Spis treści[Ukryć][Pokazać]
Sposób, w jaki komunikujemy się z maszynami i innymi gadżetami, został całkowicie zmieniony przez rozwój oprogramowania do rozpoznawania mowy opartego na sztucznej inteligencji.
Konwertuje wypowiadane słowa na tekst drukowany z zadziwiającą precyzją i wydajnością przy użyciu algorytmów sztucznej inteligencji. Ta technologia ma zastosowanie w wielu sektorach, od opieki zdrowotnej i obsługi klienta po edukację i rozrywkę.
W ostatnich latach nastąpił ogromny wzrost zapotrzebowania na precyzyjną i efektywną konwersję mowy na tekst.
Zarówno firmy, jak i ludzie dostrzegają ogromną użyteczność oprogramowania do rozpoznawania mowy AI, biorąc pod uwagę szybki rozwój technologii i rosnącą zależność od komunikacji cyfrowej.
Potrzeba ta wynika z chęci poprawy produktywności, usprawnienia procedur oraz zwiększenia dostępności dla osób z niepełnosprawnościami.
W celu prowadzenia dokumentacji pacjentów i umożliwienia skutecznego świadczenia opieki zdrowotnej dokładne i szybkie transkrypcje dyktand lekarskich są niezbędne w sektorach takich jak opieka zdrowotna.
Dzięki automatyzacji procesu transkrypcji, wyeliminowaniu konieczności ręcznego wprowadzania danych oraz zapewnieniu większej dokładności i szybkości powstało oprogramowanie do rozpoznawania mowy oparte na sztucznej inteligencji.
Ponadto działy obsługi klienta wykorzystują tę technologię, aby przyspieszyć czas reakcji i zapewnić zindywidualizowaną obsługę.
Firmy mogą wykrywać wzorce, ulepszać swoje usługi i dokonywać wyborów w oparciu o dane, zapisując rozmowy z klientami i uzyskując wnikliwe informacje z tych interakcji.
Kolejną branżą, która czerpie korzyści z oprogramowania do rozpoznawania mowy opartego na sztucznej inteligencji, jest edukacja, ponieważ umożliwia ono tworzenie najnowocześniejszych narzędzi dydaktycznych.
Bardziej dynamiczne i wciągające środowisko uczenia się można promować, umożliwiając uczniom dyktowanie zadań lub interakcję głosową z wirtualnymi instruktorami.
Sektor rozrywki również przyjął technologię rozpoznawania głosu AI, torując drogę dla inteligentnych produktów aktywowanych głosem i wirtualnych asystentów, które poprawiają komfort użytkowania.
Dzięki komendom głosowym do odtwarzania multimediów i wyszukiwarkom aktywowanym głosem technologia ta sprawia, że korzystanie z rozrywki jest łatwe i wygodne.
W tym artykule przyjrzymy się najlepszemu oprogramowaniu do rozpoznawania mowy AI.
1. Obrót silnika
Rev to oparty na chmurze program do rozpoznawania mowy, który stał się bardziej popularny wśród firm i osób poszukujących precyzyjnych i skutecznych usług transkrypcji danych audio i wideo. Wykorzystanie przez Rev najnowocześniejszych algorytmów sztucznej inteligencji do konwersji mowy na tekst czyni ją wyjątkową.
Aby właściwie przekonwertować słowa mówione na tekst pisany, te złożone algorytmy wykorzystują mocne strony uczenie maszynowe i przetwarzania języka naturalnego.
Szeroka gama akcentów, dialektów i języków może być rozpoznawana i interpretowana przez algorytmy sztucznej inteligencji Rev, ponieważ zostały one przeszkolone na ogromnych ilościach danych.
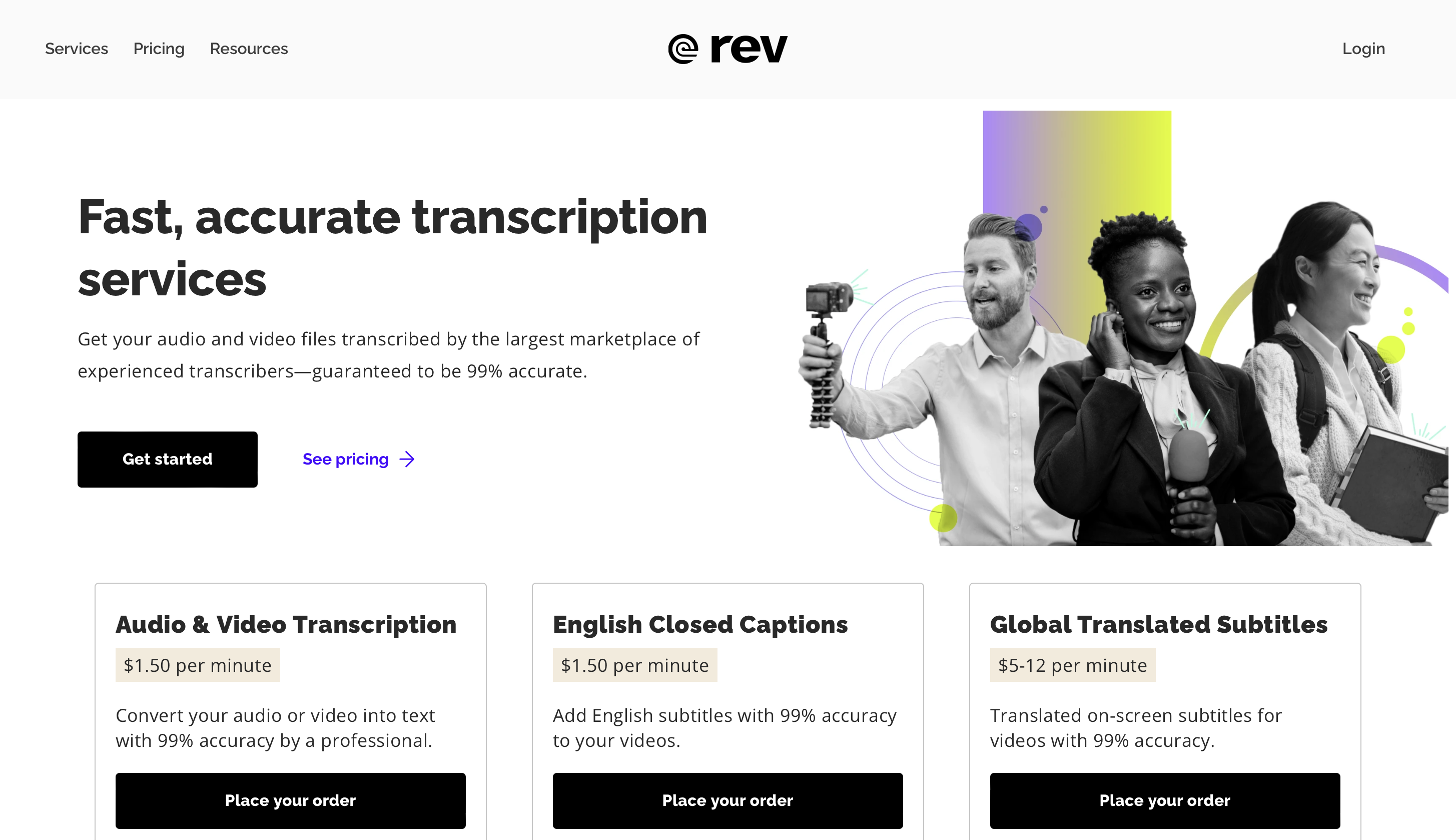
W rezultacie Rev może dostarczać niezwykle dokładne usługi transkrypcji, które można również dostosować do konkretnych potrzeb językowych. Program może obsługiwać różne typy plików audio, w tym podcasty, konferencje, wywiady i filmy.
