INHOUDSOPGAWE[Versteek][Wys]
Ons kan nou die omvang van die ruimte en die klein verwikkeldheid van subatomiese deeltjies bereken danksy rekenaars.
Rekenaars klop mense wanneer dit kom by tel en berekening, asook om logiese ja/nee-prosesse te volg, danksy elektrone wat teen die spoed van lig deur sy stroombane beweeg.
Ons sien hulle egter nie dikwels as "intelligent" nie, aangesien rekenaars in die verlede niks kon verrig sonder om deur mense geleer (geprogrammeer) te word nie.
Masjienleer, insluitend diep leer en kunsmatige intelligensie, het 'n modewoord in wetenskaplike en tegnologie-opskrifte geword.
Masjienleer blyk alomteenwoordig te wees, maar baie mense wat die woord gebruik, sal sukkel om voldoende te definieer wat dit is, wat dit doen en waarvoor dit die beste gebruik word.
Hierdie artikel poog om masjienleer te verduidelik, terwyl dit ook konkrete, werklike voorbeelde verskaf van hoe die tegnologie werk om te illustreer waarom dit so voordelig is.
Dan sal ons na die verskillende masjienleer-metodologieë kyk en kyk hoe dit gebruik word om besigheidsuitdagings aan te spreek.
Ten slotte sal ons ons kristalbal raadpleeg vir 'n paar vinnige voorspellings oor die toekoms van masjienleer.
Wat is masjienleer?
Masjienleer is 'n dissipline van rekenaarwetenskap wat rekenaars in staat stel om patrone uit data af te lei sonder om uitdruklik geleer te word wat daardie patrone is.
Hierdie gevolgtrekkings is dikwels gebaseer op die gebruik van algoritmes om die statistiese kenmerke van die data outomaties te assesseer en die ontwikkeling van wiskundige modelle om die verwantskap tussen verskeie waardes uit te beeld.
Kontrasteer dit met klassieke rekenaars, wat op deterministiese stelsels gebaseer is, waarin ons die rekenaar uitdruklik 'n stel reëls gee om te volg sodat dit 'n sekere taak kan doen.
Hierdie manier van programmeer rekenaars staan bekend as reël-gebaseerde programmering. Masjienleer verskil van en presteer beter as reëlgebaseerde programmering deurdat dit hierdie reëls op sy eie kan aflei.
Gestel jy is 'n bankbestuurder wat wil vasstel of 'n leningsaansoek op hul lening gaan misluk.
In 'n reëlgebaseerde metode sal die bankbestuurder (of ander spesialiste) die rekenaar uitdruklik inlig dat indien die aansoeker se krediettelling onder 'n sekere vlak is, die aansoek afgekeur moet word.
'n Masjienleerprogram sal egter bloot vorige data oor kliëntkredietgraderings en leningsresultate ontleed en op sy eie bepaal wat hierdie drempel moet wees.
Die masjien leer uit vorige data en skep op hierdie manier sy eie reëls. Natuurlik, dit is slegs 'n begin oor masjienleer; werklike masjienleermodelle is aansienlik meer ingewikkeld as 'n basiese drempel.
Nietemin, dit is 'n uitstekende demonstrasie van die potensiaal van masjienleer.
Hoe kan 'n masjien leer?
Om dinge eenvoudig te hou, "leer" masjiene deur patrone in vergelykbare data op te spoor. Beskou data as inligting wat jy van die buitewêreld versamel. Hoe meer data 'n masjien gevoer word, hoe "slimmer" word dit.
Nie alle data is egter dieselfde nie. Gestel jy is 'n seerower met 'n lewensdoel om die begrawe rykdom op die eiland te ontbloot. Jy sal 'n aansienlike hoeveelheid kennis wil hê om die prys op te spoor.
Hierdie kennis, soos data, kan jou óf op die regte óf verkeerde manier neem.
Hoe groter die inligting/data wat verkry word, hoe minder onduidelikheid is daar, en omgekeerd. Gevolglik is dit van kritieke belang om te oorweeg watter soort data jy jou masjien voer om van te leer.
Sodra 'n aansienlike hoeveelheid data egter verskaf is, kan die rekenaar voorspellings maak. Masjiene kan die toekoms verwag solank dit nie veel van die verlede afwyk nie.
Masjiene "leer" deur historiese data te ontleed om te bepaal wat waarskynlik sal gebeur.
