På grund af den voksende betydning af dataanalyse og datastyring for virksomheder, er en sammenligning af dataplatformene Snowflake og Databricks nødvendig for dagens marked.
Organisationer har brug for en mekanisme til at samle alle de data, de har brug for for at evaluere på ét sted, hvor de kan være klar til datamining, efterhånden som mængden af data, der skal studeres, vokser gradvist.
Uden tvivl er de anerkendte cloud-baserede datasystemer Snowflake og Databricks begge industriledere. Hvilken dataplatform er dog ideel til din virksomhed?
Den mængde, hastighed og kvalitet, som business intelligence-applikationer kræver, leveres alle af Snowflake og Databricks.
Selvom der er varianser, er der også masser af paralleller. De har en tydelig orientering, hvilket er tydeligt, når de bliver nøje inspiceret.
Grundlæggerne af Apache Spark etablerede virksomhedssoftwarevirksomheden Databricks.
Det er kendt for at sammensmelte de største aspekter af datasøer og datavarehuse til en søhusarkitektur.
Datavarehusvirksomhed Snowflake tilbyder cloud-baseret lagring og adgangstjenester med minimalt besvær. Det etablerer sin status som en løsning, der giver sikker adgang til dine data, mens den kræver næsten lidt vedligeholdelse.
Denne artikel giver dig en detaljeret sammenligning af Snowflake vs. Databricks og forklarer hvert produkts fordele, så du kan beslutte, hvad der er bedst for din virksomhed. Lad os starte med deres introduktion.
Hvad er Snowflake?
Snowflake er en fuldstændig administreret tjeneste, der tilbyder kunder næsten ubegrænset skalerbarhed af samtidige arbejdsbelastninger til enkel dataintegration, indlæsning, analyse og deling.
Data Lakes, Data Engineering, Data Application Development, Data Science og sikkert forbrug af delte data er nogle af dets typiske anvendelser.

Databehandling og lagring er naturligt adskilt af Snowflakes karakteristiske design.
Ved hjælp af denne arkitektur kan du praktisk talt give alle dine brugere og dataarbejdsbelastninger adgang til en enkelt kopi af dine data uden at lide nogen negativ effekt på ydeevnen.
For en ensartet brugeroplevelse gør Snowflake dig i stand til at eksekvere din dataløsning usynligt på tværs af forskellige lokationer og skyer.
Ved at fjerne kompleksiteten af de underliggende Cloud-infrastrukturer gør Snowflake det muligt.
Snowflake Data Marketplace, som tilbyder mange muligheder for at interagere med tusindvis af Snowflake-kunder, giver dig også adgang til delte datasæt og datatjenester.
Funktionalitet
- Mere effektiv datadrevet beslutningstagning: Med Snowflake kan du eliminere datasiloer og give alle i virksomheden adgang til nyttig indsigt. Dette er et afgørende indledende trin i at forbedre partnerrelationer, optimere priser, reducere omkostninger forbundet med driften, øge salgseffektiviteten og mange andre ting.
- Forbedre Analytics hastighed og kvalitet: Du kan styrke din analysepipeline med Snowflake ved at skifte fra natlige batchbelastninger til datastrømme i realtid. Ved at give alle i din virksomhed sikker, samtidig og kontrolleret adgang til dit datavarehus kan du forbedre kvaliteten af analyser på arbejdspladsen. Dette reducerer udgifter og manuelt arbejde, hvilket gør det muligt for virksomheder at fordele ressourcer optimalt for at maksimere indkomsten.
- Dataudveksling med tilpasning: Du kan oprette din egen dataudveksling med Snowflake, så du kan overføre live, regulerede data på en sikker måde. Derudover tjener det som en motivation til at udvikle stærkere dataforbindelser med partnere, kunder og andre forretningsenheder. Den opnår dette ved at opnå et 360-graders perspektiv af din forbruger, som tilbyder information om vigtige kundekarakteristika, herunder interesser, erhverv og mange flere.
- Større produkt- og brugeroplevelser: Du kan bedre forstå brugeradfærd og produktbrug med Snowflake på plads. Derudover kan du gøre brug af hele datasættet til at tilfredsstille kunder, forbedre din produktlinje i høj grad og fremme datavidenskabsinnovation.
