Table of Contents[Ferstopje][Toanje]
Bedriuwen fange mear gegevens dan ea, om't se der hieltyd mear op fertrouwe om wichtige saaklike besluten te ynformearjen, produktoanbod te ferbetterjen en bettere klanttsjinst te leverjen.
Mei de kwantiteit fan gegevens dy't op in eksponinsjele taryf wurdt makke, biedt de wolk ferskate foardielen foar gegevensferwurking en -analytyk, ynklusyf skalberens, betrouberens en beskikberens.
Yn it wolkekosysteem binne d'r ek ferskate ark en technologyen foar gegevensferwurking en analytyk. De twa soarten opslachstruktueren foar grutte gegevens dy't it meast wurde brûkt binne gegevenspakhuzen en gegevensmarren.
Hoewol it brûken fan in gegevensmar minder oantreklik is, om't jo it model en de gegevens net kinne opfreegje wylst it noch relevant is, is it brûken fan in gegevenspakhús foar streaming fan gegevensopslach fergriemd.

Whokker type wolk-arsjitektuer kieze wy?
Moatte wy nijere konsepten beskôgje foar it datamarehouse, of moatte wy tefreden wêze mei de beheiningen fan it pakhús as de beheiningen fan 'e mar?
In nije data-opslacharsjitektuer neamd in "data lakehouse" kombinearret it oanpassingsfermogen fan datamarren mei it databehear fan datapakhuzen.
Begryp fan 'e ferskate metoaden foar opslach fan grutte gegevens is essensjeel foar it bouwen fan in betroubere pipeline foar gegevensopslach foar saaklike yntelliginsje (BI), gegevensanalytyk, en masine learen (ML) wurkdruk, ôfhinklik fan de easken fan jo bedriuw.
Yn dit post sille wy nau sjen nei Data Warehouse, Data Lake en Data Lakehouse, mei foardielen, beheiningen en ek foar- en neidielen dêrfan. Litte wy begjinne.
Wat is Data Warehouse?
In data warehouse is in sintralisearre data repository brûkt troch in organisaasje om enoarme voluminten gegevens út in protte boarnen te hâlden. In gegevenspakhús fungearret as de ienige boarne fan in organisaasje fan "gegevenswierheid" en is essensjeel foar rapportaazje en saaklike analytyk.
