Spis treści[Ukryć][Pokazać]
Fałszywe zdjęcia i filmy nie są niczym nowym. Od czasu powszechnego korzystania z Internetu ludzie tworzyli fałszerstwa, które miały na celu oszukać lub rozbawić, odkąd pojawiły się obrazy i filmy.
Istnieje jednak nowy rodzaj podróbek produkowanych maszynowo, które pewnego dnia mogą utrudnić nam odróżnienie rzeczywistości od fikcji.
Te podróbki różnią się od prostych manipulacji obrazami generowanych przez oprogramowanie do edycji, takie jak Photoshop, czy sprytnie zmanipulowane filmy z przeszłości.
Deepfake to najbardziej znany przykład „mediów syntetycznych” — obrazów, dźwięków i filmów, które wyglądają, jakby zostały wyprodukowane przy użyciu konwencjonalnych metod, ale w rzeczywistości zostały wykonane przy użyciu zaawansowanego oprogramowania.
Deepfake istnieją już od jakiegoś czasu i chociaż ich najpopularniejszym dotychczas zastosowaniem jest umieszczanie głów sławnych ludzi na ciałach aktorów w filmach pornograficznych, mają one możliwość tworzenia przekonujących materiałów, na których każdy robi cokolwiek i gdziekolwiek.
W tym poście przyjrzymy się Deepfakes, jak to działa, jak możesz je samodzielnie generować i wiele więcej.
Czym więc jest DeepFake?
Deepfake — połączenie słów deep learning i fake — to kawałek media syntetyczne w którym podobieństwo innej osoby jest używane do zastąpienia osoby na już istniejącej fotografii lub filmie.
Deepfake wykorzystują wyrafinowane techniki uczenia maszynowego i sztucznej inteligencji do modyfikowania i tworzenia informacji wizualnych i dźwiękowych, które mają wysoki potencjał oszustwa.
Metody głębokiego uczenia, takie jak autokodery i generatywne sieci adwersarzy, są podstawowym mechanizmem produkcji deepfake (GAN).
Modele te są wykorzystywane do analizy emocji i ruchów twarzy danej osoby oraz do syntezy zdjęć twarzy innych osób wykazujących porównywalne mimiki i ruchy.
Dużą uwagę przyciągnęło wykorzystywanie deepfake w filmach pornograficznych celebrytów, fałszywych wiadomościach, mistyfikacjach i oszustwach finansowych. Zarówno przemysł, jak i rząd zareagowali, próbując je znaleźć i ograniczyć ich użycie.
Model ruchu pierwszego rzędu
Podczas próby opracowania głębokich podróbek w przeszłości problem polegał na tym, że potrzebujemy jakiejś dodatkowej wiedzy lub priorytetów, aby te podejścia działały.
Na przykład, znaczniki twarzy są wymagane, jeśli chcemy śledzić ruch głowy. Estymacja pozycji była konieczna, jeśli chcieliśmy odwzorować ruch całego ciała.
Zmieniło się to na zeszłorocznej konferencji NeurIPS, kiedy zespół badawczy z Uniwersytetu w Toronto zaprezentował swoją pracę:Model ruchu pierwszego rzędu do animacji obrazu".
Do tego podejścia nie jest potrzebna dalsza znajomość animacji. Ponadto, po przeszkoleniu tego modelu, można go użyć do uczenia transferu i zastosować do dowolnego elementu należącego do tej samej kategorii.
Przyjrzyjmy się nieco dalej działaniu tej metody. Ekstrakcja i generacja ruchu to pierwsza połowa całego procesu. Jako dane wejściowe wykorzystywane są wideo z jazdy i obrazy źródłowe.
