在当今知识就是力量的数据驱动型社会中,Web 抓取已成为重要工具。 您一定听说过基于浏览器的网络抓取平台。
现在让我们讨论基于浏览器的网络抓取平台。 这些系统提供了一种简单快捷的方法来从网站中提取数据,而无需使用复杂的代码或专业知识。 他们提供简单的工具和用户友好的界面,简化了抓取过程。
基于浏览器的系统的美妙之处在于它们使 网络抓取 每个人都可以访问,从初学者到专家。 基于浏览器的解决方案使每个人都可以使用在线数据采集,无论他们是分析模式的研究人员、试图观察竞争对手的公司所有者,还是寻找信息的个人。
使用基于浏览器的网络抓取解决方案有几个优点。
首先,他们取消了对技术专长的要求,使任何人都可以轻松地从网站上抓取数据。 这些系统通常包括点击功能和图形 用户界面,使用户能够轻松地与网站互动并选择他们希望提取的数据。
基于浏览器的解决方案的数据验证、自动化和调度等功能的可用性简化了抓取过程并节省了宝贵的时间。 他们通常也有强大的代理网络,这保证了可靠和安全的数据提取,同时克服了限制或阻塞系统。
您可以使用基于浏览器的技术处理困难的抓取工作,从动态网站中提取数据,并将获取的数据转化为有用的见解。 通过访问在线可用的海量数据,它们使组织、研究人员和人们能够在数据驱动的世界中保持领先地位。 在这篇文章中,我们将看看最好的基于浏览器的网络抓取平台。
1. 明亮的数据
