Struktura uczenia głębokiego składa się z kombinacji interfejsów, bibliotek i narzędzi do szybkiego i dokładnego definiowania i trenowania modeli uczenia maszynowego.
Ponieważ uczenie głębokie wykorzystuje dużą ilość nieustrukturyzowanych danych nietekstowych, potrzebujesz struktury, która kontroluje interakcję między „warstwami” i przyspiesza tworzenie modelu, ucząc się na podstawie danych wejściowych i podejmując autonomiczne decyzje.
Jeśli jesteś zainteresowany nauką o głębokim uczeniu się w 2021 r., rozważ skorzystanie z jednego ze wskazanych poniżej frameworków. Pamiętaj, aby wybrać taki, który pomoże Ci osiągnąć Twoje cele i wizję.
1. TensorFlow

Mówiąc o głębokim uczeniu się, TensorFlow jest często pierwszym wspomnianym frameworkiem. Bardzo popularny framework jest używany nie tylko przez Google – firmę odpowiedzialną za jego stworzenie – ale także przez inne firmy, takie jak Dropbox, eBay, Airbnb, Nvidia i wiele innych.
TensorFlow może być używany do tworzenia interfejsów API wysokiego i niskiego poziomu, co pozwala na uruchamianie aplikacji na prawie każdym urządzeniu. Chociaż Python jest jego podstawowym językiem, interfejs Tensoflow może być dostępny i kontrolowany za pomocą innych języków programowania, takich jak C++, Java, Julia i JavaScript.
Będąc open-source, TensorFlow pozwala na kilka integracji z innymi interfejsami API oraz szybkie wsparcie i aktualizacje od społeczności. Jego zależność od „wykresów statycznych” do obliczeń pozwala na natychmiastowe obliczenia lub zapisanie operacji w celu uzyskania dostępu w innym czasie. Te powody, w połączeniu z możliwością „obserwowania” rozwoju sieci neuronowej za pośrednictwem TensorBoard, sprawiają, że TensorFlow jest najpopularniejszym frameworkiem do głębokiego uczenia.
Podstawowe dane
- Open-source
- Elastyczność
- Szybkie debugowanie
2. PyTorch
PyTorch to framework opracowany przez Facebooka w celu wsparcia działania jego usług. Odkąd stał się open-source, framework ten był używany przez firmy inne niż Facebook, takie jak Salesforce i Udacity.
Ta struktura obsługuje dynamicznie aktualizowane wykresy, umożliwiając wprowadzanie zmian w architekturze zestawu danych podczas jego przetwarzania. Z PyTorch łatwiej jest rozwijać i trenować sieć neuronową, nawet bez doświadczenia w głębokim uczeniu.
Będąc open-source i opartym na Pythonie, możesz wykonywać proste i szybkie integracje z PyTorch. Jest to również prosty framework do nauki, używania i debugowania. Jeśli masz pytania, możesz liczyć na świetne wsparcie i aktualizacje od obu społeczności – społeczności Pythona i społeczności PyTorch.
Podstawowe dane
- Łatwe do nauki
- Obsługuje GPU i CPU
- Bogaty zestaw API do rozbudowy bibliotek
3. Apache MX Net

