Spis treści[Ukryć][Pokazać]
Przyszłość jest tutaj. I w tej przyszłości maszyny pojmują otaczający je świat w taki sam sposób, jak ludzie. Komputery mogą prowadzić samochody, diagnozować choroby i dokładnie przewidywać przyszłość.
Może się to wydawać science fiction, ale modele głębokiego uczenia się sprawiają, że staje się to rzeczywistością.
Te wyrafinowane algorytmy ujawniają tajemnice sztuczna inteligencja, pozwalając komputerom na samouczenie się i rozwój. W tym poście zagłębimy się w sferę modeli głębokiego uczenia się.
I zbadamy ich ogromny potencjał do zrewolucjonizowania naszego życia. Przygotuj się, aby dowiedzieć się o najnowocześniejszej technologii, która zmienia przyszłość ludzkości.

Czym dokładnie są modele głębokiego uczenia się?
Czy kiedykolwiek grałeś w grę, w której musisz zidentyfikować różnice między dwoma obrazkami?
To zabawne, ale może być też trudne, prawda? Wyobraź sobie, że możesz nauczyć komputer grać w tę grę i wygrywać za każdym razem. Modele głębokiego uczenia się właśnie to umożliwiają!
Modele głębokiego uczenia są podobne do superinteligentnych maszyn, które mogą badać dużą liczbę obrazów i określać, co mają ze sobą wspólnego. Osiągają to, rozkładając obrazy i studiując każdy z nich z osobna.
Następnie stosują to, czego się nauczyli, do identyfikowania wzorców i przewidywania nowych obrazów, których nigdy wcześniej nie widzieli.

Modele głębokiego uczenia to sztuczne sieci neuronowe, które mogą uczyć się i wydobywać skomplikowane wzorce i cechy z ogromnych zbiorów danych. Modele te składają się z kilku warstw połączonych węzłów lub neuronów, które analizują i zmieniają przychodzące dane w celu wygenerowania danych wyjściowych.
Modele głębokiego uczenia się szczególnie dobrze nadają się do zadań wymagających dużej dokładności i precyzji, takich jak identyfikacja obrazu, rozpoznawanie mowy, przetwarzanie języka naturalnego i robotyka.
Były wykorzystywane we wszystkim, od samojezdnych samochodów po diagnostykę medyczną, systemy rekomendacyjne i analityka predykcyjna.
Oto uproszczona wersja wizualizacji ilustrująca przepływ danych w modelu uczenia głębokiego.
Dane wejściowe wpływają do warstwy wejściowej modelu, która następnie przekazuje dane przez szereg ukrytych warstw przed dostarczeniem prognozy wyjściowej.
Każda warstwa ukryta wykonuje serię operacji matematycznych na danych wejściowych przed przekazaniem ich do następnej warstwy, która zapewnia ostateczną prognozę.
Zobaczmy teraz, czym są modele głębokiego uczenia się i jak możemy je wykorzystać w naszym życiu.
1. Konwolucyjne sieci neuronowe (CNN)
CNN to model głębokiego uczenia się, który zmienił obszar wizji komputerowej. Sieci CNN służą do klasyfikowania obrazów, rozpoznawania obiektów i segmentowania obrazów. Struktura i funkcja ludzkiej kory wzrokowej wpłynęły na projekt CNN.
Jak to działa?
CNN składa się z wielu warstw splotowych, warstw łączących i warstw w pełni połączonych. Dane wejściowe to obraz, a dane wyjściowe to przewidywanie etykiety klasy obrazu.
Warstwy splotowe CNN budują mapę obiektów, wykonując iloczyn skalarny między obrazem wejściowym a zestawem filtrów. Warstwy puli zmniejszają rozmiar mapy obiektów poprzez jej próbkowanie w dół.
Wreszcie mapa obiektów jest używana przez w pełni połączone warstwy do przewidywania etykiety klasy obrazu.

Dlaczego CNN są ważne?