Rev przedkłada wydajność nad dokładność, zapewniając szybkie czasy realizacji bez utraty jakości. Program może szybko przetwarzać ogromne ilości danych audio i wideo dzięki zoptymalizowanemu przepływowi pracy i skalowalnej infrastrukturze.
Zakres usług transkrypcji Rev wykracza poza zwykłe tłumaczenie mowy na tekst.
Ponadto program zapewnia opcje formatowania, identyfikacji mówcy i znaczników czasu.
Znacznik czasu nadaje transkrybowanemu tekstowi odniesienie chronologiczne, a identyfikacja mówcy ułatwia rozróżnienie różnych uczestników konwersacji.
Opcje formatowania zapewniają klientom możliwość dostosowania prezentacji i układu transkrypcji do własnych wymagań.
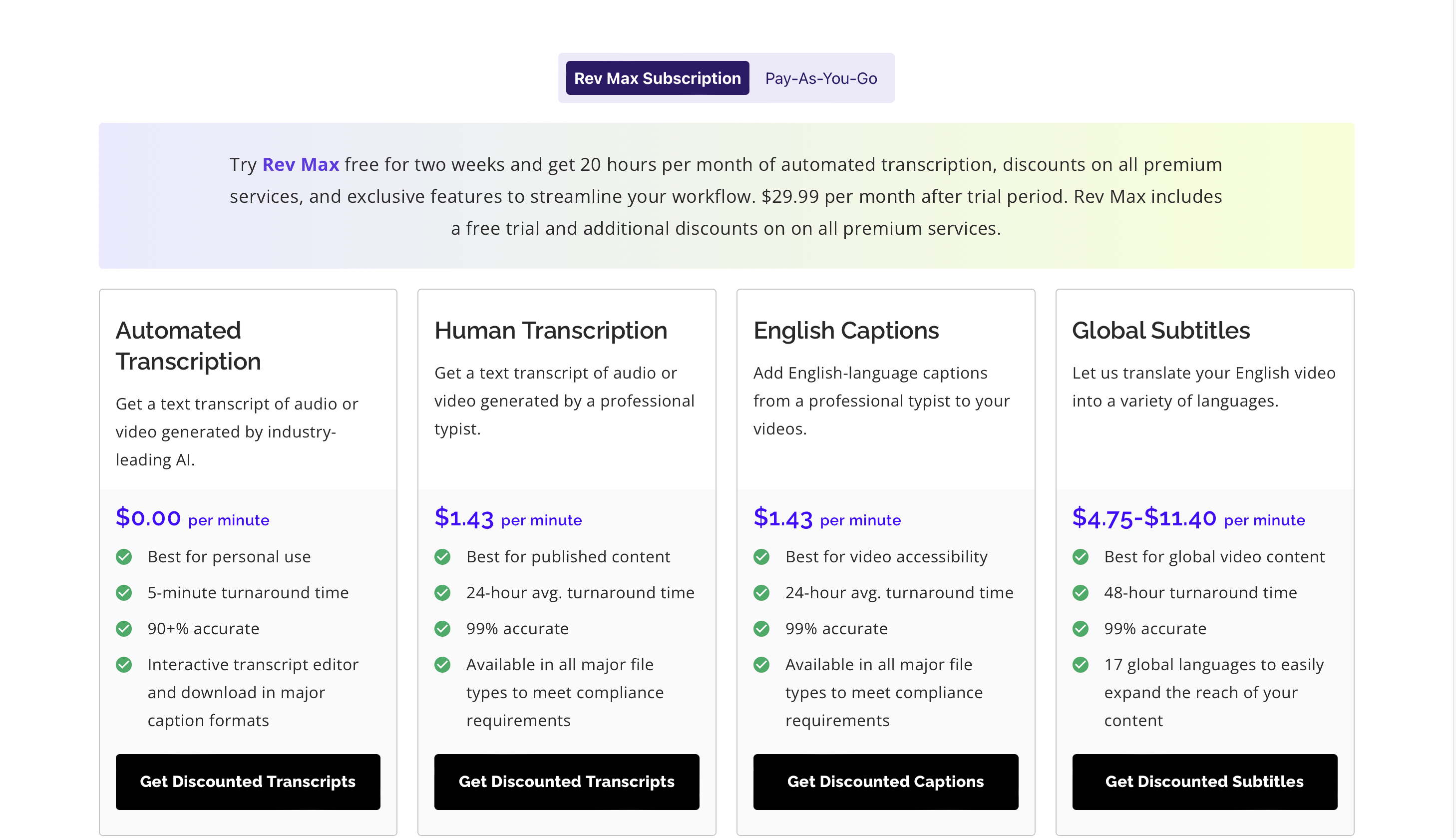
Cennik
Możesz wypróbuj Rev Max za darmo przez 2 tygodnie, a ceny premium zaczynają się od 29.99 USD miesięcznie.
2. Profesjonalny smok Nuance
Nuance Dragon Professional to wiodące na rynku oprogramowanie do rozpoznawania mowy, które zapewnia pełny zestaw funkcji i możliwości, aby umożliwić profesjonalistom z wielu różnych sektorów.
Dzięki wyrafinowanym funkcjom poleceń głosowych możesz obsługiwać komputer bez użycia rąk, przeglądając aplikacje i dyktując dokumenty, zwiększając wydajność i produktywność. Program ma wyjątkowy poziom dokładności transkrypcji, dzięki czemu wypowiadane słowa są niezawodnie konwertowane na formę pisemną.
Oferując specjalistyczne słownictwo i modele językowe, Nuance Dragon Professional spełnia wymagania poszczególnych branż. Korzystając ze specjalistycznych słowników i wyboru słownictwa, profesjonaliści z branż takich jak opieka zdrowotna, prawo i finanse mogą zwiększyć produktywność i tworzyć dokładniejsze transkrypcje.
Dodatkowo program może rozpoznawać różne wzorce mowy i dialekty dzięki konfigurowalnym przez użytkownika profilom głosowym.
Pracownicy służby zdrowia mogą rejestrować notatki pacjentów, dane medyczne i recepty z niezwykłą precyzją za pomocą Nuance Dragon Professional w branży medycznej, co zmniejsza obciążenie administracyjne i poprawia opiekę nad pacjentem.
Jego funkcje rozpoznawania mowy mogą być wykorzystywane przez prawników do szybkiego i skutecznego przygotowywania dokumentów sądowych i tworzenia notatek ze spraw.
Program upraszcza również procedury dokumentacyjne w branży bankowej i ubezpieczeniowej, umożliwiając ekspertom szybkie i precyzyjne tworzenie komunikatów, roszczeń i raportów.
Poza prostym dyktowaniem, zaawansowane możliwości poleceń głosowych oprogramowania umożliwiają wykorzystanie poleceń głosowych do wykonywania skomplikowanych instrukcji, zarządzania programami i wykonywania zadań komputerowych. Ta funkcja będzie szczególnie przydatna dla osób mających problemy z poruszaniem się lub preferujących obsługę bez użycia rąk.
