Web scraping stał się kluczową metodą uzyskiwania wnikliwych danych z platform internetowych w dzisiejszym społeczeństwie opartym na danych.
Jako niezwykle popularny serwis społecznościowy, Instagram udostępnia wiele materiałów tworzonych przez użytkowników. Te wygenerowane dane mogą być wykorzystywane do celów marketingowych, badawczych i innych.
Użytkownicy mogą łatwo i skutecznie wydobywać dane z Instagrama dzięki bogatym w funkcje skrobakom Instagram Bright Data, wiodącym skrobanie sieci narzędzie. W tym poście szczegółowo omówimy krok po kroku proces czyszczenia Instagrama.
Zobaczmy więc, jak możemy zeskrobać dane z Instagrama.
Zrozumienie skrobaków na Instagramie z Bright Data
Za pomocą dwóch uniwersalnych skrobaków internetowych i wstępnie skompilowanego zestawu danych Bright Data zapewnia różnorodne usługi skrobania Instagrama. Technologie te oferują wszechstronność w ekstrakcji danych i dostosowują się do różnych wymagań.
Przyjrzyjmy się każdemu z tych wyborów bardziej szczegółowo:
a. Skrobanie przeglądarki
Innowacyjna technologia znana jako Scraping Browser została stworzona, aby sprostać wymaganiom projektów scrapingu danych. Oferuje wszystko, co jest potrzebne do skrobania na dużą skalę w jednej przeglądarce. Wyróżnia się zintegrowaną automatyzacją odblokowywania stron internetowych, co czyni ją jedyną tego typu przeglądarką na całym świecie.
Scraping Browser zapewnia użytkownikom dostęp do solidnych funkcji, które wykraczają poza zautomatyzowane i bezobsługowe przeglądarki, pozwalając im wyjść poza nawet najtrudniejsze skrypty i bariery witryn w wykrywaniu botów.
Skrobanie danych jest bardziej efektywne i bezproblemowe dzięki funkcjom automatycznego dostosowywania, które z łatwością zarządzają świeżymi blokami, rozwiązaniami CAPTCHA, odciskami palców i ponownymi próbami, a także wyglądają jak prawdziwy użytkownik.
Wykorzystanie sztucznej inteligencji do przechytrzenia systemów wykrywania botów
Wykorzystując najnowocześniejszą technologię sztucznej inteligencji, Scraping Browser może przechytrzyć systemy wykrywania botów i stale dostosowywać się do ich strategii zmian. Aby lepiej odblokowywać strony internetowe, Scraping Browser uczy się na podstawie prób tych systemów wykrywania i blokowania prób scrapingu i odpowiednio modyfikuje swoje zachowanie.
Przewyższa wydajność konwencjonalnych serwerów proxy, naśladując zachowanie przeglądarki używanej przez prawdziwego użytkownika. W rezultacie klienci mogą skoncentrować się na swoich celach zbierania danych bez konieczności radzenia sobie z trudnościami i kosztami trwających procedur wykrywania botów.
b. IDE skrobaka sieciowego
Solidne narzędzie do skrobania stron internetowych stworzone dla programistów, Web Scraper IDE może obsługiwać złożone zadania zgarniania. Znacznie skraca czas programowania, zapewniając jednocześnie nieskończoną skalowalność dzięki całkowicie hostowanemu rozwiązaniu i wbudowanym funkcjom skrobania. Aplikacja umożliwia szybkie i skalowalne budowanie skrobaków internetowych poprzez dostarczanie szablonów kodu oraz gotowych funkcji JavaScript z popularnych serwisów.
Wszystko, co jest potrzebne do skutecznego skrobania sieci, zapewnia Web Scraper IDE. Jest to kompletne rozwiązanie do ekstrakcji danych online, ponieważ opcje integracji umożliwiają klientom planowanie indeksowania lub uruchamianie go za pośrednictwem interfejsu API i połączenia z głównymi systemami pamięci masowej.
Jak tego użyć? - Instruktaż
Najpierw przejdź do pulpitu użytkownika na stronie internetowej.

Zacznijmy od naszych kroków, aby zeskrobać Instagram.
1- Przejdź do Panel Użytkownika i kliknij sekcję Datasets & Web Scraper IDE.