CNN są niezbędne, ponieważ mogą nauczyć się wykrywać wzorce i cechy na obrazach, które ludzie mają trudności z zauważeniem. Sieci CNN można nauczyć rozpoznawania cech, takich jak krawędzie, narożniki i tekstury przy użyciu dużych zbiorów danych. Po poznaniu tych właściwości CNN może ich użyć do identyfikacji obiektów na świeżych zdjęciach. Sieci CNN wykazały najnowocześniejszą wydajność w różnych aplikacjach do identyfikacji obrazu.
Gdzie używamy CNN
Opieka zdrowotna, przemysł samochodowy i handel detaliczny to tylko kilka sektorów, w których pracują CNN. W branży opieki zdrowotnej mogą być przydatne do diagnozowania chorób, opracowywania leków i analizy obrazów medycznych.
W sektorze samochodowym pomagają w wykrywaniu pasa ruchu, wykrywanie obiektówi autonomicznej jazdy. Są również szeroko stosowane w handlu detalicznym do wyszukiwania wizualnego, rekomendacji produktów opartych na obrazach i kontroli zapasów.
Na przykład; Google wykorzystuje CNN do różnych zastosowań, m.in Google Lens, lubiane narzędzie do identyfikacji obrazu. Program wykorzystuje CNN do oceny zdjęć i przekazywania użytkownikom informacji.
Na przykład Google Lens może rozpoznawać rzeczy na obrazie i podawać szczegółowe informacje na ich temat, takie jak rodzaj kwiatu.

Może również tłumaczyć tekst wyodrębniony z obrazu na wiele języków. Google Lens jest w stanie dostarczyć konsumentom przydatnych informacji dzięki pomocy CNN w dokładnej identyfikacji przedmiotów i wyodrębnieniu cech ze zdjęć.
2. Sieci pamięci długoterminowej (LSTM).
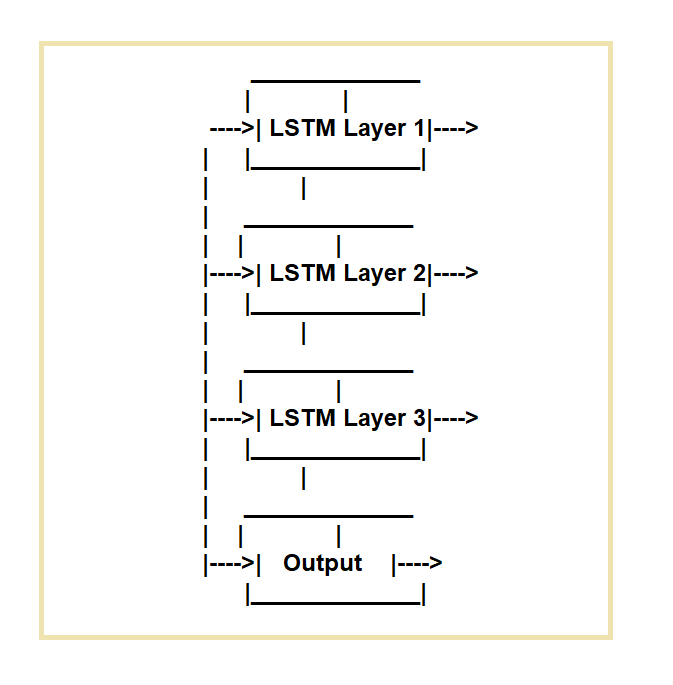
Sieci Long Short-Term Memory (LSTM) są tworzone w celu wyeliminowania niedociągnięć regularnych, powtarzających się sieci neuronowych (RNN). Sieci LSTM są idealne do zadań wymagających przetwarzania sekwencji danych w czasie.
Działają poprzez zastosowanie określonej komórki pamięci i trzech mechanizmów bramkowania.
Regulują przepływ informacji do i z komórki. Bramka wejściowa, bramka zapominania i bramka wyjściowa to trzy bramki.
