Vivimos tiempos emocionantes, con anuncios sobre tecnología de punta cada semana. OpenAI acaba de lanzar el modelo de vanguardia de texto a imagen DALLE 2.
Solo unas pocas personas obtuvieron acceso temprano a un nuevo sistema de inteligencia artificial que puede generar gráficos realistas a partir de descripciones en lenguaje natural. Todavía está cerrado al público.
Stability AI luego lanzó el Difusión estable modelo, una variante de código abierto de DALLE2. Este lanzamiento lo ha alterado todo. La gente en Internet publicaba resultados rápidos y se sorprendía con el arte realista.
¿Qué es la difusión estable?
Difusión estable es un modelo de aprendizaje automático capaz de crear imágenes a partir de texto, cambiar imágenes según el texto y completar detalles en imágenes de baja resolución o con poco detalle.
Se entrenó en miles de millones de fotos y puede ofrecer resultados equivalentes a DALL-E2 y Medio viaje. Estabilidad IA lo inventó y se hizo público el 22 de agosto de 2022.
Pero con recursos informáticos locales limitados, el modelo de difusión estable tarda mucho tiempo en crear imágenes de alta calidad. Ejecutar el modelo en línea utilizando un proveedor de la nube nos brinda recursos computacionales casi infinitos y nos permite obtener excelentes resultados mucho más rápido.
Alojar el modelo como un microservicio también permite que otras aplicaciones creativas exploten más fácilmente el potencial del modelo sin tener que lidiar con las complejidades de ejecutar modelos ML en línea.
En esta publicación, intentaremos demostrar cómo desarrollar un modelo de difusión estable e implementarlo en AWS.
Cree e implemente difusión estable
BentoML y Amazon Web Services EC2 son dos opciones para alojar el modelo Stable Diffusion en línea. BentoML es un marco de código abierto para escalar máquina de aprendizaje servicios. Con BentoML, crearemos un servicio de dispersión confiable y lo implementaremos en AWS EC2.
Preparación del entorno y descarga del modelo de difusión estable
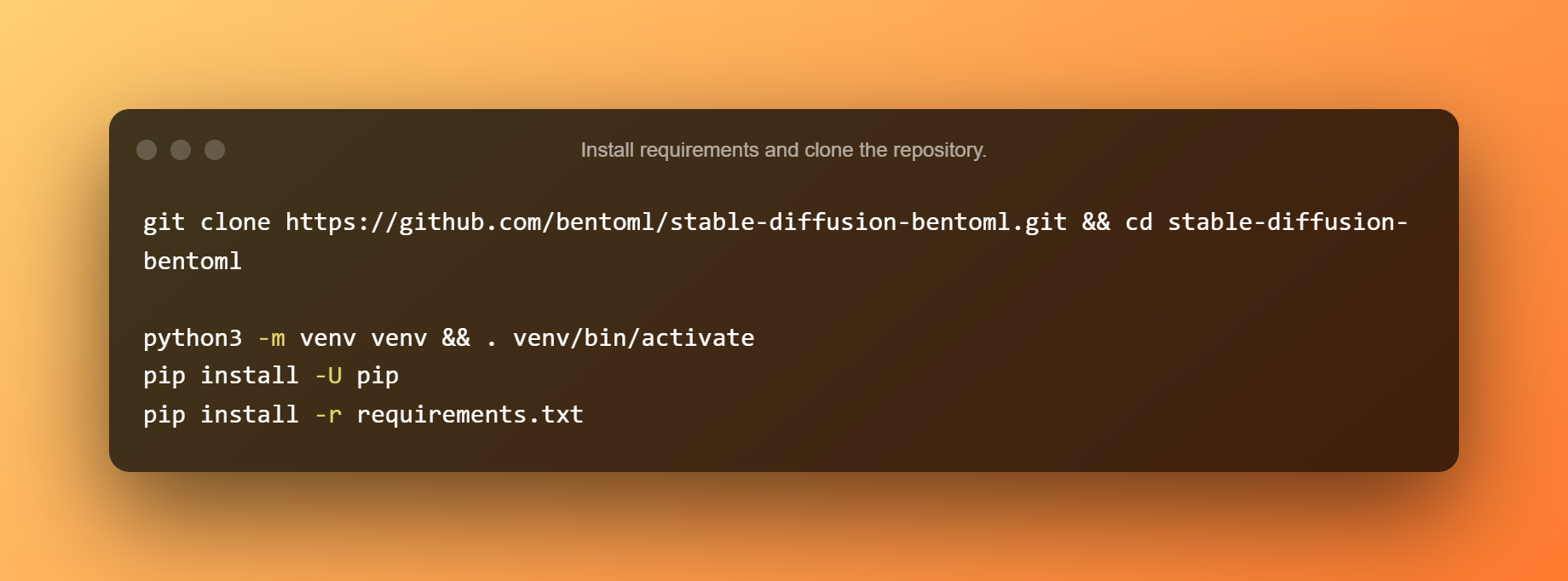
Instale los requisitos y clone el repositorio.
