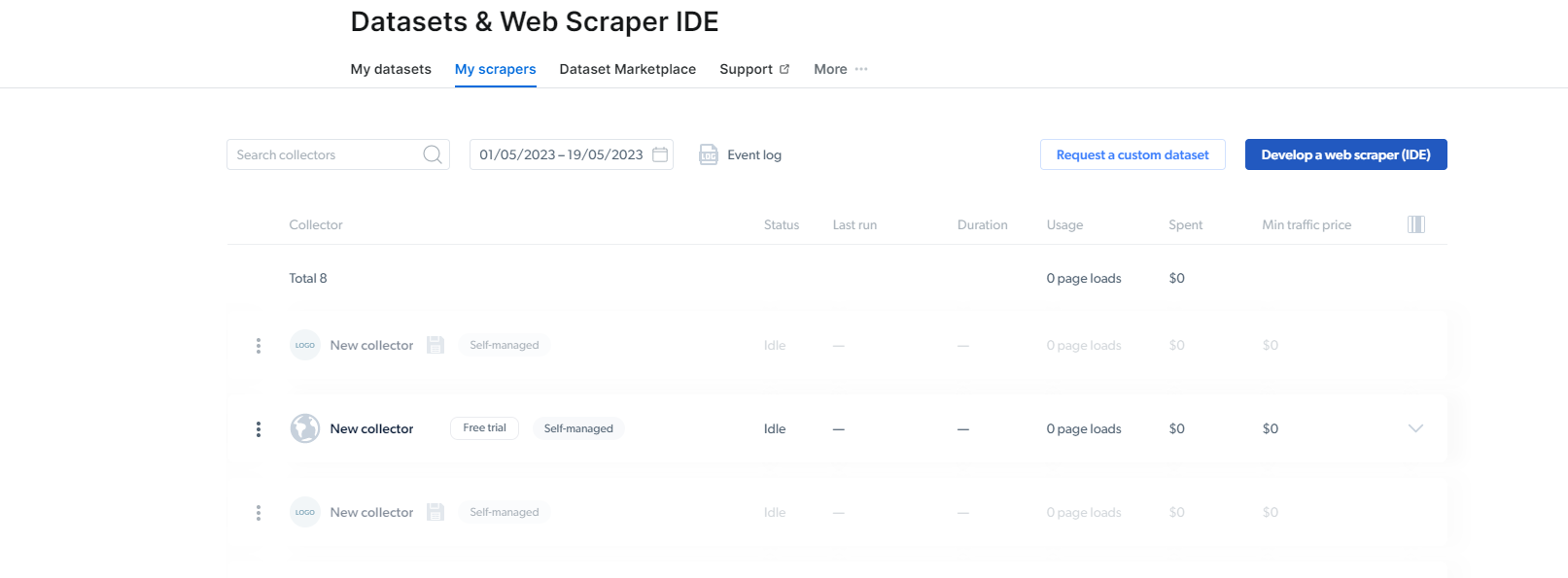
Dito, kailangan mong mag-click sa "Bumuo ng isang web scraper(IDE)". Dito gagawa kami ng aming scraper para sa Instagram.
3-Ngayon, kailangan nating bumuo ng bagong web scraper. Para lamang sa halimbawang ito, pinili kong i-scrape ang account na "NASA". Ito ay para lamang sa kapakanan ng halimbawang ito.
Kaya, ang aking code ay magiging ganito:
/ Click the 'play' button in the top right to run this code:
// 1. Go to the page where you want to start
navigate('https://www.instagram.com/nasa/');
// 2. Add anything else you need to do on the page.
// For example: (see the help box for all command docs).
// click('.some-button')
// type('.some-input', 'shoes')
// wait('.some-lazy-loaded-element')
// 3. Once the browser page has the data you want, call parse() to get the data
// and call collect() to add a record to your final dataset
let data = parse();
collect({
url: new URL(location.href),
title: "Nasa Account",
links: data.links,
});
Kailangan mong i-click ang button na 'play' sa kanang tuktok upang patakbuhin ang code na ito.
