Spis treści[Ukryć][Pokazać]
- 1. Czym jest skryptowanie w Pythonie i czym różni się od programowania w Pythonie?
- 2. Jak działa zbieranie śmieci w Pythonie?
- 3. Wyjaśnij różnicę pomiędzy listą a krotką
- 4. Co to są wyrażenia listowe i podaj przykład ich użycia?
- 5. Opisz różnicę pomiędzy deepcopy i copy?
- 6. Jak w Pythonie realizowana jest wielowątkowość i czym różni się ona od wieloprocesorowości?
- 7. Czym są dekoratory i jak się ich używa w Pythonie?
- 8. Wyjaśnij różnice pomiędzy *args i **kwargs?
- 9. Jak zapewnić, że funkcja będzie mogła zostać wywołana tylko raz przy użyciu dekoratorów?
- 10. Jak działa dziedziczenie w Pythonie?
- 11. Co to jest przeciążanie i zastępowanie metod?
- 12. Opisz pojęcie polimorfizmu na przykładzie.
- 13. Wyjaśnij różnicę pomiędzy instancjami, klasami i metodami statycznymi.
- 14. Opisz, jak wewnętrznie działa zestaw Pythona.
- 15. Jak zaimplementowano słownik w Pythonie?
- 16. Wyjaśnij korzyści płynące ze stosowania nazwanych krotek.
- 17. Jak działa blok try-except?
- 18. Jaka jest różnica pomiędzy instrukcjami raise i Assert?
- 19. Jak czytać i zapisywać dane z pliku binarnego w Pythonie?
- 20. Wyjaśnij instrukcję with i jej zalety podczas pracy z operacjami we/wy plików.
- 21. Jak utworzyłbyś moduł singletonowy w Pythonie?
- 22. Wymień kilka sposobów optymalizacji wykorzystania pamięci w skrypcie Pythona.
- 23. Jak wyodrębnić wszystkie adresy e-mail z danego ciągu za pomocą wyrażenia regularnego?
- 24. Wyjaśnij wzorzec projektowy Factory i jego zastosowanie w Pythonie
- 25. Jaka jest różnica pomiędzy iteratorem a generatorem?
- 26. Jak działa dekorator @property?
- 27. Jak stworzyłbyś podstawowy interfejs API REST w Pythonie?
- 28. Opisz, jak używać biblioteki żądań do tworzenia żądania HTTP POST.
- 29. Jak połączyć się z bazą danych PostgreSQL za pomocą Pythona?
- 30. Jaka jest rola ORM w Pythonie i podaj jakiś popularny?
- 31. Jak sprofilowałbyś skrypt w Pythonie?
- 32. Wyjaśnij GIL (Global Interpreter Lock) w CPythonie
- 33. Wyjaśnij funkcję async/await w Pythonie. Czym różni się od tradycyjnego gwintowania?
- 34. Opisz, w jaki sposób użyłbyś concurrent.futures w Pythonie.
- 35. Porównaj Django i Flask pod względem przypadków użycia i skalowalności.
- Wnioski
W czasach, gdy technologia jest obecna w każdym aspekcie naszego życia, Python skrypty jawią się jako kluczowy element ogromnej i skomplikowanej infrastruktury IT, ustanawiając paradygmat łatwości użycia i użyteczności.
Siła Pythona leży nie tylko w jego prostocie składniowej i czytelności, ale także w jego możliwościach adaptacji, co pozwala mu z łatwością wypełnić lukę pomiędzy tworzeniem skryptów o niskim ryzyku dla początkujących a tworzeniem oprogramowania na poziomie korporacyjnym, obarczonym wysokimi stawkami.
Szerokie biblioteki i frameworki Pythona torują drogę płynnej, pomysłowej przygodzie technicznej, czy to w obszarach analizy danych, tworzenia stron internetowych, sztucznej inteligencji czy serwerów sieciowych.
Oprócz tego, że jest narzędziem do rozwiązywania problemów, Python stwarza także atmosferę, w której innowacje są nie tylko akceptowane, ale także w naturalny sposób włączane dzięki ogromnym bibliotekom i frameworkom, takim jak Django do tworzenia stron internetowych lub Pandas do analizy danych.
W świecie, w którym królują dane, Python zapewnia potężne narzędzia do manipulowania, analizowania i... wizualizacja danych, co skutkuje praktycznymi spostrzeżeniami i wskazówkami dla strategicznych wyborów.
Python to nie tylko język programowania; to także prężnie rozwijająca się społeczność, centrum, w którym programiści, badacze danych i entuzjaści technologii spotykają się, aby wymyślać, tworzyć i przenosić branżę IT na wyższy poziom.
Programiści Pythona są poszukiwani przez firmy każdej wielkości, od raczkujących start-upów po organizacje o ugruntowanej pozycji, jako katalizatory innowacji, ulepszania procesów i lepszej obsługi klienta.
Ponadto jego charakter typu open source sprzyja kulturze wspólnego uczenia się i wspólnego rozwoju, gwarantując dalszy rozwój wraz z szybko zmieniającym się światem technologii.
Nauka języka Python w roku 2023 to inwestycja w język, który obiecuje pozostać aktualny, elastyczny i niezbędny do zarządzania przypływami i odpływami technologii.
Daje dostęp do pól uczenie maszynowe, analityka danych, cyberbezpieczeństwo i nie tylko, a wszystkie one mają kluczowe znaczenie dla kształtowania ery cyfrowej.
Dlatego przygotowaliśmy dla Ciebie listę najlepszych pytań do rozmowy kwalifikacyjnej na temat skryptowania Pythona, dzięki którym zabłyśniesz jako programista i pomyślnie przejdziesz rozmowę kwalifikacyjną.
1. Czym jest skryptowanie w Pythonie i czym różni się od programowania w Pythonie?
Python jest znany ze swoich możliwości adaptacyjnych i zapewnia zarówno umiejętności pisania skryptów, jak i programowania, każdy dostosowany do konkretnego zadania i celów.
Skrypty w języku Python to zasadniczo proces pisania krótszych, bardziej wydajnych skryptów, których zadaniem jest zarządzanie plikami, automatyzacja powtarzalnych procesów lub szybkie prototypowanie pomysłów.
Skrypty te, często samodzielne, skutecznie wykonują listę działań w określonej kolejności.
Z kolei programowanie w Pythonie idzie dalej, kładąc nacisk na tworzenie większych, bardziej skomplikowanych programów z ustrukturyzowanym kodem przy użyciu bibliotek, frameworków i najlepszych praktyk.
Chociaż oba pochodzą z tego samego języka, skrypty upraszczają i automatyzują, podczas gdy programowanie tworzy i wymyśla. Różnicę tę widać w zakresie i celach poszczególnych dyscyplin.
2. Jak działa zbieranie śmieci w Pythonie?
Kluczowym elementem zapewniającym efektywne zarządzanie pamięcią jest system usuwania śmieci w Pythonie.
Niestrudzenie działa w tle, chroniąc zasoby systemowe przed przepełnieniem w wyniku wycieków pamięci. To zautomatyzowane podejście opiera się głównie na metodzie zliczania odniesień, w której każdy obiekt śledzi, ile innych obiektów się do niego odwołuje.
Obiekt ten staje się kandydatem do odzyskania pamięci, gdy liczba ta spadnie do 0, co oznacza, że element nie jest już potrzebny.
Ponadto Python używa cyklicznego modułu zbierającego elementy bezużyteczne, którego proste podejście polegające na liczeniu odwołań może pominąć, aby znaleźć i wyczyścić cykle odwołań.
Zatem dwuwarstwowa strategia zliczania referencji i cyklicznego usuwania śmieci zapewnia ostrożne i efektywne wykorzystanie pamięci, zwiększając wydajność Pythona, szczególnie w aplikacjach intensywnie korzystających z pamięci.
Poniżej znajduje się prosty przykładowy kod pokazujący, jak połączyć się z systemem usuwania śmieci w Pythonie:
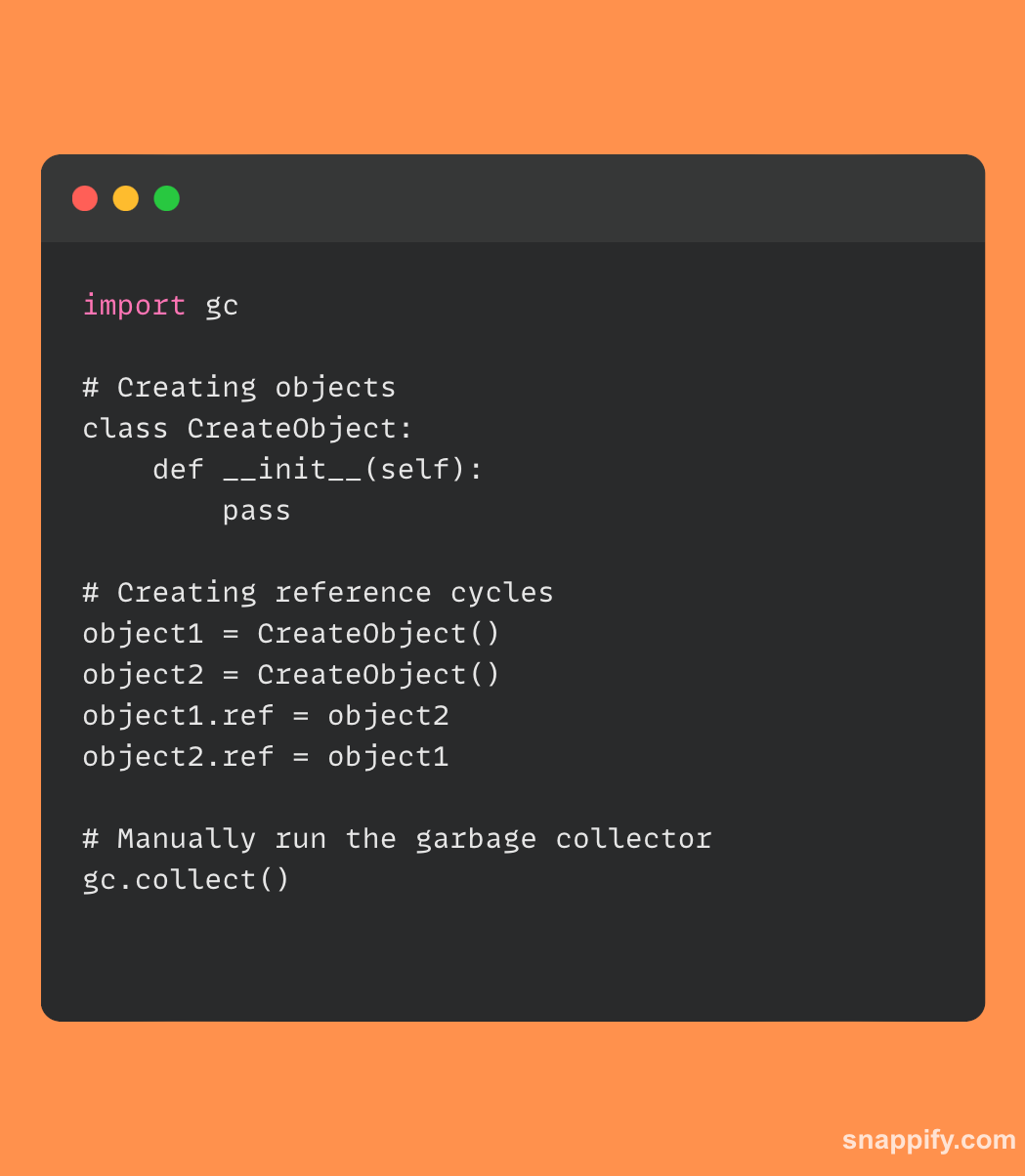
W tym fragmencie wygenerowano dwa obiekty, które powiązano ze sobą w celu ustalenia cyklu. Następnie moduł zbierający elementy bezużyteczne jest uruchamiany ręcznie za pomocą gc.collect(), co pokazuje, w jaki sposób programiści mogą w razie potrzeby korzystać z mechanizmu zarządzania pamięcią Pythona.
3. Wyjaśnij różnicę pomiędzy listą a krotką
Listy i krotki są skutecznymi pojemnikami na dane w świecie Pythona, ale mają różne właściwości, które odpowiadają różnym celom programistycznym.
Lista oznaczona nawiasami kwadratowymi zapewnia elastyczność, umożliwiając zmianę i dynamiczną zmianę rozmiaru jej komponentów.
Z kolei krotka ujęta w nawias jest niezmienna i zachowuje swój stan początkowy podczas wykonywania funkcji.
Krotki zapewniają solidną, niezmienną sekwencję, podczas gdy listy oferują elastyczność, pozwalając na różnorodne zastosowania w przetwarzaniu i modyfikacji danych.
Oto trochę Kod Pythona przykład pokazujący, jak używać zarówno list, jak i krotek:

4. Co to są wyrażenia listowe i podaj przykład ich użycia?
Rozumienie list to skuteczny i ekspresyjny sposób tworzenia list w Pythonie, który łączy w sobie możliwości logiki warunkowej i pętli w jeden, zrozumiały wiersz kodu.
Zapewniają uproszczoną składnię do przekształcania naszych intencji w listę, łącząc iterację i warunkowość w jedną, wyrafinowaną strukturę.
Rozumienie list zasadniczo daje programistom możliwość tworzenia list poprzez wykonywanie operacji na każdym elemencie i być może filtrowanie ich w zależności od określonych kryteriów, a wszystko to przy zachowaniu porządku w bazie kodu.
Ta wyrazista funkcja łączy wydajność z przejrzystością programowania w języku Python, poprawiając czytelność, a jednocześnie w pewnych okolicznościach zapewniając korzyści obliczeniowe.
Poniżej przedstawiono ilustrację rozumienia listy w języku Python:
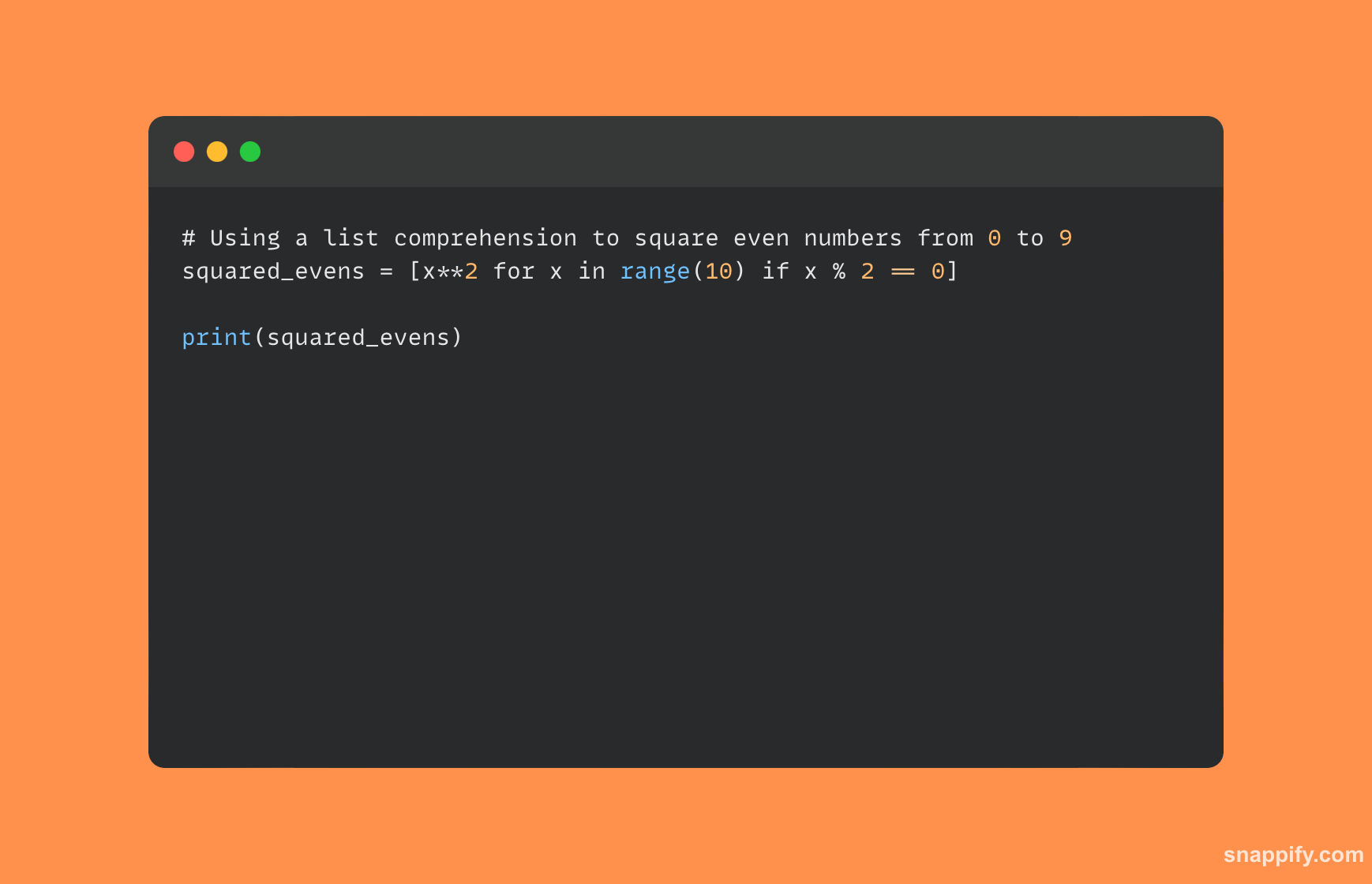
5. Opisz różnicę pomiędzy deepcopy i copy?
Głębokość i integralność zduplikowanych obiektów określa różnicę między nimi deepcopy i copy w Pythonie.
Tworząc nowy element, zachowując odniesienia do oryginalnych zagnieżdżonych obiektów, a copy tworzy płytką replikę, która splata ich losy w sieć współzależności.
Deepcopy tworzy całkowicie autonomiczny klon poprzez rekurencyjne kopiowanie oryginalnego obiektu i wszystkich jego hierarchicznych komponentów, odcinając wszystkie połączenia i zachowując autonomię w zmianach.
Dlatego w zależności od wymaganego poziomu niezależności obiektu, deepcopy zapewnia wszechstronną reprodukcję, podczas gdy kopia daje jedynie powielanie na poziomie powierzchni.