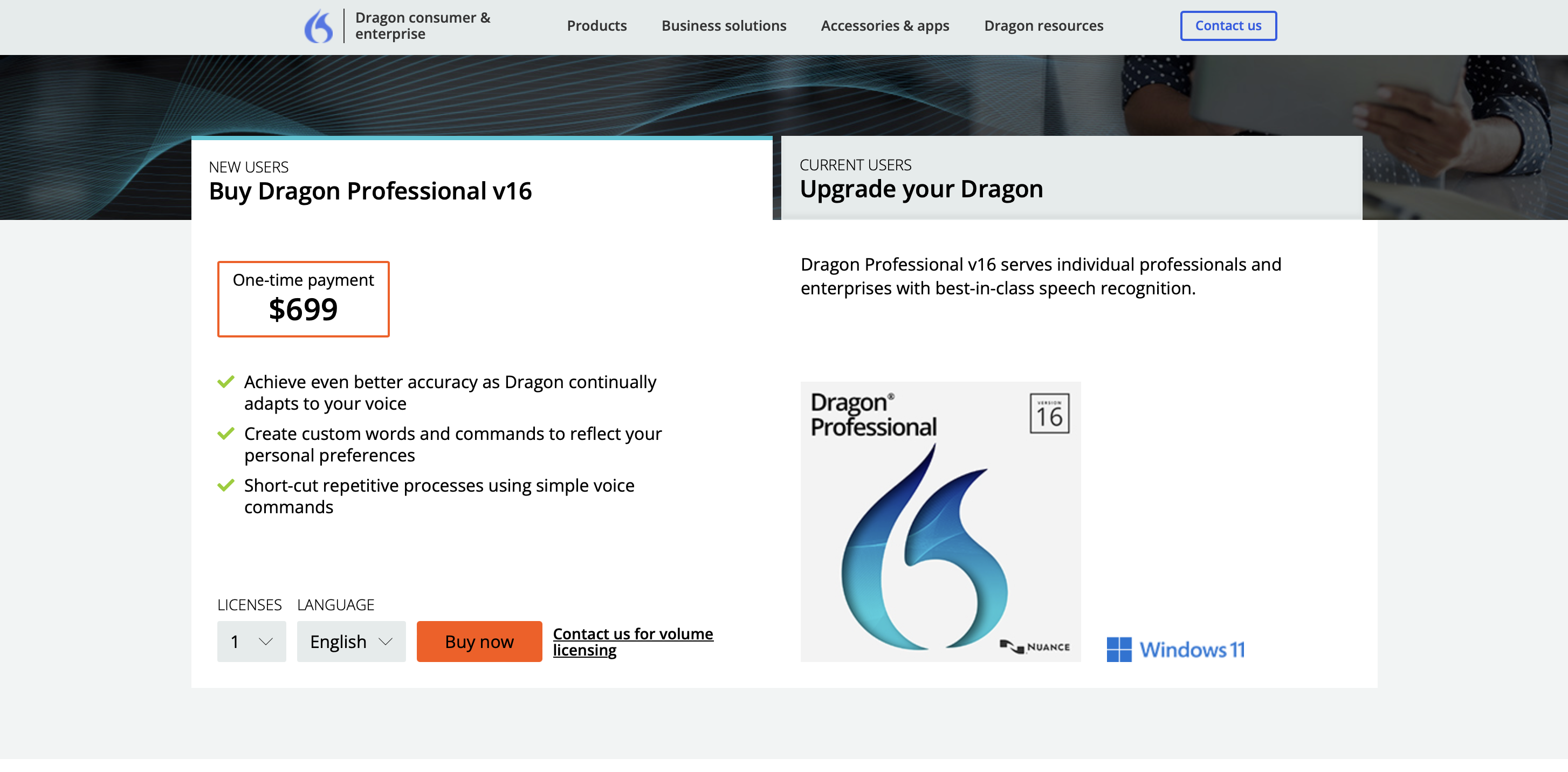
Cennik
Cena premium oprogramowania do zakupu wynosi 699 USD.
3. Zamiana mowy na tekst w Google Cloud
Google Cloud Speech-to-Text to dobrze znany program do rozpoznawania mowy AI o wyjątkowych mocach i kompetencjach technologicznych.
Jest to idealna opcja dla firm i programistów poszukujących precyzyjnej konwersji mowy na tekst, ponieważ jest składnikiem Google Cloud Platform i oferuje pełen zakres funkcji.
Wyjątkową cechą programu jest jego duża dokładność, którą wykorzystuje wyrafinowany algorytmy uczenia maszynowego konwertować słowa mówione na tekst pisany z niesamowitą dokładnością.
Ponadto usługa Google Cloud Speech-to-Text oferuje szeroką gamę kompatybilności językowej, umożliwiając tłumaczenie dźwięku na różne języki, dialekty i akcenty. Jest to przydatne narzędzie dla międzynarodowych korporacji i aplikacji, które używają kilku języków ze względu na szeroki zakres językowy.
Program jest odpowiedni dla aplikacji o dużym zapotrzebowaniu na transkrypcję, ponieważ może szybko obsłużyć ogromne ilości danych audio, wykorzystując moc chmury.
Dzięki opartej na chmurze architekturze Google Cloud Speech-to-Text programiści mogą bez wysiłku integrować ją z innymi usługami i interfejsami API Google Cloud, aby tworzyć aplikacje w pełni sterowane głosem.
Program oferuje również inne funkcje, które poprawiają dokładność i użyteczność transkrypcji, takie jak nagrywanie mówcy, automatyczna interpunkcja i zrozumienie kontekstu.
Podczas gdy zapis mówcy umożliwia rozpoznanie i rozróżnienie wielu mówców w dyskusji, automatyczna interpunkcja zapewnia przejrzystość i strukturę danych wyjściowych.
Rozumienie kontekstowe pomaga w interpretacji i transkrypcji dźwięku w zależności od konkretnych dziedzin lub żargonu biznesowego.
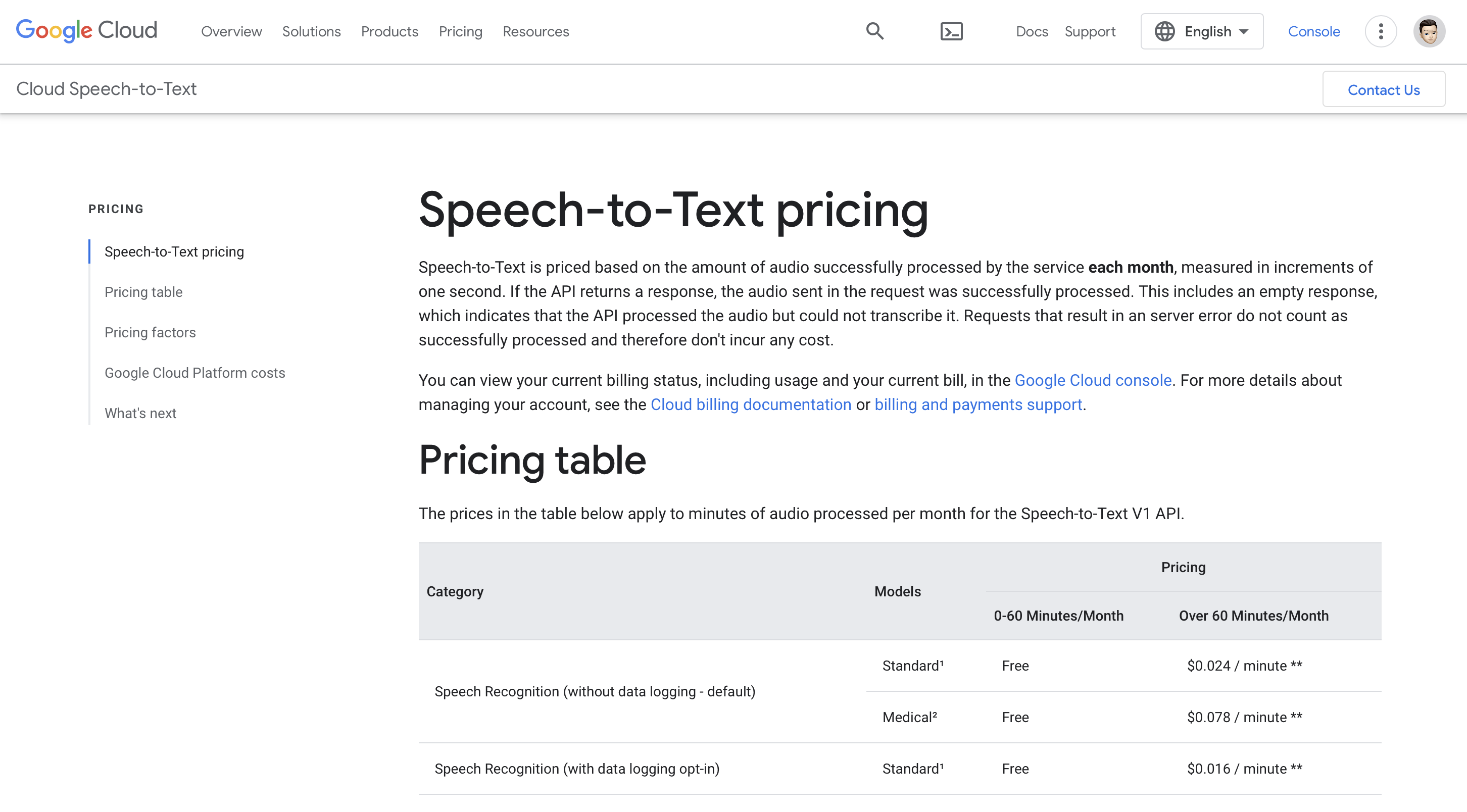
Cennik
Można z niego korzystać bezpłatnie przez 0-60 minut/miesiąc, a ceny premium zaczynają się powyżej 60 minut/miesiąc, czyli 0.024 USD/minutę.
