Gegevens binne in kritysk ûnderdiel fan moderne bedriuwen. Bedriuwen krije gegevens út in protte boarnen, lykas konsuminten, leveransiers en ynterne systemen, en brûke it om opliedende besluten te nimmen. Dochs, as gegevensvolumint en kompleksiteit groeie, kin it lestich wurde om it effisjint te behearjen en te brûken.
In gegevenskatalogus kin hjirmei helpe. It is in ark dat wurdt brûkt troch bedriuwen om har gegevensaktiva te behearjen. Mei oare wurden, it is gewoan in map mei feiten oer in bedriuw. Dizze feiten kinne lokaasje, struktuer en applikaasjes omfetsje.
Foar effektyf behear fan gegevensasset is in gegevenskatalogus essensjeel. Sûnder in gegevenskatalogus rinne bedriuwen it gefaar om har gegevens te ferliezen. It foarkomt dat se witte hokker gegevens se hawwe, wêr't se binne en hoe't se se brûke. Gegevensflaters, duplikaasje en inkonsistinsjes feroarsake troch dit kinne serieuze effekten hawwe op bedriuwen.
Komponinten yn in gegevenskatalogus
Metadata, data lineage, en gegevens kwaliteit details binne de trije wichtige dielen fan in gegevens katalogus.
metadata
De details dy't de gegevens yn 'e katalogus karakterisearje, wurde bekend as metadata. It befettet details lykas de namme fan 'e gegevens, lokaasje, formaat en bedoeld gebrûk. Troch de gegevenskontekst te jaan, kinne metadata brûkers de gegevensaktiva rapper fine en begripe.
Data Skiednis
Data lineage is de dokumintaasje fan 'e skepping, transformaasje en beweging fan' e gegevens tusken ferskate systemen. It biedt in wiidweidich perspektyf fan 'e rûte fan' e gegevens, wêrtroch it makliker is om de krektens fan 'e gegevens te bepalen en har skiednis te folgjen.
Quality Data Information
Ynformaasje oer gegevenskwaliteit ûndersiket faktoaren ynklusyf folsleinens, korrektens, konsistinsje en aktualiteit. It biedt in middel om de geskiktheid fan de gegevens foar bepaalde gebrûk te bepalen. Ek garandearret it dat de gegevens foldogge oan de easken fan 'e organisaasje.
Understanding Data Catalogues
In gegevenskatalogus is in folsleine ynventarisaasje fan gegevensaktiva dy't krekte ynformaasje befettet oer elke gegevenssammeling. It omfettet metadata, gegevenslineage, en gegevenskwaliteitynformaasje om organisaasjes te helpen by it effektyf behearen fan har gegevensaktiva.
Metadata beskriuwt de wichtige funksjes fan in dataset, lykas syn skema, formaat, gegevenstype en gegevensboarne. Data lineage ferklearret de skiednis fan in dataset, ynklusyf syn komôf, wizigingen en ôfhinklikens. En ynformaasje oer gegevenskwaliteit toant de krektens, folsleinens en betrouberens fan in gegevensset oan.
Gegevenskatalogussen wurde faak fersin mei gegevenswurdboeken of gegevensynventarissen, hoewol se net itselde binne. Hoewol gegevenswurdboeken gegevensstikken definiearje en beskriuwe, jouwe gegevenskatalogussen detaillearre ynformaasje oer folsleine datasets. Yn tsjinstelling, gegevens-ynventarissen listje gewoan de gegevensaktiva sûnder fierdere ynformaasje te jaan.
It plannen fan in gegevenskatalogus
It is kritysk om goed ta te rieden foardat jo in gegevenskatalogus bouwe om te soargjen dat it foldocht oan 'e easken fan it bedriuw. Gegevensboarnen identifisearje, metadatastanderts fêststelle, en brûkerseasken begripe binne allegear wichtige saken.