Oto kod pokazujący, jak to zrobić copy i deepcopy różnią się między sobą:
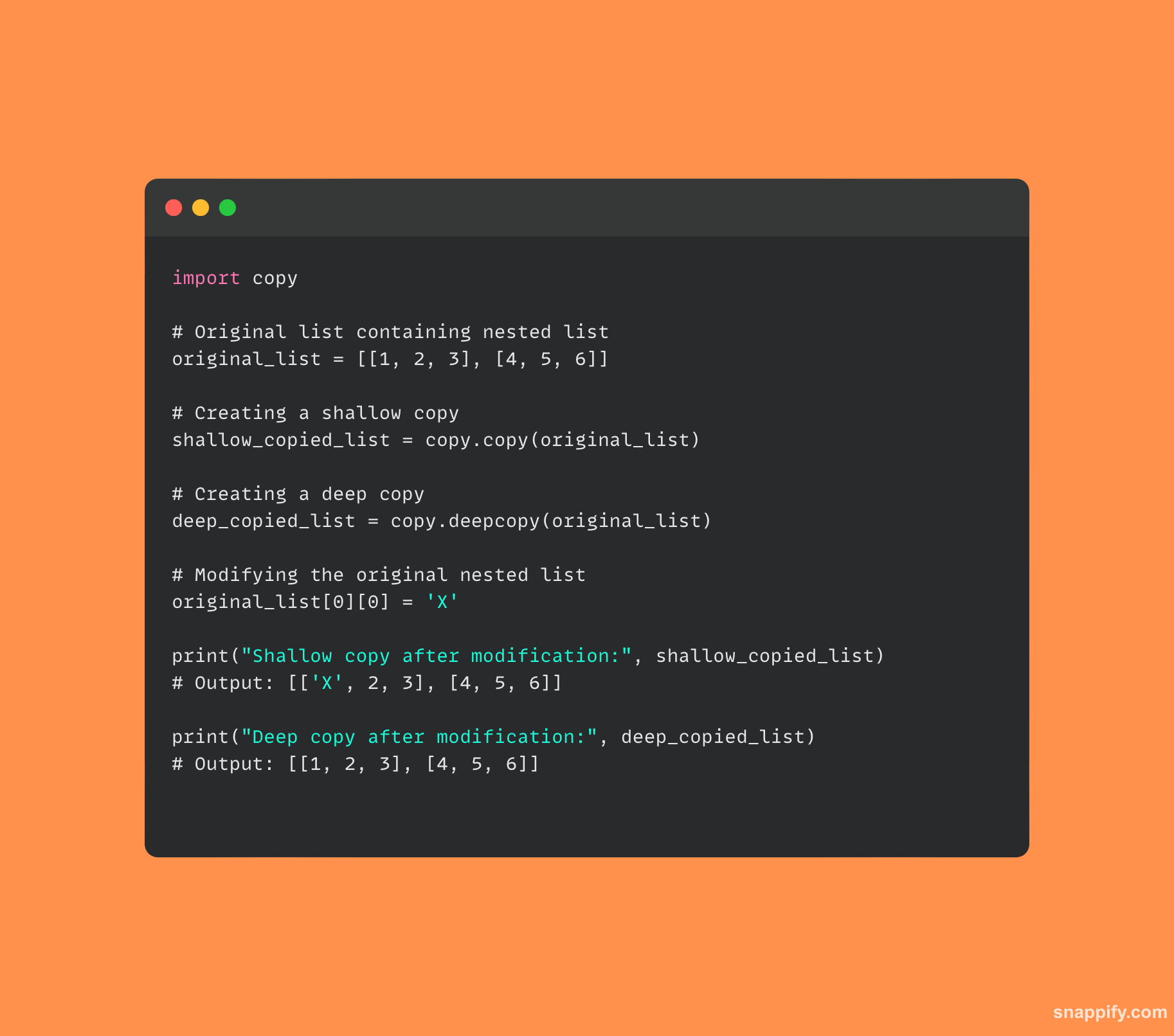
6. Jak w Pythonie realizowana jest wielowątkowość i czym różni się ona od wieloprocesorowości?
Zarówno wieloprocesowość, jak i wielowątkowość Pythona dotyczą współbieżnego wykonywania, ale przy użyciu różnych paradygmatów.
Wykorzystując wiele wątków w jednym procesie, wielowątkowość umożliwia współbieżne wykonywanie zadań w przestrzeni pamięci współdzielonej.
Jednak rzeczywiste wykonanie wątku równoległego może być trudne do osiągnięcia ze względu na globalną blokadę interpretera Pythona (GIL).
Z drugiej strony przetwarzanie wieloprocesowe wykorzystuje kilka procesów, każdy z oddzielnym interpreterem Pythona i przestrzenią pamięci, zapewniając prawdziwą równoległość.
W przypadku działań związanych z we/wy wielowątkowość jest lżejsza i praktyczna, ale przetwarzanie wieloprocesowe sprawdza się doskonale w sytuacjach związanych z procesorem, gdzie kluczowe jest rzeczywiste wykonanie równoległe.
Oto krótki przykładowy kod porównujący wieloprocesowość z wielowątkowością:
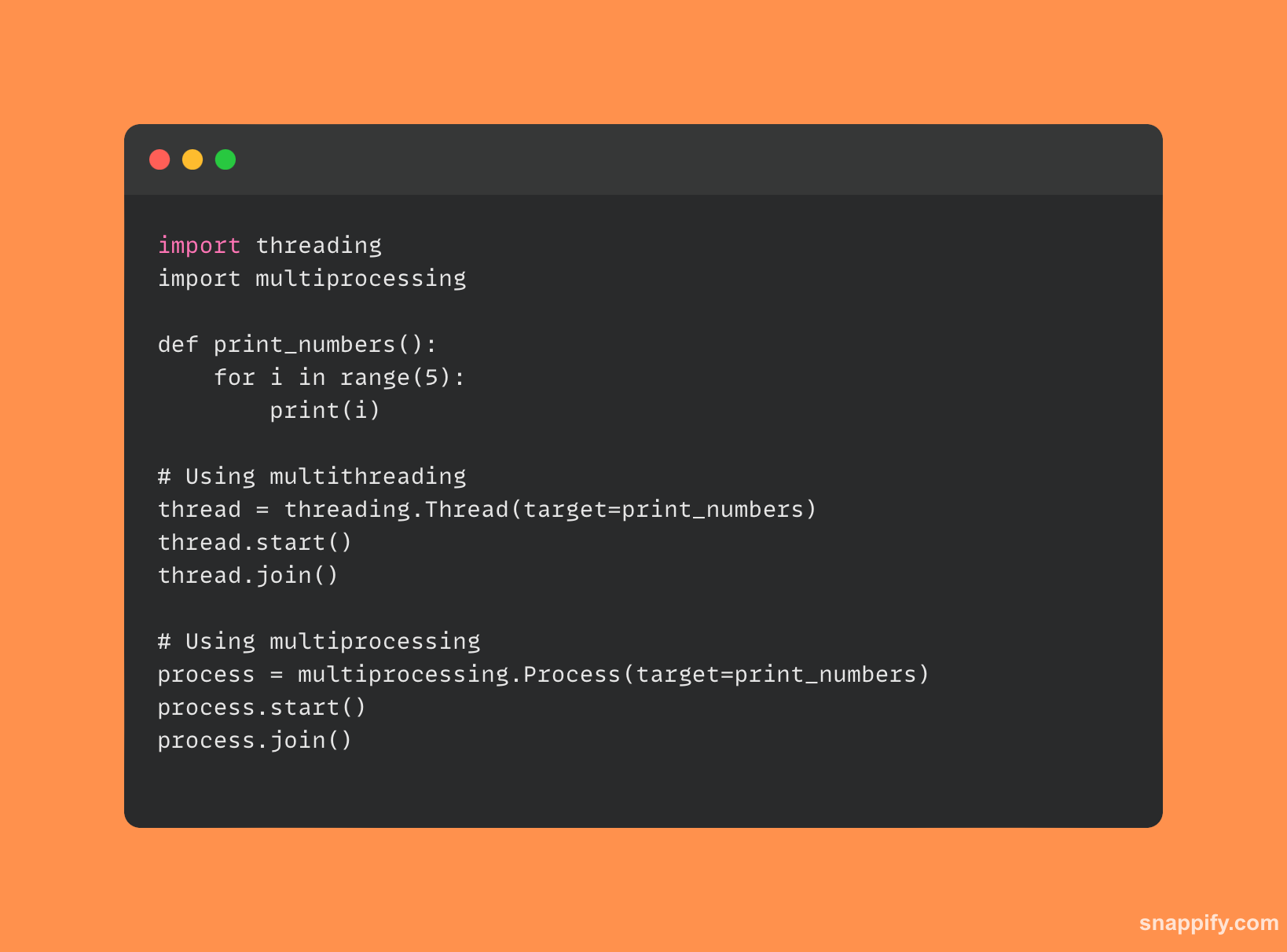
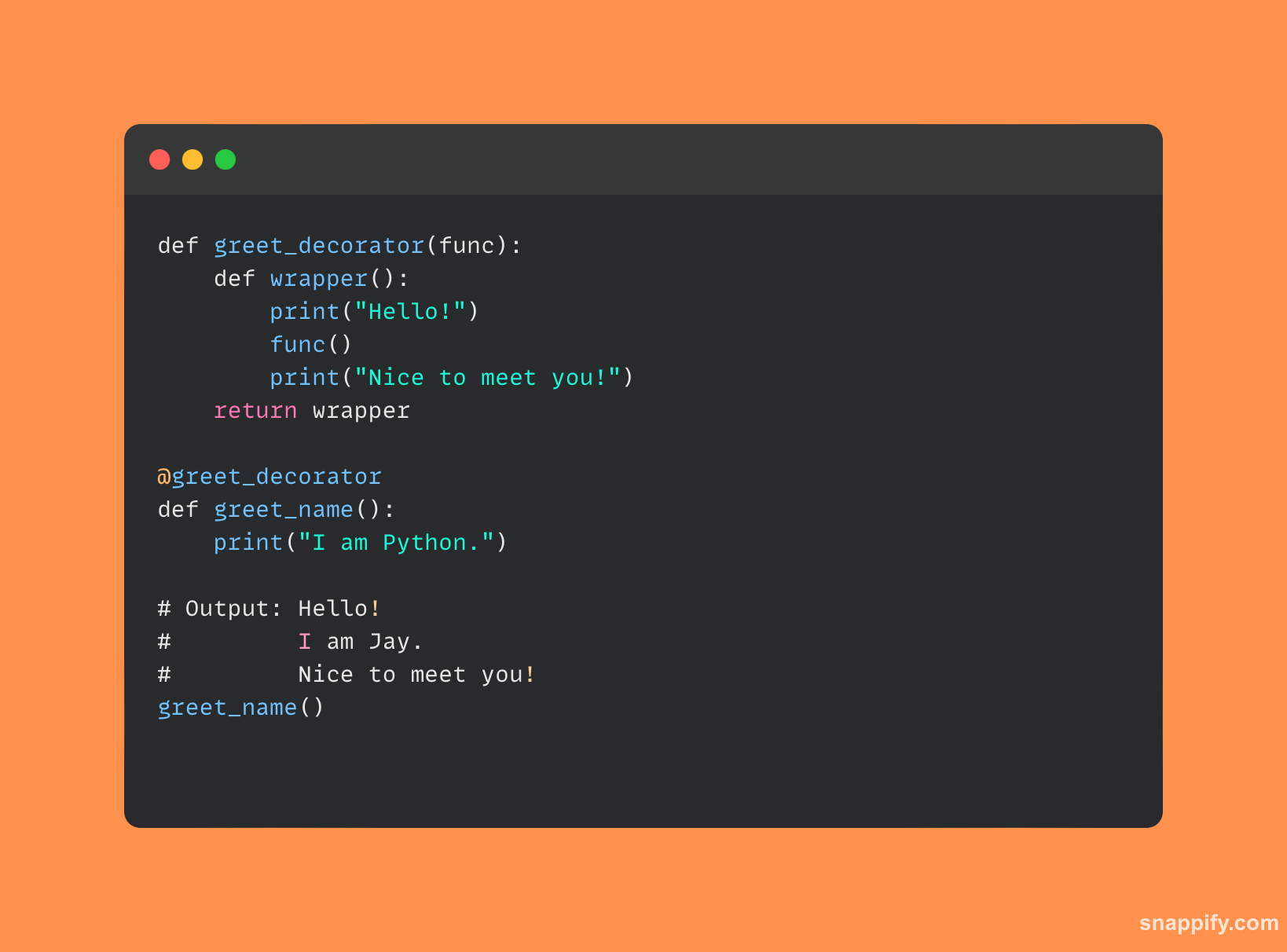
7. Czym są dekoratory i jak się ich używa w Pythonie?
W Pythonie dekoratorzy elegancko łączą użyteczność i prostotę, jednocześnie subtelnie rozszerzając lub zmieniając funkcje.
Pomyśl o dekoratorach jak o zasłonie, która pięknie otacza funkcję, zwiększając jej możliwości, nie zmieniając jej zasadniczego charakteru.
Podmioty te są oznaczone symbolem @, zaakceptuj funkcję jako dane wejściowe i wyprowadź zupełnie nową funkcję, oferując płynny sposób modyfikowania zachowania funkcji.
Dekoratory udostępniają szeroką gamę funkcji, od logowania po kontrolę dostępu, wzbogacając kod o nowe warstwy, zachowując przy tym jasną i zrozumiałą składnię.
Oto prosty przykład kodu Pythona pokazujący sposób użycia dekoratorów:
8. Wyjaśnij różnice pomiędzy *args i **kwargs?
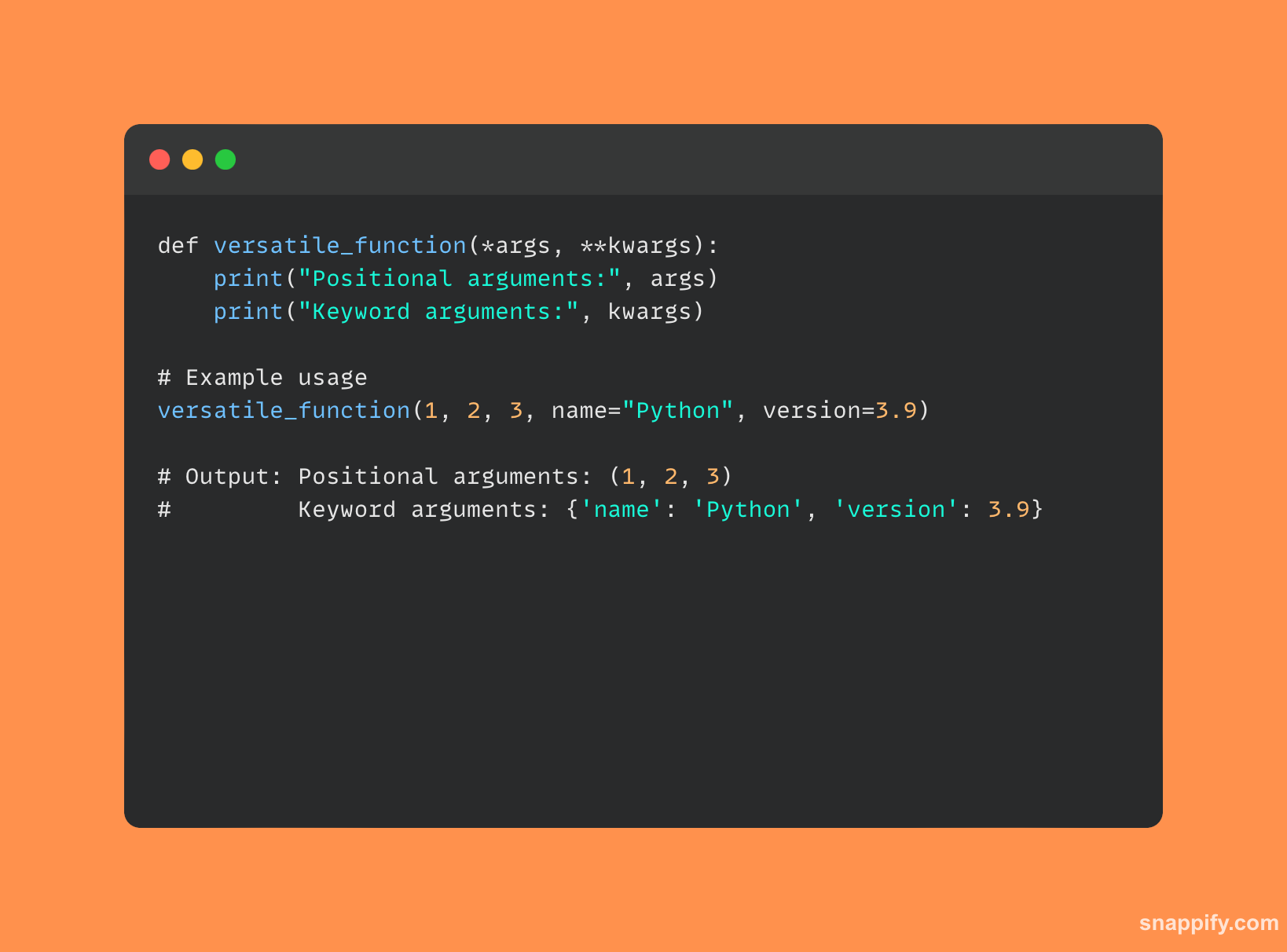
Elastyczne parametry Pythona *args i **kwargs pozwalają funkcjom prawidłowo przyjmować zakres argumentów.
Funkcja może przyjąć dowolną liczbę argumentów pozycyjnych przy użyciu metody *args parametr, który grupuje je w krotkę.
Natomiast funkcja może przyjąć dowolną liczbę argumentów słów kluczowych przy użyciu metody **kwargs parametr, który grupuje je w słownik.
Obydwa działają jako kanały zapewniające dynamikę i elastyczność w konstruowaniu i wywoływaniu funkcji, **kwargs oferując ustrukturyzowaną metodę obsługi dowolnej liczby słów kluczowych podczas *args z wdziękiem obsługuje niezdefiniowane wejścia pozycyjne.
Razem poprawiają elastyczność i trwałość funkcji Pythona, umiejętnie i przejrzyście obsługując szeroką gamę scenariuszy aplikacji.
Przykład kodu Pythona, który używa *args i **kwargs podano poniżej:
9. Jak zapewnić, że funkcja będzie mogła zostać wywołana tylko raz przy użyciu dekoratorów?
Dekoratorzy Pythona są biegli w łączeniu użyteczności z elegancją, która jest konieczna, aby zapewnić wyjątkowość wykonania funkcji.
Możliwe jest zaprojektowanie dekoratora, który zawrze w sobie funkcję i będzie śledził te informacje wewnątrz, zachowując stan wewnętrzny.
Hermetyzowana funkcja jest wywoływana raz i wykonywana, a dekorator rejestruje wywołanie. Kolejne wywołania są blokowane, co chroni funkcję przed ponownym wykonaniem i zapewnia, że nie zostanie zakłócona.
Za pomocą tego zastosowania dekoratorów można w subtelny, ale skuteczny sposób kontrolować wywołania funkcji, gwarantując niepowtarzalność w sposób zarówno piękny, jak i dyskretny.
Oto przykładowy kod pokazujący, jak można użyć dekoratorów do ograniczenia liczby wywołań funkcji:

10. Jak działa dziedziczenie w Pythonie?
System dziedziczenia w Pythonie tworzy sieć hierarchicznych powiązań między klasami, umożliwiając udostępnianie cech i funkcji z klasy nadrzędnej jej potomkom.
Zarządza linią, która umożliwia klasom pochodnym (podrzędnym) dziedziczenie, zastępowanie lub dodawanie funkcjonalności z klas podstawowych (nadrzędnych), promując ponowne użycie kodu i logiczny, hierarchiczny projekt.
