O movemento e o almacenamento de datos creceron en importancia como resultado da constante expansión da industria de TI e dos millóns de puntos de datos que se producen cada segundo.
Ademais, estes datos deben ser claros e sinxelos de comprender para apoiar a toma de decisións precisas.
Para manter a competitividade e acadar o éxito a longo prazo, a súa empresa debe almacenar e mover datos utilizando as solucións máis eficientes dispoñibles.
Debido a isto, máis empresas están a utilizar tecidos de datos. Unha das mellores formas de conservar o teu tempo, diñeiro e recursos é usar un tecido de datos para procesar datos e habilitar a aprendizaxe automática da intelixencia artificial.
Neste artigo, analizaremos en profundidade Data Fabric, incluíndo os seus usos, compoñentes principais, vantaxes e outros detalles vitais.
Entón, que é Data Fabric?
Independentemente de onde se atopen, xestiona e supervisa os teus datos e aplicacións. Na súa esencia, un tecido de datos é unha arquitectura de datos integrada que é segura, versátil e adaptable.
Un tecido de datos, que combina o mellor da nube, o núcleo e o borde, é en moitos sentidos un novo enfoque estratéxico para a operación de almacenamento da túa empresa.
Aínda que está controlado de forma centralizada, pode chegar a todas partes, incluíndo nubes locais, públicas e privadas, así como dispositivos de borde e IoT.
Os silos de datos do tamaño de rañaceos e infraestruturas diversas e sen conexión son cousa do pasado. Un tecido de datos baséase nunha colección completa de ferramentas de xestión de datos que garanten a coherencia nos seus contornos vinculados.
A través da automatización, axiliza a xestión que leva tempo, acelera o desenvolvemento, as probas e a implantación e protexe os teus activos durante todo o día.
Non importa onde estean os teus datos e aplicacións, podes rastrexar os gastos de almacenamento, o rendemento e a eficiencia desde unha única plataforma.
Podes facer cambios rapidamente (e, nalgúns casos, automaticamente) na túa infraestrutura de nube híbrida unha vez que teñas coñecementos prácticos sobre ela, como corrixir erros, solucionar problemas de seguridade e cumprimento e aumentar e baixar a escala da computación.
En resumo, Data Fabric mellora o despregamento da infraestrutura e a eficiencia do mantemento, reduce os custos e aumenta o rendemento.
Por que deberías usar un Data Fabric?
Calquera empresa centrada en datos necesita unha estratexia integral que supere obstáculos como o tempo, o espazo, varios tipos de software e a localización dos datos. Os datos non deben estar escondidos detrás de firewalls nin dispersos en varios lugares, senón que deben estar dispoñibles para as persoas que o precisen.
Para ter éxito, as empresas necesitan unha solución de datos a proba de futuro e un ambiente seguro, eficaz e unificado. Isto pódese facer cun tecido de datos.
As necesidades das empresas modernas de conexión en tempo real, autoservizo, automatización e cambios universais non se poden satisfacer coa integración de datos tradicional.
Aínda que a recompilación de datos de moitas fontes non adoita ser un problema, moitas empresas teñen dificultades para integrar, procesar, curar e transformar datos con datos doutras fontes.
Para dar unha comprensión profunda dos consumidores, socios e bens, debe levarse a cabo este paso crítico no proceso de xestión de datos. Debido á súa capacidade para actualizar os seus sistemas, servir mellor aos clientes e aproveitar computación en nube, as empresas gañan unha vantaxe competitiva como resultado.
Onde queira que estean os usuarios da organización, o tecido de datos pódese imaxinar como un pano que se estende por todo o mundo. Nesta rede, o usuario pode estar en calquera lugar e aínda ter acceso sen restricións e en tempo real aos datos en calquera outro lugar.
Compoñentes fundamentais de Data Fabric
Os compoñentes fundamentais que constitúen un tecido de datos pódense escoller e reunilos de varias maneiras. Así, o tecido de datos pódese implementar de varias maneiras. Vexamos os elementos primarios dun tecido de datos.
- Catálogo de datos aumentados
- Capa de persistencia
- Gráfico de coñecemento
- Motor de información e recomendacións
- Preparación de datos e capa de entrega de datos
- Operacións de orquestración e datos
Podes botar unha ollada aos piares fundamentais da arquitectura Data Fabric segundo Gartner.
