Table of Contents[Ferstopje][Toanje]
As jo in fan fan Machine Learning, Artificial Intelligence, of kompjûterwittenskip binne, begripe jo wierskynlik it konsept en ferlet fan gegevens om te helpen in opjûn systeem of tsjinst te ferbetterjen.
Technyske reuzen en multynasjonale bedriuwen meitsje gebrûk fan grutte voluminten gegevens om klantûnderfining en har algemiene kwaliteit fan tsjinst te ferbetterjen troch avansearre techniken fan saaklike yntelliginsje oan te nimmen om sin te meitsjen fan har gegevens. Ien fan 'e opkommende en wichtichste techniken wurdt oantsjutten as foarsizzende analytyk.
Dit artikel giet oer it idee fan foarsizzende analytyske ark, har tapassing, en in oantal foarbylden fan iepen-boarne ark dat jo kinne brûke!
Wat binne Predictive Analytics Tools?
Foarsizzende analytyske ark binne software dy't patroanen en trends bepale troch it analysearjen en ekstrahearjen fan ynformaasje út in besteande dataset. Dizze ark meitsje gebrûk fan in ferskaat oan statistyske techniken, ynklusyf data mining, foarsizzend modellering, en Machine Learning om de opjûne gegevens te analysearjen en foarsizzingen te meitsjen.
Dizze ark kinne wurde brûkt om sin te meitsjen fan patroanen yn konsumintegedrach en eardere trends om in plan te meitsjen foar in spesifike tiidsduur om de profitabiliteit en sukses fan in opjûne tsjinst te fergrutsjen.
Tapassingen fan Predictive Analytics
D'r binne in protte tapassingen fan foarsizzende analytyske ark dy't fariearje oer in oantal fjilden, ynklusyf:
E-commerce
- Klantgegevens analysearje om minsken te groepearjen op basis fan har keapfoarkarren en dan de kâns fan dizze groepen foarsizze om produkten te keapjen.
- Foarsizze de Return Of Investment (ROI) fan doelgroep marketingkampanjes.
- Gegevens sammelje fan trendy online winkels lykas Amazon Marketplace.
Social Media Marketing
- Planning fan it type en soarte ynhâld om te pleatsen.
- Foarsizze de bêste dei en tiid om de opjûne ynhâld te pleatsen.
- Behannelje Google Ads en advertinsjes yn it algemien.
Banking en fersekering
- Útfine credit ratings.
- Identifisearje frauduleuze aktiviteiten.
Sûnenssoarch
- Monitoring sûnens yn it algemien.
- Identifisearje iere tekens fan sûnensproblemen yn in yndividu.
Manufacturing
- Behear fan ynventarisaasje en supply chain.
- Helpjen yn it ferstjoeren en ferfollingproses.
Iepenboarne Predictive Analytics Tools
1. Oranje Data Mining
Oranje is in ark foar gegevensfisualisaasje en -analytyk dat foarsizzende analytiken útfiert fia fisuele programmearring as Python-skripting. Dizze toolkit wurdt ymportearre as in Python-bibleteek en befettet komponinten foar Machine Learning, bioinformatika, tekst mining, en oare gegevens analytyske skaaimerken.