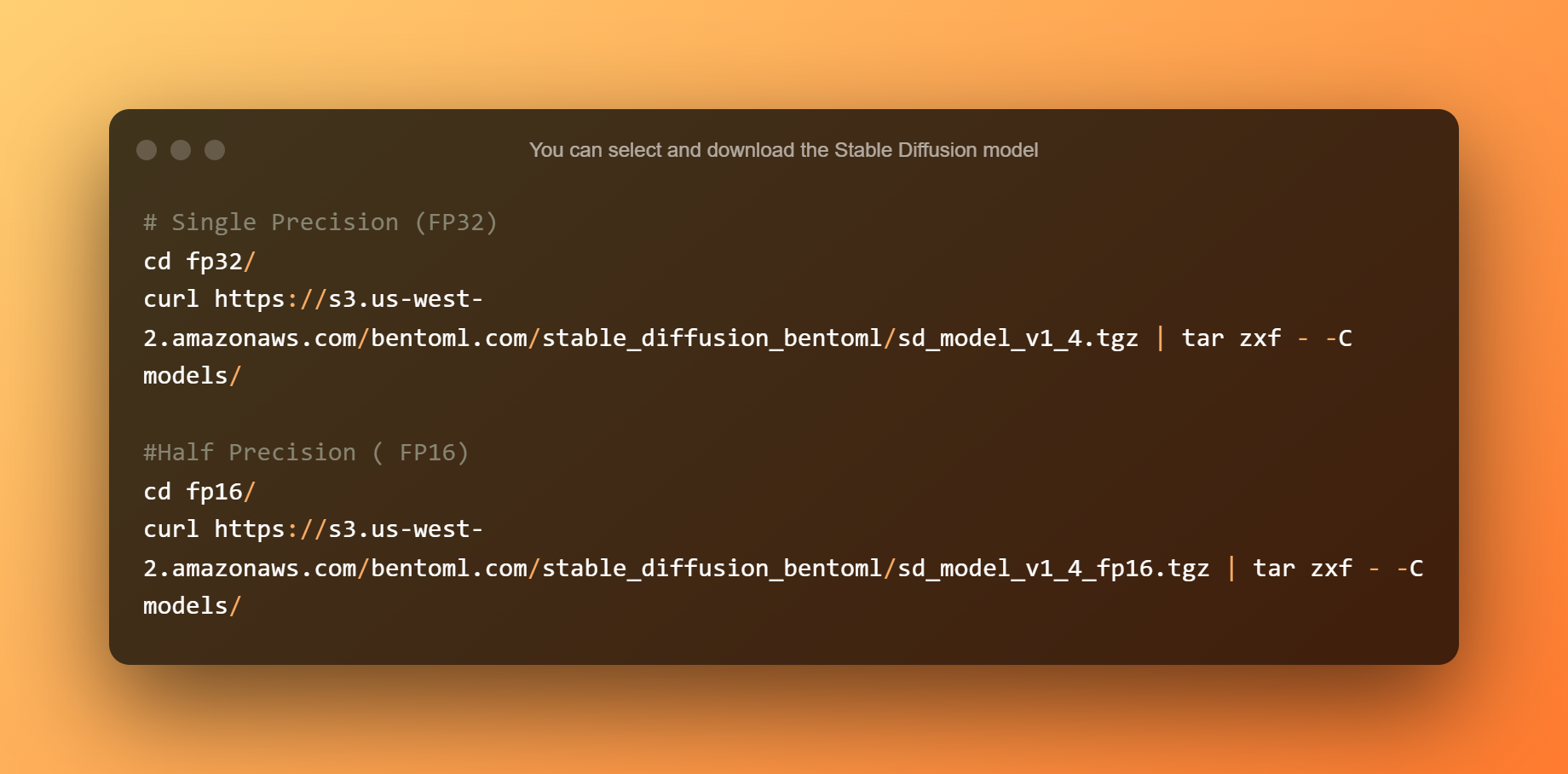
Puede seleccionar y descargar el modelo Stable Diffusion. La precisión simple es adecuada para CPU o GPU con más de 10 GB de VRAM. La precisión media es ideal para GPU con menos de 10 GB de VRAM.
