Nettskraping har blitt en avgjørende metode for å skaffe innsiktsfulle data fra internettplattformer i dagens datadrevne samfunn.
Som et ekstremt populært sosialt medieside tilbyr Instagram mye brukergenerert materiale. Og disse genererte dataene kan brukes til markedsføring, forskning og andre årsaker.
Brukere kan trekke ut data fra Instagram med letthet og effektivitet takket være Bright Datas funksjonsrike Instagram-skrapere, en ledende nettskraping verktøy. I dette innlegget vil vi gi en grundig, steg-for-steg gjennomgang av Instagram-skrapeprosessen.
Så la oss se fremgangsmåten for hvordan vi kan skrape data fra Instagram.
Forstå Instagram-skrapere fra Bright Data
Ved hjelp av to nettskrapere for alle formål og et forhåndskompilert datasett, tilbyr Bright Data en rekke Instagram-skrapetjenester. Disse teknologiene tilbyr allsidighet i datautvinning og tilpasser seg ulike krav.
La oss undersøke hvert av disse valgene mer detaljert:
a. Scraping Browser
Den innovative teknologien kjent som Scraping Browser ble laget for å oppfylle kravene til dataskrapingsprosjekter. Den tilbyr alt som kreves for å skrape i stor skala inne i en enkelt nettleser. Den skiller seg ut takket være den integrerte automatiseringen av blokkering av nettsteder, som gjør den til den eneste nettleseren i sitt slag i hele verden.
Scraping Browser gir brukere tilgang til robuste funksjoner som går utover automatiserte og hodeløse nettlesere, og lar dem komme utover selv de vanskeligste skriptene og nettstedbarrierene for bot-deteksjon.
Dataskraping er mer effektiv og problemfri på grunn av dens automatiserte justeringsfunksjoner, som enkelt administrerer nye blokker, CAPTCHA-løsninger, fingeravtrykk og gjenforsøk, og fremstår som en ekte bruker.
Bruker AI for å overliste bot-deteksjonssystemer
Ved å bruke banebrytende AI-teknologi kan Scraping Browser overliste bot-deteksjonssystemer og kontinuerlig tilpasse seg deres skiftende strategier. For å låse opp nettsider bedre, lærer Scraping Browser av disse systemenes forsøk på å oppdage og blokkere skrapingsforsøk og endrer oppførselen på riktig måte.
Den overgår effektiviteten til konvensjonelle proxyer ved å imitere oppførselen til en nettleser som brukes av en ekte bruker. Som et resultat kan kunder konsentrere seg om målene sine for dataskraping uten å måtte håndtere vanskelighetene og kostnadene ved pågående bot-deteksjonsprosedyrer.
b. Web Scraper IDE
Web Scraper IDE er et robust verktøy for nettskraping laget for utviklere, og kan håndtere komplekse skrapeoppgaver. Den reduserer utviklingstiden betraktelig samtidig som den gir uendelig skalerbarhet takket være den fullstendig vertsbaserte løsningen og forhåndsbygde skrapefunksjoner. Applikasjonen muliggjør rask og skalerbar bygging av nettskrapere ved å tilby kodemaler og ferdiglagde JavaScript-funksjoner fra populære nettsteder.
Alt som kreves for vellykket nettskraping leveres av Web Scraper IDE. Det er en komplett løsning for online datautvinning siden integreringsalternativer gjør det mulig for kunder å planlegge gjennomganger eller starte dem gjennom API og koble til hovedlagringssystemer.
Hvordan bruke det? - Opplæringen
Naviger først til brukerdashbordet på nettstedet.

La oss starte med trinnene våre for å skrape Instagram.
