Przenoszenie i przechowywanie danych zyskało na znaczeniu w wyniku ciągłego rozwoju branży IT i milionów punktów danych generowanych w każdej sekundzie.
Ponadto dane te muszą być jasne i łatwe do zrozumienia, aby wspierać precyzyjne podejmowanie decyzji.
Aby utrzymać konkurencyjność i osiągnąć długotrwały sukces, Twoja firma musi przechowywać i przenosić dane przy użyciu najbardziej wydajnych dostępnych rozwiązań.
Z tego powodu coraz więcej firm korzysta z sieci danych. Jednym z najlepszych sposobów na zaoszczędzenie czasu, pieniędzy i zasobów jest wykorzystanie struktury danych do przetwarzania danych i umożliwienie uczenia maszynowego AI.
W tym artykule przyjrzymy się szczegółowo Data Fabric, w tym jego zastosowaniom, głównym komponentom, zaletom i innym istotnym szczegółom.
Czym więc jest Data Fabric?
Niezależnie od tego, gdzie się znajdują, zarządzaj i kontroluj swoje dane i aplikacje. U podstaw struktury danych jest zintegrowana architektura danych, która jest bezpieczna, wszechstronna i elastyczna.
Sieć szkieletowa danych, która łączy w sobie to, co najlepsze w chmurze, rdzeniu i krawędzi, jest pod wieloma względami nowym strategicznym podejściem do operacji pamięci masowej w firmie.
Będąc centralnie kontrolowanym, może dotrzeć wszędzie, w tym lokalnie, w chmurach publicznych i prywatnych, a także na urządzeniach brzegowych i IoT.
Silosy danych wielkości drapaczy chmur i zróżnicowana, niepołączona infrastruktura to już przeszłość. Sieć danych opiera się na wszechstronnym zbiorze narzędzi do zarządzania danymi, które gwarantują spójność we wszystkich połączonych środowiskach.
Dzięki automatyzacji usprawnia czasochłonne zarządzanie, przyspiesza opracowywanie, testowanie i wdrażanie oraz chroni Twoje zasoby przez całą dobę.
Bez względu na to, gdzie znajdują się Twoje dane i aplikacje, możesz śledzić wydatki na pamięć masową, wydajność i efektywność z jednej platformy.
Możesz szybko (a w niektórych przypadkach automatycznie) wprowadzać zmiany w infrastrukturze chmury hybrydowej, gdy uzyskasz praktyczną wiedzę na jej temat, na przykład naprawianie błędów, rozwiązywanie problemów związanych z bezpieczeństwem i zgodnością oraz skalowanie w górę i w dół.
W skrócie, Data Fabric poprawia wydajność wdrażania i konserwacji infrastruktury, obniża koszty i zwiększa wydajność.
Dlaczego warto korzystać z Data Fabric?
Każda firma zorientowana na dane potrzebuje kompleksowej strategii, która pokona przeszkody, takie jak czas, przestrzeń, różne rodzaje oprogramowania i lokalizacje danych. Dane nie powinny być ukryte za zaporami ogniowymi ani rozproszone w kilku miejscach, ale powinny być dostępne dla osób, które ich potrzebują.
Aby odnieść sukces, firmy potrzebują przyszłościowego rozwiązania danych oraz bezpiecznego, efektywnego i ujednoliconego środowiska. Można to zrobić za pomocą struktury danych.
Potrzeby nowoczesnych firm w zakresie połączeń w czasie rzeczywistym, samoobsługi, automatyzacji i uniwersalnych zmian nie mogą zostać zaspokojone przez tradycyjną integrację danych.
Chociaż zbieranie danych z wielu źródeł często nie stanowi problemu, wiele firm ma trudności z integracją, przetwarzaniem, przechowywaniem i przekształcaniem danych za pomocą danych z innych źródeł.
Aby zapewnić dogłębne zrozumienie konsumentów, partnerów i towarów, ten krytyczny krok w procesie zarządzania danymi musi mieć miejsce. Ze względu na ich zdolność do ulepszania swoich systemów, lepszej obsługi klientów i korzystania z cloud computingw rezultacie firmy zyskują przewagę konkurencyjną.
