KI ist überall, aber manchmal kann es schwierig sein, die Terminologie und den Fachjargon zu verstehen. In diesem Blogbeitrag erklären wir über 50 KI-Begriffe und -Definitionen, damit Sie diese schnell wachsende Technologie besser verstehen können.
Egal, ob Sie Anfänger oder Experte sind, wir wetten, dass es hier ein paar Begriffe gibt, die Sie nicht kennen!
1. Künstliche Intelligenz
Künstliche Intelligenz (KI) bezieht sich auf die Entwicklung von Computersystemen, die die Fähigkeit haben, unabhängig zu lernen und zu funktionieren, oft durch Nachahmung menschlicher Intelligenz.
Diese Systeme analysieren Daten, erkennen Muster, treffen Entscheidungen und passen ihr Verhalten auf der Grundlage von Erfahrungen an. Durch die Nutzung von Algorithmen und Modellen zielt die KI darauf ab, intelligente Maschinen zu schaffen, die in der Lage sind, ihre Umgebung wahrzunehmen und zu verstehen.
Das ultimative Ziel besteht darin, Maschinen in die Lage zu versetzen, Aufgaben effizient auszuführen, aus Daten zu lernen und ähnliche kognitive Fähigkeiten wie Menschen zu entwickeln.
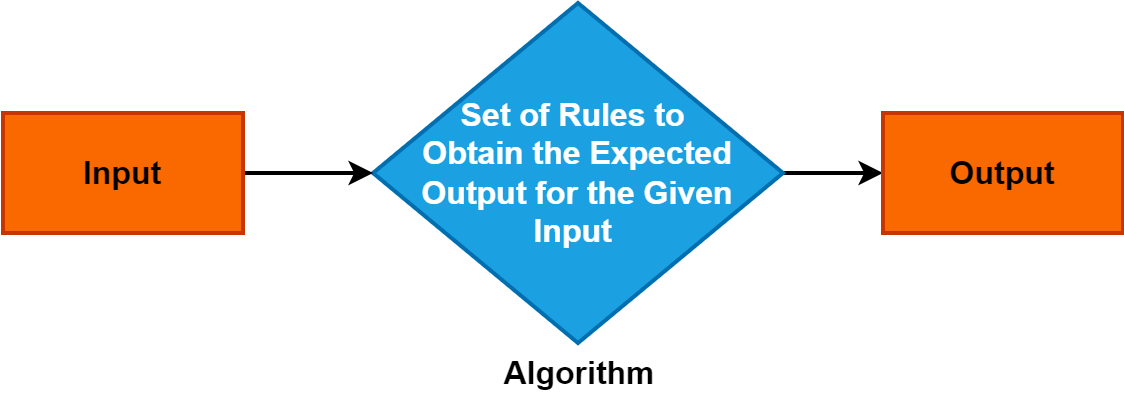
2. Algorithmus
Ein Algorithmus ist ein präziser und systematischer Satz von Anweisungen oder Regeln, die den Prozess der Lösung eines Problems oder der Erledigung einer bestimmten Aufgabe leiten.
Es dient als grundlegendes Konzept in verschiedenen Bereichen und spielt eine zentrale Rolle in der Informatik, Mathematik und Problemlösungsdisziplinen. Das Verständnis von Algorithmen ist von entscheidender Bedeutung, da sie effiziente und strukturierte Problemlösungsansätze ermöglichen und Fortschritte in Technologie und Entscheidungsprozessen vorantreiben.
3. Große Daten
Unter Big Data versteht man extrem große und komplexe Datensätze, die die Möglichkeiten herkömmlicher Analysemethoden übersteigen. Diese Datensätze zeichnen sich typischerweise durch ihr Volumen, ihre Geschwindigkeit und ihre Vielfalt aus.
Unter Volumen versteht man die große Datenmenge, die aus verschiedenen Quellen generiert wird, z Social Media, Sensoren und Transaktionen.
Unter Geschwindigkeit versteht man die hohe Geschwindigkeit, mit der Daten generiert werden und in Echtzeit oder nahezu in Echtzeit verarbeitet werden müssen. Vielfalt bezeichnet die verschiedenen Arten und Formate von Daten, einschließlich strukturierter, unstrukturierter und halbstrukturierter Daten.
4. Data Mining
Data Mining ist ein umfassender Prozess, der darauf abzielt, wertvolle Erkenntnisse aus riesigen Datensätzen zu gewinnen.
Es umfasst vier Schlüsselphasen: Datenerfassung, einschließlich der Erfassung relevanter Daten; Datenaufbereitung, Sicherstellung der Datenqualität und -kompatibilität; Durchsuchen der Daten und Einsatz von Algorithmen zur Entdeckung von Mustern und Beziehungen; und Datenanalyse und -interpretation, bei der das extrahierte Wissen untersucht und verstanden wird.
5. Neuronales Netzwerk
Ein Computersystem ist so konzipiert, dass es wie folgt funktioniert menschliches Gehirn, bestehend aus miteinander verbundenen Knoten oder Neuronen. Lassen Sie uns dies etwas genauer verstehen, da die meisten KI darauf basieren Neuronale Netze.
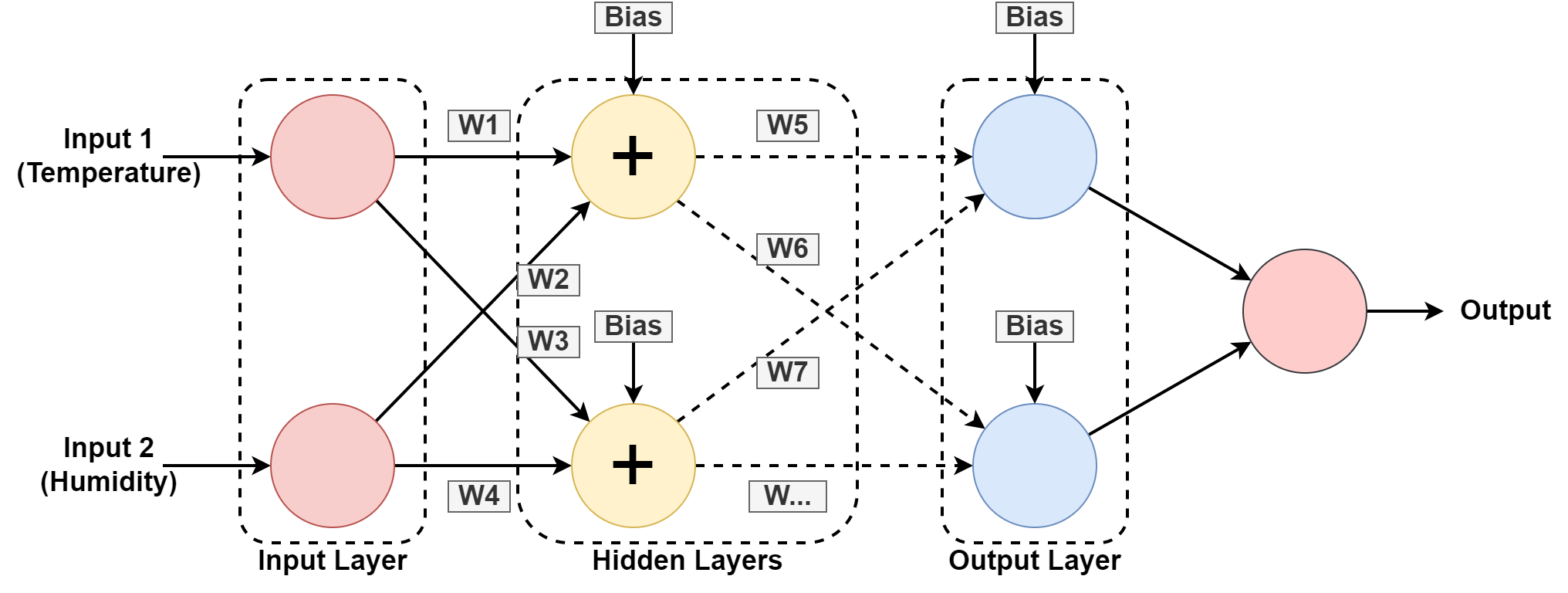
In den obigen Grafiken sagen wir die Luftfeuchtigkeit und Temperatur eines geografischen Standorts voraus, indem wir aus dem Muster der Vergangenheit lernen. Die Eingaben sind der Datensatz für den vergangenen Datensatz.
Das Neuronales Netzwerk lernt das Muster, indem Sie mit Gewichten spielen und Bias-Werte in den verborgenen Ebenen anwenden. W1, W2….W7 sind die jeweiligen Gewichte. Es trainiert sich selbst anhand des bereitgestellten Datensatzes und gibt die Ausgabe als Vorhersage aus.
Diese komplexen Informationen könnten Sie überfordern. Wenn dies der Fall ist, können Sie mit unserer einfachen Anleitung beginnen hier.
6. Maschinelles lernen
Maschinelles Lernen konzentriert sich auf die Entwicklung von Algorithmen und Modellen, die in der Lage sind, automatisch aus Daten zu lernen und ihre Leistung im Laufe der Zeit zu verbessern.
Dabei kommen statistische Techniken zum Einsatz, die es Computern ermöglichen, Muster zu erkennen, Vorhersagen zu treffen und datengesteuerte Entscheidungen zu treffen, ohne dass sie explizit programmiert werden müssen.
Algorithmen für maschinelles Lernen Analysieren und lernen Sie aus großen Datensätzen, sodass Systeme ihr Verhalten basierend auf den von ihnen verarbeiteten Informationen anpassen und verbessern können.
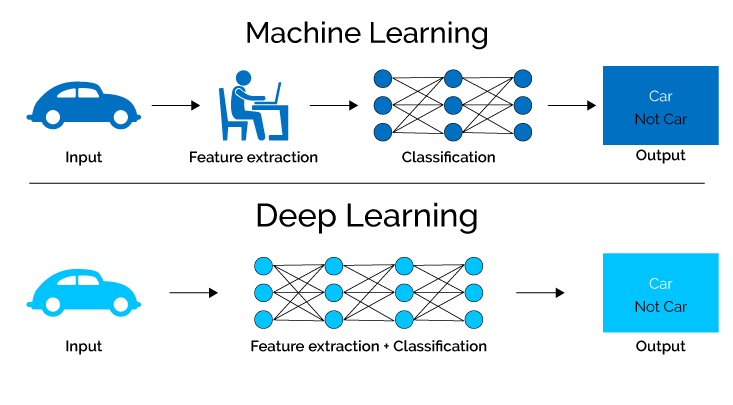
7. Tiefes Lernen
Tiefes Lernen, ein Teilgebiet des maschinellen Lernens und neuronaler Netze, nutzt hochentwickelte Algorithmen, um Wissen aus Daten zu gewinnen, indem es die komplizierten Prozesse des menschlichen Gehirns simuliert.
Durch den Einsatz neuronaler Netze mit zahlreichen verborgenen Schichten können Deep-Learning-Modelle selbstständig komplexe Merkmale und Muster extrahieren und so komplexe Aufgaben mit außergewöhnlicher Genauigkeit und Effizienz bewältigen.