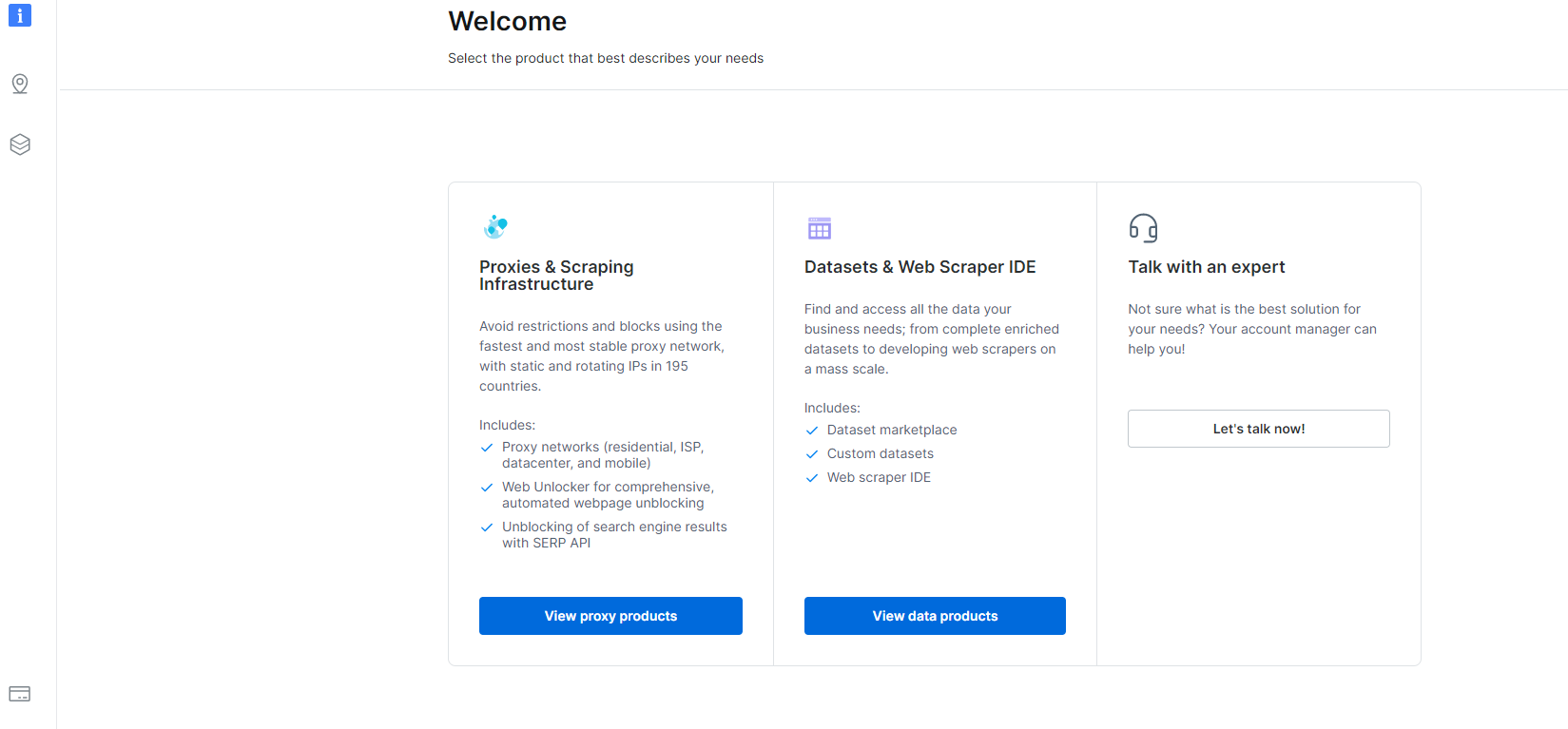
1- Naviger til Dashbord og klikk på Datasett & Web Scraper IDE-delen.