De relevânsje en wearde fan gegevensboarnen foar de organisaasje moatte soarchfâldich beskôge wurde. Om uniformiteit en ynteroperabiliteit yn it heule bedriuw te behâlden, moatte metadatanormen brûkt wurde. Brûker easken moatte wurde definiearre om te soargjen dat de gegevens katalogus wurdt makke mei harren yn gedachten.
Stappen om in gegevenskatalogus te meitsjen
Stap 1: Sykje gegevensboarnen
De earste stap yn it meitsjen fan in gegevenskatalogus is om alle gegevensboarnen fan jo organisaasje te identifisearjen. Dit omfettet databases, data pakhuzen, spreadsheets en oare gegevensrepositories. As jo alle boarnen identifisearre hawwe, kinne jo begjinne mei it sammeljen fan metadata.
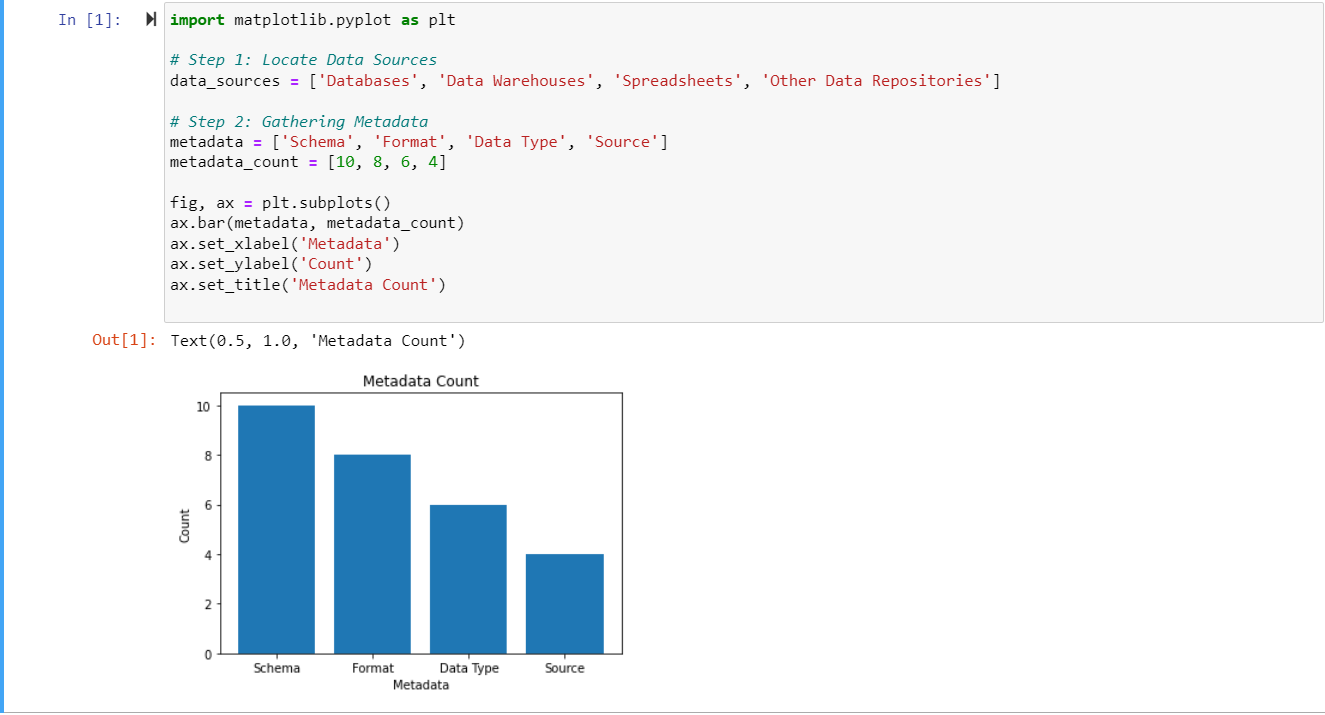
Stap 2: Metadata sammelje
De folgjende stap is om metadata te sammeljen fan alle neamde gegevensboarnen. Metadata spesifiseart de wichtichste skaaimerken fan in dataset, lykas syn skema, opmaak, gegevenstype en boarne. Metadata-sammeling helpt by gegevensorganisaasje en makket it makliker om te sykjen en te finen.