- Stærk sikkerhed: Alle compliance- og cybersikkerhedsdata kan centraliseres i en sikker datasø. Den hurtige hændelsesreaktion er garanteret af datasøer med snefnug. Ved at kombinere enorme mængder logdata på ét sted og hurtigt evaluere års logdata, kan du få det fulde billede af en hændelse. Semistrukturerede logfiler og strukturerede virksomhedsdata kan nu kombineres i en enkelt datasø. Uden nogen indeksering giver Snowflake dig mulighed for at få foden inden for døren, mens det gør det nemt at redigere og ændre data, når de er blevet importeret.
Hvad er Databrikker?
Databricks er en cloud-baseret dataplatform drevet af Apache Spark. Det fokuserer hovedsageligt på Big Data Analytics og Collaboration.
Du kan tilbyde et komplet Data Science-arbejdsområde til Forretningsanalytikere, Data Scientists og Data Engineers til at interagere ved hjælp af Databricks' Machine Learning Runtime, kontrolleret ML Flow og Collaborative Notebooks.

Dataframes og Spark SQL-biblioteker, som giver dig mulighed for at håndtere strukturerede data, er placeret hos Databricks.
Ud over at hjælpe dig med at skabe Kunstig intelligens løsninger, gør Databricks det nemt at drage konklusioner ud fra dine nuværende data.
Derudover tilbyder Databricks en række forskellige biblioteker til machine learning, herunder Tensorflow, Pytorch og andre, til opbygning og træning af maskinlæringsmodeller.
En bred vifte af erhvervskunder bruger Databricks til at udføre massive produktionsprocesser på tværs af en bred vifte af brugssager og sektorer, herunder Healthcare, Media & Entertainment, Financial Services, Detail, og så meget mere.
Funktionalitet
- Delta søen: Databricks har et transaktionslagerlag, der er open source og designet til at blive brugt på tværs af hele datalivscyklussen. Dette lag kan bruges til at give dataskalerbarhed og pålidelighed til din nuværende datasø.
- Interaktive notesbøger: Du kan hurtigt få adgang til dine data, analysere dem, konstruere modeller med andre og dele frisk, nyttig indsigt, når du har de rigtige værktøjer og sprog. Scala, R, SQL og Python er blot nogle få af de sprog, der understøttes af Databricks.
- Maskinelæring: Ved hjælp af banebrydende rammer som Tensorflow, Scikit-Learn og Pytorch giver Databricks dig adgang med et enkelt klik til forudkonfigurerede Machine Learning-miljøer. Du kan dele og overvåge eksperimenter, administrere modeller sammen og replikere kørsler fra ét centralt lager.
- Forbedret Spark Engine: Du kan få de nyeste versioner af Apache Spark ved hjælp af Databricks. Forskellige Open source-biblioteker kan også integreres problemfrit med Databricks. Du kan hurtigt opsætte klynger og skabe et fuldt administreret Apache Spark-miljø, hvis du har adgang til tilgængeligheden og skalerbarheden hos flere Cloud-tjenesteudbydere. Klynger kan konfigureres, konfigureres og finjusteres med Databricks uden behov for løbende overvågning for at opretholde optimal ydeevne og pålidelighed.
Kerneforskelle mellem Snowflake og Databricks
arkitektur
Snowflake er et ANSI SQL-baseret serverløst system med helt forskellige lager- og databehandlingslag.
Hvert virtuelt lager (dvs. computerklynge) i Snowflake gemmer en delmængde af hele datasættet lokalt, mens de bruger massivt parallel behandling (MPP) til at udføre forespørgsler.
Til intern dataorganisation og optimering til et komprimeret søjleformat, der kan gemmes i skyen, anvender Snowflake mikropartitioner.
Det faktum, at Snowflake vedligeholder alle aspekter af datastyring, inklusive filstørrelse, komprimering, struktur, metadata, statistik og andre dataelementer, der ikke umiddelbart er synlige for brugerne og kun kan tilgås via SQL-forespørgsler, gør det muligt at gøre alt dette automatisk.
Virtuelle varehuse, som er beregnede klynger, der består af mange MPP-noder, bruges til at udføre al behandling i Snowflake.
Snowflake og Databricks er begge SaaS-løsninger, dog er Databricks' arkitektur meget anderledes, fordi den er bygget på Spark.