Ze względu na wysoką skalowalność, wysoką wydajność, szybkie rozwiązywanie problemów i zaawansowaną obsługę GPU, framework ten został stworzony przez Apache do użytku w dużych projektach przemysłowych.
MXNet zawiera interfejs Gluon, który pozwala programistom na wszystkich poziomach umiejętności zacznij od głębokiego uczenia w chmurze, na urządzeniach brzegowych i w aplikacjach mobilnych. W zaledwie kilku linijkach kodu Gluon możesz zbudować regresję liniową, sieci splotowe i powtarzalne LSTM dla wykrywanie obiektów, rozpoznawanie mowy, rekomendacje i personalizacja.
MXNet może być używany na różnych urządzeniach i jest obsługiwany przez kilka języki programowania takich jak Java, R, JavaScript, Scala i Go. Chociaż liczba użytkowników i członków w jego społeczności jest niewielka, MXNet ma dobrze napisaną dokumentację i duży potencjał wzrostu, szczególnie teraz, gdy Amazon wybrał ten framework jako podstawowe narzędzie do uczenia maszynowego w AWS.
Podstawowe dane
- 8 wiązań językowych
- Szkolenie rozproszone, obsługujące systemy wieloprocesorowe i wielo-GPU
- Hybrydowy front-end, pozwalający na przełączanie między trybami imperatywnymi i symbolicznymi
4. Zestaw narzędzi poznawczych firmy Microsoft
Jeśli myślisz o tworzeniu aplikacji lub usług działających na platformie Azure (usługi w chmurze firmy Microsoft), zestaw narzędzi Microsoft Cognitive Toolkit to platforma do wyboru dla projektów uczenia głębokiego. Jest to oprogramowanie typu open source, obsługiwane między innymi przez języki programowania, takie jak Python, C++, C#, Java. Ta struktura została zaprojektowana tak, aby „myśleć jak ludzki mózg”, dzięki czemu może przetwarzać duże ilości nieustrukturyzowanych danych, oferując jednocześnie szybkie szkolenie i intuicyjną architekturę.
Wybierając ten framework – ten sam, który stoi za Skype, Xbox i Cortana – uzyskasz dobrą wydajność swoich aplikacji, skalowalność i prostą integrację z Azure. Jednak w porównaniu z TensorFlow lub PyTorch liczba członków społeczności i wsparcia jest zmniejszona.
Poniższy film przedstawia pełne wprowadzenie i przykłady zastosowań:
Podstawowe dane
- Przejrzysta dokumentacja
- Wsparcie zespołu Microsoft
- Bezpośrednia wizualizacja wykresu
5. Keras

Podobnie jak PyTorch, Keras jest biblioteką opartą na Pythonie do projektów wymagających dużej ilości danych. Keras API działa na wysokim poziomie i umożliwia integrację z niskopoziomowymi interfejsami API, takimi jak TensorFlow, Theano i Microsoft Cognitive Toolkit.
Niektóre zalety korzystania z keras to prostota uczenia się – jest to zalecana platforma dla początkujących w głębokim uczeniu; jego szybkość rozmieszczania; mając duże wsparcie ze strony społeczności Pythona i społeczności innych frameworków, z którymi jest zintegrowany.
Keras zawiera różne implementacje elementy budulcowe sieci neuronowych takie jak warstwy, funkcje celu, funkcje aktywacji i optymalizatory matematyczne. Jego kod jest hostowany na GitHub i istnieją fora i kanał wsparcia Slack. Oprócz obsługi standardu sieci neuronoweKeras oferuje obsługę splotowych sieci neuronowych i rekurencyjnych sieci neuronowych.
Keras pozwala modele uczenia głębokiego do generowania na smartfonach z systemem iOS i Android, na wirtualnej maszynie Java lub w Internecie. Pozwala również na wykorzystanie rozproszonego szkolenia modeli głębokiego uczenia się w klastrach jednostek przetwarzania grafiki (GPU) i jednostek przetwarzania tensorów (TPU).
Podstawowe dane
- Wstępnie wytrenowane modele
- Obsługa wielu backendów
- Przyjazne dla użytkownika i duże wsparcie społeczności
6. Rdzeń jabłkowy ML
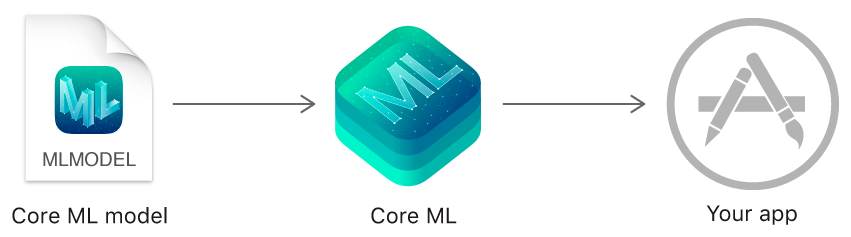
Core ML został opracowany przez Apple, aby wspierać jego ekosystem — IOS, Mac OS i iPad OS. Jego interfejs API działa na niskim poziomie, dobrze wykorzystując zasoby procesora i karty graficznej, co pozwala stworzonym modelom i aplikacjom działać nawet bez połączenia z Internetem, co zmniejsza zużycie pamięci i zużycie energii przez urządzenie.
Sposób, w jaki Core ML osiąga to, nie polega dokładnie na tworzeniu kolejnej biblioteki uczenia maszynowego, która jest zoptymalizowana do działania na iPhone'ach/ipadach. Zamiast tego Core ML przypomina bardziej kompilator, który pobiera specyfikacje modelu i wytrenowane parametry wyrażone za pomocą innego oprogramowania do uczenia maszynowego i konwertuje je na plik, który staje się zasobem dla aplikacji na iOS. Ta konwersja do modelu Core ML odbywa się podczas tworzenia aplikacji, a nie w czasie rzeczywistym, gdy aplikacja jest używana, i jest ułatwiana przez bibliotekę coremltools Python.
Core ML zapewnia wysoką wydajność i łatwą integrację uczenie maszynowe modele w aplikacje. Obsługuje głębokie uczenie z ponad 30 typami warstw, a także drzewami decyzyjnymi, maszynami wektorów pomocniczych i metodami regresji liniowej, a wszystko to oparte na technologiach niskiego poziomu, takich jak Metal i Accelerate.
Podstawowe dane
- Łatwa integracja z aplikacjami
- Optymalne wykorzystanie lokalnych zasobów, niewymagające dostępu do internetu
- Prywatność: dane nie muszą opuszczać urządzenia
7. ONNX

