目录[隐藏][展示]
- 1. 什么是 Python 脚本,它与 Python 编程有何不同?
- 2.Python的垃圾回收是如何工作的?
- 3.解释列表和元组的区别
- 4. 什么是列表推导式并给出其用法的示例?
- 5. 描述一下deepcopy和copy的区别?
- 6. Python 中的多线程是如何实现的,它与多处理有何不同?
- 7. 什么是装饰器以及它们在Python中如何使用?
- 8.解释一下*args和**kwargs之间的区别?
- 9. 如何确保使用装饰器只能调用一次函数?
- 10. Python 中继承是如何工作的?
- 11.什么是方法重载和重写?
- 12.举例描述多态性的概念。
- 13.解释实例、类和静态方法之间的区别。
- 14. 描述 Python 集的内部工作原理。
- 15. Python 中字典是如何实现的?
- 16. 解释使用命名元组的好处。
- 17. try- except 块如何工作?
- 18. raise 和assert 语句有什么区别?
- 19.如何在Python中从二进制文件中读取和写入数据?
- 20. 解释 with 语句及其在处理文件 I/O 时的优点。
- 21. 如何在 Python 中创建单例模块?
- 22. 列举几种优化 Python 脚本内存使用的方法。
- 23. 如何使用正则表达式从给定字符串中提取所有电子邮件地址?
- 24.讲解Factory设计模式及其在Python中的应用
- 25.迭代器和生成器有什么区别?
- 26. @property 装饰器如何工作?
- 27. 如何用 Python 创建基本的 REST API?
- 28. 描述如何使用requests库发出HTTP POST请求。
- 29. 如何使用 Python 连接到 PostgreSQL 数据库?
- 30. ORM 在 Python 中的作用是什么?请说出一种流行的 ORM?
- 31. 您将如何分析 Python 脚本?
- 32.解释CPython中的GIL(全局解释器锁)
- 33.解释Python的async/await。 它与传统的线程有何不同?
- 34. 描述如何使用Python的concurrent.futures。
- 35. 在用例和可扩展性方面比较 Django 和 Flask。
- 结论
在科技渗透到我们生活方方面面的时代, 蟒蛇 脚本作为庞大而复杂的 IT 基础设施的关键组件而出现,开创了易用性和实用性的典范。
Python 的优势不仅在于其语法简单性和可读性,还在于其适应性,这使其能够轻松弥合低风险、初学者级脚本与高风险企业级软件开发之间的差距。
Python 广泛的库和框架为流畅、富有想象力的技术冒险铺平了道路,无论是在数据分析、Web 开发、人工智能还是网络服务器领域。
除了作为解决问题的工具之外,Python 还营造了一种氛围,在这种氛围中,创新不仅受到欢迎,而且由于其庞大的库和框架(例如用于 Web 开发的 Django 或用于数据分析的 Pandas)而自然地融入其中。
在数据为王的世界中,Python 提供了强大的工具来操作、分析和 可视化数据,产生可行的见解并指导战略选择。
Python 不仅仅是一种编程语言;它也是一种编程语言。 它也是一个蓬勃发展的社区,是开发人员、数据科学家和技术爱好者聚集在一起发明、创造并将 IT 行业提升到新水平的中心。
Python 开发人员受到各种规模企业的追捧,从刚刚起步的初创公司到成熟的组织,他们都是创新、流程改进和改善客户服务的催化剂。
此外,它的开源性质培育了共享学习和协作成长的文化,保证了它能够随着快速变化的技术世界而继续发展。
在 2023 年学习 Python 是对一门语言的投资,这种语言有望保持最新、灵活,并且对于管理技术的潮起潮落至关重要。
它允许访问以下字段 机器学习、数据分析、网络安全等等,所有这些对于塑造数字时代都至关重要。
因此,我们为您整理了一份最佳 Python 脚本面试问题列表,这将使您作为开发人员脱颖而出并在面试中取得好成绩。
1. 什么是 Python 脚本,它与 Python 编程有何不同?
Python 以其适应性而闻名,并提供脚本和编程技能,每种技能都适合特定的工作和目标。
Python 脚本从根本上来说是编写更短、更高效的脚本的过程,这些脚本旨在管理文件、自动化重复流程或快速原型化想法。
这些脚本通常是独立的,可以有效地按顺序执行一系列操作。
另一方面,Python 编程更进一步,强调使用库、框架和最佳实践通过结构化代码创建更大、更复杂的程序。
虽然它们都来自相同的语言,但脚本简化并自动化,而编程则创造和发明。 这种差异可以从每个学科的范围和目标中看出。
2.Python的垃圾回收是如何工作的?
确保有效内存管理的一个关键要素是 Python 的垃圾收集系统。
它在后台不知疲倦地工作,以保护系统资源免遭内存泄漏的影响。 这种自动化方法主要基于引用计数方法,其中每个对象都会跟踪有多少其他对象正在引用它。
当该计数降至 0 时,该对象将成为内存回收的候选者,这表明不再需要该项目。
此外,Python 使用循环垃圾收集器(简单的引用计数方法可能会错过)来查找和清除引用循环。
因此,引用计数和循环垃圾收集双层策略提供了对内存的谨慎有效的使用,增强了Python的性能,特别是在内存密集型应用程序中。
下面提供了一个简单的代码示例,展示了如何与 Python 的垃圾收集系统交互:
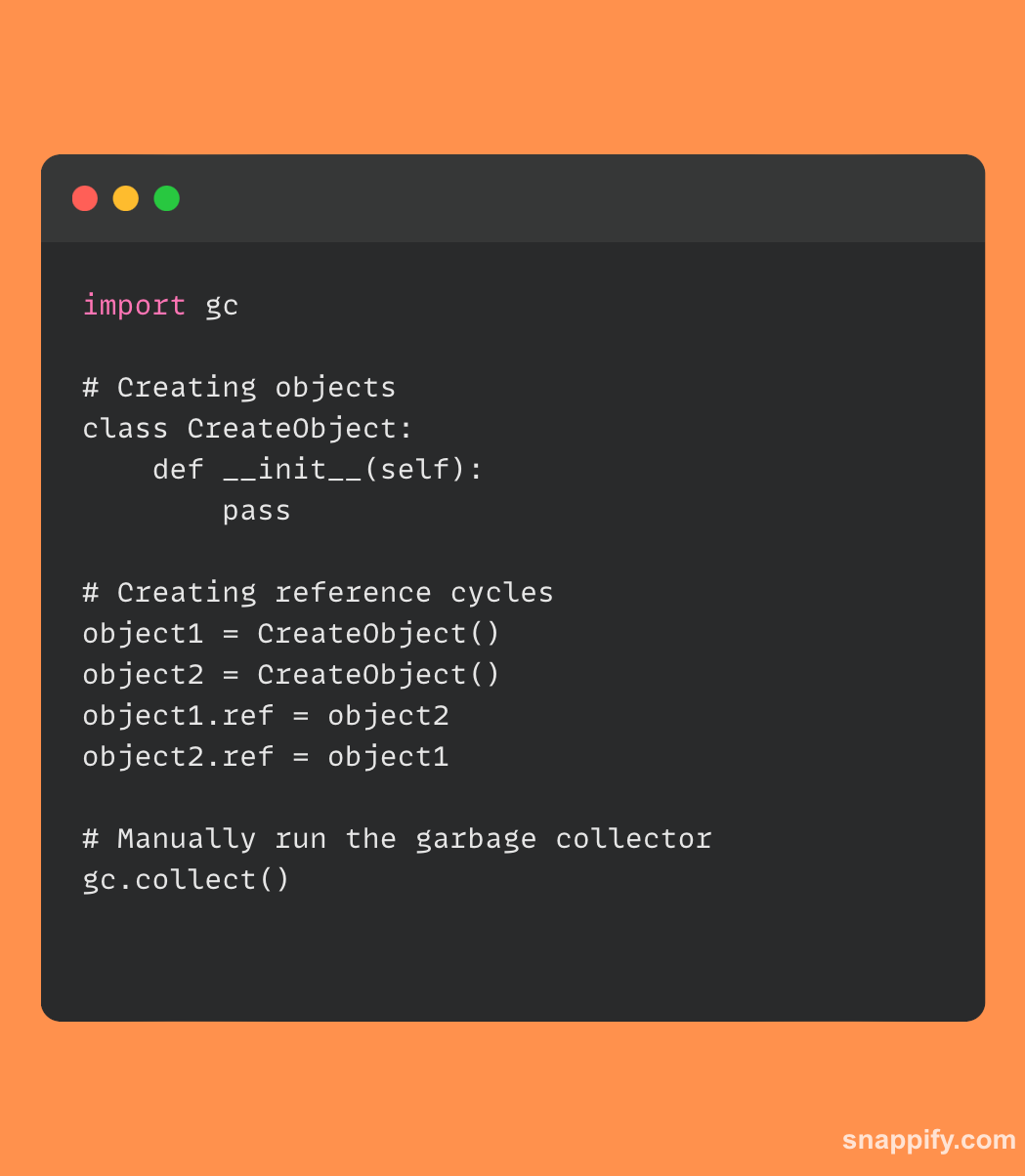
在此摘录中生成两个对象并交叉引用以建立循环。 然后使用 gc.collect() 手动触发垃圾收集器,展示程序员如何在必要时使用 Python 的内存管理机制。
3.解释列表和元组的区别
列表和元组是Python世界中数据的有效容器,但它们具有不同的属性来满足不同的编程目的。
用方括号表示的列表通过允许更改和动态调整其组件大小来实现灵活性。
另一方面,括号中的元组是不可变的,并且在执行函数时保持其初始状态。
元组提供了可靠的、不可变的序列,而列表提供了灵活性,允许在数据处理和修改中进行多种用途。
这里有一点 Python代码 显示如何使用列表和元组的示例:

4. 什么是列表推导式并给出其用法的示例?
列表推导式是一种在 Python 中创建列表的高效且富有表现力的方法,它将条件逻辑和循环的强大功能结合到一行易于理解的代码中。
它们提供了一种简化的语法,将我们的意图转换为列表,将迭代和条件性组合成一个单一的、精致的结构。
列表推导本质上使程序员能够通过对每个成员执行操作来创建列表,并可能根据某些标准过滤它们,同时保持整洁的代码库。
这种富有表现力的功能通过提高可读性,同时在某些情况下还可能提供计算增益,从而将 Python 编程的效率和清晰度结合在一起。
Python 列表理解的示例如下所示:
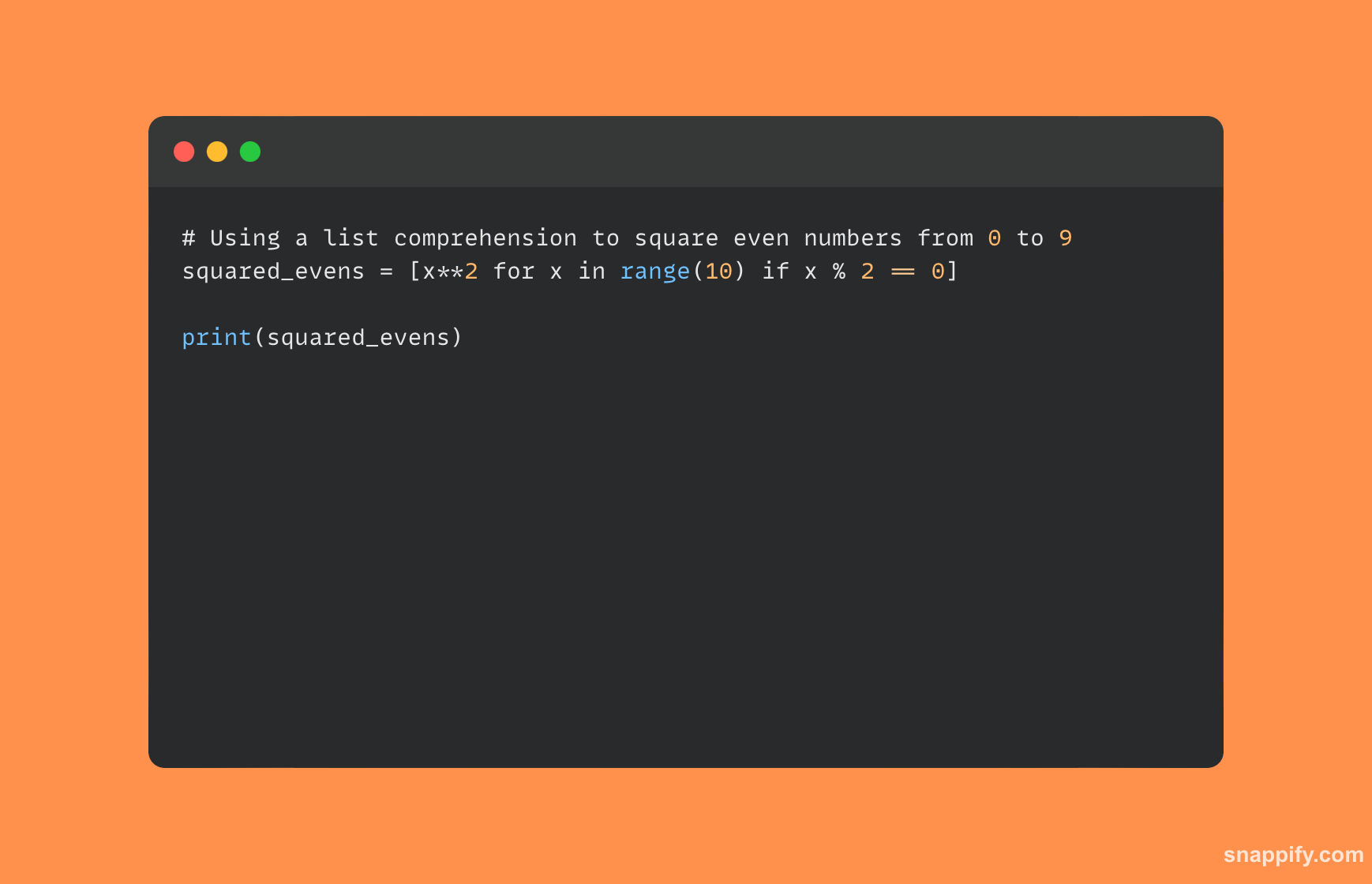
5. 描述一下deepcopy和copy的区别?
复制对象的深度和完整性决定了之间的差异 deepcopy 和 copy 在Python中。
通过创建一个新项目,同时保留对原始嵌套对象的引用, copy 创造了一个浅薄的复制品,将他们的命运编织在相互依赖的网络中。
Deepcopy 通过递归复制原始对象及其所有分层组件、切断所有连接并在更改中保持自主性,创建完全自主的克隆。
因此,根据所需的对象独立性级别, deepcopy 确保全面的复制,而复制仅提供表面水平的复制。
这是一些代码来展示如何 copy 和 deepcopy 各有不同:
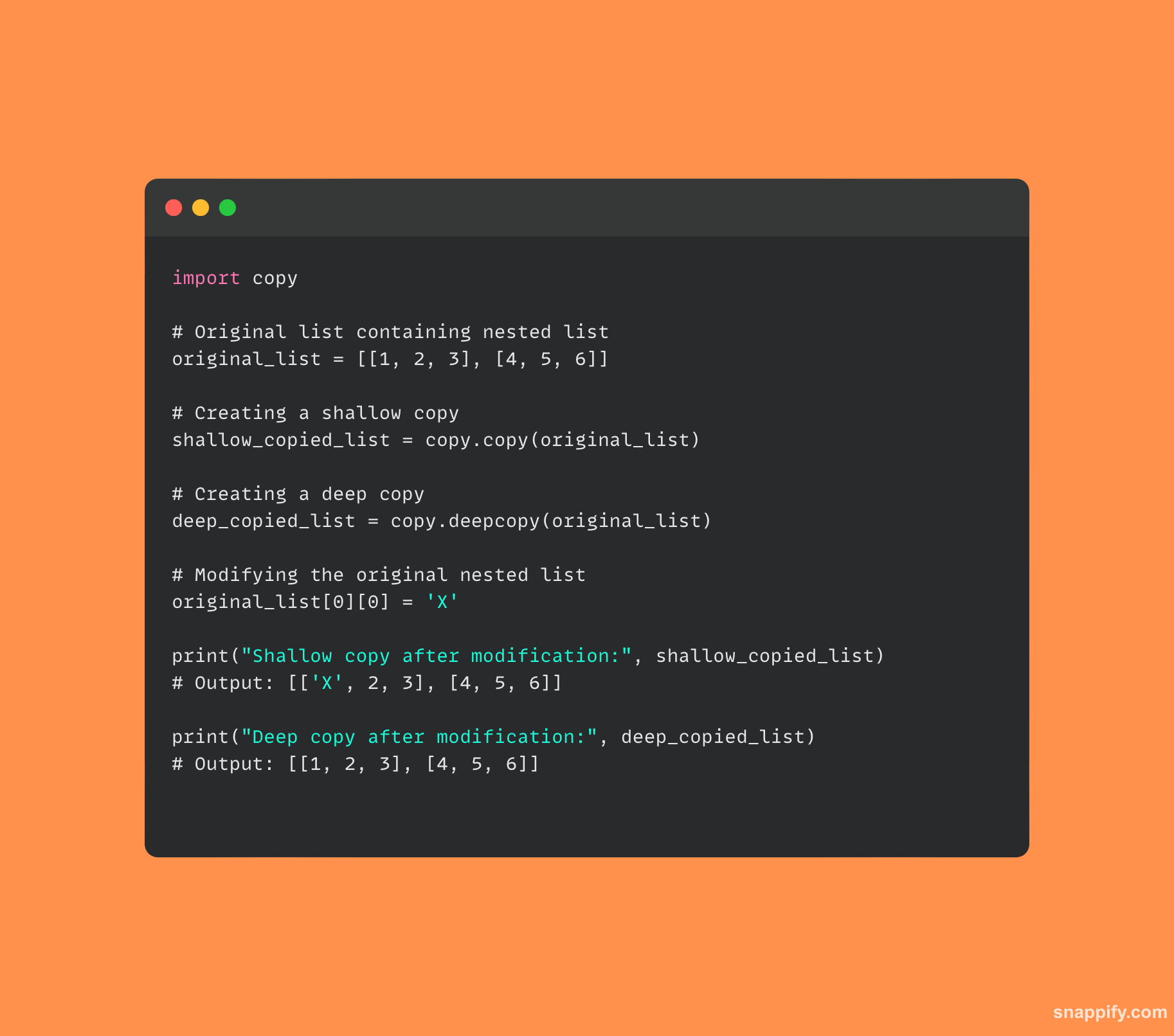
6. Python 中的多线程是如何实现的,它与多处理有何不同?
Python 的多处理和多线程都解决并发执行问题,但使用不同的范例。
通过在单个进程内使用多个线程,多线程可以在共享内存空间内实现并发任务执行。
然而,由于Python的全局解释器锁(GIL),真正的并行线程执行可能很难实现。
另一方面,多处理利用多个进程,每个进程都有一个单独的 Python 解释器和内存空间,确保真正的并行性。
对于 I/O 密集型活动,多线程更加轻量级和实用,但多处理在 CPU 密集型情况下表现出色,在这种情况下,真正的并行执行至关重要。
以下是对比多处理与多线程的简短代码示例:
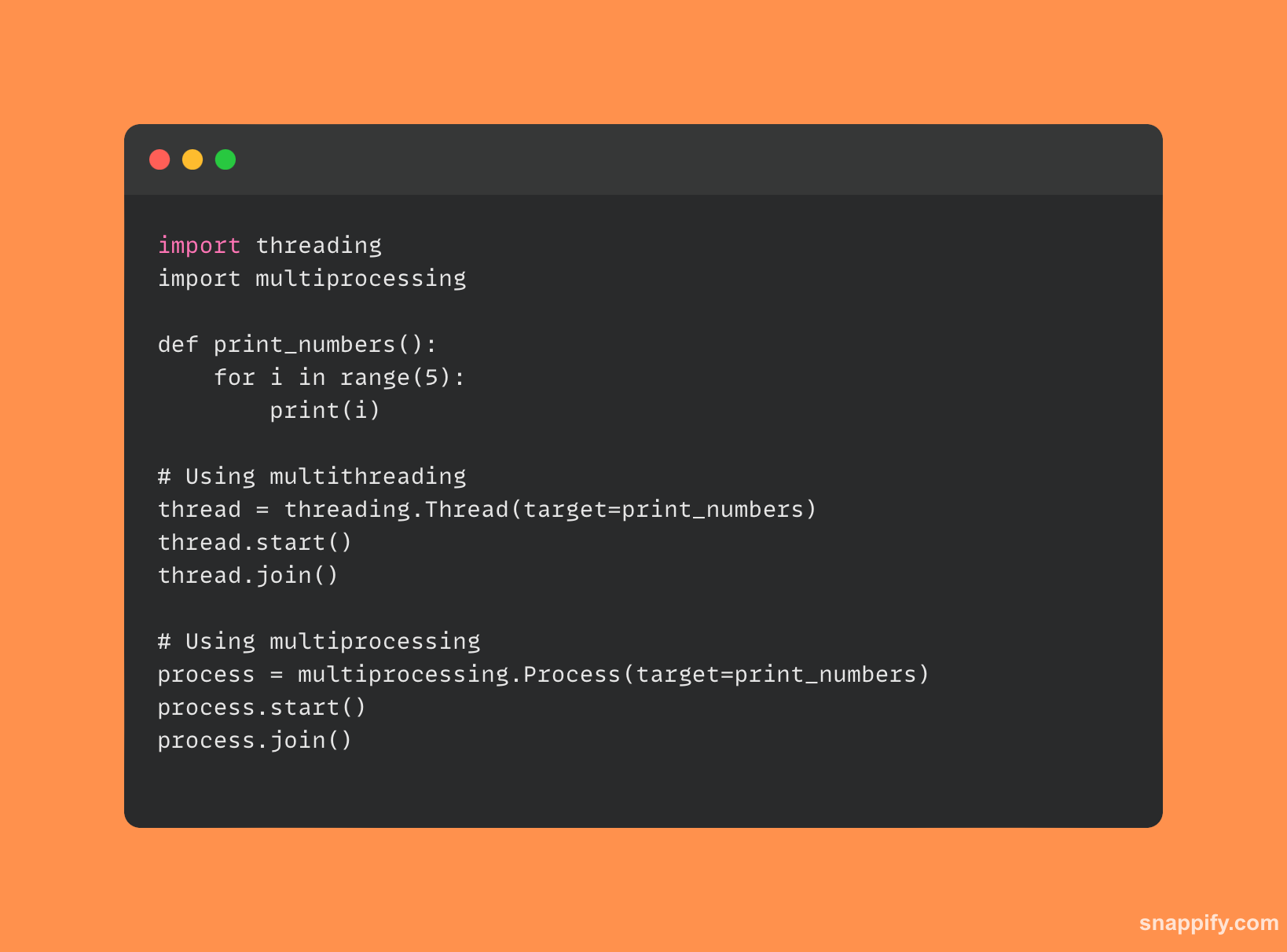
7. 什么是装饰器以及它们在Python中如何使用?
在 Python 中,装饰器优雅地结合了实用性和简单性,同时巧妙地增强或改变了功能。
将装饰器视为精美地包裹函数的面纱,在不改变其本质的情况下增加其功能。
这些实体用符号表示 @,接受一个函数作为输入并输出一个全新的函数,提供了修改函数行为的无缝方法。
装饰器赋予了广泛的功能,从日志记录到访问控制,用新的层增强代码,同时保持清晰、易于理解的语法。
下面是一个简单的 Python 代码示例,展示了如何使用装饰器:
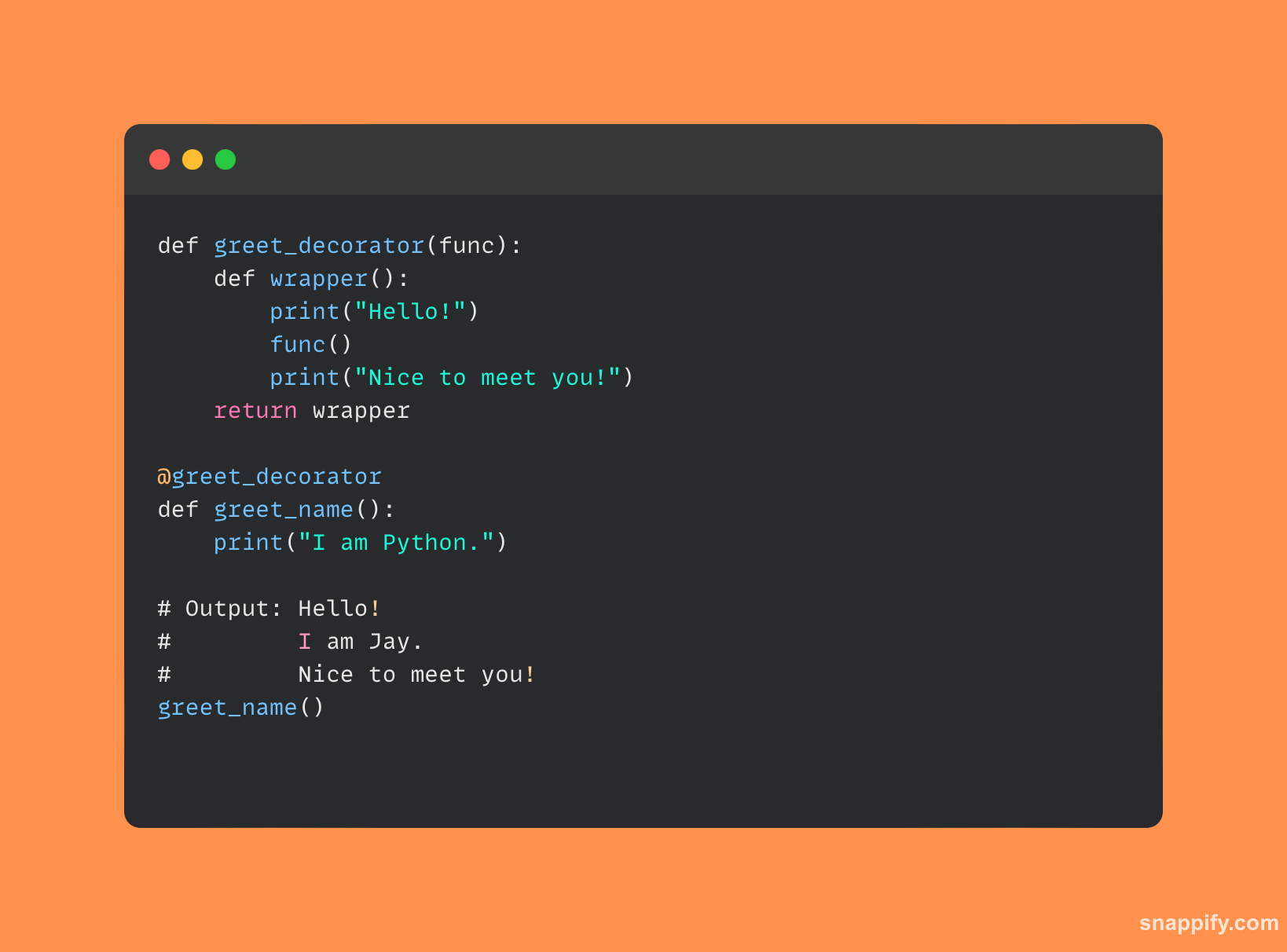
8.解释一下*args和**kwargs之间的区别?
Python灵活的参数 *args 和 **kwargs 允许函数正确地接受一系列参数。
函数可以接受任意数量的位置参数,使用 *args 参数,将它们分组到一个元组中。
相反,函数可以使用以下方式接受任意数量的关键字参数 **kwargs 参数,将它们分组到一个字典中。
两者都充当函数构造和调用的动态性和灵活性的渠道, **kwargs 提供一种结构化方法来处理任意数量的关键字输入,同时 *args 优雅地处理未定义的位置输入。
它们共同通过巧妙、清晰地处理各种应用场景,提高了 Python 函数的灵活性和耐用性。
使用的 Python 代码示例 *args 和 **kwargs 提供如下:
9. 如何确保使用装饰器只能调用一次函数?
Python 装饰器善于将实用性与优雅性结合起来,这是确保函数执行时的奇异性所必需的。
可以设计一个装饰器来封装一个函数并通过保持内部状态来跟踪内部的信息。
封装的函数被调用一次,然后执行,装饰器会记录该调用。 后续调用将被阻止,通过确保函数不受干扰来防止函数重复执行。
借助装饰器的这种应用程序,可以以微妙而有效的方式控制函数调用,以既美观又不引人注目的方式保证唯一性。
下面是一个代码示例,展示了如何使用装饰器来限制调用函数的次数:

10. Python 中继承是如何工作的?
Python 的继承系统在类之间创建了一个分层链接网络,允许父类的特征和功能与其子类共享。
它管理的沿袭允许派生(子)类从其基(父)类继承、替换或添加功能,从而促进代码重用和逻辑分层设计。
子类除了吸收父类的功能外,还可以引入其独特的功能和行为,创建强大的多层对象模型。
在这种方法中,继承巧妙地在整个类层次结构的动脉中分配功能,创建一个统一的、组织良好的面向对象的体系结构。
以下简化的 Python 代码演示了继承:

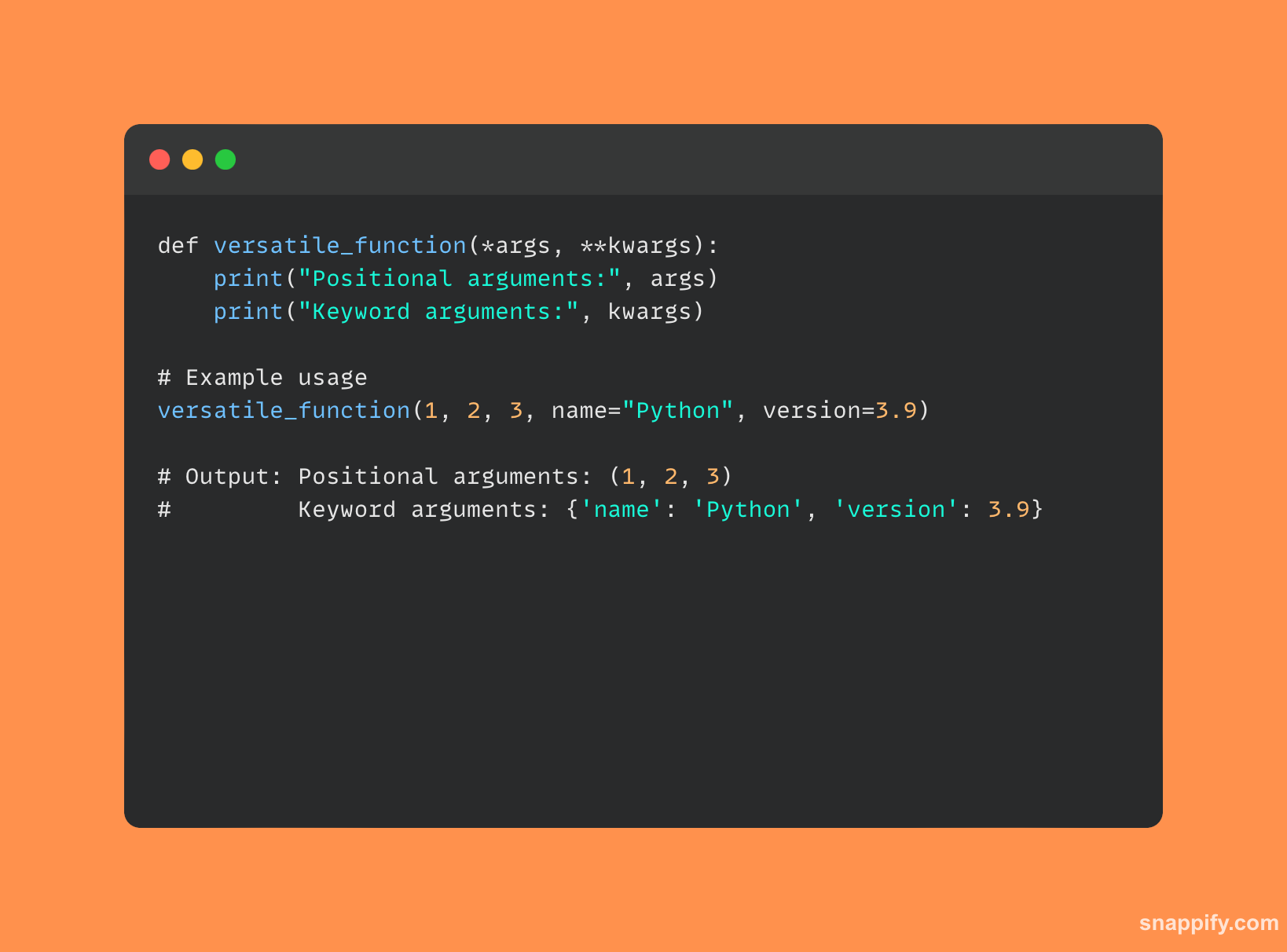
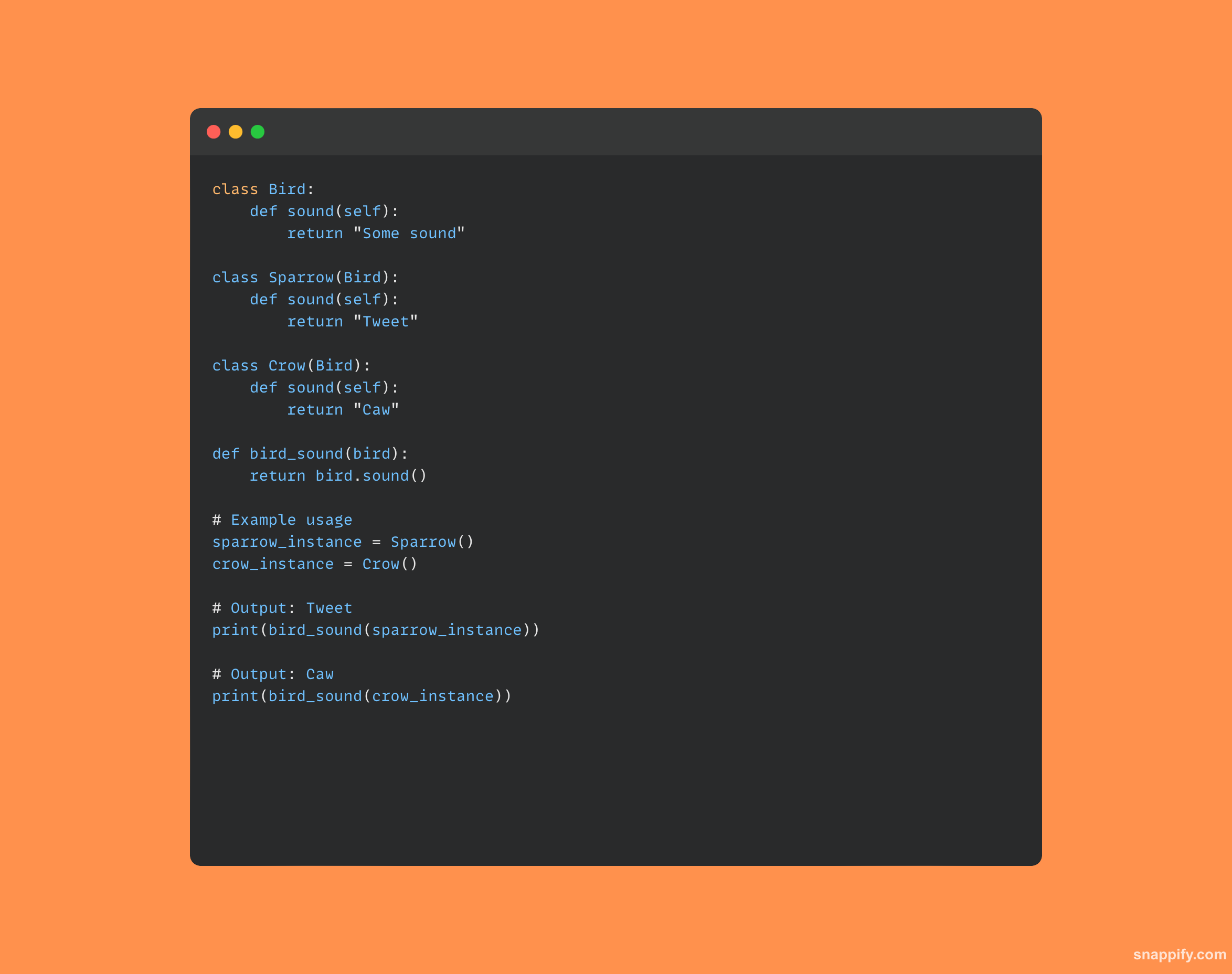
11.什么是方法重载和重写?