En flersproget motor kaldet Spark kan installeres i skyen og er baseret på enkelte noder eller klynger. Databricks bruger i øjeblikket AWS, GCP og Azure ligesom Snowflake.
Et kontrolplan og et dataplan udgør dets struktur. Alle behandlede data er indeholdt i dataplanet, mens alle backend-tjenester administreret af Databricks Serverless computing findes i kontrolplanet.
Serverløs computing gør det muligt for administratorer at skabe serverløse SQL-endepunkter, der er fuldt administreret af Databricks og tilbyder øjeblikkelig databehandling.
Mens beregningsressourcer for størstedelen af andre Databricks-beregninger deles inde i skykontoen eller det traditionelle dataplan, deles disse ressourcer i et serverløst dataplan.
Databricks arkitektur består af flere vigtige dele:
- Databricks Delta Lake
- Databricks Delta Engine
- MLFlow
Datastruktur
Både semi-strukturerede og strukturerede filer kan gemmes og uploades ved hjælp af Snowflake uden behov for et ETL-værktøj til først at arrangere dataene, før de importeres til EDW.
Snowflake konverterer øjeblikkeligt dataene til sit eget interne, organiserede format, når dataene indsendes. I modsætning til en Data Lake behøver Snowflake ikke, at du giver struktur til dine ustrukturerede data, før du kan indlæse og interagere med dem.
Datatyperne kan alle bruges med Databricks i deres originale format. For at give din ustrukturerede datastruktur, så den kan bruges af andre værktøjer som Snowflake, kan du endda bruge Databricks som et ETL-værktøj.
I debatten mellem Databricks og Snowflake sejrer Databricks over Snowflake med hensyn til datastruktur.
Dataejerskab
Behandlings- og lagerlag er adskilt i Snowflake, så de kan vokse uafhængigt på skyen. Dette indikerer, at de alle kan skalere uafhængigt i skyen baseret på dine krav.
Det vil din økonomi have gavn af. Derudover bevares begge lags ejerskab. Snowflake sikrer adgang til data og maskinressourcer ved hjælp af den rollebaserede adgangskontrol (RBAC) teknik.
Databehandlings- og lagringslagene i Databricks er fuldstændig afkoblet, i modsætning til de afkoblede lag i Snowflake.
Brugere kan placere deres data hvor som helst i ethvert format, og Databricks vil håndtere det effektivt, fordi dets primære mål er dataapplikation.
Databricks er den klare vinder i debatten mellem Databricks og Snowflake, da du blot kan bruge det til at behandle dataene.
Databeskyttelse
Time Travel og Fail-safe er to særlige kendetegn ved Snowflake. Time Travel-funktionen i Snowflake holder data i en tilstand før en opdatering.
Mens Enterprise-kunder kan vælge et tidsinterval på op til 90 dage, er tidsrejser ofte begrænset til én dag. Databaser, skemaer og tabeller kan alle bruge denne funktion.
Når tidsrejsens opbevaringsperiode udløber, begynder en 7-dages fejlsikker periode, som er designet til at beskytte og gendanne tidligere data.
Databricks På samme måde som Snowflakes tidsrejse-funktion fungerer, gør Delta Lake's det også. Data, der opbevares i Delta Lake, bliver automatisk versioneret, hvilket giver brugerne mulighed for at hente tidligere dataversioner til fremtidig brug.
Databricks kører på Spark, og da Spark er bygget på lagring på objektniveau, gemmer Databricks aldrig rigtig nogen data.
Dette er en af dens vigtigste fordele. Dette indebærer også, at Databricks kan håndtere use cases for on-premise systemer.
Sikkerhed
Alle data krypteres automatisk i hvile i Snowflake.
Al kommunikation mellem kontrolplanet og dataplanet foregår inden for skyudbyderens private netværk, og alle data gemt i Databricks er sikret.
Begge muligheder tilbyder RBAC (rollebaseret adgangskontrol). Snowflake og Databricks overholder adskillige love og certificeringer, herunder SOC 2 Type II, ISO 27001, HIPAA og GDPR.
Men da Databricks opererer oven på lager på objektniveau som AWS S3, Azure Blob Storage, Google Cloud Opbevaring osv., den mangler et opbevaringslag i modsætning til Snowflake.
Performance (Præstation)
Med hensyn til ydeevne er Snowflake og Databricks så radikalt forskellige løsninger, at det er ret udfordrende at sammenligne dem.