Bright Data 是基于浏览器的网络抓取工具中的一颗璀璨之星,它可以全面响应客户的网络抓取需求。 通过使用基于浏览器的方法,Bright Data 使您能够抓取具有动态内容、JavaScript 呈现和复杂页面架构的网站,以确保收集所有重要数据。
使用 Bright Data 的 Scraping Browser,您可以毫不费力地浏览和导航目标网站,同时 Bright Data 代表您管理整个代理和解锁基础设施。 Web Unlocker 的自动解锁功能的强大功能已集成到 Scraping Browser 中,这是一种专为数据抓取而设计的自动浏览器。
任何需要可扩展性、浏览器和自动控制所有网站解锁活动的数据抓取项目都非常适合使用它。 通过使用 Scraping Browser、Puppeteer 和 Playwright API,它成为一种自动化操作和从网站检索数据的适应性工具。
在处理大量数据时,此功能非常方便。 最后但并非最不重要的一点是,Bright Data 已实施反封锁方法,让您绕过验证码和其他类型的网站封锁。
其广泛的代理网络包括来自世界各地的超过 72+ 百万个住宅 IP 和 2 万个移动 IP,并为网络抓取提供无与伦比的覆盖范围和可靠性,这是其最独特的品质之一。
此外,它与许多兼容 编程语言,包括 Python、Node.js 和 Java,以及广泛使用的数据存储和分析系统,如 AWS、Google Cloud 和 BigQuery。 将 Bright Data 作为您的网络抓取盟友,您可以放心有效地进行抓取,并轻松释放数据的潜力。
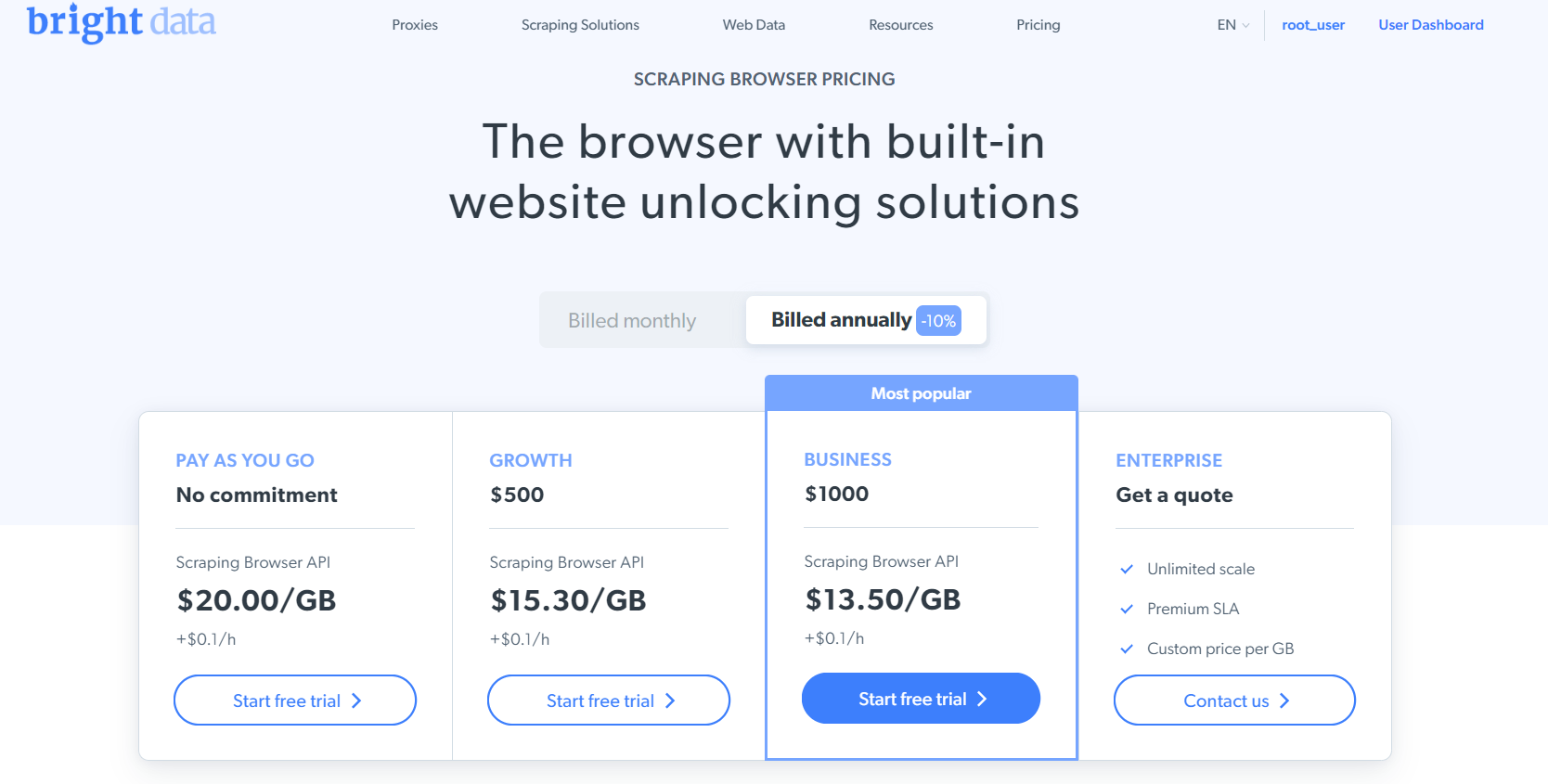
定价
2. 八度分析
Octoparse 是一个理想的基于浏览器的工具,专为网络抓取而创建。 即使没有编码技能的人也可以使用它获得流畅的抓取体验。
您可以使用其用户友好的可视化抓取工具轻松地从网站收集数据。 无需学习复杂的编码或脚本语言。 通过让您直接与网站互动并选择您想要提取的数据片段,Octoparse 简化了该过程。
这类似于获得一只虚拟手来帮助您搜索网络并找到您想要的信息。 然而,Octoparse 做的不仅仅是提取数据。 它还具有出色的数据转换和清理功能。
抓取数据后,Octoparse 使您能够根据您的独特需求对其进行格式化和增强。 为了使数据更有价值和可操作,您可以清理混乱的数据,消除重复,甚至进行复杂的转换。
借助 Octoparse,您能够管理数据生命周期的每个阶段,包括提取、清理和转换,所有这些都使用基于浏览器的简单界面。 无需技术知识,您就可以使用 Octoparse 进入网络抓取的世界,发现无价的见解并利用数据的力量。
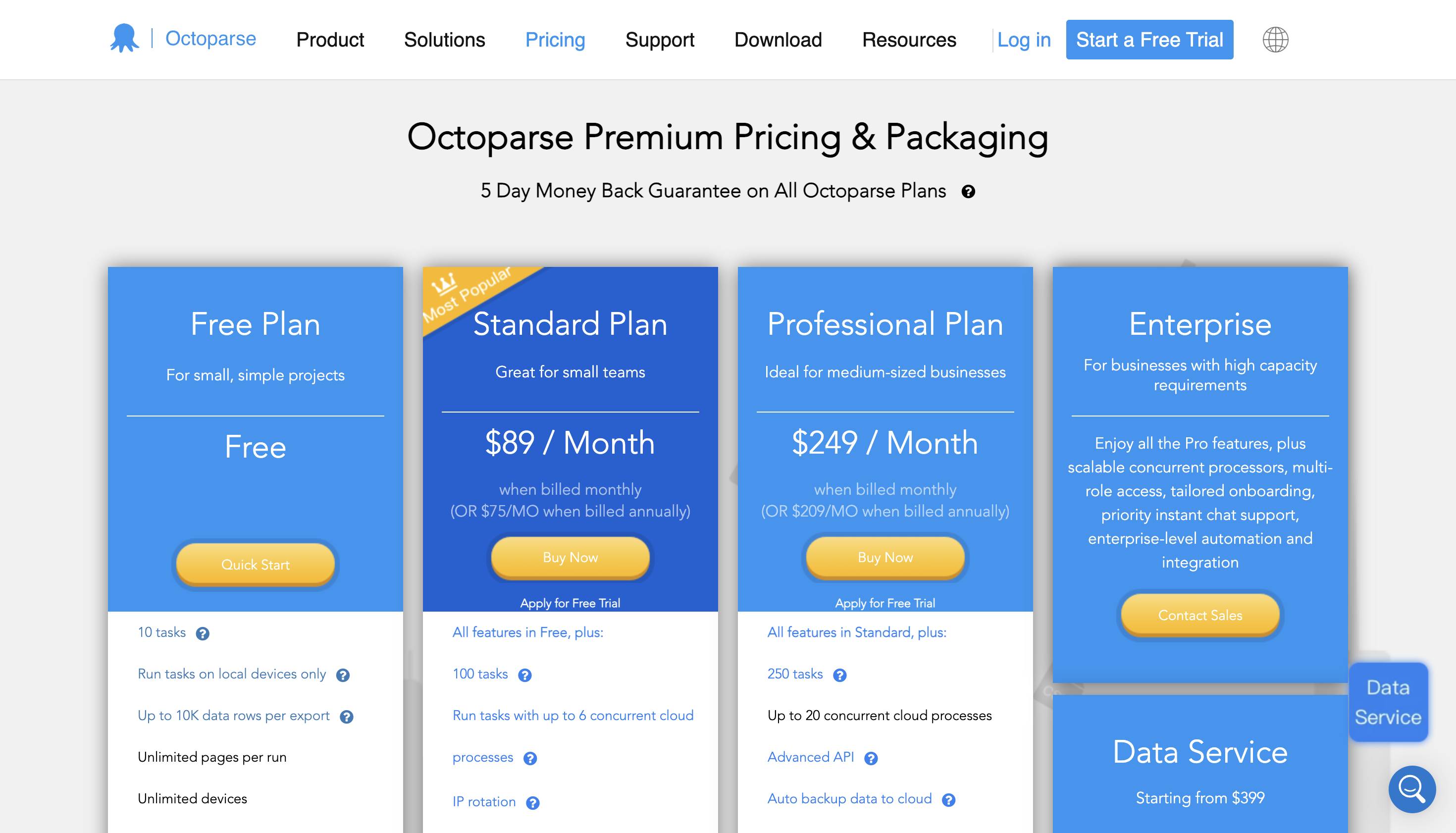
定价
您可以开始免费使用它,高级定价从每月 89 美元起。