的两个基石 面向对象的编程、方法重载和方法覆盖,使开发人员能够将相同的方法名称用于多种目的。
由于方法重载,单个方法可以通过具有多个签名来容纳各种数据类型和参数计数。
另一方面,方法重写允许子类将自己的特殊实现添加到其父类中已定义的方法中,从而保证调用子类的版本。
总之,这些策略通过启用依赖于上下文和应用程序的特定要求的方法行为来提高适应性。
下面是示例了这两个概念的代码示例:
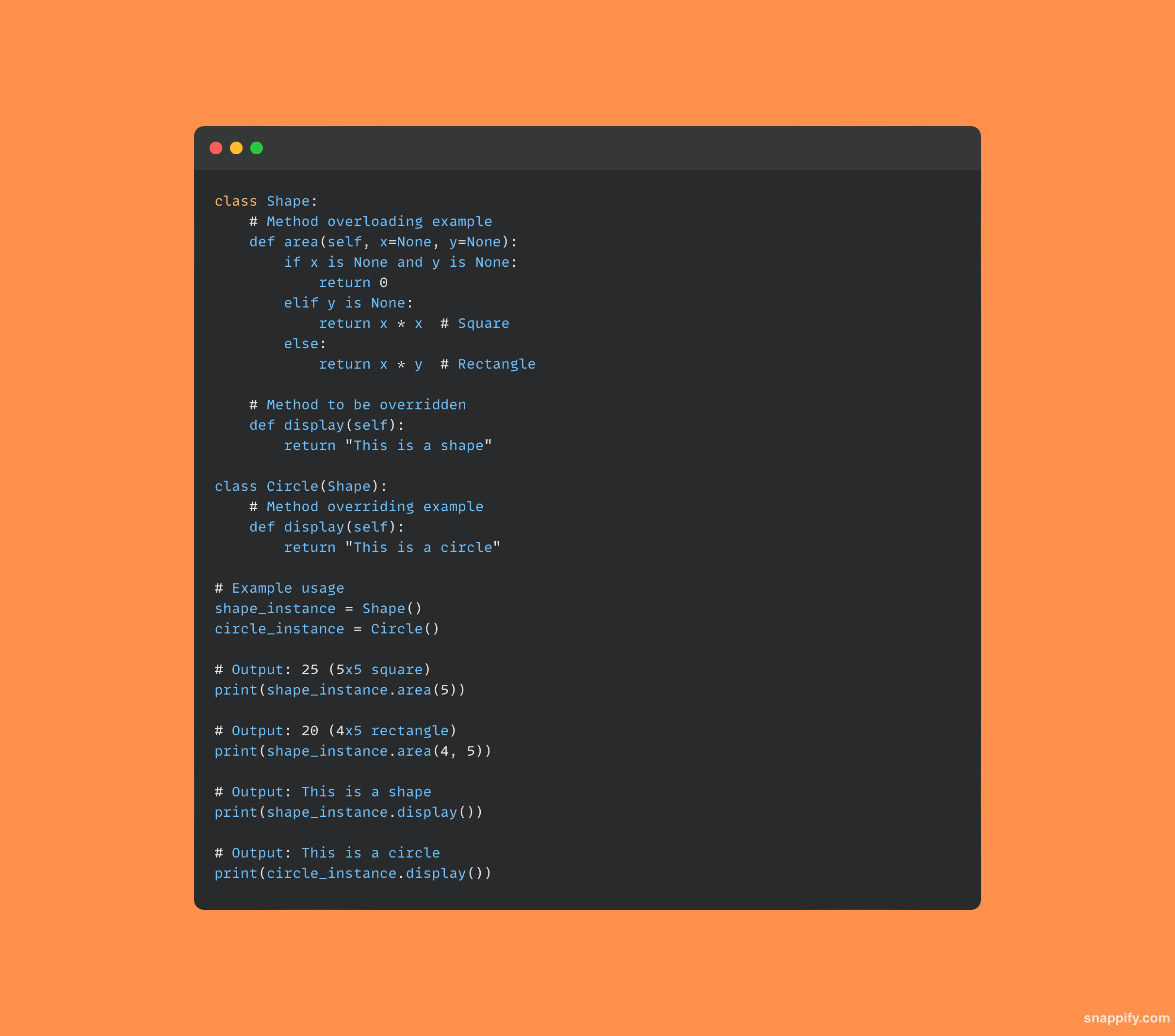
12.举例描述多态性的概念。
多态性是对各种数据类型使用单一接口的做法。
这个想法通过赋予方法根据其内在类型或类以多种方式处理对象的自由,确保了设计的适应性和可扩展性。
本质上,多态性通过继承允许不同类的对象被视为同一类的实例,从而实现统一的交互,同时保持不同的行为。
这种动态功能允许单个函数或运算符与各种对象类型交互而不会出现任何问题,从而促进了代码的简单性。
这是一个演示多态性的清晰代码示例:
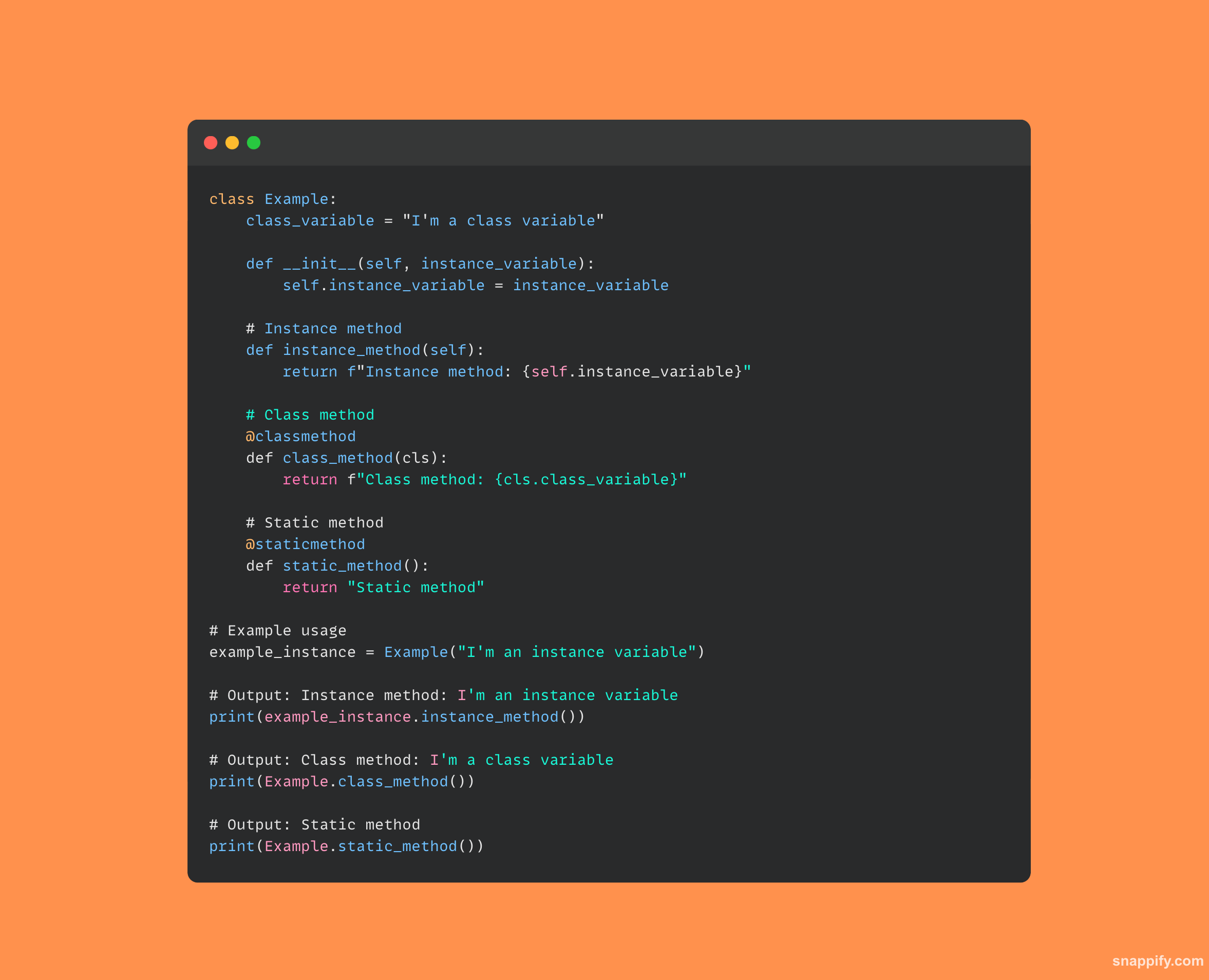
13.解释实例、类和静态方法之间的区别。
实例、类和静态方法都有自己独特的方式与 Python 中的对象和类数据进行交互。
最流行的类型是实例方法,它作用于类实例数据,并将类的实例(通常称为 self)作为输入。
类本身(通常称为 cls)被类方法接受为参数,类方法用 @classmethod 表示,并且它们操作类级别的数据。
静态方法(由哈希符号 @staticmethod 表示)不会影响类或实例状态,因为它们是类中包含的独立函数,并且不将 self 或 cls 作为第一个参数。
由于每种方法类型提供不同的访问和实用性,因此面向对象的体系结构是灵活且精确的。
作为代码中这些方法类型之一的示例:
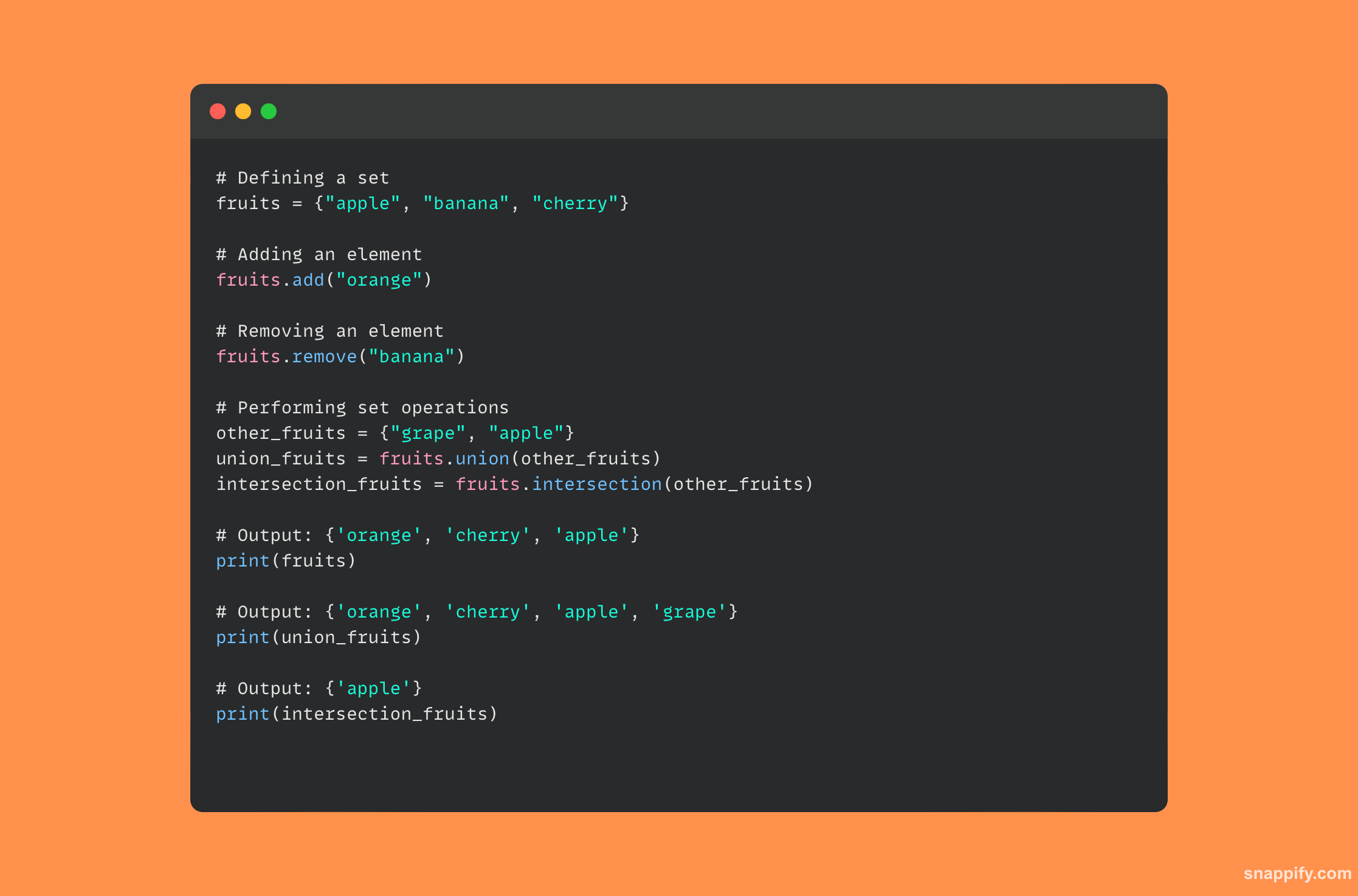
14. 描述 Python 集的内部工作原理。
一个内部 数据结构 Python 集合(不同组件的无序集合)使用称为哈希表的哈希表来执行强大且有效的操作。
当将元素添加到集合中时,Python 使用哈希函数快速管理和检索数据,将元素转换为哈希值,然后定义其在内存中的位置。
通过促进快速成员资格检查和删除重复条目,该技术可确保集合中的每个元素都是唯一的且易于访问。
因此,集合的固有架构倾向于优化并集、交叉和差异等操作,从而产生小而有效的数据结构。
下面是一段代码,展示了如何简单地与 Python 集交互:
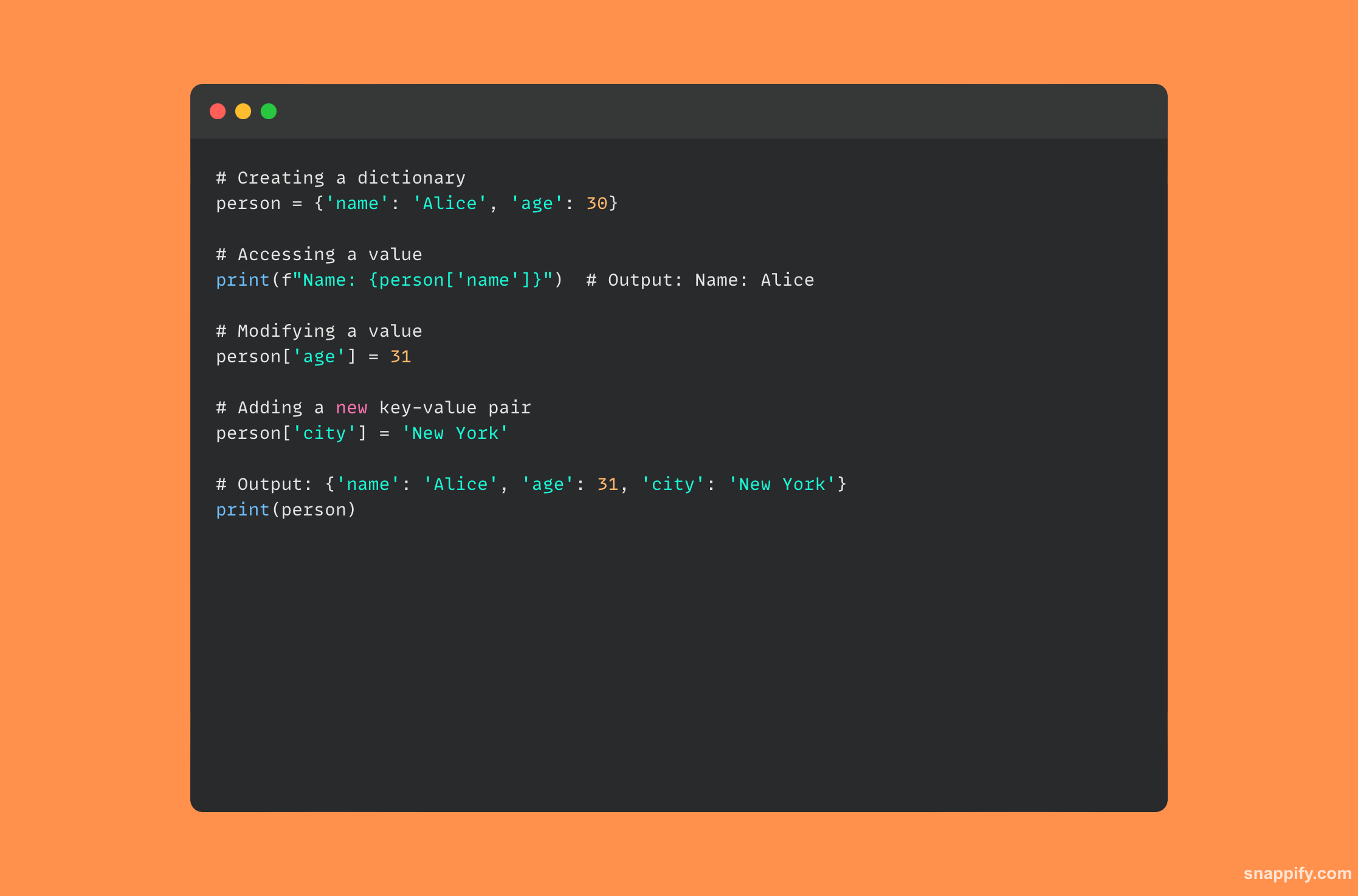
15. Python 中字典是如何实现的?
哈希表是 Python 中字典的基础,可以快速检索和操作数据。 字典是动态的、无序的键值对集合。
当发出键值对时,Python 使用哈希函数来计算键的哈希值,从而定位该值在内存中的存储地址的位置。
由于散列函数立即将解释器指向内存地址,因此这种设计可以基于键快速访问数据,并且在检索、插入和删除操作方面具有惊人的效率。
由于 Python 字典提供的速度和灵活性的诱人组合,开发人员可以轻松有效地管理数据。
下面列出的是显示如何使用 Python 字典的代码示例:
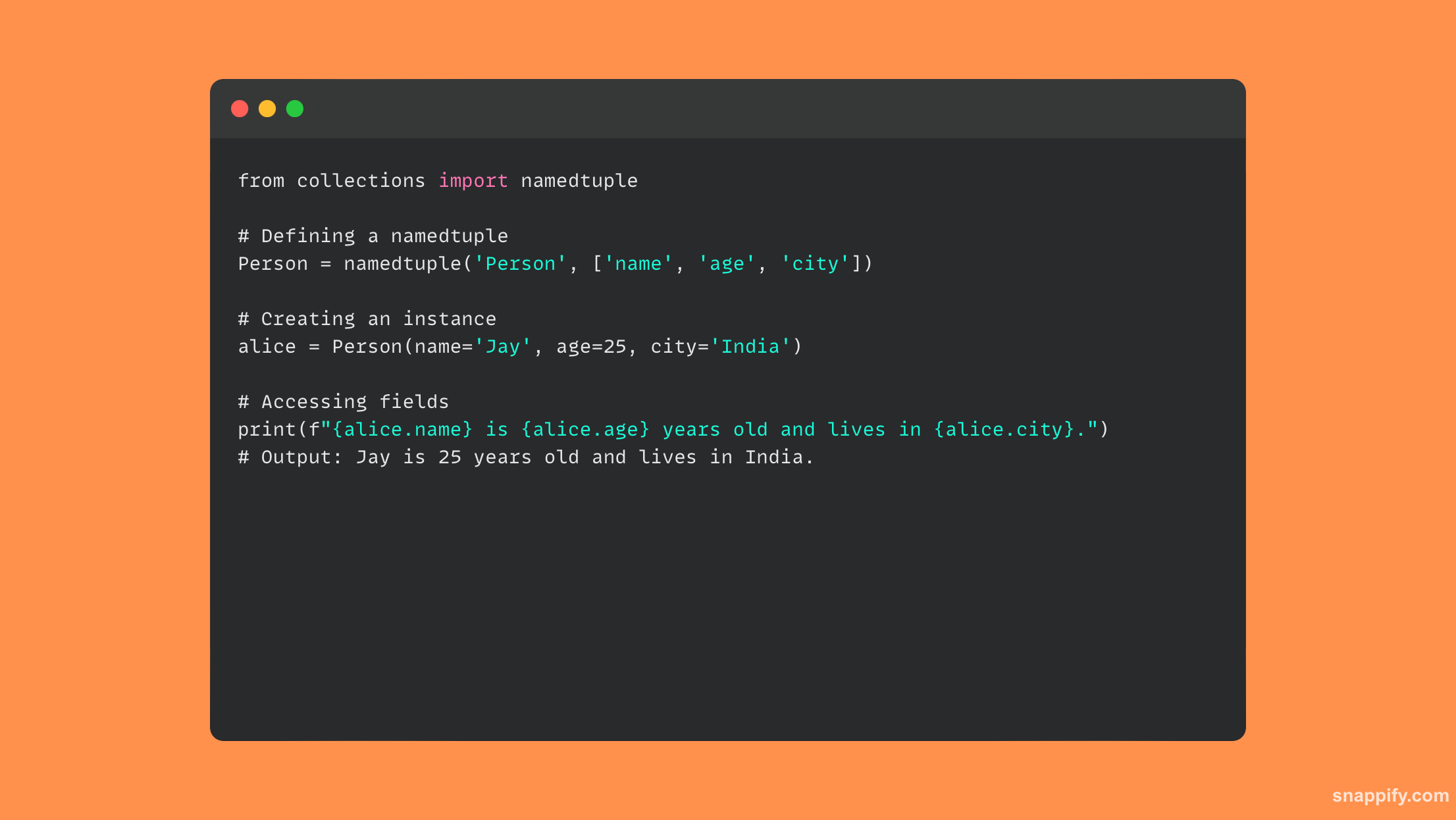
16. 解释使用命名元组的好处。
Python 中命名元组的使用巧妙地将类的表现力与元组的简单性结合起来,从而产生了一个小型的、不言自明的数据结构。
传统元组通过命名元组进行扩展,保持元组的不变性和内存效率,同时添加命名字段以提高代码可读性和自描述性。
命名元组通过建立简单、轻量级的对象(无需任何方法)来促进清晰、易理解和高性能的代码,从而提高开发人员体验和计算性能。
因此,命名元组发展成为一种强大的工具,可以在不影响速度的情况下改进数据结构和可读性。
下面显示了说明命名元组的使用的代码示例:
17. try- except 块如何工作?
try-except 块充当 Python 表达语法中的哨兵,警惕地防止运行时异常,并在存在潜在问题的情况下保持执行的顺利进行。
当 try 块遇到错误时,控制权会自动转移到适当的 except 块,通过报告、修复或重新抛出异常来解决问题。
通过以有目的的、受控的方式处理异常,该系统不仅可以防止破坏性崩溃,还可以改进 用户体验 和数据完整性。
因此,try- except 块巧妙地将错误管理与程序执行结合起来,保证了应用程序的健壮性和稳定性。
以下是使用 try-except 块的代码示例:
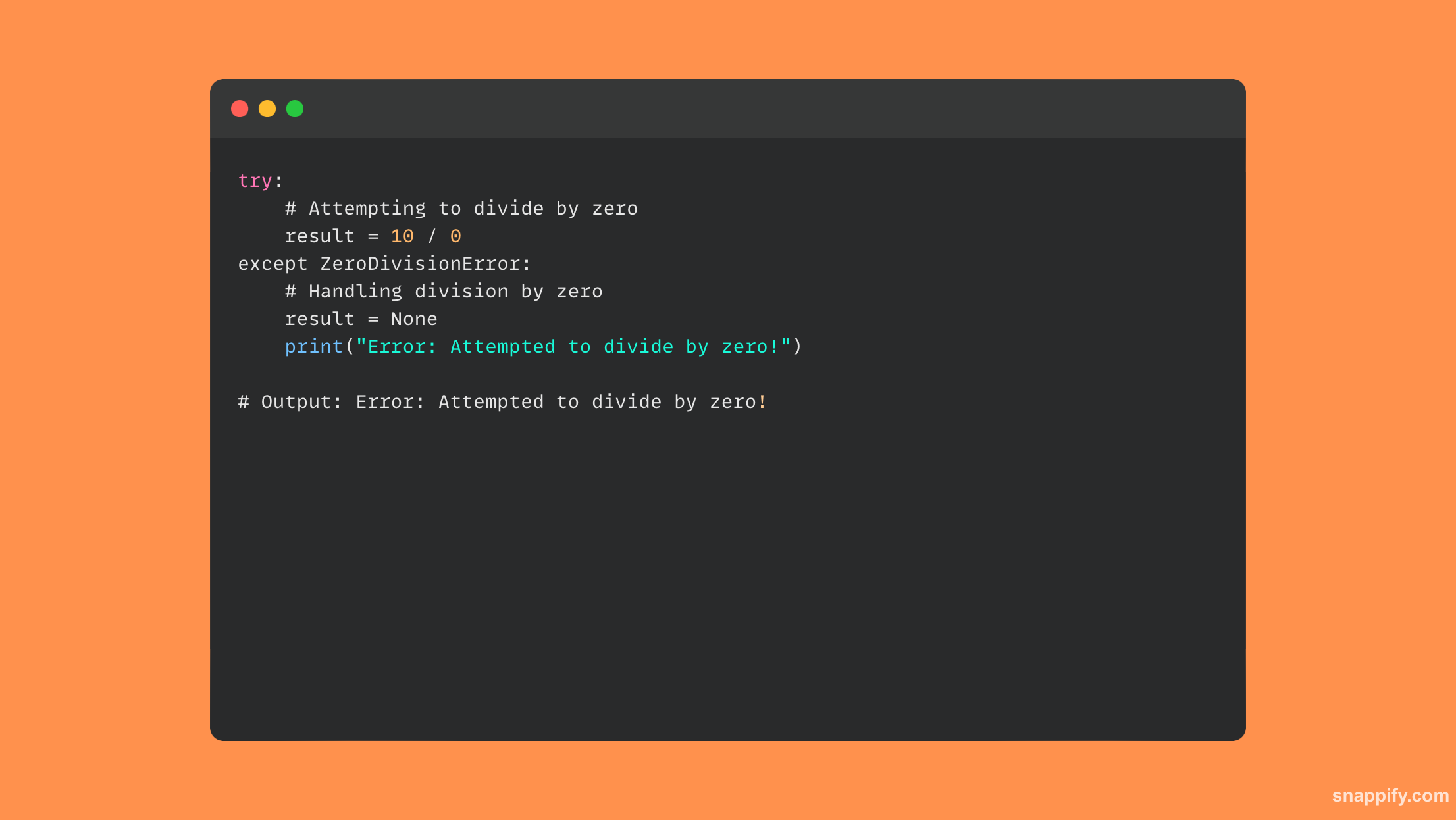
18. raise 和assert 语句有什么区别?