Klasa potomna może wprowadzić swoje unikalne cechy i zachowania, a także przejąć możliwości swojej klasy nadrzędnej, tworząc silny, wielowarstwowy model obiektowy.
W tym podejściu dziedziczenie umiejętnie rozdziela funkcjonalność pomiędzy arterie hierarchii klas, tworząc jednolitą, dobrze zorganizowaną architekturę obiektową.
Poniższy uproszczony kod Pythona demonstruje dziedziczenie:

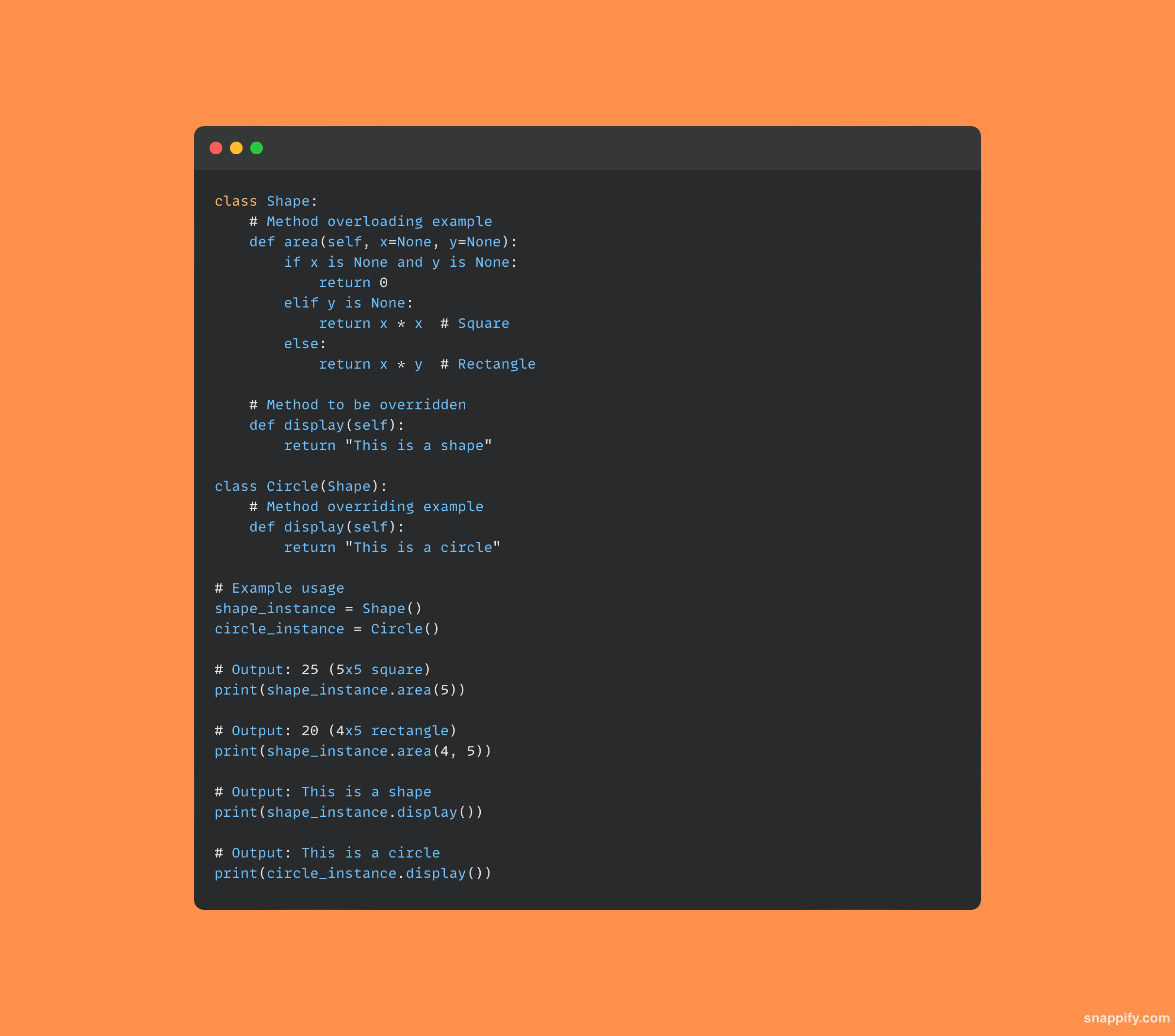
11. Co to jest przeciążanie i zastępowanie metod?
Dwa kamienie węgielne programowanie obiektowe, przeciążanie metod i zastępowanie metod umożliwiają programistom używanie tej samej nazwy metody do różnych celów.
Pojedyncza metoda może obsługiwać różne typy danych i liczbę argumentów, mając wiele podpisów dzięki przeciążeniu metody.
Z drugiej strony nadpisywanie metod umożliwia podklasie dodanie własnej, specjalnej implementacji do metody, która jest już zdefiniowana w jej klasie nadrzędnej, gwarantując wywołanie wersji podrzędnej.
Łącznie strategie te poprawiają możliwości adaptacji, umożliwiając zachowanie metod zależne od kontekstu i konkretnych wymagań aplikacji.
Oto przykładowy kod ilustrujący obie koncepcje:
12. Opisz pojęcie polimorfizmu na przykładzie.
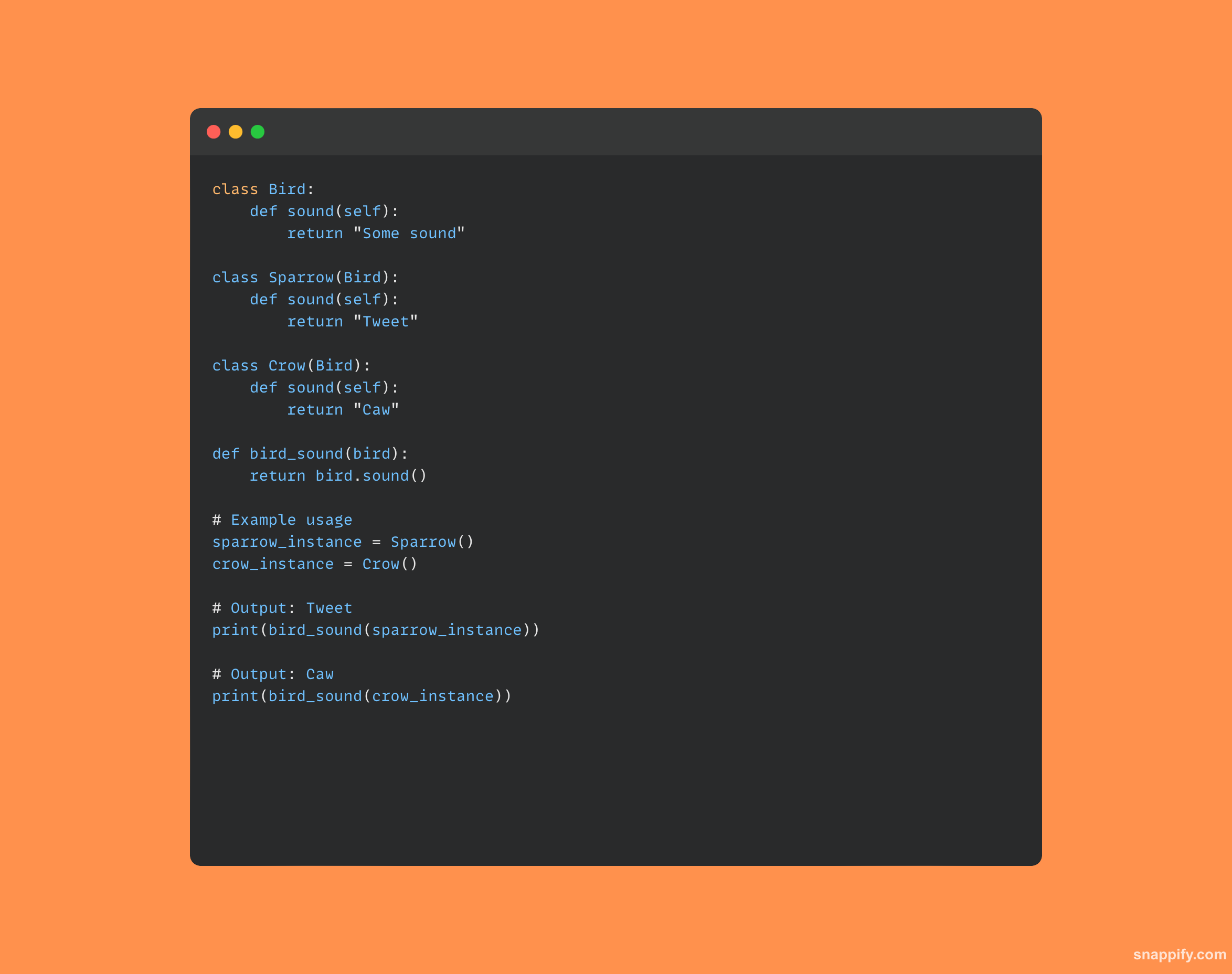
Polimorfizm to praktyka używania jednego interfejsu dla różnych typów danych.
Pomysł ten zapewnia adaptowalność i skalowalność projektu, dając metodom swobodę przetwarzania obiektów na wiele sposobów, w zależności od ich wewnętrznego typu lub klasy.
Zasadniczo polimorfizm umożliwia ujednolicone interakcje przy jednoczesnym zachowaniu odrębnych zachowań, umożliwiając traktowanie obiektów różnych klas jako instancje tej samej klasy poprzez dziedziczenie.
Ta dynamiczna funkcja zachęca do prostoty kodu, umożliwiając pojedynczej funkcji lub operatorowi bezproblemową interakcję z różnymi rodzajami obiektów.
Oto przejrzysty przykładowy kod demonstrujący polimorfizm:
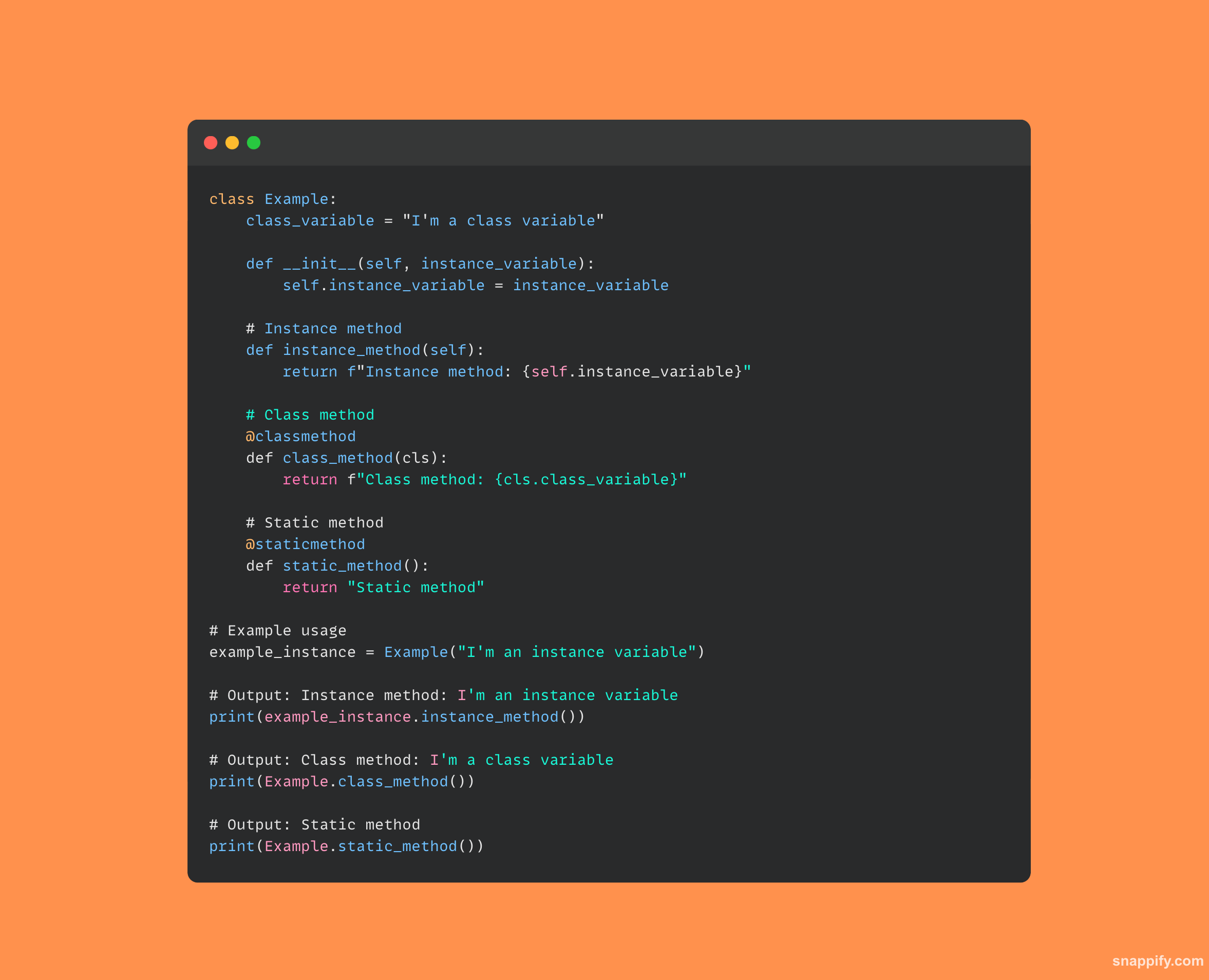
13. Wyjaśnij różnicę pomiędzy instancjami, klasami i metodami statycznymi.
Metody instancji, klas i statyczne mają swoje własne, odrębne sposoby interakcji z danymi obiektów i klas w Pythonie.
Najbardziej rozpowszechniony rodzaj, metody instancji, działają na danych instancji klasy i przyjmują jako dane wejściowe instancję klasy, zwykle zwaną self.
Sama klasa (często określana jako cls) jest akceptowana jako argument przez metody klas, które są oznaczone @classmethod i manipulują danymi na poziomie klasy.
Metody statyczne, oznaczone symbolem skrótu @staticmethod, nie wpływają na stany klas ani instancji, ponieważ są to niezależne funkcje zawarte w klasie i nie przyjmują self ani cls jako pierwszego parametru.
Ponieważ każdy typ metody zapewnia inny dostęp i użyteczność, architektury obiektowe są elastyczne i precyzyjne.
Jako przykład jednego z tych typów metod w kodzie:
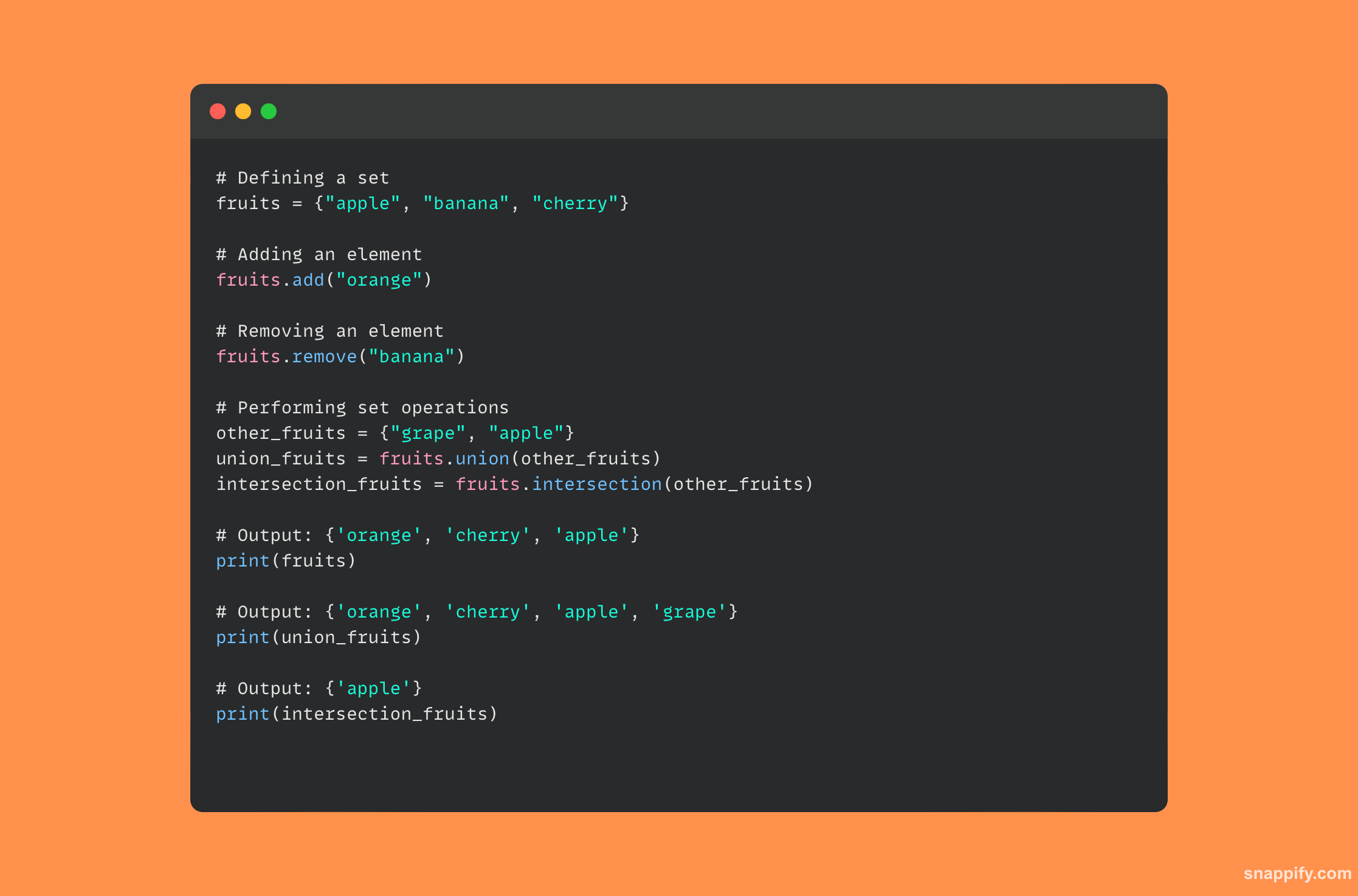
14. Opisz, jak wewnętrznie działa zestaw Pythona.
Wewnętrzny struktura danych zwany hashtable, jest używany przez zestaw Pythona, który jest nieuporządkowaną kolekcją odrębnych komponentów, do wykonywania wydajnych i skutecznych operacji.
Python używa funkcji skrótu do szybkiego zarządzania i pobierania danych, gdy element jest dodawany do zestawu, zamieniając element na wartość skrótu, która następnie definiuje jego lokalizację w pamięci.
Ułatwiając szybką kontrolę członkostwa i usuwając zduplikowane wpisy, technika ta zapewnia, że każdy element w zestawie jest unikalny i łatwo dostępny.
Dlatego nieodłączna architektura zbiorów ma tendencję do optymalizacji operacji, takich jak sumy, skrzyżowania i różnice, co skutkuje małą, efektywną strukturą danych.