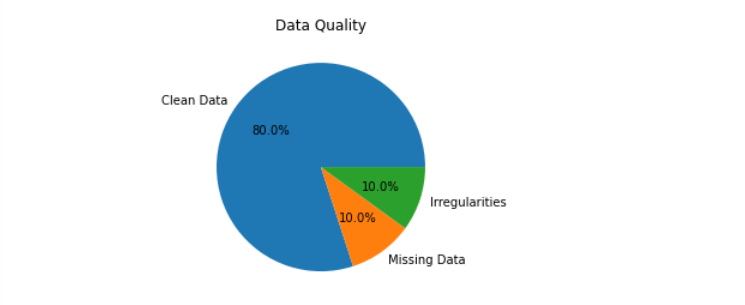
Stap 3: Data Profiling
Nei it sammeljen fan metadata wurde de gegevens profilearre. It proses fan it beoardieljen fan datasets om har struktuer, substansje en kwaliteit te identifisearjen is bekend as dataprofilearring. Profilearring helpt by it identifisearjen fan soargen oer gegevenskwaliteit lykas ûntbrekkende gegevens. It soarget derfoar dat de gegevens skjin en geskikt binne foar gebrûk.
Stap 4: Meitsje in Data Dictionary
De folgjende stap is it meitsjen fan in gegevenswurdboek. In gegevenswurdboek is in wiidweidige ynventarisaasje fan alle gegevens yn jo bedriuw. It biedt rike metadata-beskriuwings, ynformaasje oer gegevenskwaliteit en gegevenslineage. In gegevenswurdboek is kritysk om de gegevens fan jo organisaasje te begripen en te garandearjen dat se goed brûkt wurde.
Stap 5: Identifisearje gegevensrelaasjes
De folgjende stap is om de keppeling tusken de gegevens te identifisearjen. Dit omfettet it opspoaren en markearjen fan de keppeling tusken datasets. Hjirmei kinne belanghawwenden de keppeling tusken gegevensboarnen maklik begripe.
Stap 6: Bouwe in lineage
It meitsjen fan in grafysk ôfbylde lineage is krúsjaal foar it bepalen fan 'e reis fan' e gegevens. De lineage ferklearret de protte prosedueres belutsen by de gegevensstream. Dit stelt belanghawwenden yn steat om de ûnderlizzende oarsaak fan in probleem fluch te identifisearjen troch gewoan de lineage op te spoaren.
Stap 7: Data Organisaasje
Gegevens yn in bestân of in tabel binne technysk bestean. Neffens de saaklike easken kin dit wol of net sin hawwe. As resultaat binne hânmjittige ynspanningen nedich om de gegevens te organisearjen op in manier dy't saaklike brûkers kinne begripe en fertrouwe. Gegevens taggen, gegevens regelje op basis fan gebrûk en brûkersrol, en automatisearjen fan gegevensorganisaasje binne alle metoaden fan gegevensorganisaasje.
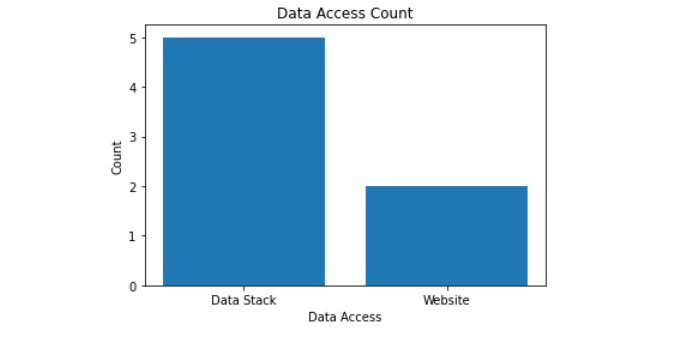
Stap 8: Meitsje maklik tagong
De gegevenskatalogus moat maklik beskikber wêze binnen de gegevensstapel om effektiver te brûken. Jo kinne de gegevenskatalogus op 'e webside brûke as jo in ark brûke lykas Spriede, wat de brûkberens fan 'e gegevenskatalogus fergruttet.

