Table of Contents[Ferstopje][Toanje]
Wy kinne no de romte fan romte en de minút yngewikkeldheden fan subatomêre dieltsjes berekkenje troch kompjûters.
Kompjûters ferslaan minsken as it giet om tellen en berekkenjen, en ek it folgjen fan logyske ja/nee-prosessen, troch elektroanen dy't reizgje mei de snelheid fan ljocht fia har circuits.
Wy sjogge se lykwols net faak as "yntelligint", om't kompjûters yn it ferline neat koenen útfiere sûnder te learen (programmearre) troch minsken.
Masine learen, ynklusyf djip learen en keunstmjittige yntelliginsje, is in buzzword wurden yn wittenskiplike en technologyske koppen.
Masine learen liket omnipresent te wêzen, mar in protte minsken dy't it wurd brûke soene muoite hawwe om adekwaat te definiearjen wat it is, wat it docht en wêr't it it bêste foar brûkt wurdt.
Dit artikel besiket masine learen te ferdúdlikjen, wylst se ek konkrete, echte foarbylden leverje fan hoe't de technology wurket om te yllustrearjen wêrom't it sa foardielich is.
Dan sille wy de ferskate metoaden foar masine learen besjen en sjen hoe't se wurde brûkt om saaklike útdagings oan te pakken.
Uteinlik sille wy ús kristallen bal rieplachtsje foar wat rappe foarsizzingen oer de takomst fan masine learen.
Wat is masine learen?
Masine learen is in dissipline fan kompjûterwittenskip dy't kompjûters mooglik makket patroanen ôf te lieden út gegevens sûnder eksplisyt te learen wat dy patroanen binne.
Dizze konklúzjes binne faak basearre op it brûken fan algoritmen om automatysk de statistyske skaaimerken fan 'e gegevens te beoardieljen en it ûntwikkeljen fan wiskundige modellen om de relaasje tusken ferskate wearden út te jaan.
Kontrast dit mei klassike berekkenjen, dy't basearre is op deterministyske systemen, wêryn wy de kompjûter eksplisyt in set regels jouwe om te folgjen om in bepaalde taak te dwaan.
Dizze manier fan programmearjen fan kompjûters wurdt bekend as regel-basearre programmearring. Masine learen ferskilt fan en prestearret better as regel-basearre programmearring yn dat it kin ôfliede dizze regels op har eigen.
Stel dat jo in bankmanager binne dy't wol bepale as in lieningsapplikaasje sil mislearje op har liening.
Yn in op regels basearre metoade soe de bankmanager (of oare spesjalisten) de kompjûter útdruklik ynformearje dat as de kredytscore fan de oanfreger ûnder in bepaald nivo leit, de oanfraach moat wurde ôfwiisd.
In programma foar masine-learen soe lykwols gewoan foarôfgeande gegevens analysearje oer klantkredytwurdearrings en lieningsresultaten en bepale wat dizze drompel op himsels moat wêze.
De masine leart fan eardere gegevens en makket op dizze manier har eigen regels. Fansels, dit is mar in primer op masine learen; Echte-wrâld masine-learmodellen binne signifikant yngewikkelder dan in basisdrompel.
Dochs is it in poerbêste demonstraasje fan it potensjeel fan masine learen.
Hoe docht in machine leare?
Om dingen ienfâldich te hâlden, "leare" masines troch patroanen te detektearjen yn fergelykbere gegevens. Beskôgje gegevens as ynformaasje dy't jo sammelje fan 'e bûtenwrâld. Hoe mear gegevens in masine wurdt fied, hoe "tûker" it wurdt.
Lykwols, net alle gegevens binne itselde. Stel dat jo in piraat binne mei in libbensdoel om de begroeven rykdom op it eilân te ûntdekken. Jo sille in substansjele hoemannichte kennis wolle om de priis te finen.
Dizze kennis, lykas gegevens, kin jo op 'e juste of ferkearde manier nimme.
Hoe grutter de ophelle ynformaasje/gegevens, hoe minder ûndúdlikens is, en oarsom. As resultaat is it kritysk om te beskôgjen hokker soarte gegevens jo jo masine fiede om fan te learen.
Ienris in substansjele hoemannichte gegevens wurdt levere, kin de kompjûter lykwols foarsizzings meitsje. Masines kinne de takomst antisipearje salang't dy net folle ôfwykt fan it ferline.
Masines "leare" troch analysearjen fan histoaryske gegevens om te bepalen wat wierskynlik sil barre.