Difusión estable del edificio
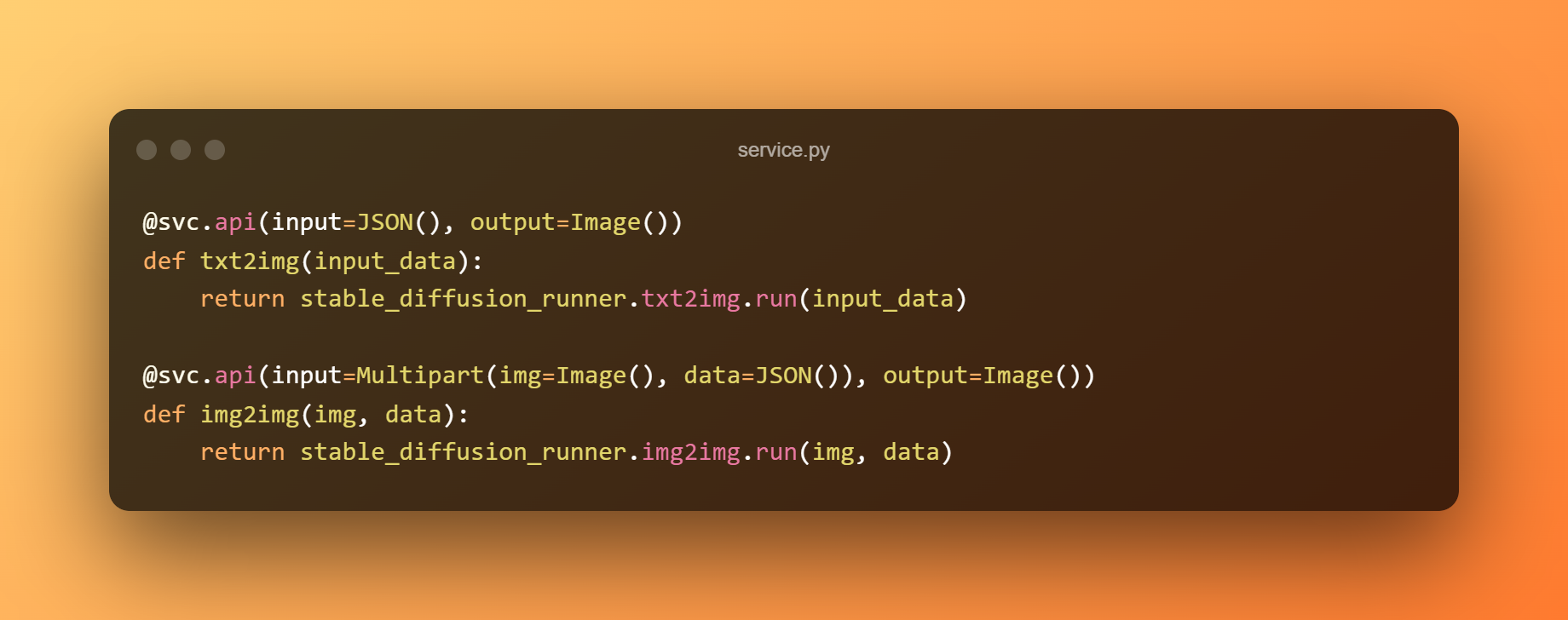
Construiremos un servicio BentoML para servir el modelo detrás de un API RESTful. El siguiente ejemplo usa el modelo de precisión simple para la predicción y el módulo service.py para conectar el servicio a la lógica empresarial. Podemos exponer las funciones como API etiquetándolas con @svc.api.
Además, podemos definir los tipos de entrada y salida de las API en los parámetros. El punto final txt2img, por ejemplo, recibe una entrada JSON y produce una salida Imagen, mientras que el punto final img2img acepta una entrada Imagen y JSON y devuelve una salida Imagen.
