Saturs[Paslēpt][Rādīt]
Nav nekas jauns, ka ir viltoti fotoattēli un videoklipi. Kopš interneta plašās izmantošanas cilvēki ir radījuši viltojumus, kuru mērķis ir apmānīt vai uzjautrināt, kopš ir bijuši attēli un filmas.
Tomēr ir jauna veida ar mašīnām ražoti viltojumi, kuru dēļ kādreiz varētu būt grūti atšķirt realitāti no daiļliteratūras.
Šie viltojumi atšķiras no vienkāršajām attēlu manipulācijām, ko rada rediģēšanas programmatūra, piemēram, Photoshop, vai gudri manipulētām pagātnes filmām.
Dziļās viltojumi ir vispazīstamākais “sintētisko datu nesēju” piemērs — attēli, skaņas un videoklipi, kas, šķiet, ir radīti, izmantojot parastās metodes, bet patiešām tika izveidoti, izmantojot sarežģītu programmatūru.
Deepfakes pastāv jau kādu laiku, un, lai gan to populārākais pielietojums līdz šim ir bijis slavenu cilvēku galvu uzlikšana uz pornogrāfisku filmu aktieru ķermeņiem, tie spēj radīt pārliecinošus kadrus, kuros ikviens dara jebko un jebkur.
Šajā ziņā mēs apskatīsim Deepfakes, kā tas darbojas, kā jūs varat tos ģenerēt pats un daudz ko citu.
Tātad, kas ir DeepFake?
Deepfake — frāžu dziļa mācīšanās un viltojums kombinācija — ir daļa no sintētiskie mediji kurā citas personas līdzība tiek izmantota, lai aizstātu personas līdzību jau esošā fotogrāfijā vai videoklipā.
Deepfakes izmanto sarežģītas mašīnmācīšanās un mākslīgā intelekta metodes, lai modificētu un izveidotu vizuālu un audio informāciju, kurai ir liels maldināšanas potenciāls.
Dziļās mācīšanās metodes, piemēram, automātiskās kodēšanas ierīces un ģeneratīvie pretrunīgie tīkli, ir galvenais dziļās viltojumu ražošanas (GAN) mehānisms.
Šos modeļus izmanto, lai analizētu cilvēka sejas emocijas un kustības un sintezētu citu cilvēku sejas attēlus, kuriem ir salīdzināmas sejas izteiksmes un kustības.
Ievērojamu uzmanību ir piesaistījusi dziļu viltojumu izmantošana slavenību pornogrāfiskos videoklipos, viltus ziņās, mānīšanās un finanšu krāpšana. Gan nozare, gan valdība ir reaģējusi, mēģinot tos atrast un ierobežot to izmantošanu.
Pirmās kārtas kustības modelis
Mēģinot izstrādāt dziļus viltojumus pagātnē, problēma bija tāda, ka mums ir vajadzīgas papildu zināšanas vai priekšzināšanas, lai šīs pieejas darbotos.
Ilustrācijai ir nepieciešami sejas marķieri, ja vēlamies izsekot galvas kustībai. Pozas novērtēšana bija nepieciešama, ja vēlējāmies kartēt visa ķermeņa kustību.
Tas mainījās NeurIPS konferencē pagājušajā gadā, kad Toronto Universitātes pētnieku komanda prezentēja savu darbu.Pirmās kārtas kustības modelis attēlu animācijai. "
Šai pieejai nav nepieciešamas papildu zināšanas par animāciju. Turklāt pēc tam, kad šis modelis ir apmācīts, to var izmantot pārnešanas mācībām un piemērot jebkuram vienumam, kas ietilpst tajā pašā kategorijā.
Apskatīsim šīs metodes darbību nedaudz tālāk. Kustības ekstrakcija un ģenerēšana veido visa procesa pirmo pusi. Braukšanas video un avota attēli tiek izmantoti kā ievades.