Typysk kombinearje gegevenspakhuzen relaasjegegevenssets út ferskate boarnen, lykas applikaasje-, bedriuws- en transaksjegegevens, om histoaryske gegevens op te slaan. Foardat se yn it opslachsysteem laden wurde, wurde gegevens omfoarme en skjinmakke yn gegevenspakhuzen, sadat it kin wurde brûkt as ienige boarne fan gegevenswierheid.
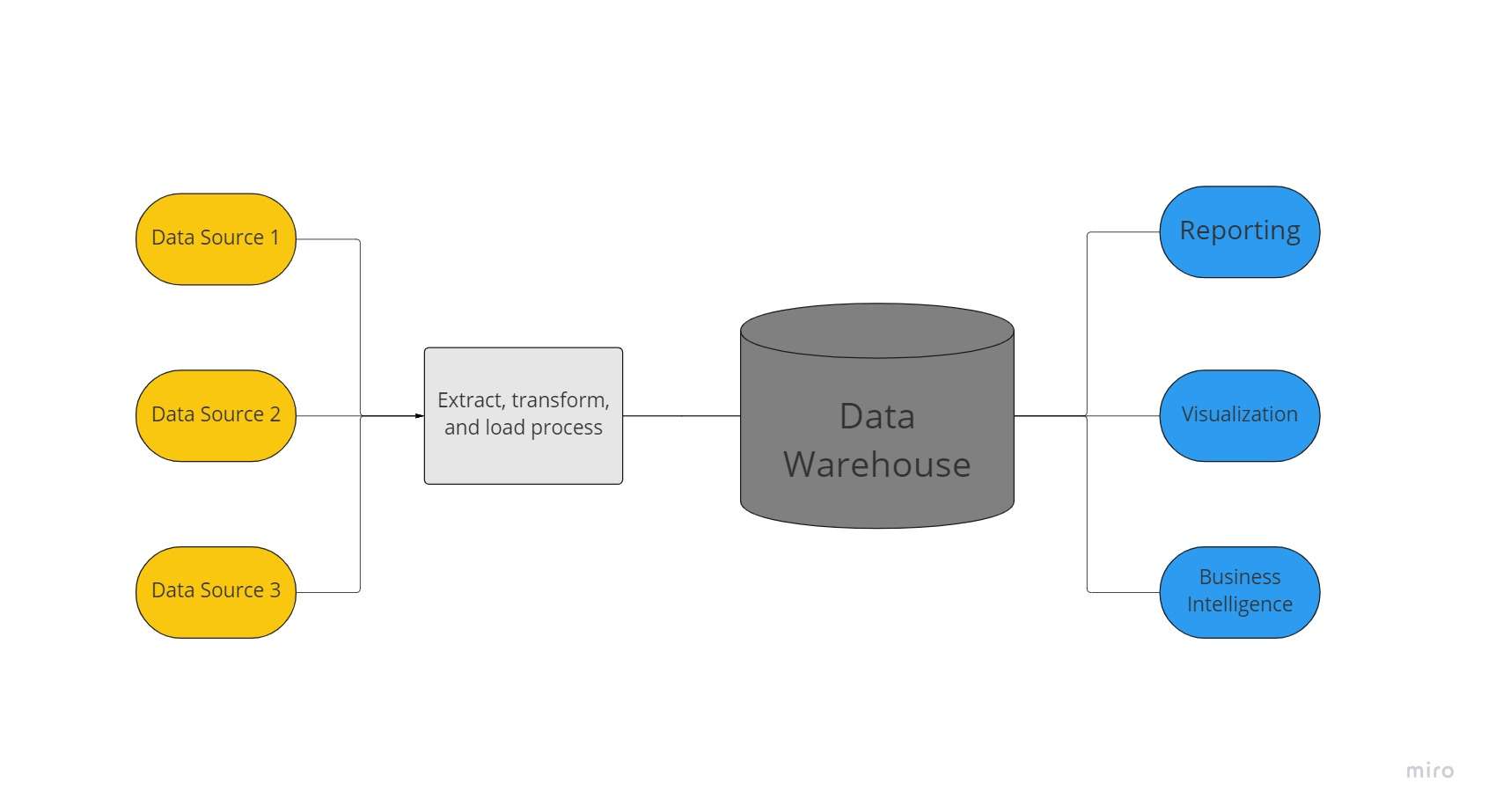
Fanwegen har fermogen om rap saaklike ynsjoch te bieden út alle gebieten fan it bedriuw, ynvestearje bedriuwen yn datapakhuzen. Mei it brûken fan BI-ark, SQL-kliïnten, en oare minder ferfine (dat wol sizze, net-gegevenswittenskip) analytyske oplossingen, saaklike analisten, data-yngenieurs en beslútmakkers kinne tagong krije ta gegevens fan datapakhuzen.
It is djoer om in pakhús te behâlden mei it hieltyd tanimmende folume fan gegevens, en in gegevenspakhús kin rau of net-strukturearre gegevens omgean. Derneist is it net de ideale opsje foar ferfine data-analyzetechniken lykas masine learen of foarsizzend modellering.
In gegevenspakhús leveret dêrom rappere antwurden op fraach en gegevens fan in hegere kwaliteit. Google Big Query, Amazon Redshift, Azure SQL Data warehouse, en Snowflake binne wolktsjinsten dy't beskikber binne foar datapakhuzen.
Foardielen fan Data Warehouse
- It fergrutsjen fan de effisjinsje en snelheid fan wurklasten foar saaklike yntelliginsje en gegevensanalyse: Data warehouses koarter de tiid nedich foar gegevens tarieding en analyze. Se kinne maklik keppelje oan gegevensanalytyk en ark foar saaklike yntelliginsje, om't de gegevens fan it gegevenspakhús betrouber en konsekwint binne. Derneist besparje gegevenspakhuzen de tiid dy't nedich is foar gegevenssammeling en jouwe teams de mooglikheid om gegevens te brûken foar rapporten, dashboards en oare analytyske easken.
- It fergrutsjen fan de konsistinsje, kwaliteit en standerdisearring fan gegevens: Organisaasjes sammelje gegevens út in ferskaat oan boarnen, ynklusyf brûkers-, ferkeap- en transaksjegegevens. It bedriuw kin de gegevens fertrouwe foar saaklike easken, om't datawarehousing bedriuwsgegevens kompilearret yn in unifoarm, standerdisearre formaat dat kin fungearje as ien boarne fan gegevenswierheid.