4. Usługi mowy Microsoft Azure
Microsoft Azure Speech Services to przełomowa technologia rozpoznawania głosu, która zmieniła nasze interakcje z maszynami i gadżetami. Jego wyrafinowane umiejętności transkrypcyjne umożliwiają konwersję słów mówionych na tekst pisany z dokładnością i wydajnością.
W rezultacie można usprawnić operacje i poprawić dostępność, jednocześnie umożliwiając organizacjom i ludziom uzyskanie wnikliwego wglądu w dane audio. Wykracza poza zwykłe rozpoznawanie głosu, obejmując funkcje rozumienia języka naturalnego (NLU).
Może zrozumieć intencje użytkownika i udzielić odpowiedzi bardziej adekwatnych do kontekstu, badając kontekst i znaczenie wypowiadanych słów. Ułatwiając komunikację z aplikacjami i wirtualnymi asystentami, ta zdolność rozumienia języka naturalnego poprawia komfort użytkowania.
Ponadto programiści mogą opracowywać w pełni sterowane głosem aplikacje dzięki możliwości płynnej integracji Microsoft Azure Speech Services z innymi usługami i interfejsami API platformy Azure.
Oferuje zestawy do tworzenia oprogramowania (SDK) i interfejsy API, które umożliwiają prostą integrację z już istniejącymi aplikacjami i systemami, a także obsługuje wiele języków programowania.
Microsoft Azure Speech Services zapewnia możliwości, w tym syntezę mowy, rozpoznawanie mówcy, tłumaczenie języka i rozumienie języka naturalnego oprócz transkrypcji i NLU.
Wyższy poziom bezpieczeństwa i personalizacji zapewnia funkcja rozpoznawania mówców, która umożliwia identyfikację i weryfikację niektórych mówców.
Wielojęzyczną komunikację ułatwiają technologie tłumaczeń językowych, które umożliwiają tłumaczenie mowy w czasie rzeczywistym na wiele języków.
Ponadto synteza mowy poprawia jakość aplikacji i usług głosowych, wytwarzając mowę, która brzmi jak ludzka mowa.
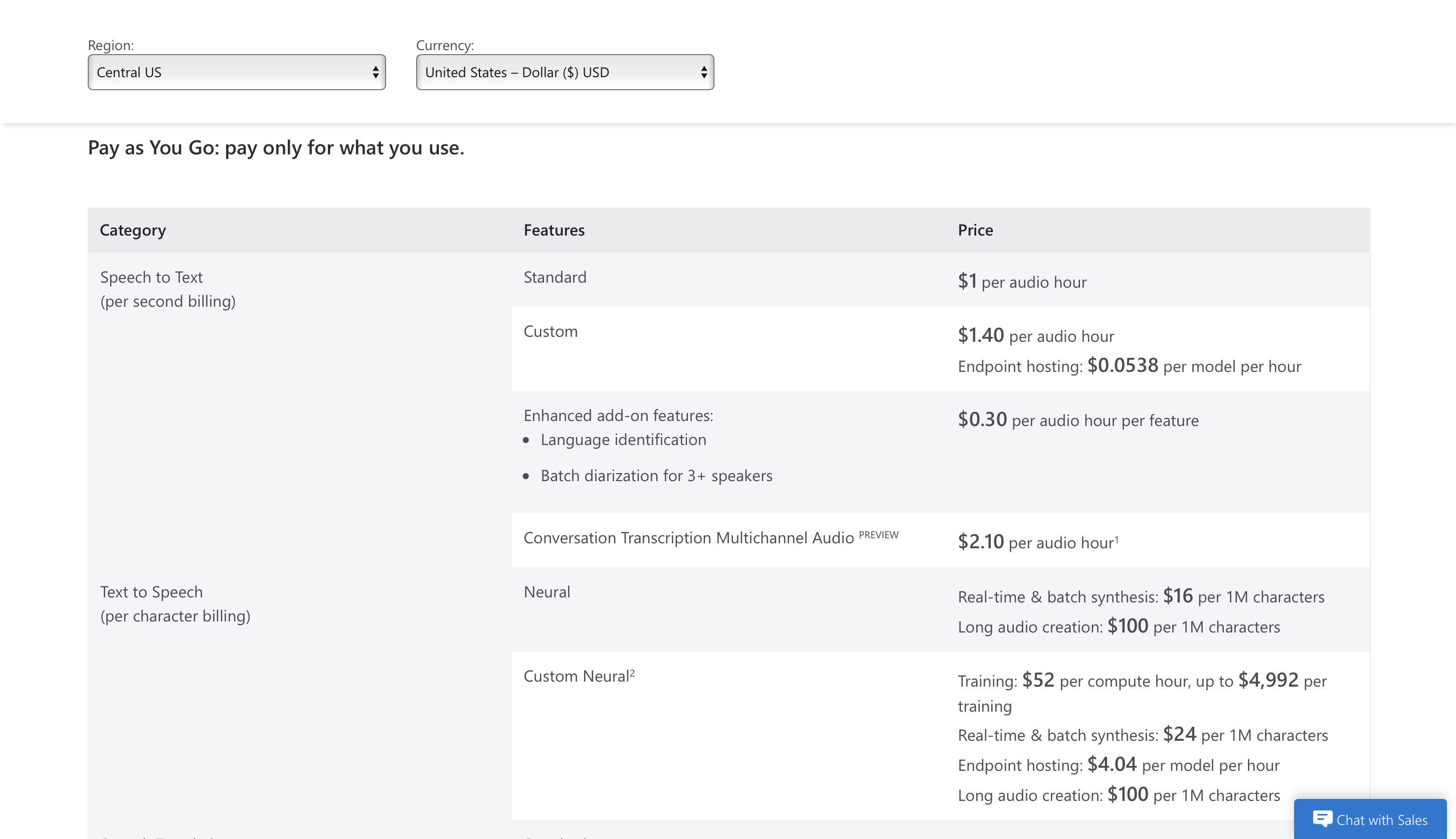
Cennik
Możesz zacząć korzystać z niego za darmo przez 5 godzin dźwięku miesięcznie, a ceny premium zaczynają się od 1 USD za godzinę dźwięku.
5. Amazon Transcribe
Amazon Transcribe to bardzo przydatna aplikacja, która zapewnia kilka korzyści, jeśli chodzi o efektywną konwersję głosu na tekst i rozpoznawanie mowy.