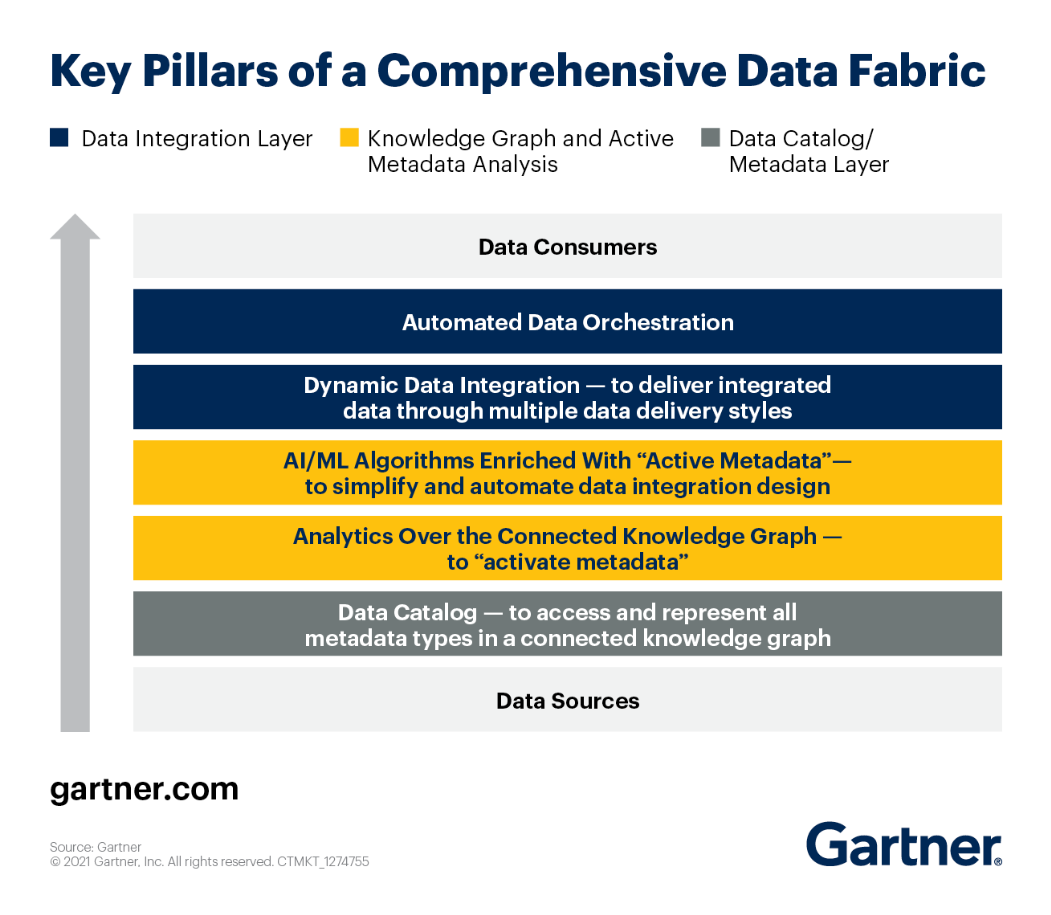
Vexamos cada un deles de preto.
- Catálogo de datos aumentados - ofrece aos usuarios acceso a todo tipo de metadatos mediante un gráfico de coñecemento sólido. Ademais, desenvolve asociacións distintivas entre a información existente e móstraa visualmente de forma comprensible. Mediante o uso aprendizaxe de máquina para vincular os recursos de datos coa terminoloxía organizativa, os catálogos de datos mellorados crean a capa semántica empresarial para o tecido de datos.
- Capa de persistencia – Segundo o caso de uso, pódense utilizar unha variedade de modelos relacionais e non relacionais para almacenar datos de forma dinámica.
- Metadatos activos – unha parte distintiva dun tecido de datos. dá ao tecido de datos a capacidade de reunir, compartir e analizar moitos tipos de metadatos. En contraste cos metadatos pasivos, os metadatos activos rastrexan o uso continuo dos datos por parte dos sistemas e as persoas (metadatos baseados no deseño e en tempo de execución).
- Gráfico de coñecemento – Outra unidade fundamental para os tecidos de datos. Usan ID estándar, esquemas adaptables, etc. para mostrar un entorno de datos vinculados. Os gráficos de coñecemento fan que o tecido de datos sexa buscable e axudan na súa comprensión.
- Insights e motor de recomendacións – crea canalizacións de datos fiables e sólidas para casos de uso operativos e analíticos.
- Preparación de datos e capa de entrega de datos – Os datos pódense recuperar de calquera fonte e enviarse a calquera destino mediante calquera mecanismo, incluíndo ETL (a granel), mensaxería, CDC, virtualización e API.
- Operacións de orquestración e datos – Este compoñente utiliza datos para coordinar todas as tarefas en cada etapa do fluxo de traballo de extremo a extremo. Permítelle escoller cando e con que frecuencia executar canalizacións, así como como xestionar os datos que producen esas canalizacións.
Beneficios
Os datos saudables nun contexto distribuído son accesibles, cargados, integrados e compartidos nun tecido de datos. Ao facelo, as empresas poden acelerar a transición dixital e maximizar o valor dos seus datos.
A continuación descríbense as principais vantaxes do modelo de tecido de datos.
eficiencia:
Un tecido de datos pode compilar resultados de consultas anteriores, o que permite ao sistema escanear a táboa agregada en lugar dos datos brutos do backend.
