فهرست مندرجات[پنهان شدن][نمایش]
هوش مصنوعی جدید و بهبود یافته توانایی ها، درک مطلب و ظرفیت تولید تصاویر با وضوح بالاتر را بهبود بخشیده است. ممکن است اخیراً با تصاویر عجیب و جالبی روبرو شده باشید که در سراسر اینترنت شناور هستند.
یک سگ شیبا اینو یک برت و یک یقه یقه اسکی سیاه پوشیده است. و یک سمور دریایی به شیوه «دختری با گوشواره مروارید» نقاش هلندی ورمیر. و یک فنجان سوپ وجود دارد که شبیه یک هیولای پشمالو است.
این تصاویر توسط یک هنرمند انسانی خلق نشده اند.
در عوض، DALL-E 2، یک سیستم هوش مصنوعی جدید که می تواند توضیحات متنی را به تصاویر تبدیل کند، آنها را ایجاد کرد.
به سادگی آنچه را که می خواهید ببینید بنویسید، و هوش مصنوعی آن را برای شما ایجاد می کند - با جزئیات واضح، کیفیت عالی، و در برخی موارد، خلاقیت واقعی. در این پست، نگاهی عمیق به آخرین مطالعه OpenAI، DALL.E 2، و همچنین نحوه عملکرد آن و موارد دیگر خواهیم داشت. بیایید شروع کنیم.
بنابراین ، دقیقاً چیست DALL.E 2?
DALL-E 2 یک "مدل مولد" است، نوعی الگوریتم یادگیری ماشین که به جای انجام وظایف پیشبینی یا طبقهبندی روی دادههای ورودی، خروجی پیچیدهای تولید میکند.
شما DALL-E 2 را با توضیحات مکتوب ارائه می دهید و تصویری مطابق با آن ایجاد می کند. با ترکیب مفاهیم، کیفیتها و سبکها، OpenAI's DALLE 2 میتواند گرافیکها و هنرهای خلاقانه و واقعی را از یک توصیف زبانشناختی اولیه تولید کند.
گفته میشود که آخرین نسخه، DALLE 2، همهکارهتر است و میتواند از زیرنویسها با وضوح بالاتر و در طیف وسیعتری از سبکهای خلاقانه عکس بسازد. به عنوان مثال، تصاویر زیر (از پست وبلاگ DALL-E 2) با توضیح "یک فضانورد سوار بر اسب" ایجاد شده است.
یکی از توضیحات "مانند طرح مداد" نتیجه می گیرد، در حالی که توضیح دیگر "به شیوه ای فوتورئالیستی" نتیجه می گیرد.

همچنین می تواند عکس های موجود را با دقت شگفت انگیزی تغییر دهد. بنابراین، میتوانید با حفظ رنگها، انعکاسها و سایهها، عناصر را اضافه یا حذف کنید، همگی با حفظ ظاهر تصویر اصلی.
چگونه کار می کند؟
DALL-E 2 از مدل های CLIP و Diffusion استفاده می کند، دو مدل پیچیده یادگیری عمیق رویکردهای توسعه یافته در سال های اخیر با این حال، آن را بر اساس همان تصوری است که همه عمیق دیگر شبکه های عصبی: یادگیری بازنمایی CLIP به طور همزمان دو نفر را آموزش می دهد شبکه های عصبی روی عکس ها و کپشن ها
یک شبکه نمایش های بصری در تصویر را می آموزد، در حالی که شبکه دیگر نمایش های متنی را می آموزد. در طول آموزش، دو شبکه سعی می کنند پارامترهای خود را به گونه ای تغییر دهند که تصاویر و توضیحات قابل مقایسه منجر به جاسازی های مشابه شود.
"Diffusion"، نوعی مدل تولیدی که یاد میگیرد با نویز کردن تدریجی و حذف نویز نمونههای آموزشی خود، تصاویر بسازد، دیگر رویکرد یادگیری ماشینی است که در DALL-E 2 استفاده میشود. مدلهای انتشار شبیه به رمزگذارهای خودکار هستند زیرا دادههای ورودی را به نمایش تعبیه شده و سپس از اطلاعات جاسازی برای ایجاد مجدد داده های اصلی استفاده کنید.