Stap 9: Set feiligensmaatregels yn plak
Om't de gegevenskatalogus in oersjoch hat fan alle gegevens fan in organisaasje, is it kritysk om feiligenseasken te folgjen. In gegevenskatalogus moat rol-basearre feiligens hawwe, ynformaasje oer wa't hokker gegevens brûkt hat en wannear, kontrôle, en fersifering.
Gebrûk meitsje fan jo gegevenskatalogus
Troch brûkers folsleine ynformaasje te jaan oer gegevensaktiva, kin in gegevenskatalogus helpe om gegevensbehear en beslútfoarming te ferbetterjen.
In gegevensanalist kin bygelyks de gegevenskatalogus brûke om relevante datasets foar in bepaalde stúdzje te finen. En se kinne de metadata brûke om de struktuer en substansje fan 'e gegevens te begripen. De gegevenskatalogus kin brûkt wurde troch in saaklike brûker om ferskate datasets te studearjen en ynsjoch te krijen yn konsumintegedrach, produktprestaasjes of merktrends.
Om gearfetsje, it behâld fan in gegevenskatalogus omfettet soarchfâldige planning en konsekwint wurk. Dochs is it foardiel fan in yngeande ynventarisaasje fan gegevensaktiva in protte. It kin beslútfoarming ferbetterje en produktiviteit ferheegje.
Ferskillen tusken gegevenswurdboeken, gegevensynventarissen en gegevenskatalogus
Hoewol gegevenswurdboeken, gegevensynventarissen en gegevenskatalogen allegear details biede oer de gegevensaktiva fan in organisaasje, ferskille har omfang en hoemannichte detail.
Wurdboek Data
Gegevenswurdboeken befetsje details oer de struktuer fan 'e gegevens, ynklusyf de nammen en beskriuwingen fan 'e tabellen, fjilden en ferbiningen. Se wurde faak ûntwikkele troch databankbehearders en konsintrearje op spesifike technyske ynformaasje.
Ynventarisaasje fan gegevens
Data-ynventarissen omfetsje details oer de fysike gegevensaktiva, ynklusyf har lokaasje, eigner en feiligensnivo. Se wurde faak ûntwikkele troch IT-ienheden mei in management-rjochte fokus op 'e ynventarisaasje fan gegevensaktiva.
Data Katalogussen
Gegevenskatalogen kombinearje metadata, gegevenslineage, en gegevenskwaliteitynformaasje om in folslein byld te bieden fan 'e gegevensaktiva fan in organisaasje. Se binne bedoeld om brûkerfreonlik en tagonklik te wêzen foar saaklike brûkers, gegevenswittenskippers en oare belanghawwenden dy't de gegevensaktiva moatte begripe en tapasse.
Wichtige dingen om rekken te hâlden
In protte fariabelen moatte wurde beskôge by it ûntwikkeljen fan in gegevenskatalogus. Om te begjinnen is it kritysk om de gegevensboarnen te bepalen dy't moatte wurde opnommen yn 'e katalogus. Dit garandearret dat alle gegevens wurde opnommen en tagonklik.
Boppedat moatte metadata-standerts en prosedueres foar gegevensbestjoer fêststeld wurde om te garandearjen dat de gegevens yn 'e katalogus korrekt, folslein en bywurke binne. Gegevensorganisaasje en tagonklikens binne ek wichtige faktoaren om te beskôgjen, om't de katalogus moat wurde regele op in manier dy't sin makket foar brûkers en maklik beskikber is binnen de gegevensstapel.





Leave a Reply