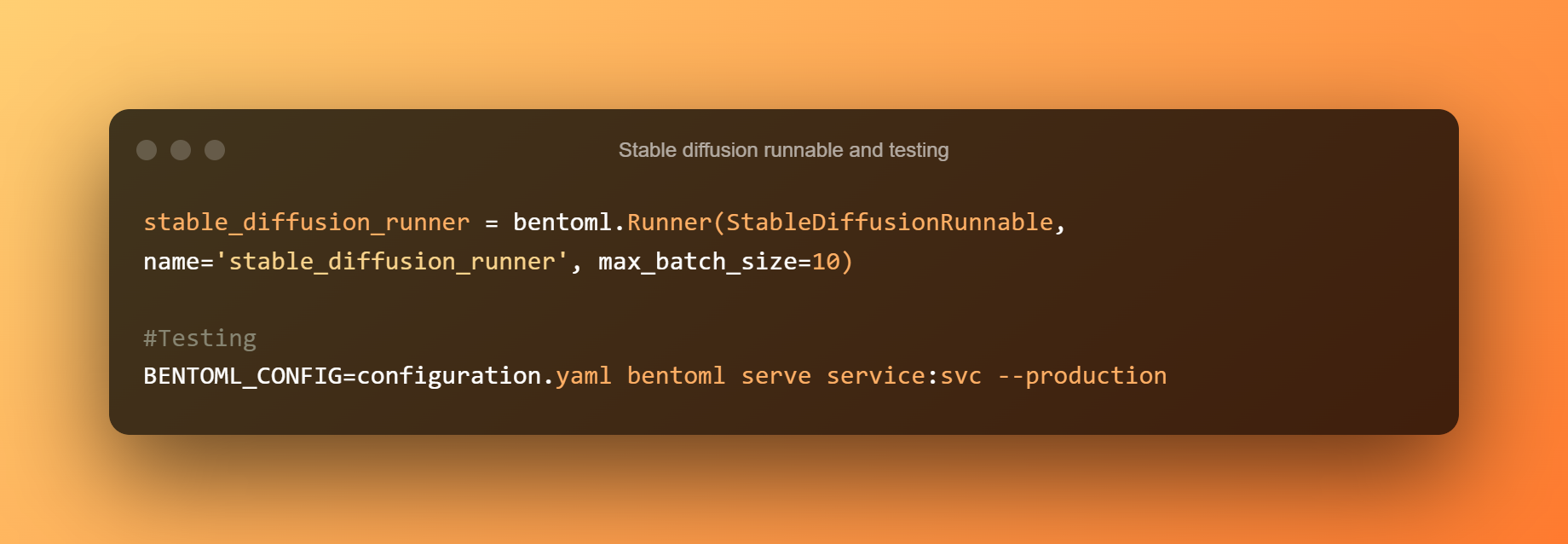
Un StableDiffusionRunnable define la lógica de inferencia esencial. El ejecutable está a cargo de ejecutar los métodos de tubería txt2img del modelo y enviar las entradas relevantes. Para ejecutar la lógica de inferencia del modelo en las API, se crea un Runner personalizado a partir de StableDiffusionRunnable.
Luego, use el siguiente comando para iniciar un servicio BentoML para realizar pruebas. ejecutar localmente el Modelo de difusión estable la inferencia en las CPU es bastante lenta. Cada solicitud tardará unos 5 minutos en procesarse.
Texto a imagen
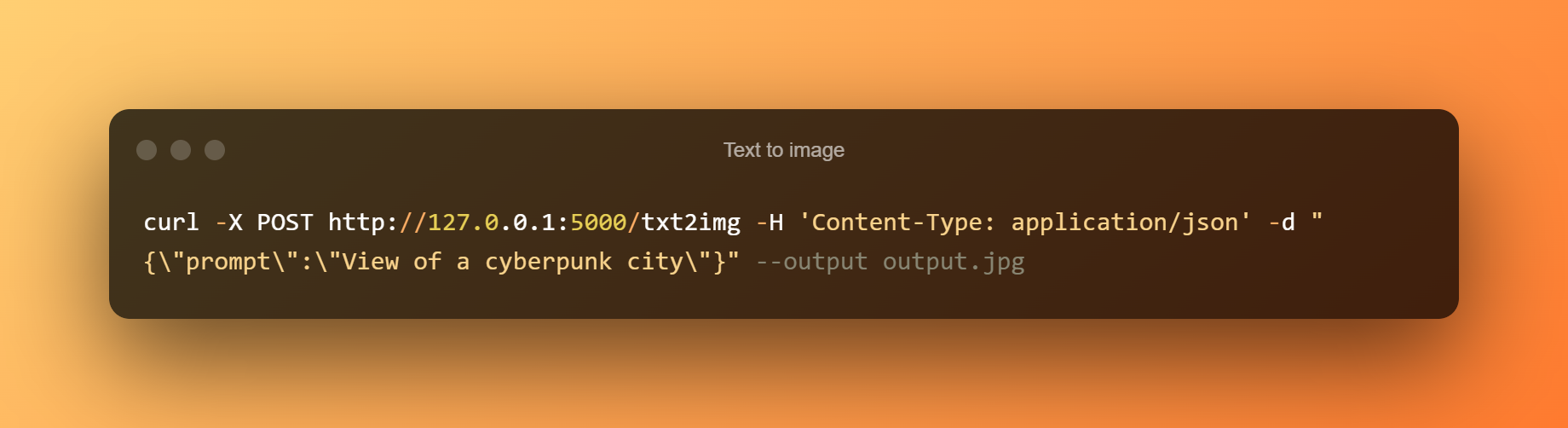
Salida de texto a imagen

El archivo bentofile.yaml define los archivos y las dependencias necesarios.