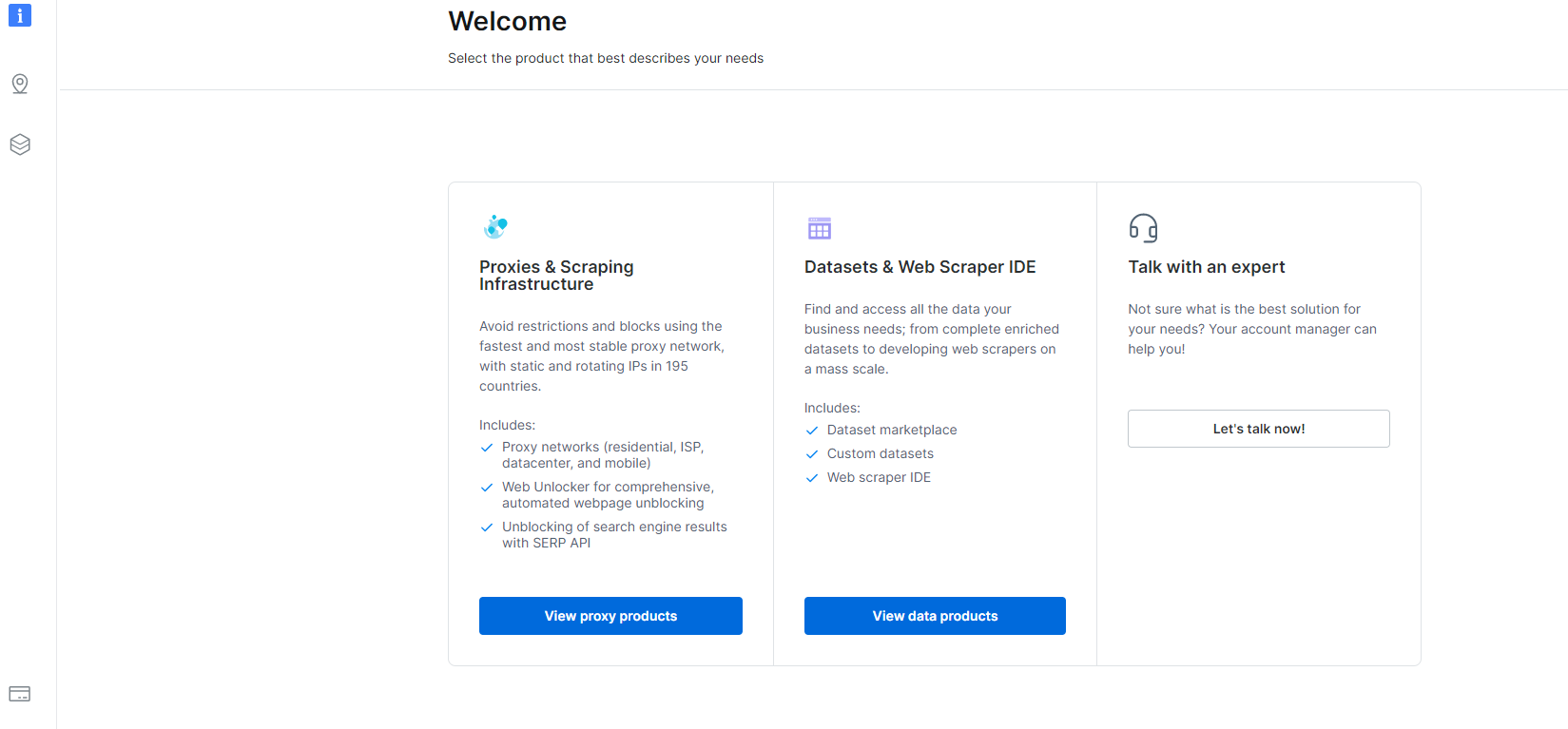
2- Gdy już tam będziesz, kliknij My Scrapers.