2- Når du er der, klikker du på Mine skrapere.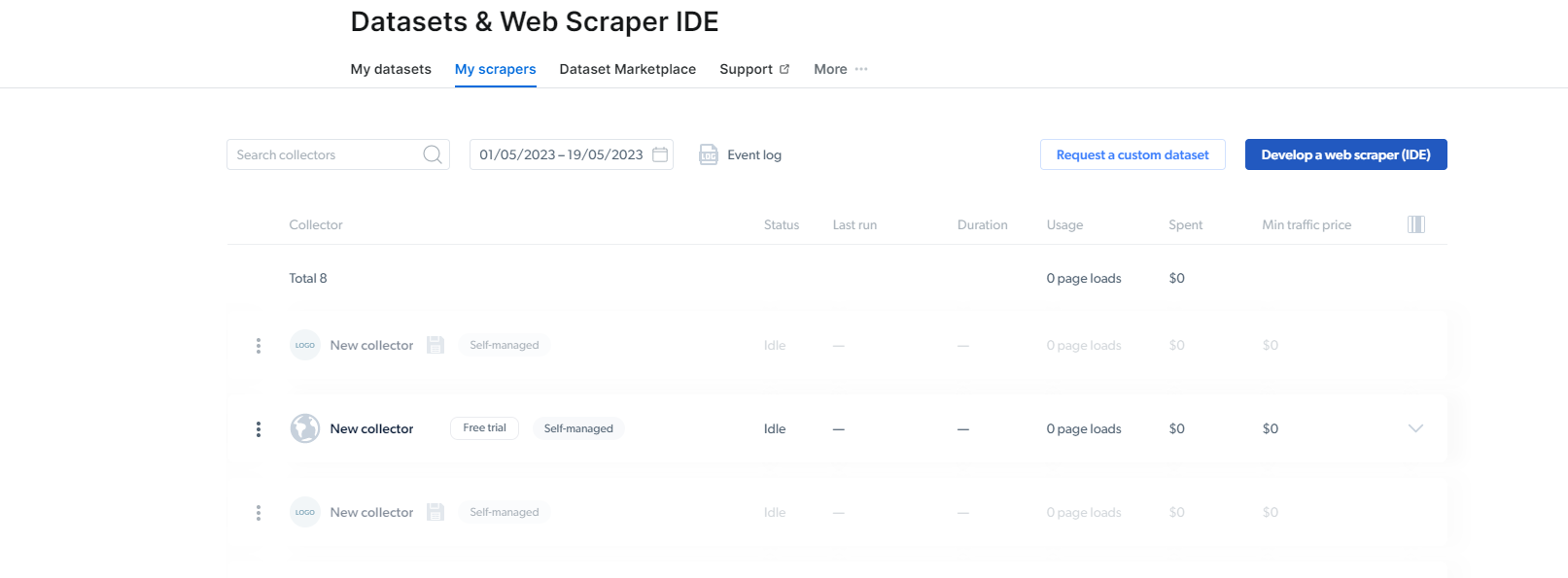
Her må du klikke på "Utvikle en webskraper (IDE)". Her skal vi lage vår skrape for Instagram.
3-Nå må vi utvikle en ny nettskraper. Bare for dette eksemplet velger jeg å skrape "NASA"-kontoen. Dette er bare for dette eksemplets skyld.
Så koden min vil se slik ut:
/ Click the 'play' button in the top right to run this code:
// 1. Go to the page where you want to start
navigate('https://www.instagram.com/nasa/');
// 2. Add anything else you need to do on the page.
// For example: (see the help box for all command docs).
// click('.some-button')
// type('.some-input', 'shoes')
// wait('.some-lazy-loaded-element')