- Ferbetterjen fan beslútfoarming yn it algemien: Data warehousing fasilitearret bettere beslútfoarming troch it oanbieden fan in sintralisearre winkel foar sawol resinte as âlde gegevens. Troch gegevens te ferwurkjen yn datapakhuzen foar krekte ynsjoggen, kinne beslútmakkers risiko's beoardielje, klantwollen begripe en guod en tsjinsten ferbetterje.
- It leverjen fan bettere saaklike yntelliginsje: Data warehousing oerbrêget de kleau tusken massive rauwe gegevens, dy't faaks regelmjittich sammele wurde, en de gearstalde gegevens dy't ynsjoch jouwe. Se fungearje as de basis foar de gegevensopslach fan in organisaasje, wêrtroch it yngewikkelde fragen oer har gegevens kin beantwurdzje en de antwurden brûke om ferdigenbere saaklike besluten te nimmen.
Beheinings fan Data Warehouse
- Gebrek oan data fleksibiliteit: Wylst data warehouses útblinke by it behanneljen fan strukturearre gegevens, semy-strukturearre en net-strukturearre dataformaten lykas log analytics, streaming, en sosjale media data kinne wêze útdaagjend foar harren. Dit makket it oanbefellen fan datapakhuzen foar gebrûk gefallen wêrby't masine learen en keunstmjittige yntelliginsje dreech.
- Djoer om te ynstallearjen en te ûnderhâlden: Gegevenspakhuzen kinne djoer wêze om te ynstallearjen en te ûnderhâlden. Fierder is it datapakhús faak net statysk; it leeftyd en moat faak ûnderhâld, dat is djoer.
pros
- Gegevens binne ienfâldich te finen, op te heljen en te freegjen.
- Salang't de gegevens al skjin binne, is SQL-gegevenstarieding ienfâldich.
Cons
- Jo wurde twongen om mar ien analytics ferkeaper te brûken.
- It analysearjen en opslaan fan ûnstrukturearre as streamende gegevens is frij kostber.
Wat is Data Lake?
Elk type gegevens wurdt tasein en mooglik makke troch gegevensmarren. It is foardielich dat gegevens op in tagonklike manier sintraal pleatst en beskikber binne foar lêzen.
In gegevensmar is in sintralisearre, ekstreem oanpasbere opslachromte wêr't massive folumes fan organisearre en net-strukturearre gegevens wurde bewarre yn har net-ferwurke, net feroare en net-opmaakte foarmen.
In gegevensmar brûkt in platte arsjitektuer en objekten opslein yn syn net-ferwurke steat om gegevens op te slaan, yn tsjinstelling ta gegevenspakhuzen, dy't relaasjegegevens bewarje dy't earder "skromme" binne.
Gegevensmarren, yn tsjinstelling ta gegevenspakhuzen, dy't muoite hawwe mei it behanneljen fan gegevens yn dit formaat, binne oanpasber, betrouber en betelber en kinne bedriuwen ferbettere ynsjoch krije fan net-strukturearre gegevens.