As de âlde gegevens lykje op de nije gegevens, dan binne de dingen dy't jo kinne sizze oer de foarige gegevens wierskynlik jilde foar de nije gegevens. It is as sjochst werom om foarút te sjen.
Wat binne de soarten masine learen?
Algoritmen foar masine learen wurde faak yndield yn trije brede soarten (hoewol oare klassifikaasjeskema's wurde ek brûkt):
- Tafersjoch op learen
- Sûnder learen learen
- Fersterking learen
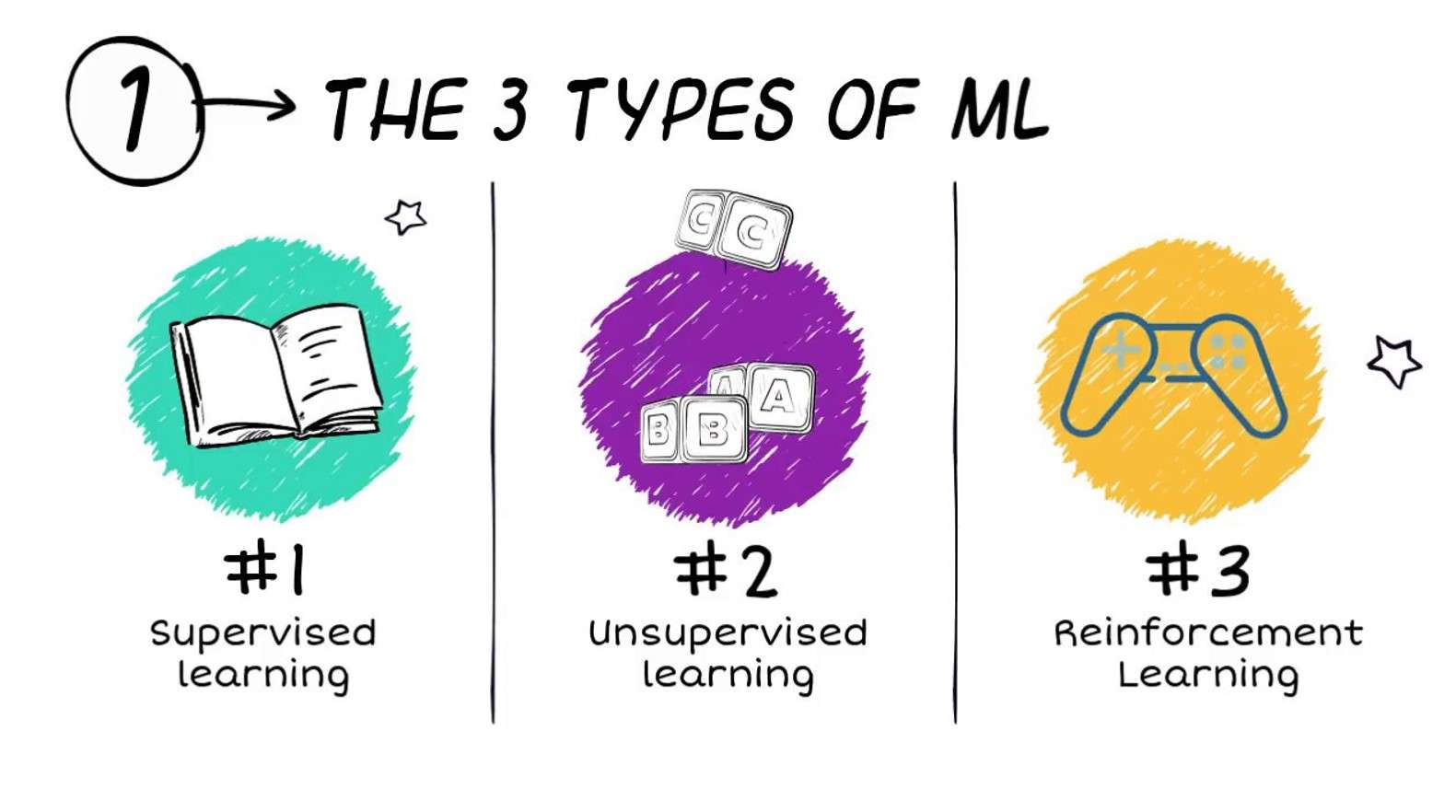
Tafersjoch op learen
Tafersjoch masine learen ferwiist nei techniken wêryn it masine learen model wurdt jûn in samling gegevens mei eksplisite labels foar de kwantiteit fan belang (dizze kwantiteit wurdt faak oantsjutten as it antwurd of doel).
