AI はどこにでも存在しますが、用語や専門用語を理解するのが難しい場合もあります。 このブログ投稿では、この急速に成長するテクノロジーをより深く理解できるように、50 を超える AI の用語と定義を説明します。
あなたが初心者であろうと専門家であろうと、ここには知らない用語がいくつかあるはずです。
1。 人工知能
Artificial Intelligence (AI) は、多くの場合人間の知能をエミュレートすることによって、独立して学習して機能する能力を備えたコンピューター システムの開発を指します。
これらのシステムは、データを分析し、パターンを認識し、意思決定を行い、経験に基づいて動作を適応させます。 AI は、アルゴリズムとモデルを活用することで、周囲を認識し理解できるインテリジェントなマシンを作成することを目指しています。
最終的な目標は、機械がタスクを効率的に実行し、データから学習し、人間と同様の認知能力を発揮できるようにすることです。
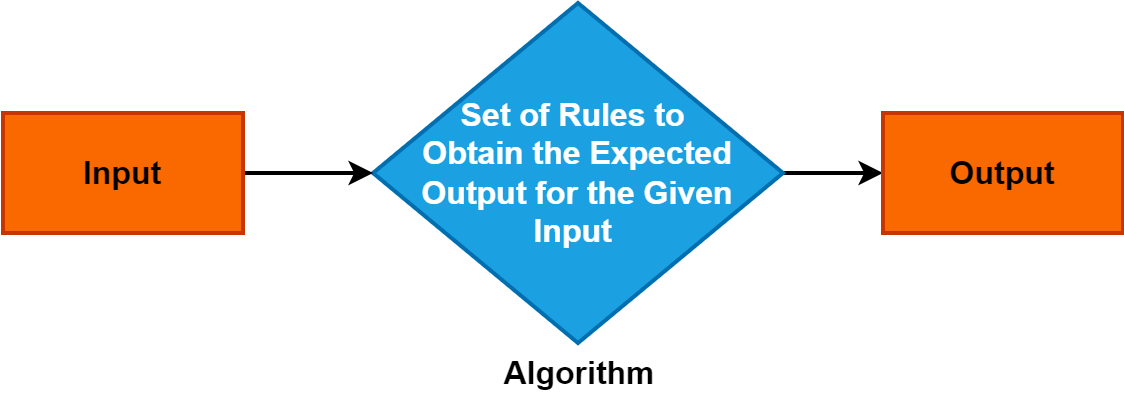
2。 アルゴリズム
アルゴリズムは、問題を解決したり特定のタスクを達成したりするプロセスを導く、正確かつ体系的な一連の指示またはルールです。
これはさまざまな分野の基本概念として機能し、コンピューター サイエンス、数学、問題解決の分野で極めて重要な役割を果たします。 アルゴリズムを理解することは、効率的で構造化された問題解決アプローチを可能にし、テクノロジーと意思決定プロセスの進歩を促進するため、非常に重要です。
3。 ビッグデータ
ビッグ データとは、従来の分析手法の能力を超える、非常に大規模で複雑なデータセットを指します。 これらのデータセットは通常、その量、速度、多様性によって特徴付けられます。
ボリュームとは、次のようなさまざまなソースから生成される膨大な量のデータを指します。 ソーシャルメディア、センサー、トランザクション。
速度とは、データが生成され、リアルタイムまたはほぼリアルタイムで処理される必要がある高速度を指します。 多様性は、構造化データ、非構造化データ、半構造化データなど、データの多様なタイプと形式を意味します。
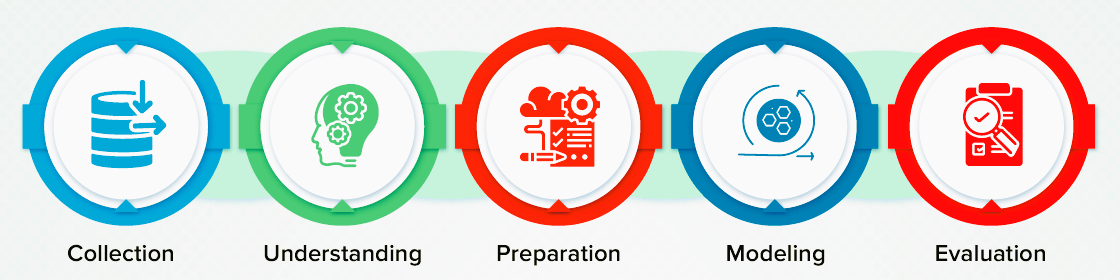
4。 データマイニング
データ マイニングは、膨大なデータセットから貴重な洞察を抽出することを目的とした包括的なプロセスです。
これには XNUMX つの主要な段階が含まれます。XNUMX つは関連データの収集を含むデータ収集です。 データの準備、データの品質と互換性の確保。 データをマイニングし、アルゴリズムを使用してパターンと関係を発見します。 そして抽出された知識を調べて理解するデータ分析と解釈。
5. ニューラルネットワーク
コンピュータ システムは次のように動作するように設計されています。 人間の脳、相互接続されたノードまたはニューロンで構成されます。 ほとんどの AI はこれに基づいているため、これをもう少し理解しましょう。 ニューラルネットワーク.
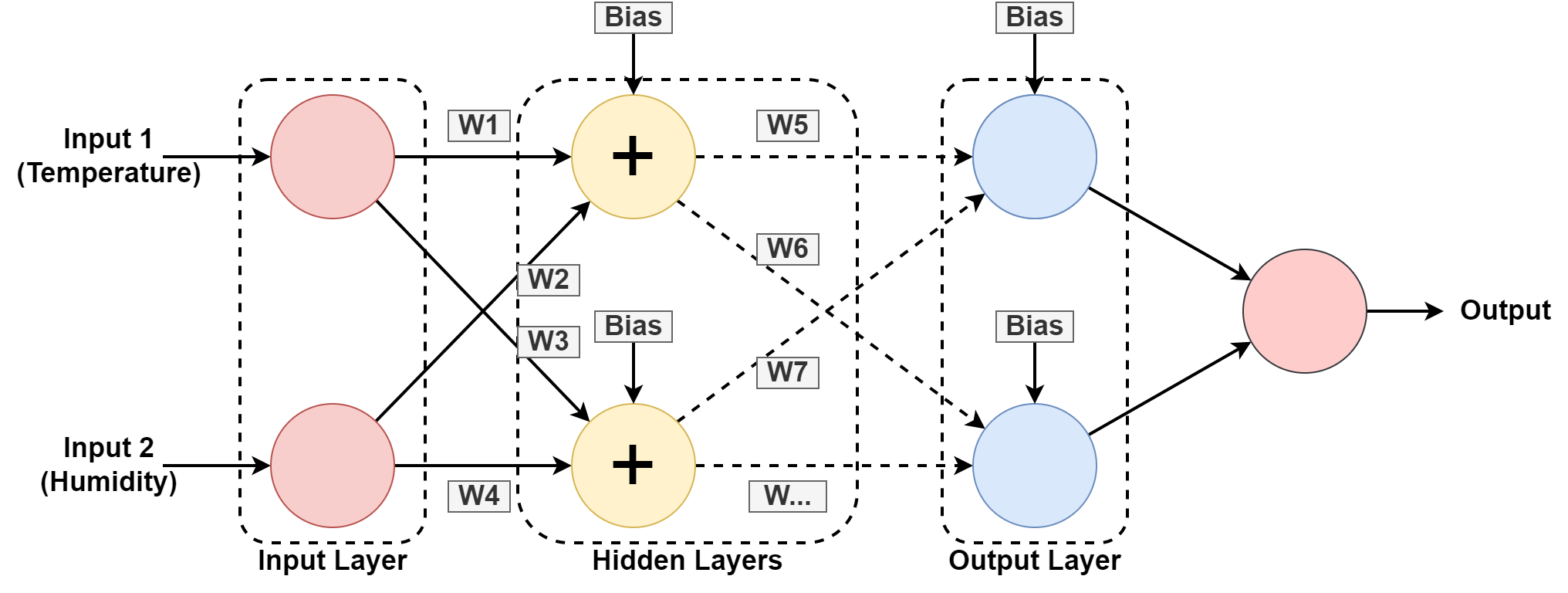
上のグラフィックでは、過去のパターンから学習して、地理的位置の湿度と温度を予測しています。 入力は過去のレコードのデータセットです。
ニューラルネットワークが学習する 重みを調整し、隠れレイヤーにバイアス値を適用することでパターンを作成します。 W1、W2….W7 はそれぞれの重みです。 提供されたデータセットに基づいてトレーニングし、予測として出力します。
この複雑な情報に圧倒されてしまうかもしれません。 この場合は、簡単なガイドから始めることができます こちら.