Wszędzie tam, gdzie znajdują się użytkownicy organizacji, tkaninę danych można sobie wyobrazić jako tkaninę, która jest rozłożona na całym świecie. W tej sieci użytkownik może znajdować się w dowolnym miejscu i nadal mieć nieograniczony dostęp do danych w czasie rzeczywistym w dowolnym innym miejscu.
Podstawowe składniki sieci danych
Podstawowe komponenty tworzące strukturę danych można wybierać i gromadzić na różne sposoby. Tkanina danych może być zatem realizowana na różne sposoby. Przyjrzyjmy się podstawowym elementom struktury danych.
- Rozszerzony katalog danych
- Warstwa trwałości
- Wykres Wiedza
- Silnik spostrzeżeń i rekomendacji
- Warstwa przygotowania i dostarczania danych
- Orkiestracja i operacje danych
Możesz przyjrzeć się kluczowym filarom architektury Data Fabric według Gartner.
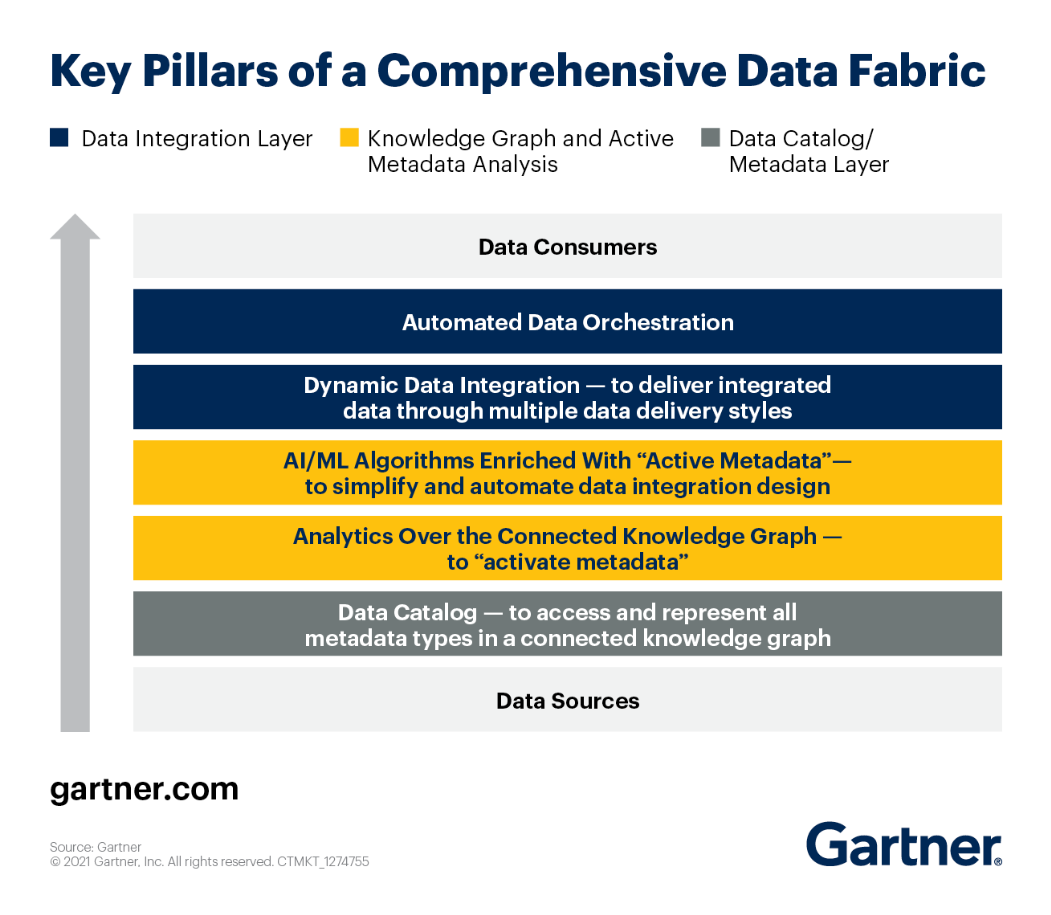
Przyjrzyjmy się każdemu z nich z bliska.