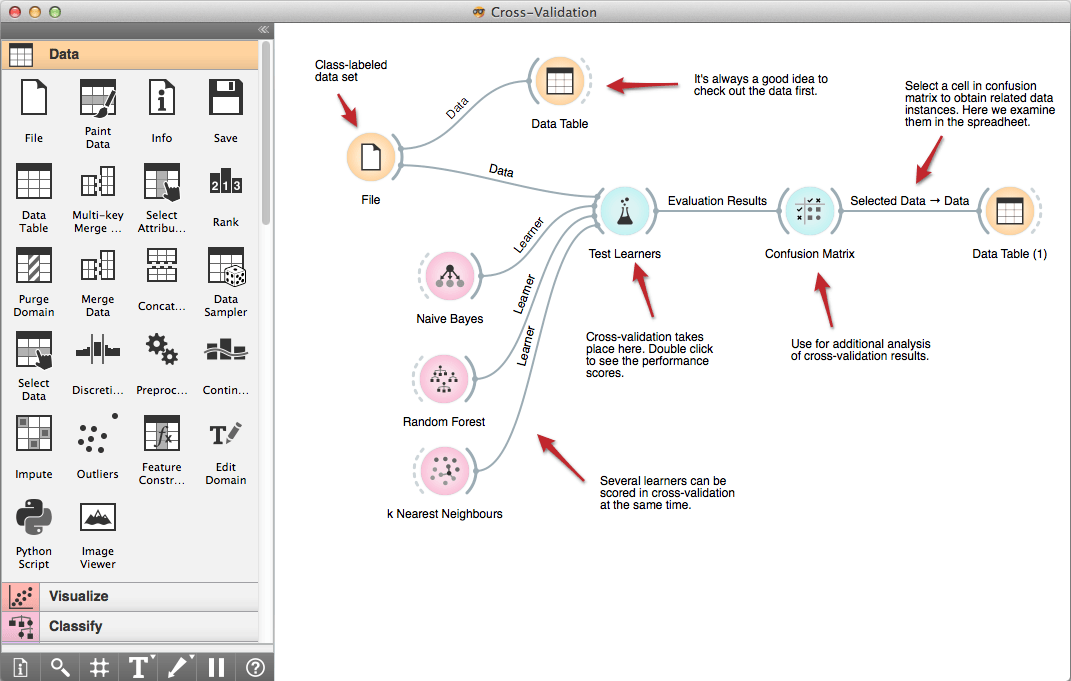
Key features
- Ynteraktyf data fisualisaasje en grafyske foarstelling funksjes.
- Omfettet fisuele programmearring.
- Canvas-basearre Graphical brûker omjouwing (GUI) makket it maklik te brûken foar begjinners.
- Yn steat om ienfâldige en komplekse gegevensanalytyk út te fieren.
2. Anaconda
In iepen-boarne gegevenswittenskip Python- en R-distribúsjeplatfoarm mei mear dan 250 ferskillende populêre pakketten brûkt om gewoan pakketbehear en ynset te meitsjen. Dizze ferdieling makket gebrûk fan gegevenswittenskip, Machine Learning applikaasjes, en grutskalige gegevensferwurking om foarsizzende analytiken út te fieren.
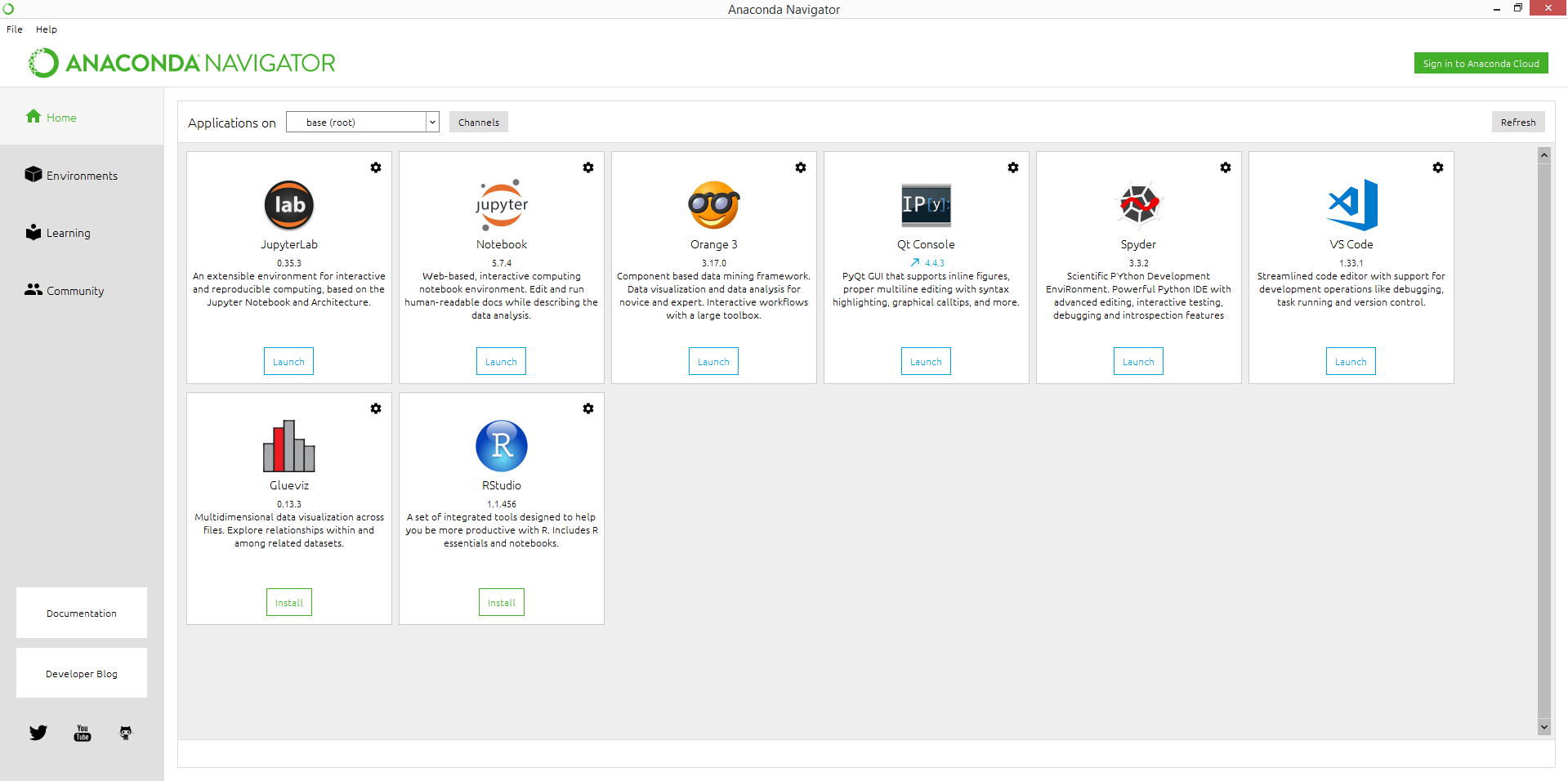
Key features
- Avansearre analytics, gebrûk fan workflows, en gegevens ynteraksje.