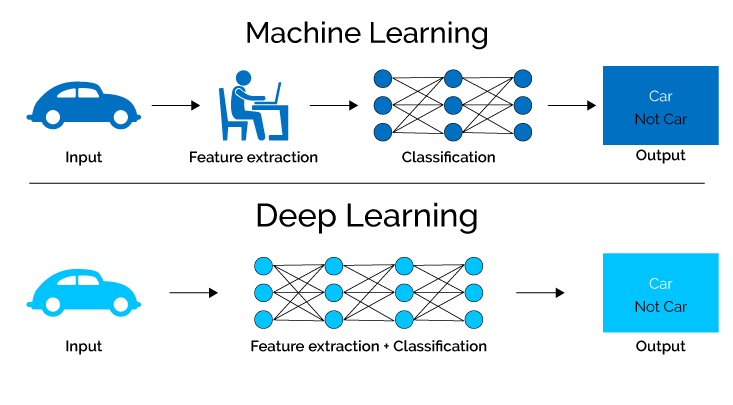
6。 機械学習
機械学習は、データから自動的に学習し、時間の経過とともにパフォーマンスを向上させることができるアルゴリズムとモデルの開発に焦点を当てています。
これには、明示的にプログラムされずにコンピューターがパターンを識別し、予測し、データに基づいた意思決定を行えるようにする統計手法の使用が含まれます。
機械学習アルゴリズム 大規模なデータセットを分析して学習し、システムが処理する情報に基づいて動作を適応させ、改善できるようにします。
7. 深層学習
深い学習は、機械学習とニューラル ネットワークのサブ分野であり、高度なアルゴリズムを活用して、人間の脳の複雑なプロセスをシミュレートすることでデータから知識を取得します。
多数の隠れ層を持つニューラル ネットワークを採用することで、ディープ ラーニング モデルは複雑な特徴とパターンを自律的に抽出でき、並外れた精度と効率で複雑なタスクに取り組むことができます。
8. パターン認識
データ分析手法であるパターン認識は、機械学習アルゴリズムの力を利用して、データセット内のパターンと規則性を自律的に検出および識別します。
計算モデルと統計手法を活用することで、パターン認識アルゴリズムは、複雑で多様なデータ内の意味のある構造、相関関係、傾向を特定できます。
このプロセスにより、貴重な洞察の抽出、データの個別のカテゴリへの分類、認識されたパターンに基づく将来の結果の予測が可能になります。 パターン認識は、さまざまなドメインにわたって重要なツールであり、意思決定、異常検出、予測モデリングを強化します。
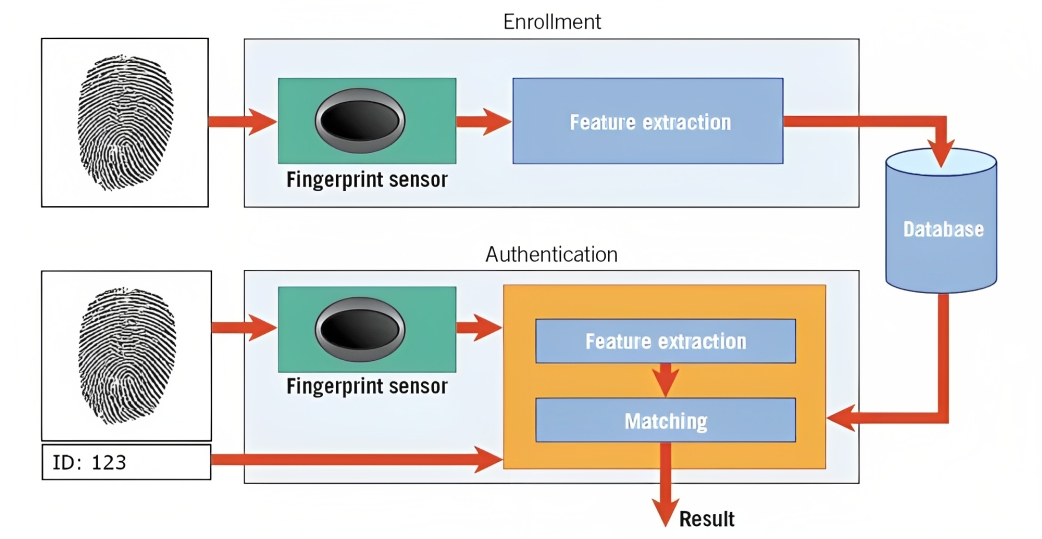
生体認証はその一例です。 たとえば、指紋認識では、アルゴリズムが人の指紋の隆線、曲線、および固有の特徴を分析して、テンプレートと呼ばれるデジタル表現を作成します。
スマートフォンのロックを解除しようとしたり、安全な施設にアクセスしようとすると、パターン認識システムは、キャプチャされた生体データ (指紋など) をデータベースに保存されているテンプレートと比較します。
パターンを照合し、類似性のレベルを評価することにより、システムは提供された生体認証データが保存されているテンプレートと一致するかどうかを判断し、それに応じてアクセスを許可します。
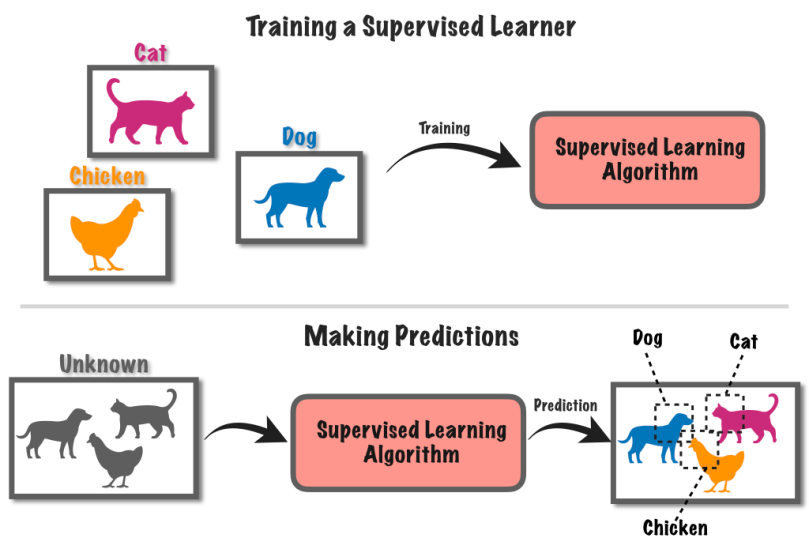
9.教師あり学習
教師あり学習は、ラベル付きデータを使用してコンピューター システムをトレーニングする機械学習アプローチです。 この方法では、コンピュータには、対応する既知のラベルまたは結果とともに入力データのセットが提供されます。
犬が写った写真や猫が写った写真など、たくさんの写真があるとします。
どの写真に犬が写っていて、どの写真に猫が写っているかをコンピュータに指示します。 その後、コンピューターは写真の中のパターンを見つけて犬と猫の違いを認識することを学習します。
学習した後、コンピューターに新しい写真を与えると、ラベル付けされた例から学習した内容に基づいて、コンピューターが犬を飼っているのか猫を飼っているのかを判断しようとします。 これは、既知の情報を使用して予測を行うようにコンピューターをトレーニングするようなものです。
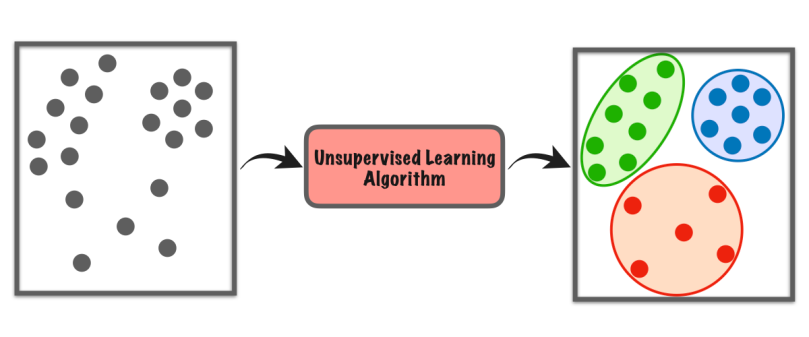
10.教師なし学習
教師なし学習は機械学習の一種で、コンピューターが独自にデータセットを探索し、特別な指示なしにパターンや類似点を見つけます。
教師あり学習のようにラベル付きの例に依存しません。 代わりに、データ内の隠れた構造またはグループを探します。 教師が何を探すべきかを指示しなくても、コンピュータが自ら何かを発見しているようなものです。
このタイプの学習は、事前知識や明確な指導を必要とせずに、新しい洞察を見つけたり、データを整理したり、異常なことを特定したりするのに役立ちます。
11.自然言語処理(NLP)
自然言語処理は、コンピューターが人間の言語をどのように理解し、対話するかに焦点を当てています。 これは、コンピューターが人間の言語をより自然に感じられる方法で分析、解釈し、応答するのに役立ちます。
NLP により、音声アシスタントやチャットボットとの通信が可能になり、メールを自動的にフォルダーに分類することもできます。
これには、単語、文章、さらにはテキスト全体の背後にある意味を理解するようにコンピューターを教えることが含まれており、コンピューターはさまざまなタスクを支援し、テクノロジーとのやり取りをよりシームレスに行うことができます。
12.コンピュータビジョン
コンピュータビジョン は、私たち人間が目で行うのと同じように、コンピューターが画像やビデオを見て理解できるようにする魅力的なテクノロジーです。 それはすべて、視覚情報を分析し、目に見えるものを理解するようにコンピューターに教えることです。
簡単に言うと、コンピューター ビジョンは、コンピューターが視覚的な世界を認識して解釈するのに役立ちます。 これには、画像内の特定のオブジェクトを識別する方法、画像をさまざまなカテゴリに分類する方法、さらには画像を意味のある部分に分割する方法を教えるなどのタスクが含まれます。
コンピュータービジョンを使用して道路とその周囲のすべてを「見る」自動運転車を想像してください。
歩行者、交通標識、その他の車両を検出して追跡し、安全な移動を支援します。 あるいは、顔認識テクノロジーがコンピューター ビジョンを使用してスマートフォンのロックを解除したり、固有の顔の特徴を認識して身元を確認したりする方法について考えてみましょう。
また、混雑した場所を監視し、不審な活動を発見するための監視システムにも使用されます。
コンピューター ビジョンは、可能性の世界を開く強力なテクノロジーです。 コンピューターが視覚情報を見て理解できるようにすることで、私たちの周囲の世界を認識して解釈できるアプリケーションやシステムを開発でき、私たちの生活をより簡単、安全、効率的にすることができます。
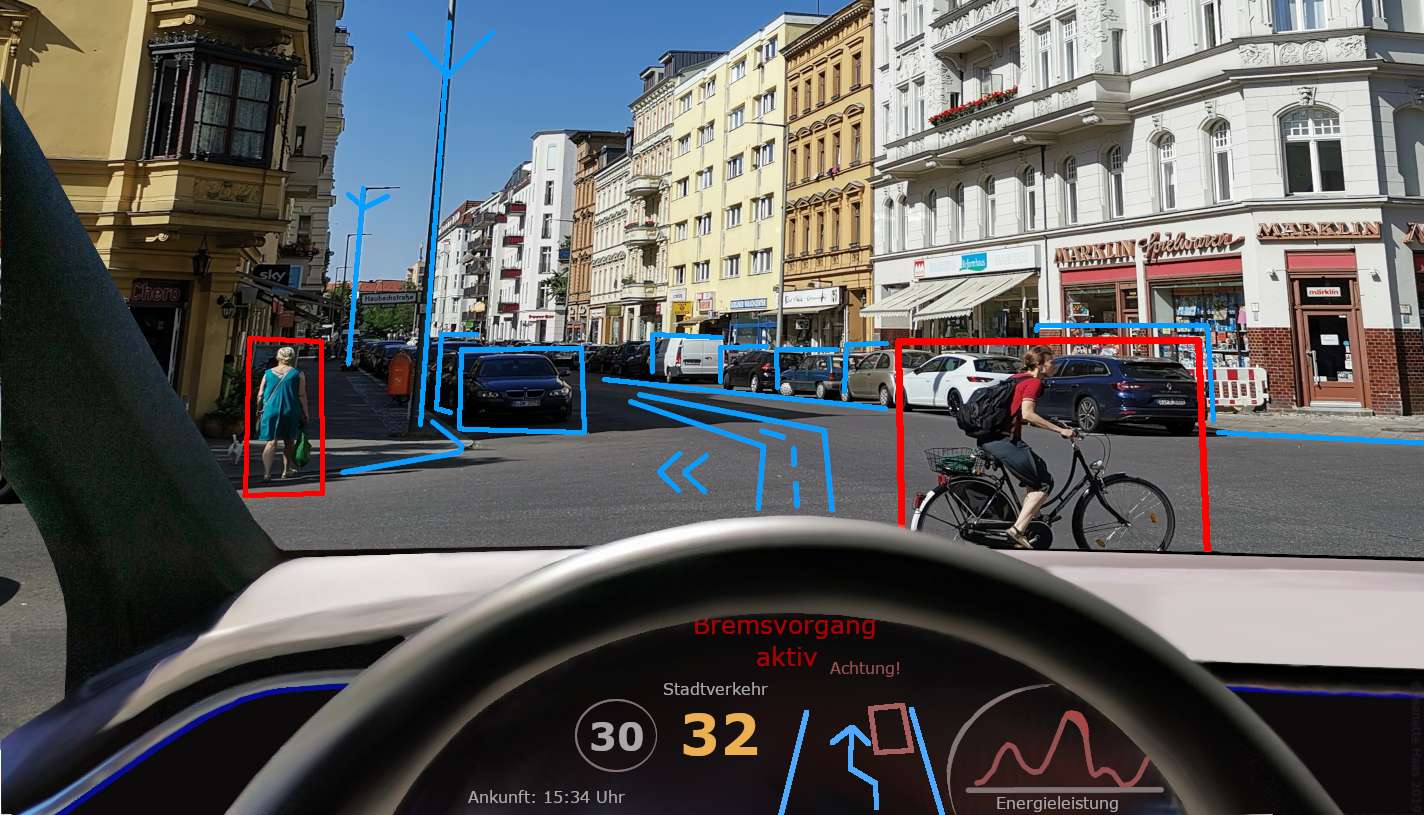
13.チャットボット
チャットボットは、実際の人間の会話と同じように人々と会話できるコンピューター プログラムのようなものです。
これは、実際にはコンピューター上で実行されるプログラムであるにもかかわらず、顧客を支援し、まるで人と話しているように感じさせるために、オンライン カスタマー サービスでよく使用されます。