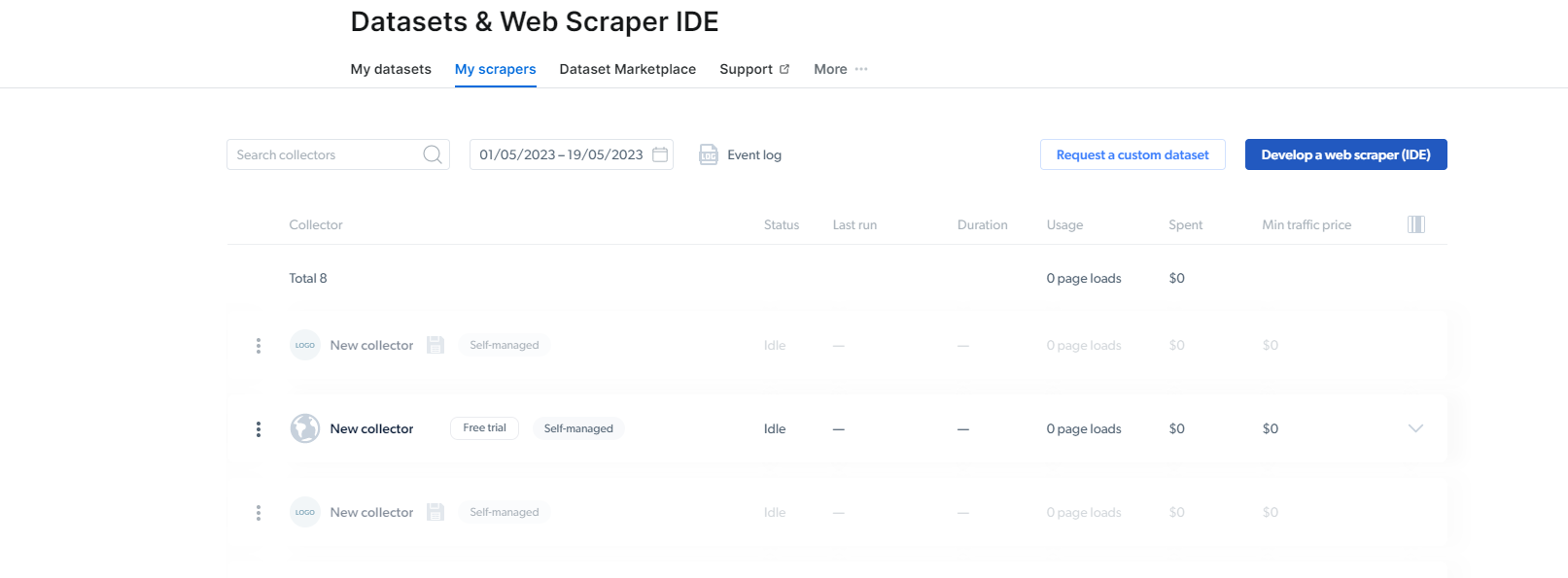
Tutaj musisz kliknąć „Opracuj skrobak internetowy (IDE)”. Tutaj stworzymy nasz scraper na Instagram.
3-Teraz musimy opracować nowy skrobak do sieci. Tylko w tym przykładzie zdecydowałem się zeskrobać konto „NASA”. To tylko na potrzeby tego przykładu.
Więc mój kod będzie wyglądał tak:
/ Click the 'play' button in the top right to run this code:
// 1. Go to the page where you want to start
navigate('https://www.instagram.com/nasa/');
// 2. Add anything else you need to do on the page.
// For example: (see the help box for all command docs).
// click('.some-button')
// type('.some-input', 'shoes')
// wait('.some-lazy-loaded-element')
// 3. Once the browser page has the data you want, call parse() to get the data