- Ferbine alle gegevensboarnen om de measte wearde út gegevens te heljen.
- Meitsje foarsizzende analytyske modellen mei Python, R, en Jupyter Notebooks.
- Yntegrearje jo foarsizzende analytyske modellen yn yntelliginte webapps en ynteraktive fisualisaasjes.
- Gearwurkje oer heule gegevenswittenskipteams mei Anaconda.
3. R Software Miljeu
De R-omjouwing wurdt brûkt foar statistyske berekkenjen en grafiken. It kompilearret en rint op in ferskaat oan bestjoeringssystemen ynklusyf UNIX, Windows, en MAC OS. Dizze omjouwing hat in grutte kolleksje fan tuskenmiddels foar gegevensanalytyk en de grafyske werjefte fan gegevensanalytyk.
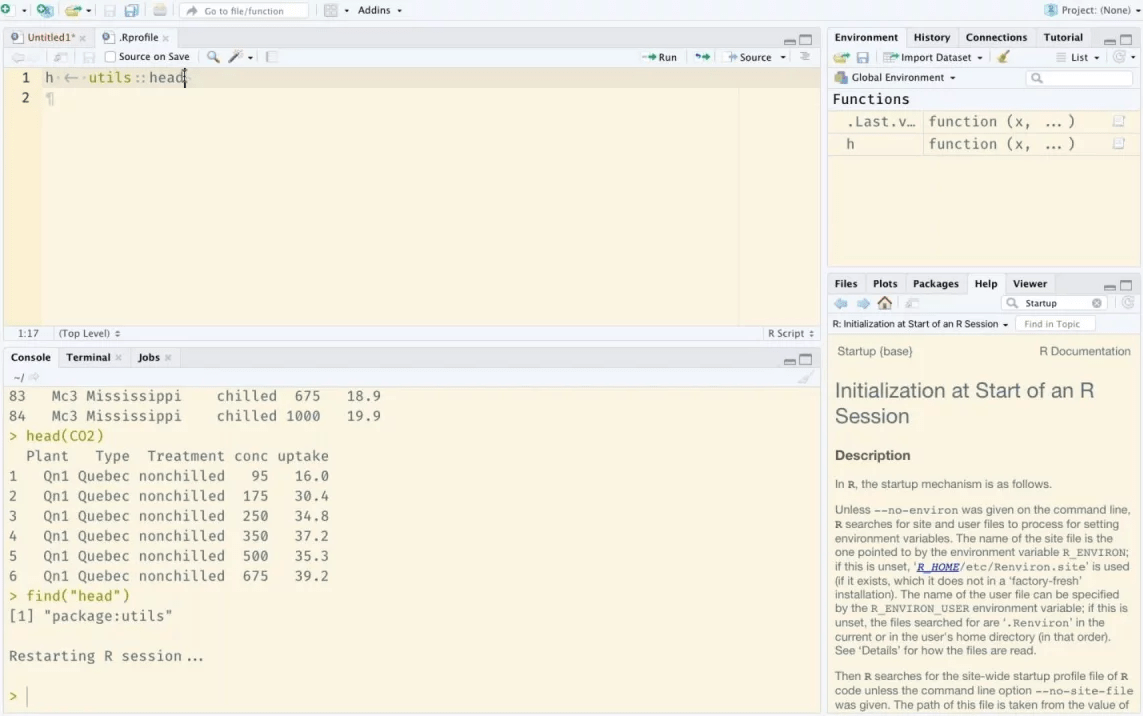
Key features
- Omfettet in ferskaat oan statistyske modellen en grafyske techniken foar foarsizzende analytyk.