8. Mustererkennung
Die Mustererkennung, eine Datenanalysetechnik, nutzt die Leistungsfähigkeit maschineller Lernalgorithmen, um Muster und Regelmäßigkeiten in Datensätzen autonom zu erkennen und zu erkennen.
Durch die Nutzung von Rechenmodellen und statistischen Methoden können Mustererkennungsalgorithmen sinnvolle Strukturen, Korrelationen und Trends in komplexen und vielfältigen Daten identifizieren.
Dieser Prozess ermöglicht die Gewinnung wertvoller Erkenntnisse, die Klassifizierung von Daten in verschiedene Kategorien und die Vorhersage zukünftiger Ergebnisse auf der Grundlage erkannter Muster. Die Mustererkennung ist in verschiedenen Bereichen ein wichtiges Werkzeug, das die Entscheidungsfindung, die Erkennung von Anomalien und die Vorhersagemodellierung erleichtert.
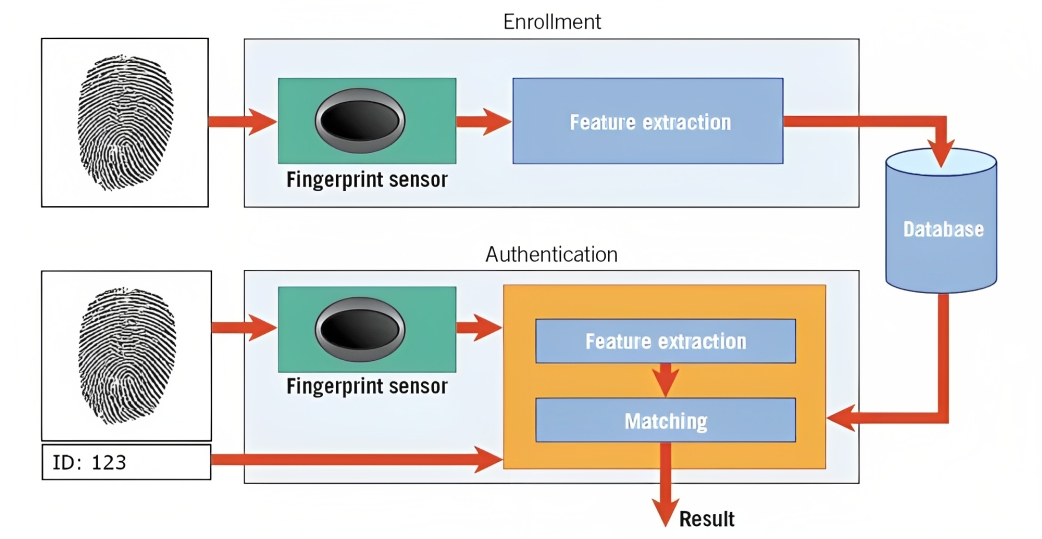
Ein Beispiel hierfür ist die Biometrie. Bei der Fingerabdruckerkennung analysiert der Algorithmus beispielsweise die Rillen, Kurven und einzigartigen Merkmale des Fingerabdrucks einer Person, um eine digitale Darstellung zu erstellen, die als Vorlage bezeichnet wird.
Wenn Sie versuchen, Ihr Smartphone zu entsperren oder auf eine sichere Einrichtung zuzugreifen, vergleicht das Mustererkennungssystem die erfassten biometrischen Daten (z. B. Fingerabdruck) mit den in seiner Datenbank gespeicherten Vorlagen.
Durch den Abgleich der Muster und die Beurteilung des Ähnlichkeitsgrads kann das System feststellen, ob die bereitgestellten biometrischen Daten mit der gespeicherten Vorlage übereinstimmen, und entsprechend Zugriff gewähren.
9. Beaufsichtigtes Lernen
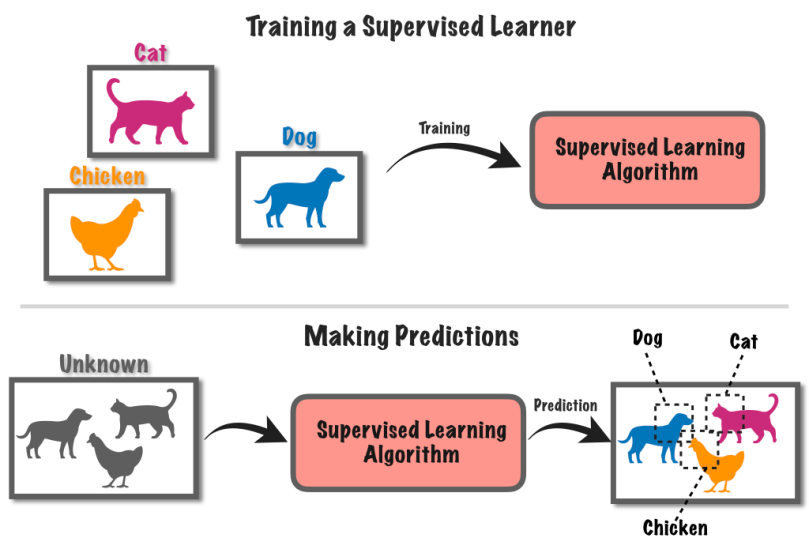
Überwachtes Lernen ist ein Ansatz des maschinellen Lernens, bei dem ein Computersystem mithilfe gekennzeichneter Daten trainiert wird. Bei dieser Methode wird dem Computer ein Satz Eingabedaten zusammen mit entsprechenden bekannten Bezeichnungen oder Ergebnissen bereitgestellt.
Nehmen wir an, Sie haben eine Reihe von Bildern, einige mit Hunden und andere mit Katzen.
Sie teilen dem Computer mit, auf welchen Bildern Hunde und auf welchen Bildern Katzen zu sehen sind. Der Computer lernt dann, die Unterschiede zwischen Hunden und Katzen zu erkennen, indem er Muster in den Bildern findet.
Nachdem es gelernt hat, können Sie dem Computer neue Bilder geben, und er wird versuchen herauszufinden, ob es sich um Hunde oder Katzen handelt, basierend auf dem, was er aus den beschrifteten Beispielen gelernt hat. Es ist, als würde man einem Computer beibringen, anhand bekannter Informationen Vorhersagen zu treffen.
10. Unüberwachtes Lernen
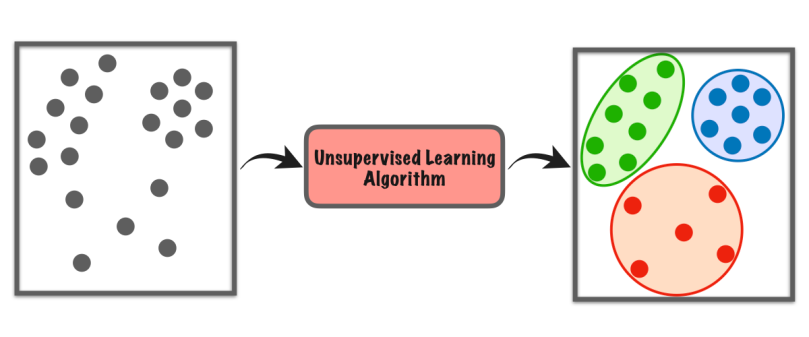
Unüberwachtes Lernen ist eine Form des maschinellen Lernens, bei der der Computer einen Datensatz selbstständig untersucht, um Muster oder Ähnlichkeiten zu finden, ohne dass dazu spezifische Anweisungen erforderlich sind.
Es basiert nicht auf beschrifteten Beispielen wie beim überwachten Lernen. Stattdessen sucht es nach versteckten Strukturen oder Gruppen in den Daten. Es ist, als würde der Computer Dinge selbst entdecken, ohne dass ihm ein Lehrer sagt, wonach er suchen soll.
Diese Art des Lernens hilft uns, neue Erkenntnisse zu gewinnen, Daten zu organisieren oder ungewöhnliche Dinge zu identifizieren, ohne dass Vorkenntnisse oder explizite Anleitung erforderlich sind.
11. Verarbeitung natürlicher Sprache (NLP)
Die Verarbeitung natürlicher Sprache konzentriert sich darauf, wie Computer menschliche Sprache verstehen und mit ihr interagieren. Es hilft Computern, die menschliche Sprache auf eine Weise zu analysieren, zu interpretieren und auf sie zu reagieren, die sich für uns natürlicher anfühlt.
NLP ermöglicht es uns, mit Sprachassistenten und Chatbots zu kommunizieren und unsere E-Mails sogar automatisch in Ordner zu sortieren.
Dabei geht es darum, Computern beizubringen, die Bedeutung von Wörtern, Sätzen und sogar ganzen Texten zu verstehen, damit sie uns bei verschiedenen Aufgaben unterstützen und unsere Interaktionen mit der Technologie reibungsloser gestalten können.
12. Computersehen
Computer Vision ist eine faszinierende Technologie, die es Computern ermöglicht, Bilder und Videos zu sehen und zu verstehen, so wie wir Menschen es mit unseren Augen tun. Es geht darum, Computern beizubringen, visuelle Informationen zu analysieren und das, was sie sehen, zu verstehen.
Einfacher ausgedrückt hilft Computer Vision Computern, die visuelle Welt zu erkennen und zu interpretieren. Dabei geht es darum, ihnen beizubringen, bestimmte Objekte in Bildern zu identifizieren, Bilder in verschiedene Kategorien zu klassifizieren oder sogar Bilder in sinnvolle Teile zu unterteilen.