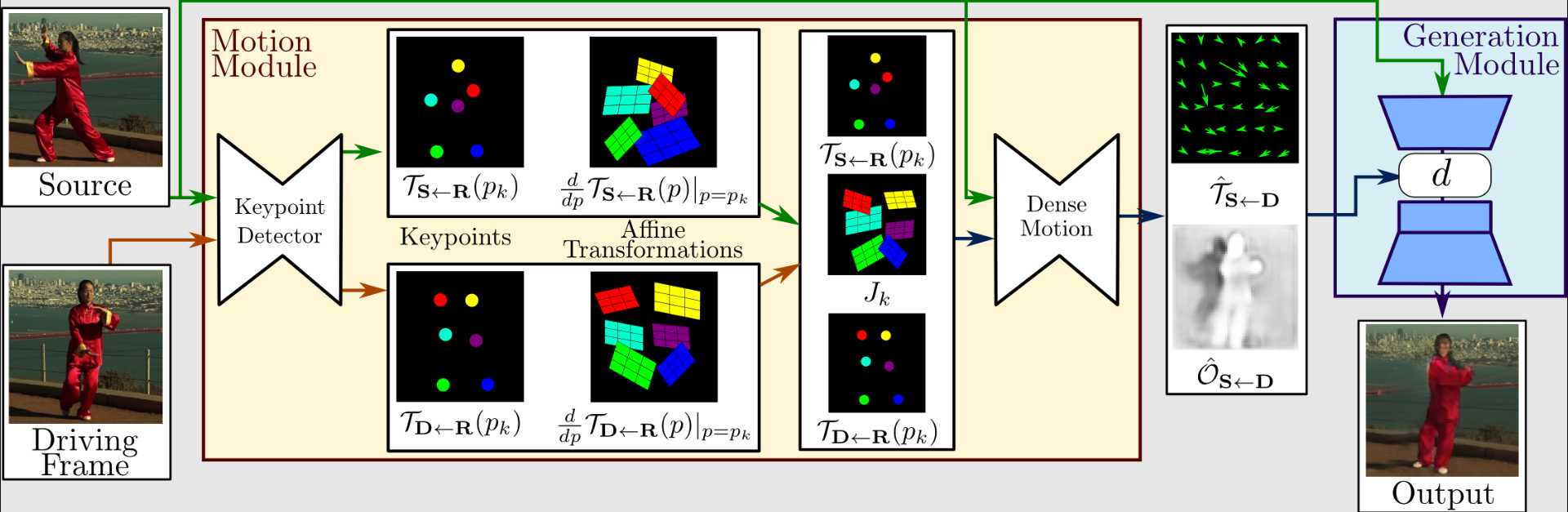
Aby wyodrębnić reprezentację ruchu pierwszego rzędu, która składa się z rzadkich punktów kluczowych i lokalnych przekształceń afinicznych, ekstraktor ruchu używa autokodera do identyfikacji punktów kluczowych.
Aby stworzyć gęstą mapę przepływu optycznego i okluzji z gęstą siecią ruchu, są one wykorzystywane wraz z wideo z jazdy. Generator następnie renderuje obraz docelowy, korzystając z danych wyjściowych z gęstej sieci ruchu i obrazu źródłowego.
Ogólnie rzecz biorąc, ta praca sprawdza się lepiej niż stan techniki. Zawiera również funkcje, których inne modele po prostu nie mają. Działa na kilku typach zdjęć, więc możesz zastosować go do zdjęć twarzy, ciała, kreskówek itp., Co jest niezwykle wspaniałe.
Stwarza to wiele nowych możliwości. Kolejnym przełomowym aspektem naszej strategii jest to, że pozwala ona teraz na tworzenie wysokiej jakości Deepfake przy użyciu tylko jednego obrazu obiektu docelowego, podobnie jak robimy to w przypadku YOLO dla obiektu uznanie.
Proces tworzenia modelu Deepfake
Do generowania deepfake potrzebne są trzy procesy: ekstrakcja, szkolenie i tworzenie. W tej sekcji zostaną omówione główne punkty każdego z tych etapów oraz ich związek z całym procesem.
Ekstrakcja
Deepfake wykorzystują głębokie sieci neuronowe do zmiany twarzy i potrzebują dużej ilości danych (zdjęć), aby działać poprawnie i przekonująco. Proces wyodrębniania to etap, na którym wyodrębniane są wszystkie klatki z klipów wideo, twarze są rozpoznawane, a następnie wyrównywane w celu zmaksymalizowania wydajności.
Trening
W fazie szkolenia sieci neuronowe może zmienić jedną twarz w drugą. W zależności od wielkości zestawu treningowego i gadżetu treningowego, trening może trwać kilka godzin, a nawet dni.
Szkolenie musi być ukończone tylko raz, podobnie jak większość innych szkoleń sieci neuronowych. Po przeszkoleniu model będzie w stanie zmienić twarz z osoby A na osobę B.
Tworzenie
Po wytrenowaniu modelu może zostać wygenerowany deepfake. Klatki są pobierane z filmu, a następnie dopasowywane do wszystkich twarzy. Wytrenowana sieć neuronowa jest następnie wykorzystywana do przekształcenia każdej klatki.
Przekształcona twarz musi zostać scalona z oryginalną ramką w ostatnim kroku.
Budowanie modelu wykrywania Deepfake
Montowanie i klonowanie repozytorium GitHub
Możliwość bezpłatnego korzystania z procesorów graficznych Google podczas pracy w Colab jest korzystna dla głęboka nauka. Dodatkową zaletą jest możliwość zamontowania Dysku Google na wirtualnej maszynie w chmurze (VM).