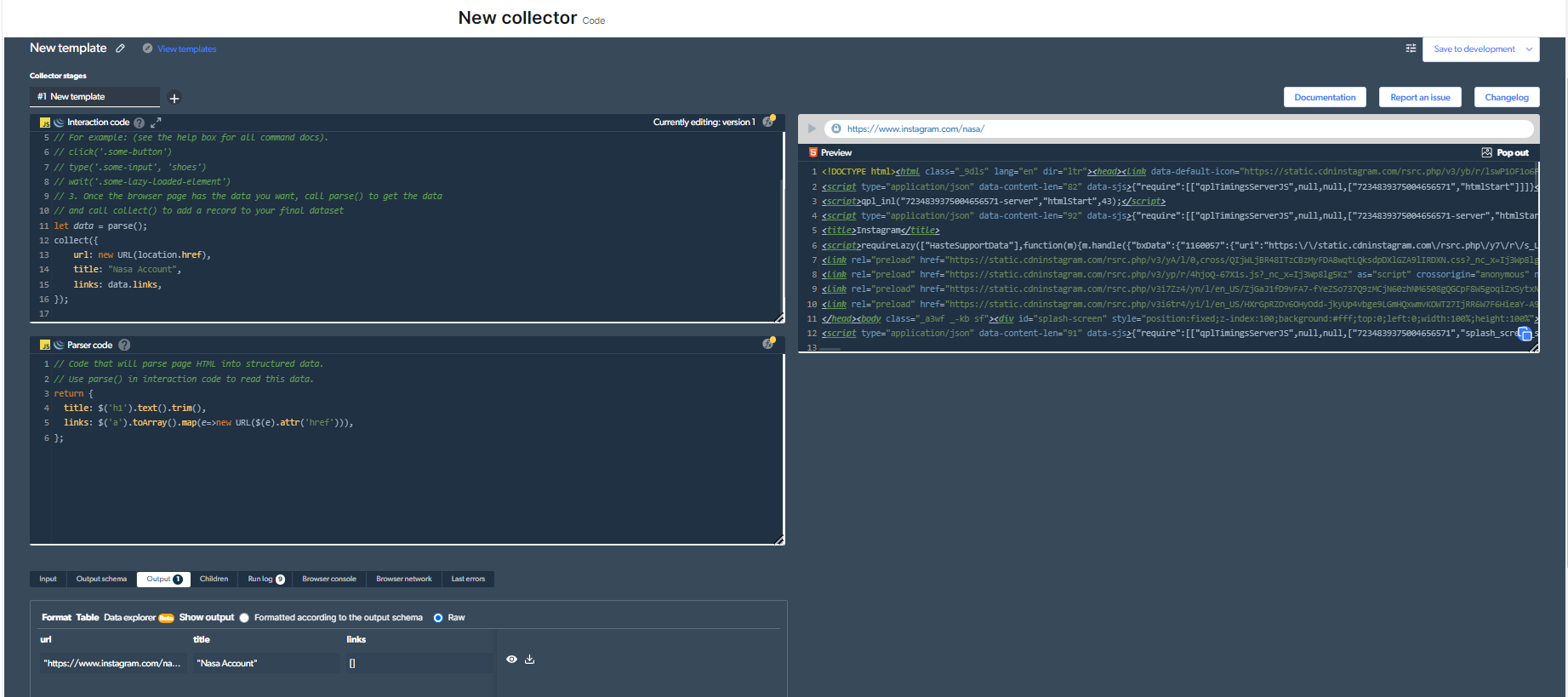
4- Ngayon, magkakaroon tayo ng output.