Bramka wejściowa reguluje przepływ danych do komórki pamięci, bramka zapomina reguluje usuwanie danych z komórki, a bramka wyjściowa reguluje przepływ danych z komórki.
Jakie jest ich znaczenie?
Sieci LSTM są przydatne, ponieważ mogą z powodzeniem reprezentować i prognozować sekwencje danych z długoterminowymi relacjami. Mogą rejestrować i przechowywać informacje o poprzednich danych wejściowych, co pozwala im na dokładniejsze prognozy dotyczące przyszłych danych wejściowych.
Rozpoznawanie mowy, rozpoznawanie pisma ręcznego, przetwarzanie języka naturalnego i podpisy pod obrazami to tylko niektóre z aplikacji, które wykorzystywały sieci LSTM.
Gdzie używamy sieci LSTM?
Wiele aplikacji i aplikacji technologicznych wykorzystuje sieci LSTM, w tym systemy rozpoznawania mowy, narzędzia do przetwarzania języków naturalnych, takie jak Analiza nastrojów, systemy tłumaczenia maszynowego oraz systemy generujące tekst i obrazy.
Były również wykorzystywane do tworzenia samojezdnych samochodów i robotów, a także w branży finansowej do wykrywania oszustw i przewidywania Giełda Papierów Wartościowych ruchy.
3. Generatywne sieci kontradyktoryjne (GAN)
Sieci GAN są głęboka nauka technika używana do generowania nowych próbek danych, które są podobne do danego zestawu danych. Sieci GAN składają się z dwóch sieci neuronowe: taki, który uczy się tworzyć nowe próbki i taki, który uczy się odróżniać próbki oryginalne od wygenerowanych.
W podobnym podejściu te dwie sieci są trenowane razem, dopóki generator nie będzie w stanie wygenerować próbek, które są nie do odróżnienia od rzeczywistych.
Dlaczego używamy sieci GAN
Sieci GAN są istotne ze względu na ich zdolność do wytwarzania wysokiej jakości dane syntetyczne które mogą być wykorzystywane do różnych zastosowań, w tym do produkcji zdjęć i wideo, generowania tekstu, a nawet generowania muzyki.
Sieci GAN zostały również wykorzystane do augmentacji danych, czyli generowania dane syntetyczne w celu uzupełnienia rzeczywistych danych i poprawy wydajności modeli uczenia maszynowego.
Ponadto, tworząc syntetyczne dane, które można wykorzystać do trenowania modeli i naśladowania prób, sieci GAN mają potencjał do przekształcania sektorów, takich jak medycyna i opracowywanie leków.

Zastosowania sieci GAN
Sieci GAN mogą uzupełniać zbiory danych, tworzyć nowe obrazy lub filmy, a nawet generować dane syntetyczne do symulacji naukowych. Ponadto sieci GAN mają potencjał do wykorzystania w różnych zastosowaniach, od rozrywki po medycynę.
wiek i filmy. Nvidia StyleGAN2, na przykład, została wykorzystana do tworzenia wysokiej jakości zdjęć celebrytów i dzieł sztuki.
4. Sieci głębokich przekonań (DBN)
Sieci głębokich przekonań (DBN) są sztuczna inteligencja systemy, które potrafią nauczyć się dostrzegać wzorce w danych. Osiągają to, dzieląc dane na coraz mniejsze fragmenty, uzyskując dokładniejsze zrozumienie ich na każdym poziomie.
DBN mogą uczyć się na podstawie danych bez wiedzy, czym one są (nazywa się to „uczeniem bez nadzoru”). To czyni je niezwykle cennymi do wykrywania wzorców w danych, które dana osoba uznałaby za trudne lub niemożliwe do rozpoznania.
Co sprawia, że DBN są znaczące?
DBN są istotne ze względu na ich zdolność uczenia się hierarchicznych reprezentacji danych. Te reprezentacje mogą być wykorzystywane do różnych zastosowań, takich jak klasyfikacja, wykrywanie anomalii i redukcja wymiarowości.