Ostatnim frameworkiem na naszej liście jest ONNX. Ramy te powstały w wyniku współpracy między Microsoft i Facebookiem w celu uproszczenia procesu przenoszenia i budowania modeli między różnymi platformami, narzędziami, środowiskami wykonawczymi i kompilatorami.
ONNX definiuje wspólny typ pliku, który może działać na wielu platformach, jednocześnie wykorzystując zalety interfejsów API niskiego poziomu, takich jak Microsoft Cognitive Toolkit, MXNet, Caffe i (przy użyciu konwerterów) Tensorflow i Core ML. Zasadą ONNX jest wytrenowanie modelu na stosie i zaimplementowanie go przy użyciu innych wniosków i prognoz.
Fundacja LF AI, podorganizacja Linux Foundation, jest organizacją zajmującą się budowaniem ekosystemu do wsparcia open-source innowacje w sztucznej inteligencji (AI), uczeniu maszynowym (ML) i uczeniu głębokim (DL). Dodano ONNX jako projekt dla absolwentów w dniu 14 listopada 2019 r. Ten ruch ONNX pod patronatem Fundacji LF AI był postrzegany jako ważny kamień milowy w ustanowieniu ONNX jako neutralnego dla dostawców standardu otwartego formatu.
ONNX Model Zoo to kolekcja wstępnie wytrenowanych modeli w Deep Learningu dostępnych w formacie ONNX. Dla każdego modelu istnieją Zeszyty Jupyter do trenowania modeli i przeprowadzania wnioskowania z wyszkolonym modelem. Notatniki są napisane w Pythonie i zawierają linki do zbiór danych treningowych oraz odniesienia do oryginalnego dokumentu naukowego opisującego architekturę modelu.
Podstawowe dane
- Interoperacyjność ramowa
- Optymalizacja sprzętu
Wnioski
To jest podsumowanie najlepszych frameworków dla głęboka nauka. Istnieje kilka ram do tego celu, darmowych lub płatnych. Aby wybrać najlepszą dla swojego projektu, najpierw dowiedz się, na jaką platformę będziesz rozwijać swoją aplikację.
Na początek najlepsze są ogólne frameworki, takie jak TensorFlow i Keras. Ale jeśli potrzebujesz skorzystać z zalet systemu operacyjnego lub konkretnych urządzeń, najlepszymi opcjami mogą być Core ML i Microsoft Cognitive Toolkit.
Istnieją inne frameworki przeznaczone dla urządzeń z Androidem, innych maszyn i konkretnych celów, które nie zostały wymienione na tej liście. Jeśli ta druga grupa Cię interesuje, sugerujemy wyszukanie jej informacji w Google lub innych witrynach opartych na uczeniu maszynowym.





Dodaj komentarz