// 3. Once the browser page has the data you want, call parse() to get the data
// and call collect() to add a record to your final dataset
let data = parse();
collect({
url: new URL(location.href),
title: "Nasa Account",
links: data.links,
});
Du må klikke på "spill"-knappen øverst til høyre for å kjøre denne koden.
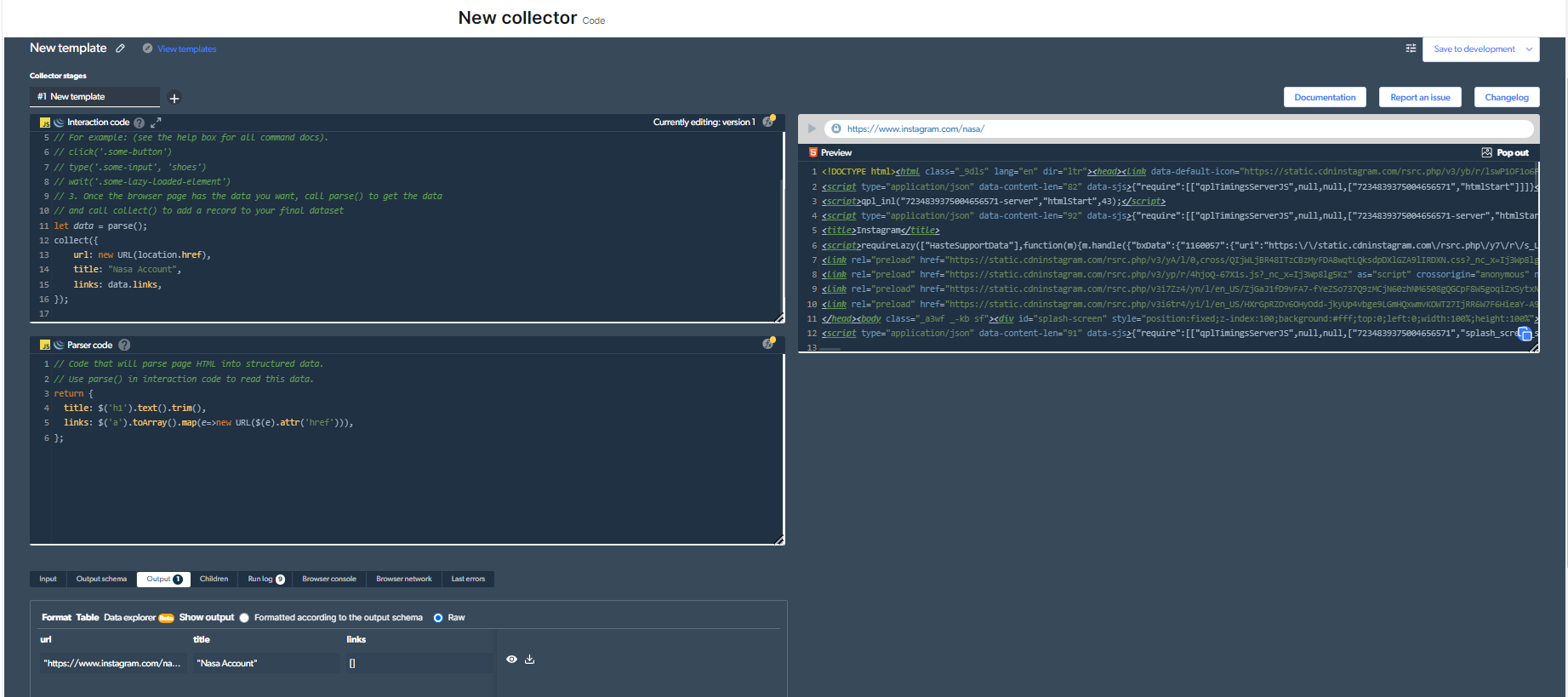
4- Nå vil vi ha en utgang.
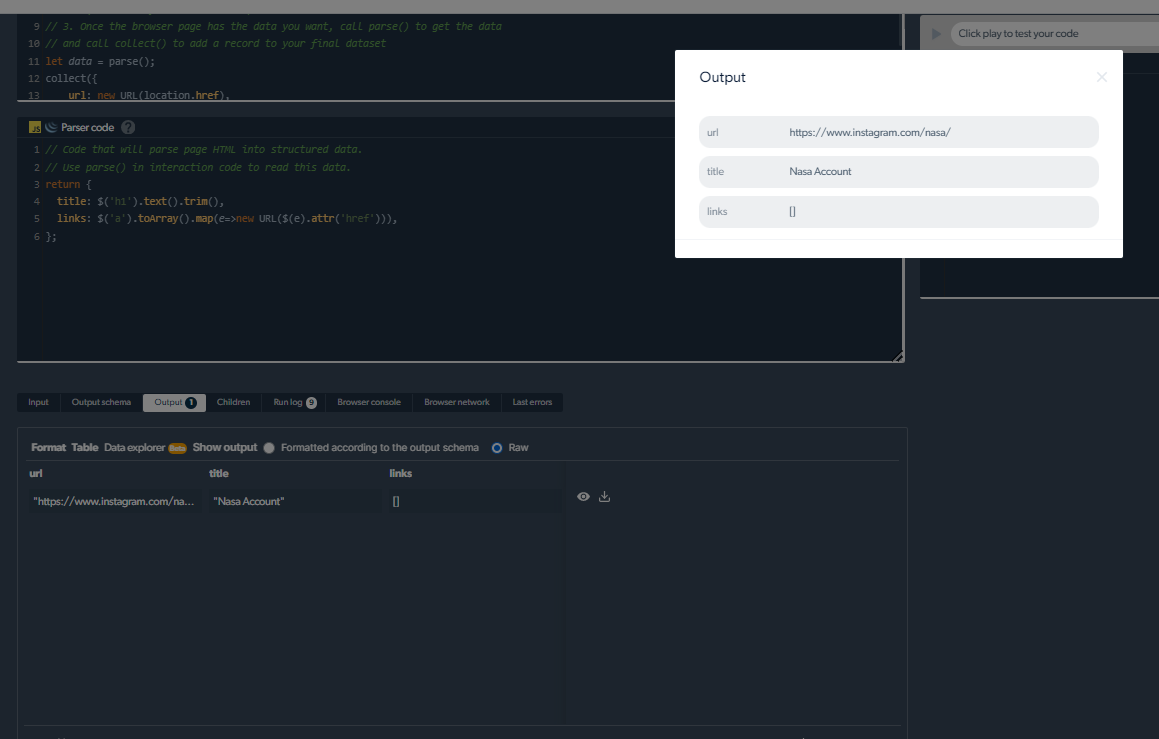
Håndtering av skrapeproblemer
Instagram-innlegg med «vis mer-knappen» kan være vanskelig for skrapere å fange. Imidlertid er Instagram-skrapere fra Bright Data laget for å håndtere slik kompleksitet på en vellykket måte. Disse skrapene har banebrytende ferdigheter til å gå gjennom paginering og lasting av ekstra knapper.