Zdolność DBN do przeprowadzania wstępnego szkolenia bez nadzoru, co może zwiększyć wydajność modeli głębokiego uczenia się przy minimalnej ilości oznakowanych danych, jest znaczącą korzyścią.

Jakie są zastosowania DBN?
Jednym z najważniejszych zastosowań jest wykrywanie obiektów, w którym DBN są używane do rozpoznawania pewnych typów rzeczy, takich jak samoloty, ptaki i ludzie. Są również wykorzystywane do generowania i klasyfikacji obrazów, wykrywania ruchu w filmach oraz rozumienia języka naturalnego do przetwarzania głosu.
Ponadto DBN są powszechnie stosowane w zbiorach danych do oceny postawy człowieka. DBN są doskonałym narzędziem dla różnych branż, w tym opieki zdrowotnej i bankowości oraz technologii.
5. Głębokie sieci uczenia się ze wzmocnieniem (DRL)
Głęboki Uczenie się ze wzmocnieniem Sieci (DRL) integrują głębokie sieci neuronowe z technikami uczenia się przez wzmacnianie, aby umożliwić agentom uczenie się w skomplikowanym środowisku metodą prób i błędów.
DRL są używane do uczenia agentów, jak optymalizować sygnał nagrody poprzez interakcję z otoczeniem i uczenie się na własnych błędach.
Co czyni je wyjątkowymi?
Były skutecznie wykorzystywane w różnych zastosowaniach, w tym w grach, robotyce i autonomicznej jeździe. DRL są ważne, ponieważ mogą uczyć się bezpośrednio z surowych danych sensorycznych, umożliwiając agentom podejmowanie decyzji na podstawie ich interakcji ze środowiskiem.
Ważne aplikacje
DRL są stosowane w rzeczywistych warunkach, ponieważ radzą sobie z trudnymi problemami.
DRL zostały włączone do kilku znanych platform oprogramowania i technologii, w tym Gym OpenAI, Agenci ML Unityoraz Laboratorium DeepMind firmy Google. AlphaGo, stworzony przez Google DeepMind, na przykład, zatrudnia DRL do grania w grę planszową Go na poziomie mistrza świata.

Innym zastosowaniem DRL jest robotyka, gdzie służy do kontrolowania ruchów ramion robotów w celu wykonywania zadań, takich jak chwytanie przedmiotów lub układanie bloków. DRL mają wiele zastosowań i są przydatnym narzędziem agentów szkoleniowych do nauki i podejmować decyzje w skomplikowanych sytuacjach.
6. Autoenkodery
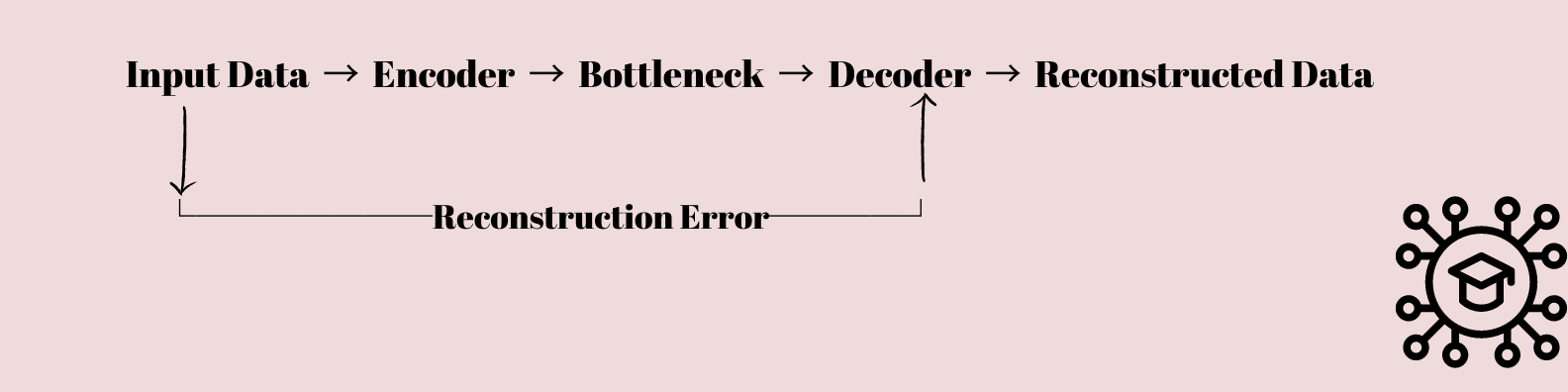
Autoenkodery są interesującym rodzajem sieci neuronowe który wzbudził zainteresowanie zarówno naukowców, jak i naukowców zajmujących się danymi. Są zasadniczo zaprojektowane, aby nauczyć się kompresować i przywracać dane.