チャットボットは顧客からのメッセージや質問を理解して応答し、人間の顧客サービス担当者と同じように役立つ情報や支援を提供します。
14.音声認識
音声認識とは、人間の音声を理解して解釈するコンピュータ システムの能力を指します。 これには、コンピューターまたはデバイスが話された言葉を「聞いて」、それを理解できるテキストまたはコマンドに変換できるようにするテクノロジーが含まれます。
音声認識を使用すると、入力したり他の入力方法を使用したりする代わりに、話しかけるだけでデバイスやアプリケーションを操作できます。
システムは話された言葉を分析し、パターンと音声を認識して、それらを理解可能なテキストまたはアクションに変換します。 テクノロジーとのハンズフリーで自然なコミュニケーションが可能になり、音声コマンド、ディクテーション、音声制御による対話などのタスクが可能になります。 最も一般的な例は、Siri や Google アシスタントなどの AI アシスタントです。
15。 感情分析
感情分析 テキストやスピーチで表現された感情、意見、態度を理解し、解釈するために使用されるテクニックです。 これには、書き言葉または話し言葉を分析して、表現された感情が肯定的、否定的、または中立的であるかどうかを判断することが含まれます。
感情分析アルゴリズムは、機械学習アルゴリズムを使用して、顧客のレビュー、ソーシャル メディアの投稿、顧客のフィードバックなどの大量のテキスト データをスキャンして分析し、言葉の背後にある根本的な感情を特定します。
アルゴリズムは、感情や意見を示す特定の単語、フレーズ、またはパターンを探します。
この分析は、企業や個人が製品、サービス、またはトピックについて人々がどのように感じているかを理解するのに役立ち、データに基づいた意思決定を行ったり、顧客の好みについての洞察を得るために使用できます。
たとえば、企業はセンチメント分析を使用して顧客満足度を追跡したり、改善すべき領域を特定したり、ブランドに関する世論を監視したりできます。
16.機械翻訳
AI の文脈における機械翻訳とは、コンピューター アルゴリズムと人工知能を使用して、テキストや音声をある言語から別の言語に自動的に翻訳することを指します。
これには、正確な翻訳を提供するために、人間の言語を理解して処理できるようにコンピューターを教えることが含まれます。 最も一般的な例は次のとおりです グーグル翻訳。
機械翻訳を使用すると、ある言語でテキストまたは音声を入力すると、システムが入力を分析して、別の言語で対応する翻訳を生成します。 これは、異なる言語間で情報を伝達したり、情報にアクセスしたりする場合に特に役立ちます。
機械翻訳システムは、言語規則、統計モデル、機械学習アルゴリズムの組み合わせに依存しています。 膨大な言語データから学習して、時間の経過とともに翻訳の精度を向上させます。 機械翻訳のアプローチの中には、翻訳の品質を高めるためにニューラル ネットワークを組み込んだものもあります。
17。 ロボティクス
ロボティクスは、人工知能と機械工学を組み合わせて、ロボットと呼ばれるインテリジェントな機械を作成することです。 これらのロボットは、自律的に、または人間の介入を最小限に抑えてタスクを実行するように設計されています。
ロボットは、環境を感知し、その感覚入力に基づいて意思決定を行い、特定のアクションやタスクを実行できる物理的実体です。
彼らにはカメラ、マイク、タッチセンサーなどのさまざまなセンサーが装備されており、周囲の世界から情報を収集できます。 AI アルゴリズムとプログラミングの助けを借りて、ロボットはこのデータを分析、解釈し、指定されたタスクを実行するためのインテリジェントな決定を下すことができます。
AI は、ロボットが経験から学習し、さまざまな状況に適応できるようにすることで、ロボット工学において重要な役割を果たします。
機械学習アルゴリズムを使用すると、ロボットが物体を認識したり、環境をナビゲートしたり、人間と対話したりするよう訓練することができます。 これにより、ロボットはより多用途かつ柔軟になり、複雑なタスクを処理できるようになります。
18。 ドロンズ
ドローンは、人間のパイロットが搭乗しなくても、空中を飛行したりホバリングしたりできるロボットの一種です。 無人航空機 (UAV) としても知られています。 ドローンにはカメラ、GPS、ジャイロスコープなどのさまざまなセンサーが装備されており、これらによりデータを収集し、周囲をナビゲートすることができます。
これらは人間のオペレーターによって遠隔制御されるか、事前にプログラムされた命令を使用して自律的に動作することができます。
ドローンは、航空写真やビデオ撮影、測量や地図作成、配送サービス、捜索救助任務、農業監視、さらには娯楽用途など、幅広い目的に使用されています。 彼らは、人間にとって困難または危険な遠隔地または危険なエリアにアクセスすることができます。
19。 拡張現実(AR)
拡張現実 (AR) は、現実世界と仮想オブジェクトまたは情報を組み合わせて、私たちの認識と環境との相互作用を強化するテクノロジーです。 コンピューターで生成された画像、音声、その他の感覚入力を現実世界に重ね合わせ、没入型でインタラクティブな体験を作り出します。
簡単に言えば、特別なメガネを着用するか、スマートフォンを使用して周囲の世界を見るのに、仮想要素が追加されることを想像してください。
たとえば、スマートフォンを街の通りに向けると、近くのレストランへの道順、評価、レビューを示す仮想標識が表示されたり、現実の環境と対話する仮想キャラクターが表示されたりする可能性があります。
これらの仮想要素は現実世界とシームレスに融合し、周囲の理解と体験を強化します。 拡張現実は、ゲーム、教育、建築などのさまざまな分野で使用できるほか、ナビゲーションや新しい家具を購入する前に家の中で試してみるなどの日常業務にも使用できます。
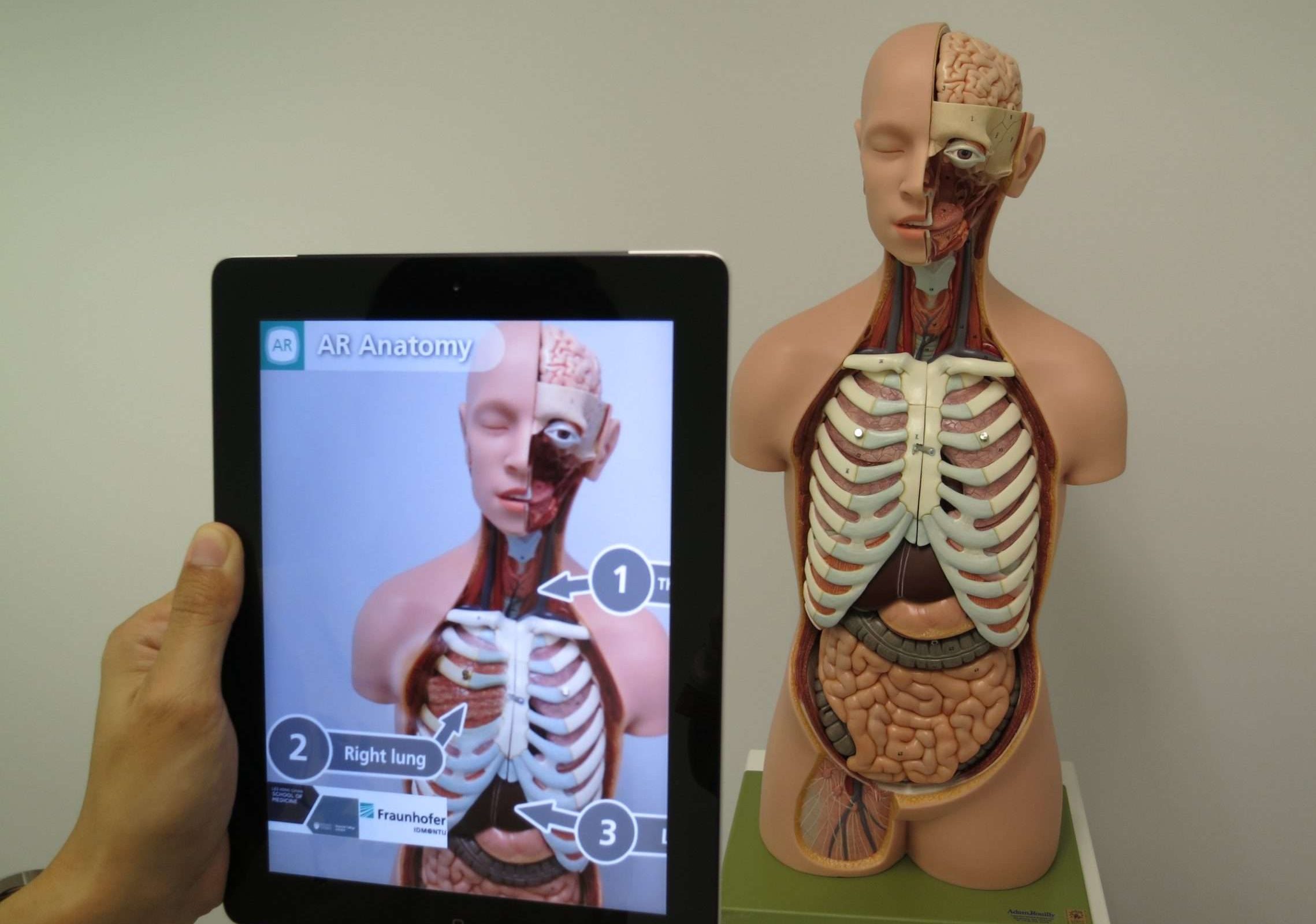
20。 バーチャルリアリティ(VR)
仮想現実 (VR) は、コンピューター生成のシミュレーションを使用して、人が探索したり対話したりできる人工環境を作成するテクノロジーです。 ユーザーを仮想世界に没入させ、現実世界を遮断し、デジタル領域に置き換えます。
簡単に言えば、目と耳を覆う特別なヘッドセットを装着すると、まったく別の場所に移動できると想像してください。 この仮想世界では、すべてコンピューターによって生成されているにもかかわらず、見るもの聞くものすべてが信じられないほど現実的に感じられます。
物理的に存在しているかのように、動き回ったり、あらゆる方向を見たり、オブジェクトやキャラクターと対話したりできます。