As die ou data soos die nuwe data lyk, sal die dinge wat jy oor die vorige data kan sê waarskynlik van toepassing wees op die nuwe data. Dit is asof jy terugkyk om vorentoe te sien.
Wat is die tipes masjienleer?
Algoritmes vir masjienleer word gereeld in drie breë tipes geklassifiseer (alhoewel ander klassifikasieskemas ook gebruik word):
- Begeleide leer
- Onbewaakte leer
- Versterking leer
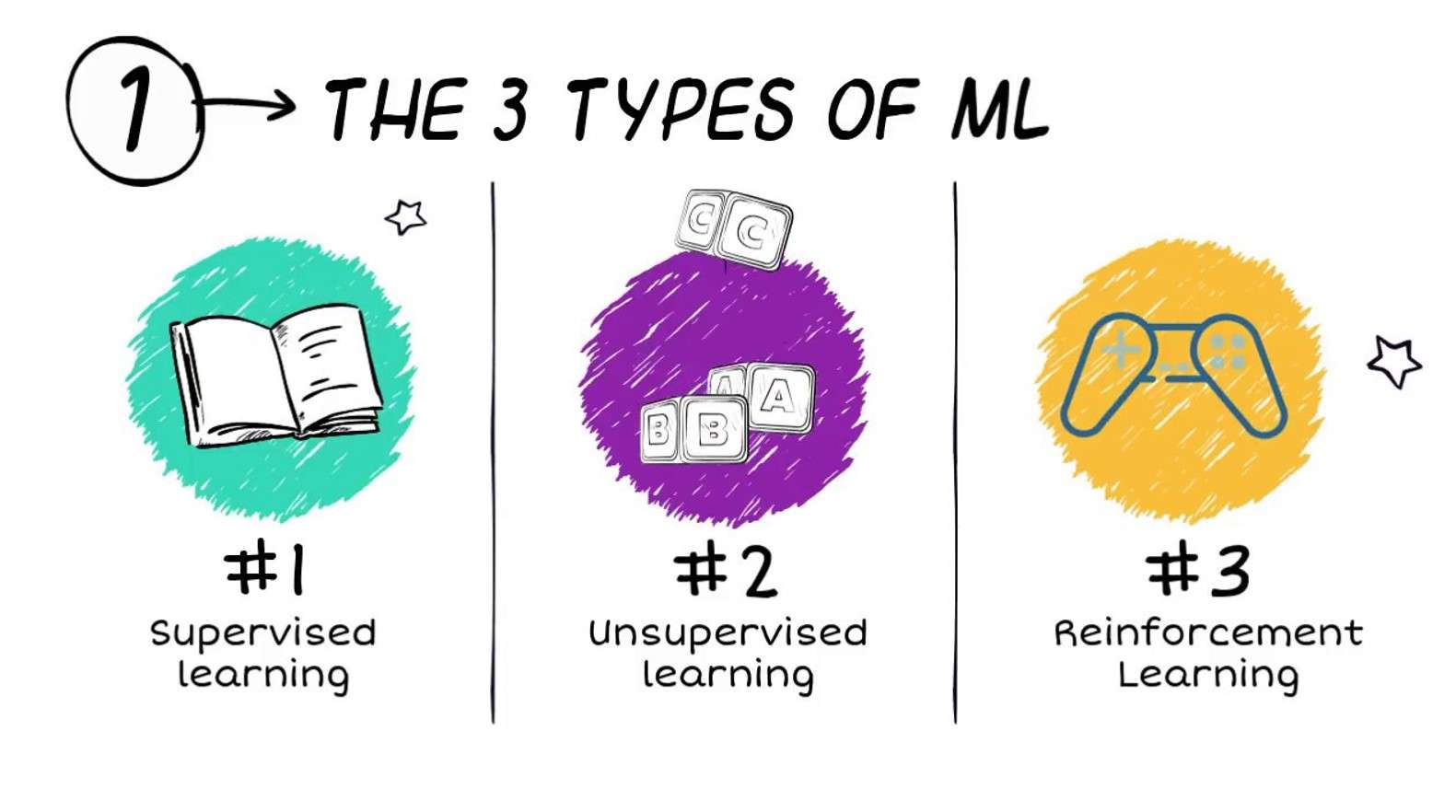
Begeleide leer
Onder toesig masjienleer verwys na tegnieke waarin die masjienleermodel 'n versameling data met eksplisiete etikette vir die hoeveelheid belangstelling gegee word (hierdie hoeveelheid word dikwels na verwys as die reaksie of teiken).
