Talaan ng nilalaman[Tago][Ipakita]
Ang bago at pinahusay na AI ay nagpahusay ng mga kakayahan, pang-unawa, at kapasidad na gumawa ng mga larawang may mas mataas na resolution. Maaaring kamakailan ay nakatagpo ka ng ilang kakaiba at nakakatuwang larawan na lumulutang sa internet.
Ang isang asong Shiba Inu ay nakasuot ng beret at isang itim na turtleneck. At isang sea otter sa paraan ng Dutch na pintor na si Vermeer na "Girl with a Pearl Earring." At may isang tasa ng sopas na parang makapal na halimaw.
Ang mga larawang ito ay hindi nilikha ng isang tao na artista.
Sa halip, ang DALL-E 2, isang bagong AI system na maaaring mag-convert ng mga tekstong paglalarawan sa mga imahe, ang lumikha ng mga ito.
Isulat lang kung ano ang gusto mong makita, at gagawin ito ng AI para sa iyo - sa matingkad na detalye, mahusay na kalidad, at, sa ilang mga kaso, tunay na pagiging imbento. Sa post na ito, titingnan natin nang malalim ang pinakabagong pag-aaral ng OpenAI, DALL.E 2, pati na rin kung paano ito gumagana, at marami pang iba. Magsimula na tayo.
Kaya, ano nga ba DALL.E 2?
Ang DALL-E 2 ay isang "generative model," isang uri ng machine learning algorithm na bumubuo ng kumplikadong output sa halip na magsagawa ng mga gawain sa paghula o pag-uuri sa input data.
Nagbibigay ka sa DALL-E 2 ng nakasulat na paglalarawan, at lumilikha ito ng larawan na tumutugma dito. Sa pamamagitan ng pagsasama-sama ng mga konsepto, katangian, at istilo, ang DALLE 2 ng OpenAI ay makakagawa ng mga makabago, makatotohanang mga graphic at sining mula sa isang pangunahing paglalarawan sa wika.
Ang pinakabagong bersyon, ang DALLE 2, ay sinasabing mas maraming nalalaman, na may kakayahang gumawa ng mga larawan mula sa mga caption sa mas matataas na resolution at sa mas malawak na spectrum ng mga malikhaing istilo. Halimbawa, ang mga larawan sa ibaba (mula sa DALL-E 2 blog post) ay nilikha ng paglalarawang "Isang astronaut na nakasakay sa kabayo."
Ang isang paglalarawan ay nagtatapos, "tulad ng isang sketch ng lapis," habang ang isa ay nagtatapos, "sa isang photorealistic na paraan."

Maaari rin nitong baguhin ang mga kasalukuyang larawan nang may kahanga-hangang katumpakan. Kaya, maaari kang magdagdag o magtanggal ng mga elemento habang pinapanatili ang mga kulay, reflection, at anino, lahat habang pinapanatili ang hitsura ng orihinal na larawan.
Paano ito gumagana?
Gumagamit ang DALL-E 2 ng mga modelong CLIP at diffusion, dalawang sopistikado malalim na pag-aaral mga diskarte na binuo sa mga nakaraang taon. Gayunpaman, ito ay batay sa parehong paniwala tulad ng lahat ng iba pang malalim mga neural network: pagkatuto ng representasyon. Ang CLIP ay sabay na nagsasanay sa dalawa neural network sa mga larawan at caption.
Natututo ang isang network ng mga visual na representasyon sa larawan, habang ang isa naman ay natututo ng mga representasyon ng teksto. Sa panahon ng pagsasanay, sinusubukan ng dalawang network na baguhin ang kanilang mga parameter upang ang mga maihahambing na larawan at paglalarawan ay magresulta sa magkatulad na mga pag-embed.
Ang "diffusion," isang uri ng generative model na natututong gumawa ng mga larawan sa pamamagitan ng unti-unting pag-iingay at pagtanggal ng mga sample ng pagsasanay nito, ay ang iba pang diskarte sa pag-aaral ng makina na ginagamit sa DALL-E 2. Ang mga modelo ng diffusion ay katulad ng mga autoencoder dahil ginagawa nila ang data ng input sa isang pag-embed ng representasyon at pagkatapos ay gamitin ang impormasyon sa pag-embed upang muling likhain ang orihinal na data.