- Rozszerzony katalog danych – daje użytkownikom dostęp do wszelkiego rodzaju metadanych za pośrednictwem silnego wykresu wiedzy. Dodatkowo tworzy charakterystyczne skojarzenia między istniejącymi informacjami i wizualnie pokazuje je w zrozumiały sposób. Używając uczenie maszynowe Aby połączyć zasoby danych z terminologią organizacyjną, ulepszone katalogi danych tworzą biznesową warstwę semantyczną dla struktury danych.
- Warstwa trwałości – W zależności od przypadku użycia do dynamicznego przechowywania danych można użyć różnych modeli relacyjnych i nierelacyjnych.
- Aktywne metadane – wyróżniający się element tkaniny danych. daje tkaninie danych możliwość gromadzenia, udostępniania i analizowania wielu rodzajów metadanych. W przeciwieństwie do metadanych pasywnych, metadane aktywne śledzą bieżące wykorzystanie danych przez systemy i osoby (metadane projektowe i wykonawcze).
- Wykres Wiedza – Kolejna podstawowa jednostka dla data fabrics. Używają standardowych identyfikatorów, adaptowalnych schematów itp. do wyświetlania połączonego środowiska danych. Wykresy wiedzy umożliwiają przeszukiwanie struktury danych i pomagają w jej zrozumieniu.
- System analiz i rekomendacji – buduje niezawodne, silne potoki danych zarówno dla operacyjnych, jak i analitycznych przypadków użycia.
- Warstwa przygotowania i dostarczania danych – Dane mogą być pobierane z dowolnego źródła i wysyłane do dowolnego celu przy użyciu dowolnego mechanizmu, w tym ETL (luzem), przesyłania wiadomości, CDC, wirtualizacji i API.
- Orkiestracja i operacje danych – Ten komponent wykorzystuje dane do koordynowania wszystkich zadań na każdym etapie kompleksowego przepływu pracy. Pozwala wybrać, kiedy i jak często uruchamiać potoki, a także jak zarządzać danymi generowanymi przez te potoki.
Benefity
Zdrowe dane w kontekście rozproszonym są dostępne, ładowane, integrowane i udostępniane za pośrednictwem sieci szkieletowej danych. W ten sposób firmy mogą przyspieszyć cyfrową transformację i zmaksymalizować wartość swoich danych.
Poniżej przedstawiono najważniejsze zalety modelu Data Fabric.
Wydajność:
Struktura danych może kompilować wyniki z wcześniejszych zapytań, umożliwiając systemowi skanowanie zagregowanej tabeli zamiast nieprzetworzonych danych w zapleczu.
Ze względu na krótsze czasy odpowiedzi poszczególnych żądań, umożliwienie żądaniom dostępu do mniejszych zbiorów danych zamiast konieczności skanowania nieprzetworzonych danych całego sklepu również rozwiązuje problem kilku równoczesnych żądań.
Przedsiębiorstwa mogą szybko odpowiadać na naglące zapytania, ponieważ struktura danych umożliwia znaczne skrócenie czasu odpowiedzi na zapytania.
Inteligentna integracja
Aby zintegrować dane z różnych rodzajów danych i punktów końcowych, struktury danych wykorzystują semantyczne grafy wiedzy, zarządzanie metadanymi i uczenie maszynowe.
Pomaga to zespołom zarządzającym danymi w grupowaniu odpowiednich zestawów danych i włączaniu zupełnie nowych źródeł danych do ekosystemu danych firmy.
Ta funkcja automatyzuje części zarządzania zadaniami związanymi z danymi, co skutkuje oszczędnościami produktywności wskazanymi powyżej, ale pomaga również w rozbiciu silosów systemu danych, centralizacji procedur zarządzania danymi i poprawie ogólnej jakości danych.
Skuteczniejsze bezpieczeństwo danych
Nie oznacza to również poświęcania bezpieczeństwa danych i ochrony prywatności w celu rozszerzenia dostępu do danych.
W rzeczywistości wymaga to zaostrzenia barier kontroli dostępu i wdrożenia większej liczby środków zarządzania danymi, aby zagwarantować, że niektóre role są jedynymi, które mają dostęp do danego zestawu danych.