// and call collect() to add a record to your final dataset
let data = parse();
collect({
url: new URL(location.href),
title: "Nasa Account",
links: data.links,
});
Musisz kliknąć przycisk „play” w prawym górnym rogu, aby uruchomić ten kod.
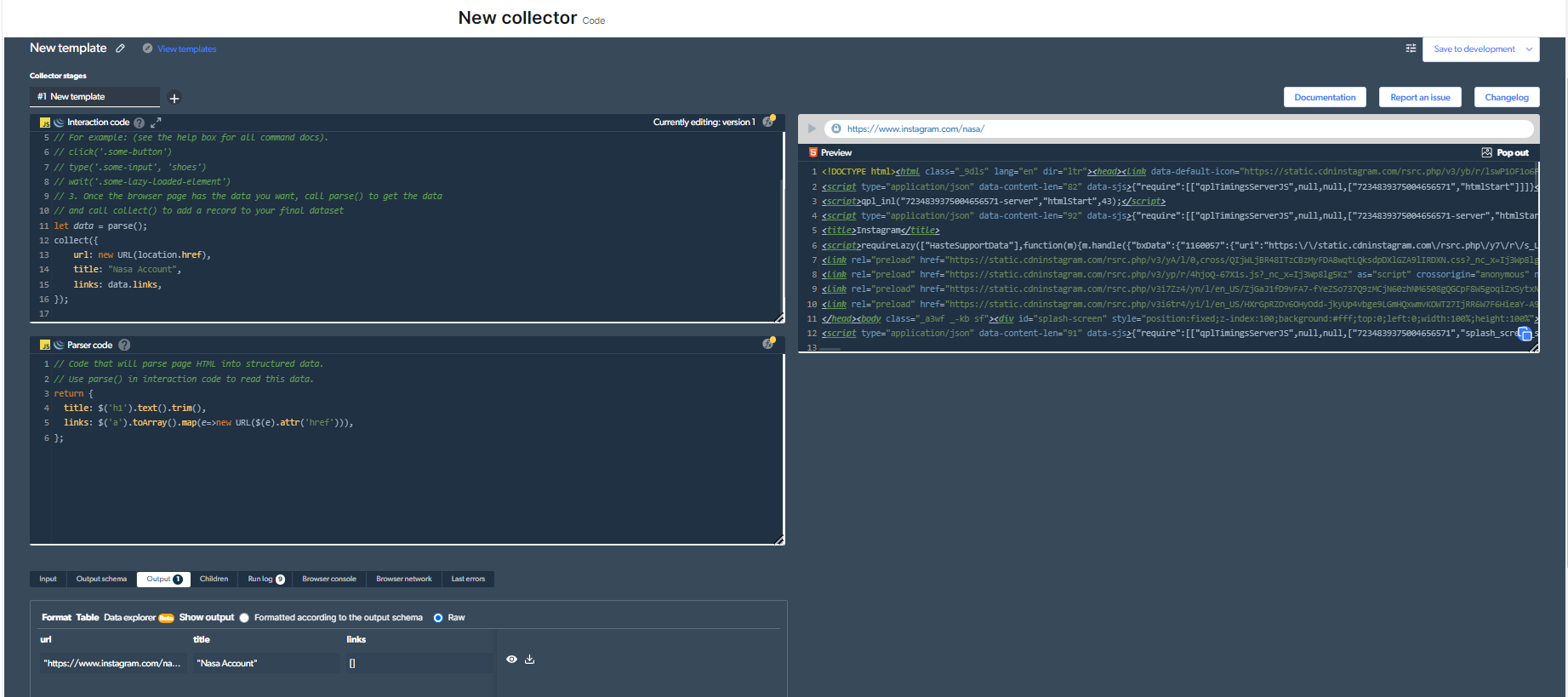
4- Teraz będziemy mieli dane wyjściowe.
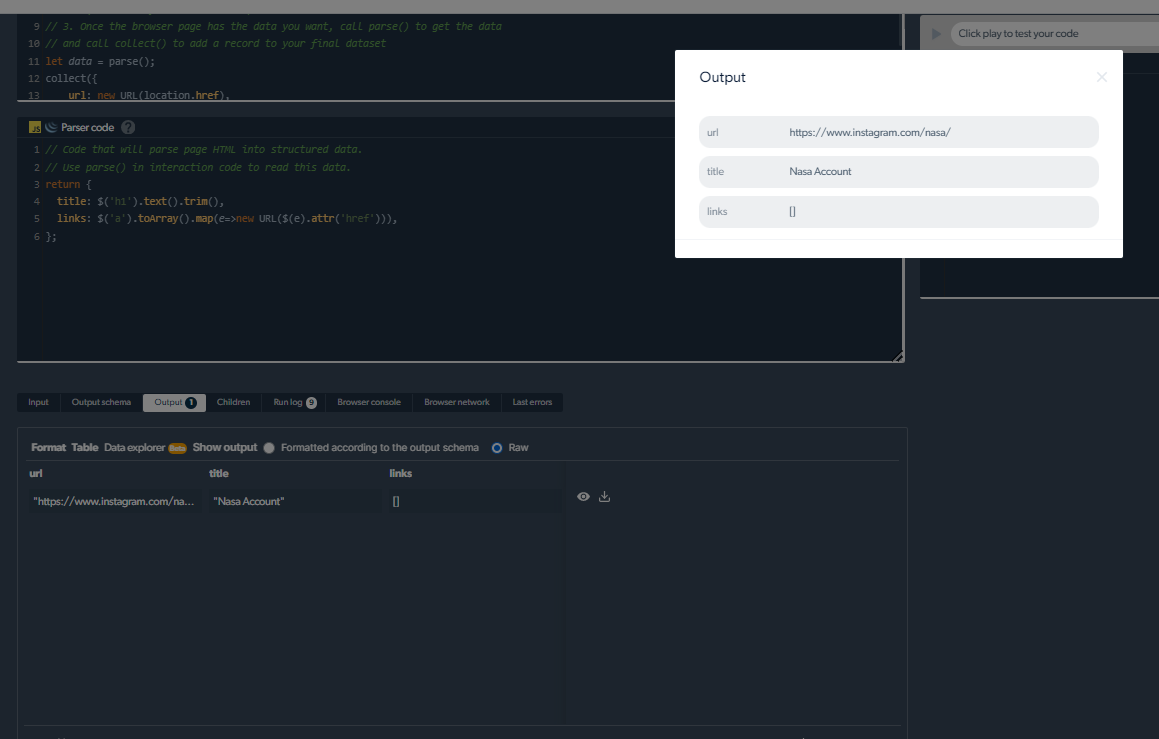
Zarządzanie problemami ze skrobaniem
Posty na Instagramie z przyciskiem „pokaż więcej” mogą być trudne do przechwycenia przez scraperów. Jednak skrobaki Instagram od Bright Data są stworzone do skutecznego radzenia sobie z taką złożonością. Te skrobaki mają najnowocześniejsze umiejętności przechodzenia przez paginację i ładowanie dodatkowych przycisków.