Python错误处理中的raise和assert语句代表异常管理的两个独立但相关的表达式。
raise 语句允许程序员显式地引发指定的异常,从而使程序员能够显式地控制错误消息和流程。
Assert另一方面,通过自动生成一个调试工具来充当调试工具 AssertionError 如果不满足其相应的条件,则保证程序在开发过程中按预期运行。
Assert 只是检查条件,改进调试和验证,而 raise 则可以实现更广泛、更明确的控制。 raise 和assert 都允许受控异常产生。
这是一些示例代码,展示了如何使用 raise 和 assert:
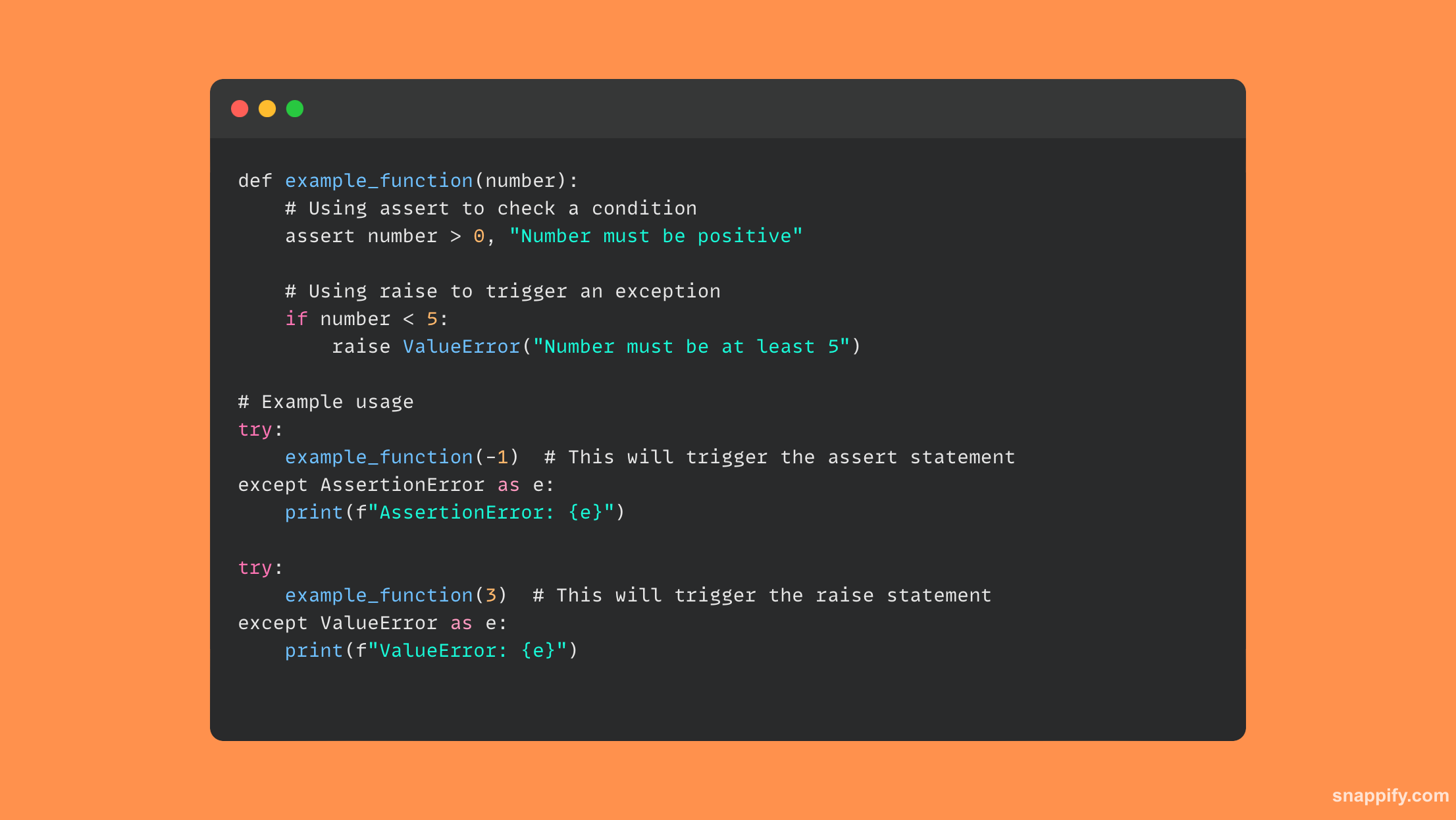
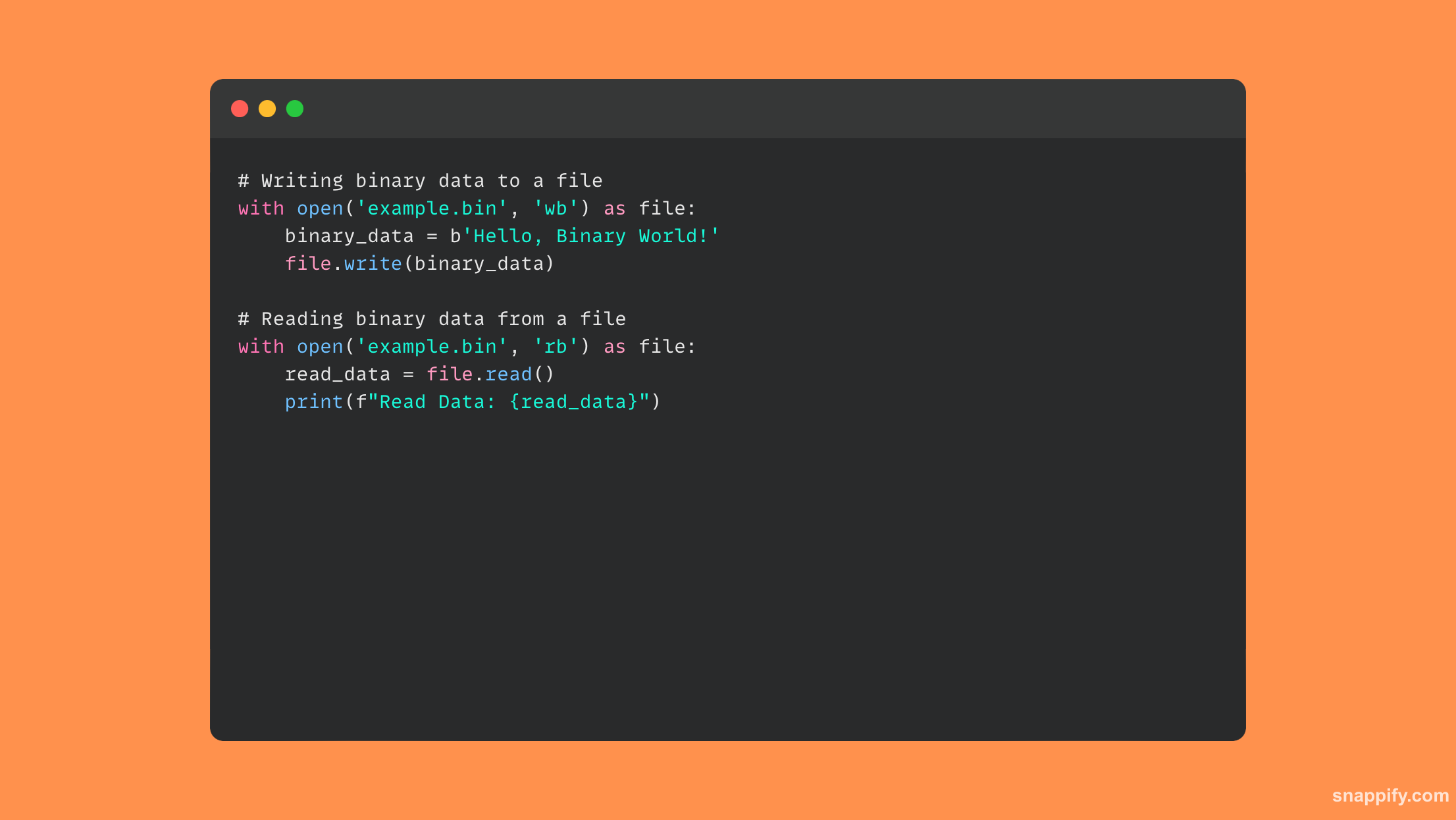
19.如何在Python中从二进制文件中读取和写入数据?
使用带有二进制模式说明符的内置 open 函数,在 Python 中与二进制文件交互需要在准确性和简单性之间取得平衡。
使用 rb or wb 打开二进制文件时的模式将确保在读取或写入二进制数据时以未编码的原始形式处理数据。
通过使用这些模式,Python简化了对非文本数据(例如图片或可执行文件)的管理,使程序员能够精确、轻松地处理和分析二进制数据。
因此,Python 中的二进制文件操作为广泛的应用打开了大门,包括数据序列化、图像处理和二进制分析等。
使用二进制文件,此代码示例展示了如何读取和写入数据:
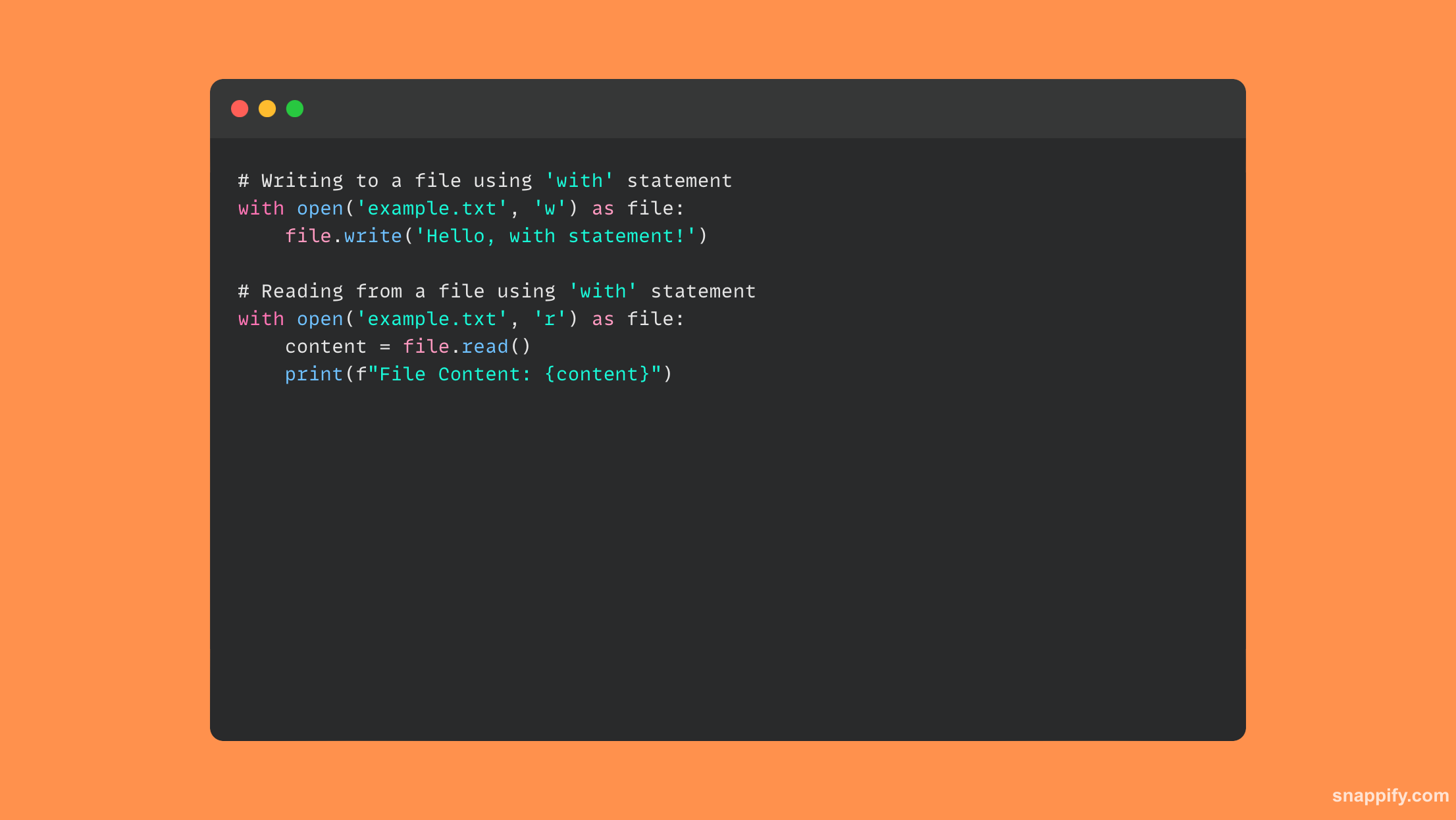
20. 解释一下 with 语句及其在使用文件 I/O 时的优点。
Python 的 with 语句经常与文件 I/O 一起使用,由于上下文管理的思想,它优雅地确保资源得到有效处理。
在处理文件的时候, with即使执行操作时发生异常,语句也会在使用后立即关闭文件,从而防止资源泄漏并保证干净终止。
通过消除样板代码,这种语法糖提高了代码的可读性。 它还通过集成资源管理和异常处理来提高可靠性和简单性。
因此,with 语句对于确保文件操作可靠且干净地包含、防止出现不可预见的问题并提高代码清晰度至关重要。
这是使用以下代码的示例 with 文件操作中的语句:
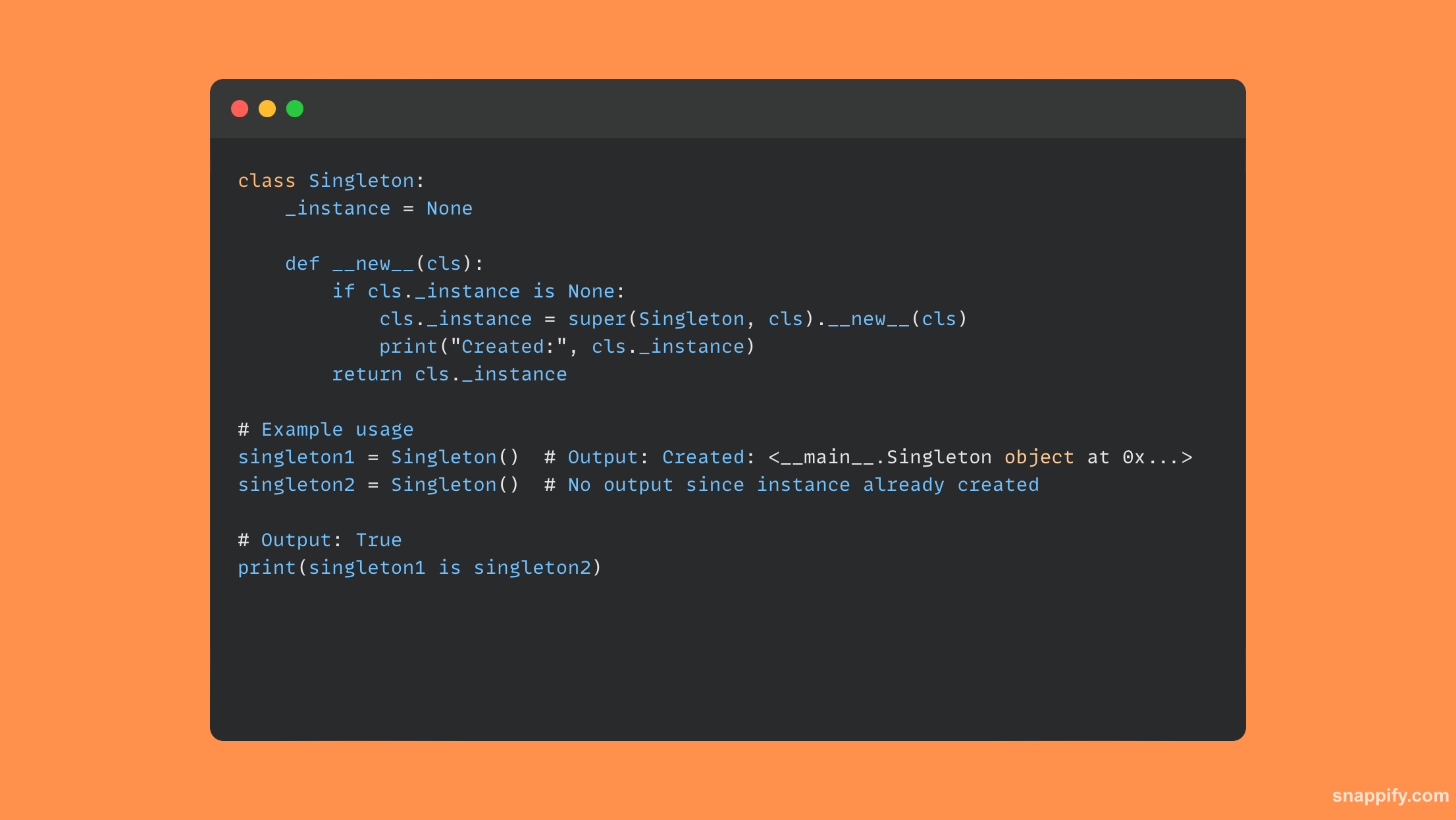
21. 如何在 Python 中创建单例模块?