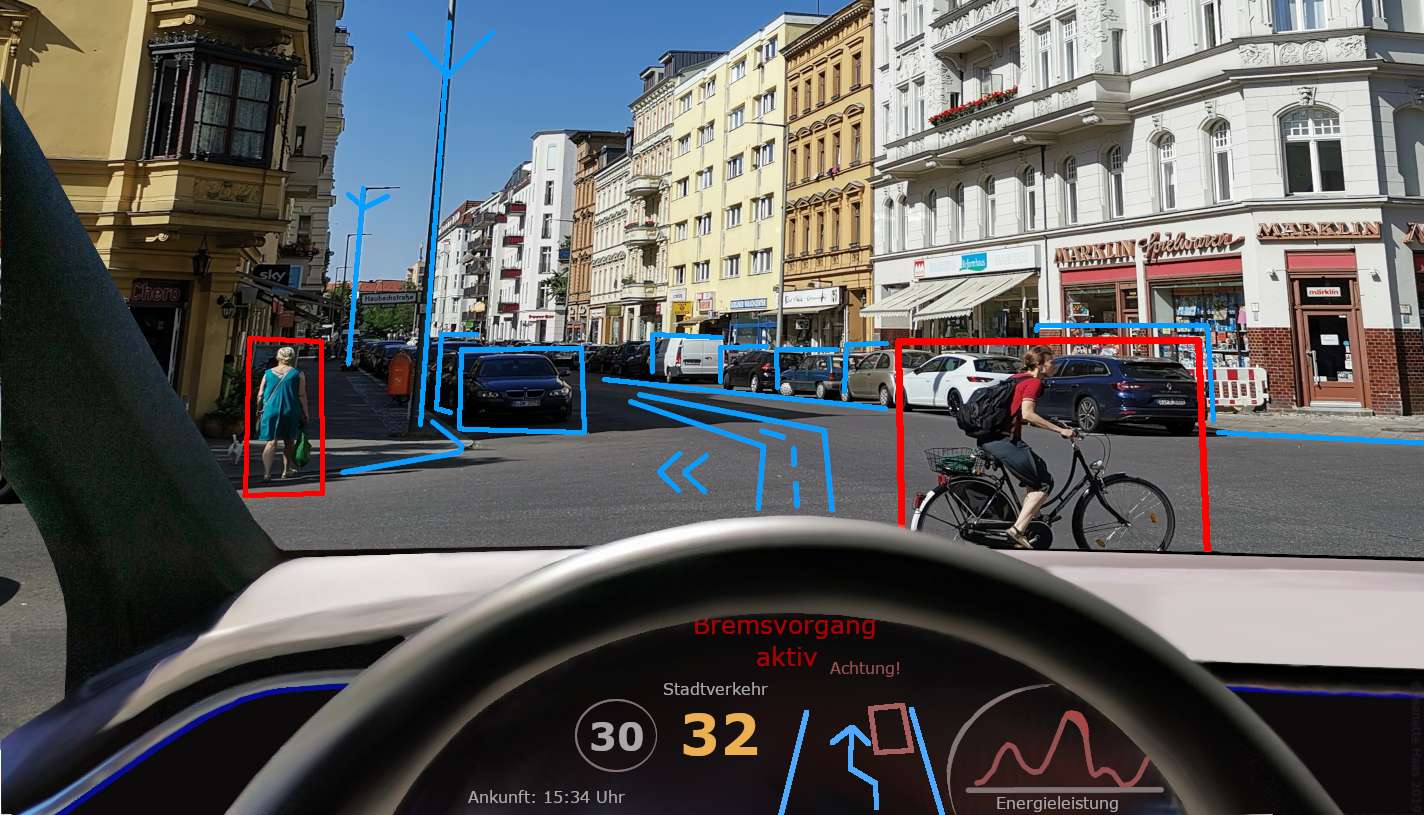
Stellen Sie sich ein selbstfahrendes Auto vor, das mithilfe von Computer Vision die Straße und alles um sie herum „sieht“.
Es kann Fußgänger, Verkehrszeichen und andere Fahrzeuge erkennen und verfolgen und ihnen so helfen, sich sicher zurechtzufinden. Oder denken Sie darüber nach, wie die Gesichtserkennungstechnologie Computer Vision nutzt, um unsere Smartphones zu entsperren oder unsere Identität zu überprüfen, indem sie unsere einzigartigen Gesichtsmerkmale erkennt.
Es wird auch in Überwachungssystemen verwendet, um überfüllte Orte zu überwachen und verdächtige Aktivitäten zu erkennen.
Computer Vision ist eine leistungsstarke Technologie, die eine Welt voller Möglichkeiten eröffnet. Indem wir es Computern ermöglichen, visuelle Informationen zu sehen und zu verstehen, können wir Anwendungen und Systeme entwickeln, die die Welt um uns herum wahrnehmen und interpretieren und so unser Leben einfacher, sicherer und effizienter machen können.
13.Chatbot
Ein Chatbot ist wie ein Computerprogramm, das mit Menschen auf eine Weise sprechen kann, die wie eine echte menschliche Konversation wirkt.
Im Online-Kundenservice wird es häufig verwendet, um Kunden zu helfen und ihnen das Gefühl zu geben, mit einer Person zu sprechen, obwohl es sich tatsächlich um ein Programm handelt, das auf einem Computer ausgeführt wird.
Der Chatbot kann Nachrichten oder Fragen von Kunden verstehen und darauf antworten und hilfreiche Informationen und Unterstützung bereitstellen, genau wie ein menschlicher Kundendienstmitarbeiter.
14. Spracherkennung
Unter Spracherkennung versteht man die Fähigkeit eines Computersystems, menschliche Sprache zu verstehen und zu interpretieren. Dabei handelt es sich um die Technologie, die es einem Computer oder Gerät ermöglicht, gesprochene Wörter zu „hören“ und sie in verständliche Texte oder Befehle umzuwandeln.
Mit der Spracherkennungkönnen Sie mit Geräten oder Anwendungen interagieren, indem Sie einfach mit ihnen sprechen, anstatt zu tippen oder andere Eingabemethoden zu verwenden.
Das System analysiert die gesprochenen Worte, erkennt Muster und Geräusche und übersetzt sie dann in verständliche Texte oder Handlungen. Es ermöglicht eine freihändige und natürliche Kommunikation mit der Technologie und macht Aufgaben wie Sprachbefehle, Diktieren oder sprachgesteuerte Interaktionen möglich. Die häufigsten Beispiele sind die KI-Assistenten wie Siri und Google Assistant.
15. Stimmungsanalyse
Stimmungsanalyse ist eine Technik zum Verstehen und Interpretieren von Emotionen, Meinungen und Einstellungen, die in Text oder Sprache zum Ausdruck kommen. Dabei wird die geschriebene oder gesprochene Sprache analysiert, um festzustellen, ob die geäußerte Stimmung positiv, negativ oder neutral ist.
Mithilfe von Algorithmen für maschinelles Lernen können Stimmungsanalysealgorithmen große Mengen an Textdaten wie Kundenrezensionen, Social-Media-Beiträge oder Kundenfeedback scannen und analysieren, um die zugrunde liegende Stimmung hinter den Wörtern zu identifizieren.
Die Algorithmen suchen nach bestimmten Wörtern, Phrasen oder Mustern, die auf Emotionen oder Meinungen hinweisen.
Diese Analyse hilft Unternehmen oder Einzelpersonen zu verstehen, wie Menschen zu einem Produkt, einer Dienstleistung oder einem Thema denken, und kann verwendet werden, um datengesteuerte Entscheidungen zu treffen oder Erkenntnisse über Kundenpräferenzen zu gewinnen.
Beispielsweise kann ein Unternehmen die Stimmungsanalyse nutzen, um die Kundenzufriedenheit zu verfolgen, Verbesserungsmöglichkeiten zu identifizieren oder die öffentliche Meinung über seine Marke zu überwachen.
16. Maschinelle Übersetzung
Unter maschineller Übersetzung versteht man im Zusammenhang mit KI den Einsatz von Computeralgorithmen und künstlicher Intelligenz, um Text oder Sprache automatisch von einer Sprache in eine andere zu übersetzen.
Dabei geht es darum, Computern beizubringen, menschliche Sprachen zu verstehen und zu verarbeiten, um genaue Übersetzungen zu liefern. Das häufigste Beispiel ist Google Übersetzer.
Bei der maschinellen Übersetzung können Sie Text oder Sprache in einer Sprache eingeben. Das System analysiert die Eingabe und erstellt eine entsprechende Übersetzung in einer anderen Sprache. Dies ist besonders nützlich, wenn Sie in verschiedenen Sprachen kommunizieren oder auf Informationen zugreifen.
Maschinelle Übersetzungssysteme basieren auf einer Kombination aus Sprachregeln, statistischen Modellen und Algorithmen für maschinelles Lernen. Sie lernen aus riesigen Mengen an Sprachdaten, um die Übersetzungsgenauigkeit im Laufe der Zeit zu verbessern. Einige maschinelle Übersetzungsansätze integrieren auch neuronale Netze, um die Qualität der Übersetzungen zu verbessern.
17. Robotik
Robotik ist die Kombination von künstlicher Intelligenz und Maschinenbau zur Schaffung intelligenter Maschinen, sogenannter Roboter. Diese Roboter sind so konzipiert, dass sie Aufgaben autonom oder mit minimalem menschlichen Eingriff ausführen.
Roboter sind physische Einheiten, die ihre Umgebung wahrnehmen, auf der Grundlage dieser sensorischen Eingaben Entscheidungen treffen und bestimmte Aktionen oder Aufgaben ausführen können.
Sie sind mit verschiedenen Sensoren wie Kameras, Mikrofonen oder Berührungssensoren ausgestattet, die es ihnen ermöglichen, Informationen aus der Welt um sie herum zu sammeln. Mit Hilfe von KI-Algorithmen und Programmierung können Roboter diese Daten analysieren, interpretieren und intelligente Entscheidungen treffen, um die ihnen zugewiesenen Aufgaben auszuführen.
KI spielt in der Robotik eine entscheidende Rolle, da sie es Robotern ermöglicht, aus ihren Erfahrungen zu lernen und sich an unterschiedliche Situationen anzupassen.
Algorithmen für maschinelles Lernen können verwendet werden, um Robotern beizubringen, Objekte zu erkennen, in Umgebungen zu navigieren oder sogar mit Menschen zu interagieren. Dadurch werden Roboter vielseitiger, flexibler und in der Lage, komplexe Aufgaben zu bewältigen.
18 Drohnen
Drohnen sind eine Art Roboter, die ohne einen menschlichen Piloten an Bord fliegen oder in der Luft schweben können. Sie werden auch als unbemannte Luftfahrzeuge (UAVs) bezeichnet. Drohnen sind mit verschiedenen Sensoren wie Kameras, GPS und Gyroskopen ausgestattet, die es ihnen ermöglichen, Daten zu sammeln und in ihrer Umgebung zu navigieren.
Sie werden von einem menschlichen Bediener ferngesteuert oder können mithilfe vorprogrammierter Anweisungen autonom arbeiten.
Drohnen dienen einer Vielzahl von Zwecken, darunter Luftfotografie und Videografie, Vermessung und Kartierung, Lieferdienste, Such- und Rettungsmissionen, Überwachung der Landwirtschaft und sogar Freizeitnutzung. Sie können abgelegene oder gefährliche Bereiche erreichen, die für Menschen schwierig oder gefährlich sind.