Skrobaki Bright Data na Instagramie skutecznie radzą sobie z tymi trudnościami, umożliwiając dokładną ekstrakcję danych, umożliwiając zebranie całego zbioru informacji wymaganych do analizy lub badania.
Możesz obejść wyzwania związane z dynamicznym charakterem postów na Instagramie, korzystając z tych narzędzi do skrobania.
c. Wstępnie zebrany zbiór danych
Bright Data rozumie, że nie każdy chce uruchomić swój skrobak. Dostarczają wstępnie zebrany zestaw danych dla Instagrama, aby przyciągnąć takich konsumentów.
Ten zestaw danych zawiera wiele przydatnych informacji, takich jak obserwujący, profile, posty i inne.
Bright Data oferuje opcje dostosowywania, aby spersonalizować zestaw danych do Twoich potrzeb, niezależnie od tego, czy chcesz cały zestaw danych, czy podzbiór wyspecjalizowanych danych. Takie podejście pozwala uniknąć konstruowania skrobaka i zarządzania nim, zapewniając gotowe do użycia dane do analizy i spostrzeżeń.
Teraz sprawdźmy infrastrukturę, która sprawia, że te narzędzia są tak skuteczne: infrastrukturę proxy i Web Unlocker.
Uwolnij moc pełnomocników
Korzystanie z proksies ma kluczowe znaczenie podczas przeglądania sieci, aby zagwarantować, że Twoje działania pozostaną niezauważone.
Bright Data zapewnia szeroki wybór usługi proxy które są dostosowane do Twoich wymagań. Możesz wybrać z Lokalni proxy, które oferują ponad 72 miliony adresów IP rotowanych z rzeczywistych urządzeń równorzędnych w 195 krajach.
Możesz wybrać ISP Proxy, które oferują ponad 700,000 770,000 prawdziwych domowych adresów IP na całym świecie do długoterminowego użytku; Serwery proxy centrów danych, które mają ponad 3 4 współdzielonych adresów IP z dowolnej geolokalizacji; oraz Mobile Proxy, które tworzą największą sieć mobilną 7,000,000G/XNUMXG typu peer-to-peer z ponad XNUMX XNUMX XNUMX adresów IP.
Za pomocą tych serwerów proxy można łatwo zbierać dane, podając się za autoryzowanego użytkownika w wielu miejscach.

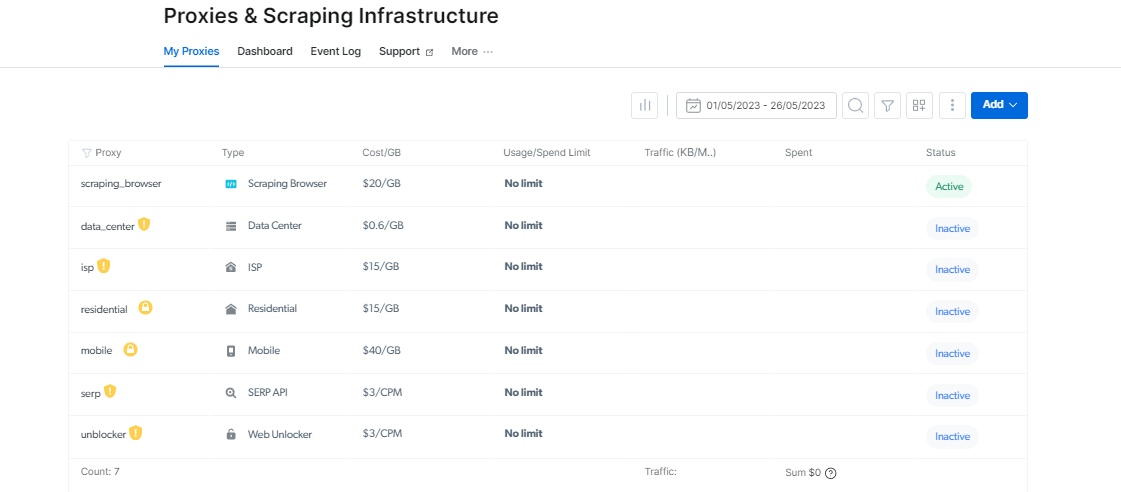
Proxy Manager: Ułatw zarządzanie proxy
Zarządzanie kilkoma serwerami proxy może być trudne, ale Proxy Manager ułatwia to zadanie.
