Los modelos de difusión han arrasado en todo el mundo con el lanzamiento de Desde E 2, Imagen de Google, Difusión establey a mitad de camino, impulsando la innovación y ampliando los límites del aprendizaje automático.
Estos modelos pueden producir una cantidad casi ilimitada de imágenes a partir de indicaciones de palabras, incluidas imágenes fotorrealistas, mágicas, futuristas y, por supuesto, lindas.
Estas capacidades reinventan lo que significa para los humanos interactuar con el silicio, dándonos la capacidad de hacer prácticamente cualquier imagen que podamos imaginar.
A medida que se desarrollen estos modelos o se imponga el próximo paradigma generativo, los humanos podrán producir imágenes, películas y otras experiencias inmersivas con solo un pensamiento.
En esta publicación, discutiremos el modelo de difusión, difusión estable, cómo funciona y un modelo de difusión en tutorial de pintura, entre otras cosas.
¿Qué es el modelo de difusión?
Los modelos de aprendizaje automático que pueden crear nuevos datos a partir de datos de entrenamiento se denominan modelos generativos. Otros modelos generativos incluyen modelos basados en flujo, codificadores automáticos variacionales y redes antagónicas generativas (GAN).
Cada uno puede generar imágenes de excelente calidad. Los modelos de difusión aprenden a recuperar los datos invirtiendo este proceso de adición de ruido después de dañar los datos de entrenamiento al agregar ruido. En otras palabras, los modelos de difusión pueden crear imágenes coherentes a partir del ruido.