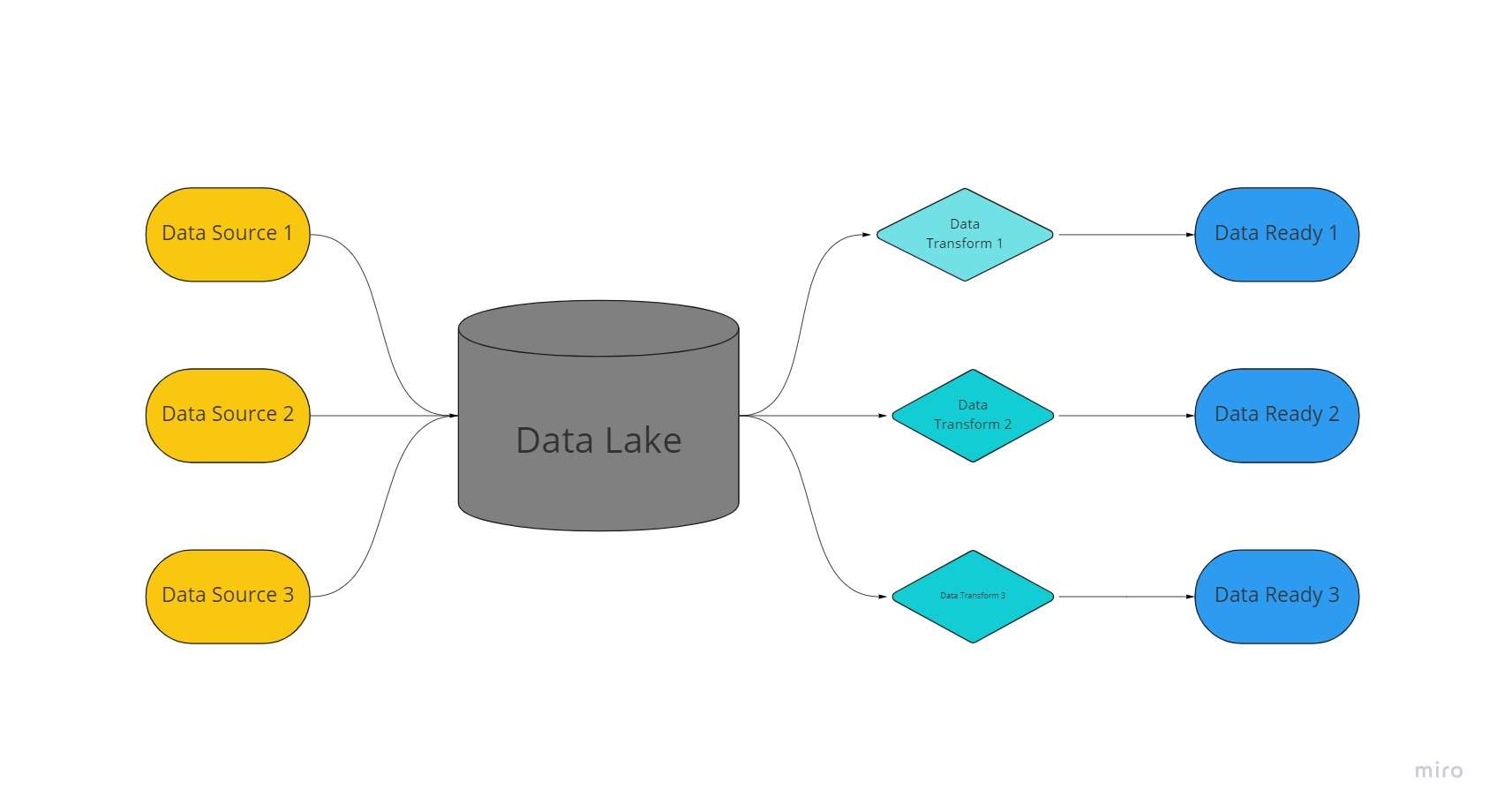
Yn gegevensmarren wurde gegevens ekstrahearre, laden en omfoarme (ELT) foar analytyske doelen ynstee fan it skema of gegevens te hawwen fêststeld op it momint fan gegevens sammeljen.
Gebrûk fan technologyen foar in protte gegevenssoarten fan IoT-apparaten, sosjale media, en streaming gegevens, gegevensmarren ynskeakelje masine learen en foarsizzende analytyk.
Derneist kin in gegevenswittenskipper dy't rûge gegevens ferwurkje kin de gegevensmar brûke. In data warehouse, oan 'e oare kant, is makliker foar bedriuwen te brûken. It is perfekt foar brûkersprofilering, predictive analytics, masine learen, en oare taken.
Hoewol gegevensmarren ferskate problemen oanpakke mei gegevenspakhuzen, is har gegevenskwaliteit min en har querysnelheid is net genôch. Derneist nimt it ekstra ark foar saaklike brûkers om SQL-fragen út te fieren. In gegevensmar dy't min strukturearre is, kin in probleem ûnderfine mei gegevensstagnaasje.
Foardielen fan Data Lake
- Stipe foar in breed oanbod fan tapassingsgefallen foar masine-learen en gegevenswittenskip It is ienfâldiger om in oare masine en algoritmen foar djippe learen te brûken om de gegevens yn gegevensmarren te behanneljen, om't de gegevens op in iepen, rauwe manier wurde hâlden.
- De veelzijdigheid fan gegevensmarren, wêrtroch jo gegevens yn elk formaat of media kinne opslaan sûnder de eask foar in ynsteld skema, is in grut foardiel. Takomstige gefallen fan gebrûk fan gegevens kinne wurde stipe, en mear gegevens kinne wurde analysearre as de gegevens yn har oarspronklike steat bliuwe.
