¿Qué pasaría si pudiéramos usar la inteligencia artificial para responder a uno de los mayores misterios de la vida: el plegamiento de proteínas? Los científicos han estado trabajando en esto durante décadas.
Las máquinas ahora pueden predecir estructuras de proteínas con una precisión asombrosa utilizando modelos de aprendizaje profundo, alterando el desarrollo de fármacos, la biotecnología y nuestro conocimiento de los procesos biológicos fundamentales.
Únase a mí en una exploración del intrigante reino del plegamiento de proteínas de IA, donde la tecnología de vanguardia choca con la complejidad de la vida misma.
Desentrañando el misterio del plegamiento de proteínas
Las proteínas funcionan en nuestros cuerpos como pequeñas máquinas para llevar a cabo tareas cruciales como descomponer los alimentos o transportar oxígeno. Deben doblarse correctamente para que funcionen de manera efectiva, al igual que una llave debe cortarse correctamente para que encaje en una cerradura. Tan pronto como se crea la proteína, comienza un proceso de plegamiento muy complicado.
El plegamiento de proteínas es el proceso mediante el cual largas cadenas de aminoácidos, los componentes básicos de la proteína, se pliegan en estructuras tridimensionales que dictan la función de la proteína.
Considere una larga cadena de cuentas que debe ordenarse en una forma precisa; esto es lo que ocurre cuando una proteína se pliega. Sin embargo, a diferencia de las perlas, los aminoácidos tienen características únicas e interactúan entre sí de varias maneras, lo que hace que el plegamiento de proteínas sea un proceso complejo y sensible.
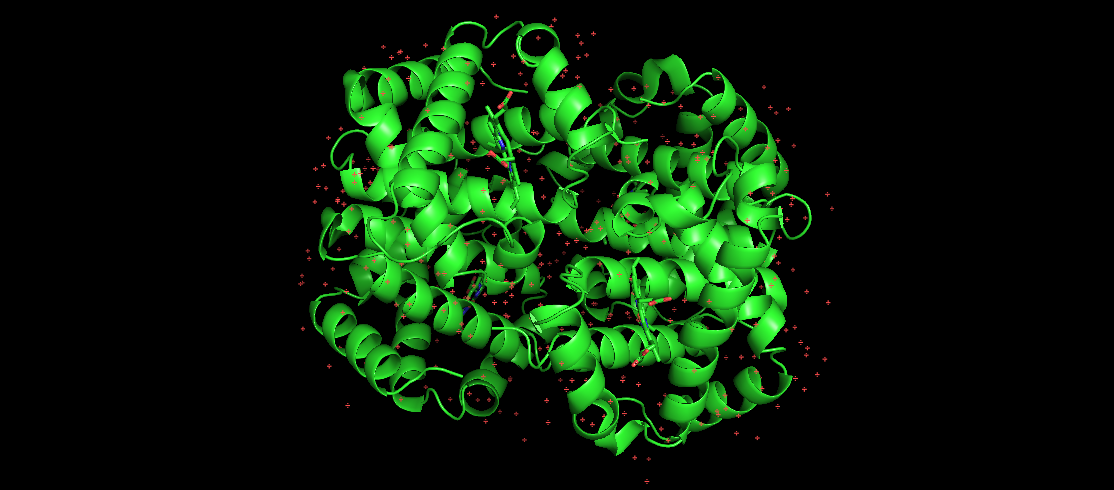
La imagen aquí representa la hemoglobina humana, que es una proteína plegada bien conocida
Las proteínas deben plegarse rápida y precisamente, o se doblarán mal y serán defectuosas. Eso podría conducir a enfermedades como el Alzheimer y el Parkinson. La temperatura, la presión y la presencia de otras moléculas en la célula tienen un efecto en el proceso de plegamiento.
Después de décadas de investigación, los científicos todavía están tratando de averiguar exactamente cómo se pliegan las proteínas.
Afortunadamente, los avances en inteligencia artificial están mejorando el desarrollo en el sector. Los científicos pueden anticipar la estructura de las proteínas con más precisión que nunca utilizando algoritmos de aprendizaje automático para examinar volúmenes masivos de datos.