Bright Datas Instagram-skrapere håndterer disse vanskelighetene effektivt for å muliggjøre grundig datautvinning, slik at du kan samle inn hele samlingen av informasjon som kreves for analysen eller studien din.
Du kan omgå utfordringene fra Instagram-innleggs dynamiske natur ved å bruke disse skrapeverktøyene.
c. Forhåndsinnsamlet datasett
Bright Data forstår at ikke alle ønsker å kjøre skrapen sin. De leverer et forhåndsinnsamlet datasett for Instagram for å appellere til slike forbrukere.
Dette datasettet tilbyr et vell av nyttig informasjon, for eksempel følgere, profiler, innlegg og mer.
Bright Data tilbyr tilpasningsmuligheter for å tilpasse datasettet til dine behov, enten du vil ha et helt datasett eller et undersett av spesialiserte data. Denne tilnærmingen unngår å konstruere og administrere en skraper, og gir deg klar til bruk data for analyse og innsikt.
La oss nå sjekke infrastrukturen som gjør disse verktøyene så effektive: proxy-infrastrukturen og Web Unlocker.
Slipp løs kraften til proxyer
Ved hjelp av fullmakter er avgjørende under nettskraping for å garantere at handlingene dine går ubemerket hen.
Bright Data gir et bredt utvalg av proxy-tjenester som er tilpasset dine behov. Du kan velge fra Boligfullmektiger, som tilbyr mer enn 72 millioner IP-er som er rotert fra reelle peer-enheter i 195 nasjoner.
Du kan velge ISP Proxies, som tilbyr 700,000 770,000+ ekte hjemme-IP-er over hele verden for langvarig bruk; Datasenter-proxyer, som har 3 4+ delte IP-er fra alle geolokasjoner; og Mobile Proxies, som danner det største real-peer 7,000,000G/XNUMXG-mobilnettverket med XNUMX XNUMX XNUMX+ IP-er.
Med bruk av disse proxyene kan man enkelt samle inn data mens man utgir seg for å være en autorisert bruker på mange steder.

Proxy Manager: Gjør proxy-administrasjon enklere
Det kan være vanskelig å administrere flere proxyer, men Proxy Manager gjør det enkelt.
Dette åpen kildekode-grensesnittet lar deg administrere alle proxyene dine fra én enkelt plattform. Si farvel til å angi og bytte proxyer manuelt. Proxy Manager forenkler prosedyren og sparer deg for tid og krefter.
Proxy-nettleserutvidelse: Endre posisjonen din enkelt
Trenger du å samle nettdata fra flere regioner? Du er dekket av vår proxy-nettleserutvidelse. Du kan endre nettleserposisjonen din med et enkelt klikk for å få regionspesifikk informasjon.
Dra nytte av fleksibiliteten og enkelheten ved å samle inn data fra flere regioner uten noen teknologiske komplikasjoner.