3. 解析中心
ParseHub 是一个可以满足您所有抓取需求的平台,并且非常灵活且用户友好。 无论您是新手还是专家数据爱好者,ParseHub 都能满足您的需求。 ParseHub 的独特之处在于其简单的点击界面,这使得从动态网站收集数据的过程变得更加容易。
无需成为专家编码人员即可浏览复杂的网页。 要提取数据,只需选择所需的数据,ParseHub 将处理其余部分。 这就像拥有您自己的个人数据提取助手。 但是 ParseHub 提供了更复杂的选项,可以将您的抓取提升到一个新的水平。
您可以通过使用计划的抓取来自动执行抓取过程,这使 ParseHub 能够以预定的时间间隔检索数据,确保您始终拥有最新的信息。
此外,ParseHub 提供无缝的 API 连接,使您可以轻松地将抓取的数据合并到您自己的程序或系统中。 这是一种有效的技术,可以优化您提取的数据的使用并改善您的数据工作流程。
借助 ParseHub 的用户友好界面和强大的功能,Web 抓取成为一个有趣且有效的过程,可以轻松地从动态网页中揭示有用的见解。
定价
您可以开始免费使用它,高级定价从每月 189 美元起。
4. Webz.io
Webz.io – Big Web Data 是一项卓越的基于浏览器的技术,专注于提取和监控网络数据。 通过使用 Webz.io,您可以轻松地在线获取有洞察力的数据,以随时掌握网络的脉搏。 这个平台是一个信息金矿,提供关于各种主题的新闻故事、博客文章和在线对话的深入报道。