19. Erweiterte Realität (AR)
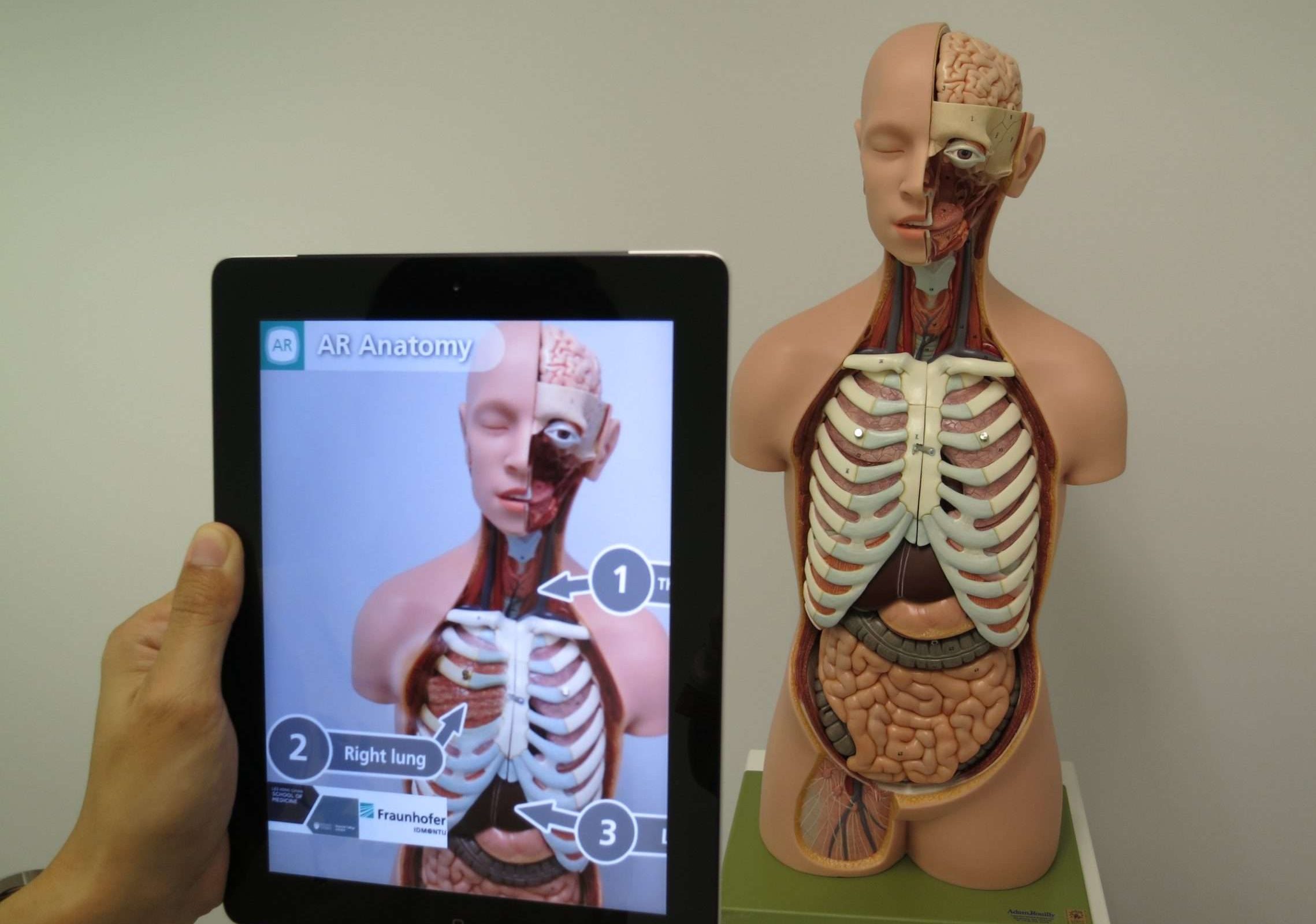
Augmented Reality (AR) ist eine Technologie, die die reale Welt mit virtuellen Objekten oder Informationen kombiniert, um unsere Wahrnehmung und Interaktion mit der Umgebung zu verbessern. Es überlagert computergenerierte Bilder, Töne oder andere sensorische Eingaben mit der realen Welt und schafft so ein immersives und interaktives Erlebnis.
Einfach ausgedrückt: Stellen Sie sich vor, Sie tragen eine spezielle Brille oder nutzen Ihr Smartphone, um die Welt um Sie herum zu sehen, aber mit zusätzlichen virtuellen Elementen.
Sie könnten beispielsweise Ihr Smartphone auf eine Stadtstraße richten und virtuelle Wegweiser mit Wegbeschreibungen, Bewertungen und Rezensionen für nahegelegene Restaurants oder sogar virtuelle Charaktere sehen, die mit der realen Umgebung interagieren.
Diese virtuellen Elemente fügen sich nahtlos in die reale Welt ein und verbessern Ihr Verständnis und Erlebnis der Umgebung. Augmented Reality kann in verschiedenen Bereichen wie Gaming, Bildung, Architektur und sogar für alltägliche Aufgaben wie Navigation oder das Ausprobieren neuer Möbel in Ihrem Zuhause vor dem Kauf eingesetzt werden.
20. Virtuelle Realität (VR)
Virtual Reality (VR) ist eine Technologie, die computergenerierte Simulationen verwendet, um eine künstliche Umgebung zu schaffen, die eine Person erkunden und mit der sie interagieren kann. Es lässt den Benutzer in eine virtuelle Welt eintauchen, indem die reale Welt ausgeblendet und durch eine digitale Welt ersetzt wird.
Einfach ausgedrückt: Stellen Sie sich vor, Sie setzen ein spezielles Headset auf, das Ihre Augen und Ohren bedeckt und Sie an einen völlig anderen Ort entführt. In dieser virtuellen Welt fühlt sich alles, was Sie sehen und hören, unglaublich real an, auch wenn alles von einem Computer generiert wird.
Sie können sich bewegen, in jede Richtung schauen und mit Objekten oder Charakteren interagieren, als ob sie physisch anwesend wären.
In einem Virtual-Reality-Spiel könnten Sie sich beispielsweise in einer mittelalterlichen Burg wiederfinden, wo Sie durch die Gänge gehen, Waffen aufheben und sich mit virtuellen Gegnern Schwertkämpfe liefern können. Die Virtual-Reality-Umgebung reagiert auf Ihre Bewegungen und Aktionen, sodass Sie das Gefühl haben, vollständig in das Erlebnis einzutauchen und sich darauf einzulassen.
Virtuelle Realität wird nicht nur für Spiele verwendet, sondern auch für verschiedene andere Anwendungen wie Trainingssimulationen für Piloten, Chirurgen oder Militärangehörige, architektonische Komplettlösungen, virtuellen Tourismus und sogar für die Therapie bestimmter psychologischer Erkrankungen. Es erzeugt ein Gefühl der Präsenz und entführt Benutzer in neue und aufregende virtuelle Welten, sodass sich das Erlebnis so realitätsnah wie möglich anfühlt.
21. Datenwissenschaft
Datenwissenschaft ist ein Bereich, in dem es um den Einsatz wissenschaftlicher Methoden, Werkzeuge und Algorithmen geht, um wertvolles Wissen und Erkenntnisse aus Daten zu gewinnen. Es kombiniert Elemente aus Mathematik, Statistik, Programmierung und Fachwissen, um große und komplexe Datensätze zu analysieren.
Einfacher ausgedrückt geht es bei der Datenwissenschaft darum, sinnvolle Informationen und Muster zu finden, die in einer Datenmenge verborgen sind. Dazu gehört das Sammeln, Bereinigen und Organisieren von Daten sowie der anschließende Einsatz verschiedener Techniken zu deren Untersuchung und Analyse. Datenwissenschaftler Verwenden Sie statistische Modelle und Algorithmen, um Trends aufzudecken, Vorhersagen zu treffen und Probleme zu lösen.
Im Gesundheitswesen kann Data Science beispielsweise zur Analyse von Patientenakten und medizinischen Daten eingesetzt werden, um Risikofaktoren für Krankheiten zu identifizieren, Patientenergebnisse vorherzusagen oder Behandlungspläne zu optimieren. In der Wirtschaft kann Data Science auf Kundendaten angewendet werden, um deren Vorlieben zu verstehen, Produkte zu empfehlen oder Marketingstrategien zu verbessern.
22. Daten-Wrangling
Beim Data Wrangling, auch Data Munging genannt, werden Rohdaten erfasst, bereinigt und in ein Format umgewandelt, das für die Analyse nützlicher und geeigneter ist. Dabei geht es um die Handhabung und Aufbereitung von Daten, um deren Qualität, Konsistenz und Kompatibilität mit Analysetools oder -modellen sicherzustellen.
Vereinfacht ausgedrückt gleicht das Daten-Wrangling dem Vorbereiten von Zutaten zum Kochen. Dabei werden Daten aus verschiedenen Quellen gesammelt, sortiert und bereinigt, um Fehler, Inkonsistenzen oder irrelevante Informationen zu entfernen.
Darüber hinaus müssen Daten möglicherweise transformiert, umstrukturiert oder aggregiert werden, um die Arbeit mit und die Gewinnung von Erkenntnissen zu erleichtern.
Beispielsweise kann das Daten-Wrangling das Entfernen doppelter Einträge, das Korrigieren von Rechtschreibfehlern oder Formatierungsproblemen, das Behandeln fehlender Werte und das Konvertieren von Datentypen umfassen. Es kann auch das Zusammenführen oder Verbinden verschiedener Datensätze, das Aufteilen von Daten in Teilmengen oder das Erstellen neuer Variablen auf der Grundlage vorhandener Daten umfassen.
23. Daten-Storytelling
Daten-Storytelling ist die Kunst, Daten auf überzeugende und ansprechende Weise zu präsentieren, um eine Erzählung oder Botschaft effektiv zu vermitteln. Es geht um die Verwendung Datenvisualisierungen, Erzählungen und Kontext, um Einsichten und Erkenntnisse auf eine Weise zu vermitteln, die für das Publikum verständlich und einprägsam ist.
Einfacher ausgedrückt geht es beim Data Storytelling darum, Daten zu nutzen, um eine Geschichte zu erzählen. Es geht über die bloße Darstellung von Zahlen und Diagrammen hinaus. Dabei geht es darum, eine Erzählung rund um die Daten zu erstellen und dabei visuelle Elemente und Storytelling-Techniken zu verwenden, um die Daten zum Leben zu erwecken und sie dem Publikum zugänglich zu machen.
Anstatt einfach nur eine Tabelle mit Verkaufszahlen zu präsentieren, könnte Data Storytelling beispielsweise die Erstellung eines interaktiven Dashboards beinhalten, das es Benutzern ermöglicht, die Verkaufstrends visuell zu erkunden.
Es könnte eine Erzählung enthalten, die die wichtigsten Ergebnisse hervorhebt, die Gründe für die Trends erläutert und auf der Grundlage der Daten umsetzbare Empfehlungen vorschlägt.
24. Datengesteuerte Entscheidungsfindung
Bei der datengesteuerten Entscheidungsfindung handelt es sich um einen Prozess, bei dem auf der Grundlage der Analyse und Interpretation relevanter Daten Entscheidungen getroffen oder Maßnahmen ergriffen werden. Dabei geht es darum, Daten als Grundlage zur Steuerung und Unterstützung von Entscheidungsprozessen zu nutzen, anstatt sich ausschließlich auf Intuition oder persönliches Urteilsvermögen zu verlassen.
Einfacher ausgedrückt bedeutet datengesteuerte Entscheidungsfindung, Fakten und Beweise aus Daten zu nutzen, um unsere Entscheidungen zu informieren und zu leiten. Dabei geht es darum, Daten zu sammeln und zu analysieren, um Muster, Trends und Beziehungen zu verstehen und dieses Wissen zu nutzen, um fundierte Entscheidungen zu treffen und Probleme zu lösen.
