Umělá inteligence je všude, ale někdy může být náročné porozumět terminologii a žargonu. V tomto příspěvku na blogu vysvětlujeme více než 50 pojmů a definic umělé inteligence, abyste mohli lépe pochopit tuto rychle rostoucí technologii.
Ať už jste začátečník nebo expert, vsadíme se, že zde existuje několik termínů, které neznáte!
1. Umělá inteligence
Umělá inteligence (AI) odkazuje na vývoj počítačových systémů, které mají schopnost učit se a fungovat nezávisle, často napodobováním lidské inteligence.
Tyto systémy analyzují data, rozpoznávají vzorce, dělají rozhodnutí a přizpůsobují své chování na základě zkušeností. Využitím algoritmů a modelů se AI snaží vytvořit inteligentní stroje schopné vnímat a chápat své okolí.
Konečným cílem je umožnit strojům efektivně vykonávat úkoly, učit se z dat a vykazovat kognitivní schopnosti podobné lidem.
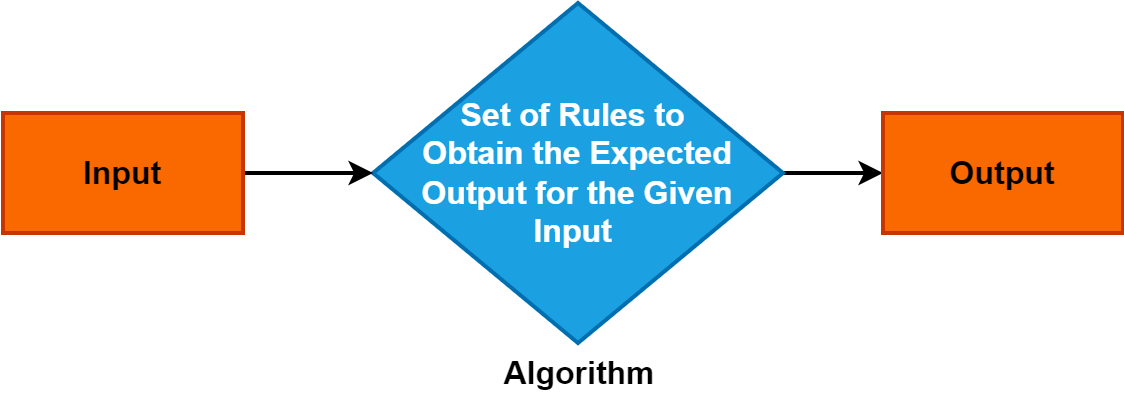
2. algoritmus
Algoritmus je přesný a systematický soubor instrukcí nebo pravidel, které řídí proces řešení problému nebo plnění konkrétního úkolu.
Slouží jako základní koncept v různých oblastech a hraje klíčovou roli v informatice, matematice a disciplínách zaměřených na řešení problémů. Porozumění algoritmům je zásadní, protože umožňují efektivní a strukturované přístupy k řešení problémů, pohánějí pokroky v technologii a rozhodovacích procesech.
3. Velká data
Velká data označují extrémně velké a komplexní datové sady, které přesahují možnosti tradičních analytických metod. Tyto datové sady jsou typicky charakterizovány svým objemem, rychlostí a rozmanitostí.
Objem označuje obrovské množství dat generovaných z různých zdrojů jako např sociální média, senzory a transakce.
Rychlost označuje vysokou rychlost, kterou jsou data generována a je třeba je zpracovávat v reálném čase nebo téměř v reálném čase. Rozmanitost znamená různé typy a formáty dat, včetně strukturovaných, nestrukturovaných a polostrukturovaných dat.
4. Dolování dat
Data mining je komplexní proces zaměřený na získávání cenných poznatků z rozsáhlých datových sad.
Zahrnuje čtyři klíčové fáze: shromažďování údajů, včetně sběru relevantních údajů; příprava dat, zajištění kvality a kompatibility dat; dolování dat, využívání algoritmů k objevování vzorců a vztahů; a analýza a interpretace dat, kde jsou extrahované znalosti zkoumány a chápány.
5. Neuronová síť
Počítačový systém je navržen tak, aby fungoval jako lidský mozek, složený z propojených uzlů nebo neuronů. Pojďme to pochopit trochu více, protože většina AI je založena na neuronové sítě.
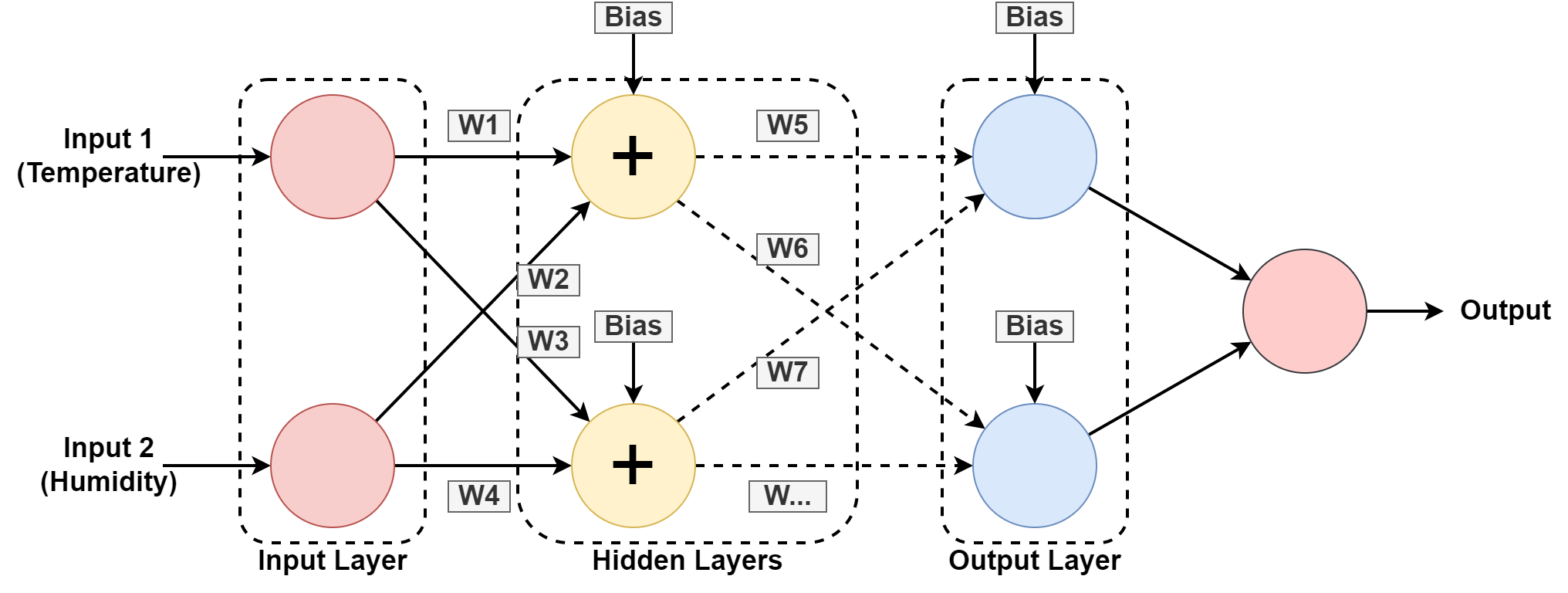
Ve výše uvedené grafice předpovídáme vlhkost a teplotu geografického umístění učením se z minulého vzoru. Vstupy jsou datová sada pro minulý záznam.
Projekt neuronová síť se učí vzor hraním s váhami a aplikací hodnot zkreslení ve skrytých vrstvách. W1, W2….W7 jsou příslušné váhy. Trénuje se na poskytnutém datovém souboru a poskytuje výstup jako předpověď.
Možná budete touto složitou informací zahlceni. Pokud je to váš případ, můžete začít s naším jednoduchým průvodcem zde.
6. Strojové učení
Strojové učení se zaměřuje na vývoj algoritmů a modelů schopných automaticky se učit z dat a zlepšovat jejich výkon v průběhu času.
Zahrnuje použití statistických technik, které umožňují počítačům identifikovat vzory, provádět předpovědi a činit rozhodnutí na základě dat, aniž by byly explicitně naprogramovány.
Algoritmy strojového učení analyzovat a učit se z velkých datových souborů, což umožňuje systémům přizpůsobit a zlepšit své chování na základě informací, které zpracovávají.
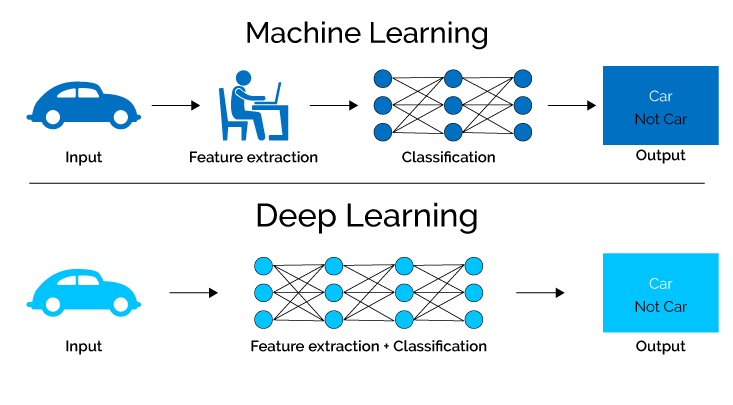
7. Hluboké učení
Hluboké učení, podpole strojového učení a neuronových sítí, využívá sofistikované algoritmy k získávání znalostí z dat simulací složitých procesů lidského mozku.