Det er muligt at ændre hvert benchmark for at præsentere en lidt anderledes fortælling. Et perfekt eksempel på dette er nylig undersøgelse udført af Databricks om TPC-DS benchmark.
Med hensyn til en head-to-head sammenligning understøtter Snowflake og Databricks lidt forskellige anvendelsestilfælde, og ingen er i sagens natur den anden overlegen.
Snowflake kan dog være en foretrukken mulighed for interaktive forespørgsler, da det optimerer al lagring til dataadgang på tidspunktet for indtagelse.
Use Case
BI og SQL use cases er godt understøttet af Databricks og Snowflake.
Snowflake leverer JDBC- og ODBC-drivere, der er nemme at integrere med anden software.
Da kunderne ikke behøver at administrere programmet, er det mest kendt for dets use-cases i BI og for virksomheder, der vælger en ligetil analytisk platform.
Open-source Delta Lake, som Databricks har udgivet, tilføjer et ekstra lag af stabilitet til deres Data Lake i mellemtiden. Kunder kan sende SQL-forespørgsler til Delta Lake med stor ydeevne.
På grund af deres mangfoldighed og overlegne teknologi er Databricks kendt for deres use-cases, der minimerer leverandørlåsning, er bedre egnet til ML-arbejdsbelastninger og hjælper teknologigiganter.
Priser
Kunder har adgang til fire visninger på virksomhedsniveau med Snowflake. Standard, Enterprise, Business Critical og Virtual Private Snowflake er de fire tilgængelige versioner. Hele prisinformationen er tilgængelig link..
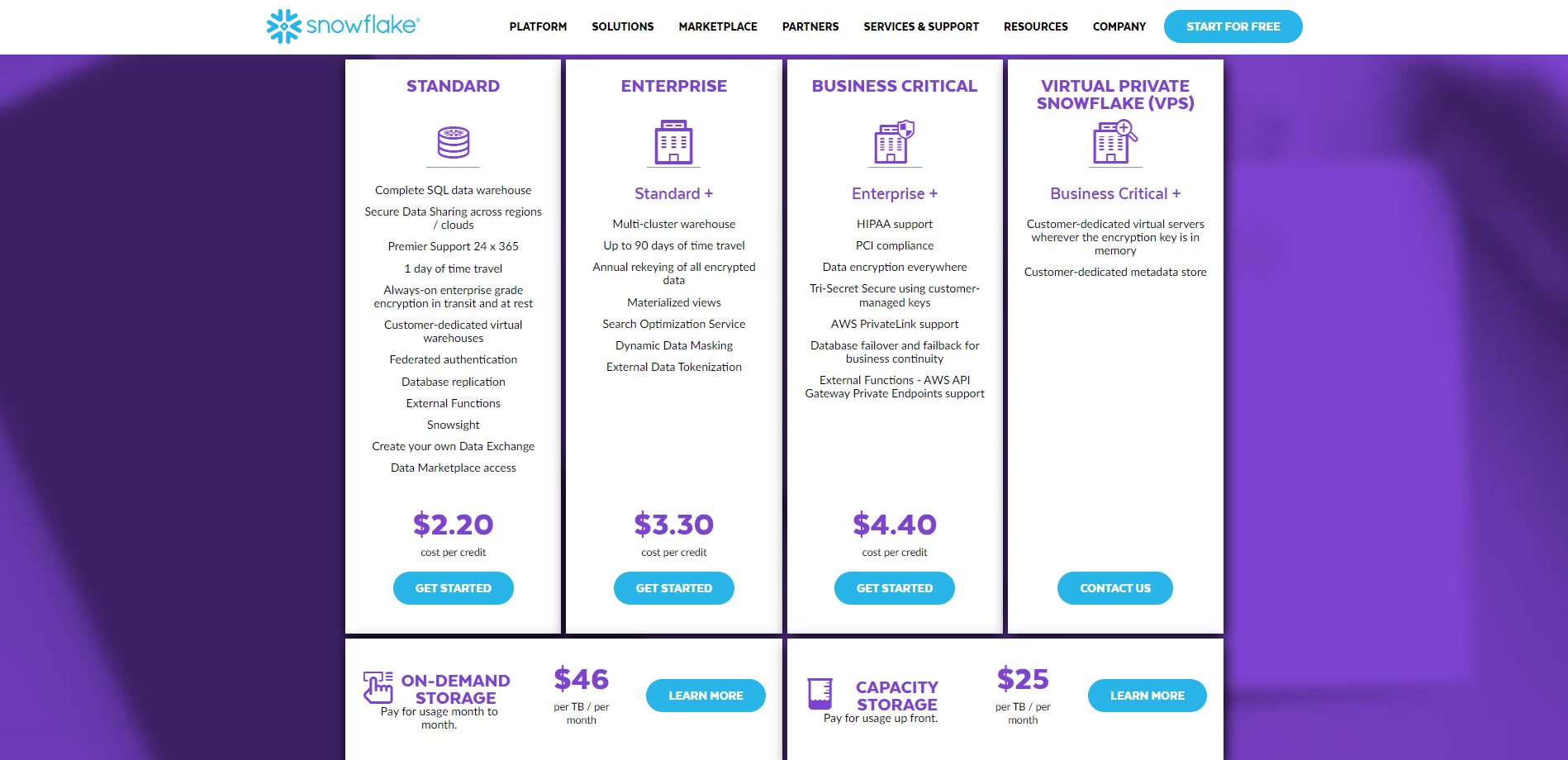
På den anden side er de tre kommercielle prisniveauer, der tilbydes af Databricks, basic, premium og enterprise. Du kan se hele prislisten til højre link..

Konklusion
Fremragende dataanalyseværktøjer inkluderer Snowflake og Databricks.
Der er fordele og ulemper ved hver. Brugsmønstre, datamængder, arbejdsbelastninger og datastrategi spiller alle ind, når du skal beslutte, hvilken platform der er ideel til din virksomhed.
Snowflake er bedre egnet til dem, der har erfaring med SQL og til typisk datatransformation og -analyse.
Streaming, ML, AI og data science-arbejdsbelastninger er bedre egnet til Databricks på grund af dens Spark-motor, som understøtter brugen af adskillige sprog.