Dane wejściowe są przekazywane przez kolejne warstwy, które stopniowo zmniejszają wymiarowość danych, aż zostaną skompresowane do warstwy wąskiego gardła z mniejszą liczbą węzłów niż warstwy wejściowe i wyjściowe.
Ta skompresowana reprezentacja jest następnie używana do odtworzenia oryginalnych danych wejściowych przy użyciu sekwencji warstw, które stopniowo przywracają wymiarowość danych do pierwotnego kształtu.
Dlaczego to jest ważne?
Autoenkodery są kluczowym elementem głęboka nauka ponieważ umożliwiają ekstrakcję cech i redukcję danych.
Są w stanie zidentyfikować kluczowe elementy przychodzących danych i przetłumaczyć je na skompresowaną postać, którą można następnie zastosować do innych zadań, takich jak klasyfikacja, grupowanie lub tworzenie nowych danych.
Gdzie używamy autoenkoderów?
Wykrywanie anomalii, przetwarzanie języka naturalnego i wizja komputerowa to tylko kilka dyscyplin, w których używane są autoenkodery. Na przykład autoenkodery mogą być używane do kompresji obrazu, odszumiania obrazu i syntezy obrazu w wizji komputerowej.
Możemy używać Autoencoderów w zadaniach takich jak tworzenie tekstu, kategoryzacja tekstu i streszczanie tekstu w przetwarzaniu języka naturalnego. Może identyfikować anomalną aktywność w danych, która odbiega od normy w identyfikacji anomalii.
7. Sieci kapsułowe
Capsule Networks to nowa architektura głębokiego uczenia się, która została opracowana jako zamiennik konwolucyjnych sieci neuronowych (CNN).
Sieci kapsułowe opierają się na koncepcji grupowania jednostek mózgowych zwanych kapsułami, które są odpowiedzialne za rozpoznawanie istnienia określonego elementu na obrazie i kodowanie jego atrybutów, takich jak orientacja i pozycja, w ich wektorach wyjściowych. Sieci kapsułowe mogą zatem lepiej zarządzać interakcjami przestrzennymi i fluktuacjami perspektywy niż CNN.
Dlaczego wybieramy sieci kapsułowe zamiast CNN?
Sieci kapsułowe są przydatne, ponieważ pokonują trudności CNN w uchwyceniu hierarchicznych relacji między elementami na obrazie. CNN mogą rozpoznawać rzeczy o różnych rozmiarach, ale mają trudności ze zrozumieniem, w jaki sposób te elementy łączą się ze sobą.
Z drugiej strony sieci kapsułowe mogą nauczyć się rozpoznawać rzeczy i ich elementy, a także sposób ich przestrzennego rozmieszczenia na obrazie, co czyni je realnymi pretendentami do komputerowych aplikacji wizyjnych.
Obszary zastosowań
Sieci kapsułowe wykazały już obiecujące wyniki w różnych zastosowaniach, w tym w klasyfikacji obrazów, identyfikacji obiektów i segmentacji obrazów.
Były używane do rozróżniania rzeczy na zdjęciach medycznych, rozpoznawania ludzi na filmach, a nawet tworzenia modeli 3D z obrazów 2D.