Využitím neuronových sítí s četnými skrytými vrstvami mohou modely hlubokého učení autonomně extrahovat složité funkce a vzory, což jim umožňuje řešit složité úkoly s výjimečnou přesností a účinností.
8. Rozpoznávání vzorů
Rozpoznávání vzorů, technika analýzy dat, využívá sílu algoritmů strojového učení k autonomní detekci a rozpoznání vzorů a pravidelností v rámci datových sad.
Díky využití výpočtových modelů a statistických metod mohou algoritmy rozpoznávání vzorů identifikovat smysluplné struktury, korelace a trendy ve složitých a různorodých datech.
Tento proces umožňuje extrakci cenných poznatků, klasifikaci dat do odlišných kategorií a predikci budoucích výsledků na základě uznávaných vzorců. Rozpoznávání vzorů je životně důležitým nástrojem napříč různými doménami, který umožňuje rozhodování, detekci anomálií a prediktivní modelování.
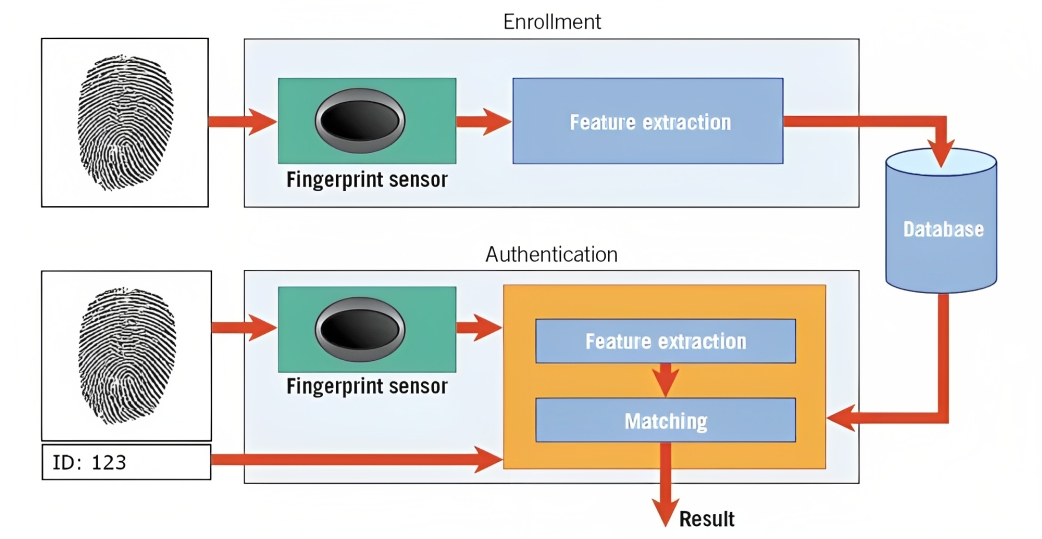
Biometrie je jedním z příkladů. Například při rozpoznávání otisků prstů algoritmus analyzuje vyvýšeniny, křivky a jedinečné rysy otisku prstu osoby, aby vytvořil digitální reprezentaci nazývanou šablona.
Když se pokusíte odemknout svůj smartphone nebo přistupovat k zabezpečenému zařízení, systém rozpoznávání vzorů porovná zachycená biometrická data (např. otisk prstu) s uloženými šablonami ve své databázi.
Porovnáním vzorů a posouzením úrovně podobnosti může systém určit, zda poskytnutá biometrická data odpovídají uložené šabloně, a podle toho udělit přístup.
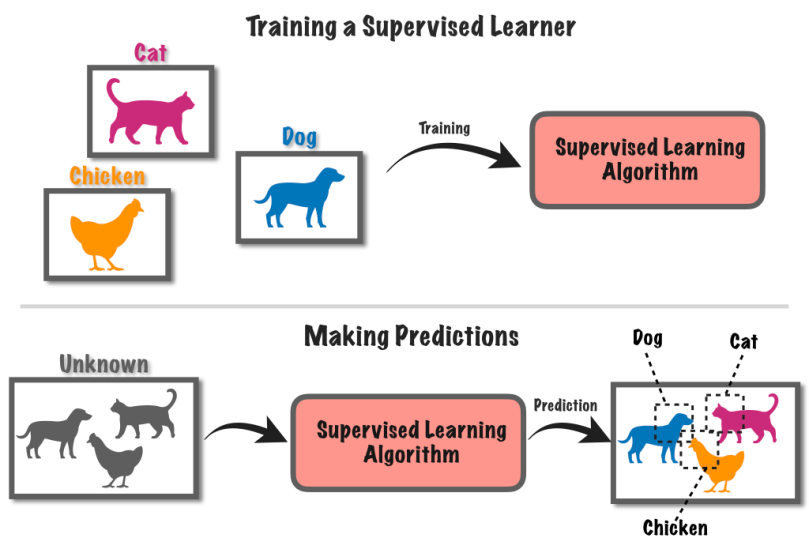
9. Učení pod dohledem
Učení pod dohledem je přístup strojového učení, který zahrnuje trénování počítačového systému pomocí označených dat. V tomto způsobu je počítač opatřen sadou vstupních dat spolu s odpovídajícími známými štítky nebo výsledky.
Řekněme, že máte spoustu obrázků, některé se psy a některé s kočkami.
Řeknete počítači, na kterých obrázcích jsou psi a na kterých kočky. Počítač se pak naučí rozpoznávat rozdíly mezi psy a kočkami tím, že na obrázcích najde vzory.
Poté, co se to naučí, můžete dát počítači nové obrázky a na základě toho, co se naučil z označených příkladů, se pokusí zjistit, zda mají psy nebo kočky. Je to jako trénovat počítač, aby předpovídal pomocí známých informací.
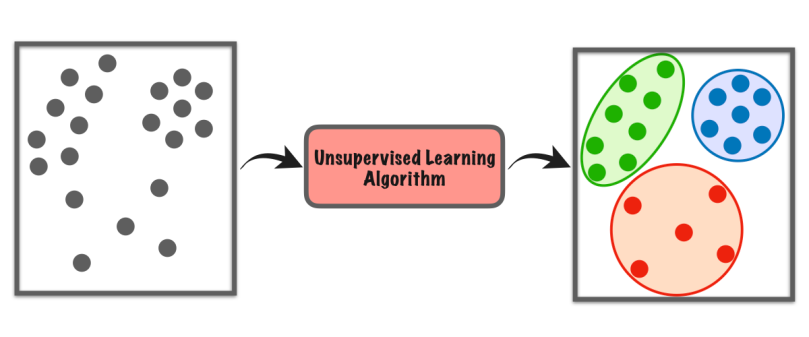
10. Učení bez dozoru
Učení bez dozoru je typ strojového učení, kdy počítač sám prozkoumává datovou sadu, aby našel vzorce nebo podobnosti bez jakýchkoli specifických pokynů.
Nespoléhá se na označené příklady jako při učení pod dohledem. Místo toho hledá v datech skryté struktury nebo skupiny. Je to, jako by počítač objevoval věci sám, aniž by mu učitel říkal, co má hledat.
Tento typ učení nám pomáhá nacházet nové poznatky, organizovat data nebo identifikovat neobvyklé věci, aniž bychom potřebovali předchozí znalosti nebo výslovné pokyny.
11. Zpracování přirozeného jazyka (NLP)
Zpracování přirozeného jazyka se zaměřuje na to, jak počítače rozumí lidskému jazyku a jak s ním komunikují. Pomáhá počítačům analyzovat, interpretovat a reagovat na lidský jazyk způsobem, který je pro nás přirozenější.
NLP je to, co nám umožňuje komunikovat s hlasovými asistenty a chatboty a dokonce nechat naše e-maily automaticky třídit do složek.
Zahrnuje to naučit počítače rozumět významu slov, vět a dokonce celých textů, takže nám mohou pomáhat při různých úkolech a usnadnit naše interakce s technologiemi.
