A videojátékok továbbra is kihívást jelentenek játékosok milliárdjai számára szerte a világon. Lehet, hogy még nem tudja, de a gépi tanulási algoritmusok is elkezdtek megfelelni a kihívásoknak.
Jelenleg jelentős mennyiségű kutatás folyik a mesterséges intelligencia területén annak kiderítésére, hogy a gépi tanulási módszerek alkalmazhatók-e a videojátékokra. Az e téren elért jelentős előrelépés ezt mutatja gépi tanulás ügynökök használhatók az emberi játékos emulálására vagy akár helyettesítésére.
Mit jelent ez a jövőre nézve videojátékok?
Ezek a projektek pusztán szórakozásból állnak, vagy mélyebb okai vannak annak, hogy oly sok kutató a játékokra összpontosít?
Ez a cikk röviden feltárja a mesterséges intelligencia történetét a videojátékokban. Ezt követően rövid áttekintést adunk néhány gépi tanulási technikáról, amelyek segítségével megtanulhatjuk, hogyan kell legyőzni a játékokat. Ezután megvizsgálunk néhány sikeres alkalmazást ideghálók konkrét videojátékok megtanulására és elsajátítására.
Az AI rövid története a játékokban
Mielőtt rátérnénk arra, hogy miért váltak a neurális hálók ideális algoritmusokká a videojátékok megoldására, nézzük meg röviden, hogyan használták fel az informatikusok a videojátékokat a mesterséges intelligencia területén végzett kutatásaik előmozdítására.
Vitatkozhat azzal, hogy a videojátékok a kezdetektől fogva az AI iránt érdeklődő kutatók forró kutatási területei voltak.
Bár eredetileg nem kifejezetten videojáték, a sakk az AI korai napjaiban nagy hangsúlyt kapott. 1951-ben Dr. Dietrich Prinz sakkjátékot írt a Ferranti Mark 1 digitális számítógéppel. Ez még abban a korban volt, amikor ezeknek a terjedelmes számítógépeknek papírszalagról kellett leolvasniuk a programokat.

Maga a program nem volt egy teljes sakk AI. A számítógép korlátai miatt Prinz csak olyan programot tudott létrehozni, amely megoldotta a „mate a kettőben” sakkproblémákat. Átlagosan 15-20 percet vett igénybe a program, hogy kiszámítsa a fehér és fekete játékosok minden lehetséges lépését.
A sakk és dáma mesterséges intelligencia fejlesztésére irányuló munka az évtizedek során folyamatosan fejlődött. A fejlődés 1997-ben érte el tetőpontját, amikor az IBM Deep Blue csapata hat játszmából álló párosban legyőzte Garri Kaszparov orosz sakknagymestert. Manapság a mobiltelefonján megtalálható sakkmotorok legyőzhetik a Deep Blue-t.
A mesterséges intelligencia ellenzői a video arcade játékok aranykorában kezdtek egyre népszerűbbek lenni. Az 1978-as Space Invaders és az 1980-as évek Pac-Manja az iparág úttörői közé tartozik a mesterséges intelligencia megalkotásában, amely még a legveteránabb játéktermi játékosokat is megfelelő kihívás elé állítja.
A Pac-Man különösen népszerű játék volt az AI-kutatók számára, akikkel kísérleteztek. Különféle versenyek A Ms. Pac-Man számára megszervezték, hogy meghatározzák, melyik csapat tudja a legjobb mesterséges intelligenciát kitalálni a játék legyőzéséhez.
A játék mesterséges intelligencia és a heurisztikus algoritmusok tovább fejlődtek, ahogy egyre okosabb ellenfelekre volt szükség. Például a harci mesterséges intelligencia népszerűsége megnőtt, amikor az olyan műfajok, mint az első személyű lövöldözős játékok, egyre általánosabbá váltak.
Gépi tanulás a videojátékokban
Ahogy a gépi tanulási technikák gyorsan népszerűvé váltak, különböző kutatási projektek próbálták ezeket az új technikákat videojátékok lejátszására használni.