Webz.io 确保您可以访问来自整个网络的最新和相关信息,无论您的业务或专业知识如何。 这相当于可以访问一个大型知识库。 然而,Webz.io 不仅仅局限于数据覆盖范围。
此外,它还提供流畅的 API 连接,使您可以轻松地将提取的数据合并到您自己的程序或系统中。 有了这种能力,就有无数机会以最能满足您需求的方式使用数据。
Webz.io API 连接简化了数据集成过程,无论您是创建自定义仪表板、执行市场研究还是创建 AI 驱动的解决方案。
Webz.io – 大在线数据的用户友好界面和强大的数据监控和提取功能使您能够保持领先地位,并最大程度地利用在线数据进行公司或研究工作。
定价
请联系供应商了解其定价。
5. 导入
Import.io 是一个非常棒的基于浏览器的工具,它具有简单的点击界面,消除了在线抓取的困难。 无论您的数据专业知识水平如何,使用 import.io 进行网络抓取都很简单。 只需点击几下,无需任何技术经验,您就可以轻松地从网站中提取数据。
就像拥有了一根魔杖,可以从庞大的网络中收集到你想要的数据。 但 import.io 不止于此。 凭借其先进的爬行技术,它超越了一切。
Import.io 现在可以发现 数据结构 和网页上的模式,这提高了互联网抓取过程的效率和准确性。 这就像拥有一个熟悉网站布局的数据侦探,可以快速轻松地收集到合适的数据。