Om AI-modellen op te trenen, brûkt semi-tafersjoch learen in miks fan markearre en net-labelde gegevens.
As jo wurkje mei net-labelde gegevens, moatte jo wat gegevenslabeling ûndernimme.
Labeljen is it proses fan etikettering fan samples om te helpen training fan in masine learen model. Labeljen wurdt foaral dien troch minsken, wat kostber en tiidslinend kin wêze. D'r binne lykwols techniken om it etiketteproses te automatisearjen.
De situaasje foar oanfraach foar liening dy't wy earder besprutsen is in poerbêste yllustraasje fan learen ûnder begelieding. Wy hiene histoaryske gegevens oangeande de kredytwurdearrings fan eardere lieningsoanfregers (en miskien ynkommensnivo's, leeftyd, ensfh.), lykas spesifike labels dy't ús fertelden oft de persoan yn kwestje standert wie op har liening of net.
Regression en klassifikaasje binne twa subsets fan begeliede leartechniken.
- Klassifikaasje - It makket gebrûk fan in algoritme om gegevens korrekt te kategorisearjen. Spamfilters binne ien foarbyld. "Spam" kin in subjektive kategory wêze - de line tusken spam en net-spamkommunikaasje is wazig - en it spamfilteralgoritme ferfine himsels konstant ôfhinklik fan jo feedback (dat betsjut e-post dy't minsken markearje as spam).
- Regression - It is nuttich om de ferbining tusken ôfhinklike en ûnôfhinklike fariabelen te begripen. Regressionmodellen kinne numerike wearden foarsizze basearre op ferskate gegevensboarnen, lykas skattings foar ferkeapynkomsten foar in bepaald bedriuw. Lineêre regression, logistyske regression, en polynomiale regression binne guon promininte regressiontechniken.
Sûnder learen learen
By learen sûnder tafersjoch krije wy unlabelde gegevens en sykje wy gewoan nei patroanen. Litte wy dwaan as jo Amazon binne. Kinne wy klusters (groepen fan ferlykbere konsuminten) fine op basis fan klantferkeapskiednis?
Sels hoewol wy gjin eksplisite, konklúzjende gegevens hawwe oer de foarkar fan in persoan, yn dit gefal, gewoan te witten dat in spesifike set fan konsuminten ferlykbere guod keapet, lit ús keapje suggestjes foar keapjen basearre op wat oare persoanen yn it kluster ek hawwe kocht.
Amazon's "jo miskien ek ynteressearre yn" karrousel wurdt oandreaun troch ferlykbere technologyen.
Learje sûnder tafersjoch kin gegevens groepearje troch klustering of assosjaasje, ôfhinklik fan wat jo wolle groepearje.
- Clustering - Learjen sûnder tafersjoch besiket dizze útdaging te oerwinnen troch te sykjen nei patroanen yn 'e gegevens. As d'r in ferlykbere kluster of groep is, sil it algoritme se op in bepaalde manier kategorisearje. It besykjen om kliïnten te kategorisearjen op basis fan eardere oankeapskiednis is hjir in foarbyld fan.
- bûn - Learjen sûnder tafersjoch besiket dizze útdaging oan te pakken troch te besykjen de regels en betsjuttingen te begripen dy't ferskate groepen ûnderlizze. In faak foarbyld fan in ferieningsprobleem is it fêststellen fan in keppeling tusken klantoankeapen. Winkels kinne ynteressearre wêze om te witten hokker guod tegearre binne kocht en kinne dizze ynformaasje brûke om de posisjonearring fan dizze produkten te regeljen foar maklike tagong.
Learjen fan fersterking
Fersterking learen is in technyk foar it learen fan masine-learmodellen om in searje doelrjochte besluten te meitsjen yn in ynteraktive ynstelling. De hjirboppe neamde gefallen fan gaminggebrûk binne poerbêste yllustraasjes hjirfan.
Jo hoege AlphaZero gjin tûzenen eardere skaakspultsjes yn te fieren, elk mei in "goede" of "earme" beweging markearre. Learje it gewoan de regels fan it spul en it doel, en lit it dan willekeurige hannelingen besykje.
Posityf fersterking wurdt jûn oan aktiviteiten dy't it programma tichter by it doel bringe (lykas it ûntwikkeljen fan in fêste pionposysje). As hannelingen it tsjinoerstelde effekt hawwe (lykas it te betiid ferhúzjen fan 'e kening), fertsjinje se negative fersterking.
De software kin it spultsje úteinlik behearskje mei dizze metoade.