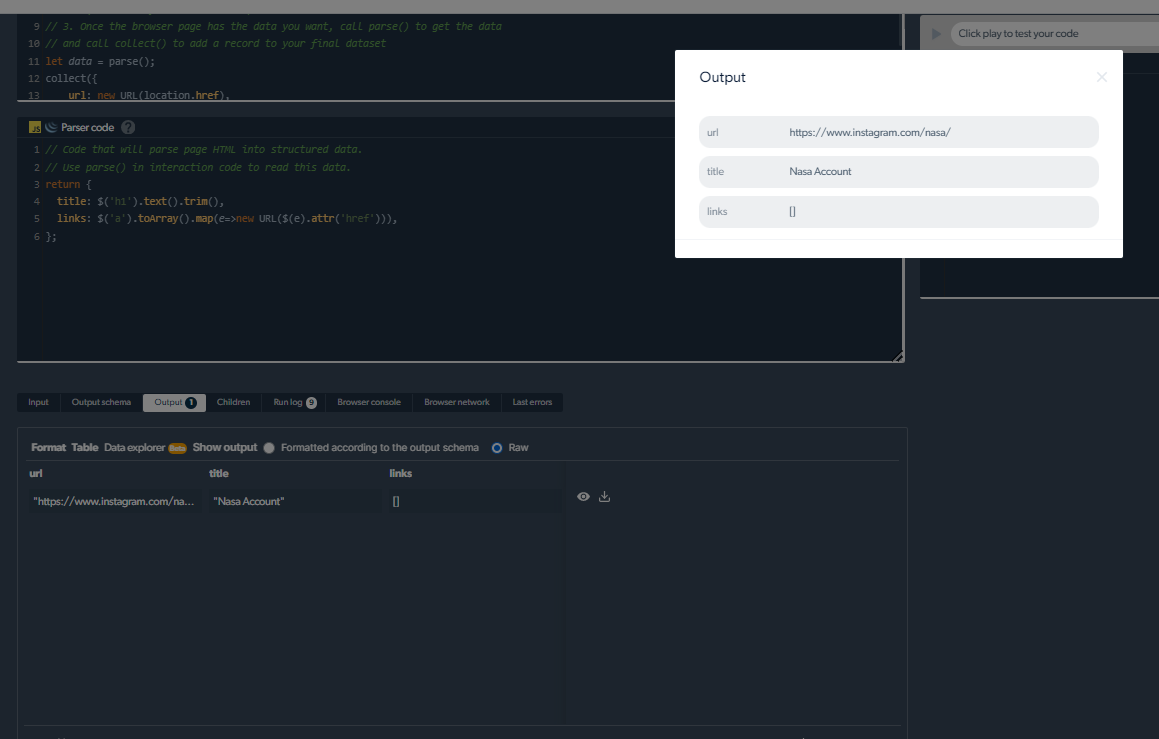
Pamamahala ng mga Problema sa Scraping
Ang mga post sa Instagram na may "show more button" ay maaaring mahirap makuha ng mga scraper. Gayunpaman, ang mga scraper ng Instagram mula sa Bright Data ay ginawa upang matagumpay na mahawakan ang naturang kumplikado. Ang mga scraper na ito ay may mga cutting-edge na kasanayan sa pagtawid sa pagination at paglo-load ng mga karagdagang button.
Ang mga scraper ng Bright Data sa Instagram ay epektibong pinangangasiwaan ang mga paghihirap na ito upang paganahin ang masusing pagkuha ng data, na nagbibigay-daan sa iyong kolektahin ang buong koleksyon ng impormasyong kinakailangan para sa iyong pagsusuri o pag-aaral.
Malalampasan mo ang mga hamon na ipinakita ng dynamic na kalikasan ng mga post sa Instagram sa pamamagitan ng paggamit ng mga tool sa pag-scrape na ito.
c. Paunang nakolektang Dataset
Naiintindihan ng Bright Data na hindi lahat ay gustong patakbuhin ang kanilang scraper. Nagbibigay sila ng isang paunang nakolektang dataset para sa Instagram upang maakit ang mga naturang consumer.
Nag-aalok ang dataset na ito ng maraming kapaki-pakinabang na impormasyon, tulad ng mga tagasunod, profile, post, at higit pa.
Nag-aalok ang Bright Data ng mga opsyon sa pag-customize para i-personalize ang dataset sa iyong mga pangangailangan, kung gusto mo ng isang buong dataset o isang subset ng espesyal na data. Iniiwasan ng diskarteng ito ang pagbuo at pamamahala ng scraper, na nagbibigay sa iyo ng handa nang gamitin na data para sa pagsusuri at mga insight.