Dzięki łatwemu dostępowi do wszystkich swoich rzeczy, użytkownik jest włączony. Program potrzebny do zamontowania Dysku Google na maszynie wirtualnej w chmurze znajdziesz w tej sekcji.


Importowanie modułów
Teraz zaimportujemy wszystkie niezbędne moduły.
Wykonanie modelu
Posłużymy się przykładem, który łączy zdjęcie Putina (zdjęcie źródłowe) z wideo Obamy. Rezultatem jest wideo przedstawiające Putina mówiącego i gestykulującego z dokładnie tym samym wyrazem twarzy, którego używał Obama podczas prowadzenia samochodu.
Przed wyświetleniem wyniku modelu, media zostaną wczytane i zostaną zadeklarowane funkcje. Następnie zostaną załadowane punkty kontrolne i zostanie skonstruowany model. Po utworzeniu głębokiej podróbki zostaną wyświetlone dwa różne style animacji.
Putin jest animowany przez ruchy Obamy wykorzystujące względne przesunięcie kluczowych punktów. Sposób, w jaki emocje twarzy i język ciała Obamy są pięknie i wyraźnie przedstawiane przez Putina w jego filmach, jest zdumiewający.
Jest kilka mikroskopijnych błędów, szczególnie gdy Obama unosi brwi i mruga oczami. Te wyrażenia nie są dokładnie powtórzone w ramach Putina.
Bez podróbki w tle film Putina wydawałby się dość wiarygodny i autentyczny, gdyby był oglądany w telewizji lub Media społecznościowe.
Tworzenie modelu
Teraz użyjemy wstępnie wytrenowanych punktów kontrolnych, aby stworzyć kompletny model.
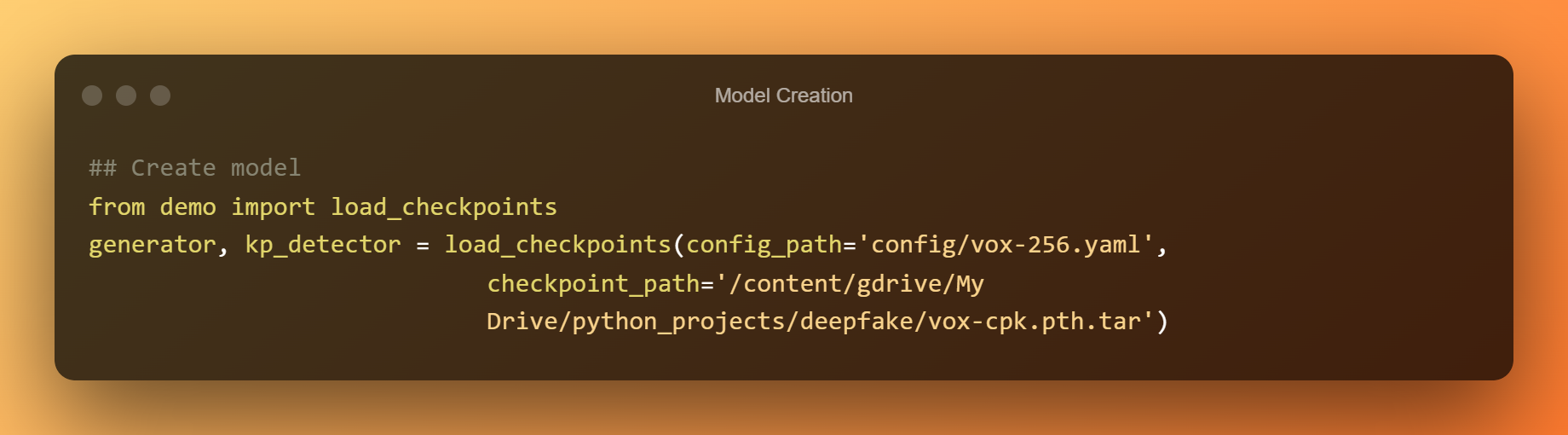
Wykrywanie deepfake'ów
Względne przesunięcie punktu kluczowego jest używane do animowania elementów w komórce poniżej. Następna komórka używa zamiast tego współrzędnych bezwzględnych, ale wszystkie proporcje przedmiotów zostaną w ten sposób pobrane z wideo z jazdy.