Hvordan virker det? - Opplæringen
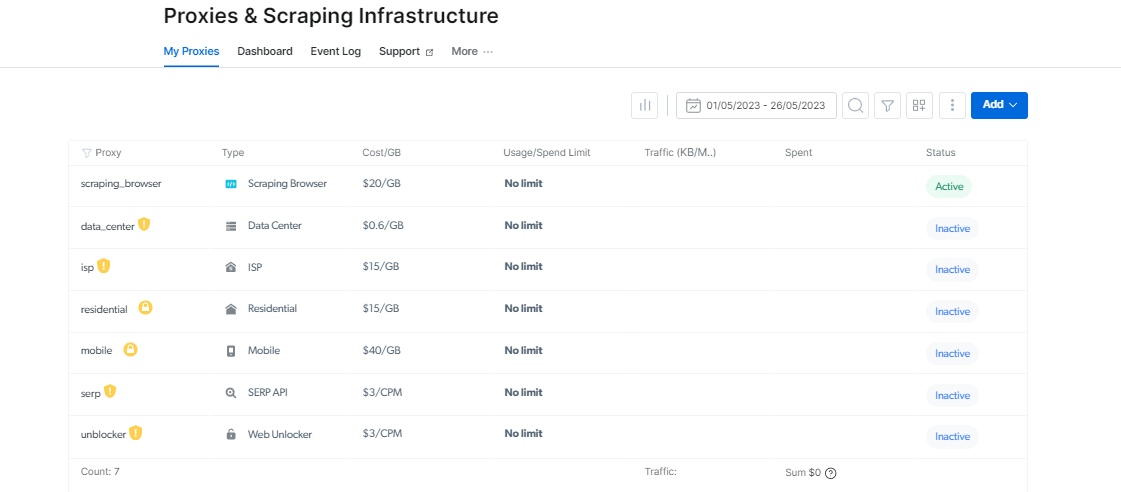
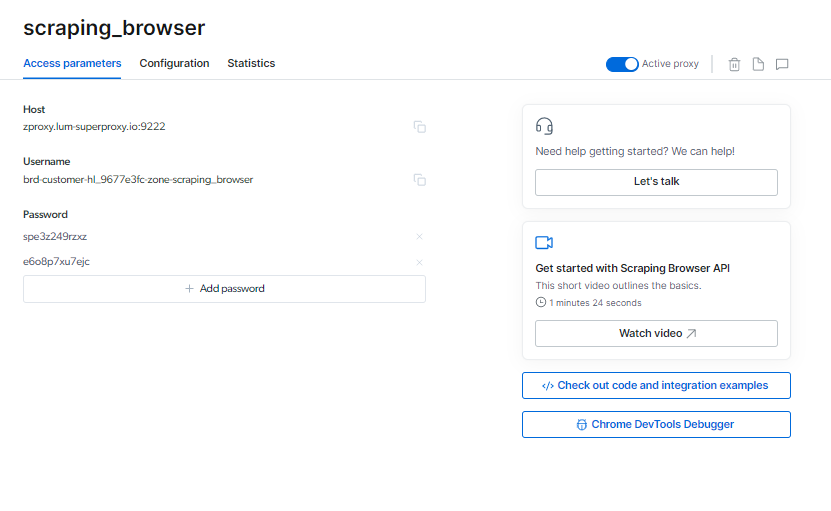
Du kan finne din Scraping Browser påloggingsinformasjon på siden Tilgangsparametere, som vil bli brukt når du starter en ny nettleserøkt.
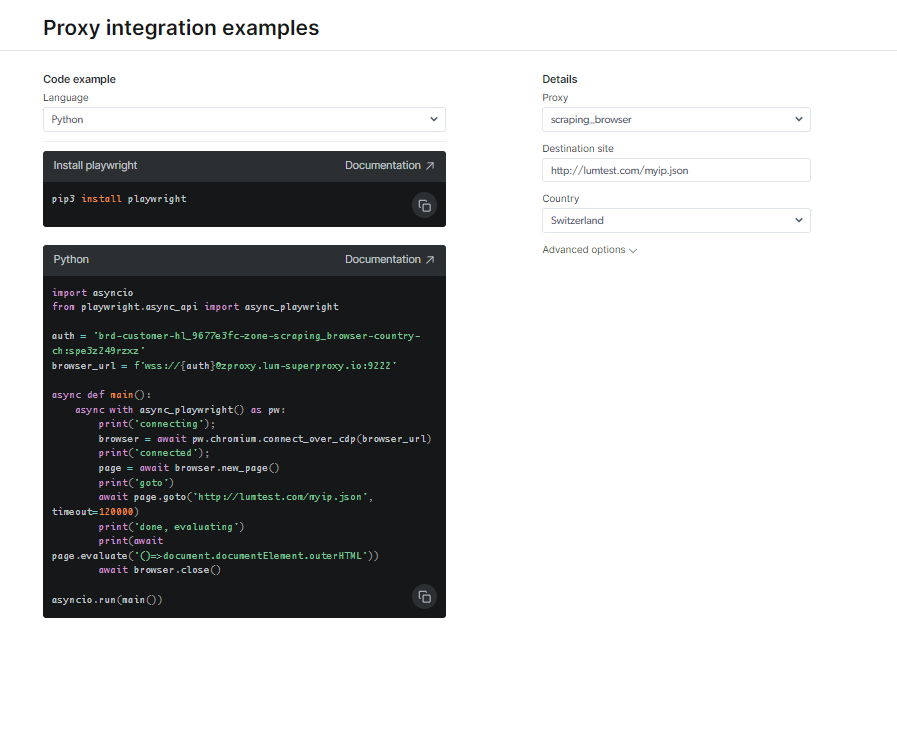
Sjekk ut dokumentasjon og kodeeksempler, inkludert et fullt funksjonelt eksempelskript som er klart til bruk, eller se en kort startinstruksjonsvideo. For eksempel; her er en Python-kode eksempel for integrasjon:
Ønsker du hjelp? For en samtale med en av spesialistene kan du klikke på chat-ikonet.