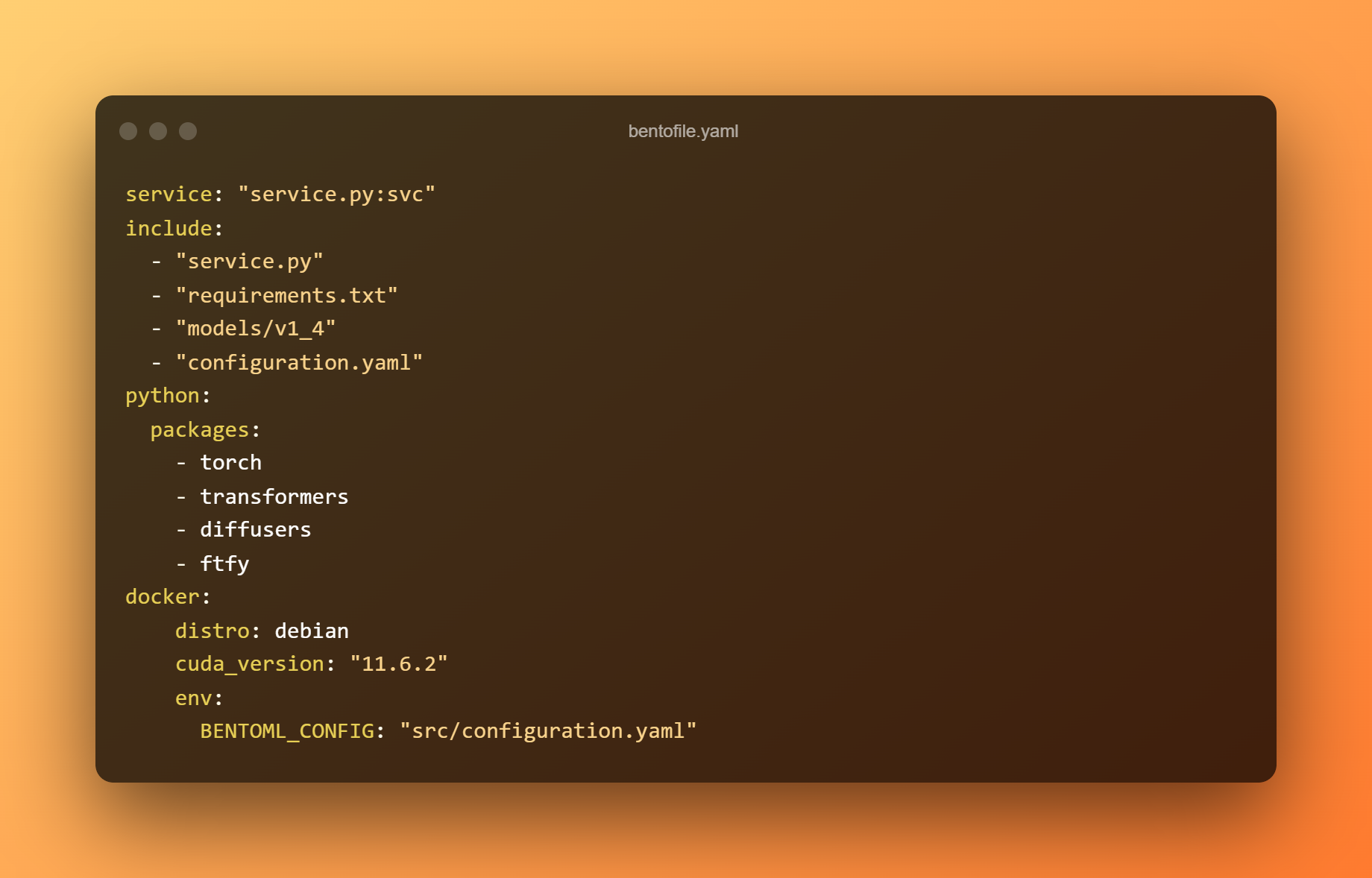
Use el siguiente comando para construir un bento. Un Bento es el formato de distribución de un servicio BentoML. Es un archivo autónomo que contiene todos los datos y configuraciones necesarios para iniciar el servicio.