Dzięki wyjątkowej skalowalności tego opartego na chmurze rozwiązania firmy Amazon Web Services (AWS) firmy mogą skutecznie zarządzać ogromnymi ilościami danych audio.
Amazon Transcribe jest w stanie z łatwością dostosować się do zmieniających się wymagań dotyczących transkrypcji, niezależnie od tego, czy dotyczą one spotkań, wywiadów czy rozmów telefonicznych z obsługą klienta. Firmy mogą uzyskiwać cenne informacje z informacji dźwiękowych, korzystając z dokładnych transkrypcji, które są rutynowo dostarczane przez technologię automatycznego rozpoznawania mowy.
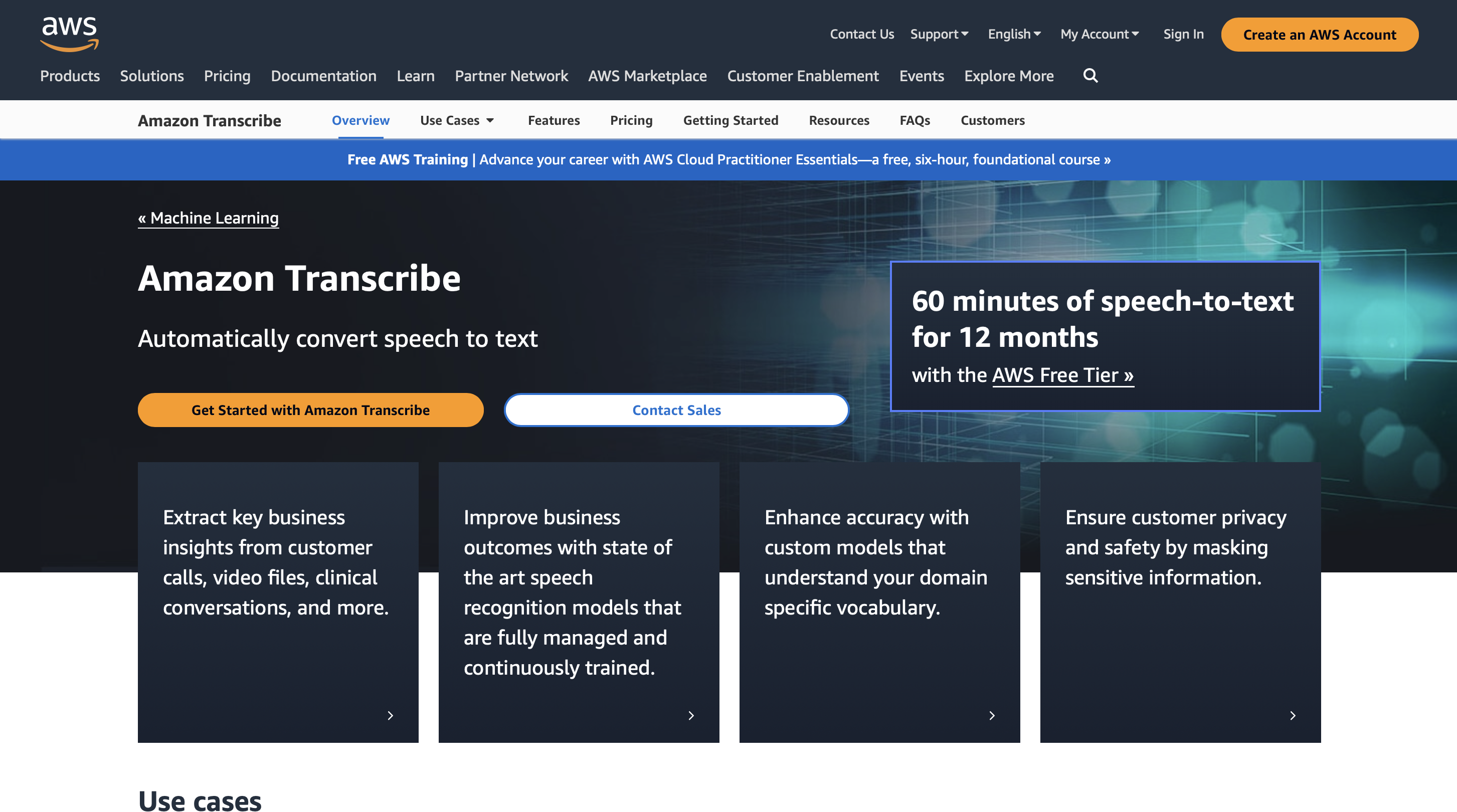
Wykorzystanie zaawansowanych algorytmów uczenia maszynowego, które nieustannie się uczą i stają się coraz lepsze, znacznie poprawia dokładność Amazon Transcribe.
Integruje się z innymi usługami Amazon Web Services bez żadnych problemów. Za pomocą tego połączenia organizacje mogą szybko dodawać funkcje rozpoznawania głosu do swojej obecnej infrastruktury AWS, redukując procesy i zwiększając ogólną efektywność.
Ponadto Amazon Transcribe oferuje dodatkowe metadane, takie jak znaczniki czasu, umożliwiające łatwiejsze przeglądanie i przeszukiwanie transkrybowanego tekstu.
Może skutecznie analizować i transkrybować dowolny rozmiar pliku audio. Firmy mogą korzystać z Amazon Transcribe, aby poradzić sobie z obciążeniem, zapewniając szybkie i dokładne transkrypcje, niezależnie od tego, czy mają kilka minut, czy kilka godzin dźwięku do transkrypcji.
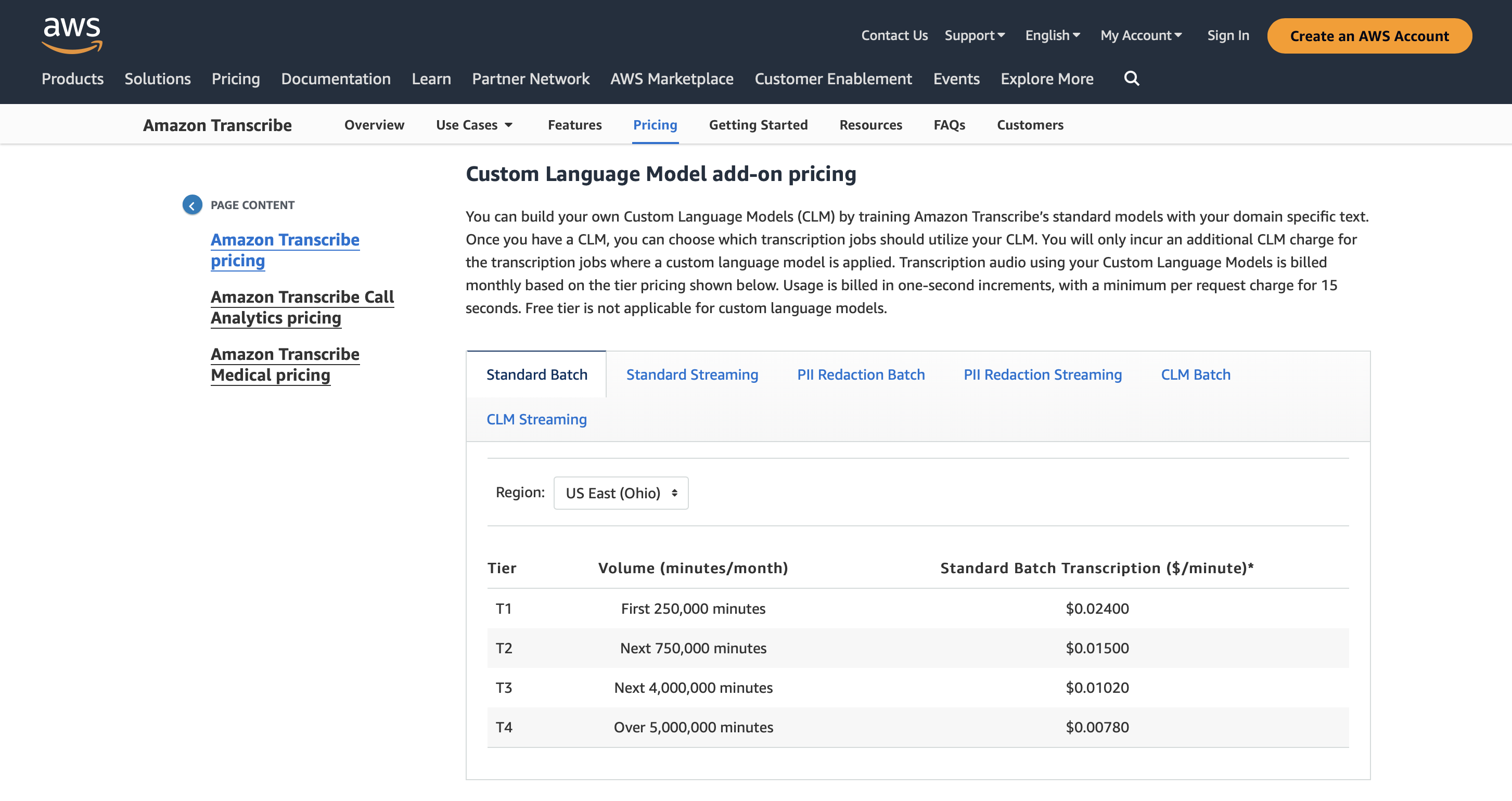
Cennik
Możesz korzystać z Amazon Transcribe przez 60 minut miesięcznie przez 12 miesięcy, a ceny premium zaczynają się od 0.02400 USD za minutę
6. IBM Watson Mowa na tekst
IBM Watson Speech to Text to solidne narzędzie do rozpoznawania i transkrypcji głosu, które obejmuje szereg zaawansowanych funkcji i opcji dostosowywania. Język mówiony jest precyzyjnie tłumaczony na tekst pisany za pomocą tej usługi opartej na chmurze, która wykorzystuje najnowocześniejsze technologie, takie jak głęboka nauka i przetwarzania języka naturalnego.