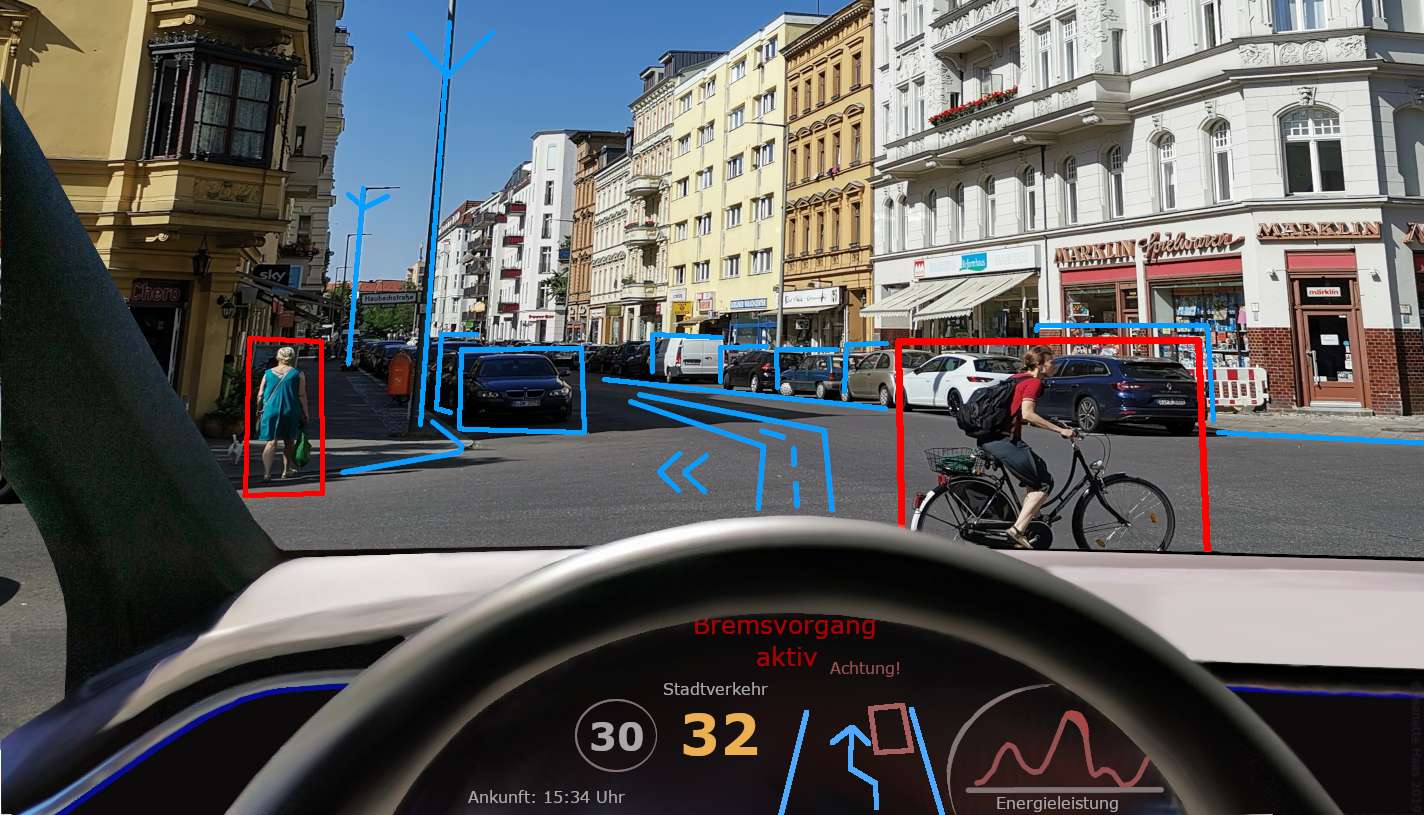
12. Počítačové vidění
Počítačové vidění je fascinující technologie, která umožňuje počítačům vidět a porozumět obrázkům a videím, stejně jako to my lidé děláme očima. Jde o to naučit počítače analyzovat vizuální informace a dávat smysl tomu, co vidí.
Jednodušeji řečeno, počítačové vidění pomáhá počítačům rozpoznat a interpretovat vizuální svět. Zahrnuje úkoly, jako je naučit je identifikovat konkrétní objekty na obrázcích, klasifikovat obrázky do různých kategorií nebo dokonce rozdělovat obrázky na smysluplné části.
Představte si auto s vlastním řízením, které používá počítačové vidění k „vidění“ silnice a všeho kolem ní.
Dokáže detekovat a sledovat chodce, dopravní značky a další vozidla a pomáhá jim bezpečně navigovat. Nebo se zamyslete nad tím, jak technologie rozpoznávání obličeje využívá počítačové vidění k odemykání našich chytrých telefonů nebo ověřování naší identity rozpoznáním našich jedinečných rysů obličeje.
Používá se také v sledovacích systémech ke sledování přeplněných míst a zjištění jakýchkoli podezřelých aktivit.
Počítačové vidění je výkonná technologie, která otevírá svět možností. Tím, že počítačům umožníme vidět a porozumět vizuálním informacím, můžeme vyvíjet aplikace a systémy, které dokážou vnímat a interpretovat svět kolem nás, díky čemuž jsou naše životy jednodušší, bezpečnější a efektivnější.
13. Chatbot
Chatbot je jako počítačový program, který dokáže mluvit s lidmi způsobem, který vypadá jako skutečná lidská konverzace.
Často se používá v online zákaznickém servisu, aby pomohl zákazníkům a dal jim pocit, že mluví s osobou, i když je to ve skutečnosti program běžící na počítači.
Chatbot dokáže porozumět zprávám nebo otázkám zákazníků a reagovat na ně a poskytovat užitečné informace a pomoc stejně jako lidský zástupce zákaznických služeb.
14. Rozpoznávání hlasu
Rozpoznávání hlasu označuje schopnost počítačového systému porozumět a interpretovat lidskou řeč. Zahrnuje technologii, která umožňuje počítači nebo zařízení „poslouchat“ mluvená slova a převádět je na text nebo příkazy, kterým rozumí.
S rozpoznávání hlasu, můžete se zařízeními nebo aplikacemi pracovat tak, že na ně budete namísto psaní nebo jiných vstupních metod jednoduše mluvit.
Systém analyzuje mluvená slova, rozpozná vzory a zvuky a poté je převede do srozumitelného textu nebo akcí. Umožňuje hands-free a přirozenou komunikaci s technologií, což umožňuje úkoly, jako jsou hlasové příkazy, diktování nebo hlasově řízené interakce. Nejběžnějšími příklady jsou asistenti AI jako Siri a Google Assistant.
15. Analýza sentimentu
Analýza sentimentu je technika používaná k porozumění a interpretaci emocí, názorů a postojů vyjádřených v textu nebo řeči. Zahrnuje analýzu psaného nebo mluveného jazyka, aby se zjistilo, zda je vyjádřený sentiment pozitivní, negativní nebo neutrální.
Pomocí algoritmů strojového učení mohou algoritmy analýzy sentimentu skenovat a analyzovat velké množství textových dat, jako jsou recenze zákazníků, příspěvky na sociálních sítích nebo zpětná vazba od zákazníků, aby identifikovaly základní sentiment za těmito slovy.
Algoritmy hledají konkrétní slova, fráze nebo vzorce, které označují emoce nebo názory.
Tato analýza pomáhá firmám nebo jednotlivcům porozumět tomu, jak lidé vnímají produkt, službu nebo téma, a lze ji použít k rozhodování na základě dat nebo k získání přehledu o preferencích zákazníků.
Společnost může například použít analýzu sentimentu ke sledování spokojenosti zákazníků, identifikaci oblastí pro zlepšení nebo sledování veřejného mínění o jejich značce.
16. Strojový překlad
Strojový překlad v kontextu umělé inteligence označuje použití počítačových algoritmů a umělé inteligence k automatickému překladu textu nebo řeči z jednoho jazyka do druhého.
Zahrnuje výuku počítačů, aby rozuměly lidským jazykům a zpracovávaly je, aby byly zajištěny přesné překlady. Nejčastějším příkladem je Google Překladač.
Pomocí strojového překladu můžete vkládat text nebo řeč v jednom jazyce a systém analyzuje vstup a vygeneruje odpovídající překlad do jiného jazyka. To je užitečné zejména při komunikaci nebo přístupu k informacím v různých jazycích.
Systémy strojového překladu se spoléhají na kombinaci lingvistických pravidel, statistických modelů a algoritmů strojového učení. Učí se z obrovského množství jazykových dat, aby časem zlepšili přesnost překladu. Některé přístupy strojového překladu také zahrnují neuronové sítě pro zvýšení kvality překladů.
17. Robotika
Robotika je spojením umělé inteligence a strojního inženýrství k vytvoření inteligentních strojů nazývaných roboti. Tyto roboty jsou navrženy tak, aby vykonávaly úkoly autonomně nebo s minimálním zásahem člověka.
Roboti jsou fyzické entity, které dokážou vnímat své prostředí, rozhodovat se na základě tohoto smyslového vstupu a provádět specifické akce nebo úkoly.
Jsou vybaveny různými senzory, jako jsou kamery, mikrofony, nebo dotykové senzory, které jim umožňují sbírat informace z okolního světa. S pomocí algoritmů a programování umělé inteligence mohou roboti tato data analyzovat, interpretovat je a činit inteligentní rozhodnutí pro plnění svých určených úkolů.
Umělá inteligence hraje klíčovou roli v robotice tím, že umožňuje robotům učit se ze svých zkušeností a přizpůsobovat se různým situacím.
Algoritmy strojového učení lze použít k trénování robotů k rozpoznávání objektů, navigaci v prostředí nebo dokonce k interakci s lidmi. To umožňuje robotům stát se všestrannějšími, flexibilnějšími a schopnými zvládat složité úkoly.
18 Drones
Drony jsou typem robota, který může létat nebo se vznášet ve vzduchu bez lidského pilota na palubě. Jsou také známé jako bezpilotní letouny (UAV). Drony jsou vybaveny různými senzory, jako jsou kamery, GPS a gyroskopy, které jim umožňují sbírat data a navigovat v okolí.
Jsou ovládány na dálku lidským operátorem nebo mohou fungovat autonomně pomocí předem naprogramovaných instrukcí.