El bento de difusión estable se ha completado. Si no pudo generar correctamente el bento, no entre en pánico; puede descargar el modelo preconstruido usando los comandos que se enumeran en la siguiente sección.
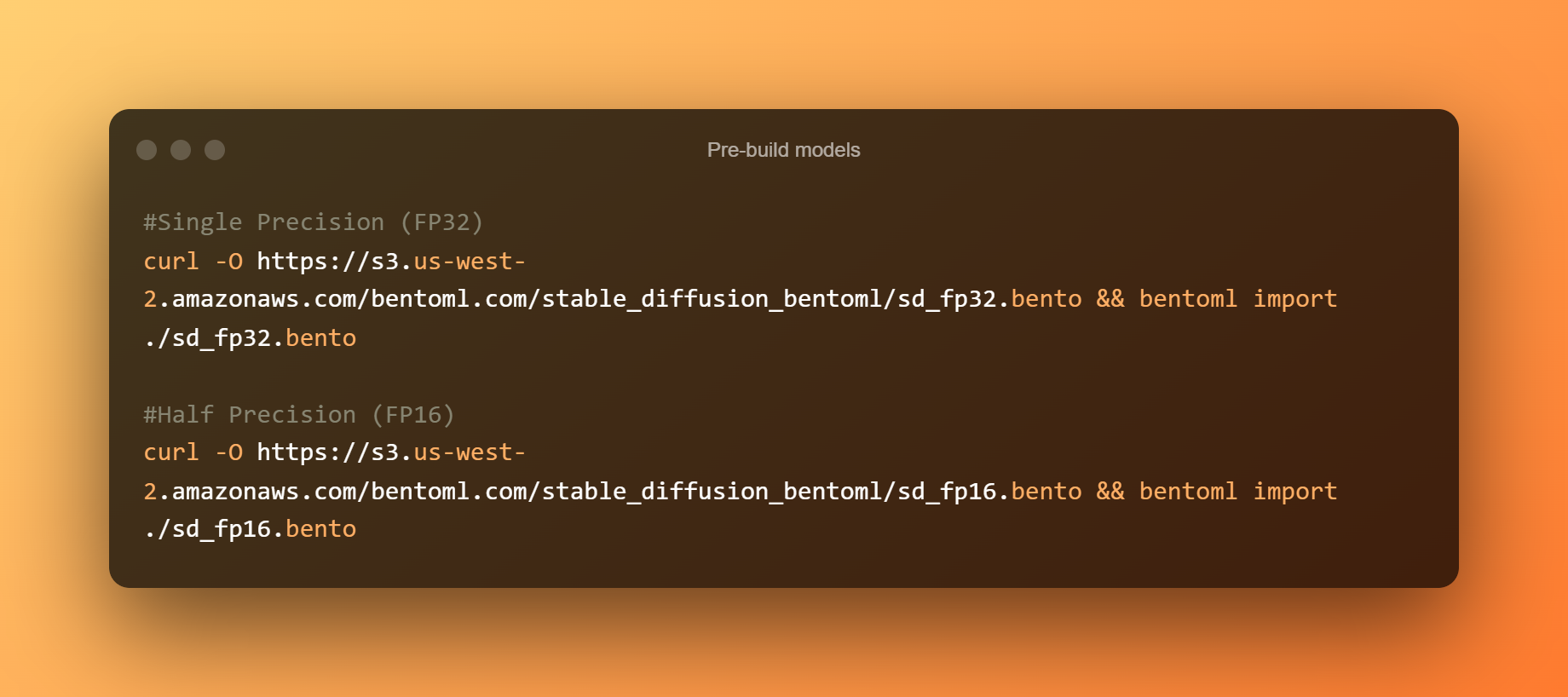
Modelos preconstruidos
Los siguientes son los modelos prefabricados:
Implementar el modelo de difusión estable en EC2
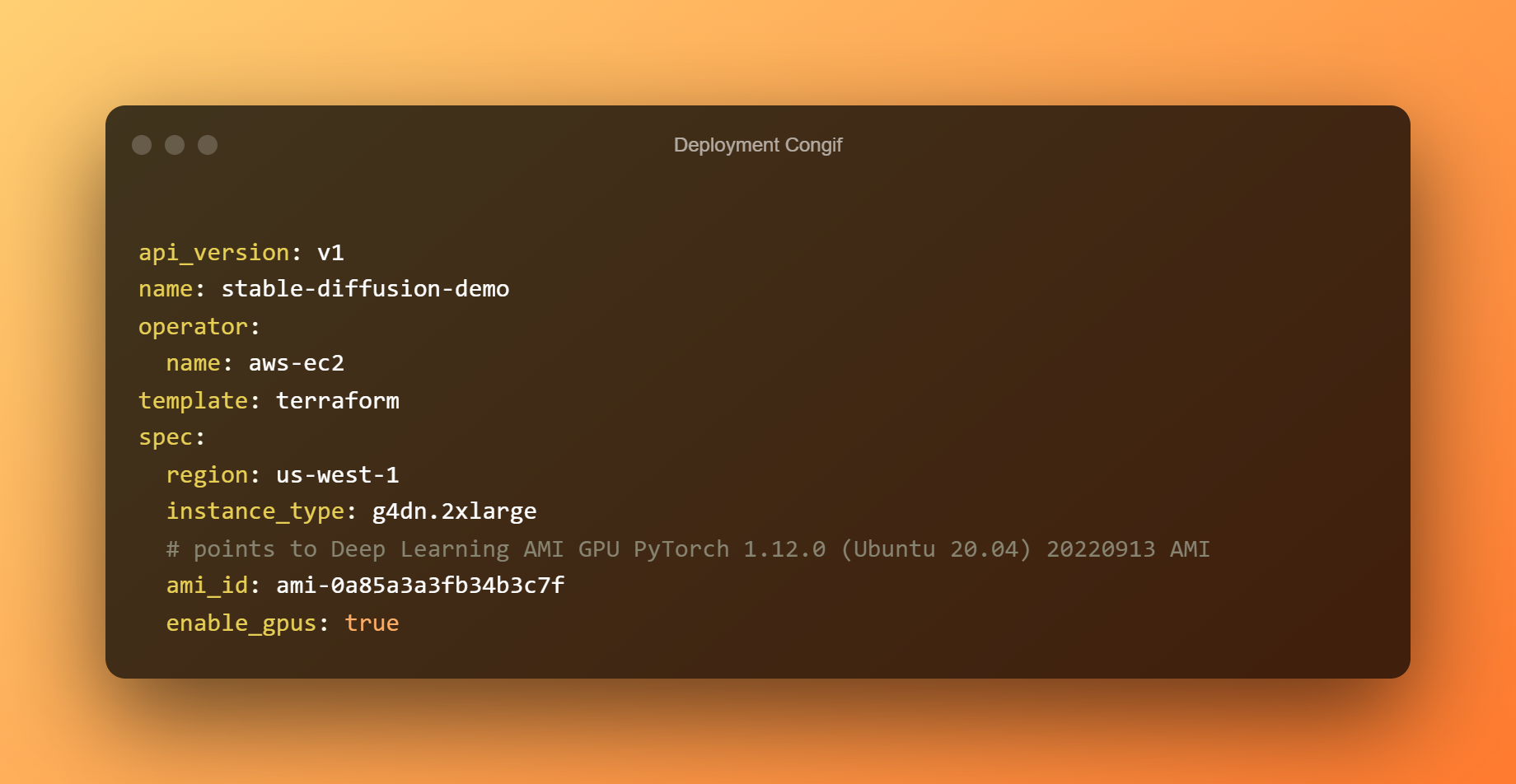
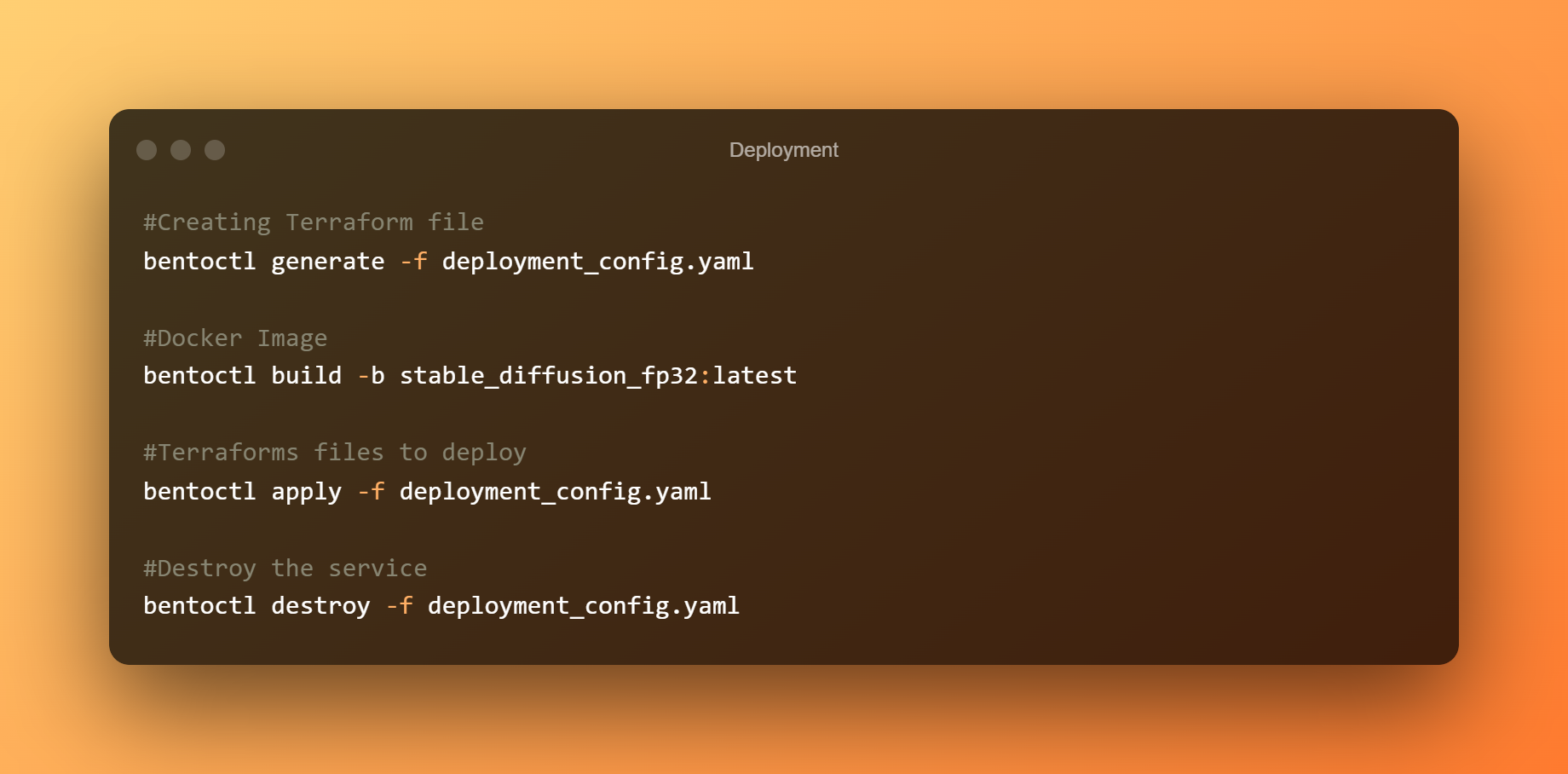
Para implementar el bento en EC2, usaremos bentoctl. bentoctl puede permitirle implementar sus bentos en cualquier plataforma en la nube utilizando Terraform. Para crear y aplicar archivos de Terraform, instale el operador AWS EC2.