Husk at du har full kontroll over nettleserøktene mens du bruker Scraping Browser og kan utføre alle operasjoner som støttes av Puppeteer, Playwright eller direkte bruk av Chrome DevTools Protocol.
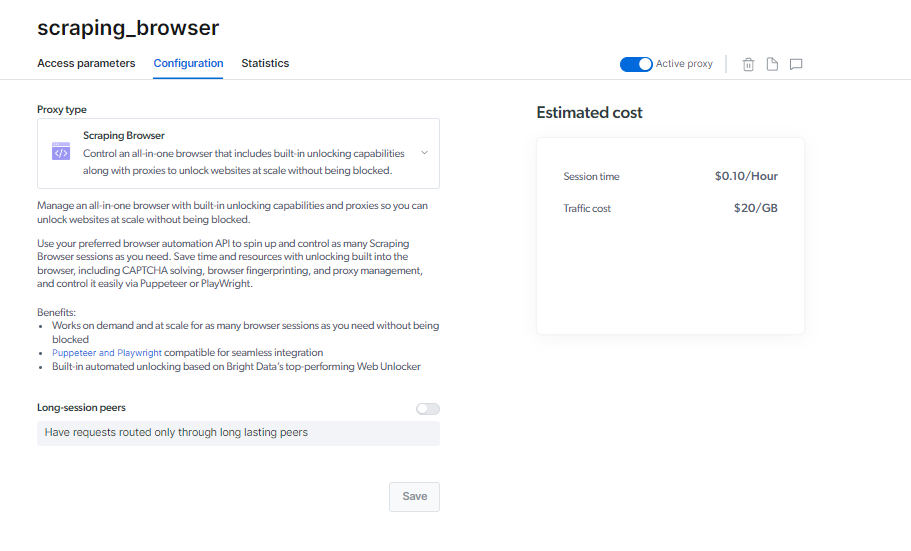
Opplåsing av nettsted uten blokkeringer
Scraping Browser er laget for å fungere i stor skala og etter behov. Du trenger ikke bekymre deg for å bli utestengt; du kan starte opp så mange nettleserøkter du trenger.
Denne kapasiteten, sammenkoblet med styrken til proxyer, garanterer kontinuerlig datainnsamling, slik at du effektivt kan få tak i dataene du ønsker.
Scraping Browsers innebygde opplåsingsferdigheter og robuste proxy-nettverk hjelper deg med å spare tid, forbedre produktiviteten og oppdage nye muligheter.
Du kan også sjekke statistikken fra samme side direkte.
Prissetting av Scraping Browser
Bright Data gir tilpassbare prisvalg for å møte en rekke formål. Du kan velge enten en månedlig eller årlig faktureringsperiode.
Pay as You Go-alternativet lar deg betale bare for det du bruker, uten forpliktelse nødvendig, fra $20.00/GB og $0.1/time.
Vekstplanen på $500 er egnet for bedrifter i vekst, med et rabattert gebyr på $15.30/GB og $0.1/time.
De Bedriftspakke, som koster $1000, er det mest populære alternativet, med Scraping Browser API som koster $13.50/GB og $0.1/time.