类方法和内部检查的组合用于在 Python 中创建单例模块,这是一种仅允许创建类的单个实例的设计模式。
通过跟踪自己的实例并提供生成或返回它的方法,类遵循此模式以确保后续实例化复制第一个实例。
通过单点控制、对资源的统一访问以及防止竞争操作,单例可确保单点控制。
因此,它发展成为封装共享资源、保证整个程序访问和修改一致的有效工具。
下面是一个演示单例类的 Python 代码示例:
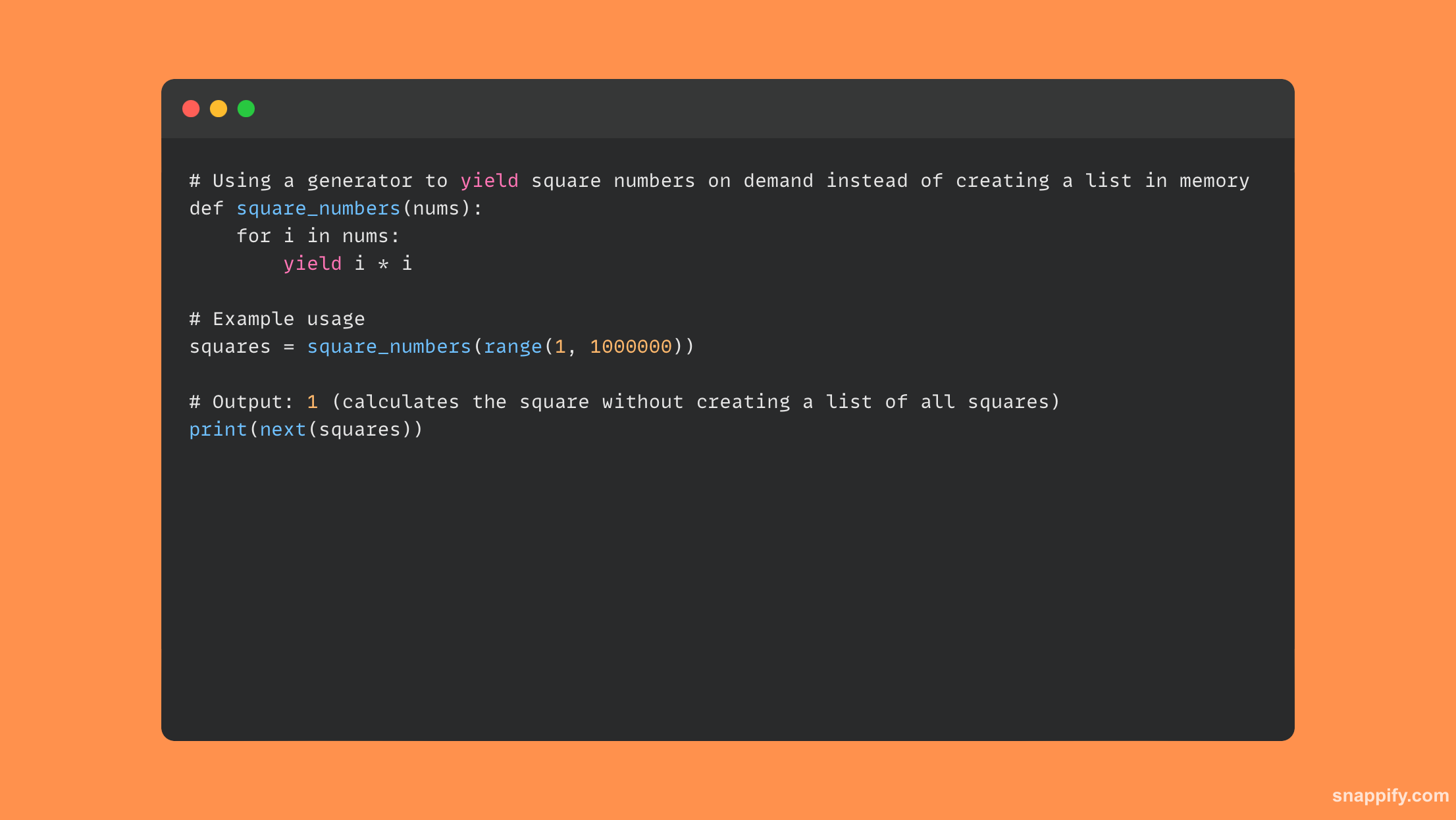
22. 列举几种优化 Python 脚本内存使用的方法。
Python 脚本内存消耗优化通常需要在数据结构选择、算法改进和资源管理之间进行仔细的平衡。
例如,在处理大型数据集时,使用生成器而不是列表可以通过延迟动态评估项目而不是将它们保留在内存中来显着减少内存使用。
通过使用数组数据结构而不是列表来处理数值数据并谨慎使用,可以进一步减少内存使用 __slots__ 类内声明控制动态属性的形成。
因此,通过平衡性能和资源使用,您可以确保 Python 程序不仅有效,而且在使用多少内存方面考虑周到。
以下是使用生成器来减少内存使用量的简短代码示例:
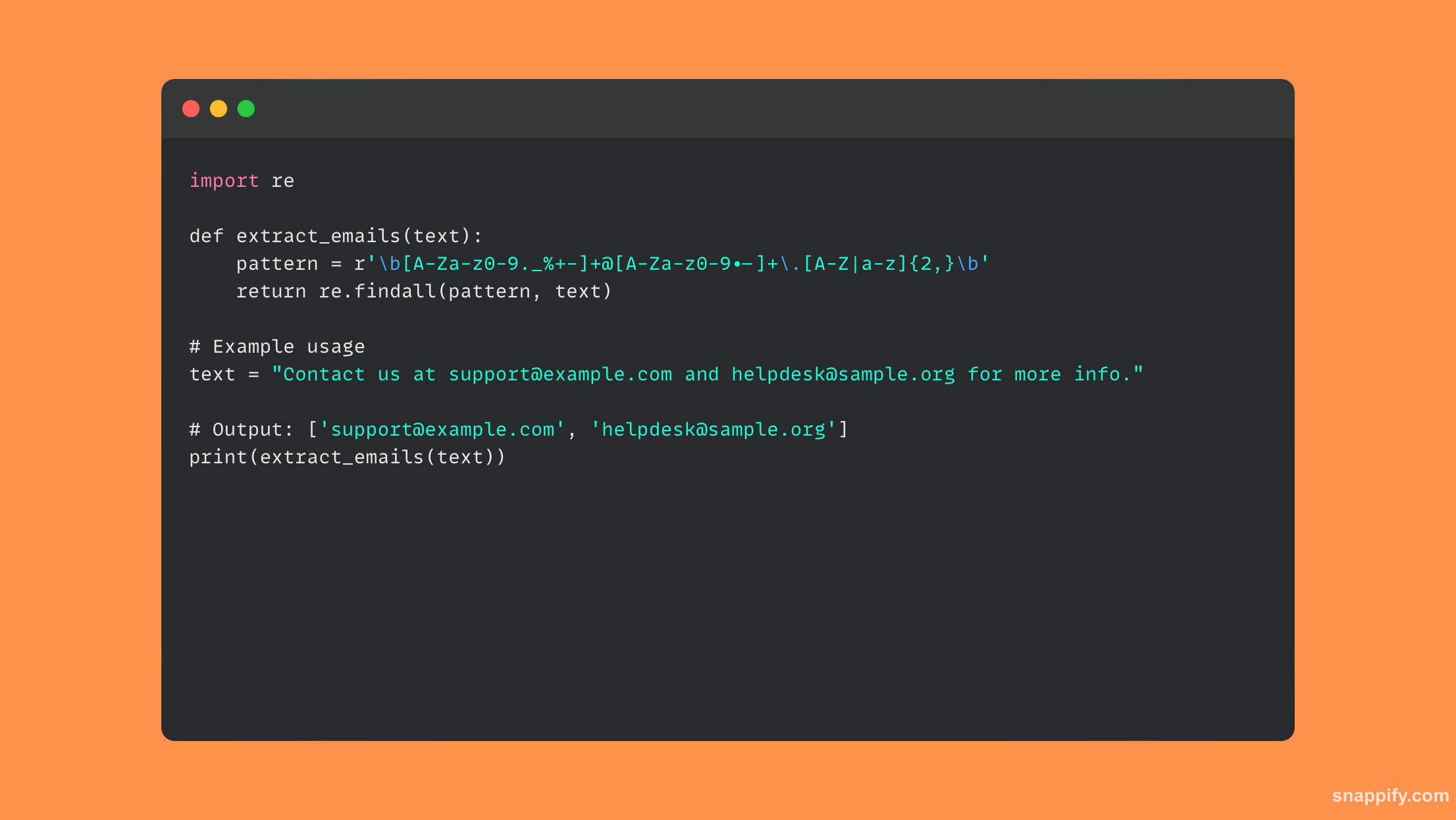
23. 如何使用正则表达式从给定字符串中提取所有电子邮件地址?
Python 中的正则表达式 (regex) 结合了准确性和多功能性,可从字符串中提取电子邮件地址,使开发人员能够巧妙地过滤文本材料并识别所需的模式。
为了建立电子邮件地址的结构,需要使用重新模块创建正则表达式模式。 然后,您可以使用 findall 获取目标字符串中所有出现的位置。
该方法熟练地导航文本迷宫以获取所有隐藏的电子邮件地址,这不仅加快了提取过程,而且确保了正确性。
巧妙地利用正则表达式可以有效地从字符串中提取某些数据,增加Python脚本的数据处理和分析能力。
这是一段使用正则表达式提取电子邮件的代码:
24.讲解Factory设计模式及其在Python中的应用
面向对象编程的基本原则,即工厂设计模式,是在不识别要生成的对象的精确类的情况下创建对象。
通过创建一个根据方法输入或配置返回多个类的实例的方法,可以在 Python 中优雅地实现工厂模式。
这个过程有时被称为“工厂”,充当编织多个类实例的中心,保证创建对象时调用者无需手动实例化类。
因此,工厂模式保持了解耦的、可扩展的架构,同时提高了代码的模块化和内聚性。 它还提供了一种构建对象的简化技术。
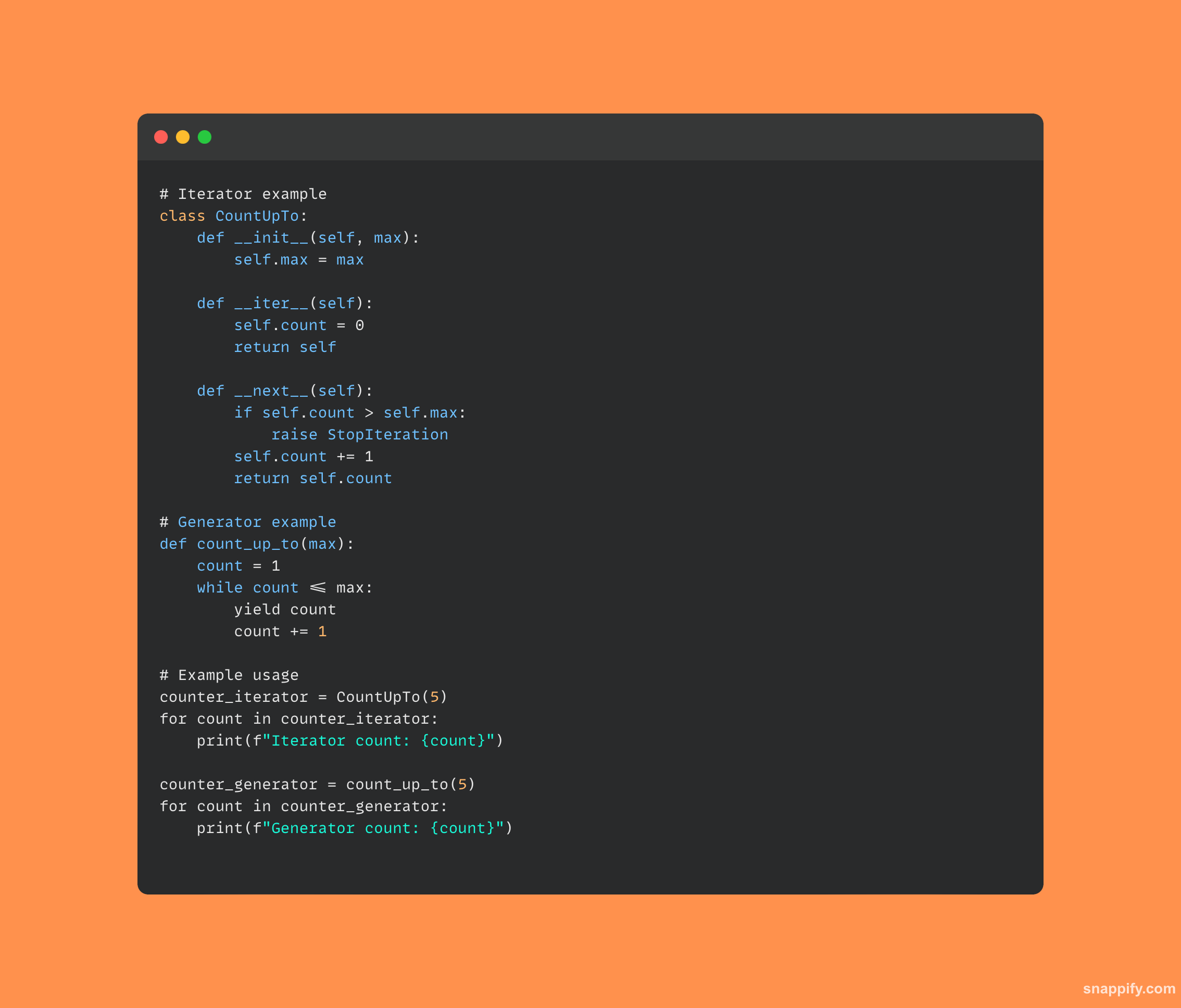
25.迭代器和生成器有什么区别?
从 Python 的迭代器和生成器可以清楚地看出,这两种结构都可以循环遍历值,但是,它们的实现和使用方式存在细微的差异。
生成器经常通过使用yield来识别,它自动维护其状态并使用函数实现,提供一种简洁且节省内存的方式来动态生成值。
迭代器通常作为类实现,使用如下方法 __iter__ 和 __next__ 管理其迭代状态并产生值。
因此,根据特定的用例,每种方法都有自己的优点,迭代器提供了一种彻底的、面向对象的方式来遍历数据,而生成器则提供了一种轻量级的、惰性的评估技术。
这两种技术都增加了开发人员的武器库,使得在各种情况下快速有效地探索数据成为可能。
下面是 Python 中迭代器和生成器的一段代码:
26.如何 @property 装修工的工作?
Python 中的“@property”装饰器演奏着美妙的旋律,将方法调用转换为类似属性的访问,从而提高对象的可用性和表现力。
使用@property可以不使用括号来调用方法,这类似于访问属性。 这为对象交互创建了一个更清晰、更易于使用的界面。
此外,它还提供了功能和封装之间的巧妙平衡,在提供直观界面的同时保护对象状态,使开发人员能够使用 getter 和 setter 方法轻松指定属性。
通过将方法功能与属性可访问性相结合, @property 装饰器作为一个重要的工具出现,并提供了一个简单而有效的对象交互范例。
Python 的一个例子 @property 装饰器如下图所示:
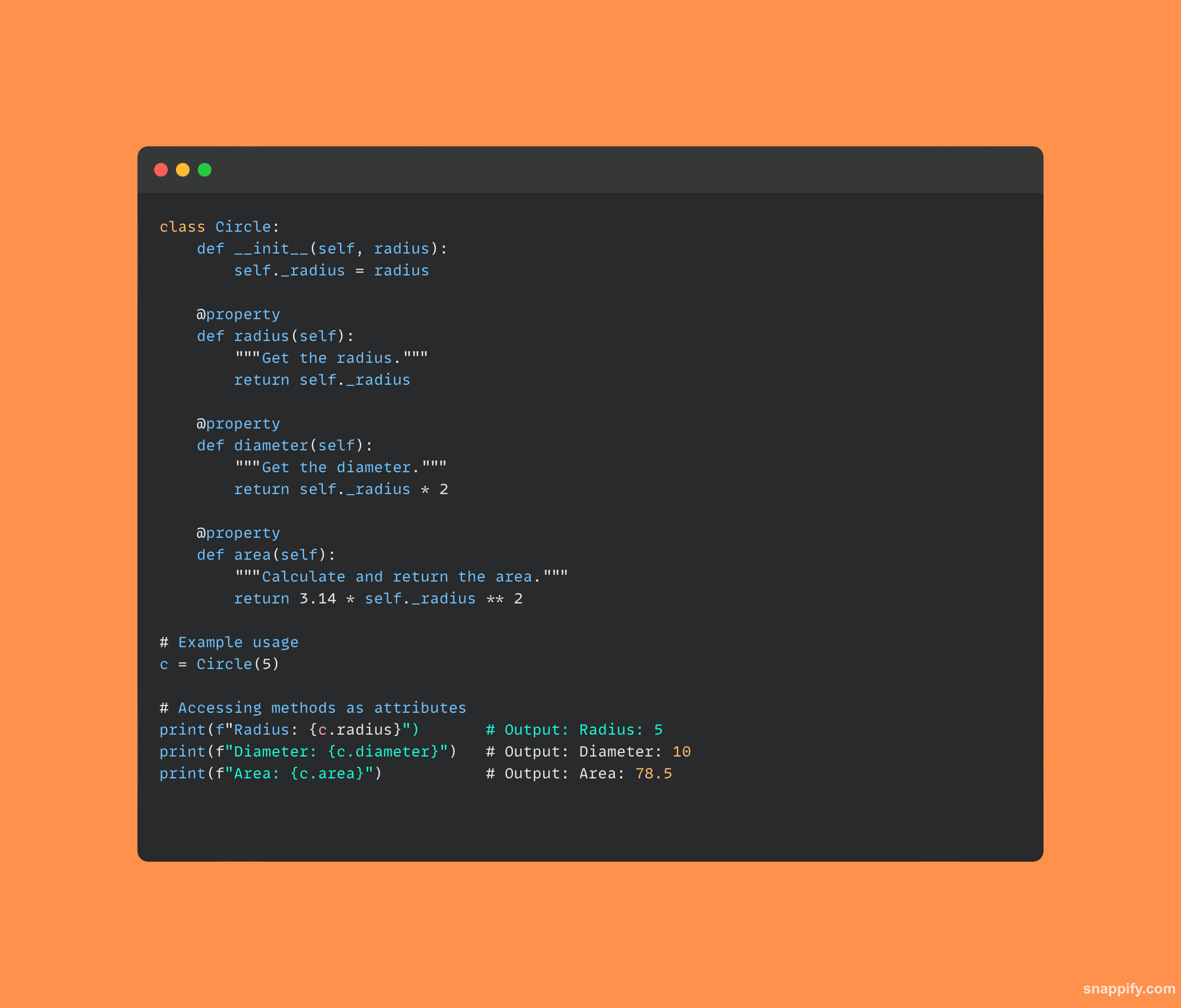
27. 如何用 Python 创建基本的 REST API?