Om KI-modelle op te lei, gebruik semi-toesig leer 'n mengsel van benoemde en ongeëtiketteerde data.
As jy met ongemerkte data werk, sal jy data-etikettering moet onderneem.
Etikettering is die proses van etikettering van monsters om te help opleiding van 'n masjienleer model. Etikettering word hoofsaaklik deur mense gedoen, wat duur en tydrowend kan wees. Daar is egter tegnieke om die etiketteringproses te outomatiseer.
Die leningaansoeksituasie wat ons voorheen bespreek het, is 'n uitstekende illustrasie van leer onder toesig. Ons het historiese data gehad oor voormalige leningaansoekers se kredietgraderings (en dalk inkomstevlakke, ouderdom, ensovoorts) sowel as spesifieke etikette wat ons vertel het of die betrokke persoon hul lening versuim het of nie.
Regressie en klassifikasie is twee substelle van leertegnieke onder toesig.
- Klassifikasie – Dit maak gebruik van 'n algoritme om data korrek te kategoriseer. Strooiposfilters is een voorbeeld. "Strooipos" kan 'n subjektiewe kategorie wees - die lyn tussen gemorspos en nie-strooipos kommunikasie is vaag - en die spam filter algoritme verfyn homself voortdurend na gelang van jou terugvoer (wat beteken e-pos wat mense as strooipos merk).
- Regressie – Dit is nuttig om die verband tussen afhanklike en onafhanklike veranderlikes te verstaan. Regressiemodelle kan numeriese waardes voorspel gebaseer op verskeie databronne, soos verkoopsinkomsteskattings vir 'n sekere maatskappy. Lineêre regressie, logistiese regressie en polinoomregressie is 'n paar prominente regressietegnieke.
Onbewaakte leer
In leer sonder toesig kry ons ongemerkte data en soek ons net na patrone. Kom ons maak asof jy Amazon is. Kan ons enige groepe (groepe soortgelyke verbruikers) vind op grond van kliënte se aankoopgeskiedenis?
Selfs al het ons nie eksplisiete, afdoende data oor 'n persoon se voorkeure nie, kan ons in hierdie geval, bloot die wete dat 'n spesifieke stel verbruikers vergelykbare goedere koop, koopvoorstelle maak gebaseer op wat ander individue in die groepering ook gekoop het.
Amazon se "jy sal dalk ook belangstel in" karrousel word aangedryf deur soortgelyke tegnologie.
Leer sonder toesig kan data groepeer deur groepering of assosiasie, afhangende van wat jy saam wil groepeer.
- groepering – Leer sonder toesig poog om hierdie uitdaging te oorkom deur na patrone in die data te soek. As daar 'n soortgelyke groep of groep is, sal die algoritme hulle op 'n sekere manier kategoriseer. Om kliënte te probeer kategoriseer op grond van vorige aankoopgeskiedenis is 'n voorbeeld hiervan.
- Vereniging – Leer sonder toesig poog om hierdie uitdaging aan te pak deur die reëls en betekenisse onderliggend aan verskeie groepe te probeer begryp. 'n Gereelde voorbeeld van 'n assosiasieprobleem is om 'n verband tussen klantaankope te bepaal. Winkels kan belangstel om te weet watter goedere saam gekoop is en kan hierdie inligting gebruik om die posisionering van hierdie produkte te reël vir maklike toegang.
Versterking Leer
Versterkingsleer is 'n tegniek vir die onderrig van masjienleermodelle om 'n reeks doelgerigte besluite in 'n interaktiewe omgewing te neem. Die spelgebruiksgevalle hierbo genoem is uitstekende illustrasies hiervan.
Jy hoef nie AlphaZero duisende vorige skaakspeletjies in te voer nie, elk met 'n "goeie" of "swak" skuif gemerk. Leer dit eenvoudig die spelreëls en die doelwit, en laat dit dan toevallige handelinge uitprobeer.
Positiewe versterking word gegee aan aktiwiteite wat die program nader aan die doelwit neem (soos die ontwikkeling van 'n soliede pionposisie). Wanneer dade die teenoorgestelde effek het (soos om die koning voortydig te verskuif), verdien dit negatiewe versterking.
Die sagteware kan uiteindelik die speletjie bemeester deur hierdie metode te gebruik.