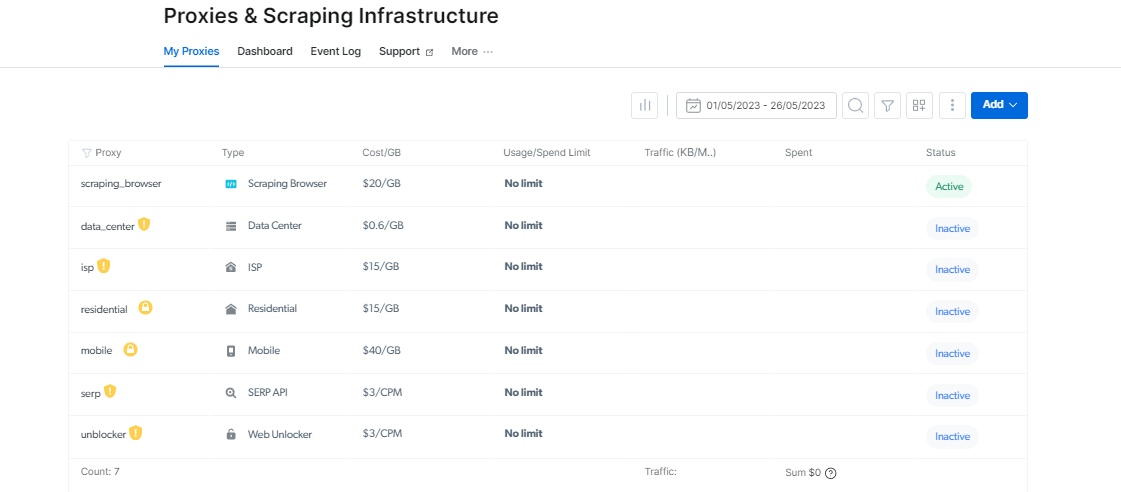
Ngayon, suriin natin ang imprastraktura na gumagawa ng mga tool na ito nang napakabisa: ang proxy infrastructure at Web Unlocker.
Ilabas ang Kapangyarihan ng mga Proxies
paggamit proxy ay mahalaga sa panahon ng pag-scrape ng web upang matiyak na hindi napapansin ang iyong mga aksyon.
Nagbibigay ang Bright Data ng malawak na seleksyon ng mga serbisyo ng proxy na naka-customize sa iyong mga kinakailangan. Maaari kang pumili mula sa Mga Proxy sa Paninirahan, na nag-aalok ng higit sa 72 milyong IP na pinaikot mula sa mga real-peer na device sa 195 na bansa.
Maaari kang pumili ng ISP Proxies, na nag-aalok ng 700,000+ totoong home IP sa buong mundo para sa pangmatagalang paggamit; Datacenter Proxies, na mayroong 770,000+ ibinahaging IP mula sa anumang geolocation; at Mobile Proxies, na bumubuo sa pinakamalaking real-peer na 3G/4G na mobile network na may 7,000,000+ IP.
Sa paggamit ng mga proxy na ito, madaling mangolekta ng data habang nagpapanggap bilang isang awtorisadong gumagamit sa maraming lugar.

Proxy Manager: Gawing Mas Madali ang Pamamahala ng Proxy
Maaaring mahirap ang pamamahala ng ilang proxy, ngunit pinapadali ng Proxy Manager.
Binibigyang-daan ka ng open-source na interface na ito na pamahalaan ang lahat ng iyong mga proxy mula sa isang platform. Magpaalam sa manu-manong pagtatakda at pagpapalit ng mga proxy. Pinapasimple ng Proxy Manager ang pamamaraan at nakakatipid ka ng oras at pagsisikap.
Proxy Browser Extension: Madaling Baguhin ang Iyong Lokasyon
Kailangan mo bang mangolekta ng data sa web mula sa ilang mga rehiyon? Saklaw ka ng aming Proxy Browser Extension. Maaari mong baguhin ang iyong lokasyon sa pagba-browse sa isang pag-click upang makakuha ng impormasyong tukoy sa rehiyon.
Samantalahin ang kakayahang umangkop at pagiging simple ng pagkolekta ng data mula sa ilang mga rehiyon nang walang anumang teknolohikal na komplikasyon.