Az olyan játékok, mint a Dota 2, a StarCraft és a Doom problémákat okozhatnak ezeknél gépi tanulási algoritmusok megoldani. Mélytanulási algoritmusok, különösen képesek voltak emberi szintű teljesítményt elérni, sőt meg is haladni.
A Arcade tanulási környezet vagy az ALE több mint száz Atari 2600 játékhoz adott felületet a kutatóknak. A nyílt forráskódú platform lehetővé tette a kutatók számára, hogy összehasonlítsák a gépi tanulási technikák teljesítményét a klasszikus Atari videojátékokon. A Google még a sajátját is közzétette papír hét játékot használ az ALE-ből

Eközben olyan projektek, mint VizDoom lehetőséget adott az AI-kutatóknak, hogy gépi tanulási algoritmusokat képezzenek ki 3D első személyű lövöldözős játékokhoz.

Hogyan működik: néhány kulcsfogalom
Neurális hálózatok
A videojátékok gépi tanulással történő megoldásának legtöbb megközelítése egyfajta neurális hálózatot foglal magában.
A neurális hálót egy olyan programnak tekintheti, amely megpróbálja utánozni az agy működését. Hasonlóan ahhoz, ahogy agyunk jeleket továbbító neuronokból áll, az idegháló is tartalmaz mesterséges neuronokat.
Ezek a mesterséges neuronok jeleket is továbbítanak egymásnak, minden jel tényleges szám. A neurális háló több réteget tartalmaz a bemeneti és kimeneti rétegek között, ezeket mély neurális hálózatnak nevezzük.
Erősítő tanulás
Egy másik gyakori gépi tanulási technika, amely releváns a videojátékok tanulásában, a megerősítő tanulás ötlete.
Ez a technika az ügynök képzésének folyamata jutalom vagy büntetés segítségével. Ezzel a megközelítéssel az ügynöknek képesnek kell lennie arra, hogy próba és hiba útján megoldást találjon a problémára.
Tegyük fel, hogy azt szeretnénk, hogy egy mesterséges intelligencia megtudja, hogyan kell játszani a Snake játékot. A játék célja egyszerű: szerezzen minél több pontot tárgyak elfogyasztásával és a növekvő farok elkerülésével.