In einem Geschäftsumfeld kann die datengesteuerte Entscheidungsfindung beispielsweise die Analyse von Verkaufsdaten, Kundenfeedback und Markttrends umfassen, um die effektivste Preisstrategie zu ermitteln oder Bereiche für Verbesserungen in der Produktentwicklung zu identifizieren.
Im Gesundheitswesen kann es darum gehen, Patientendaten zu analysieren, um Behandlungspläne zu optimieren oder Krankheitsausgänge vorherzusagen.
25. Datensee
Ein Data Lake ist ein zentralisiertes und skalierbares Datenrepository, das große Datenmengen in Roh- und unverarbeiteter Form speichert. Es ist so konzipiert, dass es eine Vielzahl von Datentypen, Formaten und Strukturen wie strukturierte, halbstrukturierte und unstrukturierte Daten speichern kann, ohne dass vordefinierte Schemata oder Datentransformationen erforderlich sind.
Beispielsweise kann ein Unternehmen Daten aus verschiedenen Quellen, wie Website-Protokollen, Kundentransaktionen, Social-Media-Feeds und IoT-Geräten, in einem Data Lake sammeln und speichern.
Diese Daten können dann für verschiedene Zwecke verwendet werden, beispielsweise zur Durchführung erweiterter Analysen, zur Ausführung von Algorithmen für maschinelles Lernen oder zur Untersuchung von Mustern und Trends im Kundenverhalten.
26. Datenlager
Ein Data Warehouse ist ein spezialisiertes Datenbanksystem, das speziell für die Speicherung, Organisation und Analyse großer Datenmengen aus verschiedenen Quellen entwickelt wurde. Es ist so strukturiert, dass es eine effiziente Datenbeschaffung und komplexe analytische Abfragen unterstützt.
Es dient als zentrales Repository, das Daten aus verschiedenen Betriebssystemen wie Transaktionsdatenbanken, CRM-Systemen und anderen Datenquellen innerhalb einer Organisation integriert.
Die Daten werden transformiert, bereinigt und in einem strukturierten, für Analysezwecke optimierten Format in das Data Warehouse geladen.
27. Geschäftsintelligenz (BI)
Unter Business Intelligence versteht man den Prozess des Sammelns, Analysierens und Präsentierens von Daten auf eine Weise, die Unternehmen dabei hilft, fundierte Entscheidungen zu treffen und wertvolle Erkenntnisse zu gewinnen. Dabei werden verschiedene Tools, Technologien und Techniken eingesetzt, um Rohdaten in aussagekräftige, umsetzbare Informationen umzuwandeln.
Beispielsweise könnte ein Business-Intelligence-System Verkaufsdaten analysieren, um die profitabelsten Produkte zu identifizieren, Lagerbestände zu überwachen und Kundenpräferenzen zu verfolgen.
Es kann Echtzeit-Einblicke in wichtige Leistungsindikatoren (KPIs) wie Umsatz, Kundenakquise oder Produktleistung liefern und es Unternehmen ermöglichen, datengesteuerte Entscheidungen zu treffen und geeignete Maßnahmen zur Verbesserung ihrer Abläufe zu ergreifen.
Business-Intelligence-Tools umfassen häufig Funktionen wie Datenvisualisierung, Ad-hoc-Abfragen und Datenexplorationsfunktionen. Mit diesen Tools können Benutzer, z Wirtschaftsanalytiker oder Manager, um mit den Daten zu interagieren, sie in Stücke zu schneiden und Berichte oder visuelle Darstellungen zu erstellen, die wichtige Erkenntnisse und Trends hervorheben.
28. Predictive Analytics
Bei der prädiktiven Analyse werden Daten und statistische Techniken eingesetzt, um fundierte Vorhersagen oder Vorhersagen über zukünftige Ereignisse oder Ergebnisse zu treffen. Dabei geht es darum, historische Daten zu analysieren, Muster zu identifizieren und Modelle zu erstellen, um zukünftige Trends, Verhaltensweisen oder Ereignisse zu extrapolieren und abzuschätzen.
Ziel ist es, Beziehungen zwischen Variablen aufzudecken und diese Informationen für Vorhersagen zu nutzen. Es geht über die bloße Beschreibung vergangener Ereignisse hinaus; Stattdessen nutzt es historische Daten, um zu verstehen und vorherzusagen, was in der Zukunft wahrscheinlich passieren wird.
Im Finanzbereich kann beispielsweise die prädiktive Analyse zur Prognose eingesetzt werden -bestands- Preise basierend auf historischen Marktdaten, Wirtschaftsindikatoren und anderen relevanten Faktoren.
Im Marketing kann es eingesetzt werden, um das Verhalten und die Präferenzen der Kunden vorherzusagen und so gezielte Werbung und personalisierte Marketingkampagnen zu ermöglichen.
Im Gesundheitswesen kann die prädiktive Analyse dazu beitragen, Patienten mit einem hohen Risiko für bestimmte Krankheiten zu identifizieren oder die Wahrscheinlichkeit einer Wiedereinweisung auf der Grundlage der Krankengeschichte und anderer Faktoren vorherzusagen.
29. Präskriptive Analytik
Unter Prescriptive Analytics versteht man die Anwendung von Daten und Analysen, um die bestmöglichen Maßnahmen in einer bestimmten Situation oder einem bestimmten Entscheidungsszenario zu ermitteln.
Es geht über die Beschreibung hinaus und Predictive analytics indem wir nicht nur Erkenntnisse darüber liefern, was in der Zukunft passieren könnte, sondern auch die optimale Vorgehensweise empfehlen, um ein gewünschtes Ergebnis zu erzielen.
Es kombiniert historische Daten, Vorhersagemodelle und Optimierungstechniken, um verschiedene Szenarien zu simulieren und die möglichen Ergebnisse verschiedener Entscheidungen zu bewerten. Es berücksichtigt mehrere Einschränkungen, Ziele und Faktoren, um umsetzbare Empfehlungen zu generieren, die die gewünschten Ergebnisse maximieren oder Risiken minimieren.
Zum Beispiel in Supply Chain Management kann Prescriptive Analytics Daten zu Lagerbeständen, Produktionskapazitäten, Transportkosten und Kundennachfrage analysieren, um den effizientesten Vertriebsplan zu ermitteln.
Es kann die ideale Zuteilung von Ressourcen empfehlen, z. B. Lagerstandorte oder Transportwege, um Kosten zu minimieren und eine pünktliche Lieferung sicherzustellen.
30. Datengesteuertes Marketing
Unter datengesteuertem Marketing versteht man die Praxis, Daten und Analysen zu nutzen, um Marketingstrategien, Kampagnen und Entscheidungsprozesse voranzutreiben.
Dabei werden verschiedene Datenquellen genutzt, um Einblicke in das Verhalten, die Vorlieben und Trends der Kunden zu gewinnen und diese Informationen zur Optimierung der Marketingbemühungen zu nutzen.
Der Schwerpunkt liegt auf der Erfassung und Analyse von Daten aus mehreren Berührungspunkten, wie z. B. Website-Interaktionen, Social-Media-Engagement, Kundendemografie, Kaufhistorie und mehr. Diese Daten werden dann genutzt, um ein umfassendes Verständnis der Zielgruppe, ihrer Vorlieben und Bedürfnisse zu schaffen.
Durch die Nutzung von Daten können Vermarkter fundierte Entscheidungen hinsichtlich Kundensegmentierung, Targeting und Personalisierung treffen.
Sie können bestimmte Kundensegmente identifizieren, die mit größerer Wahrscheinlichkeit positiv auf Marketingkampagnen reagieren, und ihre Botschaften und Angebote entsprechend anpassen.
Darüber hinaus hilft datengesteuertes Marketing dabei, Marketingkanäle zu optimieren, den effektivsten Marketing-Mix zu ermitteln und den Erfolg von Marketinginitiativen zu messen.
Ein datengesteuerter Marketingansatz könnte beispielsweise die Analyse von Kundendaten beinhalten, um Kaufverhalten und Präferenzmuster zu identifizieren. Basierend auf diesen Erkenntnissen können Vermarkter gezielte Kampagnen mit personalisierten Inhalten und Angeboten erstellen, die bei bestimmten Kundensegmenten Anklang finden.
Durch kontinuierliche Analyse und Optimierung können sie die Wirksamkeit ihrer Marketingbemühungen messen und Strategien im Laufe der Zeit verfeinern.
31. Datenverwaltung
Data Governance ist der Rahmen und die Reihe von Praktiken, die Organisationen anwenden, um die ordnungsgemäße Verwaltung, den Schutz und die Integrität von Daten während ihres gesamten Lebenszyklus sicherzustellen. Es umfasst die Prozesse, Richtlinien und Verfahren, die regeln, wie Daten innerhalb einer Organisation erfasst, gespeichert, abgerufen, verwendet und weitergegeben werden.
Ziel ist es, Rechenschaftspflicht, Verantwortung und Kontrolle über Datenbestände zu etablieren. Es stellt sicher, dass die Daten korrekt, vollständig, konsistent und vertrauenswürdig sind, und ermöglicht es Unternehmen, fundierte Entscheidungen zu treffen, die Datenqualität aufrechtzuerhalten und behördliche Anforderungen zu erfüllen.
Zur Datengovernance gehören die Definition von Rollen und Verantwortlichkeiten für die Datenverwaltung, die Festlegung von Datenstandards und -richtlinien sowie die Implementierung von Prozessen zur Überwachung und Durchsetzung der Einhaltung. Es befasst sich mit verschiedenen Aspekten des Datenmanagements, einschließlich Datenschutz, Datensicherheit, Datenqualität, Datenklassifizierung und Datenlebenszyklusmanagement.
Beispielsweise kann die Datenverwaltung die Implementierung von Verfahren umfassen, um sicherzustellen, dass personenbezogene oder sensible Daten in Übereinstimmung mit geltenden Datenschutzbestimmungen wie der Datenschutz-Grundverordnung (DSGVO) behandelt werden.
Dazu kann auch die Festlegung von Datenqualitätsstandards und die Implementierung von Datenvalidierungsprozessen gehören, um sicherzustellen, dass die Daten korrekt und zuverlässig sind.
32. Datensicherheit.
Bei der Datensicherheit geht es darum, unsere wertvollen Informationen vor unbefugtem Zugriff oder Diebstahl zu schützen. Dabei geht es darum, Maßnahmen zum Schutz der Vertraulichkeit, Integrität und Verfügbarkeit der Daten zu ergreifen.
Im Wesentlichen bedeutet dies, sicherzustellen, dass nur die richtigen Personen auf unsere Daten zugreifen können, dass diese korrekt und unverändert bleiben und dass sie bei Bedarf verfügbar sind.
Um Datensicherheit zu erreichen, werden verschiedene Strategien und Technologien eingesetzt. Beispielsweise tragen Zugriffskontrollen und Verschlüsselungsmethoden dazu bei, den Zugriff auf autorisierte Personen oder Systeme zu beschränken, wodurch es für Außenstehende schwieriger wird, auf unsere Daten zuzugreifen.