Los modelos de difusión aprenden introduciendo ruido en las imágenes, que luego el modelo domina y elimina. Para producir imágenes realistas, el modelo aplica esta técnica de eliminación de ruido a semillas aleatorias.
Al condicionar el proceso de producción de imágenes, estos modelos se pueden usar junto con la guía de texto a imagen para generar una cantidad casi ilimitada de imágenes a partir del texto solamente. Las semillas pueden ser dirigidas por entradas de incrustaciones como CLIP para brindar capacidades sólidas de texto a imagen.
Los modelos de difusión pueden realizar una variedad de tareas, incluida la creación de imágenes, la eliminación de ruido de imágenes, la pintura interna, la pintura externa y la difusión de bits.
Ahora bien, ¿qué es la difusión estable?
Stable Diffusion es un modelo de aprendizaje automático para la creación de imágenes basadas en texto proporcionado por Estabilidad.AI. Es capaz de generar imágenes a partir de texto.
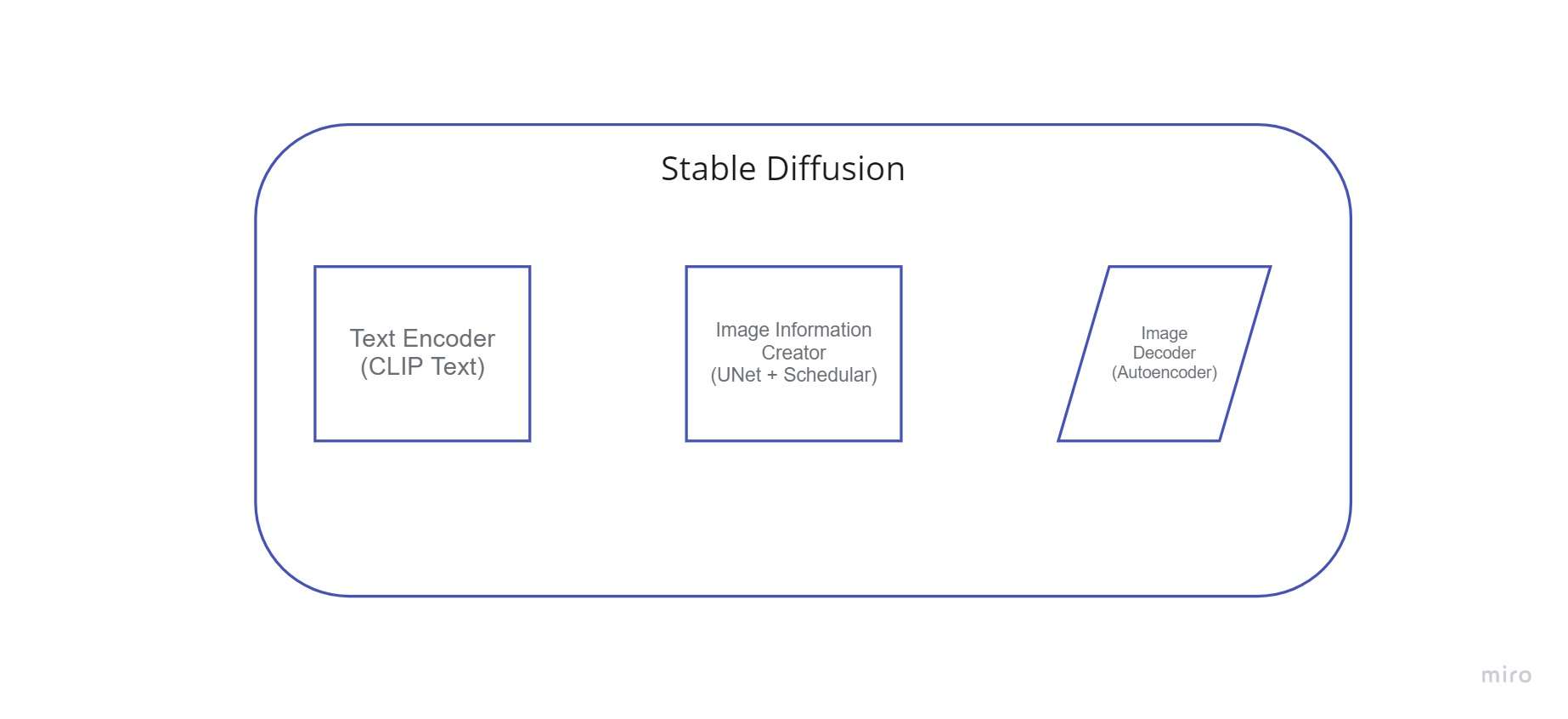
Componentes de la difusión estable
Difusión estable es un sistema compuesto por varios componentes y conceptos. No es un solo modelo. Cuando revisamos detrás del capó, lo primero que vemos es que hay un componente de comprensión de texto que convierte la información del texto en una representación numérica que captura los conceptos del texto.
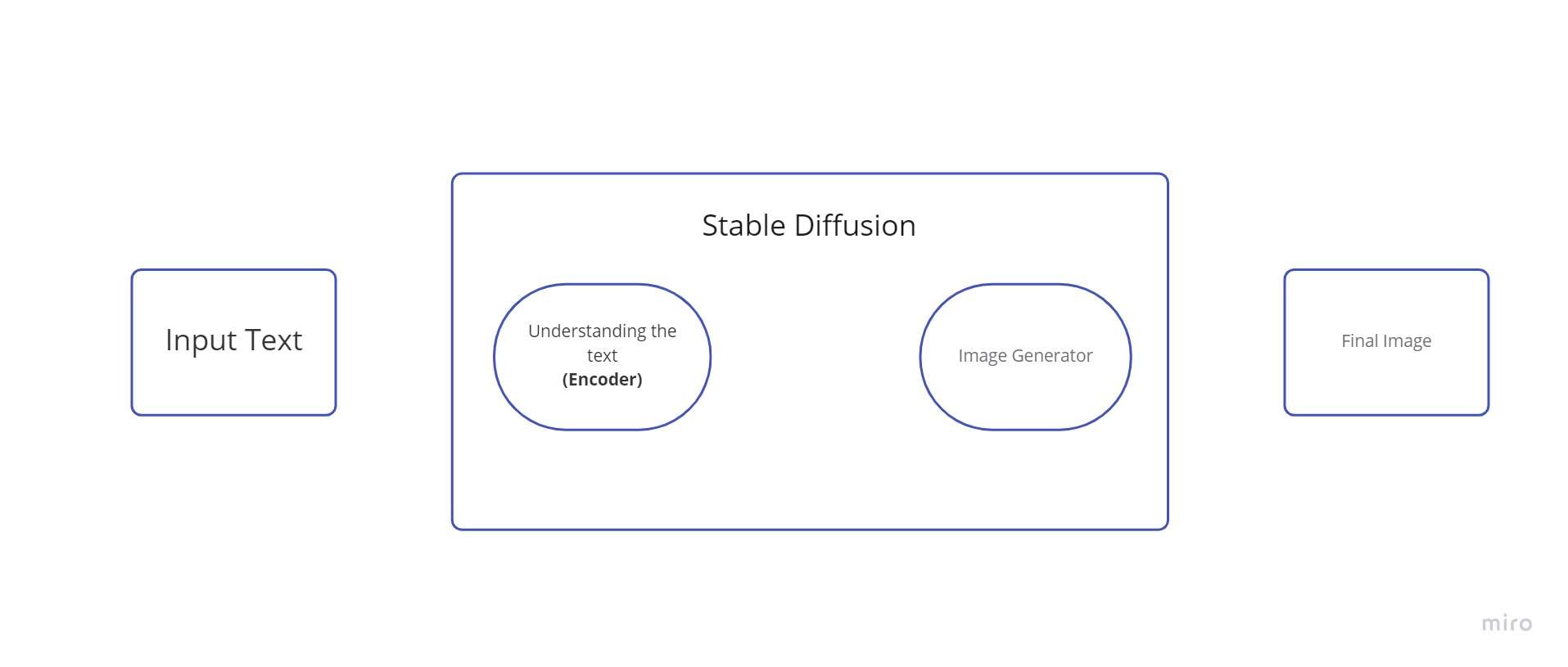