Oto fragment kodu pokazujący, jak po prostu korzystać z zestawu Pythona:
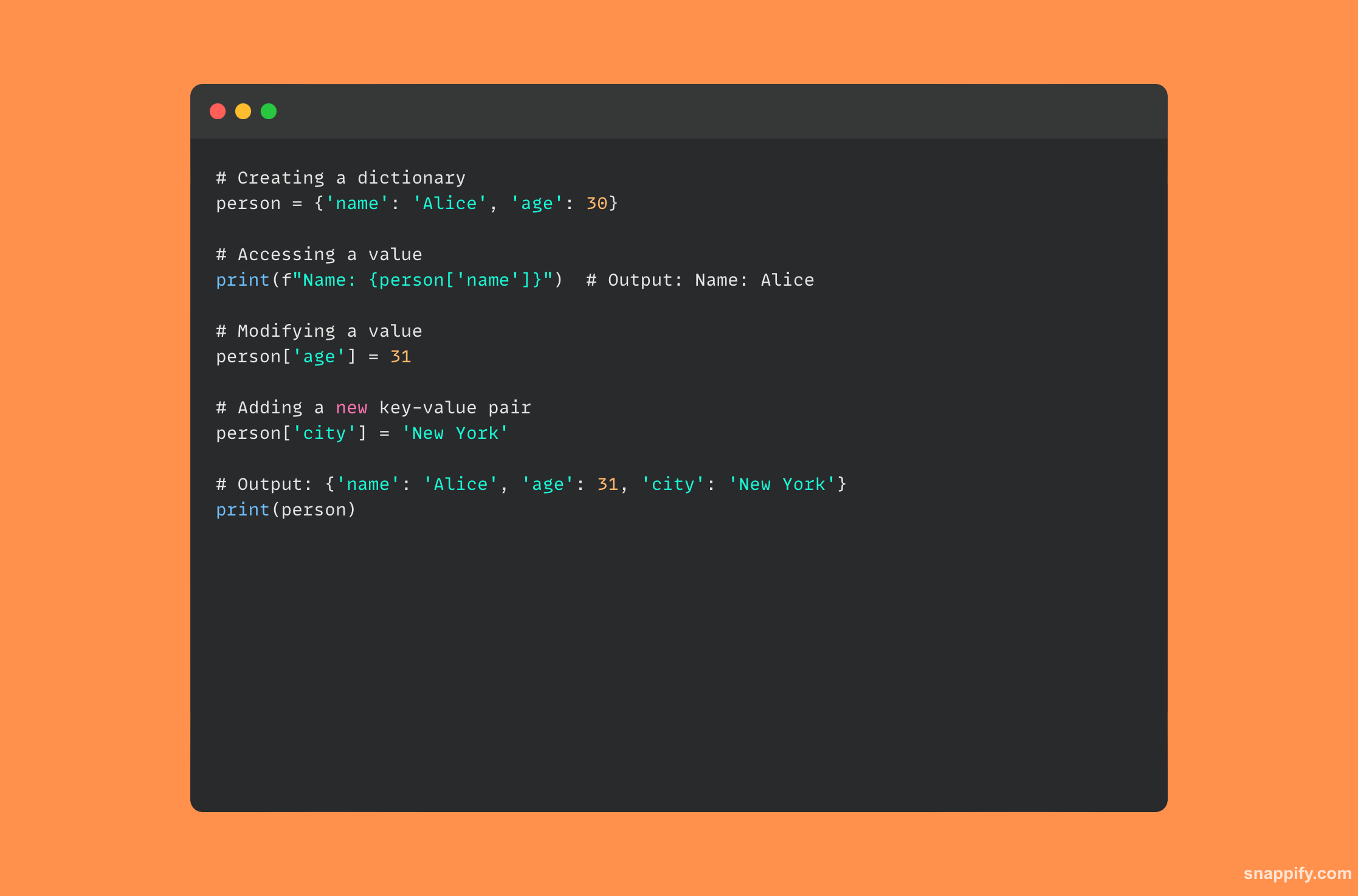
15. Jak zaimplementowano słownik w Pythonie?
Tablica mieszająca służy jako podstawa słownika w Pythonie i pozwala na szybkie wyszukiwanie i manipulowanie danymi. Słowniki to dynamiczne, nieuporządkowane zbiory par klucz-wartość.
Python używa funkcji skrótu do obliczenia skrótu klucza po wydaniu pary klucz-wartość, lokalizując lokalizację adresu przechowywania wartości w pamięci.
Ponieważ funkcja mieszająca natychmiast wskazuje interpreterowi adres pamięci, konstrukcja ta zapewnia szybki dostęp do danych w oparciu o klucze i jest zdumiewająco wydajna w operacjach wyszukiwania, wstawiania i usuwania.
Deweloperzy mogą łatwo i efektywnie zarządzać danymi dzięki kuszącej kombinacji szybkości i elastyczności, jaką zapewniają słowniki Pythona.
Poniżej znajduje się przykładowy kod pokazujący, jak używać słownika Pythona:
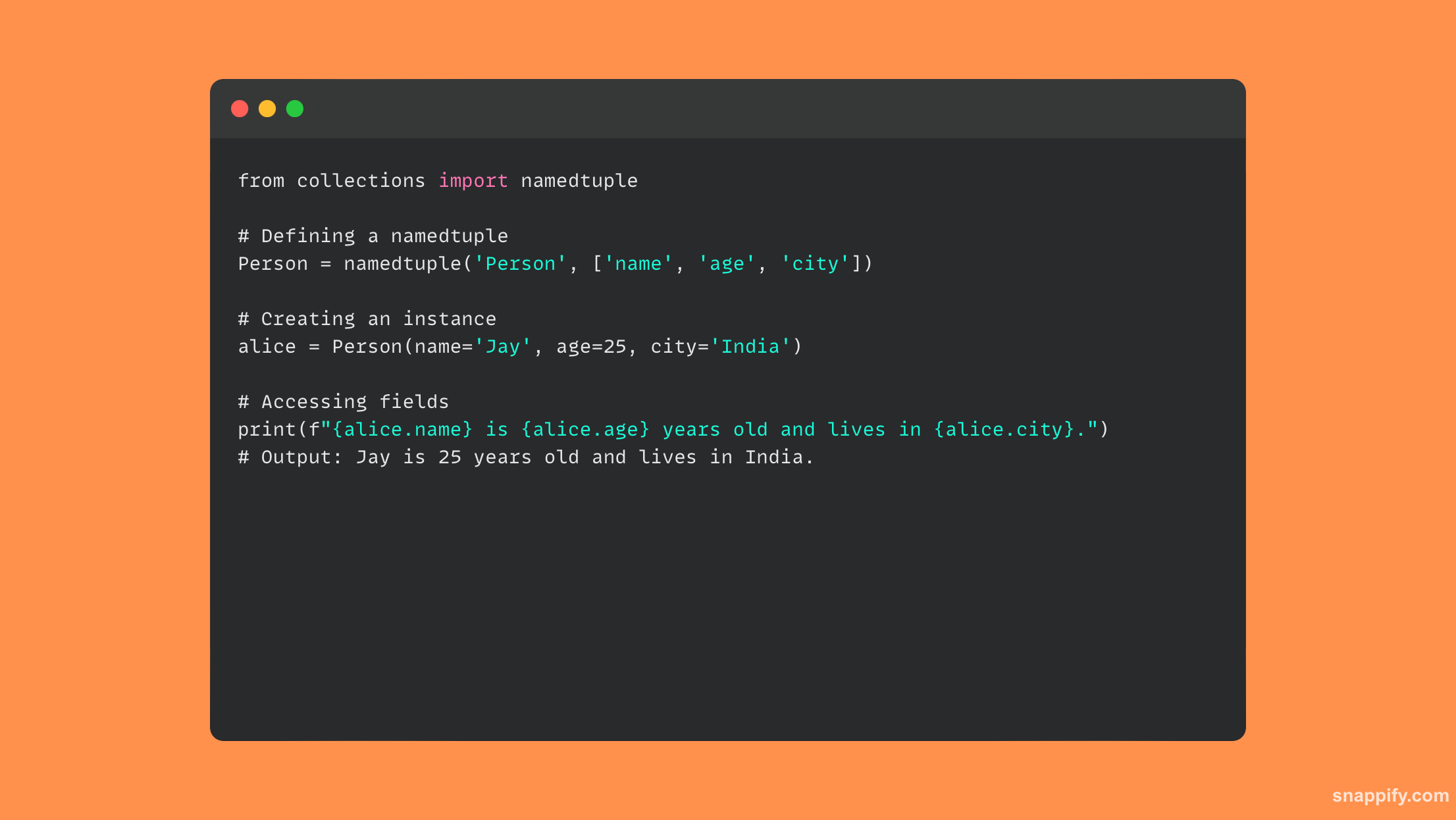
16. Wyjaśnij korzyści płynące ze stosowania nazwanych krotek.
Użycie nazwanych krotek w Pythonie umiejętnie łączy wyrazistość klas z prostotą krotek, czego efektem jest mała, oczywista struktura danych.
Tradycyjna krotka jest rozszerzana o nazwane krotki, które zachowują niezmienność i wydajność pamięci krotek, jednocześnie dodając nazwane pola w celu poprawy czytelności kodu i samoopisu.
Nazwane krotki promują przejrzysty, zrozumiały i wydajny kod poprzez ustanawianie prostych, lekkich obiektów bez żadnych metod, poprawiając zarówno doświadczenie programisty, jak i wydajność obliczeniową.
W rezultacie nazwane krotki stają się potężnym narzędziem, które poprawia strukturę danych i czytelność bez utraty szybkości.
Przykładowy kod ilustrujący użycie nazwanych krotek pokazano poniżej:
17. Jak działa blok try-except?
Blok try-except pełni funkcję strażnika w ekspresyjnej składni języka Python, czujnie chroniąc przed nieprawidłowościami w czasie wykonywania i utrzymując płynny przebieg wykonywania pomimo potencjalnych problemów.
Gdy blok try napotka błąd, kontrola jest automatycznie przekazywana do odpowiedniego bloku z wyjątkiem, gdzie problem zostanie rozwiązany poprzez zgłoszenie, naprawienie lub być może ponowne zgłoszenie wyjątku.
Obsługując wyjątki w celowy i kontrolowany sposób, system ten nie tylko chroni przed destrukcyjnymi awariami, ale także ulepsza doświadczenie użytkownika i integralność danych.
W rezultacie blok try-except umiejętnie łączy zarządzanie błędami z wykonywaniem programu, gwarantując niezawodność i stabilność aplikacji.
Oto mała próbka kodu wykorzystująca blok try-except:
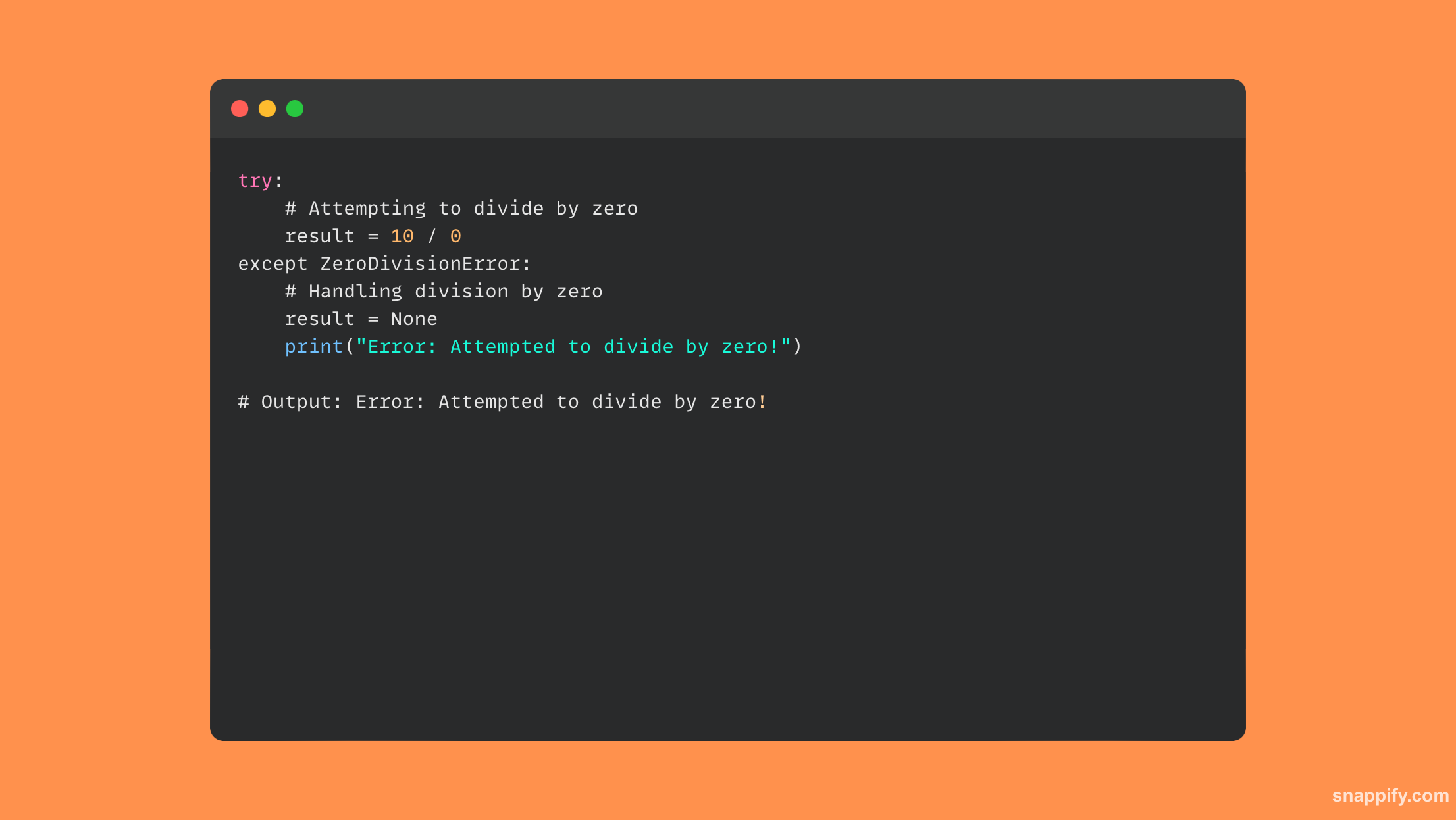
18. Jaka jest różnica pomiędzy instrukcjami raise i Assert?
Instrukcje raise i Assert w obsłudze błędów w Pythonie reprezentują dwa oddzielne, ale powiązane wyrażenia zarządzania wyjątkami.
Połączenia raise instrukcja daje programiście wyraźną kontrolę nad komunikatami o błędach i przepływem, umożliwiając mu jawne powodowanie określonych wyjątków.
AssertZ drugiej strony działa jako narzędzie do debugowania, automatycznie generując plik AssertionError jeśli odpowiedni warunek nie jest spełniony, gwarantując, że program podczas programowania będzie działał zgodnie z zamierzeniami.
Assert po prostu sprawdza warunki, usprawniając debugowanie i sprawdzanie poprawności, podczas gdy raise umożliwia szerszą, bardziej wyraźną kontrolę. Zarówno podnoszą, jak i zapewniają produkcję wyjątków kontrolowanych przez zezwolenie.
Oto przykładowy kod pokazujący, jak używać raise i assert:
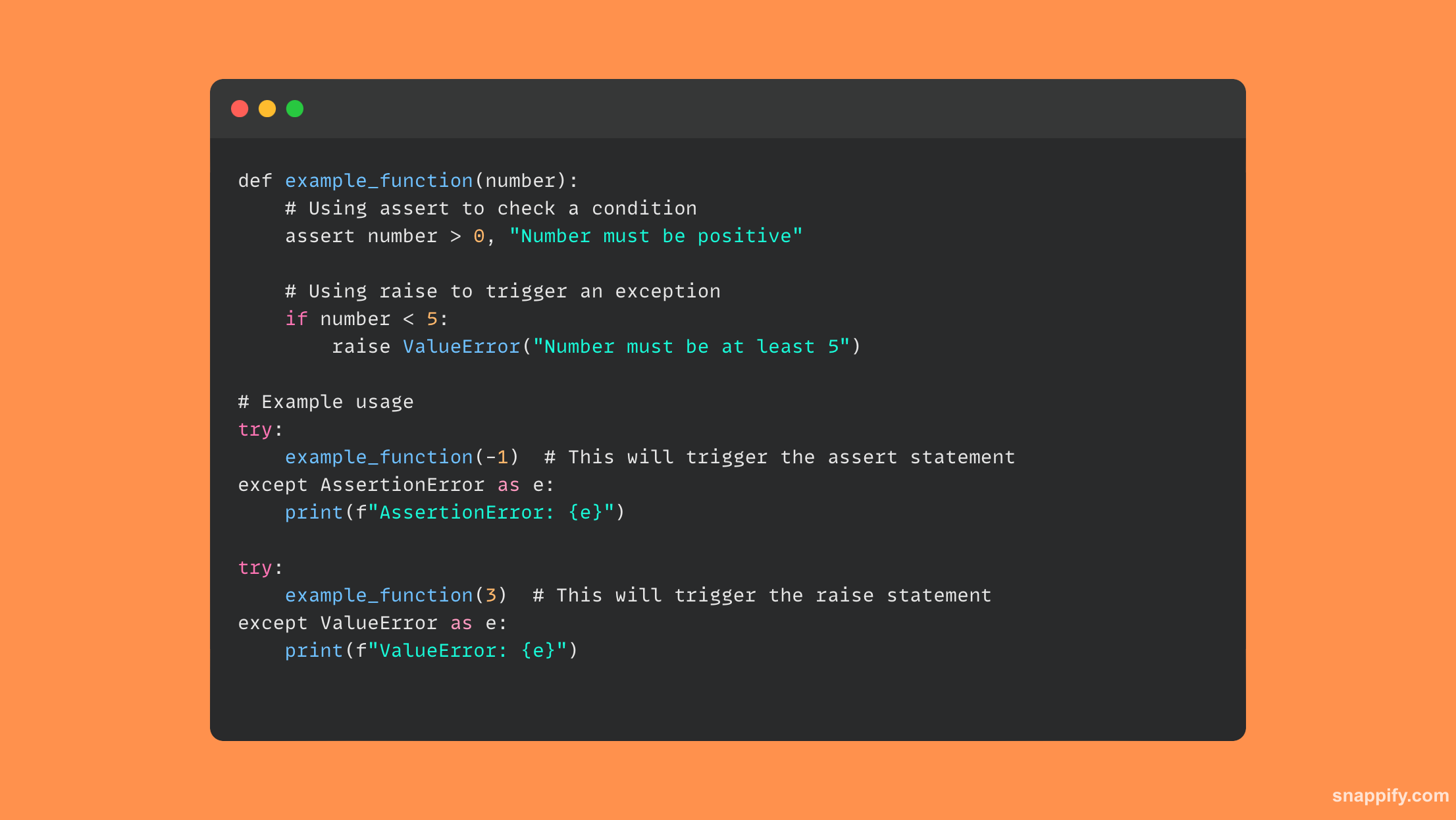
19. Jak czytać i zapisywać dane z pliku binarnego w Pythonie?
Używanie wbudowanej funkcji open ze specyfikatorem trybu binarnego, łączenie się z plikami binarnymi w Pythonie zapewnia równowagę pomiędzy dokładnością i prostotą.