Debido aos tempos de resposta máis rápidos das solicitudes individuais, permitir que as solicitudes accedan a conxuntos de datos máis pequenos en lugar de ter que escanear os datos en bruto da tenda completa tamén resolve o problema de varias solicitudes simultáneas.
As empresas poden responder rapidamente ás consultas urxentes debido á capacidade do tecido de datos para reducir significativamente os tempos de resposta ás consultas.
Integración intelixente
Para integrar datos en diversos tipos de datos e puntos finais, os tecidos de datos fan uso de gráficos de coñecemento semántico, xestión de metadatos e aprendizaxe automática.
Isto axuda aos equipos de xestión de datos a agrupar conxuntos de datos relevantes e incorporar fontes de datos novas ao ecosistema de datos dunha empresa.
Esta función automatiza partes da xestión de tarefas de datos, o que resulta no aforro de produtividade indicado anteriormente, pero tamén axuda a romper os silos do sistema de datos, a centralizar os procedementos de goberno dos datos e a mellorar a calidade xeral dos datos.
Seguridade de datos máis eficaz
Tampouco implica sacrificar a seguridade dos datos e as proteccións da privacidade en aras de ampliar o acceso aos datos.
De feito, require o endurecemento das barandillas de control de acceso e a implementación de máis medidas de goberno de datos para garantir que determinados roles sexan os únicos con acceso a un determinado conxunto de datos.
Ademais, as arquitecturas de tecido de datos permiten técnicas e equipos de seguridade para implementar o enmascaramento de datos e cifrado en torno a información confidencial e sensible, reducindo a probabilidade de compartir datos e de hackear o sistema.
Democratización dos datos
Os deseños de tecido de datos facilitan as aplicacións de autoservizo, que amplían o alcance do acceso aos datos máis aló do persoal máis técnico, como enxeñeiros de datos, desenvolvedores e equipos de análise de datos.
Ao permitir que os usuarios comerciais tomen decisións comerciais máis rápidas e liberando aos usuarios técnicos para que prioricen as actividades que mellor utilicen os seus conxuntos de habilidades, a eliminación dos pescozos de botella de datos leva a un aumento da produtividade.
Casos de uso
Unha arquitectura de tecido de datos pretende ofrecer unha estrutura global para manexar todas as formas da información almacenada para que poidan ser usadas cando sexa necesario.
Este tipo de datos pódense usar para calquera cousa, desde unha predición de vendas ata un informe sobre o estado da infraestrutura de TI dunha organización ou os puntos finais dos usuarios.
Os casos de uso da arquitectura de tecido de datos son idénticos aos casos de uso de calquera outro tipo de datos nunha empresa, incluíndo vendas, marketing, TI, ciberseguridade e moito máis.
Non obstante, os datos nunha organización adoitan estar organizados, semiestruturados ou non estruturados en case todos os casos de uso. Unha base de datos relacional pode almacenar datos estruturados e utilizarse rapidamente, como rexistros de bases de datos.
Os datos que non foron limpados ou categorizados denomínanse datos non estruturados e deben estar preparados para o seu uso cando sexa necesario.
Inclúen varias formas de datos non estruturados que moitas empresas poden adquirir e almacenar para o seu uso futuro aprendizaxe de máquina, análises, datos de sensores, computación en nube e aplicacións de produtividade.
Nos datos semiestruturados, que inclúen datos dun tipo recoñecido gardados con datos non estruturados (como ficheiros zip, páxinas web e correos electrónicos), ambos os aspectos están presentes.
Pódense atopar numerosos casos de uso posibles baseados na capacidade do tecido de datos para axudar ás empresas a acceder e utilizar os seus datos de forma máis rápida e eficaz investigando o seu uso.
Exemplos típicos inclúen:
- Detección de fraude
- Analítica IoT
- Loxística da cadea de subministración
- Análise de datos en tempo real
- Intelixencia do cliente
- Aumento da eficiencia operativa
- Análise do mantemento preventivo
- Ademais, modelos de risco de retorno ao traballo
- Asegurar transaccións con tarxetas de crédito
- Predición de abandono, detección de fraude e puntuación de crédito
Conclusión
En conclusión, os silos de datos deben desintegrarse progresivamente a medida que aumentan os nosos niveis de uso de datos para deixar espazo ás empresas conectadas.
O despregamento de tecidos de datos representa un avance significativo neste camiño, situándose entre os descubrimentos máis innovadores desde o desenvolvemento das bases de datos relacionais nos anos 1970.
Isto é así porque o tecido de datos é máis que unha tecnoloxía ou un único elemento.
Os datos e as operacións comerciais están intrincadamente entrelazados mediante o deseño da arquitectura, un procedemento sistemático e un cambio de mentalidade.
Data Fabric reduce custos, aumenta o rendemento e facilita a implantación e o mantemento da infraestrutura máis eficaces. Podería ser o compoñente clave para garantir que cada proceso, aplicación e decisión empresarial se baseen en datos.





Deixe unha resposta