Fersterking learen wurdt in protte brûkt yn robotika om robots te learen foar yngewikkelde en lestich te meitsjen aksjes. It wurdt soms brûkt yn gearhing mei dykynfrastruktuer, lykas ferkearssignalen, om ferkearsstream te ferbetterjen.
Wat kin dien wurde mei masine learen?
It gebrûk fan masine learen yn 'e maatskippij en yndustry resulteart yn foarútgong yn in breed skala oan minsklike ynspanningen.
Yn ús deistich libben kontroleart masine learen no de syk- en ôfbyldingsalgoritmen fan Google, wêrtroch't wy krekter kinne oerienkomme mei de ynformaasje dy't wy nedich binne as wy it nedich binne.
Yn medisinen, bygelyks, wurdt masine learen tapast op genetyske gegevens om dokters te helpen te begripen en te foarsizzen hoe't kanker ferspriedt, wêrtroch't effektiver terapyen ûntwikkelje kinne.
Gegevens út djippe romte wurde hjir op ierde sammele fia massive radioteleskopen - en nei't se analysearre binne mei masine learen, helpt it ús de mystearjes fan swarte gatten te ûntdekken.
Masine learen yn detailhannel ferbynt keapers mei dingen dy't se online wolle keapje, en helpt ek winkelmeiwurkers om de tsjinst oan te passen dy't se leverje oan har kliïnten yn 'e bakstien-en-speesje wrâld.
Masine learen wurdt brûkt yn 'e striid tsjin terreur en ekstremisme om it gedrach te antisipearjen fan dyjingen dy't de ûnskuldigen sear wolle.
Natuerlike taalferwurking (NLP) ferwiist nei it proses fan it tastean fan kompjûters om ús te ferstean en te kommunisearjen mei ús yn minsklike taal troch masine learen, en it hat resultearre yn trochbraken yn oersettechnology en ek de stimbestjoerde apparaten dy't wy elke dei hieltyd mear brûke, lykas Alexa, Google dot, Siri, en Google assistint.
Sûnder in fraach toant masine learen dat it in transformaasjetechnology is.
Robots dy't by steat binne om neist ús te wurkjen en ús eigen orizjinaliteit en ferbylding te stimulearjen mei har foutleaze logika en boppeminsklike snelheid binne net langer in science fiction-fantasy - se wurde in realiteit yn in protte sektoaren.
Machine Learning gebrûk gefallen
1. Cybersecurity
As netwurken yngewikkelder wurden binne, hawwe cybersecurity-spesjalisten ûnfoldwaande wurke om oan te passen oan it hieltyd útwreidzjende oanbod fan feiligensbedrigingen.
It tsjingean fan rap evoluearjende malware en hacking-taktyk is útdaagjend genôch, mar de proliferaasje fan Internet of Things (IoT)-apparaten hat de cybersecurity-omjouwing yn prinsipe feroare.
Oanfallen kinne op elk momint en op elk plak foarkomme.
Gelokkich hawwe algoritmen foar masine-learen cybersecurity-operaasjes ynskeakele om by te hâlden mei dizze rappe ûntjouwings.
Foarsichtige analytyk ynskeakelje flugger detectie en mitigaasje fan oanfallen, wylst masine learen jo aktiviteit yn in netwurk kin analysearje om abnormaliteiten en swakkens yn besteande feiligensmeganismen te detektearjen.
2. Automatisearring fan klant tsjinst
It behearen fan in tanimmend oantal online klantkontakten hat in protte organisaasje ynspannen.
Se hawwe gewoan net genôch personiel fan klanttsjinst om it folume oanfragen te behanneljen dat se ûntfange, en de tradisjonele oanpak fan it útbesteegjen fan problemen nei in kontaktsintrum is gewoan net akseptabel foar in protte fan 'e hjoeddeiske kliïnten.
Chatbots en oare automatisearre systemen kinne no dizze easken oanpakke troch foarútgong yn techniken foar masine-learen. Bedriuwen kinne personiel frijmeitsje om mear klantstipe op heech nivo te ûndernimmen troch it automatisearjen fan alledaagse en aktiviteiten mei lege prioriteit.
As se goed brûkt wurde, kin masine learen yn bedriuw helpe om probleemresolúsje te streamlynjen en konsuminten it type nuttige stipe te leverjen dy't har konvertearret ta tawijde merkkampioenen.
3. Kommunikaasje
It foarkommen fan flaters en misferstannen is kritysk yn elke soart kommunikaasje, mar mear yn 'e hjoeddeistige saaklike kommunikaasje.