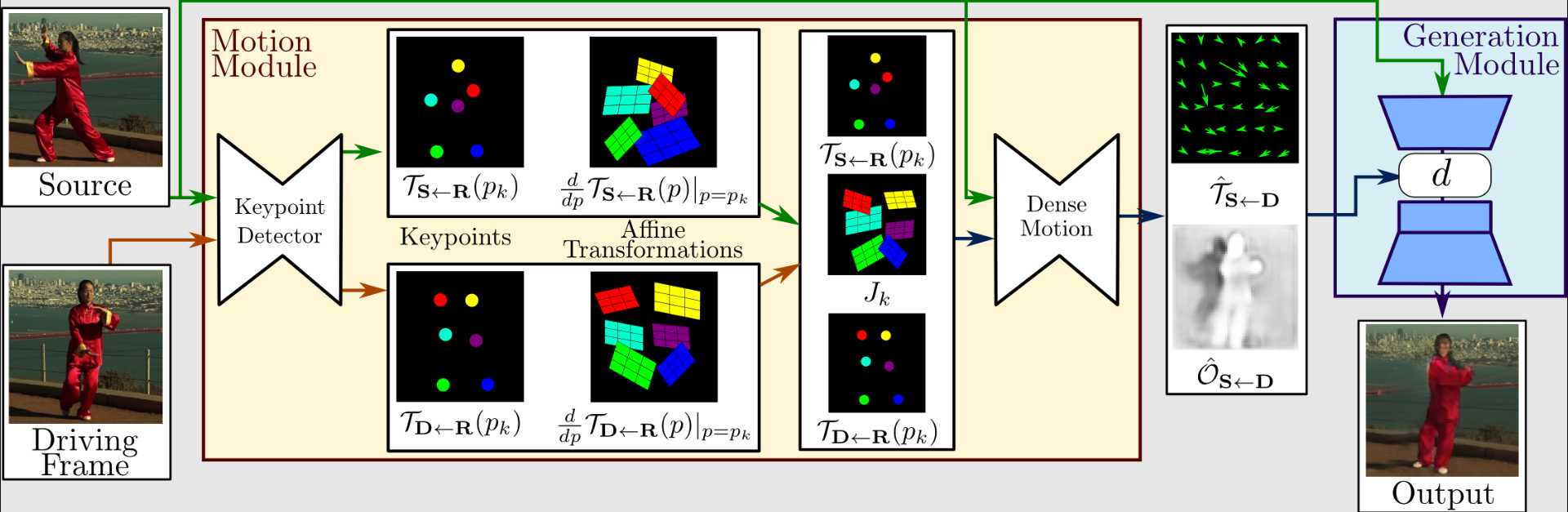
Lai iegūtu pirmās kārtas kustības attēlojumu, kas sastāv no retiem galvenajiem punktiem un lokālām afīnām transformācijām, kustību ekstraktorā galveno punktu identificēšanai tiek izmantots automātiskais kodētājs.
Lai izveidotu blīvu optiskās plūsmas un oklūzijas karti ar blīvu kustības tīklu, tie tiek izmantoti kopā ar braukšanas video. Pēc tam ģenerators atveido mērķa attēlu, izmantojot izejas no blīvās kustības tīkla un avota attēlu.
Kopumā šis darbs darbojas labāk nekā jaunākie. Tajā ir arī funkcijas, kuru citiem modeļiem vienkārši nav. Tas darbojas ar vairākiem attēlu veidiem, tāpēc varat to lietot sejas, ķermeņa, multfilmu utt. attēliem, kas ir ārkārtīgi lieliski.
Tas rada daudzas jaunas iespējas. Vēl viens revolucionārs mūsu stratēģijas aspekts ir tas, ka tagad tā ļauj jums izveidot augstas kvalitātes Deepfake, izmantojot tikai vienu mērķa objekta attēlu, līdzīgi kā mēs to darām ar YOLO priekš objektam atzīšana.
Deepfake modeļa izveides process
Deepfake ģenerēšanai ir nepieciešami trīs procesi: iegūšana, apmācība un izveide. Šajā sadaļā tiks apskatīti katra šī posma galvenie punkti un to saistība ar kopējo procesu.
Ieguve
Deepfakes izmanto dziļus neironu tīklus, lai mainītu sejas, un tiem ir nepieciešams daudz datu (attēlu), lai darbotos pareizi un pārliecinoši. Izvilkšanas process ir posms, kurā tiek izvilkti visi videoklipu kadri, tiek atpazītas sejas un pēc tam sejas tiek izlīdzinātas, lai palielinātu veiktspēju.
treniņš
Apmācības posmā, neironu tīklu var mainīt vienu seju citā. Atkarībā no treniņu komplekta lieluma un apmācības sīkrīka, apmācība var ilgt vairākas stundas vai pat dienas.
Apmācība ir jāpabeidz vienreiz, tāpat kā lielākā daļa citu neironu tīklu apmācību. Pēc apmācības modele varēs mainīt seju no personas A uz personu B.
Radīšana
Pēc modeļa apmācības var tikt izgatavots dziļš viltojums. Kadri tiek ņemti no videoklipa un pēc tam līdzināti visām sejām. Apmācītais neironu tīkls tiek izmantots, lai pārveidotu katru kadru.
Pārveidotā seja kā pēdējais solis ir jāapvieno ar sākotnējo rāmi.
Dziļās viltojumu noteikšanas modeļa izveide
GitHub Repo montāža un klonēšana
Iespēja bez maksas izmantot Google GPU, strādājot uzņēmumā Colab, ir izdevīga dziļa mācīšanās. Papildu priekšrocība ir iespēja uzstādīt Google disku mākoņa virtuālajā mašīnā (VM).