Korzystanie z rb or wb tryby otwierania pliku binarnego zapewnią, że dane będą traktowane w niezakodowanej, surowej formie podczas odczytu lub zapisu danych binarnych.
Używając tych trybów, Python upraszcza zarządzanie danymi nietekstowymi, takimi jak obrazy lub pliki wykonywalne, umożliwiając programistom precyzyjną i łatwą obsługę i analizę danych binarnych.
Dlatego operacje na plikach binarnych w Pythonie otwierają drzwi do szerokiego zakresu zastosowań, w tym do serializacji danych, przetwarzania obrazów i analizy binarnej, żeby wymienić tylko kilka.
Korzystając z pliku binarnego, ten przykład kodu pokazuje, jak czytać i zapisywać dane:
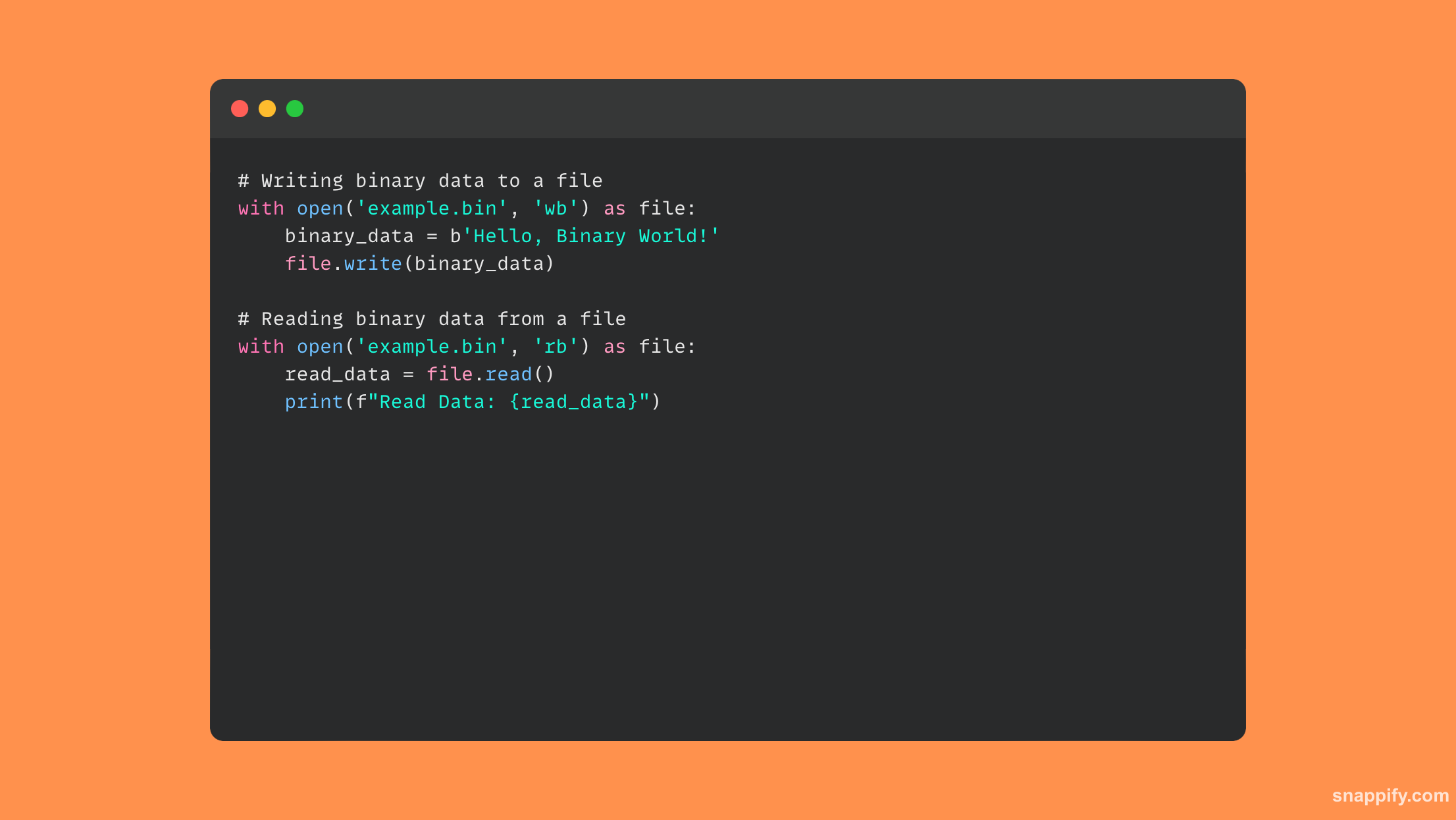
20. Wyjaśnij with instrukcja i jej zalety podczas pracy z plikami we/wy.
Instrukcja Pythona with, która jest często używana z operacjami wejścia/wyjścia pliku, elegancko zapewnia efektywną obsługę zasobów dzięki idei zarządzania kontekstem.
Kiedy mamy do czynienia z plikami, withinstrukcja natychmiast zamyka plik po użyciu, nawet jeśli w trakcie wykonywania akcji wystąpi wyjątek, chroniąc przed wyciekami zasobów i gwarantując czyste zakończenie.
Eliminując kod szablonowy, ten cukier syntaktyczny poprawia czytelność kodu. Zwiększa także niezawodność i prostotę poprzez integrację zarządzania zasobami i obsługi wyjątków.
W rezultacie instrukcja with staje się niezbędna do zapewnienia niezawodności i przejrzystości operacji na plikach, ochrony przed nieprzewidzianymi problemami i poprawy przejrzystości kodu.
Oto przykład kodu, który używa metody with instrukcja w operacjach na plikach:
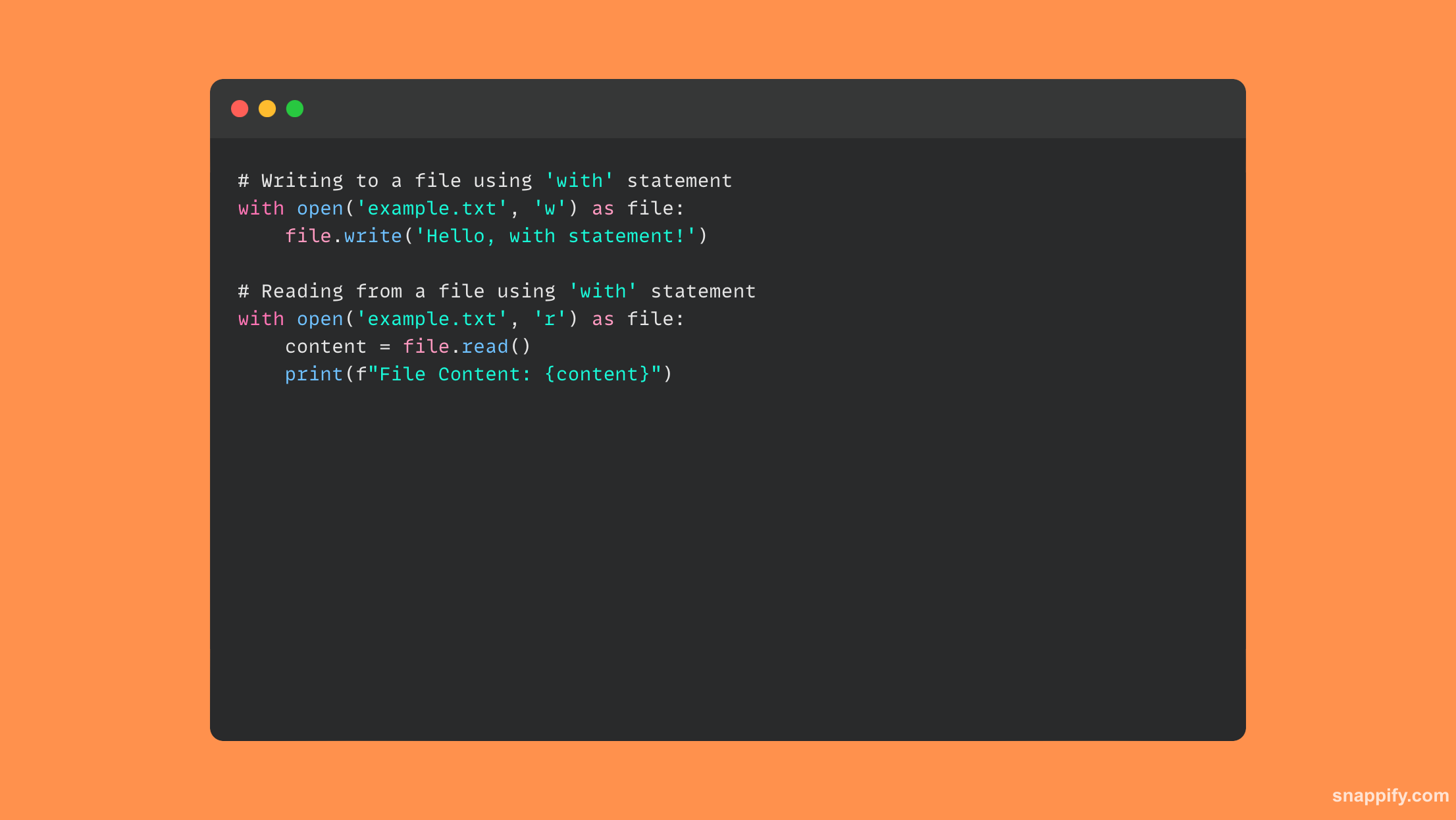
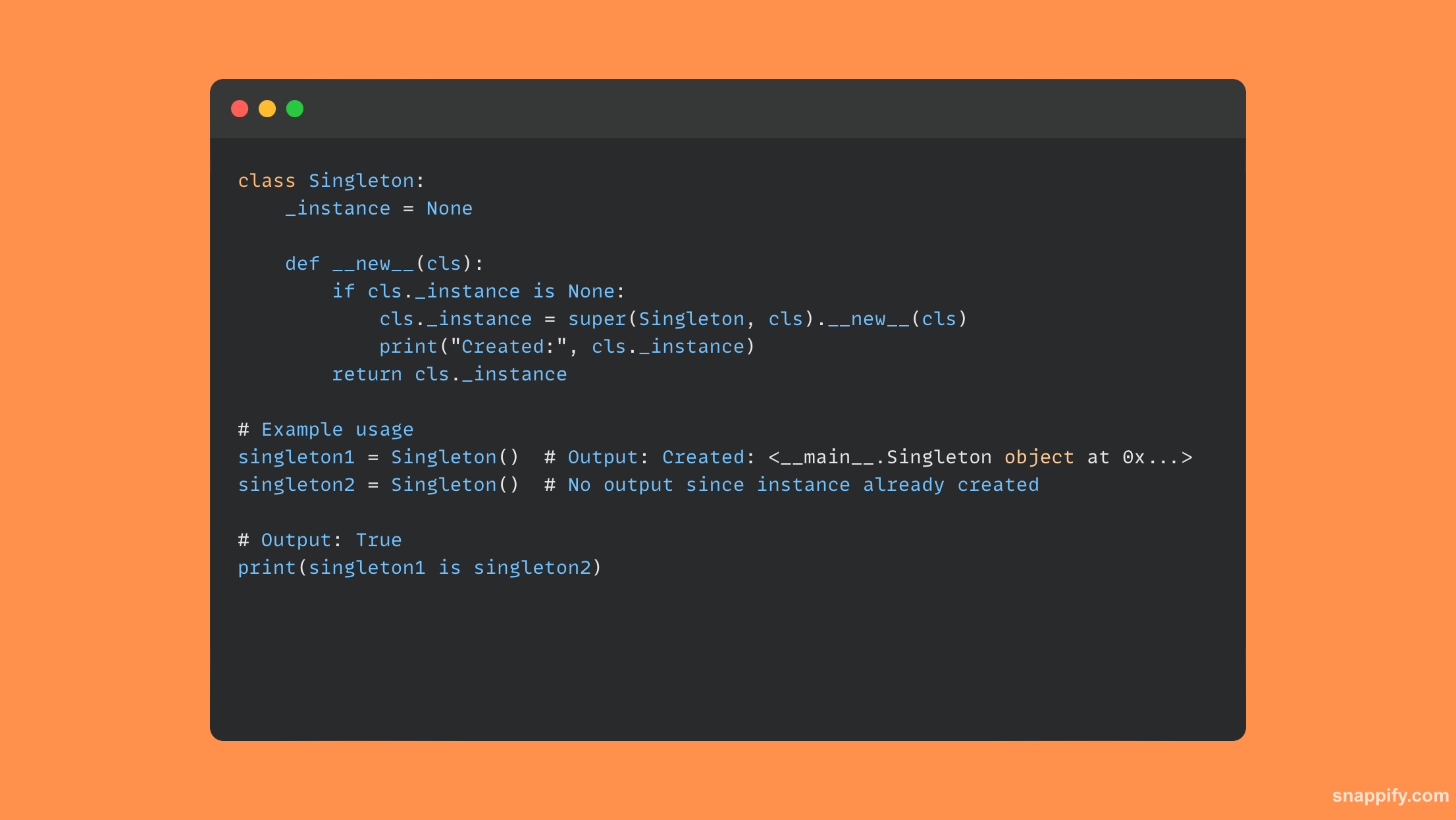
21. Jak utworzyłbyś moduł singletonowy w Pythonie?
Do utworzenia modułu singleton w Pythonie używana jest kombinacja metod klasowych i kontroli wewnętrznych, czyli wzorca projektowego, który pozwala na utworzenie tylko pojedynczej instancji klasy.
Zachowując śledzenie własnej instancji i udostępniając metodę jej generowania lub zwracania, klasa postępuje zgodnie z tym wzorcem, aby mieć pewność, że kolejne instancje będą replikować pierwszą instancję.
Dzięki jednemu punktowi kontroli, ujednoliconemu dostępowi do zasobów i ochronie przed konkurencyjnymi manipulacjami, singleton zapewnia pojedynczy punkt kontroli.
W rezultacie rozwija się w skuteczne narzędzie do hermetyzacji współdzielonych zasobów, gwarantując spójny dostęp i modyfikację w całym programie.
Oto mały przykładowy kod Pythona demonstrujący klasę singleton:
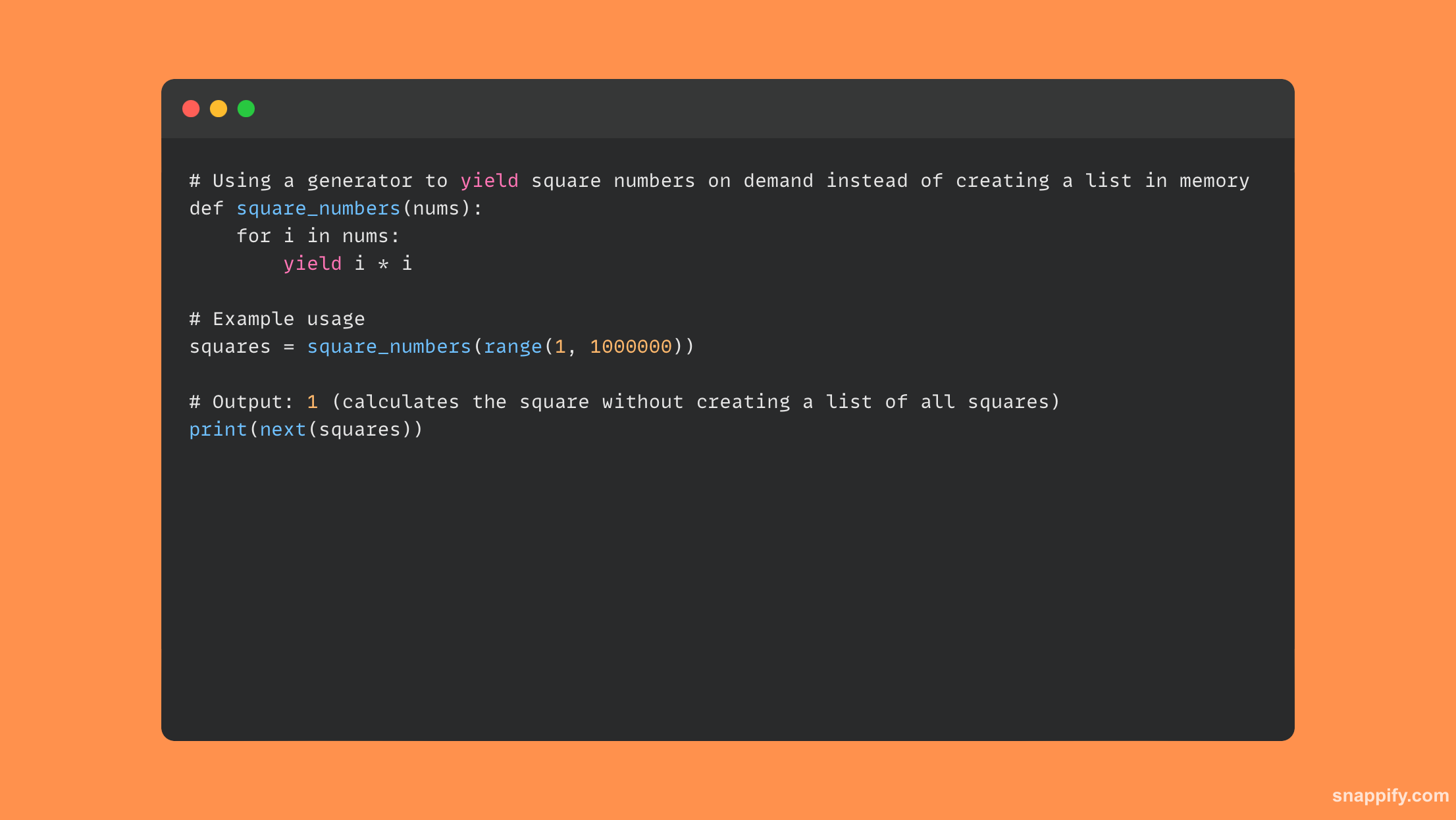
22. Wymień kilka sposobów optymalizacji wykorzystania pamięci w skrypcie Pythona.
Optymalizacja zużycia pamięci przez skrypt Pythona często wiąże się z ostrożnym balansowaniem pomiędzy wyborem struktury danych, ulepszaniem algorytmu i zarządzaniem zasobami.
Na przykład podczas pracy z ogromnymi zbiorami danych użycie generatorów zamiast list może znacznie zminimalizować użycie pamięci poprzez leniwe ocenianie elementów na bieżąco, zamiast przechowywać je w pamięci.
Dalsze ograniczenie zużycia pamięci jest możliwe poprzez obsługę danych numerycznych za pomocą struktur danych tablicowych, a nie list, oraz poprzez oszczędne używanie __slots__ deklaracje w klasie kontrolujące tworzenie atrybutów dynamicznych.
Zatem równoważąc wydajność i wykorzystanie zasobów, możesz mieć pewność, że programy w języku Python będą nie tylko skuteczne, ale także przemyślane pod względem ilości wykorzystywanej pamięci.