- Effektive gegevens ôfhanneling en opslach fasiliteiten.
- In suite fan operators foar komplekse data array berekkeningen en statistyske analytics.
- Stipe online beskikber fan de R-mienskip.
4. Scikit-Learje
Dit is in Machine Learning-bibleteek foar de programmeertaal Python. It omfettet ferskate klassifikaasje-, regression- en klusteringalgoritmen, ynklusyf Support Vector Machines (SVM's), willekeurige bosken, en k-betsjut clustering dy't heul nuttich binne foar foarsizzend modellering. Avansearre programmearkennis is lykwols fereaske om foarsizzende analytiken út te kinnen mei Scikit-Learn.
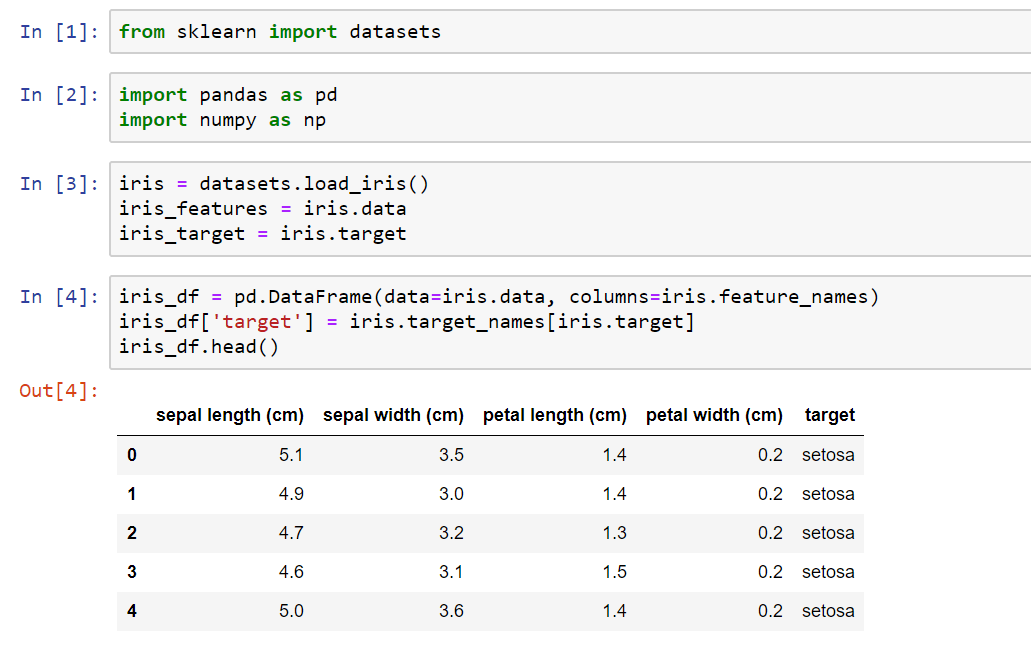
Key features
- Avansearre gegevensbehanneling omfettet it werjaan fan gegevens yn fisuele en tabelfoarm, it regeljen fan gegevens yn funksjematriksen as doelvektoren.