たとえば、仮想現実ゲームでは、中世の城の中に入り、廊下を歩き、武器を手に取り、仮想の敵と剣で戦いを繰り広げることができます。 仮想現実環境はユーザーの動きや行動に反応し、ユーザーは完全に没入し、その体験に没頭しているように感じられます。
仮想現実はゲームだけでなく、パイロット、外科医、軍人のための訓練シミュレーション、建築物のウォークスルー、仮想観光、さらには特定の心理状態の治療など、他のさまざまな用途にも使用されています。 臨場感を生み出し、ユーザーを新しくエキサイティングな仮想世界に連れて行き、体験を可能な限り現実に近づけます。
21.データサイエンス
データサイエンス 科学的手法、ツール、アルゴリズムを使用してデータから貴重な知識や洞察を抽出する分野です。 数学、統計、プログラミング、専門知識の要素を組み合わせて、大規模で複雑なデータセットを分析します。
簡単に言うと、データ サイエンスとは、大量のデータの中に隠された意味のある情報やパターンを見つけることです。 これには、データの収集、クリーニング、整理が含まれ、その後、さまざまな手法を使用してデータを調査および分析します。 データサイエンティスト 統計モデルとアルゴリズムを使用して傾向を明らかにし、予測を行い、問題を解決します。
たとえば、ヘルスケアの分野では、データ サイエンスを使用して患者の記録や医療データを分析し、病気の危険因子を特定したり、患者の転帰を予測したり、治療計画を最適化したりできます。 ビジネスでは、データ サイエンスを顧客データに適用して、顧客の好みを理解したり、製品を推奨したり、マーケティング戦略を改善したりできます。
22. データラングリング
データ ラングリング (データ マンジングとも呼ばれます) は、生データを収集、クリーニングし、より有用で分析に適した形式に変換するプロセスです。 これには、データの品質、一貫性、分析ツールやモデルとの互換性を確保するためのデータの処理と準備が含まれます。
簡単に言うと、データラングリングは料理の材料を準備するようなものです。 これには、さまざまなソースからデータを収集し、整理し、エラー、矛盾、または無関係な情報を削除するためにクリーンアップすることが含まれます。
さらに、作業や洞察の抽出を容易にするために、データの変換、再構築、または集約が必要になる場合があります。
たとえば、データ ラングリングには、重複エントリの削除、スペルミスや書式設定の問題の修正、欠損値の処理、データ型の変換が含まれる場合があります。 また、異なるデータセットをマージまたは結合したり、データをサブセットに分割したり、既存のデータに基づいて新しい変数を作成したりすることも含まれる場合があります。
23.データストーリーテリング
データのストーリーテリング 物語やメッセージを効果的に伝えるために、説得力のある魅力的な方法でデータを提示する技術です。 使用することが含まれます データの視覚化、ナラティブ、およびコンテキストを使用して、視聴者に理解しやすく記憶に残る方法で洞察と発見を伝えます。
簡単に言うと、データ ストーリーテリングとは、データを使用してストーリーを伝えることです。 それは単に数字やグラフを提示するだけではありません。 これには、データに命を吹き込み、視聴者が共感できるようにするための視覚要素とストーリーテリング手法を使用して、データに関する物語を作成することが含まれます。
たとえば、データ ストーリーテリングには、単純に売上高の表を提示するのではなく、ユーザーが売上傾向を視覚的に探索できる対話型ダッシュボードの作成が含まれる場合があります。
主要な調査結果を強調し、傾向の背後にある理由を説明し、データに基づいて実用的な推奨事項を提案する物語を含めることができます。
24. データに基づく意思決定
データ駆動型の意思決定は、関連データの分析と解釈に基づいて選択を行ったり、行動を起こしたりするプロセスです。 これには、直感や個人的な判断だけに頼るのではなく、意思決定プロセスを導きサポートするための基盤としてデータを使用することが含まれます。
より簡単に言うと、データ主導の意思決定とは、データから得られる事実と証拠を使用して、選択の情報を提供し、導くことを意味します。 データを収集および分析してパターン、傾向、関係を理解し、その知識を利用して情報に基づいた意思決定を行い、問題を解決することが含まれます。
たとえば、ビジネス環境では、データ主導の意思決定には、販売データ、顧客からのフィードバック、市場動向を分析して、最も効果的な価格戦略を決定したり、製品開発の改善領域を特定したりすることが含まれる場合があります。
ヘルスケアでは、治療計画を最適化したり病気の転帰を予測したりするために患者データを分析することが含まれる場合があります。
25. データレイク
データ レイクは、大量のデータを生の未処理の形式で保存する、一元化されたスケーラブルなデータ リポジトリです。 事前定義されたスキーマやデータ変換を必要とせずに、構造化データ、半構造化データ、非構造化データなど、さまざまなデータ型、形式、構造を保持できるように設計されています。
たとえば、企業は、Web サイトのログ、顧客トランザクション、ソーシャル メディア フィード、IoT デバイスなどのさまざまなソースからデータを収集し、データ レイクに保存することがあります。
このデータは、高度な分析の実施、機械学習アルゴリズムの実行、顧客の行動のパターンや傾向の調査など、さまざまな目的に使用できます。
26. データ ウェアハウス
データ ウェアハウスは、さまざまなソースからの大量のデータを保存、整理、分析するために特別に設計された特殊なデータベース システムです。 効率的なデータ取得と複雑な分析クエリをサポートする方法で構造化されています。
これは、トランザクション データベース、CRM システム、組織内のその他のデータ ソースなど、さまざまな運用システムからのデータを統合する中央リポジトリとして機能します。
データは変換、クレンジングされ、分析目的に最適化された構造化形式でデータ ウェアハウスにロードされます。
27.ビジネスインテリジェンス(BI)
ビジネス インテリジェンスとは、企業が情報に基づいた意思決定を行い、貴重な洞察を得るのに役立つ方法でデータを収集、分析、提示するプロセスを指します。 これには、さまざまなツール、テクノロジー、手法を使用して、生データを意味のある実用的な情報に変換することが含まれます。
たとえば、ビジネス インテリジェンス システムは販売データを分析して、最も収益性の高い製品を特定し、在庫レベルを監視し、顧客の好みを追跡します。