Paano Ito Gumagana? - Pagtuturo
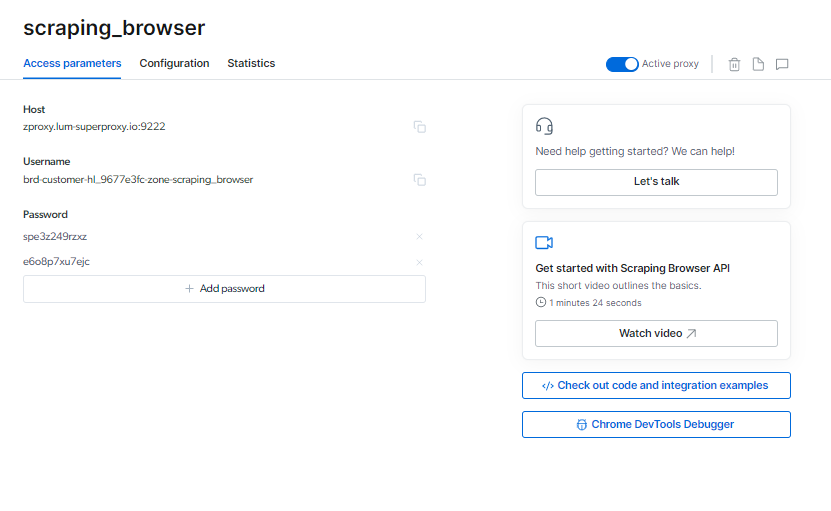
Maaari mong mahanap ang iyong Pag-scrape ng Browser impormasyon sa pag-log in sa page ng Access parameters, na gagamitin kapag nagsimula ka ng bagong session ng browser.
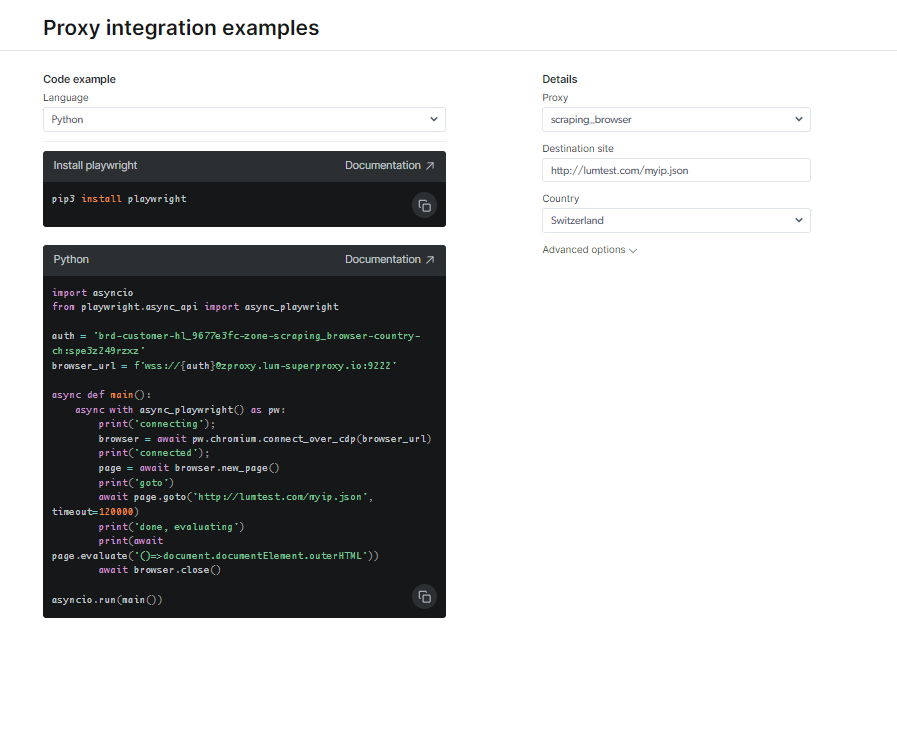
Tingnan ang dokumentasyon at mga sample ng code, kabilang ang isang ganap na gumaganang halimbawa ng script na handang gamitin, o manood ng maikling panimulang video ng pagtuturo. Halimbawa; Heto ang Python code halimbawa para sa pagsasama:
Gusto ng tulong? Para sa isang pag-uusap sa isa sa mga espesyalista, maaari mong i-click ang icon ng chat.