由于 import.io 广泛的数据集成功能,抓取的数据还可以导出为各种格式和程序。 Import.io 可以提供您需要的 CSV、Excel 或 JSON 格式的数据。 检索到的数据可以简单地合并到您的数据库、分析程序甚至商业应用程序中。
import.io 使 Web 抓取变得简单,使您能够获得有洞察力的信息并优化数据驱动的操作。
定价
您可以使用该平台的 14 天免费试用期,高级定价从每月 199 美元起。
6. 德西
Dexi.io 是一个创新的平台,可以在浏览器中使用,并提供全方位的网络抓取选项。 凭借其简单的可视化编辑器和点击式用户界面,Dexi.io 使各种技术经验水平的用户都可以访问网络抓取。 要掌握网络抓取的复杂性,您不需要成为编码天才。
Dexi.io 使构建能够快速准确地从网页中抓取数据的抓取机器人变得简单。 这类似于拥有一个虚拟助手来处理所有繁重的任务。

Dexi.io 超越了简单的数据提取。 数据丰富是其更复杂的功能之一,使您能够通过添加来自其他来源的更多详细信息来改进检索到的数据。 因此,您的分析将更有洞察力和更完整。
此外,您可以使用各种格式导出使用 Dexi.io 抓取的数据,包括 CSV、Excel 或 JSON。 Dexi.io 使您可以轻松获取集成到其他系统或进行进一步深入研究所需的数据。