Ten interfejs typu open source umożliwia zarządzanie wszystkimi serwerami proxy z poziomu jednej platformy. Pożegnaj się z ręcznym ustawianiem i przełączaniem serwerów proxy. Proxy Manager upraszcza procedurę i oszczędza czas i wysiłek.
Rozszerzenie przeglądarki proxy: łatwo zmieniaj swoją lokalizację
Czy potrzebujesz zbierać dane sieciowe z kilku regionów? Jesteś objęty naszym rozszerzeniem przeglądarki proxy. Możesz zmienić lokalizację przeglądania jednym kliknięciem, aby uzyskać informacje dotyczące regionu.
Skorzystaj z elastyczności i prostoty zbierania danych z kilku regionów bez żadnych komplikacji technologicznych.
Jak to działa? - Instruktaż
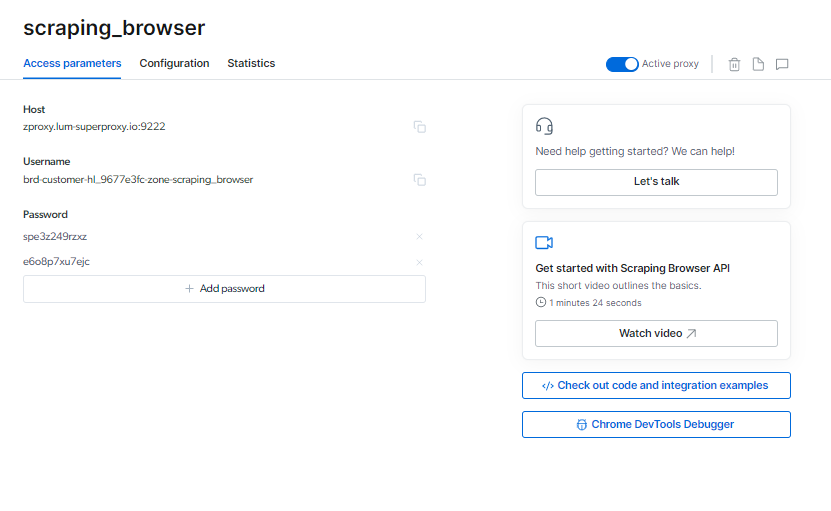
Możesz zlokalizować swój Skrobanie przeglądarki dane logowania na stronie Parametry dostępu, które będą wykorzystywane podczas rozpoczynania nowej sesji przeglądarki.
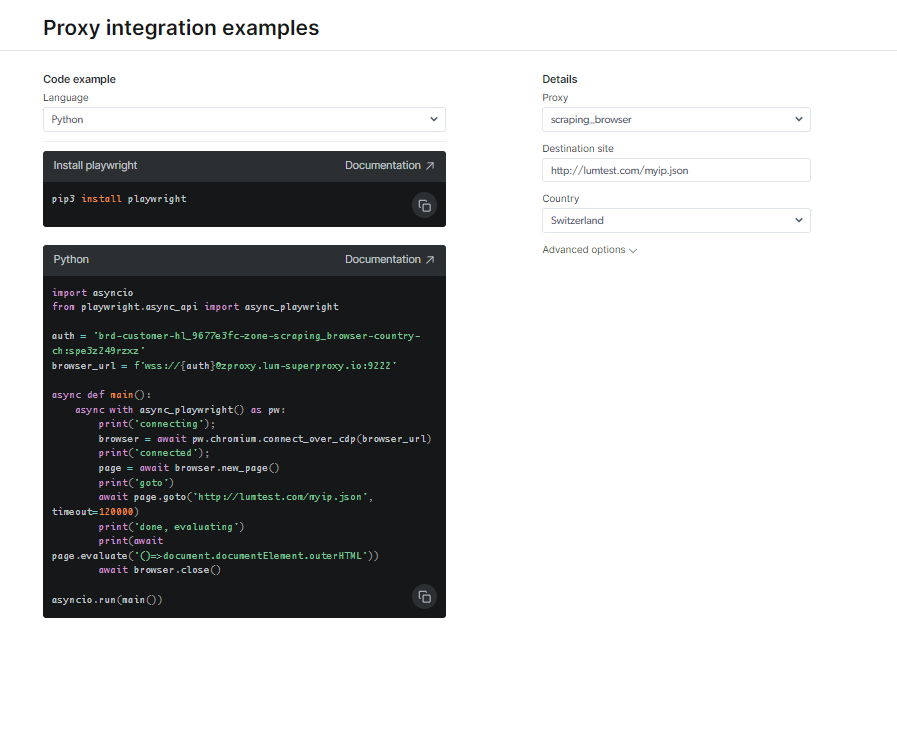
Zapoznaj się z dokumentacją i przykładami kodu, w tym w pełni funkcjonalnym przykładowym skryptem gotowym do użycia, lub obejrzyj krótki film instruktażowy. Na przykład; tutaj jest Kod Pythona przykład integracji:
Chcesz pomocy? Aby porozmawiać z jednym ze specjalistów, możesz kliknąć ikonę czatu.