Überwachungssysteme, Firewalls und Intrusion-Detection-Systeme fungieren als Wächter, machen uns auf verdächtige Aktivitäten aufmerksam und verhindern unbefugten Zugriff.
33. Internet der Dinge
Das Internet der Dinge (IoT) bezieht sich auf ein Netzwerk physischer Objekte oder „Dinge“, die mit dem Internet verbunden sind und miteinander kommunizieren können. Es ist wie ein großes Netz aus Alltagsgegenständen, Geräten und Maschinen, die durch Interaktion über das Internet Informationen austauschen und Aufgaben ausführen können.
Einfach ausgedrückt geht es beim IoT darum, verschiedenen Objekten oder Geräten, die traditionell nicht mit dem Internet verbunden waren, „intelligente“ Funktionen zu verleihen. Zu diesen Objekten können Haushaltsgeräte, tragbare Geräte, Thermostate, Autos und sogar Industriemaschinen gehören.
Durch die Verbindung dieser Objekte mit dem Internet können sie Daten sammeln und teilen, Anweisungen erhalten und Aufgaben autonom oder als Reaktion auf Benutzerbefehle ausführen.
Ein intelligenter Thermostat kann beispielsweise die Temperatur überwachen, Einstellungen anpassen und Energieverbrauchsberichte an eine Smartphone-App senden. Ein tragbarer Fitness-Tracker kann Daten über Ihre körperlichen Aktivitäten sammeln und diese zur Analyse mit einer cloudbasierten Plattform synchronisieren.
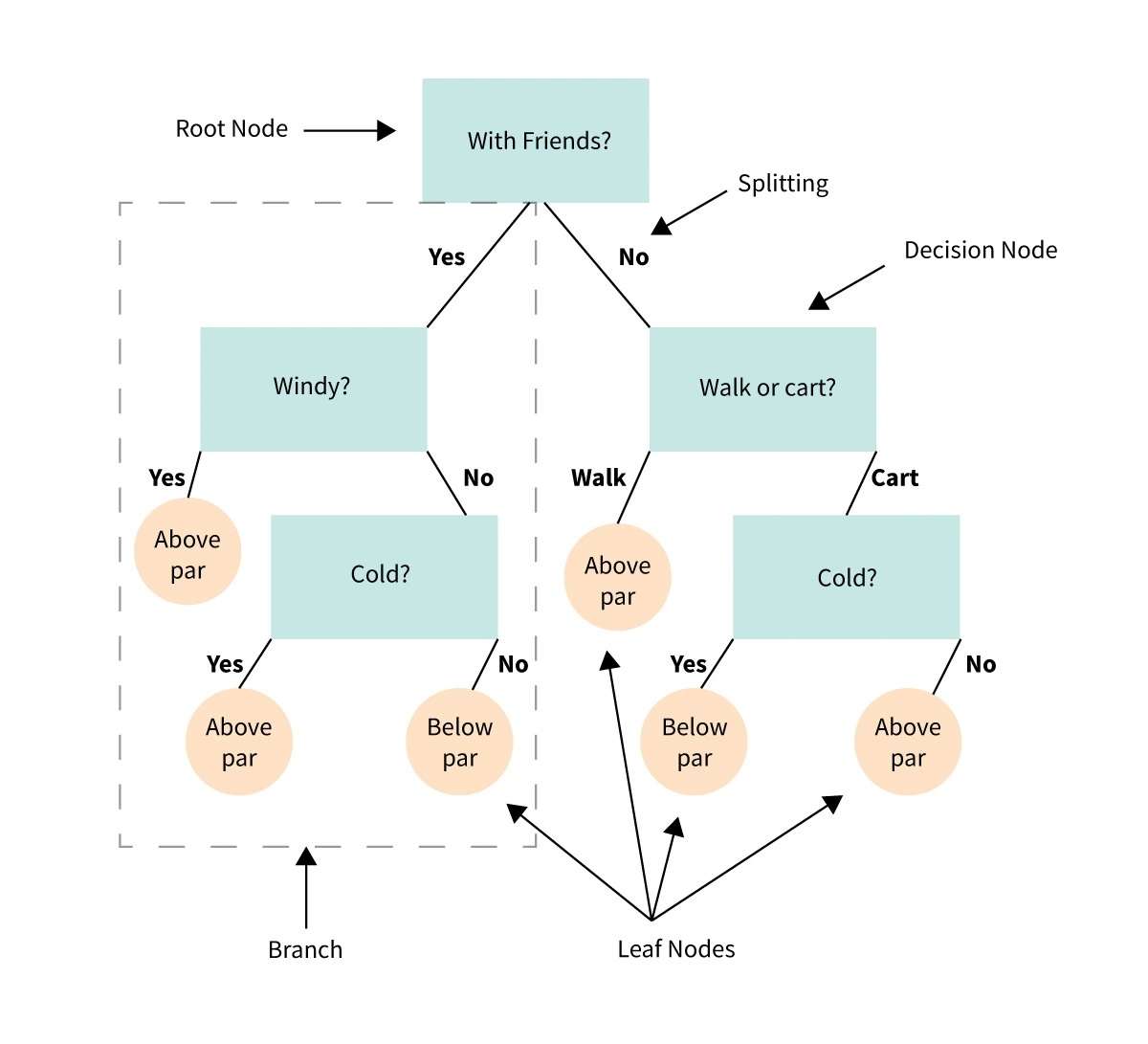
34. Entscheidungsbaum
Ein Entscheidungsbaum ist eine visuelle Darstellung oder ein Diagramm, das uns hilft, Entscheidungen zu treffen oder eine Vorgehensweise auf der Grundlage einer Reihe von Entscheidungen oder Bedingungen festzulegen.
Es ist wie ein Flussdiagramm, das uns durch einen Entscheidungsprozess führt, indem es verschiedene Optionen und ihre möglichen Ergebnisse berücksichtigt.
Stellen Sie sich vor, Sie haben ein Problem oder eine Frage und müssen eine Entscheidung treffen.
Ein Entscheidungsbaum unterteilt die Entscheidung in kleinere Schritte, beginnend mit einer anfänglichen Frage und verzweigt sich in verschiedene mögliche Antworten oder Aktionen, basierend auf den Bedingungen oder Kriterien in jedem Schritt.
35. Kognitives Rechnen
Vereinfacht ausgedrückt bezieht sich Cognitive Computing auf Computersysteme oder -technologien, die die kognitiven Fähigkeiten des Menschen nachahmen, beispielsweise Lernen, Denken, Verstehen und Problemlösen.
Dabei geht es darum, Computersysteme zu schaffen, die Informationen auf eine Weise verarbeiten und interpretieren können, die dem menschlichen Denken ähnelt.
Cognitive Computing zielt darauf ab, Maschinen zu entwickeln, die Menschen auf natürlichere und intelligentere Weise verstehen und mit ihnen interagieren können. Diese Systeme sind darauf ausgelegt, große Datenmengen zu analysieren, Muster zu erkennen, Vorhersagen zu treffen und aussagekräftige Erkenntnisse zu liefern.
Stellen Sie sich Cognitive Computing als einen Versuch vor, Computer dazu zu bringen, mehr wie Menschen zu denken und zu handeln.
Dabei werden Technologien wie künstliche Intelligenz, maschinelles Lernen, Verarbeitung natürlicher Sprache und Computer Vision genutzt, um Computer in die Lage zu versetzen, Aufgaben auszuführen, die traditionell mit menschlicher Intelligenz verbunden waren.
36. Computergestützte Lerntheorie
Die Computational Learning Theory ist ein Spezialzweig im Bereich der künstlichen Intelligenz, der sich mit der Entwicklung und Untersuchung von Algorithmen befasst, die speziell darauf ausgelegt sind, aus Daten zu lernen.
In diesem Bereich werden verschiedene Techniken und Methoden zur Konstruktion von Algorithmen untersucht, die ihre Leistung durch die Analyse und Verarbeitung großer Informationsmengen autonom verbessern können.
Durch die Nutzung der Kraft von Daten zielt die Computational Learning Theory darauf ab, Muster, Beziehungen und Erkenntnisse aufzudecken, die es Maschinen ermöglichen, ihre Entscheidungsfähigkeiten zu verbessern und Aufgaben effizienter auszuführen.
Das ultimative Ziel besteht darin, Algorithmen zu entwickeln, die sich an die ihnen ausgesetzten Daten anpassen, verallgemeinern und genaue Vorhersagen treffen können, um so zur Weiterentwicklung der künstlichen Intelligenz und ihrer praktischen Anwendungen beizutragen.
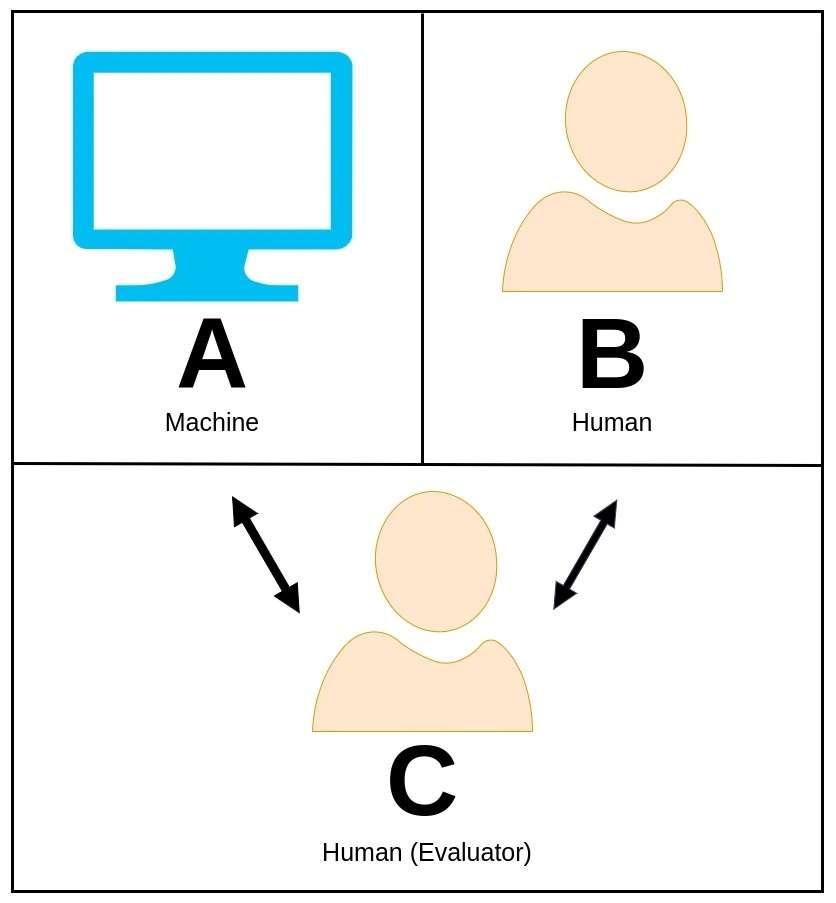
37. Turing-Test
Der Turing-Test, ursprünglich vom brillanten Mathematiker und Informatiker Alan Turing vorgeschlagen, ist ein faszinierendes Konzept, mit dem beurteilt wird, ob eine Maschine ein intelligentes Verhalten zeigen kann, das mit dem eines Menschen vergleichbar oder praktisch nicht von diesem zu unterscheiden ist.