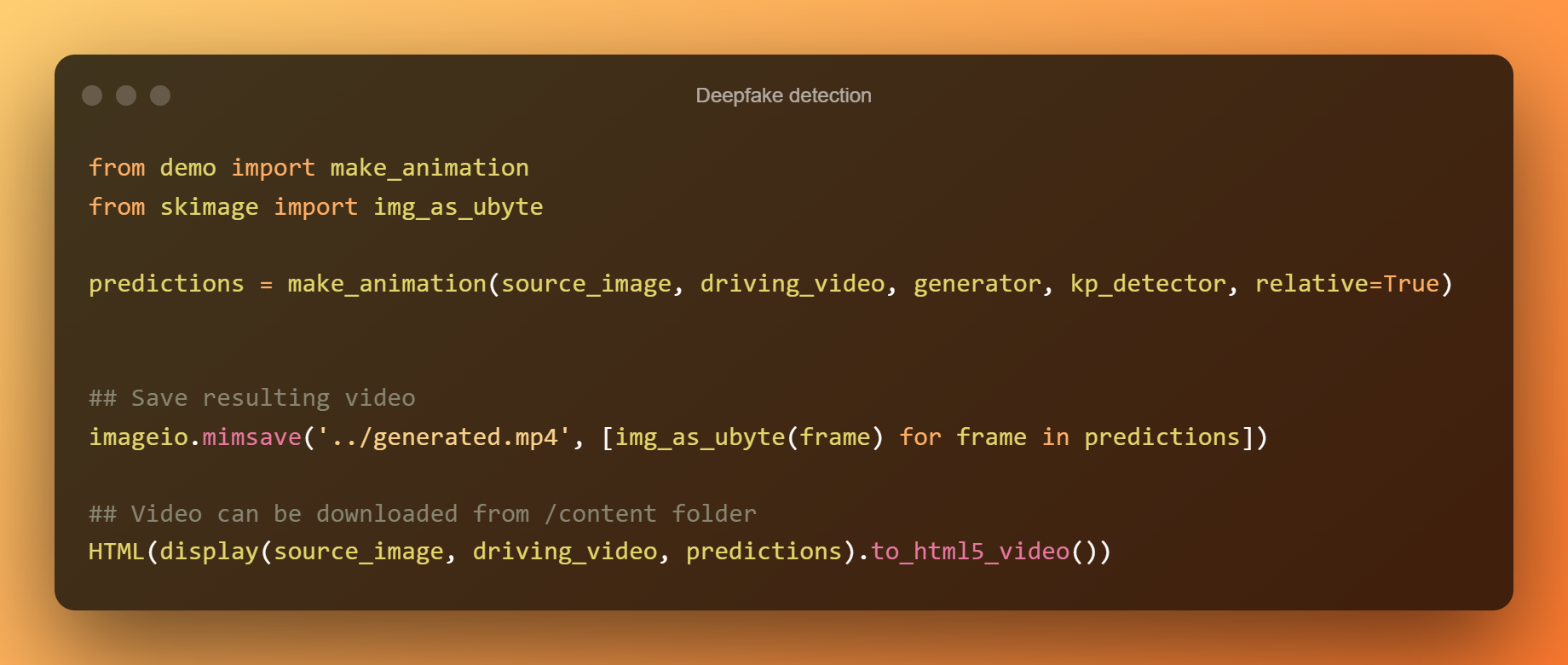
Zwiększanie wydajności przy użyciu współrzędnych bezwzględnych

W ten sposób będziesz mógł opracować wykrywanie deepfake.
Jakie są zagrożenia związane z technologią Deepfake?
Filmy Deepfake są teraz wciągające i zabawne do oglądania ze względu na ich nowość. Jednak pod powierzchnią tej pozornie zabawnej technologii istnieje ryzyko, które może wymknąć się spod kontroli.
Z pewnością trudno będzie odróżnić fałszywe od prawdziwych filmów, ponieważ technologia deepfake nadal się rozwija. Szczególnie w przypadku wybitnych osobistości i celebrytów może to mieć poważne skutki. Deepfake, które są celowo wrogie, mogą całkowicie zniszczyć karierę i życie.
Mogą być używane przez kogoś, kto ma złośliwe zamiary uchodzić za innych i wykorzystywać swoich przyjaciół, krewnych i współpracowników. Są również w stanie wywołać ogólnoświatowe kontrowersje, a nawet wojny, wykorzystując fałszywe filmy zagranicznych przywódców.
Wnioski
Podsumowując, jesteśmy w dziwnym okresie i niezwykłym środowisku. Bardziej niż kiedykolwiek, tworzenie i rozpowszechnianie fałszywych wiadomości i filmów jest proste. Zrozumienie, co jest prawdą, a co nie, staje się coraz większym wyzwaniem.
Dziś okazuje się, że nie możemy już polegać na własnych zmysłach.
Pomimo tego, że opracowano fałszywe detektory wideo, jest tylko kwestią czasu, kiedy luka informacyjna będzie tak mała, że nawet najlepsze fałszywe detektory nie będą w stanie określić, czy wideo jest prawdziwe, czy nie.





Dodaj komentarz