Dzięki kompleksowej obsłudze języków użytkownicy mogą dokonywać transkrypcji dźwięku w różnych językach i dialektach. Dla firm, które prowadzą działalność międzynarodową lub potrzebują wielojęzycznych usług transkrypcyjnych, ta możliwość adaptacji sprawia, że jest to nieocenione narzędzie.
Ponadto IBM Watson Speech to Text oferuje modele i słowniki wyspecjalizowane w określonej branży, które można dostosować do jej wymagań.
IBM Watson Speech to Text może dostosować się do specyficznych potrzeb wielu firm, niezależnie od tego, czy działają one w sektorze prawnym, finansowym czy medycznym.
Zdolność rozwiązania IBM Watson Speech to Text do obsługi dźwięku w trybie wsadowym lub w czasie rzeczywistym zapewnia elastyczność w zależności od własnych potrzeb. Podczas gdy transkrypcja wsadowa dobrze sprawdza się w przypadku nagranych wcześniej plików audio, transkrypcja w czasie rzeczywistym najlepiej sprawdza się w zastosowaniach takich jak analiza mowy i napisy na żywo.
Ponadto IBM Watson Speech to Text oferuje zaawansowane funkcje diaryzacji mówców, które umożliwiają rozpoznawanie i rozdzielanie różnych mówców w źródle dźwięku.
Gdy występuje wielu mówców, np. podczas nagrań z konferencji lub wywiadów, funkcja ta jest bardzo pomocna. Dzięki bezproblemowemu połączeniu z innymi usługami i interfejsami API IBM Watson programiści mogą szybko i łatwo tworzyć solidne aplikacje głosowe.
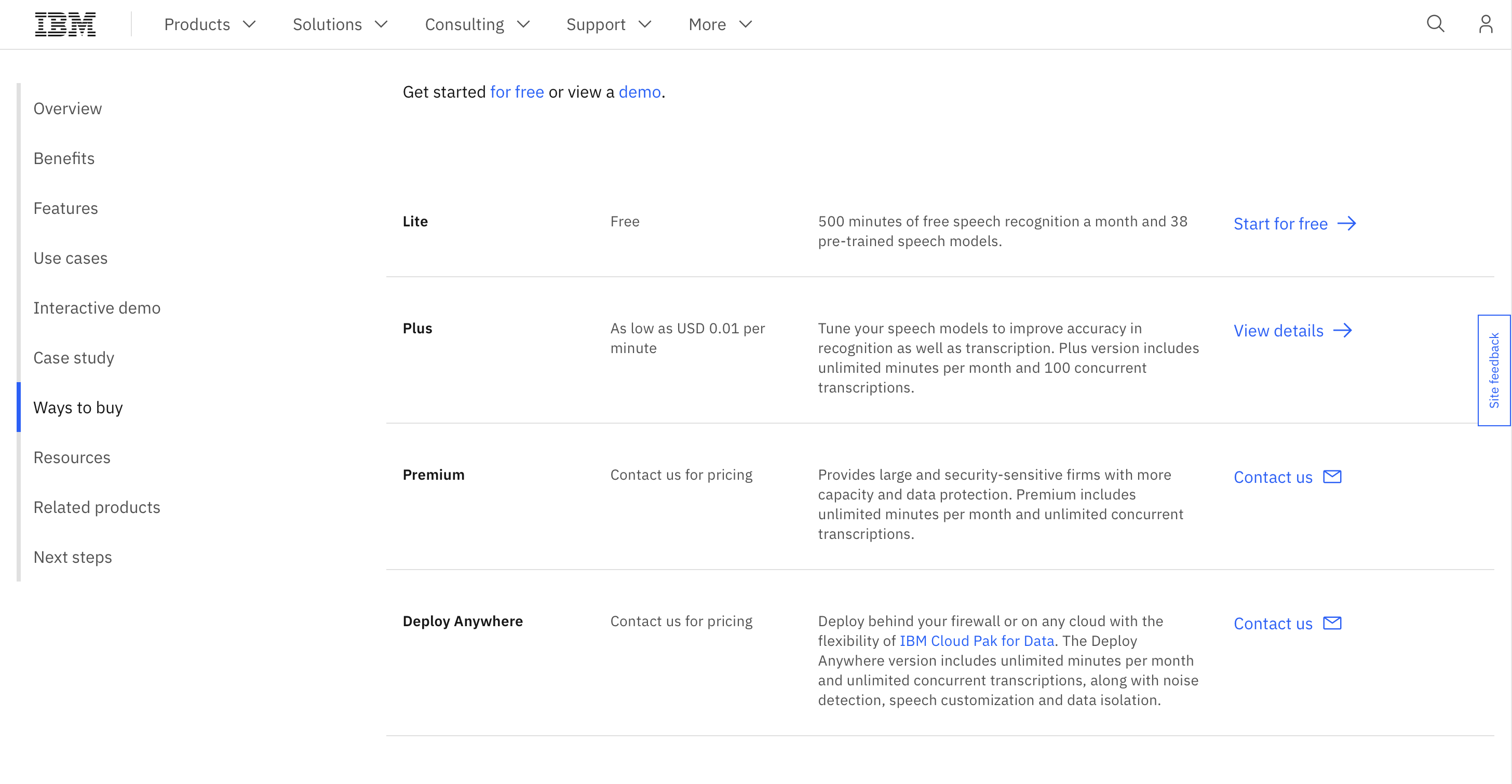
Cennik
Możesz korzystać z usługi przez 500 minut bezpłatnego rozpoznawania mowy miesięcznie, a ceny premium zaczynają się od 0.01 USD za minutę.