- In oantal klassifikaasje-, regression- en klustermodellen beskikber foar foarsizzende analytyk.
- Meardere krektensmetriken om foarsizzende modelprestaasjes te testen.
5. Weka Data Mining
Weka is in samling Machine Learning-algoritmen foar foarsizzende modelleartaken skreaun yn Java. Dizze algoritmen kinne wurde tapast op jo gegevens direkt of neamd mei Javascript. De metoaden foar gegevensanalytyk levere troch Weka omfetsje techniken foar data mining, foarferwurking en fisualisearjen. Weka makket ek gebrûk fan klassifikaasje-, regression- en klustermodellen foar foarsizzende analytyk.
Key features
- Data preprocessing en fisualisaasje techniken.
- Algorithmen foar klassifikaasje, regression en klustering fan gegevens.
- Wiidweidige ferieningsregels om trends yn gegevens te foarsizzen.
- Draachbere en ûnthâld romte-friendly software.
6. Apache mahout
In ienfâldige en útwreidbere programmearomjouwing en ramt foar it bouwen fan skaalbere en performante Machine Learning-algoritmen. De omjouwing omfettet in oantal foarmakke Scala, Apache Spark, en Apache Flint-algoritmen. Dizze omjouwing brûkt Samsara, in fektor wiskundige eksperimintearjen fergelykber mei de R-taal dy't op skaal wurket.
Key features
- Gearwurkingsfiltering om oanbefellingssystemen te bouwen.
- Clustering- en klassifikaasjealgoritmen foar foarsizzend modellering.
- Unterstützt faak itemsettiming foar avansearre gegevensekstraksje.
- Lineêre algebra operator en ferspraat algebra optimizer foar avansearre statistyske analytics.
- Bout scalable algoritmen foar foarsizzende analytics.
7. GNU Octave
Dizze software stiet foar in taal op heech nivo bedoeld foar numerike berekkeningen. Dizze software hat in krêftige math-oriïntearre syntaksis mei ynboude plot- en fisualisaasje-ark foar avansearre gegevensanalytyk. GNU Octave is kompatibel mei MATLAB-skripts en bestjoeringssystemen ynklusyf GNU/Linux, MAC OS, en Windows.
Key features
- Ynboude 2D / 3D data plotting en fisualisaasje ark.
- Unterstützt in oantal GNU statistyske pakketten foar gegevensanalytyk.
- Makket gebrûk fan math-oriïntearre foarsizzend modellering.
- Mooglikheid om MATLAB foarsizzende modellen en Machine Learning-algoritmen út te fieren.
8. SciPy
In kolleksje fan iepen boarne Python-basearre software brûkt foar technyske en wittenskiplike komputer. SciPy hat kearnpakketten dy't komputerark foar Python leverje. It makket gebrûk fan avansearre gegevensbehannelingstechniken en foarsizzende modellen ynklusyf k neiste buorman, willekeurige bosk, en neurale netwurken.
SciPy is beskikber as in Python bibleteek yn in protte Python-distribúsjes en is in pakket yn Anaconda.
Key features
- Modules foar optimisaasje, lineêre algebra, yntegraasje, ynterpolaasje, spesjale funksjes, FFT, en ODE-oplossers.
- Biedt ferskate funksjes foar sinjaal-, ôfbyldings- en gegevensferwurking.
- Unterstützt NumPy en Matplot.
Konklúzje
Jo moatte no in goed idee hawwe oer iepen boarne foarsizzende analytyske ark, har applikaasjes, en hoe't se gebrûk meitsje fan avansearre techniken om foarsizzingen te meitsjen fia gegevens.
Alle neamde ark binne folslein fergees te brûken en beskikber foar elkenien. As jo dizze ark earder hawwe brûkt, lit ús dan witte oer jo ûnderfining yn 'e opmerkings.





Leave a Reply