Drony slouží široké škále účelů, včetně leteckého fotografování a natáčení videa, průzkumu a mapování, doručovacích služeb, pátracích a záchranných misí, monitorování zemědělství a dokonce i rekreačního využití. Mohou se dostat do vzdálených nebo nebezpečných oblastí, které jsou pro člověka obtížné nebo nebezpečné.
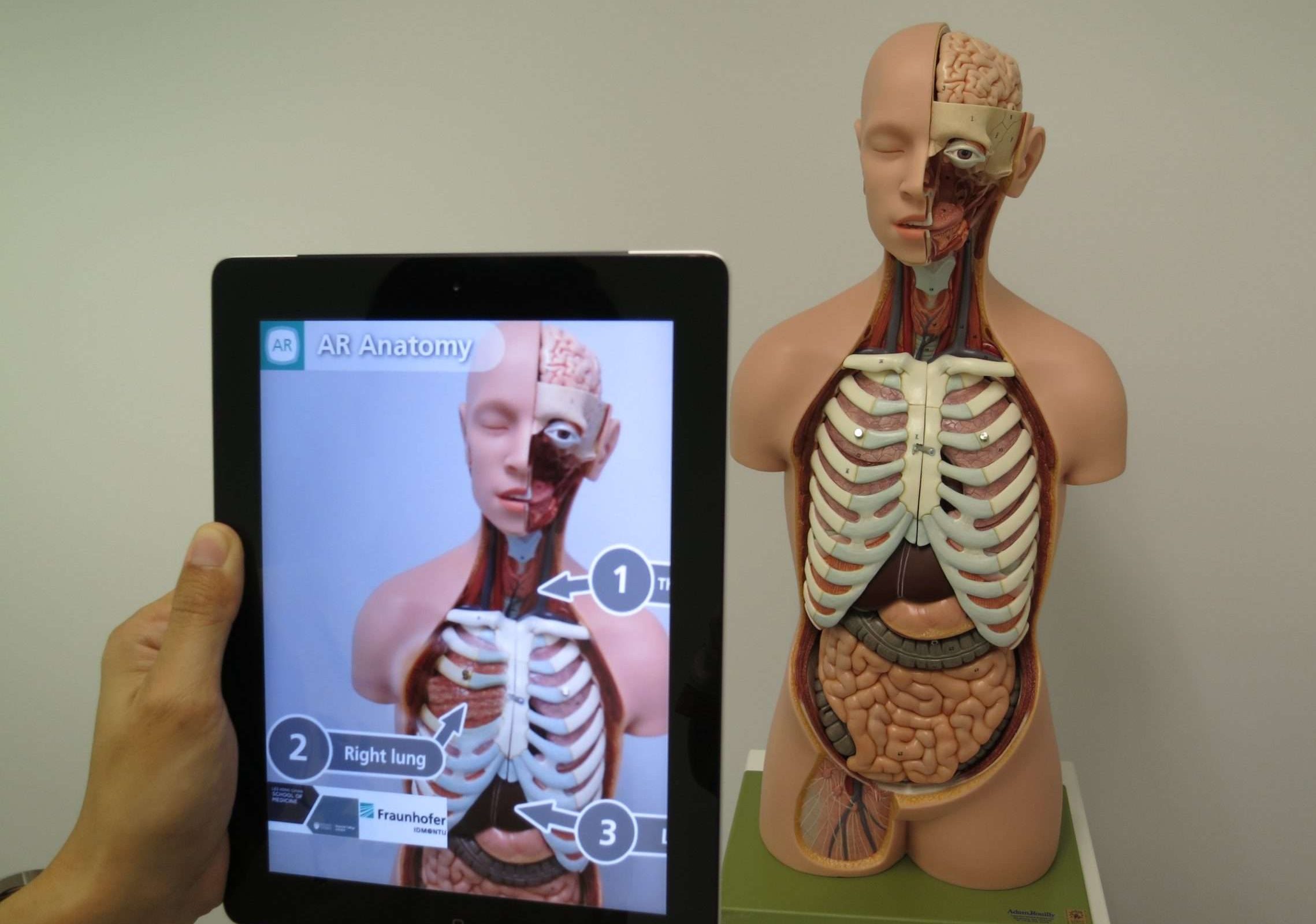
19. Rozšířená realita (AR)
Rozšířená realita (AR) je technologie, která kombinuje skutečný svět s virtuálními objekty nebo informacemi, aby zlepšila naše vnímání a interakci s okolím. Překrývá počítačem generované obrazy, zvuky nebo jiné smyslové vstupy do skutečného světa a vytváří pohlcující a interaktivní zážitek.
Jednoduše řečeno, představte si, že nosíte speciální brýle nebo používáte svůj chytrý telefon k vidění světa kolem sebe, ale s přidanými dalšími virtuálními prvky.
Můžete například namířit svůj smartphone na ulici města a vidět virtuální ukazatele s pokyny, hodnocení a recenze restaurací v okolí nebo dokonce virtuální postavy, které komunikují se skutečným prostředím.
Tyto virtuální prvky se hladce prolínají se skutečným světem a zlepšují vaše porozumění a zkušenosti s okolím. Rozšířenou realitu lze použít v různých oblastech, jako je hraní her, vzdělávání, architektura, a dokonce i pro každodenní úkoly, jako je navigace nebo zkoušení nového nábytku ve vaší domácnosti, než si jej koupíte.
20. Virtuální realita (VR)
Virtuální realita (VR) je technologie, která využívá počítačově generované simulace k vytvoření umělého prostředí, které může člověk zkoumat a interagovat s ním. Ponoří uživatele do virtuálního světa, zablokuje skutečný svět a nahradí jej digitální sférou.
Jednoduše řečeno, představte si, že si nasadíte speciální headset, který vám zakryje oči a uši a přenese vás na úplně jiné místo. V tomto virtuálním světě je vše, co vidíte a slyšíte, neuvěřitelně skutečné, i když je to všechno generováno počítačem.
Můžete se pohybovat, dívat se libovolným směrem a interagovat s předměty nebo postavami, jako by byly fyzicky přítomné.
Například ve hře pro virtuální realitu se můžete ocitnout uvnitř středověkého hradu, kde můžete procházet jeho chodbami, sbírat zbraně a pouštět se do šermířských soubojů s virtuálními protivníky. Prostředí virtuální reality reaguje na vaše pohyby a akce, díky čemuž se cítíte plně ponořeni a zapojeni do zážitku.
Virtuální realita se nepoužívá pouze pro hraní her, ale také pro různé další aplikace, jako jsou simulace výcviku pilotů, chirurgů nebo vojenského personálu, architektonické návody, virtuální turistika a dokonce i terapie určitých psychických stavů. Vytváří pocit přítomnosti a přenáší uživatele do nových a vzrušujících virtuálních světů, díky čemuž je zážitek co nejblíže realitě.
21. Data Science
Datová věda je obor, který zahrnuje používání vědeckých metod, nástrojů a algoritmů k získávání cenných znalostí a poznatků z dat. Kombinuje prvky matematiky, statistiky, programování a doménových znalostí k analýze velkých a komplexních datových sad.
Jednodušeji řečeno, datová věda je o hledání smysluplných informací a vzorců skrytých v hromadě dat. Zahrnuje shromažďování, čištění a organizování dat a poté použití různých technik k jejich prozkoumání a analýze. Datoví vědci používat statistické modely a algoritmy k odhalování trendů, vytváření předpovědí a řešení problémů.
Například v oblasti zdravotnictví lze datovou vědu použít k analýze záznamů o pacientech a lékařských údajů k identifikaci rizikových faktorů onemocnění, předpovídání výsledků pacientů nebo optimalizaci léčebných plánů. V podnikání lze datovou vědu aplikovat na zákaznická data, aby bylo možné pochopit jejich preference, doporučit produkty nebo zlepšit marketingové strategie.
22. Data Wrangling
Data wrangling, také známý jako data munging, je proces shromažďování, čištění a transformace nezpracovaných dat do formátu, který je užitečnější a vhodnější pro analýzu. Zahrnuje zpracování a přípravu dat k zajištění jejich kvality, konzistence a kompatibility s analytickými nástroji nebo modely.
Jednodušeji řečeno, zápas o data je jako příprava ingrediencí na vaření. Zahrnuje shromažďování dat z různých zdrojů, jejich třídění a čištění, aby se odstranily všechny chyby, nekonzistence nebo nepodstatné informace.
Kromě toho může být nutné data transformovat, restrukturalizovat nebo agregovat, aby se s nimi snadněji pracovalo a extrahovaly statistiky.
Datové šarvátky mohou například zahrnovat odstranění duplicitních záznamů, opravu překlepů nebo problémů s formátováním, zpracování chybějících hodnot a převod datových typů. Může také zahrnovat slučování nebo spojování různých datových sad dohromady, rozdělení dat do podmnožin nebo vytváření nových proměnných na základě existujících dat.
23. Vyprávění dat
Vyprávění dat je umění prezentovat data přesvědčivým a poutavým způsobem, aby bylo možné efektivně komunikovat příběh nebo zprávu. Zahrnuje použití vizualizace dat, vyprávění a kontext k předávání postřehů a zjištění způsobem, který je pro publikum srozumitelný a zapamatovatelný.