Versterking leer word wyd in robotika gebruik om robotte te leer vir ingewikkelde en moeilik om te ontwerp aksies. Dit word soms saam met padinfrastruktuur, soos verkeersseine, gebruik om verkeersvloei te verbeter.
Wat kan met masjienleer gedoen word?
Die gebruik van masjienleer in die samelewing en industrie lei tot vooruitgang in 'n wye reeks menslike pogings.
In ons daaglikse lewe beheer masjienleer nou Google se soek- en beeldalgoritmes, wat ons in staat stel om meer akkuraat te pas by die inligting wat ons nodig het wanneer ons dit nodig het.
In medisyne word masjienleer byvoorbeeld op genetiese data toegepas om dokters te help verstaan en voorspel hoe kanker versprei, wat dit moontlik maak om meer effektiewe terapieë te ontwikkel.
Data uit die diep ruimte word hier op aarde ingesamel via massiewe radioteleskope – en nadat dit met masjienleer ontleed is, help dit ons om die geheimenisse van swart gate te ontrafel.
Masjienleer in kleinhandel verbind kopers met goed wat hulle aanlyn wil koop, en help ook winkelwerknemers om die diens wat hulle aan hul kliënte in die baksteen-en-mortier-wêreld lewer, aan te pas.
Masjienleer word aangewend in die stryd teen terreur en ekstremisme om die gedrag van diegene wat die onskuldiges wil seermaak, te voorspel.
Natuurlike taalverwerking (NLP) verwys na die proses om rekenaars toe te laat om ons in menslike taal te verstaan en met ons te kommunikeer deur masjienleer, en dit het gelei tot deurbrake in vertaaltegnologie sowel as die stembeheerde toestelle wat ons toenemend elke dag gebruik, soos bv. Alexa, Google dot, Siri en Google-assistent.
Sonder 'n vraag demonstreer masjienleer dat dit 'n transformasietegnologie is.
Robotte wat in staat is om saam met ons te werk en ons eie oorspronklikheid en verbeelding 'n hupstoot te gee met hul foutlose logika en bomenslike spoed, is nie meer 'n wetenskapfiksie-fantasie nie - hulle word 'n werklikheid in baie sektore.
Masjienleer-gebruiksgevalle
1. Kuberveiligheid
Namate netwerke meer ingewikkeld geraak het, het kuberveiligheidspesialiste onvermoeid gewerk om by die steeds groter wordende reeks sekuriteitsbedreigings aan te pas.
Om vinnig ontwikkelende wanware en inbraaktaktieke teë te werk is uitdagend genoeg, maar die verspreiding van Internet of Things (IoT) toestelle het die kuberveiligheidsomgewing fundamenteel verander.
Aanvalle kan enige oomblik en op enige plek plaasvind.
Gelukkig het masjienleeralgoritmes kuberveiligheidsbedrywighede in staat gestel om tred te hou met hierdie vinnige ontwikkelings.
Voorspellende ontleding maak vinniger opsporing en versagting van aanvalle moontlik, terwyl masjienleer jou aktiwiteit binne 'n netwerk kan ontleed om abnormaliteite en swakhede in bestaande sekuriteitsmeganismes op te spoor.
2. Outomatisering van kliëntediens
Die bestuur van 'n toenemende aantal aanlyn kliëntkontakte het baie organisasie gespanne.
Hulle het eenvoudig nie genoeg kliëntedienspersoneel om die hoeveelheid navrae wat hulle ontvang te hanteer nie, en die tradisionele benadering van uitkontraktering van kwessies aan 'n kontak sentrum is net onaanvaarbaar vir baie van vandag se kliënte.
Chatbots en ander outomatiese stelsels kan nou hierdie eise aanspreek danksy vooruitgang in masjienleertegnieke. Maatskappye kan personeel bevry om meer hoëvlak kliëntediens te onderneem deur alledaagse en lae-prioriteit aktiwiteite te outomatiseer.
As dit korrek gebruik word, kan masjienleer in besigheid help om probleemoplossing te stroomlyn en verbruikers die tipe nuttige ondersteuning te bied wat hulle omskep om toegewyde handelsmerkkampioene te word.
3. kommunikasie
Om foute en wanopvattings te vermy is van kritieke belang in enige tipe kommunikasie, maar meer so in vandag se besigheidskommunikasie.