Oto krótki przykład kodu wykorzystującego generator w celu zmniejszenia ilości używanej pamięci:
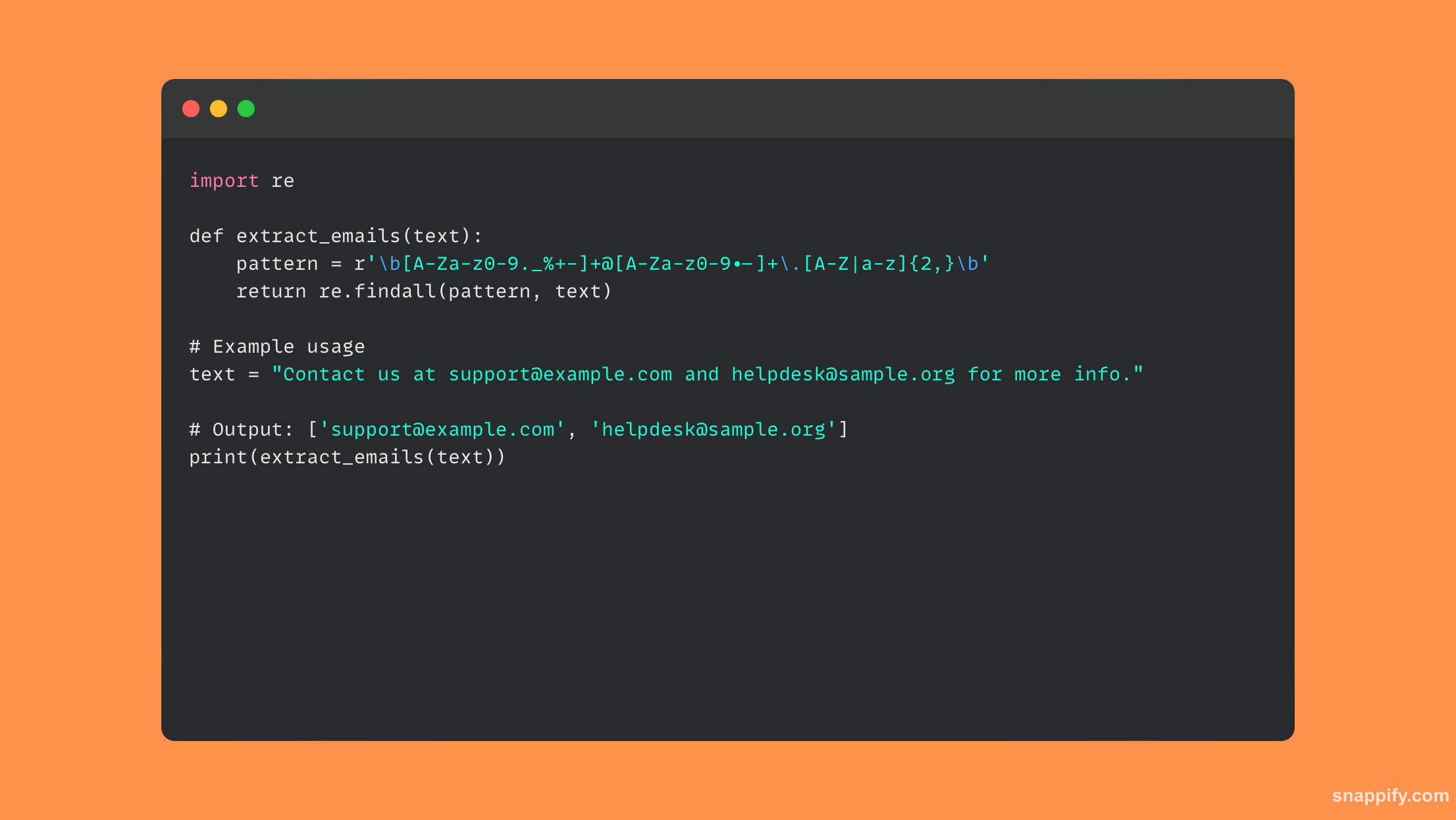
23. Jak wyodrębnić wszystkie adresy e-mail z danego ciągu za pomocą wyrażenia regularnego?
Wyrażenia regularne (regex) w Pythonie łączą dokładność i wszechstronność w celu wyodrębnienia adresów e-mail z ciągu, umożliwiając programiście sprawne filtrowanie materiału tekstowego i identyfikowanie pożądanych wzorców.
Aby ustalić strukturę adresu e-mail, tworzy się wzór wyrażenia regularnego za pomocą modułu re. Następnie możesz użyć findall aby uzyskać wszystkie wystąpienia z ciągu docelowego.
Ta metoda sprawnie porusza się po labiryncie tekstowym, aby uzyskać wszystkie ukryte adresy e-mail, co nie tylko przyspiesza proces ekstrakcji, ale także zapewnia poprawność.
Regex można umiejętnie wykorzystać do skutecznego wyodrębniania określonych danych z ciągów znaków, zwiększając przetwarzanie i analizę danych w skryptach Pythona.
Oto fragment kodu, który używa wyrażenia regularnego do wyodrębniania wiadomości e-mail:
24. Wyjaśnij wzorzec projektowy Factory i jego zastosowanie w Pythonie
Podstawową zasadą programowania obiektowego, wzorcem projektowym fabryki, jest tworzenie obiektów bez określenia dokładnej klasy obiektów, które mają zostać wygenerowane.
Wzorzec Factory można elegancko zaimplementować w Pythonie, tworząc metodę zwracającą instancje kilku klas w zależności od danych wejściowych metody lub konfiguracji.
Procedura ta, czasami nazywana „fabryką”, pełni funkcję centrum łączenia kilku instancji klas, gwarantując utworzenie obiektów bez konieczności ręcznego tworzenia instancji klas przez osobę wywołującą.
Zatem wzorzec Factory utrzymuje oddzieloną, skalowalną architekturę, poprawiając jednocześnie modułowość i spójność kodu. Oferuje również uproszczoną technikę budowania obiektów.
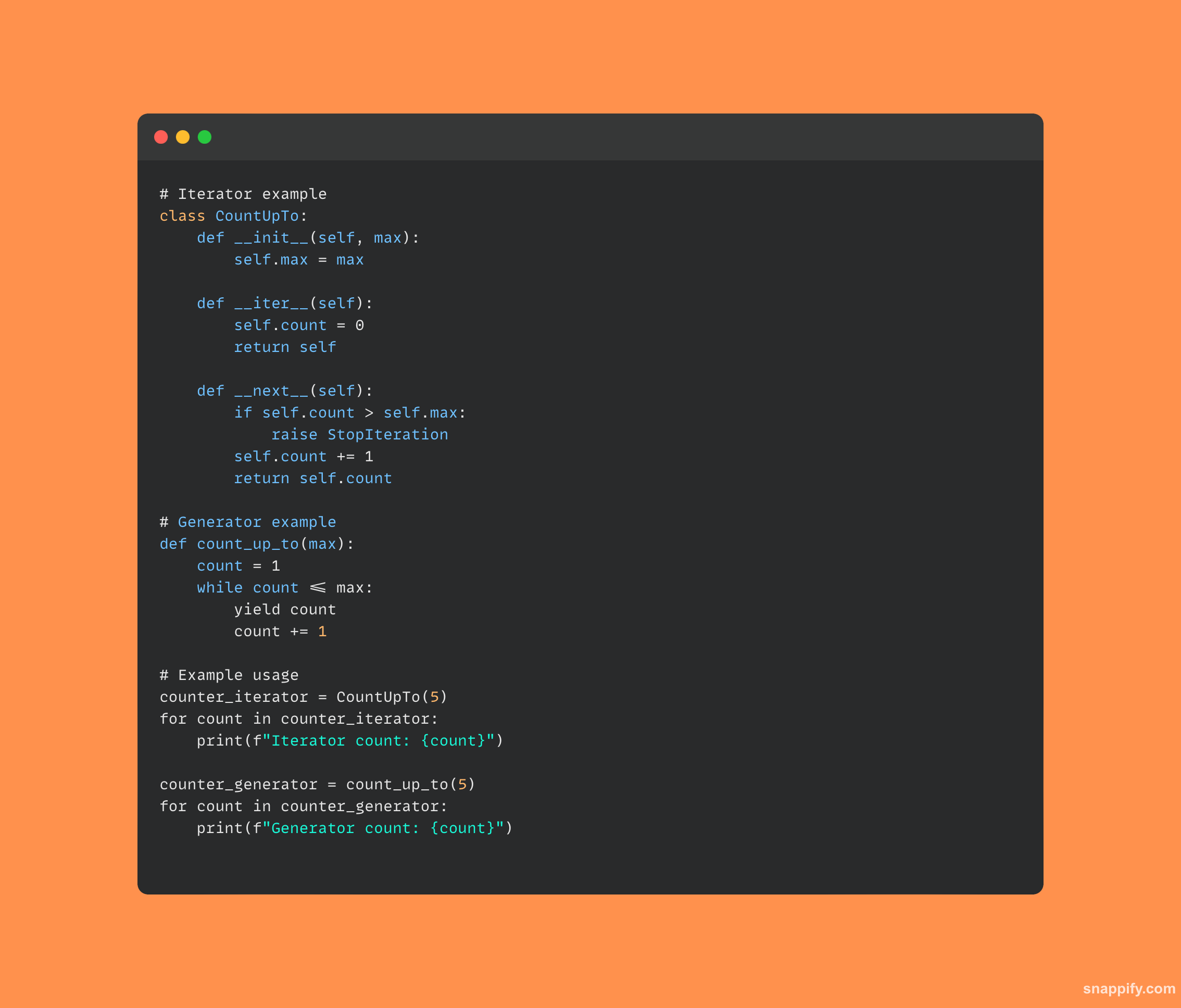
25. Jaka jest różnica pomiędzy iteratorem a generatorem?
Z iteratorów i generatorów Pythona jasno wynika, że obie konstrukcje umożliwiają pętlę poprzez wartości, jednakże istnieją subtelne różnice w sposobie ich implementacji i używania.
Generator, który często jest identyfikowany na podstawie wykorzystania wydajności, automatycznie utrzymuje swój stan i jest zaimplementowany z funkcją, zapewniając zwięzły i oszczędzający pamięć sposób tworzenia wartości na bieżąco.
Iterator, który jest zwykle implementowany jako klasa, używa metod takich jak __iter__ i __next__ zarządzać stanem iteracji i generować wartości.
W rezultacie każdy z nich ma swoje zalety w zależności od konkretnego przypadku użycia, przy czym iteratory oferują dokładny, obiektowy sposób przeglądania danych, podczas gdy generatory oferują lekką, leniwą technikę oceny.
Obie techniki poszerzają arsenał programisty i umożliwiają szybkie i skuteczne eksplorowanie danych w różnych sytuacjach.
Oto fragment kodu iteratora i generatora w Pythonie:
26. Jak działa @property praca dekoratora?
Dekorator „@property” w Pythonie odtwarza cudowną melodię, która przekształca wywołania metod w dostęp podobny do atrybutów, poprawiając użyteczność i ekspresję obiektu.
Metodę można wywołać bez użycia nawiasów, używając @property, co jest podobne do uzyskiwania dostępu do atrybutu. Tworzy to wyraźniejszy i łatwiejszy w użyciu interfejs interakcji z obiektami.
Dodatkowo oferuje zręczną równowagę pomiędzy funkcjonalnością i enkapsulacją, chroniąc stany obiektów, zapewniając jednocześnie intuicyjny interfejs, umożliwiający programistom łatwe określanie atrybutów za pomocą metod pobierających i ustawiających.
Łącząc funkcjonalność metody z dostępnością atrybutów, @property dekorator okazuje się kluczowym narzędziem oferującym prosty, ale skuteczny paradygmat interakcji z obiektami.
Przykład Pythona @property dekorator pokazano poniżej:
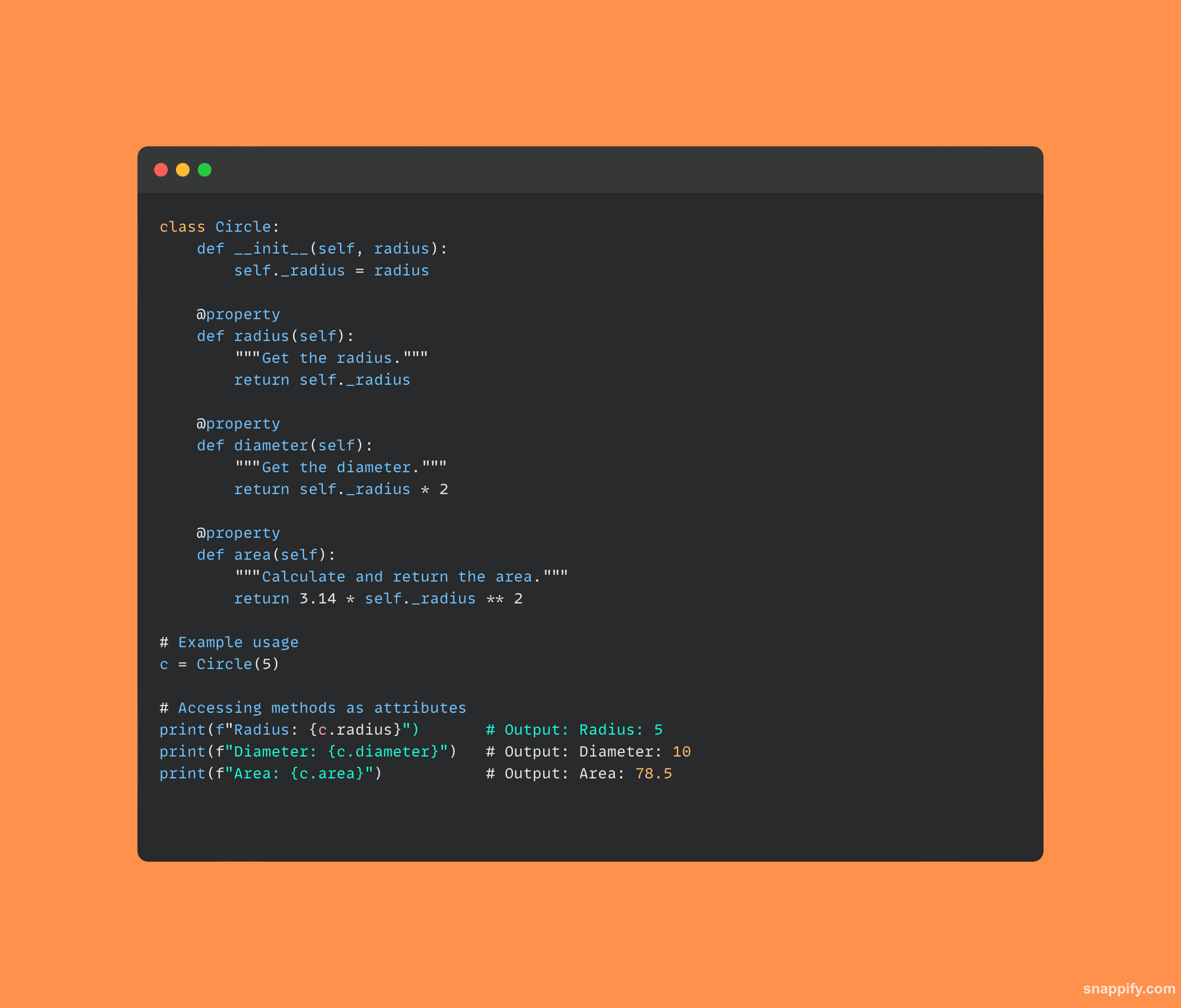
27. Jak stworzyłbyś podstawowy interfejs API REST w Pythonie?
Aby tworzyć usługi internetowe współpracujące za pośrednictwem żądań HTTP, programiści często korzystają z możliwości ekspresji frameworków takich jak Flask, budując proste REST API w Pythonie.
Dzięki prostej i zrozumiałej składni Flask umożliwia programistom konstruowanie tras, do których można uzyskać dostęp za pomocą wielu metod HTTP, w tym GET i POST, w celu komunikacji z podstawową aplikacją.
Interfejs API REST zbudowany przy użyciu Flaska może z łatwością akceptować żądania HTTP, przetwarzać zawarte w nich dane i dostarczać w odpowiedzi odpowiednie informacje, określając unikalne punkty końcowe powiązane z różnymi funkcjonalnościami.
Aby zapewnić bezproblemową komunikację pomiędzy różnymi komponentami oprogramowania w środowisku sieciowym, programiści mogą korzystać z wydajnych interfejsów API REST, korzystając z kombinacji Pythona i Flaska.
Oto mały fragment kodu, który wykorzystuje Flask do utworzenia interfejsu API REST:
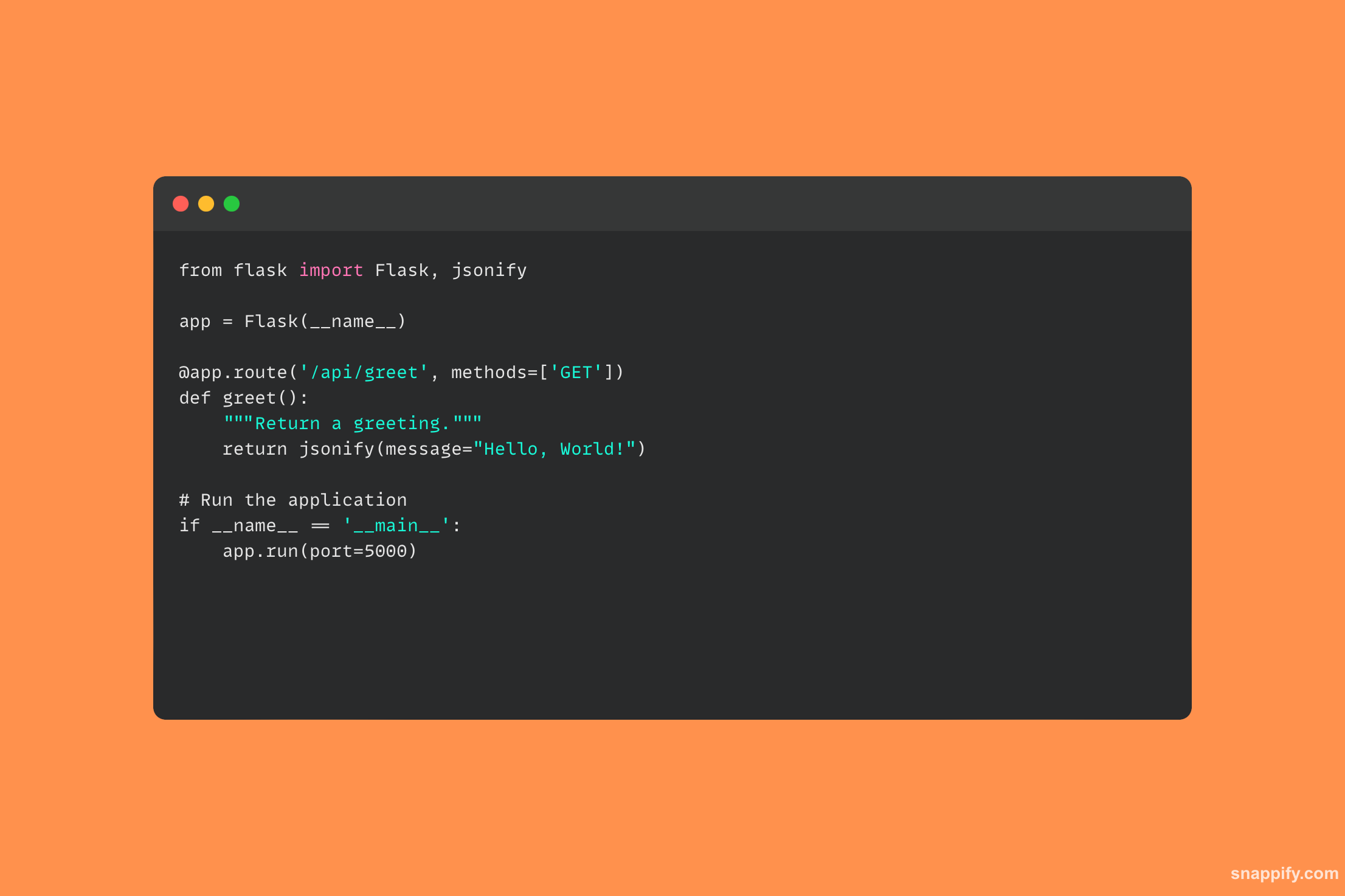
28. Opisz, jak używać biblioteki żądań do tworzenia żądania HTTP POST.
Biblioteka żądań Pythona to potężne narzędzie, które przekształca trudności związane z komunikacją HTTP w przyjazny interfejs API i sprawia, że interakcja z usługami online za pomocą żądań HTTP POST jest prosta i naturalna.