Ponadto architektury sieci szkieletowej danych umożliwiają techniczne i bezpieczeństwa do wdrożenia maskowania danych i szyfrowanie wokół poufnych i wrażliwych informacji, zmniejszając prawdopodobieństwo udostępniania danych i włamań do systemu.
Demokratyzacja danych
Aplikacje samoobsługowe są ułatwione dzięki projektom struktury danych, rozszerzając zasięg dostępu do danych poza personel techniczny, taki jak inżynierowie danych, programiści i zespoły zajmujące się analizą danych.
Pozwalając użytkownikom biznesowym na dokonywanie szybszych wyborów biznesowych i pozwalając użytkownikom technicznym na nadawanie priorytetów działaniom, które najlepiej wykorzystują ich umiejętności, eliminacja wąskich gardeł danych prowadzi do wzrostu produktywności.
Przypadków użycia
Architektura struktury Data Fabric ma oferować nadrzędną strukturę do obsługi wszystkich form przechowywanych informacji, tak aby można je było wykorzystać w razie potrzeby.
Tego rodzaju danych można używać do dowolnych celów, od prognoz sprzedaży po raport o stanie infrastruktury IT organizacji lub punktów końcowych użytkowników.
Przypadki użycia architektury Data Fabric są identyczne jak przypadki użycia dla każdego innego rodzaju danych w firmie, w tym sprzedaży, marketingu, IT, cyberbezpieczeństwa i innych.
Jednak dane w organizacji są często zorganizowane, częściowo ustrukturyzowane lub nieustrukturyzowane w prawie wszystkich przypadkach użycia. Relacyjna baza danych może przechowywać dane strukturalne i być niezwłocznie wykorzystywana, na przykład rekordy bazy danych.
Dane, które nie zostały wyczyszczone lub skategoryzowane, są określane jako dane nieustrukturyzowane i muszą być przygotowane do użycia w razie potrzeby.
Kilka form nieustrukturyzowanych danych, które wiele firm może pozyskiwać i przechowywać do wykorzystania w przyszłości, obejmuje: uczenie maszynowe, analityka, dane z czujników, przetwarzanie w chmurze i aplikacje zwiększające produktywność.
W danych częściowo ustrukturyzowanych, które obejmują dane uznanego rodzaju zapisane z danymi nieustrukturyzowanymi (takimi jak pliki zip, strony internetowe i wiadomości e-mail), występują oba aspekty.
Liczne możliwe przypadki użycia oparte na zdolności struktury danych do wspomagania firm w szybszym i efektywnym dostępie do danych i ich wykorzystaniu można znaleźć, badając ich wykorzystanie.
Typowe przykłady to:
- Wykrywanie oszustw
- Analityka IoT
- Logistyka łańcucha dostaw
- Analiza danych w czasie rzeczywistym
- Inteligencja klienta
- Wzrost efektywności operacyjnej
- Analiza konserwacji prewencyjnej
- Dodatkowo modele ryzyka powrotu do pracy
- Zabezpieczanie transakcji kartami kredytowymi
- Przewidywanie rezygnacji, wykrywanie oszustw i ocena kredytowa
Wnioski
Podsumowując, silosy danych muszą się stopniowo rozpadać w miarę wzrostu poziomu wykorzystania danych, aby zrobić miejsce dla połączonych firm.
Wdrożenie struktur danych stanowi znaczący postęp na tej ścieżce, plasując się wśród najbardziej przełomowych odkryć od czasu rozwoju relacyjnych baz danych w latach 1970. XX wieku.
Dzieje się tak, ponieważ struktura danych to coś więcej niż technologia czy pojedynczy element.
Dane i operacje biznesowe są misternie splecione przez projekt architektury, systematyczną procedurę i zmianę mentalności.
Data Fabric obniża koszty, zwiększa wydajność i ułatwia bardziej efektywne wdrażanie i konserwację infrastruktury. Może być kluczowym elementem zapewniającym, że każdy proces, aplikacja i decyzja biznesowa są oparte na danych.





Dodaj komentarz