Tandaan na mayroon kang kumpletong kontrol sa mga session ng browser habang gumagamit ng Scraping Browser at maaaring magsagawa ng anumang operasyon na sinusuportahan ng Puppeteer, Playwright, o direktang paggamit ng Chrome DevTools Protocol.
Pag-unlock ng Website nang Walang Mga Harangan
Ang Scraping Browser ay ginawa upang gumana sa sukat at kung kinakailangan. Hindi mo kailangang mag-alala tungkol sa pagbabawal; maaari kang magsimula ng maraming session ng browser hangga't kailangan mo.
Ang kapasidad na ito, kapag ipinares sa lakas ng mga proxy, ay ginagarantiyahan ang tuluy-tuloy na pangangalap ng data, na nagbibigay-daan sa iyong epektibong makuha ang data na gusto mo.
Nakakatulong sa iyo ang pag-scrape ng mga built-in na kasanayan sa pag-unlock ng Browser at matatag na proxy network na makatipid ng oras, mapahusay ang pagiging produktibo, at tumuklas ng mga bagong pagkakataon.
Maaari mo ring direktang suriin ang mga istatistika mula sa parehong pahina.
Pagpepresyo ng Scraping Browser
Nagbibigay ang Bright Data ng mga napapasadyang pagpipilian sa pagpepresyo upang matugunan ang iba't ibang layunin. Maaari kang pumili ng buwanan o taunang panahon ng pagsingil.
Binibigyang-daan ka ng opsyong Pay as You Go na magbayad para lang sa iyong ginagamit, nang walang kinakailangang pangako, simula sa $20.00/GB at $0.1/hour.
Ang $500 Growth plan ay angkop para sa mga lumalagong negosyo, na may diskwentong bayad na $15.30/GB at $0.1/hour.
Ang Pakete ng negosyo, na nagkakahalaga ng $1000, ay ang pinakasikat na opsyon, kasama ang Scraping Browser API na nagkakahalaga ng $13.50/GB at $0.1/hour.
Sa pamamagitan ng direktang pakikipag-ugnayan sa Bright Data team, masisiyahan ang mga user ng enterprise sa walang katapusang pag-scale at personalized na pagpepresyo. Magsimula ng libreng pagsubok ngayon upang matuklasan ang potensyal ng Scraping Browser ng Bright Data at baguhin ang iyong mga pagsisikap sa online na pag-scrape.
Website Unlocker
Ang Web Unlocker ay isang makapangyarihang tool na nilikha upang lumampas sa mga paghihigpit sa website at magbigay ng madaling pag-aani ng data. Napagtagumpayan nito ang ilang hamon, kabilang ang cookies, mga ahente ng gumagamit ng browser na tukoy sa site, at mga solusyon sa captcha, sa pamamagitan ng paggamit ng mga awtomatikong pamamaraan.
Sa pamamagitan ng paggamit ng awtomatikong pag-ikot ng IP address, ang mga gumagamit ng Web Unlocker ay maaaring patuloy na mag-scrape ng mga target na website, na tinitiyak ang patuloy na pag-access sa mahalagang data.
Pagpapahusay sa Mga Paglalakbay sa Kahilingan ng Developer
Maraming mga tampok ang nagpapasikat sa Web Unlocker sa mga developer. Pina-streamline ng programa ang proseso ng pangangalap ng data sa pamamagitan ng awtomatikong pagtukoy sa mga ahente ng gumagamit na kailangan para sa bawat website, na nakakatipid ng mahalagang oras at mapagkukunan.
Ang Web Unlocker ay umaangkop sa real-time upang maiwasan ang pagtuklas bilang tugon sa patuloy na pagbabago ng mga diskarte na ginagamit ng pagharang sa mga bot, na tinitiyak ang patuloy na pag-access sa mga website ng interes. Mabilis na malulutas ng mga machine-learning algorithm ng platform ang mga captcha, isang madalas na hadlang sa mga hakbangin sa pagkolekta ng data.