Żądanie POST jest realizowane przy użyciu metody post, podając docelowy adres URL i załączając materiał do wysłania, który może zawierać dane formularza, JSON, pliki i inne.
Biblioteka żądań zarządza następnie bazowym połączeniem HTTP, wysyłając dane pod wskazany adres URL i zbierając odpowiedź serwera, aby umożliwić płynne interakcje w sieci Web.
Programiści mogą łatwo korzystać z usług online, przesyłać dane z formularzy i łączyć się z internetowymi interfejsami API za pomocą żądań, wypełniając lukę między aplikacjami lokalnymi a globalną siecią.
Korzystając z biblioteki żądań, poniższy przykładowy kod pokazuje, jak wysłać żądanie HTTP POST:
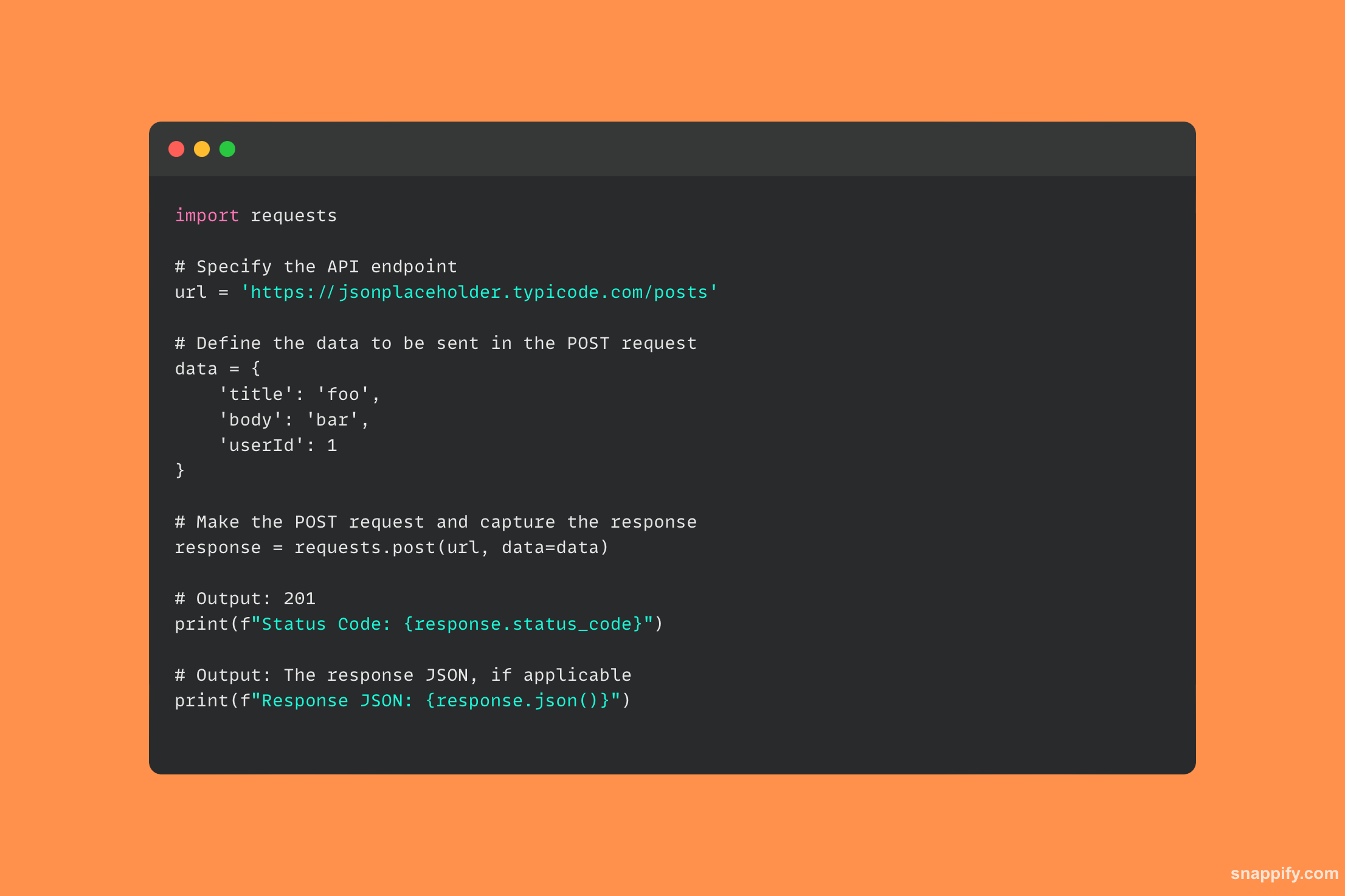
29. Jak połączyć się z bazą danych PostgreSQL za pomocą Pythona?
Współpraca z bazą danych PostgreSQL w środowisku Python jest obsługiwana elegancko przez pakiet psycopg2, potężny most, który pozwala na bezproblemową interakcję z bazą danych.
Za pomocą psycopg2programiści mogą łatwo tworzyć połączenia, uruchamiać zapytania SQL i uzyskiwać wyniki, bezpośrednio integrując możliwości PostgreSQL z programami w języku Python.
Możesz odblokować złożone funkcje bazy danych za pomocą zaledwie kilku linijek kodu, gwarantując, że dostęp do danych, ich modyfikacja i zapisywanie będą odbywały się z dokładnością i wydajnością.
Moduł ten umożliwia programistom pełne wykorzystanie relacyjnych baz danych w swoich aplikacjach poprzez eleganckie wykorzystanie synergii pomiędzy Pythonem i PostgreSQL.
Oto przykładowy kod demonstrujący sposób użycia psycopg2 biblioteka do nawiązania połączenia z bazą danych PostgreSQL:
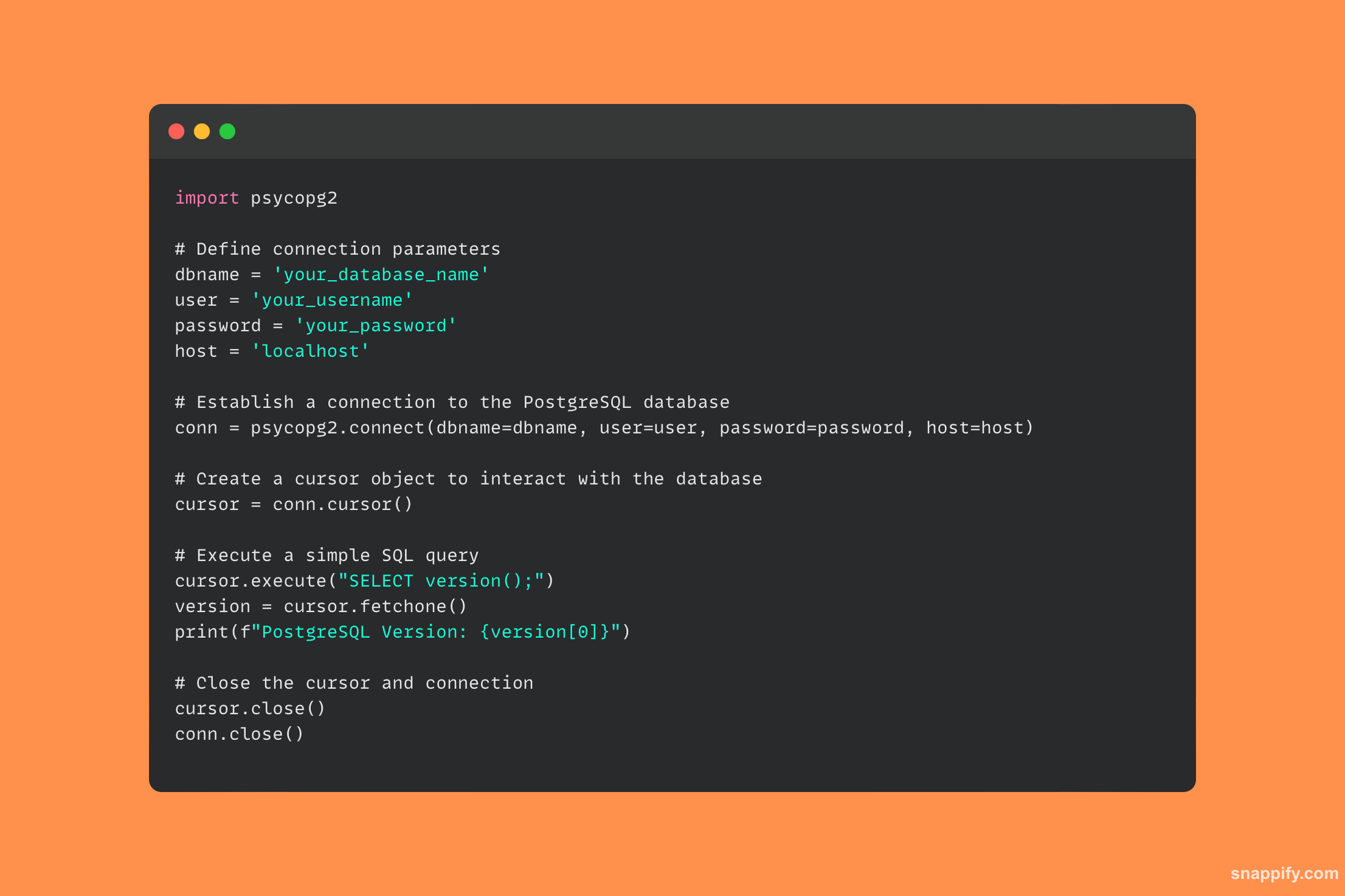
30. Jaka jest rola ORM w Pythonie i podaj jakiś popularny?
Mapowanie obiektowo-relacyjne (ORM) w Pythonie umożliwia programistom łączenie się z bazami danych przy użyciu klas Pythona i paradygmatów obiektowych.
Działa jako harmonijny mediator pomiędzy programowaniem obiektowym a administracją relacyjną bazą danych.
SQLAlchemy, jeden z najbardziej znanych ORM w środowisku Python, oferuje kompletny zestaw narzędzi do interakcji z wieloma bazami danych SQL przy użyciu składni zorientowanej obiektowo wysokiego poziomu.
Za pomocą SQLAlchemy jednostki bazy danych mogą być reprezentowane jako klasy Pythona, a instancje tych klas służą jako wiersze w tabelach bazy danych.
Dzięki temu programiści mogą pracować z bazami danych bez konieczności pisania surowych zapytań SQL.
Ze względu na złożoność SQL i łączności z bazami danych, ORM, takie jak SQLAlchemy, umożliwiają bardziej przyjazne dla użytkownika, bezpieczne i łatwiejsze w utrzymaniu interakcje z bazami danych.
Oto prosty przykład pokazujący, jak działa SQLAlchemy:
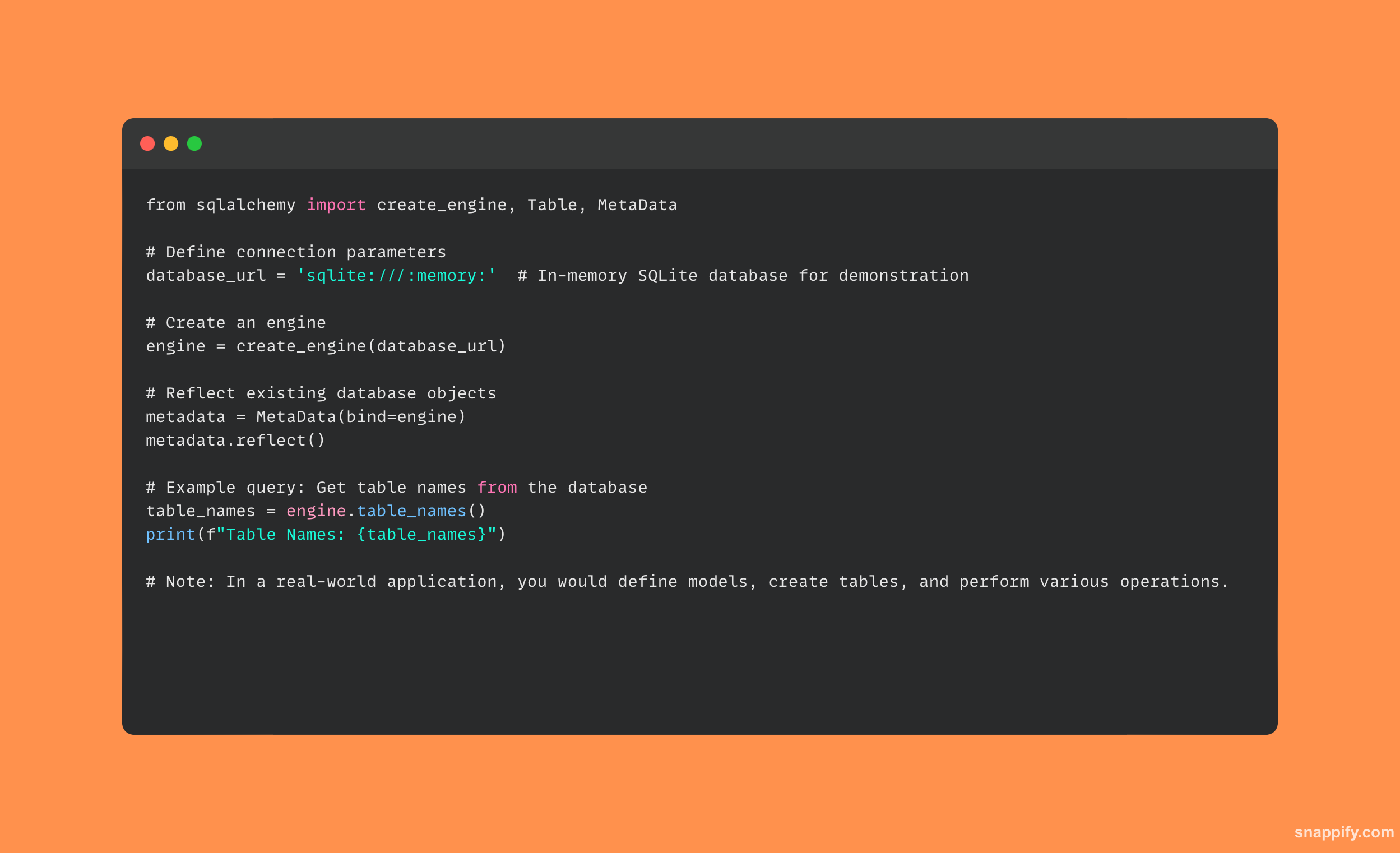
31. Jak sprofilowałbyś skrypt w Pythonie?
Skrypt w języku Python jest profilowany poprzez analizę jego struktury obliczeniowej oraz szczegółów czasowych i przestrzennych jego wykonania w celu znalezienia ewentualnych wąskich gardeł wydajnościowych i poprawy wydajności.
Programiści mogą dokładnie analizować zachowanie swojego kodu w czasie wykonywania, korzystając z wbudowanych funkcji cProfile moduł.
W ten sposób mogą uzyskać dokładne dane na temat wywołań funkcji, czasów wykonywania i relacji wywołań, co pozwala im identyfikować i eliminować wąskie gardła wydajności.
Możesz zagwarantować, że kod nie tylko będzie działał poprawnie, ale także wydajnie, równoważąc zasoby obliczeniowe i poprawiając ogólną wydajność aplikacji, włączając profilowanie do cyklu życia oprogramowania.
Programiści mogą zatem chronić programy przed nieefektywnością poprzez dokładne profilowanie, zapewniając, że są one niezawodnie dostrojone i wydajne w szerokim zakresie wymagań obliczeniowych.