Jednodušeji řečeno, vyprávění příběhů dat spočívá v použití dat k vyprávění příběhu. Jde nad rámec pouhé prezentace čísel a grafů. Zahrnuje vytvoření příběhu o datech, použití vizuálních prvků a technik vyprávění, aby data ožila a stala se poutavou pro publikum.
Například namísto jednoduché prezentace tabulky prodejních čísel může vyprávění dat zahrnovat vytvoření interaktivního řídicího panelu, který uživatelům umožňuje vizuálně prozkoumat prodejní trendy.
Mohlo by to zahrnovat vyprávění, které zdůrazňuje klíčová zjištění, vysvětluje důvody trendů a na základě dat navrhuje praktická doporučení.
24. Rozhodování na základě dat
Rozhodování založené na datech je proces rozhodování nebo přijímání opatření na základě analýzy a interpretace relevantních dat. Zahrnuje používání dat jako základu pro vedení a podporu rozhodovacích procesů, spíše než spoléhání se pouze na intuici nebo osobní úsudek.
Jednodušeji řečeno, rozhodování založené na datech znamená používat fakta a důkazy z dat k informování a vedení našich rozhodnutí. Zahrnuje shromažďování a analýzu dat k pochopení vzorců, trendů a vztahů a využívání těchto znalostí k přijímání informovaných rozhodnutí a řešení problémů.
Například v obchodním prostředí může rozhodování založené na datech zahrnovat analýzu dat o prodeji, zpětné vazby od zákazníků a tržních trendů za účelem stanovení nejúčinnější cenové strategie nebo identifikaci oblastí pro zlepšení ve vývoji produktů.
Ve zdravotnictví může zahrnovat analýzu údajů o pacientech za účelem optimalizace léčebných plánů nebo predikce výsledků onemocnění.
25. Datové jezero
Datové jezero je centralizované a škálovatelné úložiště dat, které ukládá obrovské množství dat v nezpracované a nezpracované podobě. Je navržen tak, aby pojal širokou škálu datových typů, formátů a struktur, jako jsou strukturovaná, polostrukturovaná a nestrukturovaná data, bez potřeby předdefinovaných schémat nebo transformací dat.
Společnost může například shromažďovat a ukládat data z různých zdrojů, jako jsou protokoly webových stránek, transakce zákazníků, zdroje sociálních médií a zařízení IoT, v datovém jezeře.
Tato data pak lze použít pro různé účely, jako je provádění pokročilé analýzy, provádění algoritmů strojového učení nebo zkoumání vzorců a trendů v chování zákazníků.
26. Datový sklad
Datový sklad je specializovaný databázový systém, který je speciálně navržen pro ukládání, organizaci a analýzu velkého množství dat z různých zdrojů. Je strukturován způsobem, který podporuje efektivní vyhledávání dat a komplexní analytické dotazy.
Slouží jako centrální úložiště, které integruje data z různých operačních systémů, jako jsou transakční databáze, systémy CRM a další zdroje dat v rámci organizace.
Data jsou transformována, vyčištěna a načtena do datového skladu ve strukturovaném formátu optimalizovaném pro analytické účely.
27. Business Intelligence (BI)
Business intelligence označuje proces shromažďování, analýzy a prezentace dat způsobem, který pomáhá podnikům činit informovaná rozhodnutí a získávat cenné poznatky. Zahrnuje použití různých nástrojů, technologií a technik k přeměně nezpracovaných dat na smysluplné a použitelné informace.
Systém business intelligence může například analyzovat údaje o prodeji, aby identifikoval nejziskovější produkty, sledoval úrovně zásob a sledoval preference zákazníků.
Může poskytovat v reálném čase přehledy o klíčových ukazatelích výkonu (KPI), jako jsou výnosy, akvizice zákazníků nebo výkon produktů, což firmám umožňuje přijímat rozhodnutí na základě dat a přijímat vhodná opatření ke zlepšení jejich provozu.
Nástroje business intelligence často zahrnují funkce jako vizualizace dat, ad hoc dotazování a možnosti prozkoumávání dat. Tyto nástroje umožňují uživatelům, jako je např obchodní analytici nebo manažerům, k interakci s daty, jejich dělení a dělení a generování zpráv nebo vizuálních reprezentací, které zdůrazňují důležité poznatky a trendy.
28. Prediktivní analýza
Prediktivní analýza je praxe používání dat a statistických technik k vytváření informovaných předpovědí nebo předpovědí budoucích událostí nebo výsledků. Zahrnuje analýzu historických dat, identifikaci vzorců a vytváření modelů pro extrapolaci a odhad budoucích trendů, chování nebo výskytů.
Jeho cílem je odhalit vztahy mezi proměnnými a použít tyto informace k předpovědím. Jde nad rámec pouhého popisu minulých událostí; místo toho využívá historická data k pochopení a předvídání toho, co se pravděpodobně stane v budoucnosti.
Například v oblasti financí lze k prognózování použít prediktivní analýzu stock ceny založené na historických tržních datech, ekonomických ukazatelích a dalších relevantních faktorech.
V marketingu jej lze využít k predikci chování a preferencí zákazníků, což umožňuje cílenou reklamu a personalizované marketingové kampaně.
Ve zdravotnictví může prediktivní analýza pomoci identifikovat pacienty s vysokým rizikem určitých onemocnění nebo předpovědět pravděpodobnost opětovného přijetí na základě anamnézy a dalších faktorů.
29. Preskriptivní analýza
Preskriptivní analytika je aplikace dat a analýzy k určení nejlepších možných akcí, které je třeba podniknout v konkrétní situaci nebo scénáři rozhodování.
Jde nad rámec popisnosti a prediktivní analýzy tím, že nejen poskytne přehled o tom, co se může stát v budoucnu, ale také doporučí nejoptimálnější postup k dosažení požadovaného výsledku.
Kombinuje historická data, prediktivní modely a optimalizační techniky k simulaci různých scénářů a vyhodnocení potenciálních výsledků různých rozhodnutí. Bere v úvahu několik omezení, cílů a faktorů, aby generovala praktická doporučení, která maximalizují požadované výsledky nebo minimalizují rizika.
Například v dodavatelského řetězce management, preskriptivní analytika může analyzovat data o úrovních zásob, výrobních kapacitách, dopravních nákladech a poptávce zákazníků a určit tak nejefektivnější plán distribuce.
Může doporučit ideální alokaci zdrojů, jako jsou skladová místa nebo přepravní trasy, aby se minimalizovaly náklady a zajistilo se včasné dodání.
30. Marketing řízený daty
Marketing řízený daty označuje praxi používání dat a analýz k řízení marketingových strategií, kampaní a rozhodovacích procesů.
Zahrnuje využití různých zdrojů dat k získání přehledu o chování zákazníků, preferencích a trendech a použití těchto informací k optimalizaci marketingového úsilí.
Zaměřuje se na shromažďování a analýzu dat z více kontaktních bodů, jako jsou interakce na webu, zapojení na sociálních sítích, demografické údaje zákazníků, historie nákupů a další. Tato data se pak použijí k vytvoření komplexního pochopení cílového publika, jeho preferencí a potřeb.
Díky využití dat mohou marketéři činit informovaná rozhodnutí týkající se segmentace zákazníků, cílení a personalizace.
Dokážou identifikovat konkrétní segmenty zákazníků, u kterých je pravděpodobnější, že budou pozitivně reagovat na marketingové kampaně, a podle toho přizpůsobit svá sdělení a nabídky.
Marketing řízený daty navíc pomáhá při optimalizaci marketingových kanálů, určování nejúčinnějšího marketingového mixu a měření úspěšnosti marketingových iniciativ.
Marketingový přístup založený na datech může například zahrnovat analýzu zákaznických dat za účelem identifikace nákupního chování a vzorců preferencí. Na základě těchto poznatků mohou marketéři vytvářet cílené kampaně s personalizovaným obsahem a nabídkami, které rezonují u konkrétních zákaznických segmentů.
Prostřednictvím nepřetržité analýzy a optimalizace mohou měřit efektivitu svých marketingových snah a zdokonalovat strategie v průběhu času.
31. Správa dat
Správa dat je rámec a soubor postupů, které organizace přijímají k zajištění správné správy, ochrany a integrity dat během jejich životního cyklu. Zahrnuje procesy, zásady a postupy, které řídí, jak jsou data shromažďována, ukládána, zpřístupňována, používána a sdílena v rámci organizace.
Jeho cílem je vytvořit odpovědnost, odpovědnost a kontrolu nad datovými aktivy. Zajišťuje, že data jsou přesná, úplná, konzistentní a důvěryhodná, což organizacím umožňuje přijímat informovaná rozhodnutí, udržovat kvalitu dat a plnit regulační požadavky.
Správa dat zahrnuje definování rolí a odpovědností za správu dat, stanovení datových standardů a zásad a implementaci procesů pro sledování a vynucování souladu. Zabývá se různými aspekty správy dat, včetně ochrany osobních údajů, zabezpečení dat, kvality dat, klasifikace dat a správy životního cyklu dat.
Správa dat může například zahrnovat implementaci postupů, které zajistí, že s osobními nebo citlivými údaji bude nakládáno v souladu s platnými předpisy o ochraně osobních údajů, jako je obecné nařízení o ochraně osobních údajů (GDPR).
