目錄[隱藏][顯示]
視頻遊戲繼續為全球數十億玩家帶來挑戰。 你可能還不知道,但機器學習算法也已經開始迎接挑戰。
目前在人工智能領域進行了大量研究,以了解機器學習方法是否可以應用於視頻遊戲。 該領域的重大進展表明 機器學習 代理可以用來模擬甚至替代人類玩家。
這對未來意味著什麼 視頻遊戲?
這些項目僅僅是為了好玩,還是有這麼多研究人員專注於遊戲的更深層次的原因?
本文將簡要探討人工智能在視頻遊戲中的歷史。 之後,我們將向您簡要介紹一些機器學習技術,我們可以使用這些技術來學習如何擊敗遊戲。 然後我們將看看一些成功的應用 神經網絡 學習和掌握特定的視頻遊戲。
遊戲中的人工智能簡史
在我們了解為什麼神經網絡已成為解決視頻遊戲的理想算法之前,讓我們簡要了解一下計算機科學家如何使用視頻遊戲來推進他們在人工智能方面的研究。
你可以說,從一開始,視頻遊戲就一直是對人工智能感興趣的研究人員的熱門研究領域。
國際象棋雖然不是嚴格意義上的視頻遊戲,但在 AI 的早期階段一直是一大焦點。 1951 年,Dietrich Prinz 博士使用 Ferranti Mark 1 數字計算機編寫了一個下棋程序。 這可以追溯到這些笨重的計算機必須從紙帶上讀取程序的時代。

該程序本身並不是一個完整的國際象棋人工智能。 由於計算機的限制,普林茨只能創建一個程序來解決二分之一的國際象棋問題。 平均而言,該程序需要 15-20 分鐘來計算白人和黑人玩家的每一個可能的移動。
幾十年來,改進國際象棋和跳棋人工智能的工作穩步改進。 這一進展在 1997 年達到了高潮,當時 IBM 的深藍在一對六場比賽中擊敗了俄羅斯國際象棋大師加里卡斯帕羅夫。 如今,您可以在手機上找到的國際象棋引擎可以擊敗深藍。
在電子街機遊戲的黃金時代,人工智能對手開始流行起來。 1978 年代的 Space Invaders 和 1980 年代的 Pac-Man 是行業中的一些先驅者,他們創造了足以挑戰最老牌街機遊戲玩家的 AI。
尤其是吃豆人,它是人工智能研究人員用來試驗的流行遊戲。 各種各樣的 比賽 吃豆人女士已經組織起來,以確定哪個團隊可以想出最好的人工智能來擊敗遊戲。
隨著對更聰明的對手的需求出現,遊戲 AI 和啟發式算法不斷發展。 例如,隨著第一人稱射擊遊戲等類型變得更加主流,戰鬥 AI 越來越受歡迎。
視頻遊戲中的機器學習
隨著機器學習技術迅速普及,各種研究項目試圖使用這些新技術來玩電子遊戲。
Dota 2、StarCraft 和 Doom 等遊戲可能會成為這些遊戲的問題 機器學習算法 解決。 深度學習算法,特別是能夠達到甚至超過人類水平的表現。
街機學習環境 或者 ALE 為研究人員提供了一個用於一百多個 Atari 2600 遊戲的界面。 這個開源平台允許研究人員對經典 Atari 視頻遊戲中機器學習技術的性能進行基準測試。 谷歌甚至發布了自己的 紙 使用 ALE 的七場比賽