Eenvoudige grammatikale foute, verkeerde toon of foutiewe vertalings kan 'n reeks probleme veroorsaak in e-poskontak, kliënte-evaluasies, videokonferensies, of teksgebaseerde dokumentasie in baie vorme.
Masjienleerstelsels het gevorderde kommunikasie ver verby Microsoft se Clippy se bedrywige dae.
Hierdie masjienleervoorbeelde het individue gehelp om eenvoudig en presies te kommunikeer deur natuurlike taalverwerking, intydse taalvertaling en spraakherkenning te gebruik.
Alhoewel baie individue nie van outokorreksievermoëns hou nie, waardeer hulle dit ook om beskerm teen verleentheidsfoute en onbehoorlike stemtoon.
4. Voorwerpherkenning
Terwyl die tegnologie om data in te samel en te interpreteer al 'n rukkie bestaan, het dit bewys dat dit 'n bedrieglik moeilike taak is om rekenaarstelsels te leer verstaan waarna hulle kyk.
Objekherkenningsvermoëns word by 'n toenemende aantal toestelle gevoeg as gevolg van masjienleertoepassings.
'n Selfbesturende motor herken byvoorbeeld 'n ander motor wanneer dit een sien, selfs al het programmeerders dit nie 'n presiese voorbeeld van daardie motor gegee om as verwysing te gebruik nie.
Hierdie tegnologie word nou in kleinhandelondernemings gebruik om die betaalproses te help bespoedig. Kameras identifiseer die produkte in verbruikers se waentjies en kan outomaties hul rekeninge faktureer wanneer hulle die winkel verlaat.
5. Digitale bemarking
Baie van vandag se bemarking word aanlyn gedoen, met behulp van 'n reeks digitale platforms en sagtewareprogramme.
Soos besighede inligting oor hul verbruikers en hul aankoopgedrag insamel, kan bemarkingspanne daardie inligting gebruik om 'n gedetailleerde prentjie van hul teikengehoor te bou en te ontdek watter mense meer geneig is om hul produkte en dienste te soek.
Masjienleeralgoritmes help bemarkers om sin te maak van al daardie data, deur beduidende patrone en eienskappe te ontdek wat hulle in staat stel om moontlikhede noukeurig te kategoriseer.
Dieselfde tegnologie laat groot digitale bemarkingsoutomatisering toe. Advertensiestelsels kan opgestel word om nuwe voornemende verbruikers dinamies te ontdek en relevante bemarkingsinhoud op die regte tyd en plek aan hulle te verskaf.
Toekoms van Masjienleer
Masjienleer is beslis besig om gewild te word namate meer besighede en groot organisasies die tegnologie gebruik om spesifieke uitdagings aan te pak of innovasie aan te wakker.
Hierdie volgehoue belegging demonstreer 'n begrip dat masjienleer ROI lewer, veral deur sommige van die bogenoemde gevestigde en reproduceerbare gebruiksgevalle.
Na alles, as die tegnologie goed genoeg is vir Netflix, Facebook, Amazon, Google Maps, ensovoorts, is die kans groot dat dit jou maatskappy ook kan help om die meeste van sy data te maak.
As nuut machine learning modelle ontwikkel en bekendgestel word, sal ons 'n toename sien in die aantal toepassings wat oor nywerhede gebruik sal word.
Dit gebeur reeds met gesigsherkenning, wat eens 'n nuwe funksie op jou iPhone was, maar nou in 'n wye reeks programme en toepassings geïmplementeer word, veral dié wat met openbare veiligheid verband hou.
Die sleutel vir die meeste organisasies wat probeer om met masjienleer te begin, is om verby die blink futuristiese visies te kyk en die werklike besigheidsuitdagings te ontdek waarmee die tegnologie jou kan help.
Gevolgtrekking
In die post-geïndustrialiseerde era het wetenskaplikes en professionele mense probeer om 'n rekenaar te skep wat meer soos mense optree.
Die denkmasjien is KI se belangrikste bydrae tot die mensdom; die fenomenale koms van hierdie selfaangedrewe masjien het korporatiewe bedryfsregulasies vinnig verander.
Selfbesturende voertuie, outomatiese assistente, outonome vervaardigingswerknemers en slim stede het die afgelope tyd die lewensvatbaarheid van slim masjiene getoon. Die masjienleerrevolusie, en die toekoms van masjienleer, sal nog lank met ons wees.





Lewer Kommentaar