En el archivo deployment config.yaml, la implementación ya se configuró. Por favor, siéntase libre de editar según sus requisitos. Bento se implementa de manera predeterminada en un host g4dn.xlarge con el Aprendizaje profundo AMI GPU PyTorch 1.12.0 (Ubuntu 20.04) AMI en la región us-west-1.
Cree los archivos de Terraform ahora. Cree la imagen de Docker y cárguela en AWS ECR. Dependiendo de su ancho de banda, la carga de imágenes puede demorar mucho tiempo. Al implementar el bento en AWS EC2, use los archivos de Terraform.
Para acceder a la interfaz de usuario de Swagger, conéctese a la consola EC2 y abra la dirección IP pública en un navegador. Finalmente, si ya no se requiere el servicio Stable Diffusion BentoML, elimine la implementación.
Conclusión
Debería poder ver lo fascinantes y poderosos que son SD y sus modelos complementarios. El tiempo dirá si iteraremos más en el concepto o pasaremos a enfoques más sofisticados.
Sin embargo, actualmente hay iniciativas en marcha para entrenar modelos más grandes con ajustes para comprender mejor el entorno y las instrucciones. Intentamos desarrollar el servicio Stable Diffusion usando BentoML y lo implementamos en AWS EC2.
Pudimos ejecutar el modelo Stable Diffusion en un hardware más potente, crear imágenes con baja latencia y extendernos más allá de una sola computadora al implementar el servicio en AWS EC2.





Deje un comentario