同時,項目如 維茲杜姆 讓 AI 研究人員有機會訓練機器學習算法來玩 3D 第一人稱射擊遊戲。

它是如何工作的:一些關鍵概念
神經網絡
大多數使用機器學習解決視頻遊戲的方法都涉及一種稱為神經網絡的算法。
你可以把神經網絡想像成一個試圖模仿大腦功能的程序。 類似於我們的大腦是由傳遞信號的神經元組成的,神經網絡也包含人工神經元。
這些人工神經元也相互傳遞信號,每個信號都是一個實際數字。 神經網絡在輸入層和輸出層之間包含多個層,稱為深度神經網絡。
強化學習
另一種與學習視頻遊戲相關的常見機器學習技術是強化學習的概念。
這種技術是使用獎勵或懲罰來訓練代理的過程。 使用這種方法,代理應該能夠通過反複試驗提出問題的解決方案。
假設我們想要一個 AI 來了解如何玩 Snake 遊戲。 遊戲的目標很簡單:通過消耗物品並避免不斷增長的尾巴來獲得盡可能多的積分。
通過強化學習,我們可以定義一個獎勵函數 R。該函數在 Snake 消耗物品時加分,在 Snake 撞到障礙物時減分。 給定當前環境和一組可能的動作,我們的強化學習模型將嘗試計算最大化我們的獎勵函數的最佳“策略”。
神經進化
受自然啟發的主題保持不變,研究人員還通過一種稱為神經進化的技術將 ML 應用到視頻遊戲中取得了成功。
而不是使用 梯度下降 為了更新網絡中的神經元,我們可以使用進化算法來獲得更好的結果。
進化算法通常從生成隨機個體的初始種群開始。 然後,我們使用某些標準評估這些人。 最優秀的個體被選為“父母”,並一起培育形成新一代個體。 然後這些人將替換人口中最不適合的人。
這些算法通常還會在交叉或“繁殖”步驟期間引入某種形式的突變操作,以保持遺傳多樣性。
電子遊戲中機器學習的樣本研究
OpenAI五

OpenAI五 是 OpenAI 的一個計算機程序,旨在玩流行的多人移動競技場 (MOBA) 遊戲 DOTA 2。
該程序利用現有的強化學習技術,可從每秒數百萬幀中學習。 得益於分佈式訓練系統,OpenAI 能夠每天玩 180 年的遊戲。
訓練期結束後,OpenAI Five 能夠達到專家級的表現,並展示了與人類玩家的合作。 2019 年,OpenAI XNUMX 能夠 打敗 99.4%的球員在公開比賽中。
為什麼 OpenAI 決定做這個遊戲? 根據研究人員的說法,DOTA 2 擁有復雜的機制,超出了現有深度遊戲的範圍 強化學習 算法。
超級馬里奧兄弟
神經網絡在視頻遊戲中的另一個有趣應用是使用神經進化來玩超級馬里奧兄弟等平台遊戲。
例如這個 黑客馬拉松入口 從對遊戲一無所知開始,然後慢慢建立通關所需的基礎。
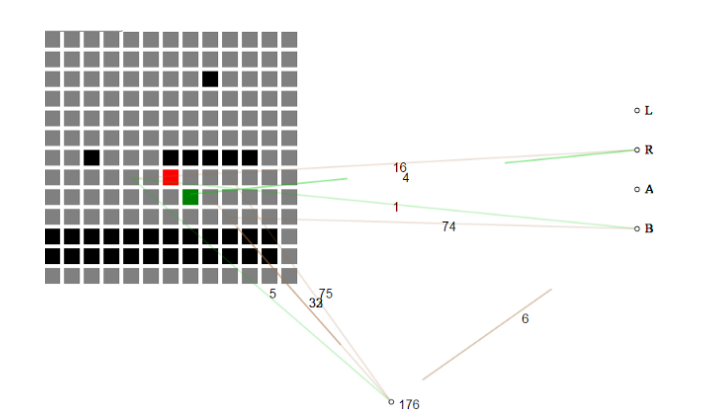
自我進化的神經網絡將游戲的當前狀態視為一個瓷磚網格。 起初,神經網絡並不了解每個瓦片的含義,只是“空氣”瓦片不同於“地瓦”和“敵人瓦片”。
黑客馬拉松項目對神經進化的實現使用 NEAT 遺傳算法選擇性地培育不同的神經網絡。
重要性
既然您已經看到了一些神經網絡玩電子遊戲的例子,您可能想知道這一切的意義何在。
由於視頻遊戲涉及代理與其環境之間的複雜交互,因此它是製作 AI 的完美試驗場。 虛擬環境是安全可控的,並提供無限的數據供應。
該領域的研究使研究人員深入了解如何優化神經網絡以學習如何解決現實世界中的問題。
神經網絡 靈感來自大腦在自然界中的工作方式。 通過研究人工神經元在學習如何玩電子遊戲時的行為,我們還可以深入了解 人類的大腦 作品。
結論
神經網絡和大腦之間的相似性導致了這兩個領域的見解。 對神經網絡如何解決問題的持續研究有朝一日可能會導致更高級的 人工智能.
想像一下,使用根據您的規格量身定制的 AI 可以在您購買之前玩整個視頻遊戲,讓您知道它是否值得您花時間。 視頻遊戲公司會使用神經網絡來改進遊戲設計、調整水平和對手難度嗎?
當神經網絡成為終極遊戲玩家時,你認為會發生什麼?





發表評論