For at indhente andre sprog har Snowflake introduceret understøttelse af Python, Java og Scala.
Nogle hævder, at Snowflake minimerer opbevaring under indtagelse, så det er overlegent til interaktive forespørgsler.
Derudover er den fremragende til at producere rapporter og dashboards og administrere BI-arbejdsbelastninger. Med hensyn til et datavarehus klarer det sig godt.
Nogle brugere har dog bemærket, at det lider af store datamængder, såsom dem, der ses i streaming-applikationer. Snowflake triumferer i en direkte konkurrence baseret på data warehousing færdigheder.
Databricks er dog faktisk ikke et datavarehus. Dens dataplatform er mere omfattende og har overlegne ELT-, datavidenskab- og maskinlæringsegenskaber i forhold til Snowflake.
Brugere kontrollerer ikke omkostningerne ved administreret objektlagring, hvor de gemmer deres data. Datasøen og databehandling er hovedemnerne.
Det er dog specifikt rettet mod dataforskere og ekstremt dygtige analytikere.
Afslutningsvis triumferer Databricks for et teknisk publikum. Både teknisk kyndige og ikke-teknisk kyndige brugere kan nemt bruge Snowflake.
Næsten alle de datastyringsfunktioner, som Snowflake tilbyder, er tilgængelige via Databricks og meget mere. Men det er sværere at betjene, involverer en høj indlæringskurve og har brug for mere vedligeholdelse.
Det kan dog håndtere et langt større udvalg af dataarbejdsbelastninger og sprog. Og dem, der er fortrolige med Apache Spark, vil læne sig mod Databricks.
Snowflake er bedre egnet til kunder, der hurtigt vil installere et godt datavarehus og analyseplatform uden at blive hængende i opsætninger, datavidenskabelige detaljer eller manuel opsætning.
Dette er heller ikke for at påstå, at Snowflake er et simpelt værktøj eller for nye brugere. Slet ikke.
Det er ikke så avanceret som Databricks; denne platform er mere velegnet til kompliceret datateknik, ETL, datavidenskab og streamingapplikationer.
Snowflake er et datavarehus til analyse, der gemmer produktionsdata. Derudover er det gavnligt for personer, der ønsker at starte i det små og øge gradvist, såvel som for nybegyndere.





Giv en kommentar