Pagpepresyo ng Web Unlocker
Simula sa humigit-kumulang $2.03 bawat libong kahilingan (CPM), ang Web Unlocker ay nag-aalok ng maraming mga pagpipilian sa presyo upang matugunan ang iba't ibang mga pangangailangan. Available ang 7-araw na libreng pagsubok sa mga user para makapagsimula sila at hayaan silang subukan ang mga feature ng Web Unlocker bago gumawa.
Ang Web Unlocker ay may kakayahang umangkop upang suportahan ang iba't ibang mga pattern ng paggamit, hindi alintana kung gusto ng mga mamimili ang isang pay-as-you-go na diskarte o kailangan ng isang naka-customize na plano na angkop sa kanilang mga partikular na kinakailangan. Bukod pa rito, ang mga pipili ng pangmatagalang plano sa presyo ay maaaring makatipid ng 32%.
Paghahambing sa pagitan ng Web Unlocker sa Self-Managed Proxies
Nag-aalok ang Web Unlocker ng maraming instant na benepisyo sa mga proxy na pinamamahalaan ng sarili. Para sa maayos na pagpapatupad, nag-aalok ito ng malawak na diskarte sa pagsasama na pinagsasama ang mga function ng super proxy at Proxy Manager. Maaaring epektibong palakihin ng mga user ang kanilang mga operasyon sa pagkolekta ng data gamit ang walang katapusang bilang ng mga kasabay na koneksyon.
Ang Web Unlocker ay naghahatid ng awtomatikong pag-unblock, nilulutas ang mga CAPTCHA, at matagumpay na namamahala ng mga pagbabago sa markup sa mga target na website.
Ginagarantiyahan ng platform ang tuluy-tuloy at maaasahang pagkuha ng data sa pamamagitan ng pagpapatupad ng isang awtomatikong muling pagsubok na system at paggawa ng mga asynchronous na tawag para sa ilang partikular na domain. Bilang karagdagan, ang dumaraming koleksyon ng online Unlocker ng mga kahilingan sa header ng HTTP, cookies ng browser na tukoy sa site, at mga simulate na gadget ay nagbibigay-daan sa mga user na manatiling hindi natukoy habang pinapagana silang makakuha ng online na data sa real time.
Mga Pangwakas na Kaisipan at Mahahalagang Bagay na Dapat Tandaan
Sa wakas, habang ginagamit ang Bright Data para sa pag-scrape ng Instagram, mahalagang tandaan ang ilang mahahalagang punto.
Pakitandaan na ang kanilang mga kakayahan sa pag-scrape ay limitado sa pampublikong magagamit na data, ayon sa mga etikal na kasanayan.
Dapat mong palaging sundin ang mga tuntunin ng serbisyo at mga patakaran sa privacy ng Instagram. Ang pag-scrape ay dapat gawin nang may etika at responsable, nang hindi nakikialam sa mga karapatan ng mga gumagamit o lumalabag sa anumang mga batas.
Pangalawa, regular na i-update at i-fine-tune ang iyong mga parameter sa pag-scrape upang matiyak ang katumpakan at kaugnayan ng nakuhang data. Ang platform at algorithm ng Instagram ay napapailalim sa pagbabago, kaya dapat mong baguhin ang iyong mga diskarte sa pag-scrape nang naaayon.
Panghuli, gamitin ang tulong at mga mapagkukunan ng platform ng Bright Data upang ma-optimize ang tagumpay ng iyong mga pagsusumikap sa pag-scrap sa Instagram. Makipag-ugnayan sa kanilang dokumentasyon, mga tutorial, at serbisyo sa customer upang mapabuti ang iyong kaalaman sa kanilang mga tool sa pag-scrape.
Maaari kang makakuha ng mga kapaki-pakinabang na insight, makaimpluwensya sa matalinong paggawa ng desisyon, at magtagumpay sa iyong mga inisyatiba na batay sa data sa platform ng Instagram sa pamamagitan ng pagsunod sa mga pinakamahuhusay na kagawian na ito at paggamit ng lakas ng mga kakayahan sa pag-scrap ng Instagram ng Bright Data.





Mag-iwan ng Sagot