Aby zwiększyć ich wydajność, sieci kapsułowe zostały połączone z innymi architekturami głębokiego uczenia, takimi jak generatywne sieci przeciwstawne (GAN) i wariacyjne autoenkodery (VAE). Przewiduje się, że sieci kapsułowe będą odgrywać coraz ważniejszą rolę w ulepszaniu technologii widzenia komputerowego w miarę rozwoju nauki głębokiego uczenia się.
Na przykład; Nibabel jest dobrze znanym narzędziem Pythona do odczytywania i zapisywania typów plików neuroobrazowania. Do segmentacji obrazu wykorzystuje sieci kapsułowe.
8. Modele oparte na uwadze
Modele głębokiego uczenia się, znane jako modele oparte na uwadze, znane również jako mechanizmy uwagi, dążą do zwiększenia dokładności modele uczenia maszynowego. Modele te działają poprzez koncentrację na pewnych cechach przychodzących danych, co skutkuje bardziej wydajnym i efektywnym przetwarzaniem.
W zadaniach związanych z przetwarzaniem języka naturalnego, takich jak tłumaczenie maszynowe i analiza nastrojów, metody uwagi okazały się całkiem skuteczne.
Jakie jest ich znaczenie?
Modele oparte na uwadze są przydatne, ponieważ umożliwiają bardziej efektywne i wydajne przetwarzanie skomplikowanych danych.
Tradycyjne sieci neuronowe oceniać wszystkie dane wejściowe jako równie ważne, co skutkuje wolniejszym przetwarzaniem i mniejszą dokładnością. Procesy uwagi koncentrują się na kluczowych aspektach danych wejściowych, pozwalając na szybsze i dokładniejsze przewidywania.

Obszary użytkowania
W dziedzinie sztucznej inteligencji mechanizmy uwagi mają szeroki zakres zastosowań, w tym przetwarzanie języka naturalnego, rozpoznawanie obrazu i dźwięku, a nawet pojazdy bez kierowcy.
Na przykład metody uwagi można wykorzystać do ulepszenia tłumaczenia maszynowego w przetwarzaniu języka naturalnego, umożliwiając systemowi skupienie się na określonych słowach lub frazach, które są istotne w kontekście.
Metody uwagi w samochodach autonomicznych można zastosować, aby pomóc systemowi skupić się na określonych przedmiotach lub wyzwaniach w jego otoczeniu.
9. Sieci transformatorowe
Sieci transformatorów to modele głębokiego uczenia, które badają i tworzą sekwencje danych. Działają poprzez przetwarzanie sekwencji wejściowej po jednym elemencie na raz i wytwarzanie sekwencji wyjściowej o tej samej lub różnej długości.
Sieci transformatorowe, w przeciwieństwie do standardowych modeli sekwencji do sekwencji, nie przetwarzają sekwencji przy użyciu rekurencyjnych sieci neuronowych (RNN). Zamiast tego wykorzystują procesy samouwagi, aby poznać powiązania między elementami sekwencji.
Jakie jest znaczenie sieci transformatorowych?
Sieci transformatorowe zyskały na popularności w ostatnich latach w wyniku ich lepszej wydajności w zadaniach związanych z przetwarzaniem języka naturalnego.
Szczególnie dobrze nadają się do zadań związanych z tworzeniem tekstu, takich jak tłumaczenie językowe, streszczanie tekstu i tworzenie konwersacji.
Sieci transformatorowe są znacznie wydajniejsze obliczeniowo niż modele oparte na RNN, co czyni je preferowanym wyborem w zastosowaniach na dużą skalę.

Gdzie można znaleźć sieci transformatorów?
Sieci transformatorowe są szeroko stosowane w szerokim zakresie zastosowań, w szczególności w przetwarzaniu języka naturalnego.