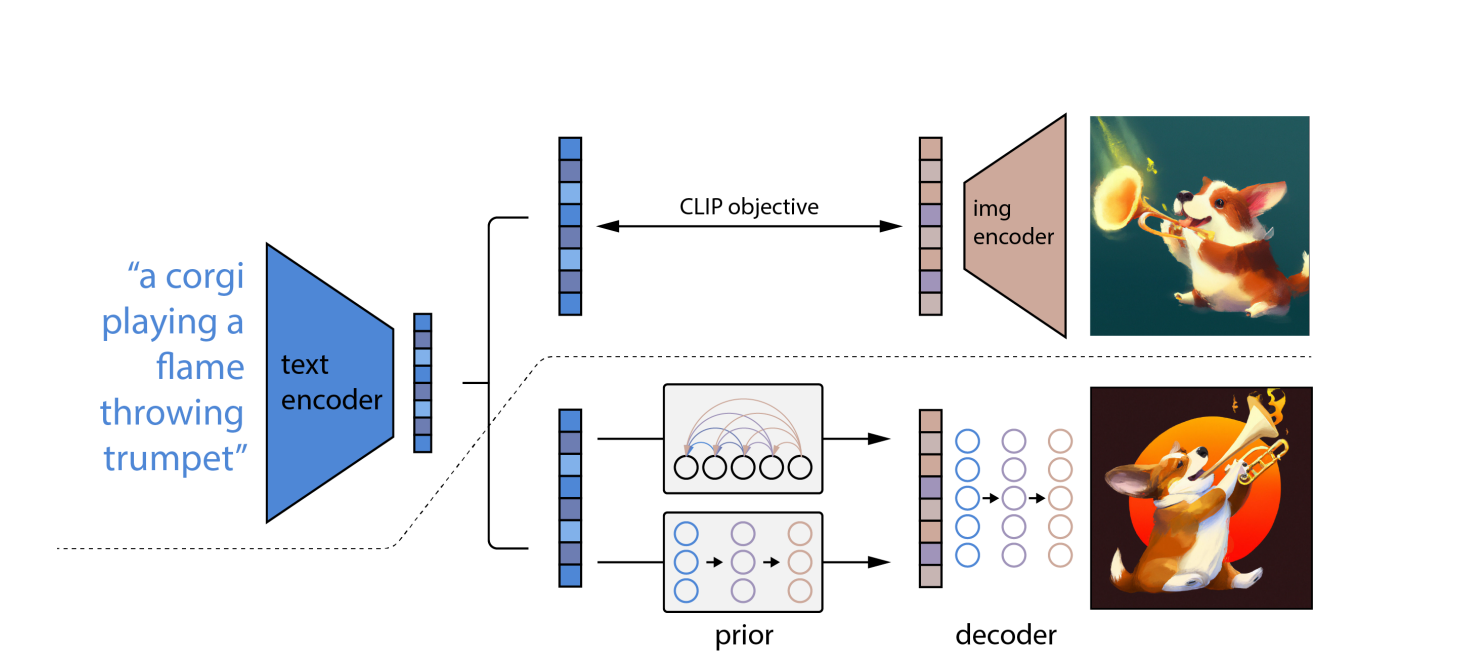
Gamit ang OpenAI's modelo ng wika CLIP, na maaaring magkonekta ng mga tekstong paglalarawan sa mga larawan, isinasalin muna nito ang nakasulat na prompt sa isang intermediate form na isinasama ang mga mahahalagang katangian na dapat magkaroon ng isang larawan upang tumugma sa prompt na iyon (ayon sa CLIP).
Pangalawa, ang DALL-E 2 ay gumagawa ng CLIP-compliant larawan gamit ang diffusion model, na isang neural network.
Sa mga distorted na larawan na may mga random na pixel, natutunan ang mga diffusion model. Natutunan nila kung paano ibalik ang orihinal na anyo ng mga larawan. Ang mga modelo ng pagsasabog ay maaaring makagawa ng mataas na kalidad na mga sintetikong larawan, lalo na kapag ginamit kasabay ng isang gabay na diskarte na inuuna ang katumpakan kaysa sa pagkakaiba-iba.
Bilang kinahinatnan, ang modelo ng pagsasabog kinukuha ang mga random na pixel at gumagamit ng CLIP upang i-convert ang mga ito sa isang bagong imahe na tumutugma sa prompt ng salita. Dahil sa konsepto ng diffusion, ang DALL-E 2 ay makakagawa ng mga larawang may mas mataas na resolution kaysa sa DALL-E.