Pamiętaj, że podczas korzystania z Scraping Browser masz pełną kontrolę nad sesjami przeglądarki i możesz wykonywać dowolne operacje obsługiwane przez Puppeteer, Playwright lub bezpośrednio przy użyciu protokołu Chrome DevTools.
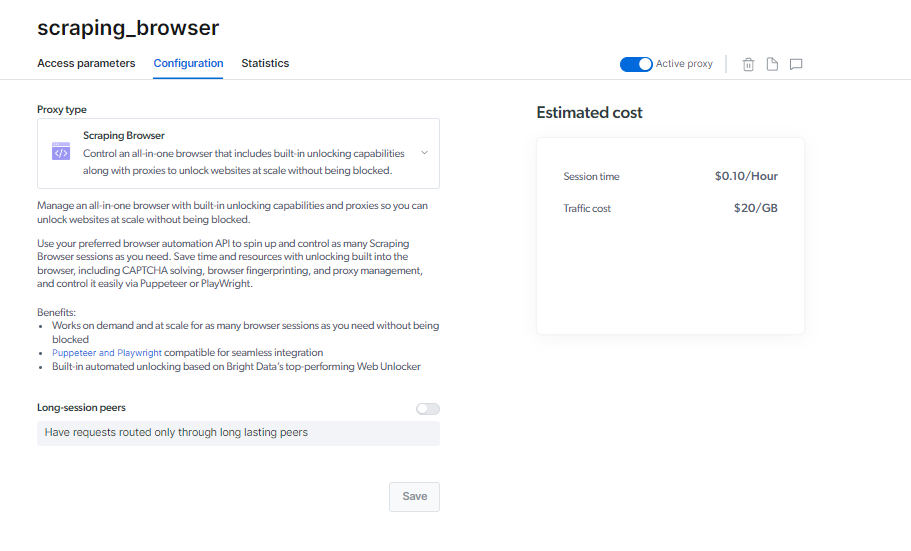
Odblokowywanie stron internetowych bez blokad
Scraping Browser działa na dużą skalę iw razie potrzeby. Nie musisz się martwić, że zostaniesz zbanowany; możesz uruchomić tyle sesji przeglądarki, ile potrzebujesz.
Ta pojemność, w połączeniu z mocą serwerów proxy, gwarantuje ciągłe gromadzenie danych, umożliwiając skuteczne uzyskiwanie pożądanych danych.
Wbudowane umiejętności odblokowywania przeglądarki Scraping Browser i solidna sieć proxy pomagają oszczędzać czas, zwiększać produktywność i odkrywać nowe możliwości.
Możesz także sprawdzić statystyki bezpośrednio z tej samej strony.
Ceny przeglądarki Scraping
Bright Data zapewnia konfigurowalne opcje cenowe, aby sprostać różnorodnym celom. Możesz wybrać miesięczny lub roczny okres rozliczeniowy.
Opcja Płać zgodnie z rzeczywistym użyciem pozwala płacić tylko za to, z czego korzystasz, bez żadnych zobowiązań, zaczynając od 20.00 USD/GB i 0.1 USD/godzinę.
Plan Growth o wartości 500 USD jest odpowiedni dla rozwijających się firm, z obniżoną opłatą w wysokości 15.30 USD/GB i 0.1 USD/godzinę.
Połączenia pakiet biznesowy, który kosztuje 1000 USD, jest najpopularniejszą opcją, a Scraping Browser API kosztuje 13.50 USD/GB i 0.1 USD/godzinę.
Kontaktując się bezpośrednio z zespołem Bright Data, użytkownicy korporacyjni mogą cieszyć się nieograniczonym skalowaniem i spersonalizowanymi cenami. Rozpocznij bezpłatną wersję próbną już dziś, aby odkryć potencjał przeglądarki Scraping Browser firmy Bright Data i zmienić swoje wysiłki w zakresie scrapingu online.