- Om foar te kommen dat jo beide soarten gegevens yn ferskate konteksten moatte opslaan, kinne gegevensmarren sawol struktureare as net-strukturearre gegevens befetsje. Foar de opslach fan ferskate soarten organisaasjegegevens biede se ien lokaasje oan.
- Yn ferliking mei tradisjonele gegevenspakhuzen binne gegevensmarren minder djoer, om't se boud binne om te hâlden op goedkeape commodity-hardware, lykas opslach fan objekten, dy't faaks rjochte is op in legere kosten per opsleine gigabyte.
Beheinings fan Data Lake
- Data analytics en saaklike yntelliginsje gebrûk gefallen skoare min: Data marren kinne wurde unorganized as se net genôch ûnderhâlden, dat makket it dreech om te keppeljen se oan saaklike yntelliginsje en analytics ark. Derneist, as it nedich is foar rapportaazje en analyse gebrûk fan gefallen, in gebrek oan konsekwint datastrukturen en ACID (atomicity, konsistinsje, isolaasje en duorsumens) transaksjestipe kin liede ta suboptimale query-prestaasjes.
- De ynkonsistinsje fan gegevensmarren makket it ûnmooglik om gegevensbetrouberens en feiligens te hanthavenjen, wat resulteart yn in gebrek oan beide. It kin lestich wêze om passende noarmen foar gegevensfeiligens en bestjoer te ûntwikkeljen om te foldwaan oan gefoelige gegevenstypen, om't gegevensmarren elke gegevensfoarm kinne omgean.
pros
- Oplossingen dy't betelber binne foar alle soarten gegevens.
- Yn steat om gegevens te behanneljen dy't sawol organisearre as semi-strukturearre binne.
- Ideaal foar yngewikkelde gegevensferwurking en streaming.
Cons
- It is nedich om in ferfine pipeline te bouwen.
- Jou gegevens wat tiid om queryable te wurden.
- It duorret tiid om betrouberens en kwaliteit fan gegevens te garandearjen.
Wat is Data Lakehouse?
In nije arsjitektuer foar opslach foar grutte gegevens neamd in "data lakehouse" kombineart de grutste aspekten fan gegevensmarren en gegevenspakhuzen. Al jo gegevens, oft strukturearre, semy-strukturearre, as net-strukturearre, kinne wurde opslein op ien lokaasje mei de moaiste masine learen, saaklike yntelliginsje, en streaming mooglikheden mooglik tank oan in gegevens lakehouse.