Může také zahrnovat stanovení norem kvality údajů a provádění procesů validace údajů, aby bylo zajištěno, že údaje jsou přesné a spolehlivé.
32. Zabezpečení údajů
Zabezpečení dat spočívá v ochraně našich cenných informací před neoprávněným přístupem nebo krádeží. Zahrnuje přijetí opatření na ochranu důvěrnosti, integrity a dostupnosti dat.
V podstatě to znamená zajistit, aby k našim údajům měli přístup pouze ti správní lidé, aby zůstala přesná a nezměněná a aby byla v případě potřeby k dispozici.
K dosažení bezpečnosti dat se používají různé strategie a technologie. Například kontroly přístupu a metody šifrování pomáhají omezit přístup k autorizovaným jednotlivcům nebo systémům, což ztěžuje přístup cizích osob k našim datům.
Monitorovací systémy, firewally a systémy detekce narušení fungují jako strážci, upozorňují nás na podezřelé aktivity a zabraňují neoprávněnému přístupu.
33 Internet věcí
Internet věcí (IoT) označuje síť fyzických objektů nebo „věcí“, které jsou připojeny k internetu a mohou spolu komunikovat. Je to jako velká síť každodenních předmětů, zařízení a strojů, které jsou schopny sdílet informace a provádět úkoly interakcí přes internet.
Jednoduše řečeno, IoT zahrnuje poskytování „inteligentních“ funkcí různým objektům nebo zařízením, které tradičně nebyly připojeny k internetu. Tyto předměty mohou zahrnovat domácí spotřebiče, nositelná zařízení, termostaty, automobily a dokonce i průmyslové stroje.
Po připojení těchto objektů k internetu mohou shromažďovat a sdílet data, přijímat pokyny a provádět úkoly autonomně nebo v reakci na příkazy uživatele.
Inteligentní termostat může například sledovat teplotu, upravovat nastavení a odesílat zprávy o spotřebě energie do aplikace pro chytré telefony. Nositelný fitness tracker může shromažďovat data o vašich fyzických aktivitách a synchronizovat je s cloudovou platformou pro analýzu.
34. Rozhodovací strom
Rozhodovací strom je vizuální reprezentace nebo diagram, který nám pomáhá při rozhodování nebo určování postupu na základě řady voleb nebo podmínek.
Je to jako vývojový diagram, který nás vede rozhodovacím procesem zvažováním různých možností a jejich potenciálních výsledků.
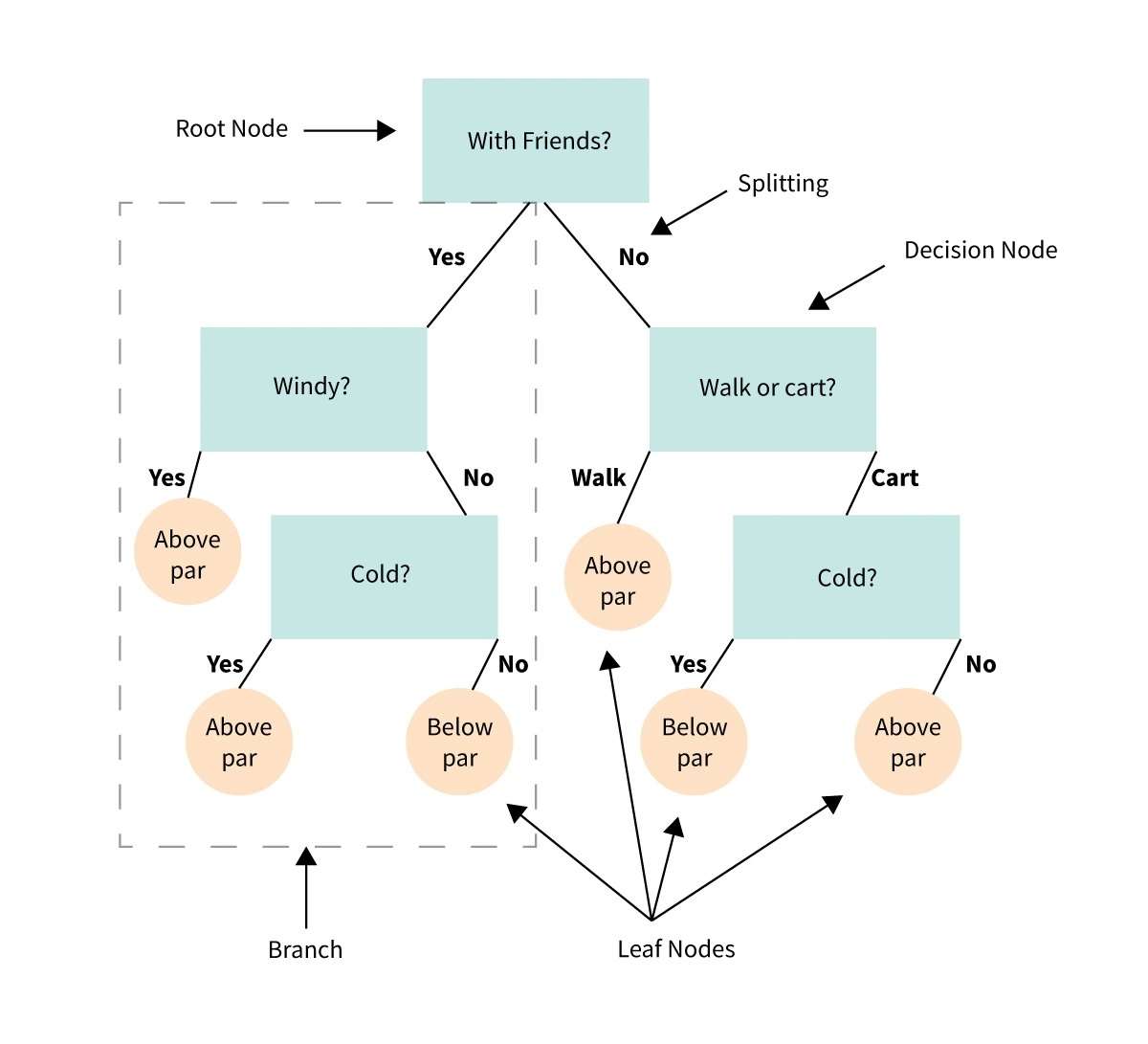
Představte si, že máte problém nebo otázku a potřebujete se rozhodnout.
Rozhodovací strom rozděluje rozhodnutí na menší kroky, počínaje počáteční otázkou a rozvětvující se do různých možných odpovědí nebo akcí na základě podmínek nebo kritérií v každém kroku.
35. Kognitivní výpočty
Kognitivní výpočetní technika, zjednodušeně řečeno, označuje počítačové systémy nebo technologie, které napodobují lidské kognitivní schopnosti, jako je učení, uvažování, porozumění a řešení problémů.
Zahrnuje vytváření počítačových systémů, které dokážou zpracovat a interpretovat informace způsobem, který připomíná lidské myšlení.
Kognitivní výpočetní technika si klade za cíl vyvinout stroje, které dokážou pochopit a komunikovat s lidmi přirozenějším a inteligentnějším způsobem. Tyto systémy jsou navrženy tak, aby analyzovaly obrovské množství dat, rozpoznávaly vzorce, vytvářely předpovědi a poskytovaly smysluplné poznatky.
Představte si kognitivní výpočetní techniku jako pokus přimět počítače myslet a jednat více jako lidé.
Zahrnuje využití technologií, jako je umělá inteligence, strojové učení, zpracování přirozeného jazyka a počítačové vidění, které počítačům umožňují provádět úkoly, které byly tradičně spojovány s lidskou inteligencí.
36. Počítačová teorie učení
Computational Learning Theory je specializovaný obor v oblasti umělé inteligence, který se točí kolem vývoje a zkoumání algoritmů speciálně navržených k učení z dat.
Tato oblast zkoumá různé techniky a metodologie pro konstrukci algoritmů, které mohou autonomně zlepšit svůj výkon analýzou a zpracováním velkého množství informací.
Využitím síly dat se Computational Learning Theory snaží odhalit vzorce, vztahy a poznatky, které umožňují strojům zlepšit jejich rozhodovací schopnosti a provádět úkoly efektivněji.
Konečným cílem je vytvořit algoritmy, které se dokážou přizpůsobit, zobecnit a vytvořit přesné předpovědi na základě dat, kterým byly vystaveny, a přispět tak k rozvoji umělé inteligence a jejích praktických aplikací.
37. Turingův test
Turingův test, původně navržený geniálním matematikem a počítačovým vědcem Alanem Turingem, je strhující koncept používaný k posouzení, zda stroj může vykazovat inteligentní chování srovnatelné s chováním člověka nebo od něj prakticky nerozeznatelné.
V Turingově testu se lidský hodnotitel zapojí do konverzace v přirozeném jazyce se strojem i jiným lidským účastníkem, aniž by věděl, který z nich je stroj.
Úlohou hodnotitele je rozpoznat, která entita je stroj, pouze na základě jejich odpovědí. Pokud je stroj schopen přesvědčit hodnotitele, že je lidským protějškem, pak se říká, že prošel Turingovým testem, čímž prokázal úroveň inteligence, která odráží lidské schopnosti.