Beim Turing-Test führt ein menschlicher Prüfer ein Gespräch in natürlicher Sprache sowohl mit einer Maschine als auch mit einem anderen menschlichen Teilnehmer, ohne zu wissen, wer die Maschine ist.
Die Rolle des Bewerters besteht darin, allein anhand seiner Antworten zu erkennen, welche Entität die Maschine ist. Wenn es der Maschine gelingt, den Prüfer davon zu überzeugen, dass es sich um das menschliche Gegenstück handelt, gilt sie als bestanden im Turing-Test und weist damit ein Intelligenzniveau auf, das menschenähnlichen Fähigkeiten entspricht.
Alan Turing schlug diesen Test vor, um das Konzept der maschinellen Intelligenz zu erforschen und die Frage zu stellen, ob Maschinen Kognitionen auf menschlicher Ebene erreichen können.
Indem Turing den Test im Hinblick auf die Ununterscheidbarkeit von Menschen formulierte, betonte er das Potenzial von Maschinen, ein Verhalten zu zeigen, das so überzeugend intelligent ist, dass es schwierig wird, sie von Menschen zu unterscheiden.
Der Turing-Test löste umfangreiche Diskussionen und Forschungen in den Bereichen künstliche Intelligenz und Kognitionswissenschaft aus. Auch wenn das Bestehen des Turing-Tests ein wichtiger Meilenstein bleibt, ist er nicht der einzige Maßstab für Intelligenz.
Nichtsdestotrotz dient der Test als zum Nachdenken anregender Maßstab, der fortlaufende Bemühungen zur Entwicklung von Maschinen anregt, die in der Lage sind, menschenähnliche Intelligenz und Verhalten nachzuahmen, und zur umfassenderen Erforschung dessen beiträgt, was es bedeutet, intelligent zu sein.
38. Verstärkungslernen
Verstärkung lernen ist eine Art des Lernens, die durch Versuch und Irrtum geschieht, wobei ein „Agent“ (der ein Computerprogramm oder ein Roboter sein kann) lernt, Aufgaben auszuführen, indem er Belohnungen für gutes Verhalten erhält und mit den Konsequenzen oder Strafen für schlechtes Verhalten konfrontiert wird.
Stellen Sie sich ein Szenario vor, in dem der Agent versucht, eine bestimmte Aufgabe zu erledigen, beispielsweise durch ein Labyrinth zu navigieren. Der Agent weiß zunächst nicht, welchen Weg er richtig einschlagen soll, also probiert er verschiedene Aktionen aus und erkundet verschiedene Routen.
Wenn es eine gute Aktion wählt, die es dem Ziel näher bringt, erhält es eine Belohnung, wie ein virtuelles „Schulterklopfen“. Trifft es jedoch eine schlechte Entscheidung, die in eine Sackgasse führt oder vom Ziel abweicht, erhält es Strafe oder negatives Feedback.
Durch diesen Versuch-und-Irrtum-Prozess lernt der Agent, bestimmte Handlungen mit positiven oder negativen Ergebnissen zu verknüpfen. Es findet nach und nach die beste Abfolge von Aktionen heraus, um seine Belohnungen zu maximieren und Bestrafungen zu minimieren, und wird letztendlich kompetenter bei der Bewältigung der Aufgabe.
Reinforcement Learning lässt sich von der Art und Weise inspirieren, wie Menschen und Tiere lernen, indem sie Feedback aus der Umgebung erhalten.
Durch die Anwendung dieses Konzepts auf Maschinen wollen Forscher intelligente Systeme entwickeln, die lernen und sich an verschiedene Situationen anpassen können, indem sie durch einen Prozess positiver Verstärkung und negativer Konsequenzen autonom die effektivsten Verhaltensweisen entdecken.
39. Entitätsextraktion
Unter Entitätsextraktion versteht man einen Prozess, bei dem wir wichtige Informationen, sogenannte Entitäten, aus einem Textblock identifizieren und extrahieren. Bei diesen Entitäten kann es sich um verschiedene Dinge wie Namen von Personen, Namen von Orten, Namen von Organisationen usw. handeln.
Stellen Sie sich vor, Sie haben einen Absatz, der einen Nachrichtenartikel beschreibt.
Bei der Entitätsextraktion müsste der Text analysiert und bestimmte Teile herausgesucht werden, die unterschiedliche Entitäten darstellen. Wenn im Text beispielsweise der Name einer Person wie „John Smith“, der Ort „New York City“ oder die Organisation „OpenAI“ erwähnt wird, sind dies die Entitäten, die wir identifizieren und extrahieren möchten.
Durch die Entitätsextraktion bringen wir einem Computerprogramm im Wesentlichen bei, wichtige Elemente aus dem Text zu erkennen und zu isolieren. Dieser Prozess ermöglicht es uns, Informationen effizienter zu organisieren und zu kategorisieren, was die Suche, Analyse und Ableitung von Erkenntnissen aus großen Textdatenmengen erleichtert.
Insgesamt hilft uns die Entitätsextraktion dabei, die Aufgabe, wichtige Entitäten wie Personen, Orte und Organisationen im Text zu lokalisieren, zu automatisieren, die Extraktion wertvoller Informationen zu rationalisieren und unsere Fähigkeit zu verbessern, Textdaten zu verarbeiten und zu verstehen.
40. Sprachliche Anmerkung
Bei der linguistischen Annotation geht es darum, den Text mit zusätzlichen sprachlichen Informationen anzureichern, um unser Verständnis und die Analyse der verwendeten Sprache zu verbessern. Es ist, als würde man verschiedene Teile eines Textes mit hilfreichen Beschriftungen oder Tags versehen.
Wenn wir linguistische Annotationen durchführen, gehen wir über die grundlegenden Wörter und Sätze in einem Text hinaus und beginnen mit der Kennzeichnung oder Kennzeichnung bestimmter Elemente. Beispielsweise könnten wir Wortart-Tags hinzufügen, die die grammatikalische Kategorie jedes Wortes angeben (z. B. Substantiv, Verb, Adjektiv usw.). Dies hilft uns zu verstehen, welche Rolle jedes Wort in einem Satz spielt.
Eine weitere Form der linguistischen Annotation ist die Erkennung benannter Entitäten, bei der wir bestimmte benannte Entitäten identifizieren und kennzeichnen, beispielsweise Namen von Personen, Orten, Organisationen oder Daten. Dadurch können wir wichtige Informationen schnell im Text finden und extrahieren.
Indem wir Text auf diese Weise mit Anmerkungen versehen, schaffen wir eine strukturiertere und organisiertere Darstellung der Sprache. Dies kann in einer Vielzahl von Anwendungen äußerst nützlich sein. Es trägt beispielsweise dazu bei, die Genauigkeit von Suchmaschinen zu verbessern, indem es die Absicht hinter Benutzeranfragen versteht. Es hilft auch bei der maschinellen Übersetzung, Stimmungsanalyse, Informationsextraktion und vielen anderen Aufgaben der Verarbeitung natürlicher Sprache.
Linguistische Annotation dient als wichtiges Werkzeug für Forscher, Linguisten und Entwickler und ermöglicht es ihnen, Sprachmuster zu studieren, Sprachmodelle zu erstellen und anspruchsvolle Algorithmen zu entwickeln, die den Text besser analysieren und verstehen können.
41. Hyperparameter
In Maschinelles LernenEin Hyperparameter ist wie eine spezielle Einstellung oder Konfiguration, über die wir uns vor dem Training eines Modells entscheiden müssen. Es ist nichts, was das Modell alleine aus den Daten lernen kann; Stattdessen müssen wir es vorher bestimmen.
Stellen Sie es sich als einen Knopf oder Schalter vor, den wir anpassen können, um die Art und Weise, wie das Modell lernt und Vorhersagen trifft, genau abzustimmen. Diese Hyperparameter steuern verschiedene Aspekte des Lernprozesses, beispielsweise die Komplexität des Modells, die Geschwindigkeit des Trainings und den Kompromiss zwischen Genauigkeit und Generalisierung.
Betrachten wir zum Beispiel ein neuronales Netzwerk. Ein wichtiger Hyperparameter ist die Anzahl der Schichten im Netzwerk. Wir müssen entscheiden, wie tief das Netzwerk sein soll, und diese Entscheidung wirkt sich auf seine Fähigkeit aus, komplexe Muster in den Daten zu erfassen.
Weitere gängige Hyperparameter sind die Lernrate, die bestimmt, wie schnell das Modell seine internen Parameter basierend auf den Trainingsdaten anpasst, und die Regularisierungsstärke, die steuert, wie stark das Modell komplexe Muster bestraft, um eine Überanpassung zu verhindern.
Die korrekte Einstellung dieser Hyperparameter ist von entscheidender Bedeutung, da sie die Leistung und das Verhalten des Modells erheblich beeinflussen können. Es erfordert oft ein wenig Versuch und Irrtum, das Experimentieren mit verschiedenen Werten und das Beobachten, wie sie sich auf die Leistung des Modells in einem Validierungsdatensatz auswirken.
42. Metadaten
Unter Metadaten versteht man zusätzliche Informationen, die Einzelheiten zu anderen Daten liefern. Es ist wie eine Reihe von Tags oder Labels, die uns mehr Kontext geben oder die Eigenschaften der Hauptdaten beschreiben.
Wenn wir über Daten verfügen, sei es ein Dokument, ein Foto, ein Video oder eine andere Art von Informationen, helfen uns Metadaten, wichtige Aspekte dieser Daten zu verstehen.
Beispielsweise könnten Metadaten in einem Dokument Details wie den Namen des Autors, das Erstellungsdatum oder das Dateiformat enthalten. Im Falle eines Fotos können uns Metadaten den Ort der Aufnahme, die verwendeten Kameraeinstellungen oder sogar das Datum und die Uhrzeit der Aufnahme verraten.
Metadaten helfen uns, Daten effektiver zu organisieren, zu suchen und zu interpretieren. Durch das Hinzufügen dieser beschreibenden Informationen können wir bestimmte Dateien schnell finden oder ihren Ursprung, Zweck oder Kontext verstehen, ohne den gesamten Inhalt durchsuchen zu müssen.
43. Dimensionsreduktion
Die Dimensionsreduktion ist eine Technik zur Vereinfachung eines Datensatzes durch Reduzierung der Anzahl der darin enthaltenen Features oder Variablen. Es ist so, als würde man die Informationen in einem Datensatz verdichten oder zusammenfassen, um ihn besser verwaltbar und einfacher zu bearbeiten.