Data marren fan alle soarten binne faak it útgongspunt foar data lakehouses; dêrnei, de gegevens wurdt omfoarme ta Delta Lake formaat (in iepen boarne opslach laach dat bringt betrouberens oan gegevens marren).
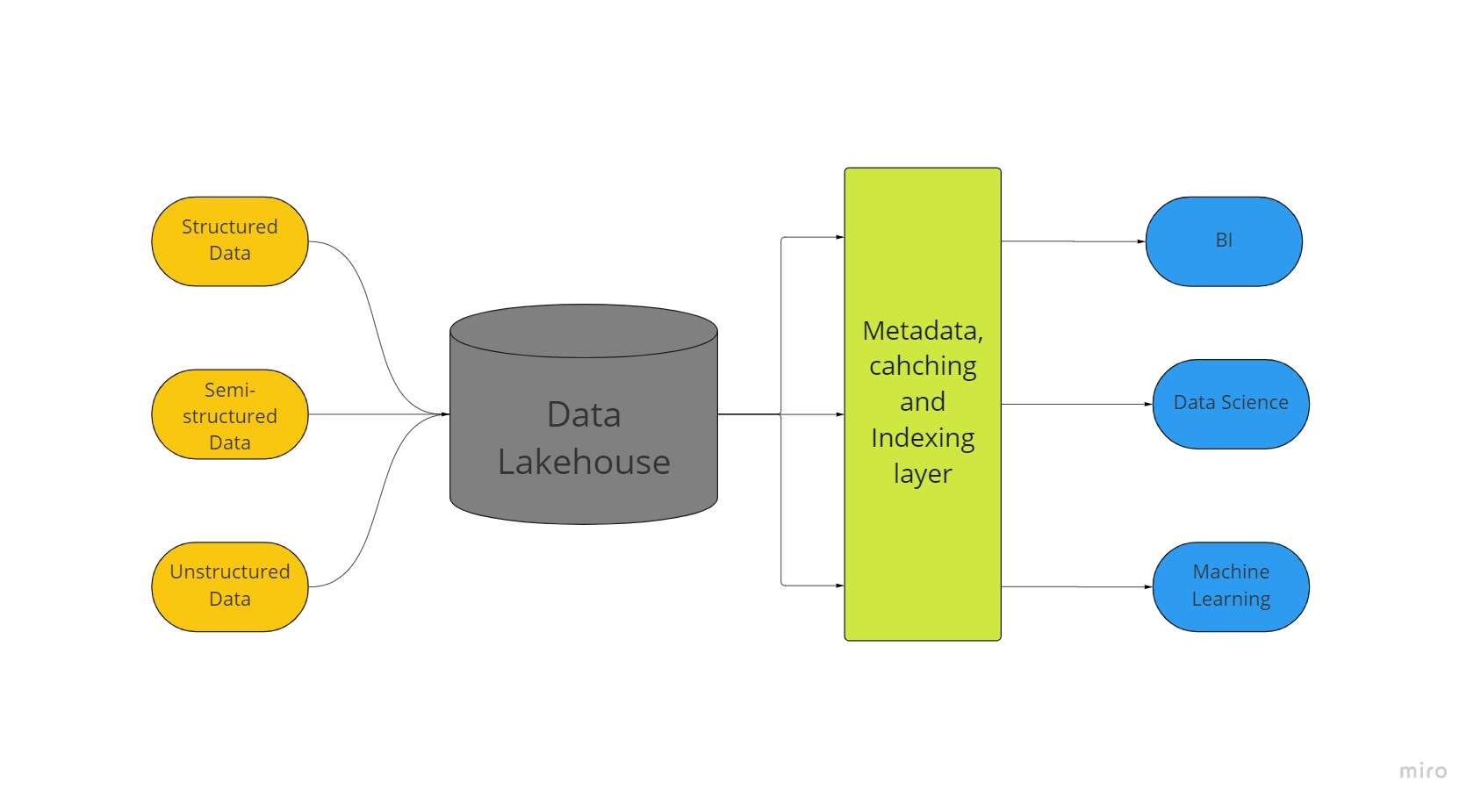
Gegevensmarren mei deltamarren ynskeakelje ACID transaksjeprosedueres fan konvinsjonele gegevenspakhuzen. Yn essinsje brûkt it lakehouse-systeem goedkeape opslach om massive hoemannichten gegevens yn har orizjinele foarmen te behâlden, lykas gegevensmarren.
It tafoegjen fan de metadata-laach boppe op 'e winkel jout ek gegevensstruktuer en machtigje ark foar gegevensbehear lykas dy fûn yn gegevenspakhuzen.
Dit makket it mooglik foar in protte teams om tagong te krijen ta alle bedriuwsgegevens fia ien inkeld systeem foar in ferskaat oan inisjativen, lykas gegevenswittenskip, masine learen, en saaklike yntelliginsje.
Foardielen fan Data Lakehouse
- Stipe foar in grutter oanbod fan wurkloads: Om ferfine analyzes te fasilitearjen, jouwe gegevensmarehouses brûkers direkte tagong ta guon fan 'e populêrste ark foar saaklike yntelliginsje (Tableau, PowerBI). Derneist kinne gegevenswittenskippers en yngenieurs foar masine-learen de gegevens maklik brûke, om't gegevensmarehouses iepen-gegevensformaten brûke (lykas Parquet) tegearre mei API's en ramt foar masine-learen, lykas Python / R.
- Kosten-effektiviteit: Datamarehouses brûke goedkeape oplossings foar opslach foar objekten om kosten-effektive opslachkarakteristiken fan datamaren út te fieren. Troch in inkele oplossing oan te bieden, meitsje datamarehouses ek de útjeften en tiid dy't ferbûn binne mei it behearen fan ferskate gegevensopslachsystemen fuort.
- Data lakehouse-ûntwerp soarget foar skema- en gegevensintegriteit, wêrtroch it ienfâldiger is om effektive gegevensfeiligens- en bestjoersystemen te bouwen. Gemak fan data ferzje, bestjoer, en feiligens.