Esto tiene el potencial de cambiar el desarrollo de medicamentos y aumentar nuestro conocimiento molecular de la enfermedad.
¿Pueden las máquinas funcionar mejor?
Las técnicas convencionales de plegamiento de proteínas tienen limitaciones
Los científicos han estado tratando de descifrar el plegamiento de proteínas durante décadas, pero la complejidad del proceso ha hecho de este un tema desafiante.
Los enfoques convencionales de predicción de la estructura de proteínas utilizan una combinación de metodologías experimentales y modelos informáticos; sin embargo, todos estos métodos tienen inconvenientes.
Las técnicas experimentales como la cristalografía de rayos X y la resonancia magnética nuclear (RMN) pueden llevar mucho tiempo y ser costosas. Además, los modelos informáticos a veces se basan en suposiciones simples, lo que puede conducir a predicciones erróneas.
La IA puede superar estos obstáculos
Por suerte, inteligencia artificial está proporcionando una nueva promesa para una predicción de la estructura de proteínas más precisa y eficiente. Los algoritmos de aprendizaje automático pueden examinar volúmenes masivos de datos. Y descubren patrones que la gente pasaría por alto.
Esto ha resultado en la creación de nuevas herramientas y plataformas de software capaces de predecir la estructura de proteínas con una precisión sin igual.
Los algoritmos de aprendizaje automático más prometedores para la predicción de la estructura de proteínas
El sistema AlphaFold creado por Google Mente profunda El equipo es uno de los avances más prometedores en esta área. Ha logrado un gran progreso en los últimos años mediante el uso de algoritmos de aprendizaje profundo para predecir la estructura de las proteínas en función de sus secuencias de aminoácidos.
Las redes neuronales, las máquinas de vectores de soporte y los bosques aleatorios se encuentran entre los métodos de aprendizaje automático más prometedores para predecir la estructura de las proteínas.
Estos algoritmos pueden aprender de enormes conjuntos de datos. Y pueden anticipar las correlaciones entre diferentes aminoácidos. Entonces, veamos cómo funciona.

Análisis coevolutivos y la primera generación AlphaFold
El éxito de AlphaFold se basa en un modelo de red neuronal profunda que se desarrolló utilizando análisis coevolutivo. El concepto de coevolución establece que si dos aminoácidos en una proteína interactúan entre sí, se desarrollarán juntos para mantener su vínculo funcional.
Los investigadores pueden detectar qué pares de aminoácidos es probable que estén en contacto en la estructura 3D comparando las secuencias de aminoácidos de numerosas proteínas similares.
Estos datos sirven como base para la primera iteración de AlphaFold. Predice las longitudes entre los pares de aminoácidos, así como los ángulos de los enlaces peptídicos que los unen. Este método superó todos los enfoques anteriores para predecir la estructura de la proteína a partir de la secuencia, aunque la precisión aún estaba restringida para las proteínas sin plantillas aparentes.

AlphaFold 2: una metodología radicalmente nueva
AlphaFold2 es un software de computadora creado por DeepMind que usa la secuencia de aminoácidos de una proteína para predecir la estructura 3D de la proteína.
Esto es importante porque la estructura de una proteína dicta cómo funciona, y comprender su función puede ayudar a los científicos a desarrollar medicamentos que se dirijan a la proteína.
La red neuronal AlphaFold2 recibe como entrada la secuencia de aminoácidos de la proteína, así como detalles sobre cómo se compara esa secuencia con otras secuencias en una base de datos (esto se denomina "alineación de secuencias").
La red neuronal hace una predicción sobre la estructura 3D de la proteína basada en esta entrada.
¿Qué lo diferencia de AlphaFold2?
A diferencia de otros enfoques, AlphaFold2 predice la estructura 3D real de la proteína en lugar de simplemente la separación entre pares de aminoácidos o los ángulos entre los enlaces que los conectan (como lo hacían los algoritmos anteriores).
Para que la red neuronal anticipe la estructura completa a la vez, la estructura se codifica de extremo a extremo.
Otra característica clave de AlphaFold2 es que ofrece una estimación de la confianza que tiene en su pronóstico. Esto se presenta como un código de colores en la estructura anticipada, donde el rojo representa alta confianza y el azul sugiere baja confianza.