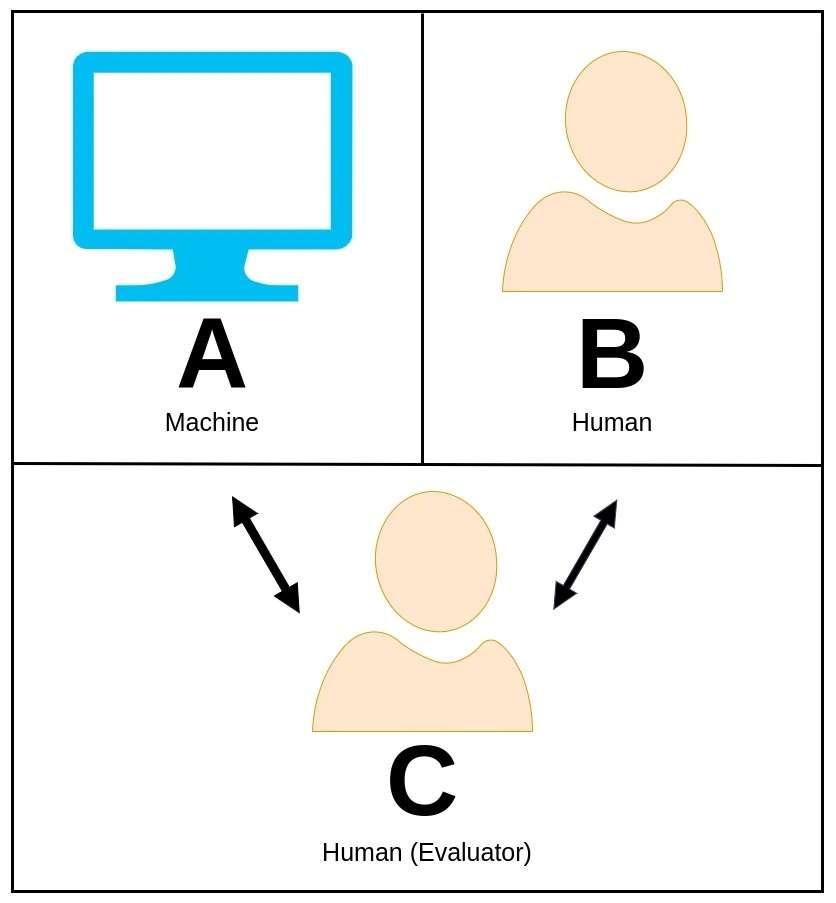
Alan Turing navrhl tento test jako prostředek k prozkoumání konceptu strojové inteligence a k položení otázky, zda stroje mohou dosáhnout poznání na lidské úrovni.
Zarámováním testu z hlediska lidské nerozlišitelnosti Turing zdůraznil potenciál strojů vykazovat chování, které je tak přesvědčivě inteligentní, že je obtížné je odlišit od lidí.
Turingův test rozpoutal rozsáhlé diskuse a výzkum v oblasti umělé inteligence a kognitivní vědy. Přestože absolvování Turingova testu zůstává významným milníkem, není jediným měřítkem inteligence.
Test nicméně slouží jako měřítko, které podněcuje k zamyšlení, stimuluje pokračující úsilí o vývoj strojů schopných napodobovat lidskou inteligenci a chování a přispívá k širšímu zkoumání toho, co to znamená být inteligentní.
38. Posílení učení
Posílení učení je typ učení, ke kterému dochází prostřednictvím pokusů a omylů, kdy se „agent“ (což může být počítačový program nebo robot) učí plnit úkoly tím, že dostává odměny za dobré chování a čelí následkům nebo trestům za špatné chování.
Představte si scénář, ve kterém se agent pokouší dokončit konkrétní úkol, jako je navigace v bludišti. Zpočátku agent nezná správnou cestu, kterou se má vydat, a tak zkouší různé akce a zkoumá různé cesty.
Když si vybere dobrou akci, která ji přiblíží k cíli, obdrží odměnu, jako je virtuální „poplácání po zádech“. Pokud však učiní špatné rozhodnutí, které vede do slepé uličky nebo jej odvede od cíle, dostane trest nebo negativní zpětnou vazbu.
Prostřednictvím tohoto procesu pokusů a omylů se agent učí spojovat určité akce s pozitivními nebo negativními výsledky. Postupně zjišťuje nejlepší posloupnost akcí, aby maximalizovala své odměny a minimalizovala tresty, a nakonec se v tomto úkolu stává zdatnější.
Posílené učení čerpá inspiraci z toho, jak se lidé a zvířata učí tím, že dostávají zpětnou vazbu od prostředí.
Aplikací tohoto konceptu na stroje se výzkumníci zaměřují na vývoj inteligentních systémů, které se mohou učit a přizpůsobovat různým situacím autonomním objevováním nejúčinnějších způsobů chování prostřednictvím procesu pozitivního posilování a negativních důsledků.
39. Extrakce entity
Extrakce entit se týká procesu, ve kterém identifikujeme a extrahujeme důležité části informací, známé jako entity, z bloku textu. Těmito entitami mohou být různé věci, jako jsou jména lidí, názvy míst, názvy organizací a tak dále.
Představme si, že máte odstavec popisující zpravodajský článek.
Extrakce entit by zahrnovala analýzu textu a výběr konkrétních bitů, které představují odlišné entity. Pokud se například v textu zmiňuje jméno osoby jako „John Smith“, místo „New York City“ nebo organizace „OpenAI“, jedná se o entity, které se snažíme identifikovat a extrahovat.
Prováděním extrakce entit v podstatě učíme počítačový program rozpoznávat a izolovat významné prvky z textu. Tento proces nám umožňuje efektivněji organizovat a kategorizovat informace, což usnadňuje vyhledávání, analýzu a odvozování poznatků z velkých objemů textových dat.
Celkově nám extrakce entit pomáhá automatizovat úkol přesně určit důležité entity, jako jsou lidé, místa a organizace, v textu, zefektivnit extrakci cenných informací a zlepšit naši schopnost zpracovávat a porozumět textovým datům.
40. Lingvistická anotace
Lingvistická anotace zahrnuje obohacení textu o další lingvistické informace, abychom zlepšili naše porozumění a analýzu použitého jazyka. Je to jako přidávání užitečných štítků nebo značek do různých částí textu.
Když provádíme lingvistickou anotaci, překračujeme základní slova a věty v textu a začínáme označovat nebo označovat konkrétní prvky. Můžeme například přidat slovní druhy, které označují gramatickou kategorii každého slova (jako podstatné jméno, sloveso, přídavné jméno atd.). To nám pomáhá pochopit roli, kterou každé slovo hraje ve větě.
Další formou lingvistické anotace je pojmenované rozpoznávání entit, kdy identifikujeme a označíme konkrétní pojmenované entity, jako jsou jména lidí, míst, organizací nebo data. To nám umožňuje rychle najít a extrahovat důležité informace z textu.
Anotováním textu těmito způsoby vytváříme strukturovanější a organizovanější reprezentaci jazyka. To může být nesmírně užitečné v různých aplikacích. Pomáhá například zlepšit přesnost vyhledávačů tím, že porozumí záměru za uživatelskými dotazy. Pomáhá také při strojovém překladu, analýze sentimentu, extrakci informací a mnoha dalších úlohách zpracování přirozeného jazyka.
Lingvistická anotace slouží jako zásadní nástroj pro výzkumníky, lingvisty a vývojáře, umožňuje jim studovat jazykové vzorce, vytvářet jazykové modely a vyvíjet sofistikované algoritmy, které dokážou lépe analyzovat a porozumět textu.
41. Hyperparametr
In strojové učení, hyperparametr je jako speciální nastavení nebo konfigurace, o které se musíme rozhodnout před trénováním modelu. Není to něco, co by se model mohl naučit sám z dat; místo toho ji musíme určit předem.
Představte si to jako knoflík nebo přepínač, který můžeme upravit, abychom doladili, jak se model učí a dělá předpovědi. Tyto hyperparametry řídí různé aspekty procesu učení, jako je složitost modelu, rychlost tréninku a kompromis mezi přesností a zobecněním.
Vezměme si například neuronovou síť. Jedním z důležitých hyperparametrů je počet vrstev v síti. Musíme si vybrat, jak hlubokou síť chceme mít, a toto rozhodnutí ovlivňuje její schopnost zachytit složité vzorce v datech.
Mezi další běžné hyperparametry patří rychlost učení, která určuje, jak rychle model upraví své vnitřní parametry na základě trénovacích dat, a síla regularizace, která řídí, jak moc model penalizuje složité vzory, aby se zabránilo nadměrnému přizpůsobení.
Správné nastavení těchto hyperparametrů je klíčové, protože mohou významně ovlivnit výkon a chování modelu. Často to zahrnuje trochu pokusů a omylů, experimentování s různými hodnotami a sledování, jak ovlivňují výkon modelu na ověřovací datové sadě.
42. Metadata
Metadata se týkají dalších informací, které poskytují podrobnosti o dalších datech. Je to jako sada značek nebo štítků, které nám poskytují více kontextu nebo popisují charakteristiky hlavních dat.
Když máme data, ať už se jedná o dokument, fotografii, video nebo jakýkoli jiný typ informací, metadata nám pomáhají porozumět důležitým aspektům těchto dat.