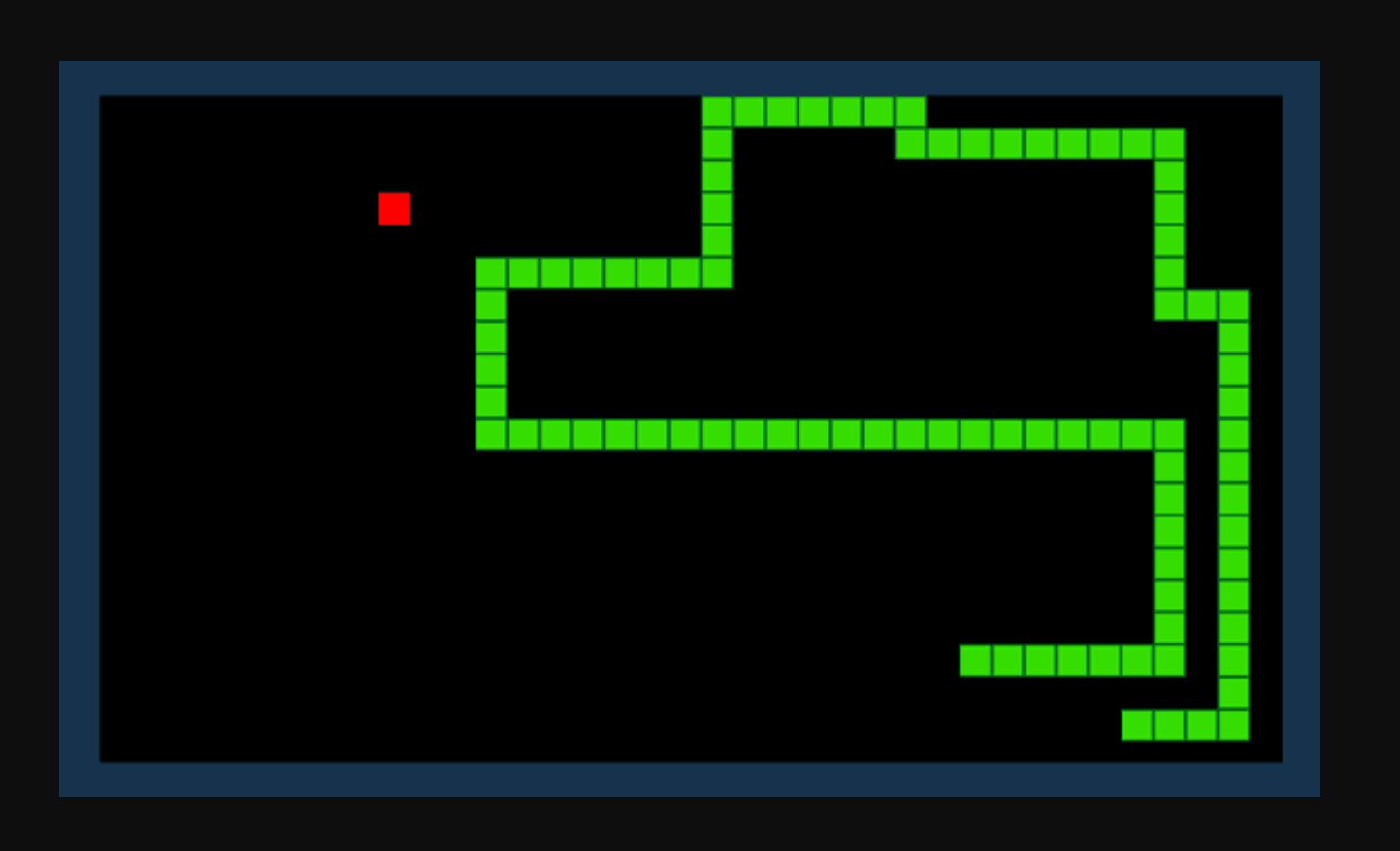
Megerősítő tanulással definiálhatunk egy R jutalmazási függvényt. A függvény pontokat ad hozzá, ha egy kígyó elfogyaszt egy tárgyat, és pontokat von le, ha a kígyó akadályba ütközik. Tekintettel a jelenlegi környezetre és a lehetséges cselekvésekre, a megerősítő tanulási modellünk megpróbálja kiszámítani az optimális „politikát”, amely maximalizálja jutalmazási funkciónkat.
Neuroevolúció
A természet ihletésének témája mellett a kutatók az ML videojátékokban való alkalmazásában is sikert értek el a neuroevolúció néven ismert technikával.
Használat helyett gradiens süllyedés a hálózat neuronjainak frissítéséhez evolúciós algoritmusokat használhatunk jobb eredmények elérése érdekében.
Az evolúciós algoritmusok általában véletlenszerű egyedek kezdeti populációjának generálásával kezdődnek. Ezután bizonyos kritériumok alapján értékeljük ezeket a személyeket. A legjobb egyedeket „szülőnek” választják, és együtt tenyésztik az egyedek új generációját. Ezek az egyedek azután felváltják a populáció legkevésbé fitt egyedeit.
Ezek az algoritmusok általában bevezetnek valamilyen mutációs műveletet a keresztezési vagy „tenyésztési” lépés során a genetikai sokféleség fenntartása érdekében.
Mintakutatás a gépi tanulásról a videojátékokban
OpenAI Five

OpenAI Five az OpenAI számítógépes programja, amelynek célja a DOTA 2, egy népszerű többjátékos mobil harcaréna (MOBA) játék.
A program a meglévő megerősítő tanulási technikákat használta, amelyeket úgy méreteztek, hogy másodpercenként több millió képkockából tanuljanak. Az elosztott képzési rendszernek köszönhetően az OpenAI naponta 180 évnyi játékot tudott játszani.