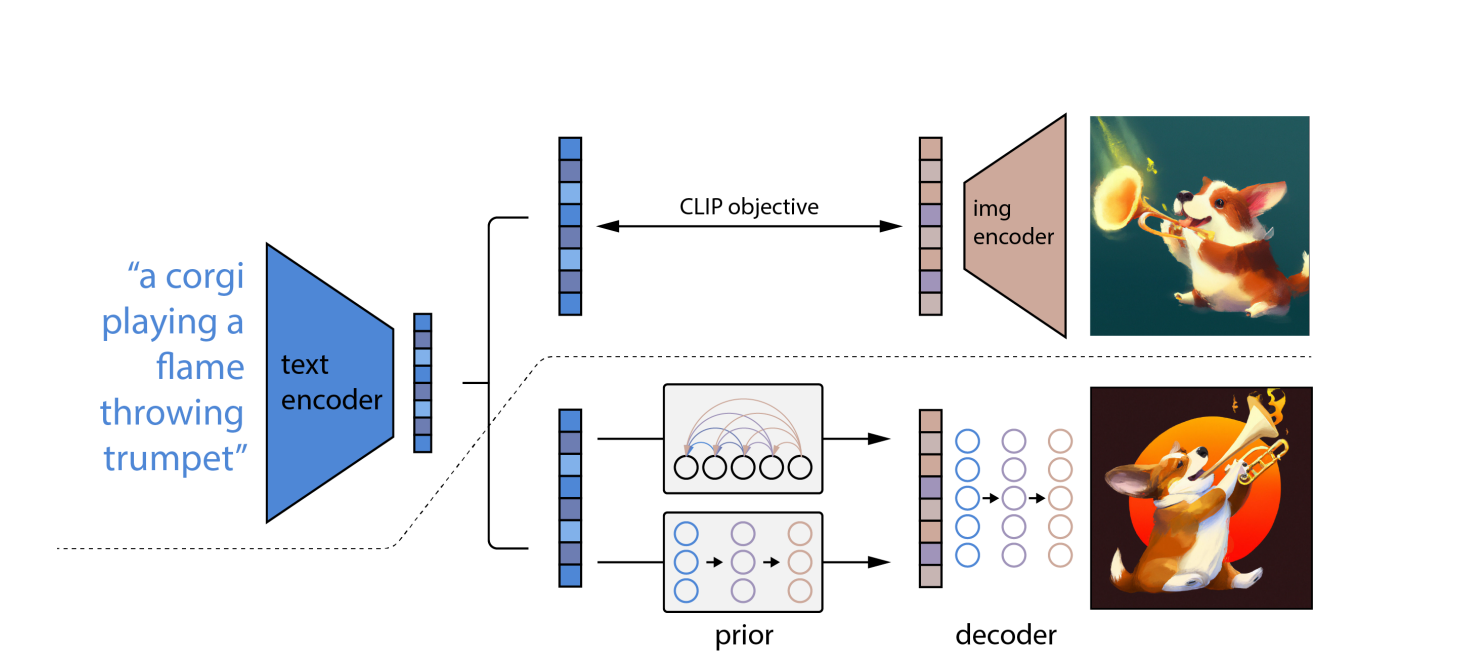
با استفاده از OpenAI مدل زبان CLIP، که میتواند توضیحات متنی را با عکسها مرتبط کند، ابتدا دستور نوشته شده را به شکلی میانی ترجمه میکند که ویژگیهای مهمی را که یک عکس باید داشته باشد برای مطابقت با آن اعلان (طبق CLIP) در خود دارد.
دوم، DALL-E 2 یک CLIP سازگار ایجاد می کند تصویر با استفاده از مدل انتشار، که یک شبکه عصبی است.
در عکس های تحریف شده با پیکسل های تصادفی، مدل های انتشار یاد می شوند. آنها یاد می گیرند که چگونه فرم اصلی عکس ها را بازیابی کنند. مدلهای انتشار میتوانند تصاویر مصنوعی با کیفیت بالا تولید کنند، بهویژه زمانی که همراه با یک رویکرد راهنما استفاده میشوند که دقت را بر تنوع اولویت میدهد.