7. Szept OpenAI
OpenAI Whisper to najnowocześniejszy interfejs API do rozpoznawania głosu, który wykorzystuje najnowocześniejsze technologie w celu osiągnięcia wyjątkowej wydajności. Whisper to godne zaufania rozwiązanie dla organizacji i programistów, ponieważ dokładnie konwertuje język mówiony na tekst pisany dzięki silnym modelom uczenia maszynowego.
Ten interfejs API wyróżnia się wielojęzycznymi możliwościami, które umożliwiają tłumaczenie treści audio na inne języki, dialekty i akcenty, obsługując zróżnicowaną bazę użytkowników.
System OpenAI Whisper może rozpoznawać i rozumieć różne wzorce i odmiany mowy, ponieważ jest zbudowany na dużym zbiorze danych szkoleniowych.
Szepty głębokie sieci neuronowe został przeszkolony w zakresie ogromnych ilości danych dźwiękowych, dzięki czemu jest teraz w stanie rozpoznawać i transkrybować wypowiadane frazy z zadziwiającą dokładnością.
Oferuje precyzyjne i skuteczne usługi transkrypcji i znajduje zastosowanie w sektorach takich jak opieka zdrowotna, obsługa klienta i media. Whisper może pomóc w dyktowaniu medycznym w branży medycznej, pomagając ekspertom w utrzymaniu prawidłowych danych pacjentów.
Pozwala na transkrypcję interakcji konsumenckich w obsłudze klienta, usprawniając analizę i kontrolę jakości. Aby poprawić dostępność i odkrywanie treści, organizacje medialne mogą dodatkowo wykorzystywać Whisper do transkrypcji wywiadów, podcastów i materiałów wideo.
Duża dokładność OpenAI Whisper jest wynikiem ciągłego uczenia się i rozwoju. Zdolności transkrypcyjne Whisper są ulepszone dzięki zastosowanym modelom, które zmieniają się w miarę przetwarzania większej ilości danych i odbierania danych wejściowych.
To ciągłe doskonalenie gwarantuje, że interfejs API pozostaje w czołówce technologii rozpoznawania głosu, zapewniając konsumentom najlepsze wyniki.
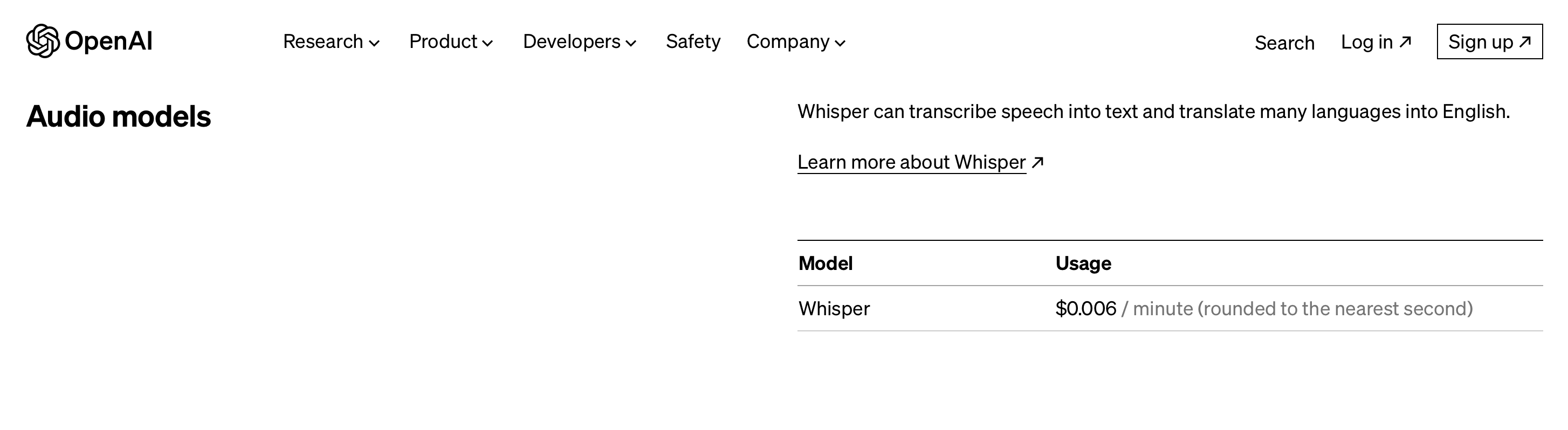
Cennik
Ceny premium tego modelu zaczynają się od 0.006 USD za minutę.
8. Mowa
Speechmatics jest liderem na rynku technologii rozpoznawania głosu, dostarczając silny i dokładny interfejs API zamiany mowy na tekst. Speechmatics przoduje w dokładnym przekształcaniu języka mówionego na tekst pisany, wykorzystując najnowocześniejsze algorytmy i metody głębokiego uczenia się.
Jest to przydatne narzędzie do różnych zastosowań, w tym napisów multimedialnych, contact center analityczne i indeksowanie treści dzięki dokładnym możliwościom transkrypcji.
Speechmatics może niezawodnie transkrybować informacje dźwiękowe z różnych źródeł językowych dzięki szerokiej obsłudze języków, która obejmuje regionalne dialekty i akcenty.
Bez względu na to, w jakim języku jest wypowiadany, będziesz w stanie dokładnie skopiować i zrozumieć mówiony tekst dzięki tej wielojęzyczności. Speechmatics zapewnia wiarygodne i precyzyjne wyniki, niezależnie od tego, czy chodzi o języki angielski, hiszpański, mandaryński czy inne.
Podstawowa technologia Speechmatics jest stale ulepszana i wyciągana z niej nauka, co pozwala dostosować ją do różnych wzorców mowy, akcentów i czynników otoczenia.
Zaangażowanie Speechmatics w ciągłe innowacje gwarantuje, że będzie nadal liderem w dziedzinie technologii rozpoznawania głosu i oferowania swoim klientom najbardziej precyzyjnej konwersji mowy na tekst.