Podemos llamar a este codificador de texto un Transformador modelo de lenguaje (técnicamente: el codificador de texto de un modelo CLIP). Toma el texto de entrada y genera una lista de enteros (un vector) para cada palabra/token en el texto. Luego, esos datos se suministran al Generador de imágenes, que se compone de varios componentes.
Hay dos pasos en el generador de imágenes:
1. Creador de información de imagen
El componente principal de la difusión estable es este elemento. Es donde se realiza la mayor parte de la mejora en el rendimiento con respecto a las versiones anteriores.
Este componente pasa por varias etapas para proporcionar datos de imagen. El creador de la información de la imagen opera solo dentro del espacio de información de la imagen (o espacio latente).
Debido a esta característica, es más rápido que los modelos de difusión anteriores que operaban en el espacio de píxeles. Técnicamente hablando, este componente está compuesto por un algoritmo de programación y un UNet red neural.
El proceso que tiene lugar en este componente se denomina “difusión”. En última instancia, se produce una imagen de alta calidad como resultado del procesamiento de la información en pasos (por el siguiente componente, el decodificador de imágenes).
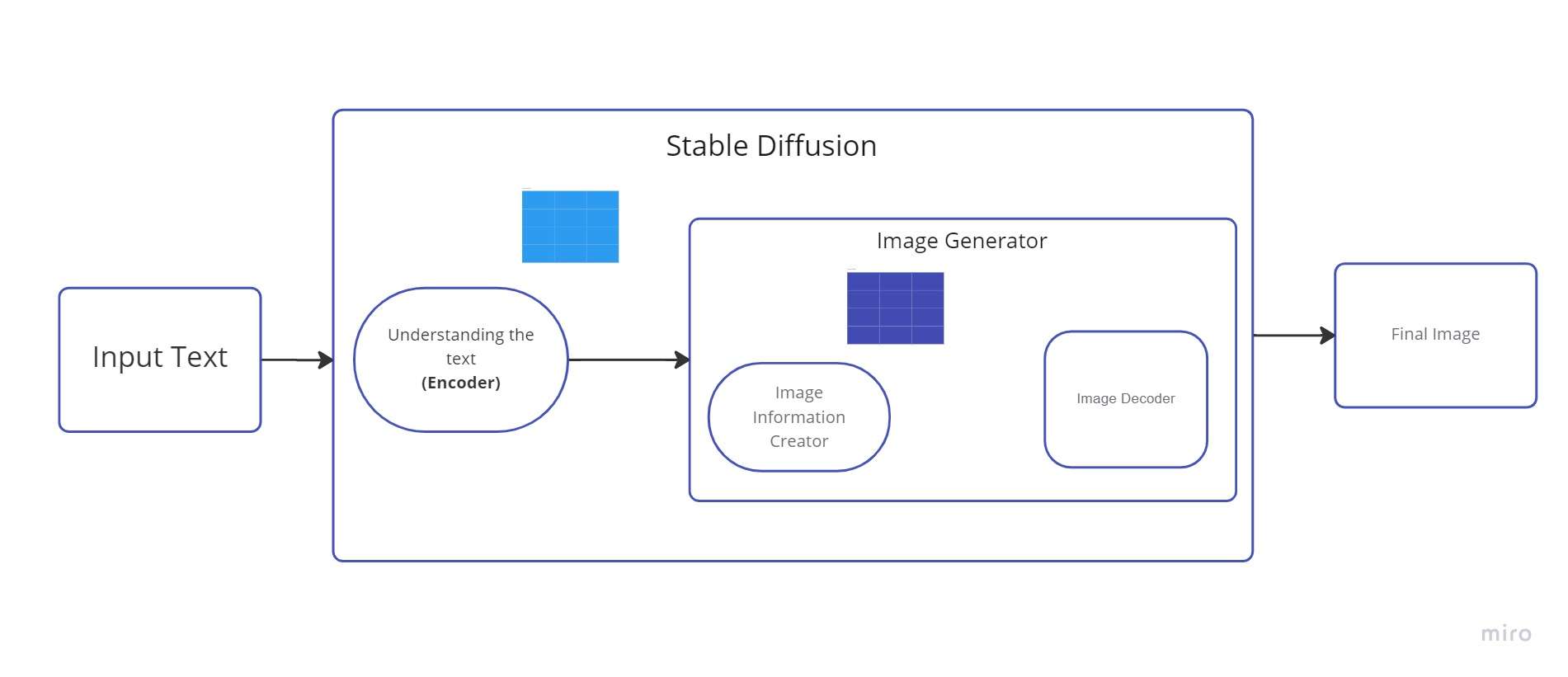
2. Decodificador de imágenes
Usando los datos que recibió del productor de información, el decodificador de imágenes crea una imagen. Solo se ejecuta una vez para crear la imagen de píxeles terminada al final de la operación.
Tutorial de impresión de difusión estable
La pintura de imágenes de difusión estable es la técnica de rellenar áreas faltantes o dañadas de una imagen. El propósito de pintar una imagen es ocultar el hecho de que la imagen ha sido restaurada.