为了构建通过 HTTP 请求交互的 Web 服务,开发人员在构建简单的 Web 服务时经常利用 Flask 等框架的表达能力 REST API 在Python中。
凭借其简单易懂的语法,Flask 使开发人员能够构建可通过多种 HTTP 方法(包括 GET 和 POST)访问的路由,以与底层应用程序进行通信。
使用 Flask 构建的 REST API 可以轻松接受 HTTP 请求、处理所包含的数据,并通过指定与各种功能链接的唯一端点来提供相关信息作为响应。
为了确保网络环境中各个软件组件之间的无缝通信,开发人员可以结合使用Python和Flask来使用强大的REST API。
以下是使用 Flask 创建 REST API 的一小段代码:
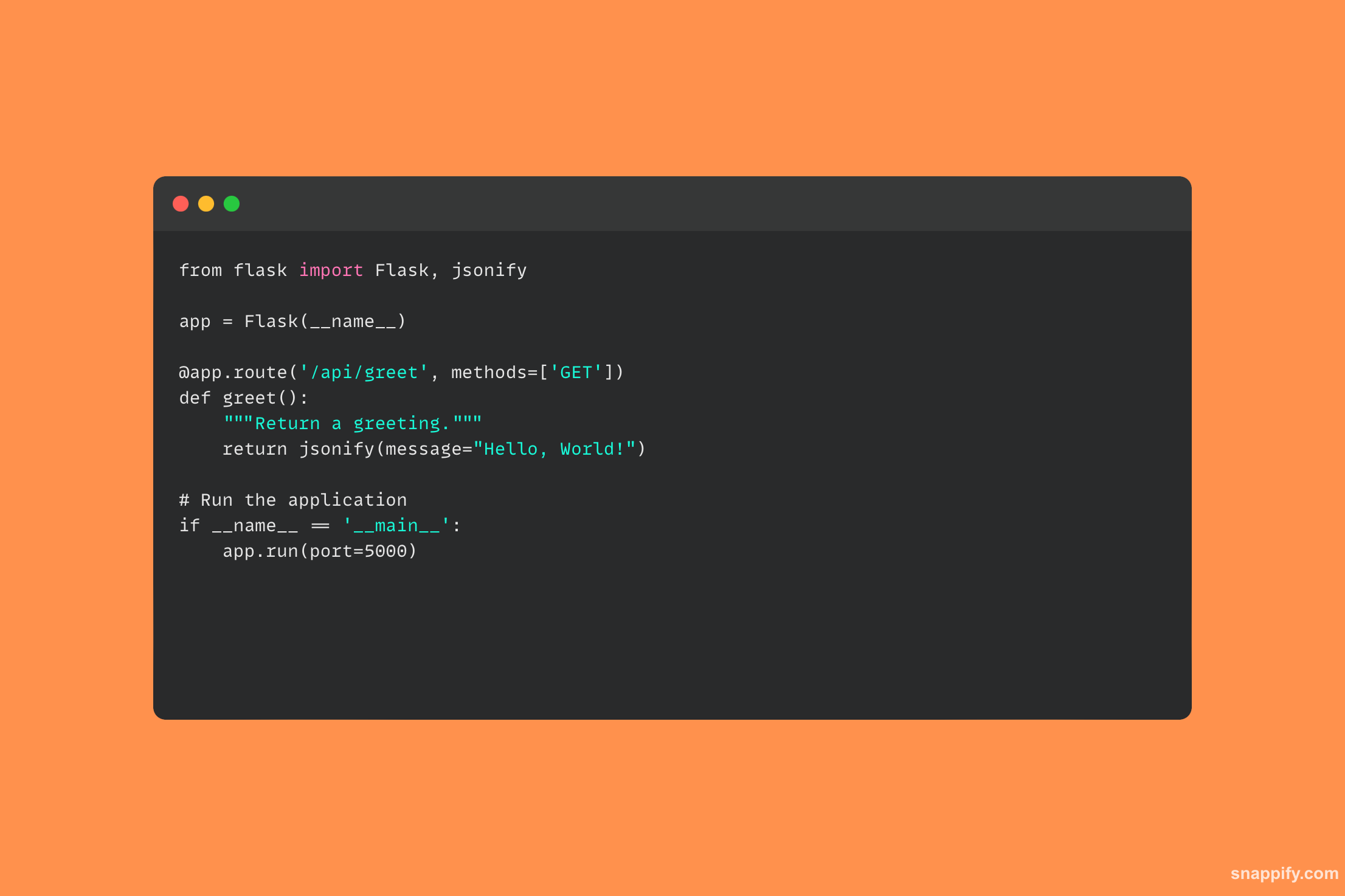
28. 描述如何使用requests库发出HTTP POST请求。
Python 的 requests 库是一个强大的工具,它将 HTTP 通信的困难转化为友好的 API,并使使用 HTTP POST 请求与在线服务交互变得简单自然。
POST 请求是通过使用 post 方法发出的,给出目标 URL,并附加要发送的材料,其中可以包含表单数据、JSON、文件等。
然后,请求库管理底层 HTTP 连接,将数据发送到指定的 URL 并收集服务器的响应以实现流畅的 Web 交互。
开发人员可以轻松地使用在线服务、提交表单数据并通过请求与 Web API 进行交互,从而弥合本地应用程序与全球网络之间的差距。
使用 requests 库,以下代码示例展示了如何发送 HTTP POST 请求:
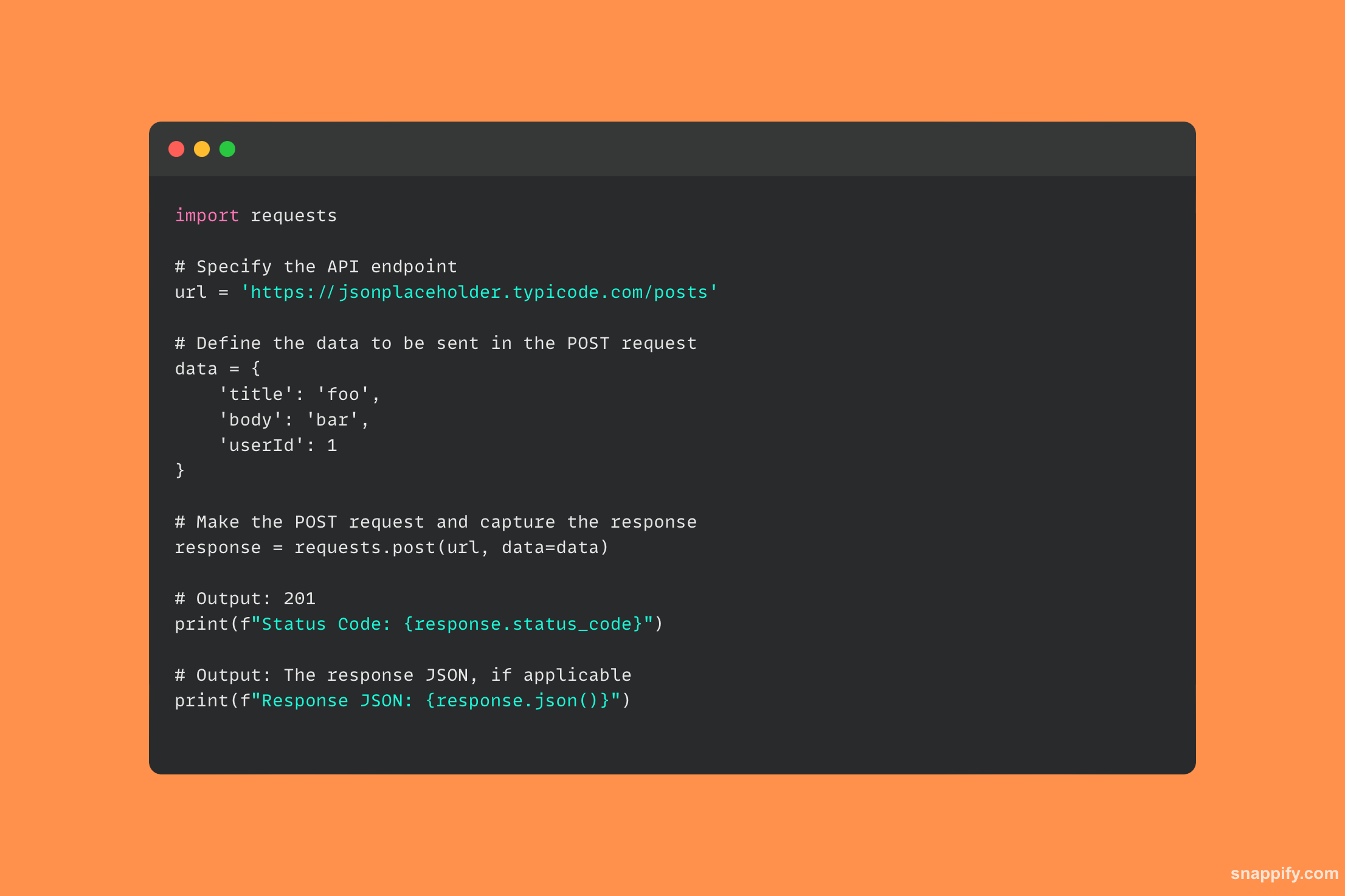
29. 如何使用 Python 连接到 PostgreSQL 数据库?
psycopg2 包可以优雅地处理从 Python 环境与 PostgreSQL 数据库的交互,这是一个允许无缝数据库交互的强大桥梁。
通过使用 psycopg2,程序员可以轻松创建连接、运行 SQL 查询并获取结果,将 PostgreSQL 的能力直接集成到 Python 程序中。
只需几行代码即可解锁复杂的数据库功能,保证数据的访问、修改和保存准确高效。
该模块通过优雅地实现Python和PostgreSQL之间的协同作用,使开发人员能够在他们的应用程序中充分利用关系数据库。
这是演示如何使用的示例代码 psycopg2 建立与 PostgreSQL 数据库的连接的库:
30. ORM 在 Python 中的作用是什么?请说出一种流行的 ORM?
Python 中的对象关系映射 (ORM) 使开发人员能够使用 Python 类和对象范例连接数据库。
它充当面向对象编程和关系数据库管理之间的和谐中介。
SQLAlchemy 是 Python 环境中最著名的 ORM 之一,它提供了一套完整的工具,用于使用高级、面向对象的语法与多个 SQL 数据库进行交互。
在 SQLAlchemy 的帮助下,数据库实体可以表示为 Python 类,这些类的实例充当数据库表中的行。
这使得程序员无需编写任何原始 SQL 查询即可操作数据库。
由于 SQL 和数据库连接的复杂性,像 SQLAlchemy 这样的 ORM 使得更加用户友好、安全和可维护的数据库交互成为可能。
下面是一个简单的示例,展示了 SQLAlchemy 的工作原理:
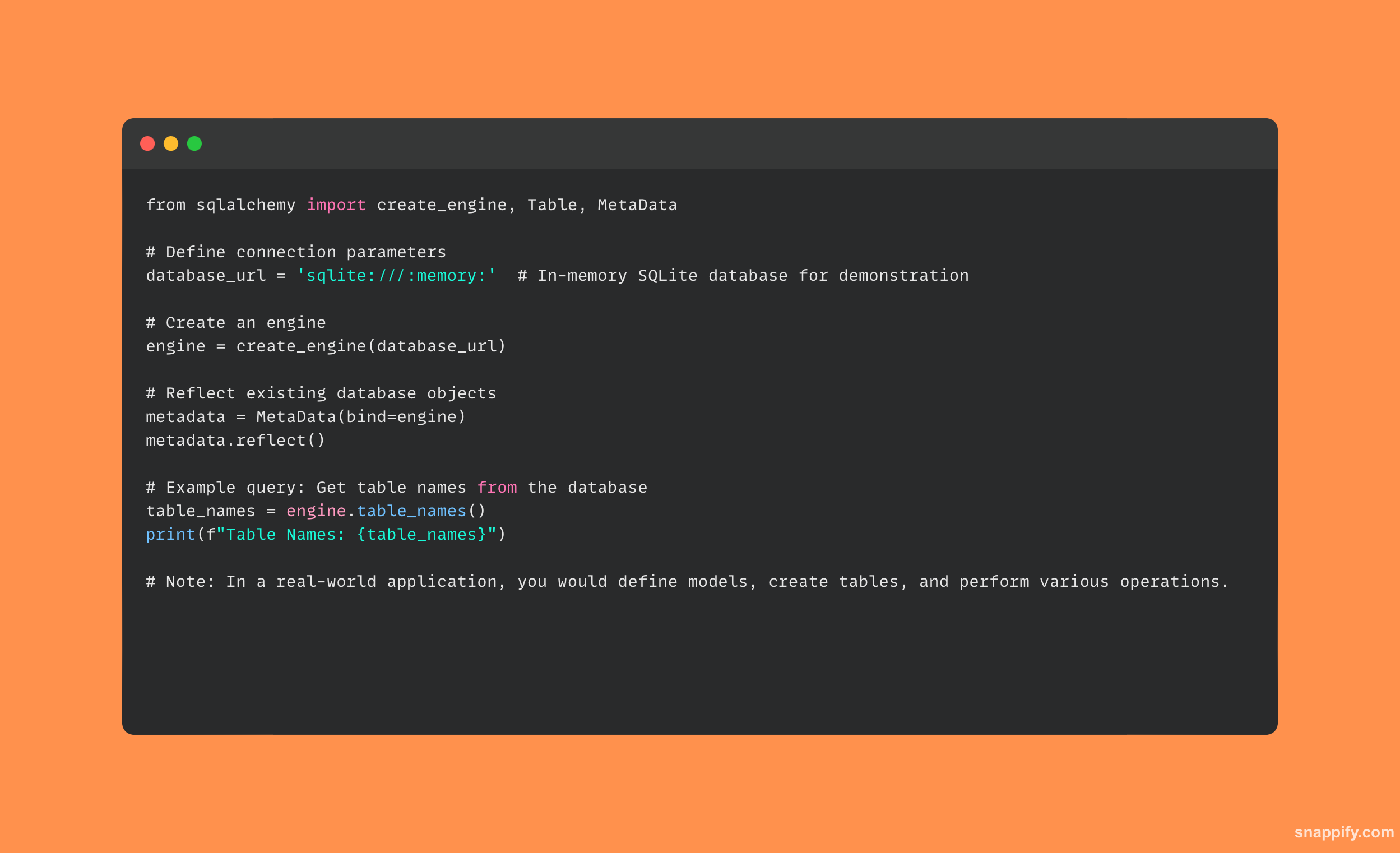
31. 您将如何分析 Python 脚本?