Například v dokumentu mohou metadata obsahovat podrobnosti, jako je jméno autora, datum vytvoření nebo formát souboru. V případě fotografie nám metadata mohou sdělit místo, kde byla pořízena, použitá nastavení fotoaparátu nebo dokonce datum a čas, kdy byla pořízena.
Metadata nám pomáhají efektivněji organizovat, vyhledávat a interpretovat data. Přidáním těchto popisných informací můžeme rychle najít konkrétní soubory nebo pochopit jejich původ, účel nebo kontext, aniž bychom se museli prohrabovat celým obsahem.
43. Redukce rozměrů
Redukce rozměrů je technika používaná ke zjednodušení datové sady snížením počtu prvků nebo proměnných, které obsahuje. Je to jako zhuštění nebo sumarizace informací v datové sadě, aby byla lépe ovladatelná a lépe se s ní pracovalo.
Představte si, že máte datovou sadu s mnoha sloupci nebo atributy představujícími různé charakteristiky datových bodů. Každý sloupec zvyšuje složitost a výpočetní požadavky algoritmů strojového učení.
V některých případech může mít vysoký počet dimenzí problém najít smysluplné vzorce nebo vztahy v datech.
Redukce rozměrů pomáhá vyřešit tento problém tím, že transformuje datovou sadu do reprezentace nižší dimenze a zároveň zachovává co nejvíce relevantních informací. Jeho cílem je zachytit nejdůležitější aspekty nebo variace v datech a zároveň se zbavit nadbytečných nebo méně informativních dimenzí.
44. Klasifikace textu
Klasifikace textu je proces, který zahrnuje přiřazení konkrétních štítků nebo kategorií k blokům textu na základě jejich obsahu nebo významu. Je to jako třídění nebo organizování textových informací do různých skupin nebo tříd pro usnadnění další analýzy nebo rozhodování.
Podívejme se na příklad klasifikace e-mailů. V tomto scénáři chceme určit, zda je příchozí e-mail spam nebo není spam (také známý jako ham). Klasifikace textu Algoritmy analyzují obsah e-mailu a podle toho mu přiřazují štítek.
Pokud algoritmus určí, že e-mail vykazuje vlastnosti běžně spojované se spamem, přiřadí mu štítek „spam“. A naopak, pokud se e-mail jeví jako legitimní a není spam, přiřadí mu štítek „není spam“ nebo „ham“.
Klasifikace textu nachází uplatnění v různých doménách mimo filtrování e-mailů. Používá se v analýze sentimentu k určení sentimentu vyjádřeného v recenzích zákazníků (pozitivní, negativní nebo neutrální).
Zpravodajské články lze zařadit do různých témat nebo kategorií, jako je sport, politika, zábava a další. Protokoly chatu zákaznické podpory lze kategorizovat podle záměru nebo řešeného problému.
45. Slabá AI
Slabá AI, známá také jako úzká AI, označuje systémy umělé inteligence, které jsou navrženy a naprogramovány tak, aby vykonávaly specifické úkoly nebo funkce. Na rozdíl od lidské inteligence, která zahrnuje širokou škálu kognitivních schopností, je slabá umělá inteligence omezena na určitou doménu nebo úkol.
Představte si slabou umělou inteligenci jako specializovaný software nebo stroje, které vynikají při provádění konkrétních úloh. Například může být vytvořen program umělé inteligence pro hraní šachů, který analyzuje herní situace, strategicky tahy a soutěží s lidskými hráči.
Dalším příkladem je systém rozpoznávání obrazu, který dokáže identifikovat objekty na fotografiích nebo videích.
Tyto systémy umělé inteligence jsou vyškoleny a optimalizovány tak, aby vynikaly ve svých specifických oblastech odborných znalostí. Při efektivním plnění svých úkolů spoléhají na algoritmy, data a předem definovaná pravidla.
Nemají však obecnou inteligenci, která by jim umožňovala porozumět nebo vykonávat úkoly mimo jejich určenou doménu.
46. Silná AI
Silná umělá inteligence, známá také jako obecná umělá inteligence nebo umělá obecná inteligence (AGI), označuje formu umělé inteligence, která má schopnost porozumět, učit se a vykonávat jakýkoli intelektuální úkol, který lidská bytost dokáže.
Na rozdíl od slabé umělé inteligence, která je navržena pro konkrétní úkoly, má silná umělá inteligence za cíl replikovat inteligenci a kognitivní schopnosti podobné lidské inteligenci. Usiluje o vytvoření strojů nebo softwaru, které nejen vynikají ve specializovaných úkolech, ale mají také širší porozumění a přizpůsobivost pro řešení široké škály intelektuálních výzev.
Cílem silné umělé inteligence je vyvinout systémy, které dokážou uvažovat, chápat složité informace, učit se ze zkušeností, zapojovat se do konverzací v přirozeném jazyce, projevovat kreativitu a vykazovat další vlastnosti spojené s lidskou inteligencí.
V podstatě se snaží vytvořit systémy umělé inteligence, které dokážou simulovat nebo replikovat myšlení a řešení problémů na lidské úrovni napříč více doménami.
47. Dopředné řetězení
Dopředné řetězení je metoda uvažování nebo logiky, která začíná dostupnými daty a používá je k vyvozování závěrů a vyvozování nových závěrů. Je to jako spojování teček pomocí dostupných informací k posunu vpřed a získání dalších poznatků.
Představte si, že máte soubor pravidel nebo faktů a chcete na jejich základě odvodit nové informace nebo dospět ke konkrétním závěrům. Dopředné řetězení funguje tak, že zkoumá počáteční data a aplikuje logická pravidla ke generování dalších faktů nebo závěrů.
Pro zjednodušení uvažujme jednoduchý scénář určování toho, co si obléct na základě povětrnostních podmínek. Máte pravidlo, které říká: „Když prší, vezmi si deštník“ a další pravidlo říká „Pokud je zima, vezmi si bundu.“ Nyní, když si všimnete, že skutečně prší, můžete pomocí řetězení dopředu odvodit, že byste si měli přinést deštník.
48. Zpětné řetězení
Zpětné řetězení je metoda uvažování, která začíná požadovaným závěrem nebo cílem a pracuje zpětně, aby určila nezbytná data nebo fakta potřebná k podpoře tohoto závěru. Je to jako sledovat své kroky od požadovaného výsledku k počátečním informacím potřebným k jeho dosažení.
Abychom porozuměli zpětnému řetězení, uvažujme jednoduchý příklad. Předpokládejme, že chcete zjistit, zda je vhodné jít si zaplavat. Požadovaným závěrem je, zda je plavání za určitých podmínek vhodné či nikoli.
Namísto toho, aby se začalo s podmínkami, zpětné řetězení začíná závěrem a pracuje zpětně, aby nalezlo podpůrná data.
V tomto případě by zpětné řetězení zahrnovalo kladení otázek jako "Je teplé počasí?" Pokud je odpověď ano, zeptali byste se: "Je k dispozici bazén?" Pokud je odpověď opět ano, položili byste další otázky, například: „Je dost času jít plavat?“
Opakovaným zodpovězením těchto otázek a postupováním zpětně můžete určit nezbytné podmínky, které je třeba splnit, abyste si mohli zaplavat.
49. Heuristika
Heuristika, zjednodušeně řečeno, je praktické pravidlo nebo strategie, která nám pomáhá při rozhodování nebo řešení problémů, obvykle na základě našich minulých zkušeností nebo intuice. Je to jako mentální zkratka, která nám umožňuje rychle přijít na rozumné řešení, aniž bychom procházeli zdlouhavým nebo vyčerpávajícím procesem.
Když čelíte složitým situacím nebo úkolům, heuristika slouží jako vůdčí principy nebo „obecná pravidla“, která zjednodušují rozhodování. Poskytují nám obecné pokyny nebo strategie, které jsou v určitých situacích často účinné, i když nemusí zaručit optimální řešení.
Vezměme si například heuristiku pro nalezení parkovacího místa v přeplněné oblasti. Namísto pečlivé analýzy každého dostupného místa se můžete spolehnout na heuristiku hledání zaparkovaných aut s běžícími motory.
Tato heuristika předpokládá, že se tato auta chystají odjet, čímž se zvyšuje šance na nalezení volného místa.
50. Modelování přirozeného jazyka
Modelování přirozeného jazyka, zjednodušeně řečeno, je proces trénování počítačových modelů, aby rozuměly a generovaly lidský jazyk způsobem, který je podobný tomu, jak lidé komunikují. Zahrnuje výuku počítačů zpracovávat, interpretovat a generovat text přirozeným a smysluplným způsobem.
Cílem modelování přirozeného jazyka je umožnit počítačům porozumět a generovat lidský jazyk způsobem, který je plynulý, koherentní a kontextově relevantní.
Zahrnuje trénování modelů na obrovském množství textových dat, jako jsou knihy, články nebo konverzace, abyste se naučili vzorce, struktury a sémantiku jazyka.
Po proškolení mohou tyto modely provádět různé úkoly související s jazykem, jako je jazykový překlad, sumarizace textu, odpovídání na otázky, interakce s chatbotem a další.
Dokážou porozumět významu a kontextu vět, získat relevantní informace a vytvořit text, který je gramaticky správný a souvislý.





Napsat komentář