Stellen Sie sich vor, Sie haben einen Datensatz mit zahlreichen Spalten oder Attributen, die unterschiedliche Eigenschaften der Datenpunkte darstellen. Jede Spalte erhöht die Komplexität und die Rechenanforderungen von Algorithmen für maschinelles Lernen.
In manchen Fällen kann es aufgrund einer hohen Anzahl an Dimensionen schwierig sein, sinnvolle Muster oder Beziehungen in den Daten zu finden.
Die Reduzierung der Dimensionalität trägt dazu bei, dieses Problem zu lösen, indem der Datensatz in eine niedrigerdimensionale Darstellung umgewandelt wird und gleichzeitig so viele relevante Informationen wie möglich erhalten bleiben. Ziel ist es, die wichtigsten Aspekte oder Variationen in den Daten zu erfassen und gleichzeitig redundante oder weniger informative Dimensionen zu verwerfen.
44. Textklassifizierung
Bei der Textklassifizierung handelt es sich um einen Prozess, bei dem Textblöcken anhand ihres Inhalts oder ihrer Bedeutung bestimmte Bezeichnungen oder Kategorien zugewiesen werden. Es ist so, als würde man Textinformationen in verschiedene Gruppen oder Klassen sortieren oder organisieren, um die weitere Analyse oder Entscheidungsfindung zu erleichtern.
Betrachten wir ein Beispiel für die E-Mail-Klassifizierung. In diesem Szenario möchten wir feststellen, ob es sich bei einer eingehenden E-Mail um Spam oder Nicht-Spam (auch als Ham bezeichnet) handelt. Textklassifizierung Algorithmen analysieren den Inhalt der E-Mail und weisen ihr ein entsprechendes Label zu.
Wenn der Algorithmus feststellt, dass die E-Mail Merkmale aufweist, die üblicherweise mit Spam in Verbindung gebracht werden, weist er ihr die Kennzeichnung „Spam“ zu. Wenn die E-Mail hingegen seriös erscheint und kein Spam enthält, wird ihr die Bezeichnung „Kein Spam“ oder „Ham“ zugewiesen.
Die Textklassifizierung findet in verschiedenen Bereichen Anwendung, die über die E-Mail-Filterung hinausgehen. Es wird in der Stimmungsanalyse verwendet, um die in Kundenbewertungen ausgedrückte Stimmung (positiv, negativ oder neutral) zu bestimmen.
Nachrichtenartikel können in verschiedene Themen oder Kategorien wie Sport, Politik, Unterhaltung und mehr eingeteilt werden. Chatprotokolle des Kundensupports können basierend auf der Absicht oder dem angesprochenen Problem kategorisiert werden.
45. Schwache KI
Schwache KI, auch Narrow AI genannt, bezieht sich auf Systeme der künstlichen Intelligenz, die für die Ausführung bestimmter Aufgaben oder Funktionen konzipiert und programmiert sind. Im Gegensatz zur menschlichen Intelligenz, die ein breites Spektrum kognitiver Fähigkeiten umfasst, ist schwache KI auf einen bestimmten Bereich oder eine bestimmte Aufgabe beschränkt.
Stellen Sie sich schwache KI als spezialisierte Software oder Maschinen vor, die bestimmte Aufgaben hervorragend ausführen. Beispielsweise kann ein Schach-KI-Programm erstellt werden, um Spielsituationen zu analysieren, Spielzüge zu planen und gegen menschliche Spieler anzutreten.
Ein weiteres Beispiel ist ein Bilderkennungssystem, das Objekte in Fotos oder Videos identifizieren kann.
Diese KI-Systeme werden trainiert und optimiert, um in ihren spezifischen Fachgebieten hervorragende Leistungen zu erbringen. Sie verlassen sich auf Algorithmen, Daten und vordefinierte Regeln, um ihre Aufgaben effektiv zu erfüllen.
Sie verfügen jedoch nicht über eine allgemeine Intelligenz, die es ihnen ermöglicht, Aufgaben außerhalb ihres vorgesehenen Bereichs zu verstehen oder auszuführen.
46. Starke KI
Starke KI, auch als allgemeine KI oder künstliche allgemeine Intelligenz (AGI) bekannt, bezieht sich auf eine Form der künstlichen Intelligenz, die die Fähigkeit besitzt, alle intellektuellen Aufgaben eines Menschen zu verstehen, zu lernen und auszuführen.
Im Gegensatz zu schwacher KI, die für bestimmte Aufgaben konzipiert ist, zielt starke KI darauf ab, menschenähnliche Intelligenz und kognitive Fähigkeiten zu reproduzieren. Ziel ist es, Maschinen oder Software zu entwickeln, die sich nicht nur bei speziellen Aufgaben auszeichnen, sondern auch über ein umfassenderes Verständnis und eine größere Anpassungsfähigkeit verfügen, um ein breites Spektrum intellektueller Herausforderungen zu bewältigen.
Das Ziel einer starken KI besteht darin, Systeme zu entwickeln, die schlussfolgern, komplexe Informationen verstehen, aus Erfahrungen lernen, sich an Gesprächen in natürlicher Sprache beteiligen, Kreativität zeigen und andere Eigenschaften aufweisen, die mit menschlicher Intelligenz verbunden sind.
Im Wesentlichen geht es darum, KI-Systeme zu schaffen, die menschliches Denken und Problemlösungen über mehrere Bereiche hinweg simulieren oder reproduzieren können.
47. Vorwärtsverkettung
Vorwärtsverkettung ist eine Argumentations- oder Logikmethode, die mit den verfügbaren Daten beginnt und diese nutzt, um Schlussfolgerungen zu ziehen und neue Schlussfolgerungen zu ziehen. Es ist, als würde man die Punkte verbinden, indem man die vorhandenen Informationen nutzt, um voranzukommen und zusätzliche Erkenntnisse zu gewinnen.
Stellen Sie sich vor, Sie haben eine Reihe von Regeln oder Fakten und möchten neue Informationen ableiten oder daraus bestimmte Schlussfolgerungen ziehen. Bei der Vorwärtsverkettung werden die Ausgangsdaten untersucht und logische Regeln angewendet, um zusätzliche Fakten oder Schlussfolgerungen zu generieren.
Betrachten wir zur Vereinfachung ein einfaches Szenario, bei dem wir anhand der Wetterbedingungen bestimmen, was wir anziehen sollen. Es gibt eine Regel, die besagt: „Wenn es regnet, bringen Sie einen Regenschirm mit“, und eine andere Regel, die besagt: „Wenn es kalt ist, tragen Sie eine Jacke.“ Wenn Sie nun feststellen, dass es tatsächlich regnet, können Sie aus der Vorwärtsverkettung ableiten, dass Sie einen Regenschirm mitbringen sollten.
48. Rückwärtsverkettung
Rückwärtsverkettung ist eine Argumentationsmethode, die mit einer gewünschten Schlussfolgerung oder einem gewünschten Ziel beginnt und rückwärts arbeitet, um die notwendigen Daten oder Fakten zu ermitteln, die zur Stützung dieser Schlussfolgerung erforderlich sind. Es ist so, als würden Sie Ihre Schritte vom gewünschten Ergebnis bis zu den ersten Informationen verfolgen, die zum Erreichen dieses Ergebnisses erforderlich sind.
Um die Rückwärtsverkettung zu verstehen, betrachten wir ein einfaches Beispiel. Angenommen, Sie möchten feststellen, ob es zum Schwimmen geeignet ist. Die gewünschte Schlussfolgerung ist, ob Schwimmen unter bestimmten Bedingungen angemessen ist oder nicht.
Anstatt mit den Bedingungen zu beginnen, beginnt die Rückwärtsverkettung mit der Schlussfolgerung und arbeitet rückwärts, um die unterstützenden Daten zu finden.
In diesem Fall würde die Rückwärtsverkettung das Stellen von Fragen wie „Ist das Wetter warm?“ beinhalten. Wenn die Antwort „Ja“ lautet, würden Sie fragen: „Ist ein Pool verfügbar?“ Wenn die Antwort erneut „Ja“ lautet, würden Sie weitere Fragen stellen, z. B. „Ist noch genug Zeit zum Schwimmen?“
Indem Sie diese Fragen iterativ beantworten und rückwärts arbeiten, können Sie die notwendigen Bedingungen ermitteln, die erfüllt sein müssen, um die Schlussfolgerung, schwimmen zu gehen, zu unterstützen.
49. Heuristik
Eine Heuristik ist, vereinfacht ausgedrückt, eine praktische Regel oder Strategie, die uns hilft, Entscheidungen zu treffen oder Probleme zu lösen, normalerweise basierend auf unseren Erfahrungen oder unserer Intuition. Es ist wie eine mentale Abkürzung, die es uns ermöglicht, schnell eine vernünftige Lösung zu finden, ohne einen langwierigen oder erschöpfenden Prozess durchlaufen zu müssen.
Bei komplexen Situationen oder Aufgaben dienen Heuristiken als Leitprinzipien oder „Faustregeln“, die die Entscheidungsfindung vereinfachen. Sie liefern uns allgemeine Richtlinien oder Strategien, die in bestimmten Situationen oft wirksam sind, auch wenn sie möglicherweise nicht die optimale Lösung garantieren.
Betrachten wir beispielsweise eine Heuristik zum Finden eines Parkplatzes in einem überfüllten Bereich. Anstatt jeden verfügbaren Platz akribisch zu analysieren, könnten Sie sich auf die Heuristik verlassen, nach geparkten Autos mit laufendem Motor zu suchen.
Diese Heuristik geht davon aus, dass diese Autos bald abfahren, was die Chancen erhöht, einen freien Platz zu finden.
50. Modellierung natürlicher Sprache
Vereinfacht ausgedrückt ist die Modellierung natürlicher Sprache der Prozess, bei dem Computermodelle darauf trainiert werden, menschliche Sprache auf eine Art und Weise zu verstehen und zu erzeugen, die der Art und Weise ähnelt, wie Menschen kommunizieren. Dabei geht es darum, Computern beizubringen, Texte auf natürliche und sinnvolle Weise zu verarbeiten, zu interpretieren und zu generieren.
Das Ziel der Modellierung natürlicher Sprache besteht darin, Computer in die Lage zu versetzen, menschliche Sprache fließend, kohärent und kontextrelevant zu verstehen und zu erzeugen.
Dabei werden Modelle anhand großer Mengen an Textdaten wie Büchern, Artikeln oder Gesprächen trainiert, um die Muster, Strukturen und Semantik der Sprache zu erlernen.
Nach dem Training können diese Modelle verschiedene sprachbezogene Aufgaben ausführen, z. B. Sprachübersetzung, Textzusammenfassung, Beantwortung von Fragen, Chatbot-Interaktionen und mehr.
Sie können die Bedeutung und den Kontext von Sätzen verstehen, relevante Informationen extrahieren und grammatikalisch korrekte und kohärente Texte erstellen.





Hinterlassen Sie uns einen Kommentar