Dexi.io 进一步提供 API 连接,使您能够快速连接到已抓取的数据并将其合并到您自己的软件或系统中。 您可以自动化程序并最大限度地利用检索到的数据,因为它提供了一个流畅的工作流程。
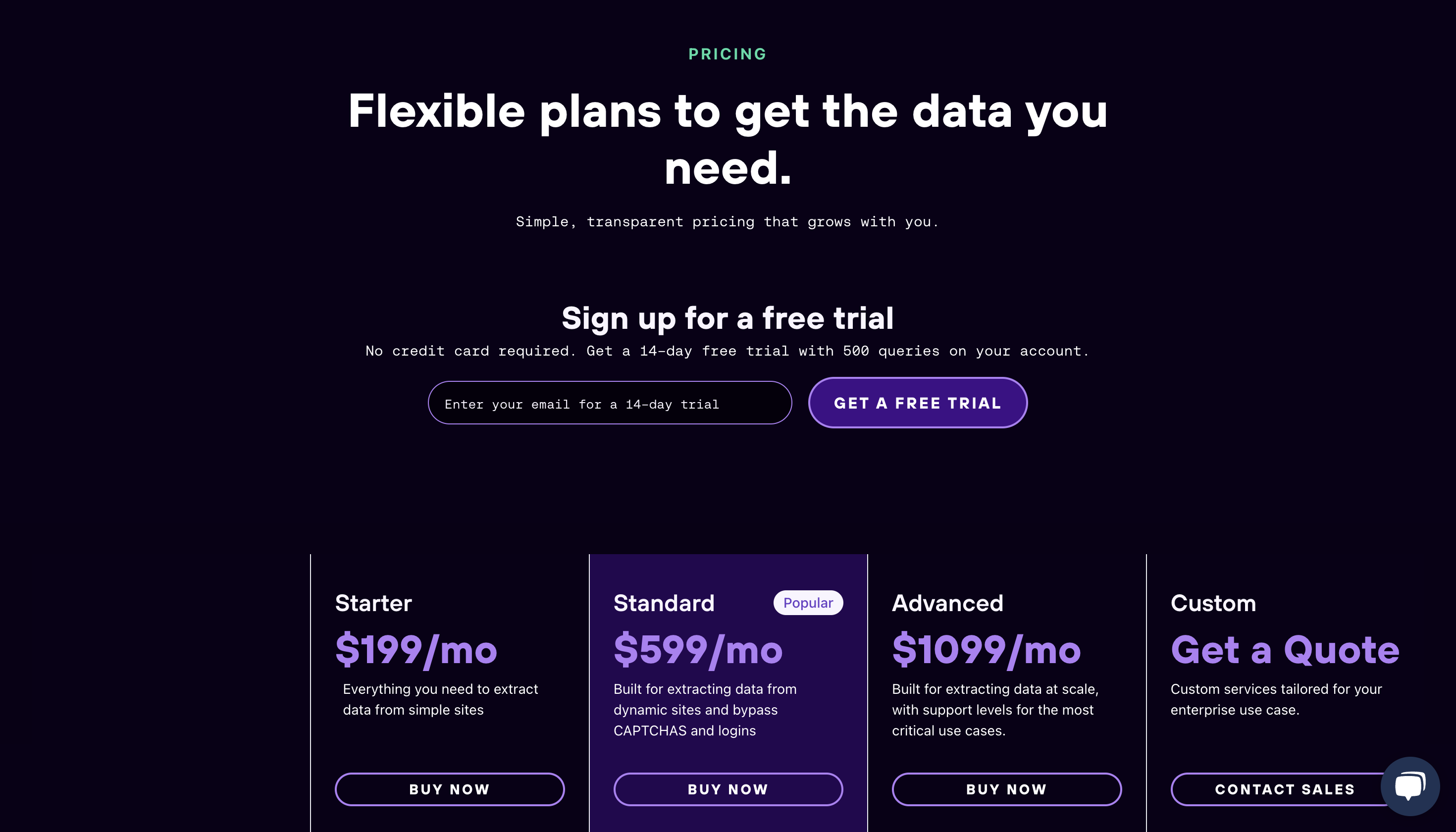
定价
您可以通过其免费试用计划试用该平台,请联系供应商了解其溢价。
7. 蒙曾达
Mozenda 是一流的网络抓取工具,提供自动化和基于浏览器的抓取选项。 Mozenda 的用户友好界面和强大的功能使从网站提取数据的过程更加简单。
利用其点击式用户界面,Mozenda 使跨网站导航变得简单。 没有编码知识? 没什么大不了。 无论您需要客户评论、产品详细信息还是任何其他数据,Mozenda 都能让您快速选择要提取的数据项。
这就像有一个了解您的抓取要求的虚拟助手。 Mozenda 并不止于此。 由于调度是其更复杂的功能之一,您可以自动执行抓取过程并在特定时间间隔提取数据。
无论您需要每天、每周还是每月更新,Mozenda 都能满足您的需求。 此外,Mozenda 提供无缝数据导出选项,让您可以将抓取的数据保存为多种文件类型,包括 Excel、CSV 或 XML。 检索到的数据可以很容易地包含在您的分析程序或数据库中。
借助 Mozenda 的 API 集成服务,抓取的数据可以额外连接并集成到您自己的应用程序或系统中。 它提供了一个高效的工作流程,使您能够自动化程序并最大限度地利用检索到的数据。