Odblokowywanie stron internetowych
Web Unlocker to potężne narzędzie stworzone, aby wyjść poza ograniczenia witryny i zapewnić łatwe zbieranie danych. Pokonuje kilka wyzwań, w tym pliki cookie, specyficzne dla witryny programy użytkownika przeglądarki i rozwiązania captcha, wykorzystując zautomatyzowane procedury.
Korzystając z automatycznej rotacji adresów IP, użytkownicy Web Unlocker mogą stale przeglądać docelowe strony internetowe, zapewniając stały dostęp do ważnych danych.
Ulepszanie ścieżek żądań programistów
Kilka funkcji sprawia, że Web Unlocker jest popularny wśród programistów. Program usprawnia proces gromadzenia danych, automatycznie identyfikując programy klienckie potrzebne dla każdej witryny, oszczędzając cenny czas i zasoby.
Web Unlocker dostosowuje się w czasie rzeczywistym, aby uniknąć wykrycia w odpowiedzi na stale zmieniające się strategie blokowania botów, zapewniając ciągły dostęp do interesujących stron internetowych. Algorytmy uczenia maszynowego platformy mogą szybko rozwiązać captcha, częstą przeszkodę w inicjatywach gromadzenia danych.

Ceny Web Unlockera
Począwszy od około 2.03 USD za tysiąc żądań (CPM), Web Unlocker oferuje wiele opcji cenowych, aby sprostać różnym wymaganiom. Dla użytkowników dostępna jest 7-dniowa bezpłatna wersja próbna, która pozwoli im rozpocząć i przetestować funkcje Web Unlocker przed podjęciem decyzji.
Web Unlocker ma możliwość adaptacji do obsługi różnych wzorców użytkowania, niezależnie od tego, czy konsumenci chcą płacić zgodnie z rzeczywistym użyciem, czy też potrzebują dostosowanego planu dostosowanego do ich konkretnych wymagań. Dodatkowo ci, którzy wybiorą długoterminowe plany cenowe, mogą zaoszczędzić 32%.
Porównanie narzędzia Web Unlocker z samozarządzającymi serwerami proxy
Web Unlocker oferuje wiele natychmiastowych korzyści w porównaniu z samodzielnie zarządzanymi serwerami proxy. Aby zapewnić płynną implementację, oferuje rozbudowaną technikę integracji, która łączy funkcje super proxy i Proxy Manager. Użytkownicy mogą skutecznie skalować swoje operacje gromadzenia danych dzięki nieskończonej liczbie jednoczesnych połączeń.
Web Unlocker zapewnia automatyczne odblokowywanie, rozwiązuje problemy CAPTCHA i skutecznie zarządza modyfikacjami znaczników na docelowych stronach internetowych.
Platforma gwarantuje ciągłą i niezawodną ekstrakcję danych poprzez wdrożenie systemu autoretry i wykonywanie asynchronicznych wywołań dla określonych domen. Dodatkowo, rosnąca kolekcja żądań nagłówków HTTP, plików cookie przeglądarki specyficznych dla witryny i symulowanych gadżetów, pozwala użytkownikom pozostać niewykrytymi, jednocześnie umożliwiając im pozyskiwanie danych online w czasie rzeczywistym.
Końcowe przemyślenia i ważne rzeczy do zapamiętania
Wreszcie, podczas korzystania z Bright Data do scrapingu na Instagramie, bardzo ważne jest, aby pamiętać o kilku istotnych kwestiach.
Należy pamiętać, że ich możliwości skrobania są ograniczone do publicznie dostępnych danych, zgodnie z praktykami etycznymi.
Zawsze należy przestrzegać warunków świadczenia usług i zasad prywatności Instagrama. Skrobanie powinno odbywać się etycznie i odpowiedzialnie, bez naruszania praw użytkowników lub łamania jakichkolwiek przepisów.
Po drugie, regularnie aktualizuj i dostrajaj parametry skrobania, aby zapewnić dokładność i trafność pobieranych danych. Platforma i algorytmy Instagrama mogą ulec zmianie, dlatego musisz odpowiednio zmienić swoje strategie skrobania.
Na koniec skorzystaj z pomocy i zasobów platformy Bright Data, aby zoptymalizować sukces swoich wysiłków związanych ze skrobaniem Instagrama. Zaangażuj się w ich dokumentację, samouczki i obsługę klienta, aby poszerzyć swoją wiedzę na temat ich narzędzi do skrobania.
Możesz uzyskać przydatne informacje, wpływać na podejmowanie mądrych decyzji i odnosić sukcesy w swoich inicjatywach opartych na danych na platformie Instagram, postępując zgodnie z tymi najlepszymi praktykami i wykorzystując siłę funkcji scrapingu Bright Data na Instagramie.





Dodaj komentarz