Ved å kontakte Bright Data-teamet direkte, kan bedriftsbrukere nyte uendelig skalering og tilpassede priser. Start en gratis prøveversjon i dag for å oppdage potensialet til Bright Datas Scraping Browser og endre din online skraping.
Opplåsing av nettsted
Web Unlocker er et kraftig verktøy laget for å komme utover nettstedsbegrensninger og gi enkel datainnsamling. Den overvinner flere utfordringer, inkludert informasjonskapsler, nettstedspesifikke nettleserbrukeragenter og captcha-løsninger, ved å bruke automatiserte prosedyrer.
Ved å bruke automatisk rotasjon av IP-adresser kan brukere av Web Unlocker kontinuerlig skrape målnettsteder, og sikre konstant tilgang til viktige data.
Forbedring av utviklerforespørselsreiser
Flere funksjoner gjør Web Unlocker populær blant utviklere. Programmet effektiviserer datainnsamlingsprosessen ved automatisk å identifisere brukeragentene som trengs for hvert nettsted, og sparer verdifull tid og ressurser.
Web Unlocker tilpasser seg i sanntid for å unngå oppdagelse som svar på de stadig skiftende strategiene som brukes av blokkering av roboter, og sikrer kontinuerlig tilgang til nettstedene av interesse. Plattformens maskinlæringsalgoritmer kan raskt løse captchaer, en hyppig hindring for datainnsamlingsinitiativer.

Prissetting av Web Unlocker
Med start på rundt $2.03 per tusen forespørsler (CPM), tilbyr Web Unlocker flere prisalternativer for å møte ulike krav. En 7-dagers gratis prøveversjon er tilgjengelig for brukere for å komme i gang og la dem teste ut funksjonene til Web Unlocker før de forplikter seg.
Web Unlocker har tilpasningsevnen til å støtte ulike bruksmønstre, uavhengig av om forbrukere ønsker en betal-som-du-gå-tilnærming eller trenger en tilpasset plan tilpasset deres spesielle behov. I tillegg kan de som velger langsiktige prisplaner spare 32 %.
Sammenligning mellom Web Unlocker med selvadministrerte proxyer
Web Unlocker tilbyr en rekke umiddelbare fordeler i forhold til selvadministrerte proxyer. For jevn implementering tilbyr den en omfattende integrasjonsteknikk som kombinerer super proxy og Proxy Manager-funksjoner. Brukere kan effektivt skalere opp sine datainnsamlingsoperasjoner med et uendelig antall samtidige tilkoblinger.
Web Unlocker leverer automatisk oppheving av blokkering, løser CAPTCHA-er og administrerer markeringsendringer på målnettsteder.
Plattformen garanterer kontinuerlig og pålitelig datautvinning ved å implementere et auto-forsøkssystem og foreta asynkrone anrop for visse domener. I tillegg lar online Unlockers økende samling av HTTP-headerforespørsler, nettstedsspesifikke nettleserinformasjonskapsler og simulerte gadgets brukere forbli uoppdaget samtidig som de lar dem skaffe online data i sanntid.
Siste tanker og viktige ting å huske
Til slutt, mens du bruker Bright Data for Instagram-skraping, er det viktig å huske på noen få viktige punkter.
Vær oppmerksom på at deres skrapingsmuligheter er begrenset til offentlig tilgjengelige data, av etisk praksis.
Du bør alltid følge Instagrams vilkår for bruk og personvernregler. Skraping bør gjøres etisk og ansvarlig, uten å trenge inn i brukernes rettigheter eller bryte noen lover.
For det andre, oppdater og finjuster skrapeparametrene dine regelmessig for å sikre nøyaktigheten og relevansen til de hentede dataene. Instagrams plattform og algoritmer kan endres, derfor må du endre skrapestrategiene dine tilsvarende.
Til slutt, bruk Bright Datas plattforms hjelp og ressurser for å optimalisere suksessen til Instagram-skrapingen din. Engasjer deg med dokumentasjonen, veiledningene og kundeservicen deres for å forbedre kunnskapen din om skrapeverktøyene deres.
Du kan få nyttig innsikt, påvirke kloke beslutninger og lykkes med dine datadrevne initiativer på Instagram-plattformen ved å følge disse beste fremgangsmåtene og utnytte styrken til Bright Datas Instagram-skrapefunksjoner.





Legg igjen en kommentar