Az edzési időszak után az OpenAI Five szakértői szintű teljesítményt tudott elérni és humán játékosokkal való együttműködést mutatott be. 2019-ben az OpenAI öt képes volt rá vereség A játékosok 99.4%-a nyilvános meccseken.
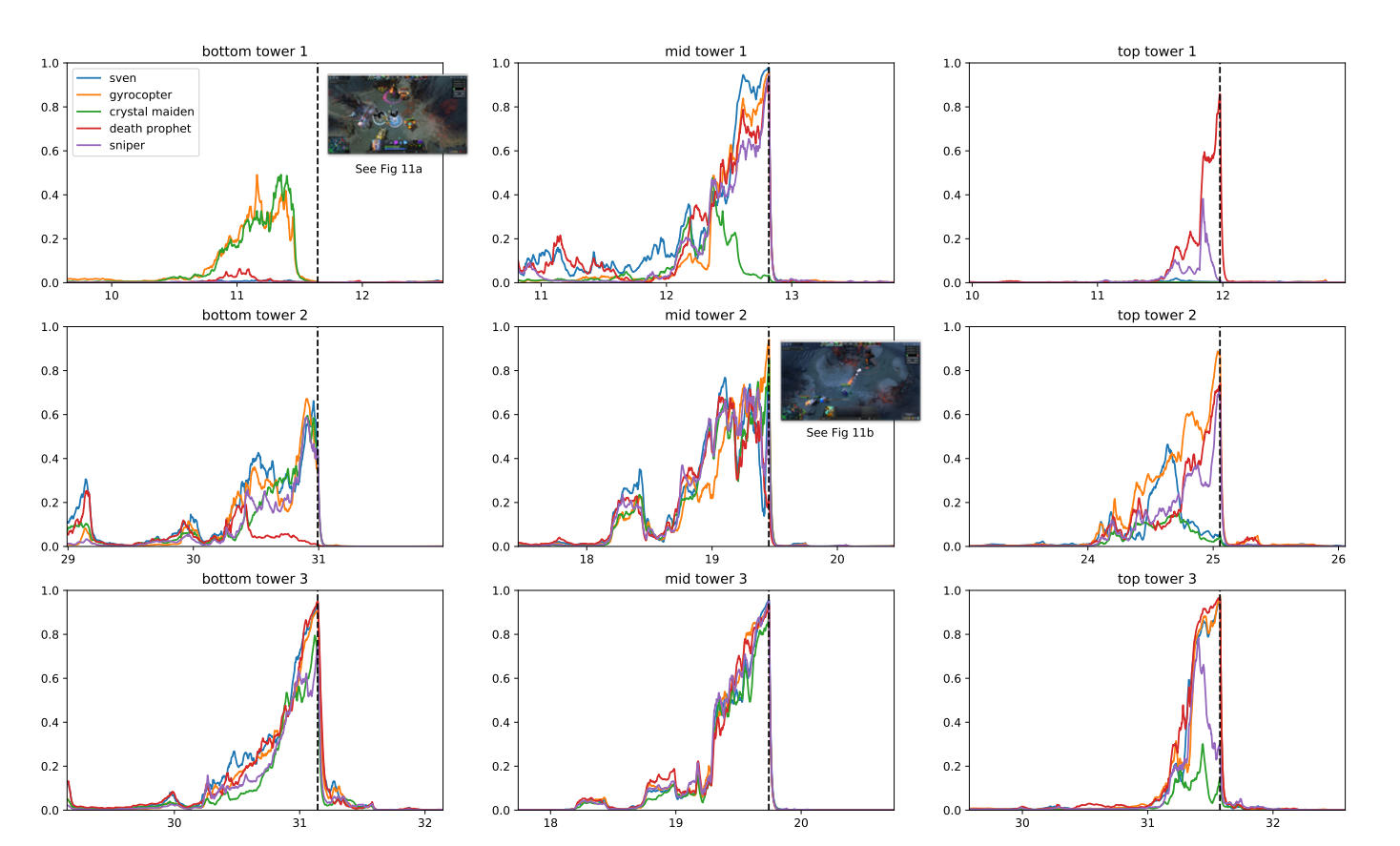
Miért döntött az OpenAI mellett ez a játék? A kutatók szerint a DOTA 2 olyan összetett mechanikával rendelkezett, amely kívül esik a meglévő mélység hatókörén megerősítő tanulás algoritmusok.