Lietotājs ir iespējots ar vieglu piekļuvi visam viņa saturam. Programma, kas nepieciešama, lai pievienotu Google disku virtuālajai mašīnai mākonī, ir atrodama šajā sadaļā.


Moduļu importēšana
Tagad mēs importēsim visus nepieciešamos moduļus.
Modeļa izpilde
Mēs izmantosim piemēru, kas apvieno Putina fotoattēlu (avota attēlu) ar Obamas video. Rezultāts ir video, kurā Putins runā un žestikulē ar tieši tādām pašām sejas izteiksmēm, kādas Obama izmantoja, vadot automašīnu.
Pirms modeļa rezultāta parādīšanas datu nesējs tiks ielādēts un funkcijas tiks deklarētas. Pēc tam tiks ielādēti kontrolpunkti un uzbūvēts modelis. Pēc dziļā viltojuma izveides tiks parādīti divi dažādi animācijas stili.
Putinu iedvesmo Obamas kustības, izmantojot relatīvu galveno punktu pārvietošanu. Tas, kā Putinam viņa videoklipos skaisti un skaidri tiek attēlotas Obamas sejas emocijas un ķermeņa valoda, ir pārsteidzošs.
Ir dažas mikroskopiskas kļūdas, it īpaši, ja Obama paceļ uzacis un mirkšķina acis. Šie izteicieni Putina rāmjos precīzi neatkārtojas.
Bez dziļa viltus fona Putina filma šķiet diezgan ticama un autentiska, ja to skatītos televīzijā vai sociālo mediju.
Modeļa izveide
Tagad mēs izmantosim iepriekš apmācītus kontrolpunktus, lai izveidotu pilnīgu modeli.
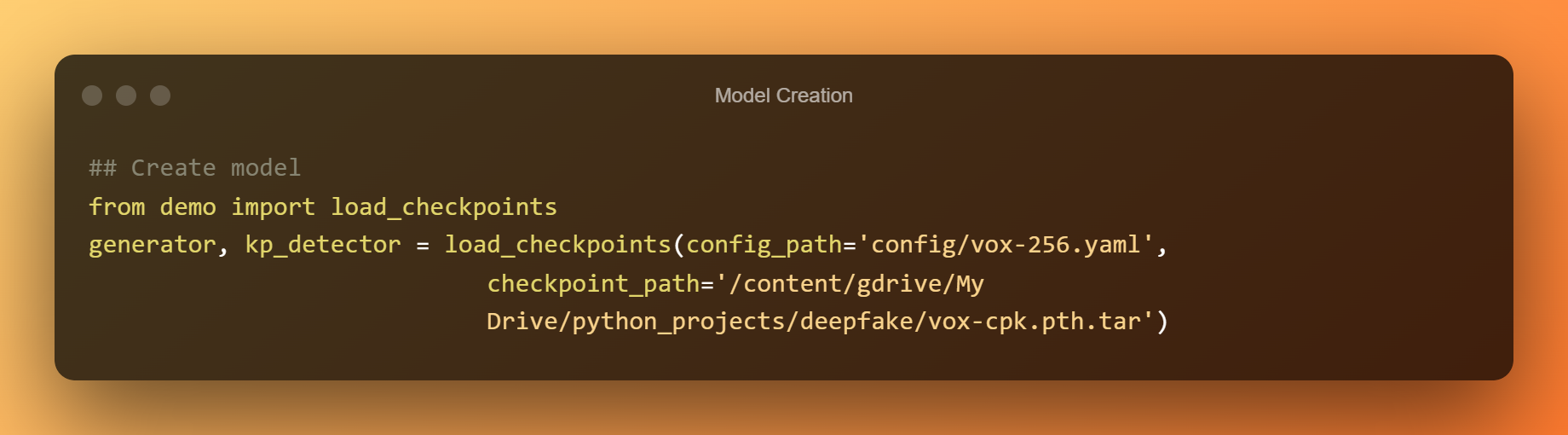
Dziļa viltojumu noteikšana
Relatīvā atslēgas punkta nobīde tiek izmantota, lai animētu vienumus tālāk esošajā šūnā. Nākamajā šūnā tiek izmantotas absolūtās koordinātas, taču visas vienumu proporcijas tiks ņemtas no braukšanas video šādā veidā.