収益、顧客獲得、製品パフォーマンスなどの主要業績評価指標 (KPI) に関するリアルタイムの洞察を提供できるため、企業はデータに基づいて意思決定を行い、業務を改善するために適切な措置を講じることができます。
ビジネス インテリジェンス ツールには、データ視覚化、アドホック クエリ、データ探索機能などの機能が含まれることがよくあります。 これらのツールにより、ユーザーは次のようなことが可能になります。 ビジネスアナリスト 管理者は、データを操作して細かく分析し、重要な洞察や傾向を強調するレポートや視覚的表現を生成します。
28。 予測分析
予測分析とは、データと統計手法を使用して、将来の出来事や結果について情報に基づいた予測や予測を行う実践です。 これには、履歴データの分析、パターンの特定、将来の傾向、行動、または出来事を推定および推定するためのモデルの構築が含まれます。
変数間の関係を明らかにし、その情報を使用して予測を行うことを目的としています。 それは単に過去の出来事を説明するだけではありません。 代わりに、過去のデータを活用して、将来何が起こるかを理解し、予測します。
たとえば、金融の分野では、予測分析を使用して予測を行うことができます。 株式 過去の市場データ、経済指標、その他の関連要因に基づいた価格。
マーケティングでは、顧客の行動や好みを予測するために使用でき、ターゲットを絞った広告やパーソナライズされたマーケティング キャンペーンが可能になります。
ヘルスケアでは、予測分析は、特定の病気のリスクが高い患者を特定したり、病歴やその他の要因に基づいて再入院の可能性を予測したりするのに役立ちます。
29. 規範的分析
処方的分析は、特定の状況または意思決定シナリオで実行すべき最善のアクションを決定するためのデータと分析のアプリケーションです。
それは説明的なものを超えており、 予測分析 将来何が起こるかについての洞察を提供するだけでなく、望ましい結果を達成するために最適な行動方針を推奨します。
過去のデータ、予測モデル、最適化手法を組み合わせて、さまざまなシナリオをシミュレートし、さまざまな意思決定の潜在的な結果を評価します。 複数の制約、目的、要因を考慮して、望ましい結果を最大化し、リスクを最小限に抑える実用的な推奨事項を生成します。
たとえば、 サプライチェーン 管理、規範的分析により、在庫レベル、生産能力、輸送コスト、顧客の需要に関するデータを分析し、最も効率的な流通計画を決定できます。
在庫の保管場所や輸送ルートなどのリソースの理想的な割り当てを推奨して、コストを最小限に抑え、タイムリーな配送を保証します。
30. データドリブンマーケティング
データドリブン マーケティングとは、データと分析を使用してマーケティング戦略、キャンペーン、意思決定プロセスを推進する実践を指します。
これには、さまざまなデータ ソースを活用して顧客の行動、好み、傾向に関する洞察を取得し、その情報を使用してマーケティング活動を最適化することが含まれます。
ウェブサイトでのやり取り、ソーシャルメディアでのエンゲージメント、顧客層、購入履歴など、複数のタッチポイントからデータを収集して分析することに重点を置いています。 このデータは、対象となる視聴者、その好み、ニーズを包括的に理解するために使用されます。
データを活用することで、マーケティング担当者は顧客のセグメンテーション、ターゲティング、パーソナライゼーションに関して情報に基づいた意思決定を行うことができます。
マーケティング キャンペーンに積極的に反応する可能性が高い特定の顧客セグメントを特定し、それに応じてメッセージやオファーを調整できます。
さらに、データ駆動型マーケティングは、マーケティング チャネルの最適化、最も効果的なマーケティング ミックスの決定、マーケティング イニシアチブの成功の測定にも役立ちます。
たとえば、データ駆動型のマーケティング アプローチには、顧客データを分析して購入行動や好みのパターンを特定することが含まれる場合があります。 これらの洞察に基づいて、マーケティング担当者は、特定の顧客セグメントの共感を呼ぶパーソナライズされたコンテンツとオファーを含むターゲットを絞ったキャンペーンを作成できます。
継続的な分析と最適化を通じて、マーケティング活動の効果を測定し、時間をかけて戦略を洗練させることができます。
31.データガバナンス
データ ガバナンスは、ライフサイクル全体を通じてデータの適切な管理、保護、整合性を確保するために組織が採用するフレームワークと一連の実践方法です。 これには、組織内でデータがどのように収集、保存、アクセス、使用、共有されるかを管理するプロセス、ポリシー、手順が含まれます。
データ資産に対する説明責任、責任、制御を確立することを目的としています。 これにより、データの正確さ、完全さ、一貫性、信頼性が確保され、組織が情報に基づいた意思決定を行い、データの品質を維持し、規制要件を満たすことができるようになります。
データ ガバナンスには、データ管理の役割と責任の定義、データ標準とポリシーの確立、コンプライアンスの監視と強制のためのプロセスの実装が含まれます。 データ プライバシー、データ セキュリティ、データ品質、データ分類、データ ライフサイクル管理など、データ管理のさまざまな側面に対処します。
たとえば、データ ガバナンスには、個人データや機密データが一般データ保護規則 (GDPR) などの適用されるプライバシー規制に従って確実に扱われるようにするための手順の実装が含まれる場合があります。
また、データの正確性と信頼性を確保するために、データ品質基準を確立し、データ検証プロセスを実装することも含まれる場合があります。
32。 データセキュリティ
データ セキュリティとは、貴重な情報を不正アクセスや盗難から安全に保つことです。 これには、データの機密性、完全性、可用性を保護するための措置を講じることが含まれます。
基本的に、これは、適切なユーザーのみが当社のデータにアクセスできること、データが正確かつ変更されていないこと、必要なときに利用できることを保証することを意味します。
データのセキュリティを実現するために、さまざまな戦略とテクノロジーが使用されます。 たとえば、アクセス制御と暗号化方式により、許可された個人またはシステムへのアクセスが制限され、部外者が当社のデータにアクセスすることが困難になります。
監視システム、ファイアウォール、侵入検知システムは監視者の役割を果たし、不審なアクティビティを警告し、不正アクセスを防ぎます。
33 モノのインターネット