Ienfâldige grammatikale flaters, ferkearde toan, of ferkearde oersettings kinne in ferskaat oan swierrichheden feroarsaakje by e-postkontakt, klantevaluaasjes, Fideo gearkomst, of tekst-basearre dokumintaasje yn in protte foarmen.
Masine-learsystemen hawwe avansearre kommunikaasje fier boppe de heulende dagen fan Microsoft's Clippy.
Dizze foarbylden fan masinelearen hawwe persoanen holpen om ienfâldich en krekt te kommunisearjen troch natuerlike taalferwurking, real-time taaloersetting en spraakherkenning te brûken.
Hoewol in protte yndividuen net fan autokorrigearjende mooglikheden hâlde, wurdearje se ek beskerme tsjin beskamsume flaters en ferkearde toan.
4. Objekt Erkenning
Wylst de technology om gegevens te sammeljen en te ynterpretearjen al in skoft bestiet, hat it learen fan kompjûtersystemen om te begripen wêr't se nei sjogge, bewiisd in bedrieglik drege taak te wêzen.
Objektherkenningsmooglikheden wurde tafoege oan in tanimmend oantal apparaten fanwegen masine-learapplikaasjes.
In selsridende auto, bygelyks, herkent in oare auto as it ien sjocht, sels as programmeurs it net in krekt foarbyld fan dy auto joegen om as referinsje te brûken.
Dizze technology wurdt no brûkt yn retailbedriuwen om it kassaproses te fersnellen. Kamera's identifisearje de produkten yn 'e karren fan konsuminten en kinne har akkounts automatysk fakturearje as se de winkel ferlitte.
5. Digitale marketing
In protte fan 'e hjoeddeistige marketing wurdt online dien, mei in ferskaat oan digitale platfoarms en softwareprogramma's.
As bedriuwen ynformaasje sammelje oer har konsuminten en har oankeapgedrach, kinne marketingteams dy ynformaasje brûke om in detaillearre byld fan har doelgroep te bouwen en te ûntdekken hokker minsken mear oanstriid hawwe om har produkten en tsjinsten te sykjen.
Algoritmen foar masine-learen helpe marketeers by it meitsjen fan sin fan al dy gegevens, ûntdekken fan wichtige patroanen en attributen wêrtroch se mooglikheden strak kinne kategorisearje.
Deselde technology makket grutte digitale marketingautomatisaasje mooglik. Advertinsjesystemen kinne wurde ynsteld om nije potensjele konsuminten dynamysk te ûntdekken en relevante marketingynhâld oan har te leverjen op 'e juste tiid en plak.
Future of Machine Learning
Masine learen wint grif populêrens, om't mear bedriuwen en enoarme organisaasjes de technology brûke om spesifike útdagings oan te pakken of ynnovaasje oan te pakken.
Dizze oanhâldende ynvestearring toant in begryp dat masinelearen ROI produseart, benammen troch guon fan 'e boppeneamde fêststelde en reprodusearjende gebrûksgefallen.
As de technology ommers goed genôch is foar Netflix, Facebook, Amazon, Google Maps, ensfh.
As nij masine learen modellen wurde ûntwikkele en lansearre, sille wy tsjûge wêze fan in tanimming fan it oantal applikaasjes dat sil wurde brûkt yn 'e yndustry.
Dit bart al mei gesicht erkenning, dy't eartiids in nije funksje op jo iPhone wie, mar no wurdt ymplementearre yn in breed oanbod fan programma's en applikaasjes, benammen dy relatearre oan iepenbiere feiligens.
De kaai foar de measte organisaasjes dy't besykje te begjinnen mei masine learen is om foarby de heldere futuristyske fisys te sjen en de echte saaklike útdagings te ûntdekken wêrmei de technology jo kin helpe.
Konklúzje
Yn 'e post-yndustrialisearre tiid hawwe wittenskippers en professionals besocht in kompjûter te meitsjen dy't mear as minsken gedraacht.
De tinkmasine is de wichtichste bydrage fan AI oan it minskdom; de fenomenale komst fan dizze selsridende masine hat fluch omfoarme bedriuw bestjoeringssysteem regeljouwing.
Selsridende auto's, automatisearre assistinten, autonome produksjemeiwurkers, en tûke stêden hawwe de lêste tiid de leefberens fan tûke masines oantoand. De revolúsje fan masine learen, en de takomst fan masine learen, sil by ús wêze foar in lange tiid.





Leave a Reply