DALL.E 2 use case
Sa huling dalawampung taon, computer vision ang teknolohiya ay umunlad mula sa isang simpleng paniwala tungo sa isang malaking tagumpay. Sa kabila ng mga pagsulong na ito, ang mga modelo ng pagkilala sa larawan at bagay ay nahaharap pa rin sa mga makabuluhang hadlang sa pang-araw-araw na buhay. Ang kawalan ng mga dataset ay isa sa mga pinaka makabuluhang disbentaha ng pagkilala sa imahe at computer vision. Dahil may kakulangan ng data sa magkabilang dulo, halos mahirap ang pagsasanay sa mga modelo ng pagkilala ng larawan upang magbigay ng 100 porsiyentong tumpak na mga resulta.
Sa kabutihang palad, ang bagong modelo ng pag-aaral ng makina ng OpenAI ay maaaring tulay ang agwat sa teknolohiya. Ang DALLE 2 ay may kakayahang bumuo ng mga kamangha-manghang larawan batay sa mga paglalarawan ng teksto. Ang pekeng paggawa ng larawan na ito ay maaaring magbigay ng data sa mga modelo ng pagkilala ng imahe batay sa kanilang mga kinakailangan. Ang kawalan ng data ay isang makabuluhang hadlang para sa pagkakakilanlan ng bagay at larawan.
Sa digital era, ang mga dataset ay nasa lahat ng dako, ngunit naghahanap pa rin kami ng mga shortcut para sa AI model, para makapagbigay ito ng magagandang resulta. Gayunpaman, hindi simpleng magsanay ng modelo ng pagkilala sa imahe. Nangangailangan ito ng malaking bilang ng mga set ng data na may kaunting mga pagkakaiba, na maaaring hindi namin nakuha nang simple.
Kaya, ano ang sagot: Ang sagot ay DALLE 2. Ang OpenAI picture generator, na may kapasidad nitong gumawa ng mga imahe mula sa mga teksto at baguhin ang mga umiiral na, ay maaaring makatulong upang tulay ang agwat. Makakatulong ito sa pagbuo ng karagdagang data ng pagsasanay habang binabawasan din ang dami ng kinakailangang pag-label ng tao. Sa kabila ng malaking benepisyo, dapat kang magkaroon ng kamalayan sa mga mapanlinlang na paggawa ng imahe at mga larawan na hindi kasama ang pagsasama. Ito ay maaaring humantong sa mga pamamaraan ng pag-detect ng imahe na gumagawa ng mga bias na resulta.
Mga hangganan
Ang DALL.E 2 ay maaaring magkaroon ng nakakapinsalang impluwensya kung ito ay nahulog sa maling mga kamay, ayon sa OpenAI. Sa mundo ngayon ng malalim na mga pekeng, ang modelo ay madaling magamit upang maikalat ang maling impormasyon o racist na imahe, kaya naman pinapayagan lang ng OpenAI ang mga developer na gamitin ang DALL.2 sa pamamagitan ng imbitasyon. Ang modelo ay dapat sumunod sa isang mahigpit na paghihigpit sa nilalaman para sa lahat ng mga mungkahi na kanyang nakukuha.
Upang ibukod ang potensyal ng DALL.E 2 na lumikha ng anumang pagalit o marahas na mga larawan, ginawa ang dataset nang walang anumang nakamamatay na armas. Habang sinabi ng OpenAI na plano nitong gawing API sa hinaharap, sa kaso ng DALL.E 2, handa itong magpatuloy nang may pag-iingat.
Konklusyon
Ang DALL-E 2 ay isa pang kawili-wiling pagtuklas ng pananaliksik sa OpenAI na nagbubukas ng pinto sa mga bagong application.
Ang isang halimbawa ay ang paglikha ng napakalaking dataset upang matugunan ang isa sa mga pangunahing bottleneck ng computer vision–data. Bagama't matutukoy ang pang-ekonomiyang kaso para sa maraming DALL-E-based na app sa pamamagitan ng presyo at mga patakarang itinakda ng OpenAI para sa mga user ng API nito, walang alinlangang isusulong ng mga ito ang paggawa ng larawan.





Mag-iwan ng Sagot