モノのインターネット (IoT) は、インターネットに接続され、相互に通信できる物理オブジェクトまたは「モノ」のネットワークを指します。 これは、インターネットを介して対話することで情報を共有し、タスクを実行できる、日常的な物体、デバイス、機械の大きなウェブのようなものです。
簡単に言えば、IoT には、これまでインターネットに接続されていなかったさまざまなオブジェクトやデバイスに「スマート」機能を与えることが含まれます。 これらのオブジェクトには、家庭用電化製品、ウェアラブル デバイス、サーモスタット、自動車、さらには産業用機械も含まれます。
これらのオブジェクトをインターネットに接続することで、データを収集および共有し、指示を受け取り、自律的にまたはユーザーのコマンドに応じてタスクを実行できます。
たとえば、スマート サーモスタットは、温度を監視し、設定を調整し、エネルギー使用量レポートをスマートフォン アプリに送信できます。 ウェアラブル フィットネス トラッカーは、身体活動に関するデータを収集し、分析のためにクラウドベースのプラットフォームに同期できます。
34.ディシジョンツリー
デシジョン ツリーは、一連の選択や条件に基づいて意思決定を行ったり、一連の行動を決定したりするのに役立つ視覚的な表現または図です。
これは、さまざまなオプションとその潜在的な結果を考慮して、意思決定プロセスをガイドするフローチャートのようなものです。
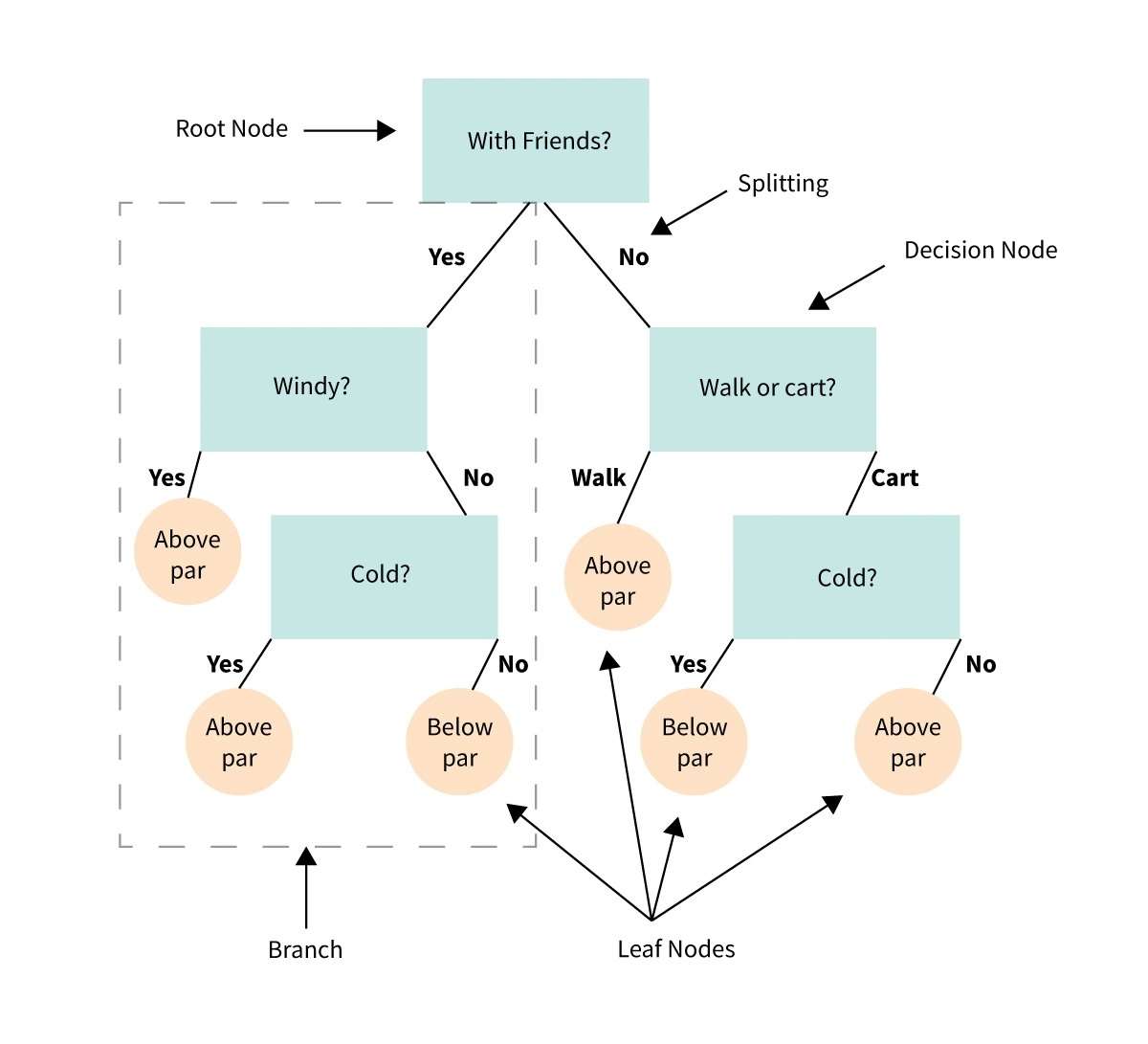
問題や質問があり、選択をする必要があると想像してください。
デシジョン ツリーは、意思決定を小さなステップに分割し、最初の質問から始まり、各ステップの条件や基準に基づいて、考えられるさまざまな回答やアクションに分岐します。
35. コグニティブコンピューティング
コグニティブ コンピューティングとは、簡単に言えば、学習、推論、理解、問題解決などの人間の認知能力を模倣するコンピューター システムまたはテクノロジーを指します。
それには、人間の思考に似た方法で情報を処理および解釈できるコンピューター システムを作成することが含まれます。
コグニティブ コンピューティングは、より自然かつインテリジェントな方法で人間を理解し、対話できるマシンを開発することを目的としています。 これらのシステムは、膨大な量のデータを分析し、パターンを認識し、予測を行い、有意義な洞察を提供するように設計されています。
コグニティブ コンピューティングは、コンピューターをより人間のように考え、行動させる試みとして考えてください。
これには、人工知能、機械学習、自然言語処理、コンピューター ビジョンなどのテクノロジーを活用して、従来人間の知能に関連付けられていたタスクをコンピューターが実行できるようにすることが含まれます。
36. 計算学習理論
計算学習理論は、人工知能の領域内の専門分野であり、データから学習するように特別に設計されたアルゴリズムの開発と検証を中心に展開します。
この分野では、大量の情報を分析および処理することで自律的にパフォーマンスを向上できるアルゴリズムを構築するためのさまざまな技術と方法論を研究します。
計算学習理論は、データの力を活用することで、機械の意思決定能力を強化し、タスクをより効率的に実行できるようにするパターン、関係性、洞察を明らかにすることを目的としています。
最終的な目標は、曝露されたデータに基づいて適応、一般化、正確な予測を行うことができるアルゴリズムを作成し、人工知能とその実用化の進歩に貢献することです。
37.チューリングテスト
チューリング テストは、優秀な数学者でコンピューター科学者のアラン チューリングによって元々提案されたもので、機械が人間と同等の、または実質的に区別できない知的な動作を示すことができるかどうかを評価するために使用される魅力的な概念です。
チューリング テストでは、人間の評価者は、どちらが機械であるかを知らずに、機械と別の人間の参加者の両方と自然言語で会話します。
評価者の役割は、応答のみに基づいてどのエンティティがマシンであるかを識別することです。 機械が人間に相当するものであると評価者に納得させることができれば、その機械はチューリングテストに合格したと言われ、それによって人間のような能力を反映するレベルの知能を実証することになります。
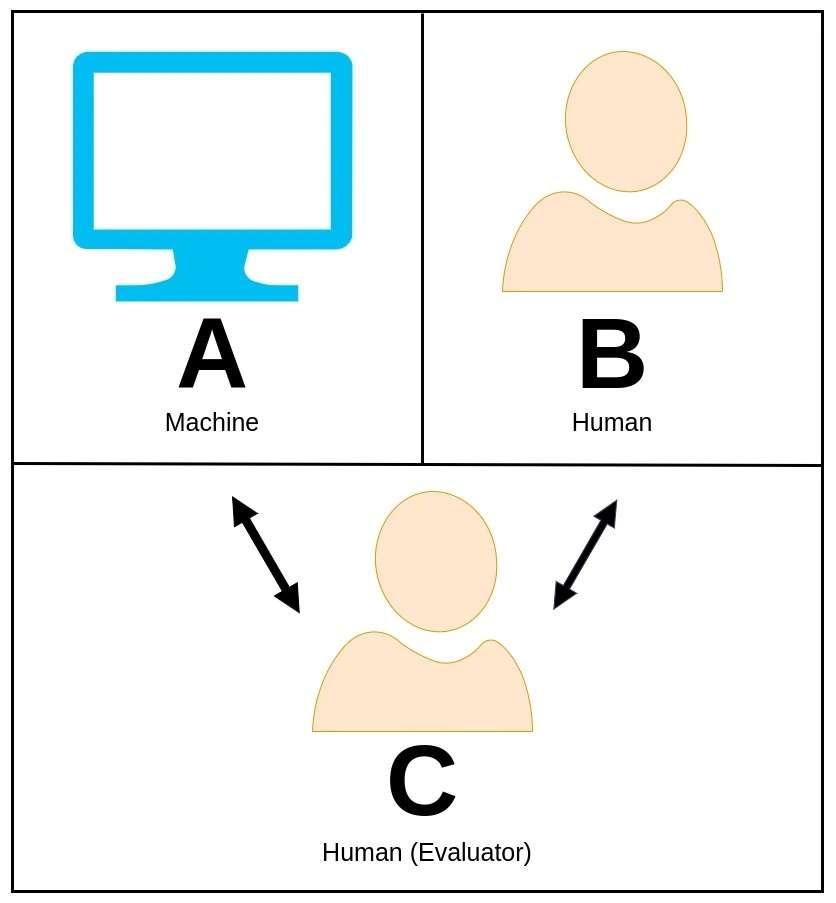
アラン・チューリングは、機械知能の概念を探求し、機械が人間レベルの認識を達成できるかどうかという問題を提起する手段としてこのテストを提案しました。
チューリングは、人間の見分けがつかないという観点からテストを組み立てることで、機械が人間と区別することが困難になるほど、説得力のある知的な動作を示す可能性を強調しました。
チューリング テストは、人工知能と認知科学の分野で広範な議論と研究を引き起こしました。 チューリング テストに合格することは重要なマイルストーンであることに変わりはありませんが、それだけが知性の唯一の尺度ではありません。
それにもかかわらず、このテストは示唆に富むベンチマークとして機能し、人間のような知能と行動をエミュレートできるマシンを開発する継続的な取り組みを刺激し、知的であるとはどういうことかをより広範に探求することに貢献します。
38.強化学習
強化学習 これは、試行錯誤を通じて起こる一種の学習であり、「エージェント」(コンピュータ プログラムまたはロボット)が、良い行動に対して報酬を受け取り、悪い行動に対する結果や罰に直面することで、タスクの実行方法を学習します。
エージェントが迷路の移動などの特定のタスクを完了しようとしているシナリオを想像してください。 最初、エージェントは取るべき正しいパスがわからないため、さまざまなアクションを試し、さまざまなルートを探索します。
目標に近づくための良い行動を選択すると、仮想的な「背中をたたく」ような報酬を受け取ります。 ただし、間違った判断を下して行き詰まったり、目標から遠ざけたりすると、罰や否定的なフィードバックが与えられます。
この試行錯誤のプロセスを通じて、エージェントは特定のアクションをプラスまたはマイナスの結果に関連付けることを学習します。 報酬を最大化し、罰を最小限に抑えるための最適な一連の行動を徐々に見つけ出し、最終的にはそのタスクに習熟していきます。
強化学習は、人間や動物が環境からフィードバックを受けて学習する方法からインスピレーションを得ています。
この概念を機械に適用することで、研究者は、ポジティブな強化とネガティブな結果のプロセスを通じて最も効果的な動作を自律的に発見することで、さまざまな状況を学習して適応できるインテリジェント システムの開発を目指しています。