Esta técnica se utiliza con frecuencia para eliminar cosas no deseadas de una imagen o para restaurar áreas dañadas de fotografías históricas. Stable Diffusion Repinting es una forma relativamente reciente de repintar que está produciendo efectos prometedores.
Si sigue las instrucciones a continuación, podrá comenzar a explorar la pintura y modificar las fotos existentes si desea intentar pintar con una difusión estable:
- Ir a Huggingface Impintura de difusión estable
- Sube tu propia imagen
- Borre la parte de su imagen que necesita ser reemplazada.
- Ingrese su mensaje aquí (lo que desea agregar en lugar de lo que está eliminando)
- Seleccione "ejecutar"
En el video de arriba, subimos una foto con tres limones y los cambiamos por manzanas. Personalmente, recomiendo probarlo con sus propias fotografías e indicaciones.
Conclusión
En general, la difusión constante en la pintura es un método excelente para producir imágenes o videos falsos que parecen extremadamente reales. A medida que avanzamos hacia nuevos avances tecnológicos, será cada vez más difícil distinguir entre lo auténtico y lo fraudulento a medida que avanza la tecnología.





La primera mitad no tiene ninguna relación con la segunda mitad. Hubiera sido genial si el autor hubiera explicado cómo funciona inpaint en el marco del modelo que explicó anteriormente, podría haber dado ideas. ¡Pero no! Eso habría requerido una comprensión real, en lugar de recopilar y procesar un texto aleatorio.