به عنوان یک نتیجه ، مدل انتشار پیکسلهای تصادفی را میگیرد و از CLIP برای تبدیل آنها به تصویر جدیدی که با عبارت prompt مطابقت دارد، استفاده میکند. به دلیل مفهوم انتشار، DALL-E 2 می تواند تصاویر با وضوح بالاتر را سریعتر از DALL-E تولید کند.
مورد استفاده DALL.E 2
در بیست سال گذشته، بینایی کامپیوتر فناوری از یک مفهوم ساده به یک پیشرفت بزرگ پیشرفت کرده است. با وجود این پیشرفتها، مدلهای تشخیص تصویر و اشیا هنوز با موانع مهمی در زندگی روزمره روبرو هستند. عدم وجود مجموعه داده ها یکی از مهم ترین اشکالات تشخیص تصویر و بینایی کامپیوتری است. از آنجایی که در هر دو طرف کمبود داده وجود دارد، آموزش مدلهای تشخیص تصویر برای ارائه نتایج 100 درصد دقیق تقریباً دشوار است.
خوشبختانه، مدل جدید یادگیری ماشین OpenAI می تواند شکاف در فناوری را پر کند. DALLE 2 قادر است تصاویر شگفت انگیزی را بر اساس توضیحات متنی ایجاد کند. این تولید تصویر جعلی میتواند دادههایی را برای مدلهای تشخیص تصویر بر اساس نیازهای آنها فراهم کند. فقدان داده یک مانع مهم برای شناسایی اشیا و تصویر است.
در عصر دیجیتال، مجموعههای داده در همه جا وجود دارند، با این حال ما همچنان به دنبال میانبرهایی برای تغذیه مدل هوش مصنوعی هستیم، بنابراین میتواند نتایج خوبی ارائه دهد. با این حال، آموزش یک مدل تشخیص تصویر ساده نیست. این نیاز به تعداد زیادی مجموعه داده با تفاوت های کمی دارد، که ممکن است به سادگی قادر به بازیابی آنها نباشیم.
بنابراین، پاسخ چیست: پاسخ DALLE 2 است. مولد تصویر OpenAI، با ظرفیت خود برای تولید تصاویر از متون و تغییر تصاویر موجود، می تواند به پر کردن شکاف کمک کند. این به تولید داده های آموزشی اضافی کمک می کند و در عین حال میزان برچسب گذاری انسانی مورد نیاز را نیز کاهش می دهد. علیرغم مزایای قابل توجه، باید از تولیدات و تصاویر تقلبی تصویری که گنجاندن آن را حذف می کنند، آگاه باشید. این ممکن است منجر به روشهای تشخیص تصویر شود که نتایج مغرضانهای را تولید میکنند.
محدودیت ها
به گفته OpenAI، اگر DALL.E 2 به دست افراد اشتباه بیفتد، ممکن است تأثیر مضری داشته باشد. در دنیای امروزی جعلیهای عمیق، این مدل به راحتی میتواند برای انتشار اطلاعات نادرست یا تصاویر نژادپرستانه استفاده شود، به همین دلیل است که OpenAI فقط به توسعهدهندگان اجازه میدهد از DALL.2 با دعوت استفاده کنند. مدل باید برای همه پیشنهادهایی که دریافت میکند، از محدودیت محتوایی دقیق پیروی کند.
برای حذف پتانسیل DALL.E 2 ایجاد هر گونه عکس خصمانه یا خشونت آمیز، مجموعه داده بدون هیچ گونه سلاح مرگبار ایجاد شد. در حالی که OpenAI اعلام کرده است که قصد دارد آن را در آینده به یک API تبدیل کند، در مورد DALL.E 2، مایل است با احتیاط عمل کند.
نتیجه
DALL-E 2 یکی دیگر از اکتشافات تحقیقاتی جالب OpenAI است که درها را به روی برنامه های جدید باز می کند.
یک مثال ایجاد مجموعه داده های عظیم برای برآورده کردن یکی از گلوگاه های اصلی بینایی کامپیوتر - داده ها است. در حالی که وضعیت اقتصادی بسیاری از برنامههای مبتنی بر DALL-E با قیمت و سیاستهایی تعیین میشود که OpenAI برای کاربران API خود تعیین میکند، بدون شک همه آنها تولید تصویر را پیش خواهند برد.





پاسخ دهید