Seria GPT (Generative Pre-trained Transformer) to wybitny model oparty na transformatorze, który został wykorzystany do zadań takich jak tłumaczenie językowe, streszczanie tekstu i generowanie chatbotów.
BERT (Dwukierunkowe reprezentacje koderów z transformatorów) to kolejny popularny model oparty na transformatorach, który został wykorzystany w aplikacjach rozumienia języka naturalnego, takich jak odpowiadanie na pytania i analiza nastrojów.
Obie GPT i BERT powstały z PyTorch, platformę głębokiego uczenia typu open source, która jest popularna przy opracowywaniu modeli opartych na transformatorach.
10. Ograniczone maszyny Boltzmanna (KMS)
Restricted Boltzmann Machines (RBM) to rodzaj nienadzorowanej sieci neuronowej, która uczy się w sposób generatywny. Ze względu na ich zdolność do uczenia się i wydobywania podstawowych cech z danych wielowymiarowych, są szeroko stosowane w dziedzinie uczenia maszynowego i uczenia głębokiego.
RBM składają się z dwóch warstw, widocznej i ukrytej, przy czym każda warstwa składa się z grupy neuronów połączonych ważonymi krawędziami. RBM są zaprojektowane tak, aby uczyć się rozkładu prawdopodobieństwa opisującego dane wejściowe.
Czym są ograniczone maszyny Boltzmanna?
RBM wykorzystują generatywną strategię uczenia się. W RBM widoczna warstwa odzwierciedla dane wejściowe, podczas gdy warstwa ukryta koduje charakterystykę danych wejściowych. Wagi widocznych i ukrytych warstw pokazują siłę ich powiązania.
RBM dostosowują wagi i odchylenia między warstwami podczas treningu za pomocą techniki znanej jako dywergencja kontrastowa. Kontrastywna dywergencja to strategia uczenia się bez nadzoru, która maksymalizuje prawdopodobieństwo przewidywania modelu.
Jakie jest znaczenie ograniczonych maszyn Boltzmanna?
RBM są znaczące w uczenie maszynowe i głębokiego uczenia się, ponieważ mogą uczyć się i wydobywać istotne cechy z dużych ilości danych.
Są bardzo skuteczne w rozpoznawaniu obrazu i mowy i były wykorzystywane w różnych zastosowaniach, takich jak systemy rekomendujące, wykrywanie anomalii i redukcja wymiarowości. RBM mogą znaleźć wzorce w ogromnych zbiorach danych, co skutkuje lepszymi przewidywaniami i spostrzeżeniami.

Gdzie można używać zastrzeżonych maszyn Boltzmanna?
Zastosowania RBM obejmują redukcję wymiarowości, wykrywanie anomalii i systemy rekomendacji. RBM są szczególnie przydatne do analizy nastrojów i modelowanie tematyczne w kontekście przetwarzania języka naturalnego.
Sieci głębokiego przekonania, rodzaj sieci neuronowej używanej do rozpoznawania głosu i obrazu, również wykorzystują RBM. Zestaw narzędzi Deep Belief Network, TensorFlow, Theano to niektóre konkretne przykłady oprogramowania lub technologii korzystającej z mechanizmów RBM.
Zamotać
Modele głębokiego uczenia się stają się coraz bardziej istotne w różnych branżach, w tym w rozpoznawaniu mowy, przetwarzaniu języka naturalnego i wizji komputerowej.
Konwolucyjne sieci neuronowe (CNN) i rekurencyjne sieci neuronowe (RNN) okazały się najbardziej obiecujące i są szeroko wykorzystywane w wielu zastosowaniach, jednak wszystkie modele głębokiego uczenia się mają swoje zalety i wady.
Jednak naukowcy wciąż przyglądają się Restricted Boltzmann Machines (RBM) i innym odmianom modeli Deep Learning, ponieważ one również mają szczególne zalety.
Przewiduje się, że wraz z postępem głębokiego uczenia się w celu radzenia sobie z trudniejszymi problemami powstaną nowe i kreatywne modele





Dodaj komentarz