39. エンティティの抽出
エンティティ抽出とは、テキストのブロックからエンティティとして知られる重要な情報を識別して抽出するプロセスを指します。 これらのエンティティには、人名、場所名、組織名など、さまざまなものが含まれます。
ニュース記事を説明する段落があると想像してみましょう。
エンティティの抽出には、テキストを分析し、別個のエンティティを表す特定のビットを抽出することが含まれます。 たとえば、テキストに「ジョン スミス」などの人の名前、「ニューヨーク市」という場所、または「OpenAI」という組織が記載されている場合、これらが識別して抽出することを目的とするエンティティになります。
エンティティ抽出を実行することにより、本質的に、コンピュータ プログラムにテキストから重要な要素を認識して分離するよう教えていることになります。 このプロセスにより、情報をより効率的に整理および分類できるようになり、大量のテキスト データから検索、分析、洞察を導き出すことが容易になります。
全体として、エンティティ抽出は、テキスト内の人、場所、組織などの重要なエンティティを正確に特定するタスクを自動化し、貴重な情報の抽出を合理化し、テキスト データを処理して理解する能力を強化するのに役立ちます。
40. 言語注釈
言語注釈には、使用されている言語の理解と分析を強化するために、追加の言語情報でテキストを強化することが含まれます。 これは、テキストのさまざまな部分に役立つラベルやタグを追加するようなものです。
言語注釈を実行するときは、テキスト内の基本的な単語や文章を超えて、特定の要素にラベル付けまたはタグ付けを開始します。 たとえば、各単語の文法カテゴリ (名詞、動詞、形容詞など) を示す品詞タグを追加する場合があります。 これは、文の中で各単語が果たす役割を理解するのに役立ちます。
言語注釈の別の形式は名前付きエンティティ認識です。これでは、人、場所、組織、日付の名前など、特定の名前付きエンティティを識別してラベルを付けます。 これにより、テキストから重要な情報をすばやく見つけて抽出することができます。
このような方法でテキストに注釈を付けることで、より構造化され、体系化された言語表現が作成されます。 これは、さまざまなアプリケーションで非常に役立ちます。 たとえば、ユーザーのクエリの背後にある意図を理解することで、検索エンジンの精度を向上させるのに役立ちます。 また、機械翻訳、感情分析、情報抽出、その他多くの自然言語処理タスクにも役立ちます。
言語注釈は、研究者、言語学者、開発者にとって重要なツールとして機能し、言語パターンを研究し、言語モデルを構築し、テキストをより適切に分析して理解できる高度なアルゴリズムを開発できるようにします。
41. ハイパーパラメータ
In 機械学習、ハイパーパラメータは、モデルをトレーニングする前に決定する必要がある特別な設定または構成のようなものです。 これはモデルがデータから独自に学習できるものではありません。 代わりに、事前に決定する必要があります。
これは、モデルがどのように学習して予測を行うかを微調整するために調整できるノブまたはスイッチと考えてください。 これらのハイパーパラメータは、モデルの複雑さ、トレーニングの速度、精度と一般化の間のトレードオフなど、学習プロセスのさまざまな側面を制御します。
たとえば、ニューラル ネットワークを考えてみましょう。 重要なハイパーパラメータの XNUMX つは、ネットワーク内の層の数です。 ネットワークの深さを選択する必要があり、この決定はデータ内の複雑なパターンをキャプチャする能力に影響します。
その他の一般的なハイパーパラメータには、モデルがトレーニング データに基づいて内部パラメータを調整する速度を決定する学習率や、過学習を防ぐためにモデルが複雑なパターンにどの程度ペナルティを与えるかを制御する正則化強度が含まれます。
これらのハイパーパラメータはモデルのパフォーマンスと動作に大きな影響を与える可能性があるため、これらのハイパーパラメータを正しく設定することが重要です。 多くの場合、さまざまな値を試して、それらの値が検証データセット上のモデルのパフォーマンスにどのような影響を与えるかを観察する、多少の試行錯誤が必要になります。
42.メタデータ
メタデータは、他のデータに関する詳細を提供する追加情報を指します。 これは、より多くのコンテキストを提供したり、メイン データの特性を説明したりする一連のタグやラベルのようなものです。
データが文書、写真、ビデオ、またはその他の種類の情報である場合、メタデータはそのデータの重要な側面を理解するのに役立ちます。
たとえば、ドキュメントのメタデータには、作成者の名前、作成日、ファイル形式などの詳細が含まれる場合があります。 写真の場合、メタデータにより、撮影された場所、使用されたカメラの設定、さらには撮影日時がわかる場合があります。
メタデータは、データをより効果的に整理、検索、解釈するのに役立ちます。 これらの説明的な情報を追加すると、コンテンツ全体を調べなくても、特定のファイルをすばやく見つけたり、その出所、目的、コンテキストを理解したりできます。
43.次元削減
次元削減は、データセットに含まれるフィーチャまたは変数の数を減らすことによってデータセットを単純化するために使用される手法です。 これは、データセット内の情報を圧縮または要約して、管理しやすく、操作しやすくするようなものです。
データ ポイントのさまざまな特性を表す多数の列または属性を含むデータセットがあると想像してください。 各列により、機械学習アルゴリズムの複雑さと計算要件が増加します。
場合によっては、次元の数が多いと、データ内で意味のあるパターンや関係を見つけることが困難になることがあります。
次元削減は、可能な限り多くの関連情報を保持しながら、データセットを低次元表現に変換することで、この問題に対処するのに役立ちます。 冗長な次元やあまり有益でない次元を破棄しながら、データの最も重要な側面や変化を捕捉することを目的としています。
44.テキスト分類
テキスト分類は、内容や意味に基づいてテキストのブロックに特定のラベルやカテゴリを割り当てるプロセスです。 これは、さらなる分析や意思決定を容易にするために、テキスト情報をさまざまなグループやクラスに分類または整理するようなものです。
電子メールの分類の例を考えてみましょう。 このシナリオでは、受信電子メールがスパムであるか、非スパム (ハムとも呼ばれます) であるかを判断したいと考えています。 テキスト分類 アルゴリズムは電子メールの内容を分析し、それに応じてラベルを割り当てます。