- Data lakehouses biede in ienich, multyfunksjoneel platfoarm foar gegevensopslach dat kin foldwaan oan alle bedriuwsgegevensfragen, wat gegevensduplikaasje ferminderet. De mearderheid fan bedriuwen kiest in hybride oplossing fanwegen de foardielen fan sawol it datapakhús as it datamar. Dizze strategy kin yntusken resultearje yn kostbere gegevensduplikaasje.
- De stipe fan iepen formaten. Iepen formaten binne bestânstypen dy't brûkt wurde kinne troch in protte softwareapplikaasjes en wêrfan de spesifikaasjes iepenbier beskikber binne. Neffens rapporten binne Lakehouses by steat om gegevens op te slaan yn gewoane bestânsformaten lykas Apache Parquet en ORC (Optimized Row Columnar).
Beheinings fan Data Lakehouse
It grutste nadeel fan in data Lakehouse is dat it noch in jonge en ûntwikkeljende technology is. It is net wis oft it syn ferplichtingen dêrtroch neikomt. Foardat gegevensmarehouses kinne konkurrearje mei fêststelde systemen foar opslach fan grutte gegevens, kin it jierren duorje.
Sjoen it tempo wêrmei't moderne ynnovaasje plakfynt, is it lykwols lestich te sizzen as in oar systeem foar gegevensopslach it úteinlik net sil ferfange.
pros
- Ien platfoarm hat alle gegevens, wat betsjut dat d'r minder hostnammen binne om te ûnderhâlden.
- Atomiteit, konsistinsje, isolaasje en hurdens wurde net beynfloede.
- It is signifikant mear betelber.
- Ien platfoarm hat alle gegevens, wat betsjut dat d'r minder hostnammen binne om te ûnderhâlden.
- Ienfâldich te behearjen, en rap om alle problemen te ferhelpen
- Meitsje it ienfâldiger om in pipeline te bouwen
Cons
- It opsetten kin wat tiid duorje.
- It is te jong en te fier fuort om te kwalifisearjen as in fêststeld opslachsysteem.
Data Warehouse vs Data Lake vs Data Lakehouse
It datapakhús hat in lange skiednis yn applikaasjes foar bedriuwsintelliginsje, rapportaazje en analytyk en is de earste technology foar opslach fan grutte gegevens.
Gegevenspakhuzen, oan 'e oare kant, binne djoer en hawwe problemen mei it behanneljen fan ferskate en net strukturearre gegevens, lykas streaminggegevens. Foar masine-learen en datawittenskip-workloads waarden gegevensmarren ûntwikkele om rauwe gegevens yn ferskate foarmen te behearjen op betelbere opslach.
Hoewol gegevensmarren effektyf binne mei net-strukturearre gegevens, misse se de ACID-transaksje-mooglikheden fan gegevenspakhuzen, wat it útdaagjend makket om gegevenskonsistinsje en betrouberens te garandearjen.
De nijste arsjitektuer foar gegevensopslach, bekend as it "gegevensmarehouse", kombinearret de betrouberens en konsistinsje fan gegevenspakhuzen mei de betelberens en oanpassingsfermogen fan gegevensmarren.
Konklúzje
Ta beslút, it bouwen fan in datamarehouse fanôf it begjin kin lestich wêze. Fierder sille jo hast wis in platfoarm brûke ûntworpen om iepen data lakehouse-arsjitektuer yn te skeakeljen.
Wês dêrom foarsichtich om de protte funksjes en ymplemintaasjes fan elk platfoarm te ûndersykjen foardat jo in oankeap meitsje. Bedriuwen op syk nei in folwoeksen, strukturearre gegevens oplossing mei in fokus op saaklike yntelliginsje en gegevens analytics gebrûk gefallen kinne beskôgje in gegevens warehouse.
Bedriuwen dy't lykwols sykje nei in skaalbere, betelbere oplossing foar grutte gegevens foar powerworkloads foar gegevenswittenskip en masinelearen op netstrukturearre gegevens, moatte gegevensmarren beskôgje.
Tink derom dat jo bedriuw mear gegevens nedich hat dan it datapakhús en datamartechnologyen kinne leverje, of dat jo sykje nei in oplossing om ferfine analytyske en masine-learoperaasjes yn jo gegevens te yntegrearjen. IN gegevens lakehouse is in ferstannige opsje yn 'e situaasje.





Leave a Reply