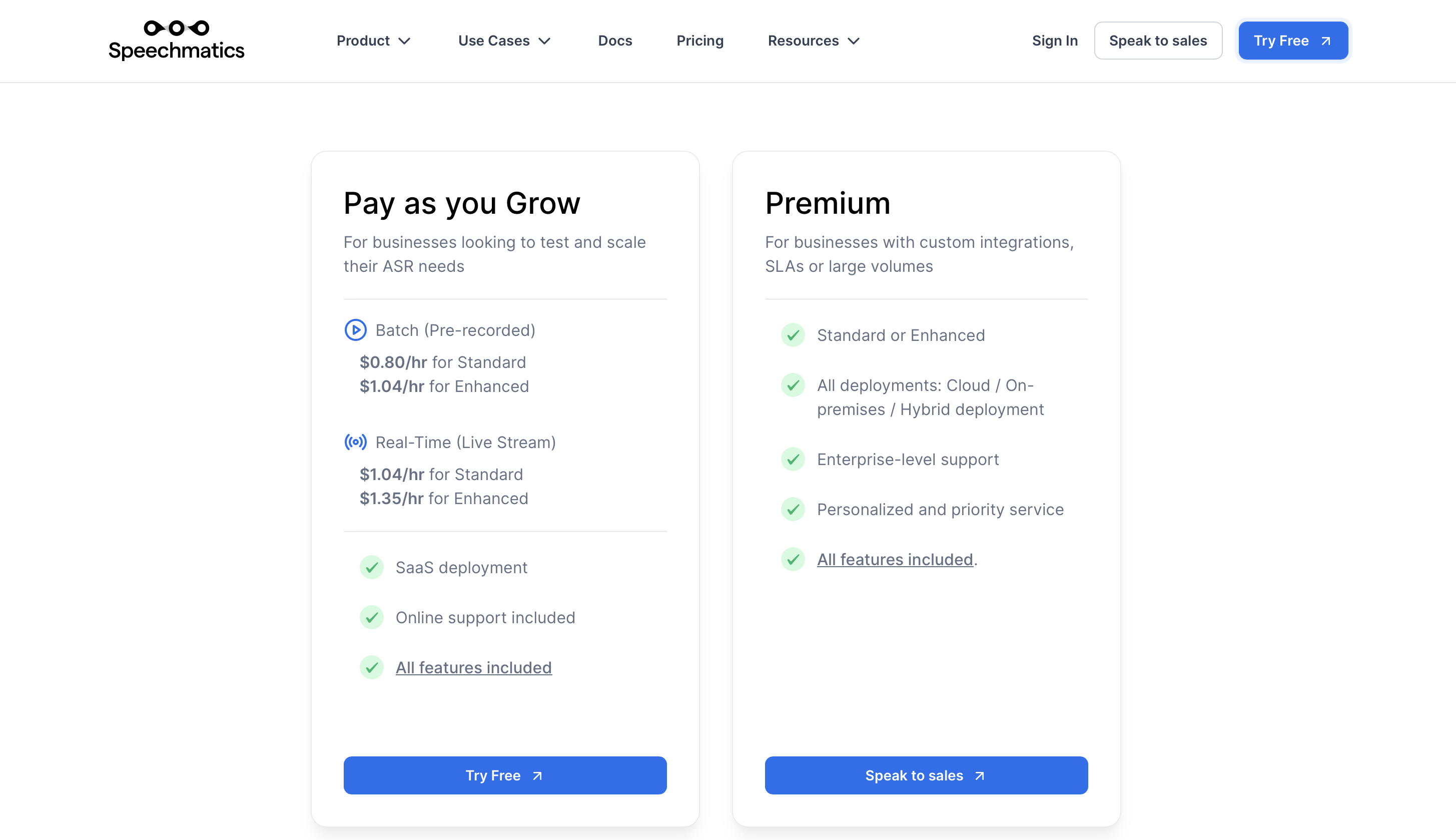
Cennik
Ceny premium zaczynają się od 0.80 USD/godz. (nagrane wcześniej) i 1.04 USD/godz. w czasie rzeczywistym (transmisja na żywo).
9. Deepgram
Deepgram, pionier w technologii rozpoznawania głosu i transkrypcji, zapewnia solidne podstawy do niezwykle precyzyjnej konwersji dźwięku na tekst modele uczenia głębokiego.
Modele głębokiego uczenia zbudowane na platformie mogą zrozumieć i złożyć szeroką gamę wzorców i odmian mowy, ponieważ zostały przeszkolone na ogromnych ilościach danych.
Duża dokładność i zdolność Deepgrama do wychwytywania subtelnych subtelności treści mówionych są wynikiem jego intensywnego szkolenia. Ze względu na wszechstronność platformy transkrypcje są dokładniejsze, ponieważ obsługuje ona różne akcenty, języki i terminy specyficzne dla branży.
Dzięki swoim modelom głębokiego uczenia się, które umożliwiają radzenie sobie z trudnymi sytuacjami słuchowymi i hałasem w tle, może generować dokładne wyniki nawet w warunkach mniej niż idealnych.
Ponadto na platformie rozpoznawania głosu i transkrypcji Deepgram dostępnych jest szereg możliwości technologicznych, które poprawiają komfort użytkowania.
Możesz otrzymywać natychmiastowe transkrypcje rozmów lub wydarzeń na żywo dzięki możliwościom przetwarzania w czasie rzeczywistym. Deepgram umożliwia również przetwarzanie wsadowe, co umożliwia wydajną transkrypcję dużych zestawów danych audio.
Cennik
Możesz zacząć używać go za darmo, a ceny premium zaczynają się od 4 XNUMX USD rocznie.
10. Siri
Siri zyskała na popularności jako jedna z najbardziej rozpoznawalnych i powszechnie używanych aplikacji do rozpoznawania mowy dostępnych obecnie. Ulubiony wirtualny asystent milionów właścicieli urządzeń Apple na całym świecie, Siri jest znany ze swojej przyjaznej dla użytkownika konstrukcji i interakcji aktywowanych głosem.
Siri to aktywowany głosem asystent, który może wykonywać różne operacje za pomocą jednego polecenia głosowego, w tym tworzyć przypomnienia, wysyłać wiadomości, wykonywać połączenia telefoniczne, a nawet odpowiadać na pytania dotyczące wiedzy ogólnej.
Bezproblemowa integracja Siri z produktami Apple, takimi jak iPhone'y, iPady, komputery Mac i HomePods, odróżnia Siri od innych asystentów cyfrowych.

Dzięki tej integracji możesz uzyskać dostęp do Siri za pomocą różnych urządzeń, co gwarantuje wygodę i spójność użytkowania. Siri jest dostępna przez cały czas, niezależnie od tego, czy pracujesz na komputerze Mac, czy na iPhonie, gdy jesteś w drodze.
Nie można zaprzeczyć przydatności i zdolności adaptacyjnych Siri w życiu codziennym. Używając tylko ich głosu, możesz używać Siri do zarządzania ich harmonogramami, wysyłania e-maili, przeglądania map i obsługi gadżetów inteligentnego domu. Możesz nadal być połączony i produktywny w podróży dzięki tej metodzie bez użycia rąk, która również oszczędza czas.
Dodatkowo Siri cały czas się rozwija i staje się coraz lepsza. Apple często zmienia możliwości Siri, zwiększając jej zdolność do interpretacji i przetwarzania języka naturalnego, poszerzając swoją bazę wiedzy i dodając nowe funkcje.
Utrzymując swoją pozycję lidera w technologii rozpoznawania mowy poprzez ciągły rozwój, Siri może nadal zapewniać płynne i dostosowane do potrzeb użytkownika.
Cennik
Jest darmowy dla każdego.
Wnioski
Podsumowując, oprogramowanie do rozpoznawania mowy oparte na sztucznej inteligencji całkowicie zmieniło sposób interakcji z technologią i stało się kluczowym narzędziem dla wielu różnych sektorów.
Różnorodność możliwości, od Microsoft Azure Speech Services i OpenAI Whisper po Google Cloud Speech-to-Text i Nuance Dragon Professional, pokazuje rozwój i możliwości adaptacyjne tych systemów.
Zachęcam czytelników do zbadania i dokładnej analizy ich indywidualnych potrzeb i wymagań przed wybraniem oprogramowania do rozpoznawania mowy opartego na sztucznej inteligencji, które najlepiej odpowiada ich celom, ponieważ każde oprogramowanie ma wiele specjalnych funkcji i możliwości.
Korzystając z tej potężnej technologii, możesz osiągnąć nowy poziom produktywności, wydajności i doświadczenia użytkownika w swoich osobistych i zawodowych przedsięwzięciach.





Robiłem porównania do pracy, jest kilka rzeczy, które możesz chcieć naprawić.
1. Siri nie jest porównywalna z innymi. Siri nie jest narzędziem programistycznym.
2. Ceny Rev, które udostępniłeś, dotyczą transkrypcji ludzkiej, podczas gdy inne są oparte wyłącznie na transkrypcji maszynowej. Jeśli spojrzysz na transkrypcję maszynową Rev, jej ceny są również konkurencyjne. https://www.rev.ai/pricing
3. Brakuje Ci Picovoice, który oferuje jedyny model na urządzeniu, który działa jako usługa. Zwykle rozwiązania na urządzeniu, takie jak Whisper, nie są dostarczane ze wsparciem technicznym, a dostosowanie jest bardzo trudne. Oferują świetne wsparcie, a personalizacja jest bardzo łatwa. https://picovoice.ai/platform/cat/