電子メールがスパムに一般的に関連付けられる特徴を示しているとアルゴリズムが判断した場合、「スパム」というラベルが割り当てられます。 逆に、電子メールが正当でスパムではないと思われる場合は、「非スパム」または「ハム」というラベルが割り当てられます。
テキスト分類は、電子メール フィルタリングを超えて、さまざまなドメインのアプリケーションを検出します。 これは、顧客レビューで表現された感情 (肯定的、否定的、または中立的) を判断するための感情分析に使用されます。
ニュース記事は、スポーツ、政治、エンターテイメントなど、さまざまなトピックやカテゴリに分類できます。 カスタマー サポートのチャット ログは、対処する目的や問題に基づいて分類できます。
45. 弱いAI
弱い AI は、ナロー AI とも呼ばれ、特定のタスクや機能を実行するように設計およびプログラムされた人工知能システムを指します。 幅広い認知能力を含む人間の知能とは異なり、弱い AI は特定の領域またはタスクに限定されます。
弱い AI は、特定の仕事の実行に優れた特殊なソフトウェアまたは機械であると考えてください。 たとえば、チェスをプレイする AI プログラムは、ゲーム状況を分析し、手を戦略化し、人間のプレイヤーと競争するために作成される可能性があります。
別の例は、写真やビデオ内のオブジェクトを識別できる画像認識システムです。
これらの AI システムは、特定の専門分野で優れた性能を発揮できるようにトレーニングされ、最適化されています。 彼らはアルゴリズム、データ、事前定義されたルールに依存してタスクを効率的に実行します。
しかし、彼らは、指定された領域外のタスクを理解したり実行したりできる一般的な知性を持っていません。
46. 強力なAI
汎用 AI または人工汎用知能 (AGI) とも呼ばれる強力な AI は、人間が可能なあらゆる知的タスクを理解し、学習し、実行する能力を備えた人工知能の一種を指します。
特定のタスク向けに設計された弱い AI とは異なり、強力な AI は人間のような知能と認知能力を再現することを目的としています。 専門的なタスクに優れているだけでなく、幅広い知的課題に取り組むためのより広い理解と適応力を備えた機械やソフトウェアを作成することを目指しています。
強力な AI の目標は、推論し、複雑な情報を理解し、経験から学習し、自然言語で会話し、創造性を発揮し、人間の知性に関連するその他の性質を発揮できるシステムを開発することです。
本質的には、人間レベルの思考と問題解決を複数の領域にわたってシミュレートまたは複製できる AI システムの作成を目指しています。
47. フォワードチェーン
フォワードチェーンは、利用可能なデータから開始し、それを使用して推論を行い、新しい結論を導き出す推論またはロジックの方法です。 それは、手元にある情報を使用して点と点を結び、前進し、さらなる洞察に到達するようなものです。
一連のルールまたは事実があり、それらに基づいて新しい情報を導き出すか、特定の結論に達したいと想像してください。 順方向連鎖は、初期データを調べ、論理ルールを適用して追加の事実や結論を生成することによって機能します。
単純化するために、気象条件に基づいて何を着るかを決定するという単純なシナリオを考えてみましょう。 「雨が降っている場合は傘を持ってください」というルールと、「寒ければ上着を着てください」というルールがあります。 ここで、実際に雨が降っていることを観察した場合、前方連鎖を使用して、傘を持っていくべきであると推測できます。
48. 後方連鎖
逆方向連鎖は、望ましい結論または目標から始めて、その結論を裏付けるために必要なデータまたは事実を決定するために逆方向に作業する推論方法です。 これは、望ましい結果から、それを達成するために必要な最初の情報までの手順をたどるようなものです。
逆方向連鎖を理解するために、簡単な例を考えてみましょう。 水泳に行くのが適切かどうかを判断したいとします。 望ましい結論は、特定の条件に基づいて水泳が適切かどうかです。
逆方向連鎖は条件から始めるのではなく、結論から始まり、逆方向に作業して裏付けとなるデータを見つけます。
この場合、後方連鎖には、「天気は暖かいですか?」などの質問が含まれます。 答えが「はい」の場合は、「利用可能なプールはありますか?」と尋ねます。 答えが再び「はい」の場合は、「泳ぎに行くのに十分な時間はありますか?」など、さらに質問します。
これらの質問に繰り返し答えて逆算することで、水泳に行くという結論を裏付けるために満たす必要がある必要な条件を判断できます。
49.ヒューリスティック
ヒューリスティックとは、簡単に言うと、通常は過去の経験や直感に基づいて意思決定をしたり問題を解決したりするのに役立つ実用的なルールまたは戦略です。 これは、時間のかかる徹底的なプロセスを経ることなく、合理的な解決策をすぐに思いつくことを可能にする精神的なショートカットのようなものです。
複雑な状況やタスクに直面したとき、ヒューリスティックは意思決定を簡素化する指針または「経験則」として機能します。 これらは、最適な解決策を保証するものではない場合でも、特定の状況で効果的な一般的なガイドラインや戦略を提供します。
たとえば、混雑したエリアで駐車スポットを見つけるためのヒューリスティックを考えてみましょう。 利用可能なすべてのスポットを注意深く分析する代わりに、エンジンがかかっている駐車中の車を探すヒューリスティックに頼ることもできます。
このヒューリスティックでは、これらの車が出発しようとしていると想定しており、空いている場所を見つける可能性が高くなります。
50. 自然言語モデリング
自然言語モデリングとは、簡単に言えば、人間のコミュニケーションと同じような方法で人間の言語を理解し、生成できるようにコンピューター モデルをトレーニングするプロセスです。 これには、自然かつ意味のある方法でテキストを処理、解釈、生成するようにコンピューターを教えることが含まれます。
自然言語モデリングの目標は、コンピューターが流暢で一貫性があり、文脈に関連した方法で人間の言語を理解して生成できるようにすることです。
これには、書籍、記事、会話などの膨大な量のテキスト データを使用してモデルをトレーニングし、言語のパターン、構造、意味論を学習することが含まれます。
これらのモデルは、トレーニングが完了すると、言語翻訳、テキストの要約、質問応答、チャットボットの対話など、さまざまな言語関連のタスクを実行できるようになります。
文の意味と文脈を理解し、関連情報を抽出し、文法的に正しく一貫性のあるテキストを生成できます。





コメントを残す