Super Mario Bros.
A neurális hálók másik érdekes alkalmazása a videojátékokban a neuroevolúció alkalmazása platformerek, például a Super Mario Bros.
Például ez hackathon belépő azzal kezdődik, hogy nem ismeri a játékot, és lassan felépíti az alapot annak, ami egy szinten való továbblépéshez szükséges.
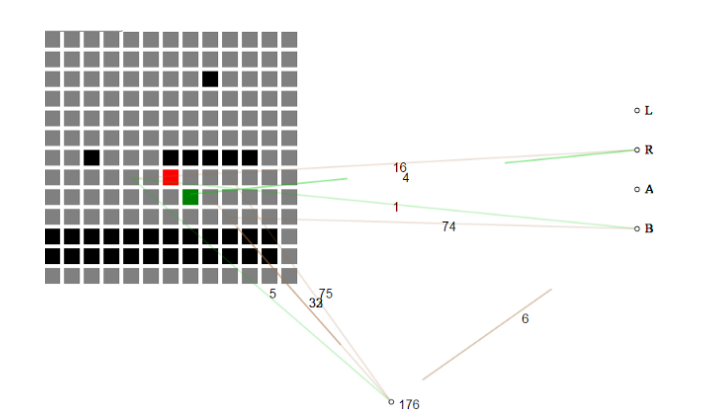
Az önfejlődő neurális háló a játék jelenlegi állapotát lapkákból álló rácsként veszi fel. Eleinte a neurális háló nem érti az egyes lapkák jelentését, csak azt, hogy a „levegő” lapkák különböznek a „földlapkáktól” és az „ellenséglapkáktól”.
A hackathon projektben egy neuroevolúció megvalósítása a NEAT genetikai algoritmust használta különböző neurális hálók szelektív tenyésztésére.
Fontosság
Most, hogy láttál néhány példát a neurális hálókra, amelyek videojátékokat játszanak, felmerülhet benned, hogy mi értelme ennek az egésznek.
Mivel a videojátékok összetett interakciókat foglalnak magukban az ügynökök és a környezetük között, tökéletes tesztelési terepet jelent az AI készítéséhez. A virtuális környezetek biztonságosak és ellenőrizhetők, és végtelen adatellátást biztosítanak.
Az ezen a területen végzett kutatások betekintést engedtek a kutatóknak abba, hogyan lehet a neurális hálókat optimalizálni, hogy megtanulják, hogyan kell megoldani a való világban felmerülő problémákat.
Neurális hálózatok az agy természetes világban való működése ihlette. Ha megvizsgáljuk, hogyan viselkednek a mesterséges neuronok, amikor megtanulnak játszani videojátékokkal, betekintést nyerhetünk abba is, emberi agy működik.
Következtetés
A neurális hálózatok és az agy közötti hasonlóságok mindkét területen meglátásokhoz vezettek. A folyamatos kutatás arra vonatkozóan, hogy a neurális hálók hogyan oldhatják meg a problémákat, egy nap a problémák fejlettebb formáihoz vezethetnek mesterséges intelligencia.
Képzeljen el egy olyan mesterséges intelligenciát, amely az Ön specifikációira szabott, és képes lejátszani egy teljes videojátékot a vásárlás előtt, hogy tudassa, megéri-e rászánni az időt. A videojáték-cégek neurális hálókat használnának a játéktervezés, a beállítási szint és az ellenfél nehézségeinek javítására?
Mit gondolsz, mi fog történni, ha a neurális hálók lesznek a legjobb játékosok?





Hagy egy Válaszol