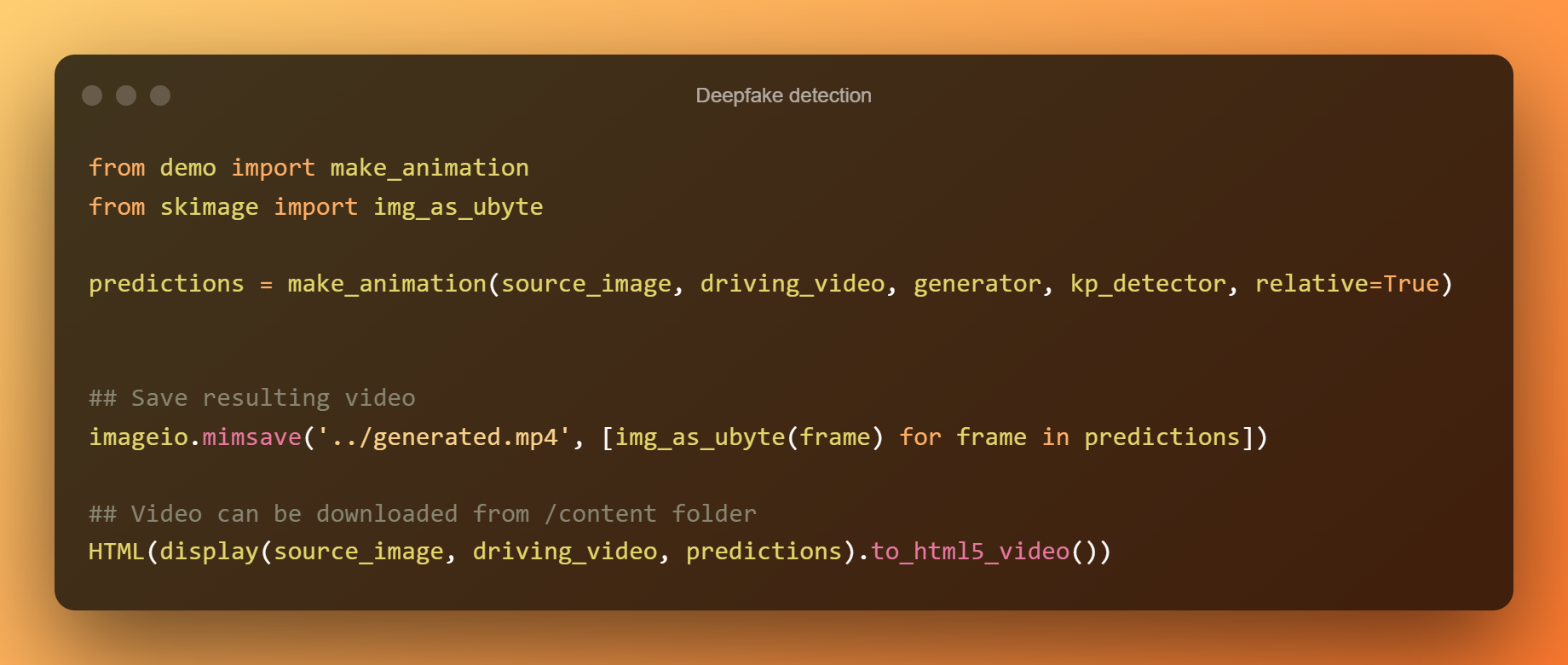
Izvades uzlabošana, izmantojot absolūtās koordinātas

Šādā veidā varēsit izveidot dziļu viltojumu noteikšanu.
Kādi ir Deepfake tehnoloģiju riski?
Deepfake videoklipi tagad ir saistoši un izklaidējoši skatīties to novitātes dēļ. Tomēr pastāv risks, ka šī šķietami smieklīgā tehnoloģija var kļūt nekontrolējama.
Noteikti būs grūti atšķirt viltotus un īstus videoklipus kā deepfake tehnoloģija turpina virzīties uz priekšu. Īpaši ievērojamām personībām un slavenībām tas var radīt nopietnas sekas. Dziļās viltojumi, kas ir apzināti ļaunprātīgi, var pilnībā sabojāt karjeru un dzīvi.
Tos var izmantot kāds ar ļaunu nolūku nodot citiem un izmantot savus draugus, radus un kolēģus. Viņi arī spēj izraisīt vispasaules strīdus un pat karus, izmantojot ārvalstu līderu viltus filmas.
Secinājumi
Rezumējot, mēs atrodamies dīvainā periodā un neparastā vidē. Vairāk nekā jebkad agrāk ir vienkārši izveidot viltus ziņas un filmas un tās izplatīt. Saprast, kas ir patiesība un kas nē, kļūst arvien grūtāk.
Šķiet, ka šodien mēs vairs nevaram paļauties uz savām sajūtām.
Neskatoties uz to, ka ir izstrādāti viltus video detektori, ir tikai laika jautājums, kad informācijas plaisa būs tik šaura, ka pat vissmalkākie viltus detektori nespēs noteikt, vai video ir vai nav.





Atstāj atbildi