Oto prosty przykład profilowania skryptu Pythona przy użyciu metody cProfile moduł:
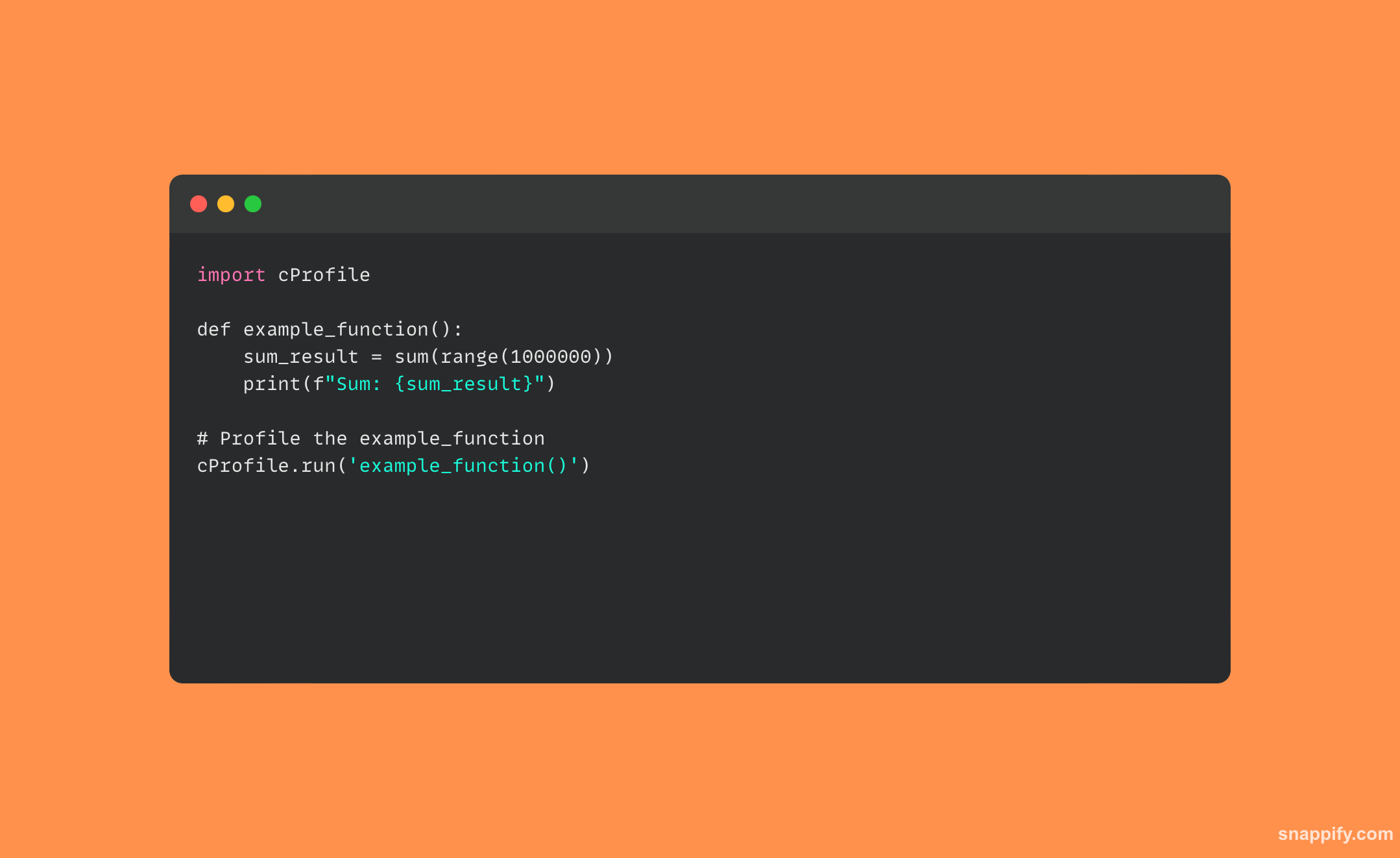
32. Wyjaśnij GIL (Global Interpreter Lock) w CPythonie
Globalna blokada interpretera (GIL) w CPythonie pełni funkcję strażnika, gwarantując, że tylko jeden wątek uruchamia kod bajtowy Pythona w danym momencie w jednym procesie, nawet w aplikacjach wielowątkowych.
Chociaż może się to wydawać wąskim gardłem, GIL ma kluczowe znaczenie w ochronie zarządzania pamięcią CPythona i wewnętrznych struktur danych przed równoczesnym dostępem i zachowaniu integralności systemu.
Należy jednak pamiętać o konieczności wielowątkowości w działaniach związanych z we/wy, gdzie wątki muszą czekać na dostarczenie lub odebranie danych, ponieważ GIL nie eliminuje tej potrzeby.
Tak więc, nawet jeśli GIL stwarza trudności w działaniach związanych z procesorem, zrozumienie jego zachowania i adaptacja technik, takich jak wykorzystanie przetwarzania wieloprocesowego lub programowania współbieżnego, pozwala programistom tworzyć efektywne, współbieżne programy w Pythonie.
Oto przykład kodu Pythona, który wykorzystuje wątki i pokazuje, jak GIL może mieć wpływ na zadania związane z procesorem:
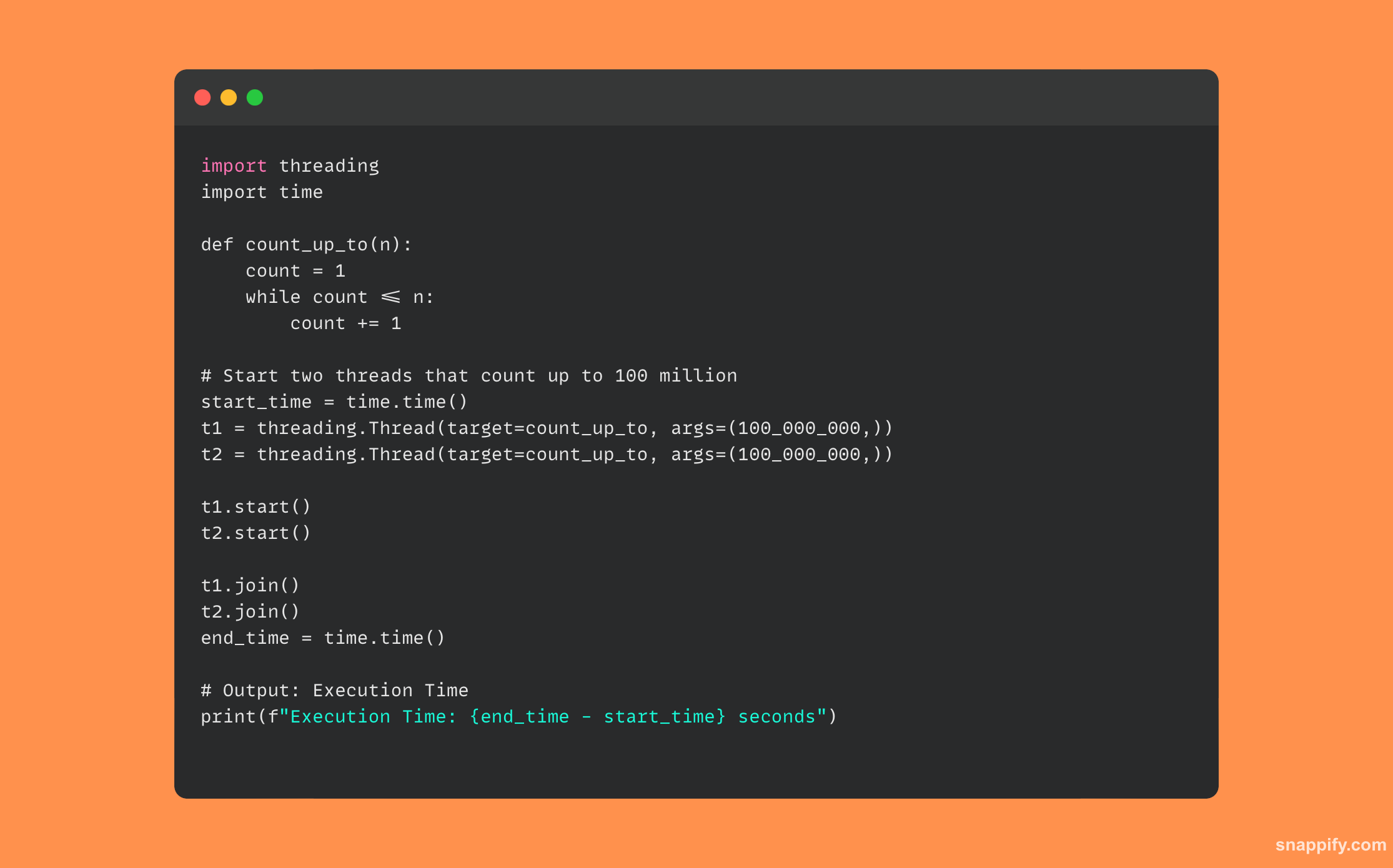
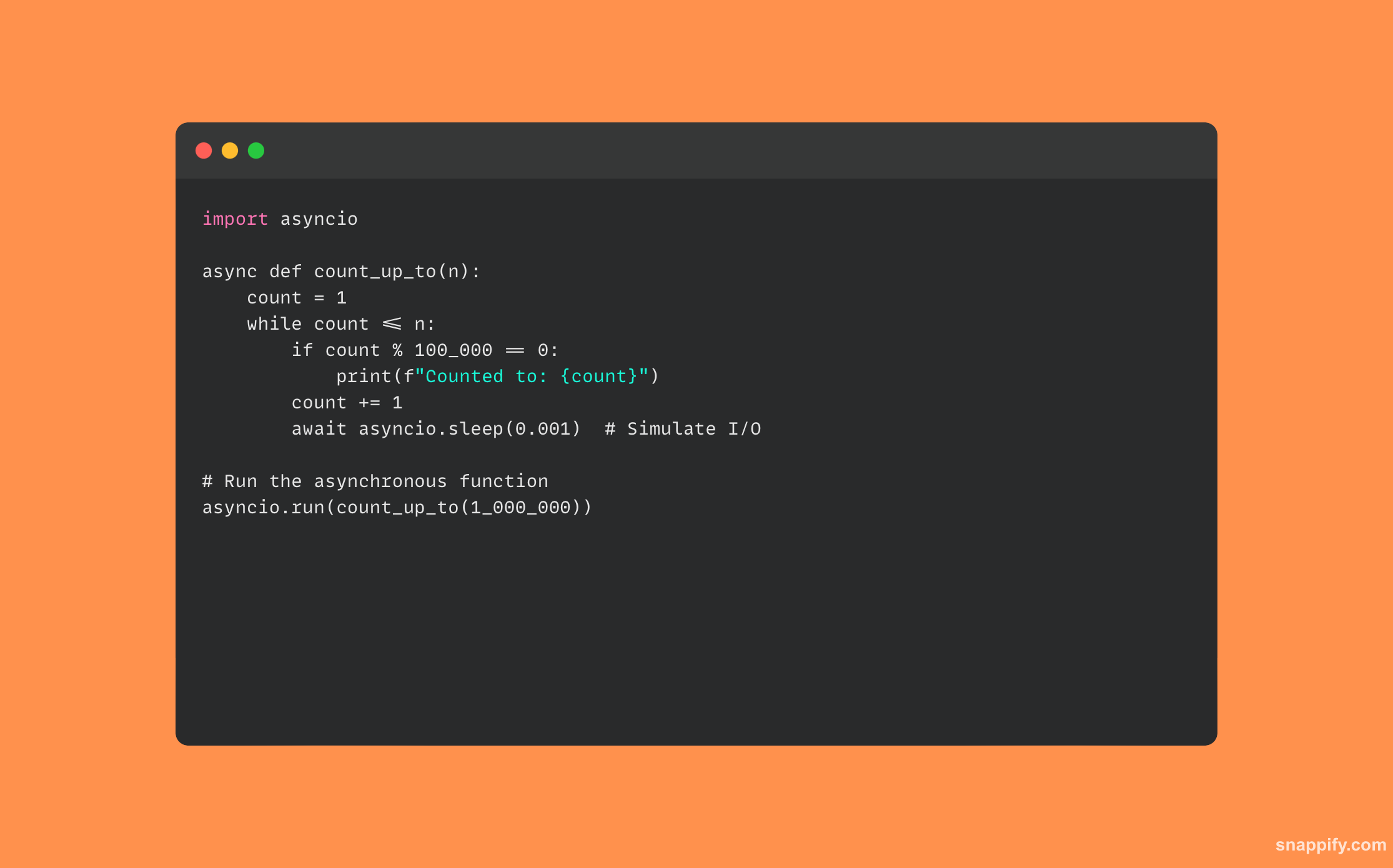
33. Wyjaśnij funkcję async/await w Pythonie. Czym różni się od tradycyjnego gwintowania?
Składnia async/await w Pythonie otwiera świat programowania asynchronicznego, paradygmatu, który pozwala niektórym funkcjom scedować kontrolę na środowisko wykonawcze, dzięki czemu w międzyczasie mogą być wykonywane inne działania, poprawiając wydajność programu.
Async/await utrzymuje działania w jednym wątku, ale umożliwia wykonanie przeskakiwanie między zadaniami, zapewniając zachowanie nieblokujące bez złożoności zarządzania wątkami.
Kontrastuje to z klasycznym wątkiem, w którym wątki działają równolegle i często wymagają skomplikowanego zarządzania i synchronizacji.
W rezultacie programiści mogą skutecznie obsługiwać współbieżne działania związane z we/wy i stosując prostsze podejście do kontrolowania współbieżności.
Promuje to model wielozadaniowości opartej na współpracy, w którym procesy chętnie oddają kontrolę.
W rezultacie async/await oferuje charakterystyczny, uproszczony sposób projektowania współbieżnych aplikacji, szczególnie tam, gdzie często występują operacje we/wy, zapewniając równowagę między wydajnością a złożonością.
Poniżej znajduje się przykład kodu Pythona korzystającego z funkcji async/await:
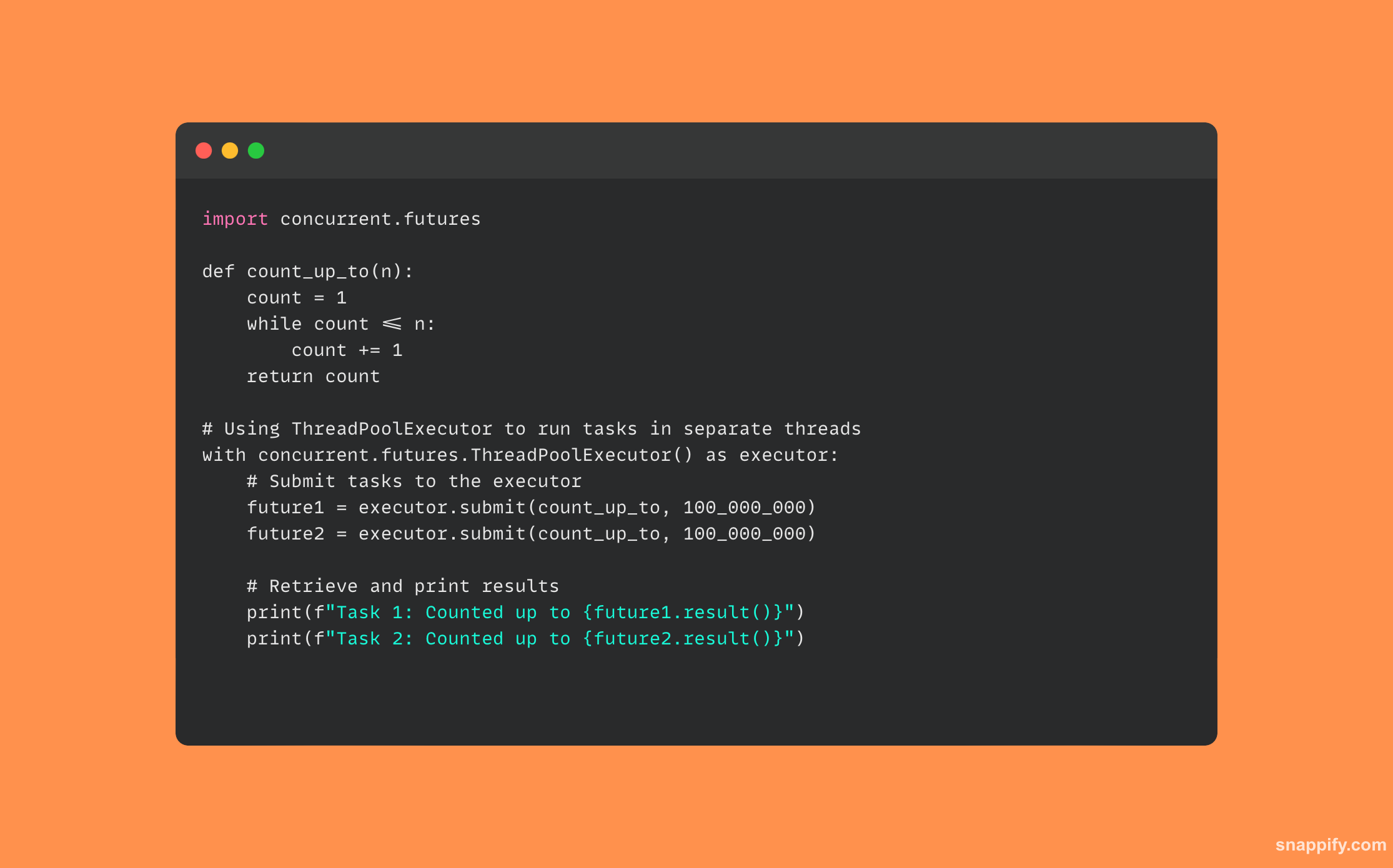
34. Opisz, jak użyłbyś języka Python concurrent.futures.
interfejs do asynchronicznego wykonywania wywołań za pośrednictwem wątków lub procesów, programiści mogą z wdziękiem zarządzać operacjami asynchronicznymi i równoległymi.
Moduł ten zarządza alokacją zasobów i wykonywaniem elementów wywołujących, jednocześnie hermetyzując delikatne aspekty wątków i przetwarzania wieloprocesowego za pomocą modułów wykonawczych (ThreadPoolExecutor i ProcessPoolExecutor).
Programiści mogą efektywnie wykorzystywać procesory wielordzeniowe do działań związanych z procesorem i zapewniać nieblokujące operacje we/wy, wysyłając zadania do modułu wykonującego, który może je następnie wykonywać współbieżnie, a nawet agregować ich wyniki.
Aby mieć pewność, że aplikacje będą responsywne i wydajne, concurrent.futures tworzy przestrzeń, w której złożone obliczenia i działania we/wy mogą płynnie łączyć się.
Oto przykład kodu, który używa concurrent.futures:
35. Porównaj Django i Flask pod względem przypadków użycia i skalowalności.
Dwie gwiazdy w konstelacji frameworków internetowych Pythona, Django i Flask, świecą jasno, spełniając różne wymagania programistów.
Dla programistów tworzących ogromne aplikacje oparte na bazach danych, Django jest narzędziem z wyboru, ponieważ zawiera ORM i wbudowany interfejs administracyjny.
Jednak prosta i modułowa konstrukcja Flask daje programistom swobodę wyboru własnych komponentów, co czyni go idealnym wyborem dla mniejszych projektów lub sytuacji, w których niezbędne jest lekkie, elastyczne rozwiązanie.
Obydwa frameworki można skalować, aby sprostać większym wymaganiom w zakresie skalowalności.
Jednak szczupła natura Flaska pozwala na niestandardowe taktyki skalowania, które są dostosowane do konkretnych potrzeb, podczas gdy wbudowane możliwości Django mogą dać mu niewielką przewagę w zakresie szybkiego rozwoju w większych, bardziej skomplikowanych projektach.
Wnioski
Rozmowy kwalifikacyjne dotyczące skryptów w języku Python wymagają dogłębnej wiedzy na temat możliwości, złożoności i zastosowań języka.
Dokładne przygotowanie nie tylko wzmacnia kompetencje techniczne, ale także budzi pewność siebie, pomagając kandydatom szybko i trafnie poruszać się po trudnym labiryncie pytań.
Kandydaci mogą upewnić się, że są przygotowani do radzenia sobie zarówno z podstawowymi, jak i stosowanymi problemami Pythona, przeglądając kluczowe pojęcia, takie jak współbieżność, zasady OOP i struktury danych, a także zagłębiając się w praktyczne zastosowania, takie jak programowanie internetowe i manipulacja danymi.
W rezultacie posiadanie wszechstronnego wykształcenia staje się niezbędne do osiągnięcia sukcesu i może prowadzić do sytuacji, w których umiejętności programowania w języku Python mogą być doskonałe i wykazywać się kreatywnością. Widzieć Seria wywiadów z haszdorkiem o pomoc w przygotowaniu rozmowy kwalifikacyjnej.





Dodaj komentarz