通过分析 Python 脚本的计算结构及其执行的时间和空间细节来对 Python 脚本进行分析,以找到任何可能的性能瓶颈并提高效率。
开发人员可以利用内置的功能仔细分析代码在运行时的行为 cProfile 模块。
通过这样做,他们可以获得有关函数调用、执行时间和调用关系的全面数据,从而使他们能够识别和解决性能瓶颈。
通过将分析纳入开发生命周期,您可以保证代码不仅正确运行而且高效运行,平衡计算资源并提高整体应用程序性能。
因此,开发人员可以通过仔细的分析来防止程序效率低下,确保它们在各种计算需求上进行可靠的调整和性能。
下面是一个使用 Python 脚本分析的简单示例 cProfile 模块:
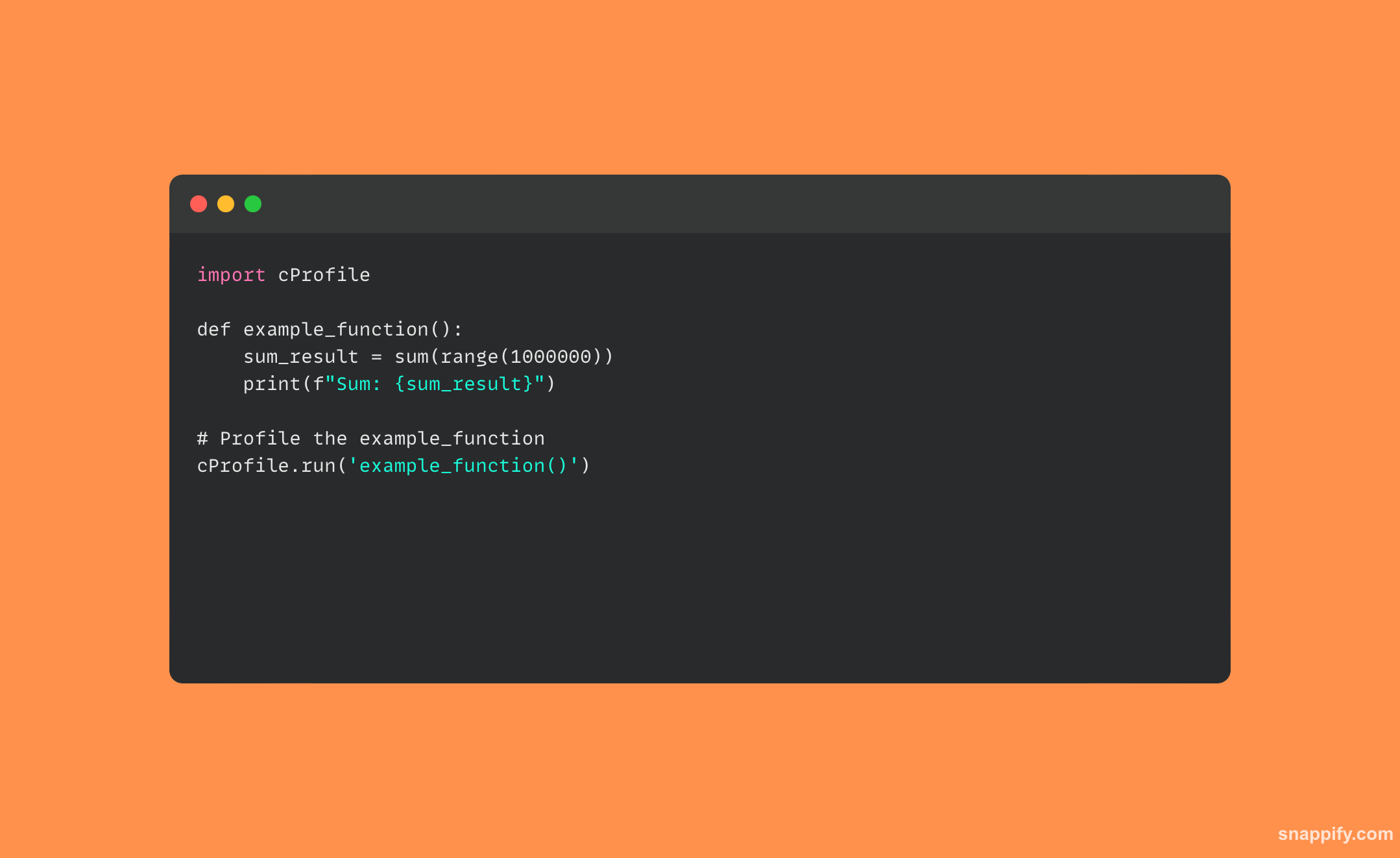
32.解释CPython中的GIL(全局解释器锁)
CPython 中的全局解释器锁 (GIL) 充当哨兵,保证单个进程中一次只有一个线程运行 Python 字节码,即使在多线程应用程序中也是如此。
尽管它可能看起来是一个瓶颈,但 GIL 对于保护 CPython 的内存管理和内部数据结构免受并发访问以及保持系统完整性至关重要。
不过,必须牢记在 I/O 密集型活动中对多线程的需求,其中线程必须等待数据的传送或接收,因为 GIL 并没有消除这种需求。
因此,即使 GIL 给受 CPU 限制的活动带来困难,但对其行为的理解和技术的适应(例如采用多处理或并发编程)允许开发人员创建有效的并发 Python 程序。
下面是一个使用线程的 Python 代码示例,展示了 GIL 如何对 CPU 密集型任务产生影响:
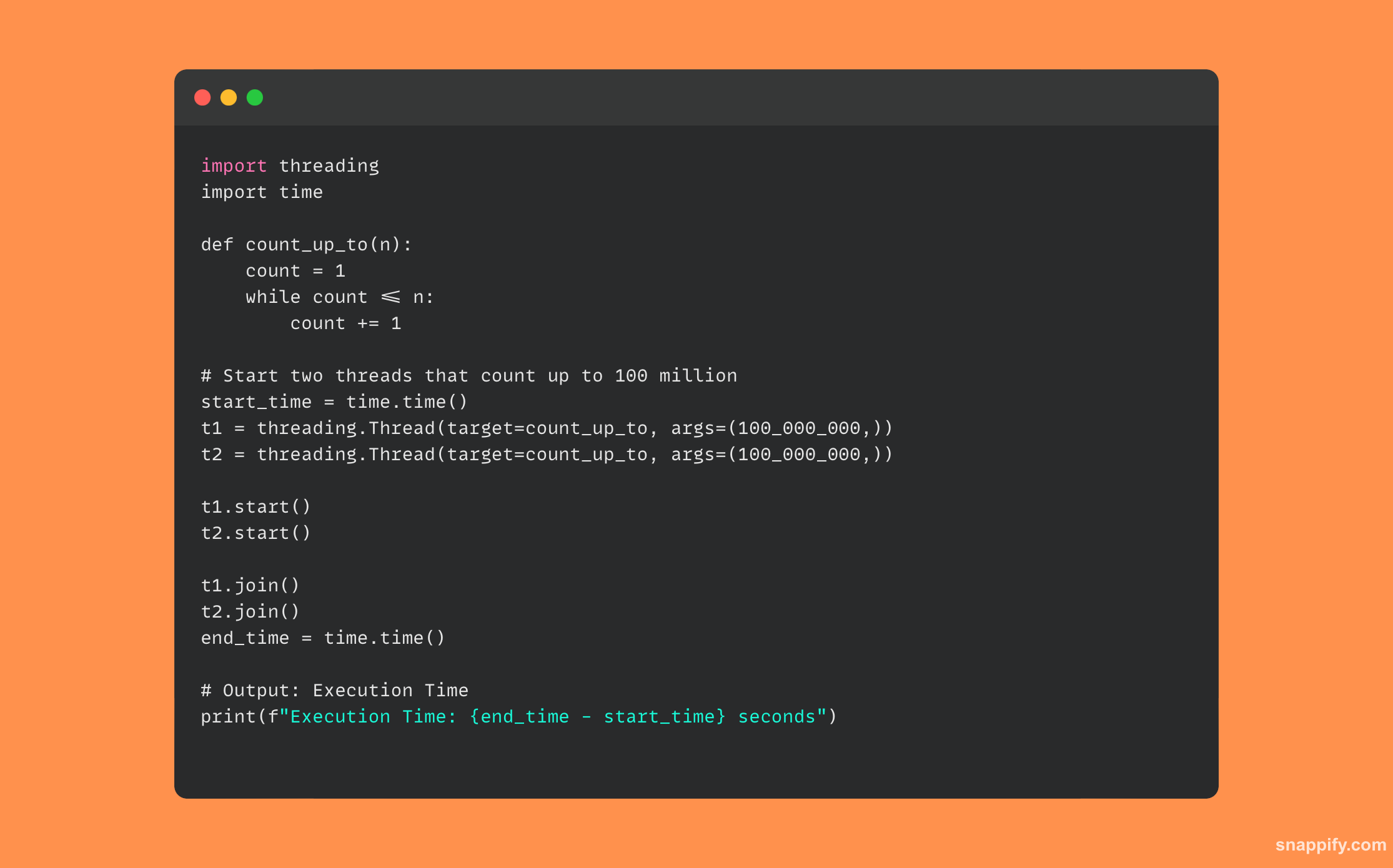
33.解释Python的async/await。 它与传统的线程有何不同?
Python 中的 async/await 语法打开了异步编程的世界,这种范例允许某些函数将控制权交给运行时环境,以便其他活动可以同时执行,从而提高程序效率。
Async/await 在单个线程中维护活动,但允许执行在任务之间跳转,从而确保非阻塞行为,而无需复杂的线程管理。
这与经典线程形成对比,在经典线程中,线程并行执行并且经常需要复杂的管理和同步。
因此,开发人员可以有效地处理并发 I/O 绑定活动,并使用更直接的方法来控制并发性。
这促进了协作式多任务处理模型,其中进程自愿屈服于控制。
因此,async/await 提供了一种独特的、简化的方式来设计并发应用程序,特别是在 I/O 操作常见的情况下,在性能和复杂性之间找到平衡。
下面提供了使用 async/await 的 Python 代码示例:
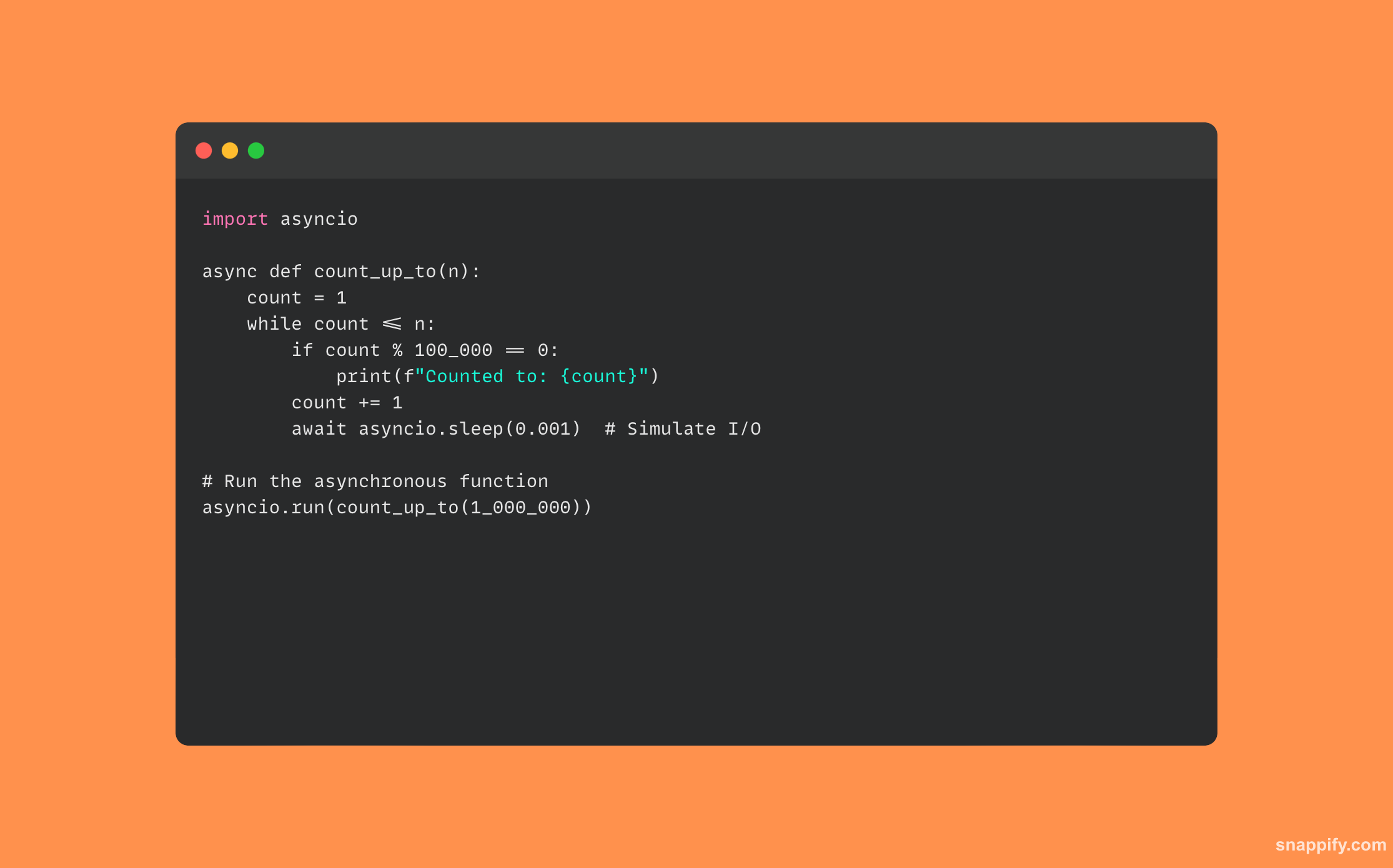
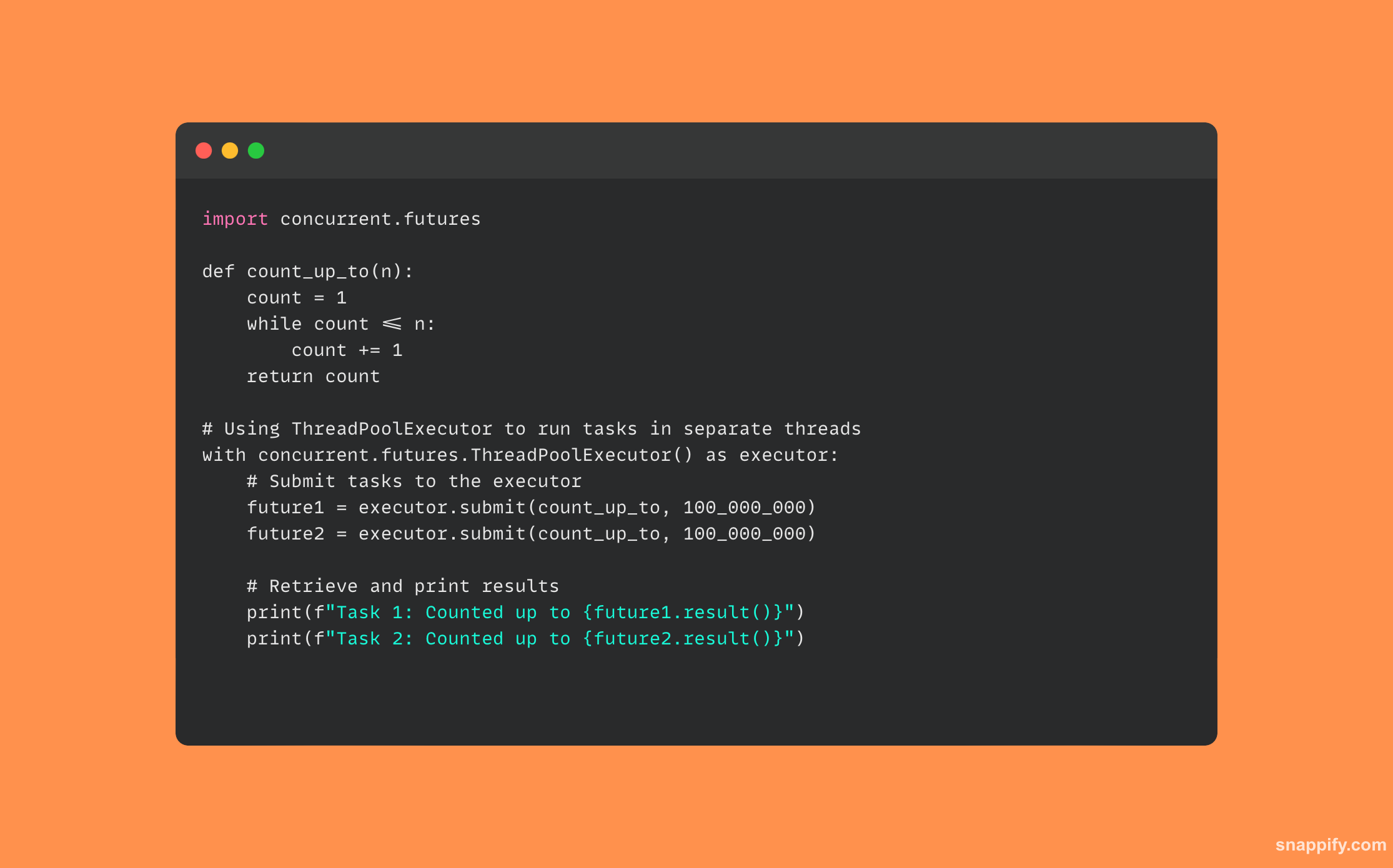
34.描述你将如何使用Python concurrent.futures.
通过线程或进程异步执行可调用对象的接口,开发人员可以优雅地管理异步和并行操作。
该模块管理可调用对象的资源分配和执行,同时通过执行器(ThreadPoolExecutor 和 ProcessPoolExecutor)封装线程和多处理的微妙方面。
开发人员可以有效地使用多核处理器来执行 CPU 密集型活动,并通过将任务发送到执行器来提供非阻塞 I/O 操作,然后执行器可以并发执行这些任务,甚至聚合它们的结果。
为了确保应用程序具有响应能力和性能, concurrent.futures 创建一个可以顺利合并复杂计算和 I/O 活动的空间。
这是使用的代码示例 concurrent.futures:
35. 在用例和可扩展性方面比较 Django 和 Flask。
Python Web 框架星座中的两颗明星 Django 和 Flask 在满足各种开发人员需求的同时,各自闪耀着光芒。
对于创建大型数据库驱动应用程序的程序员来说,Django 是首选工具,因为它带有 ORM 和内置管理界面。
然而,Flask 的简单模块化设计使开发人员可以自由选择自己的组件,使其成为小型项目或需要轻量级、适应性强的解决方案的情况的完美选择。
在可扩展性方面,这两个框架都可以扩展以满足更大的需求。
然而,Flask 的精益特性允许根据特定需求定制扩展策略,而 Django 的内置功能可以为其在更大、更复杂的项目中快速开发提供微小的优势。
结论
Python 脚本面试需要深入了解该语言的功能、复杂性和应用程序。
充分的准备不仅可以增强个人的技术能力,还可以激发信心,帮助申请人快速、准确地解决困难重重的问题。
有抱负的人可以通过回顾并发、OOP 原则和数据结构等关键思想,并深入研究 Web 编程和数据操作等实际应用程序,确保自己准备好处理基本和应用的 Python 问题。
因此,全面的教育对于成功至关重要,并且可以使一个人的 Python 编程能力变得出色并具有创造力。 看 Hashdork的采访系列 为面试准备提供帮助。





发表评论