Esto es útil ya que informa a los científicos sobre la estabilidad de la predicción.
Predicción de la estructura combinada de varias secuencias
La última expansión de Alphafold2, conocida como Alphafold Multimer, pronostica la estructura combinada de varias secuencias. Todavía tiene altas tasas de error incluso si funciona mucho mejor que las técnicas anteriores. Solo el 25% de los 4500 complejos de proteínas se predijeron con éxito.
El 70% de las regiones rugosas de formación de contactos se predijeron correctamente, pero la orientación relativa de las dos proteínas fue incorrecta. Cuando la profundidad de alineación mediana es inferior a aproximadamente 30 secuencias, la precisión de las predicciones del multímero Alphafold disminuye significativamente.
Cómo utilizar las predicciones de Alphafold
Los modelos predichos de AlphaFold se ofrecen en los mismos formatos de archivo y se pueden usar de la misma manera que las estructuras experimentales. Es fundamental tener en cuenta las estimaciones de precisión que ofrece el modelo para evitar malentendidos.
Es especialmente útil para estructuras complicadas como homómeros entrelazados o proteínas que solo se pliegan en presencia de un
ligando desconocido.
Algunos desafíos
El principal problema en el uso de estructuras predichas es la comprensión de la dinámica, la selectividad del ligando, el control, la alostería, los cambios postraduccionales y la cinética de unión sin acceso a datos biofísicos y de proteínas.
Aprendizaje automático y la investigación de dinámica molecular basada en la física se puede utilizar para superar este problema.
Estas investigaciones pueden beneficiarse de una arquitectura informática especializada y eficiente. Si bien AlphaFold ha logrado enormes avances en la predicción de estructuras de proteínas, aún queda mucho por aprender en el campo de la biología estructural, y las predicciones de AlphaFold son solo el punto de partida para estudios futuros.
¿Cuáles son otras herramientas notables?
RosaTTADoblar
RoseTTAFold, creada por investigadores de la Universidad de Washington, también emplea algoritmos de aprendizaje profundo para predecir estructuras de proteínas, pero también integra un enfoque novedoso conocido como "simulaciones de dinámica de ángulo de torsión" para mejorar las estructuras predichas.
Este método ha arrojado resultados alentadores y puede ser útil para superar las limitaciones de las herramientas de plegamiento de proteínas AI existentes.
trRosetta
Otra herramienta, trRosetta, predice el plegamiento de proteínas usando un red neural entrenado en millones de secuencias y estructuras de proteínas.
También utiliza una técnica de "modelado basado en plantillas" para crear predicciones más precisas al comparar la proteína objetivo con estructuras conocidas comparables.
Se ha demostrado que trRosetta es capaz de predecir las estructuras de proteínas diminutas y complejos proteicos.
DeepMetaPSICOV
DeepMetaPSICOV es otra herramienta que se enfoca en predecir mapas de contactos de proteínas. Estos se utilizan como guía para predecir el plegamiento de proteínas. Usa deep learning enfoques para pronosticar la probabilidad de interacciones de residuos dentro de una proteína.
Estos se utilizan posteriormente para pronosticar el mapa de contacto general. DeepMetaPSICOV ha demostrado potencial en la predicción de estructuras de proteínas con gran precisión, incluso cuando los enfoques anteriores han fallado.
¿Qué nos depara el futuro?
El futuro del plegamiento de proteínas de IA es brillante. Los algoritmos basados en el aprendizaje profundo, en particular AlphaFold2, han logrado grandes avances recientemente en la predicción confiable de estructuras de proteínas.
Este hallazgo tiene el potencial de transformar el desarrollo de fármacos al permitir que los científicos comprendan mejor la estructura y función de las proteínas, que son objetivos terapéuticos comunes.
No obstante, quedan cuestiones como la previsión de complejos proteicos y la detección del estado funcional real de las estructuras previstas. Se requiere más investigación para resolver estos problemas y aumentar la precisión y confiabilidad de los algoritmos de plegamiento de proteínas de IA.
Sin embargo, los beneficios potenciales de esta tecnología son enormes y tiene el potencial de conducir a la producción de medicamentos más efectivos y precisos.





Deje un comentario