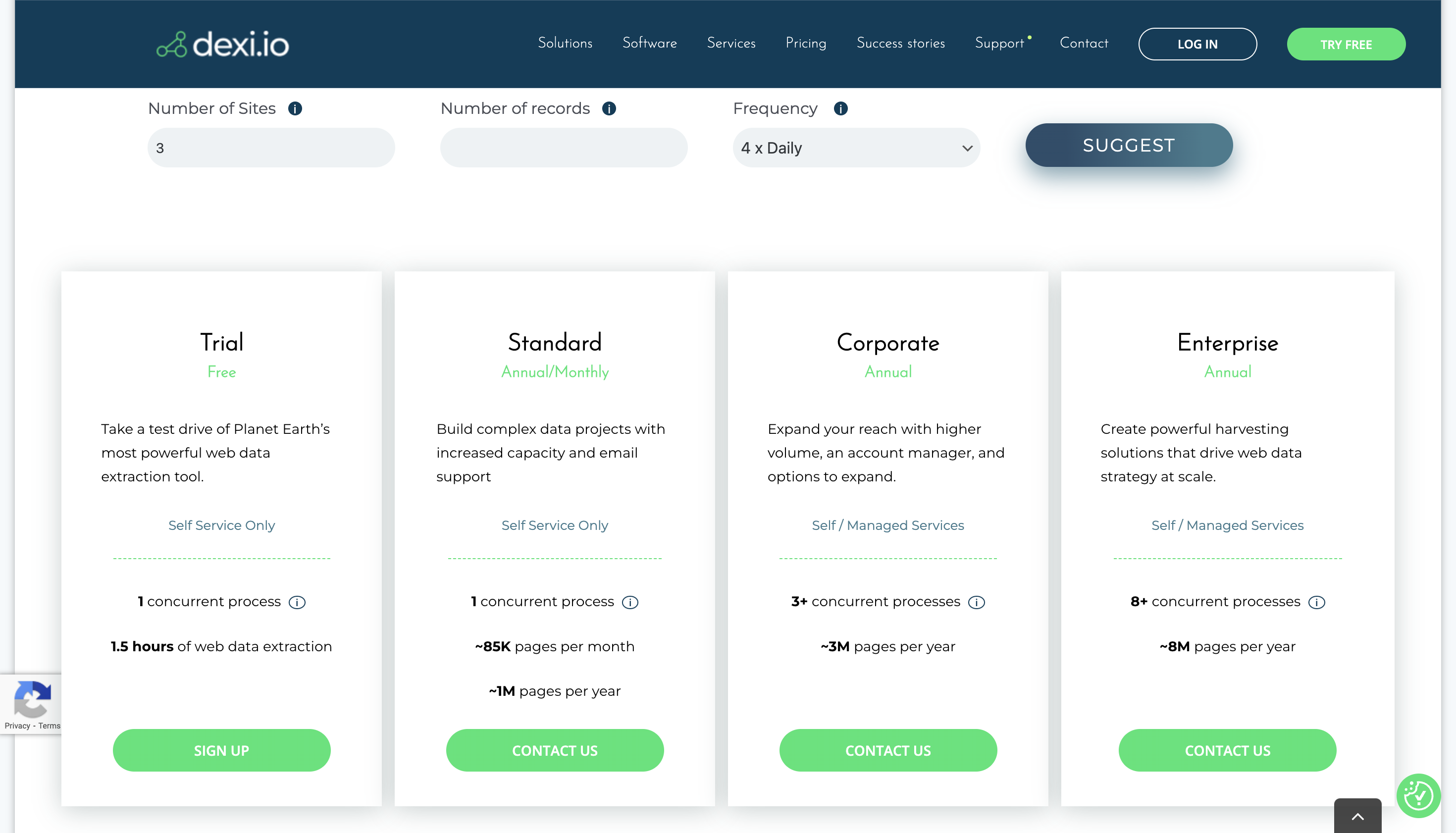
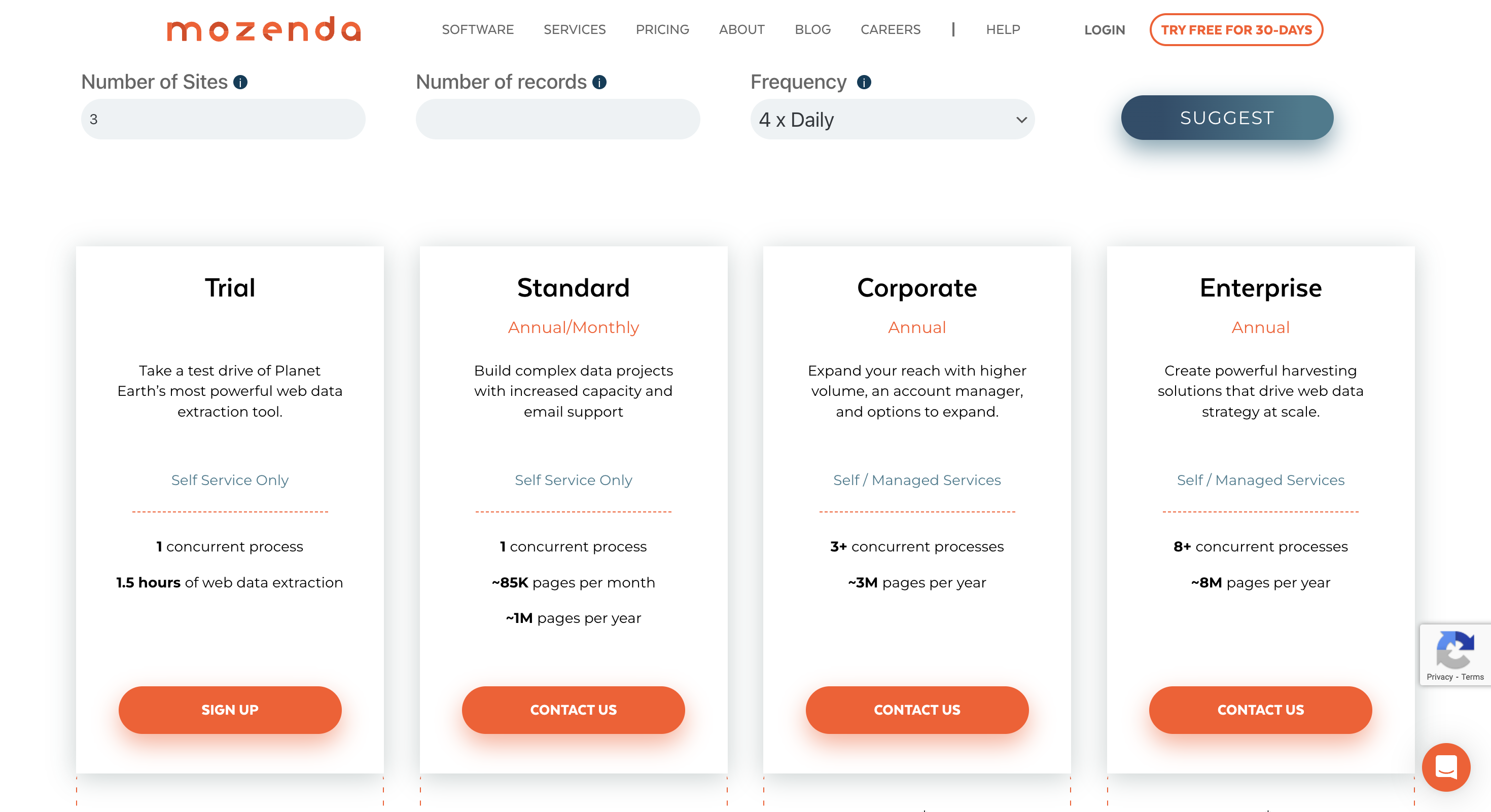
定价
您可以通过其免费试用计划试用该平台,请联系供应商了解其溢价。
8. 刮蜂
使用 ScrapingBee 从网站收集数据要容易得多,ScrapingBee 是一个很棒的基于浏览器的网络抓取应用程序。 使用 ScrapingBee 的网页抓取功能,避免基础设施管理的负担。
借助其直观的 API,您可以轻松提交查询并获取已抓取的数据。 ScrapingBee API 可以轻松提取任何类型的数据,包括产品信息、新闻文章和其他类型。
尽管如此,ScrapingBee 更进一步。 它具有超越简单网络抓取的功能。 它具有 JavaScript 呈现功能,可让您从主要依赖 JavaScript 进行内容呈现的网站中抓取信息。 这确保即使是动态网页,您也可以进入并检索全部内容。
此外,ScrapingBee 会为您处理验证码,让您免去克服这些恼人障碍的耗时工作。
它会自动解析验证码,因此您可以专注于获取所需的信息。 此外,ScrapingBee 还提供 IP 旋转器,以确保您的抓取操作的私密性和不受网站封锁。 它会更改 IP 地址,使网站难以监控您并施加访问限制。
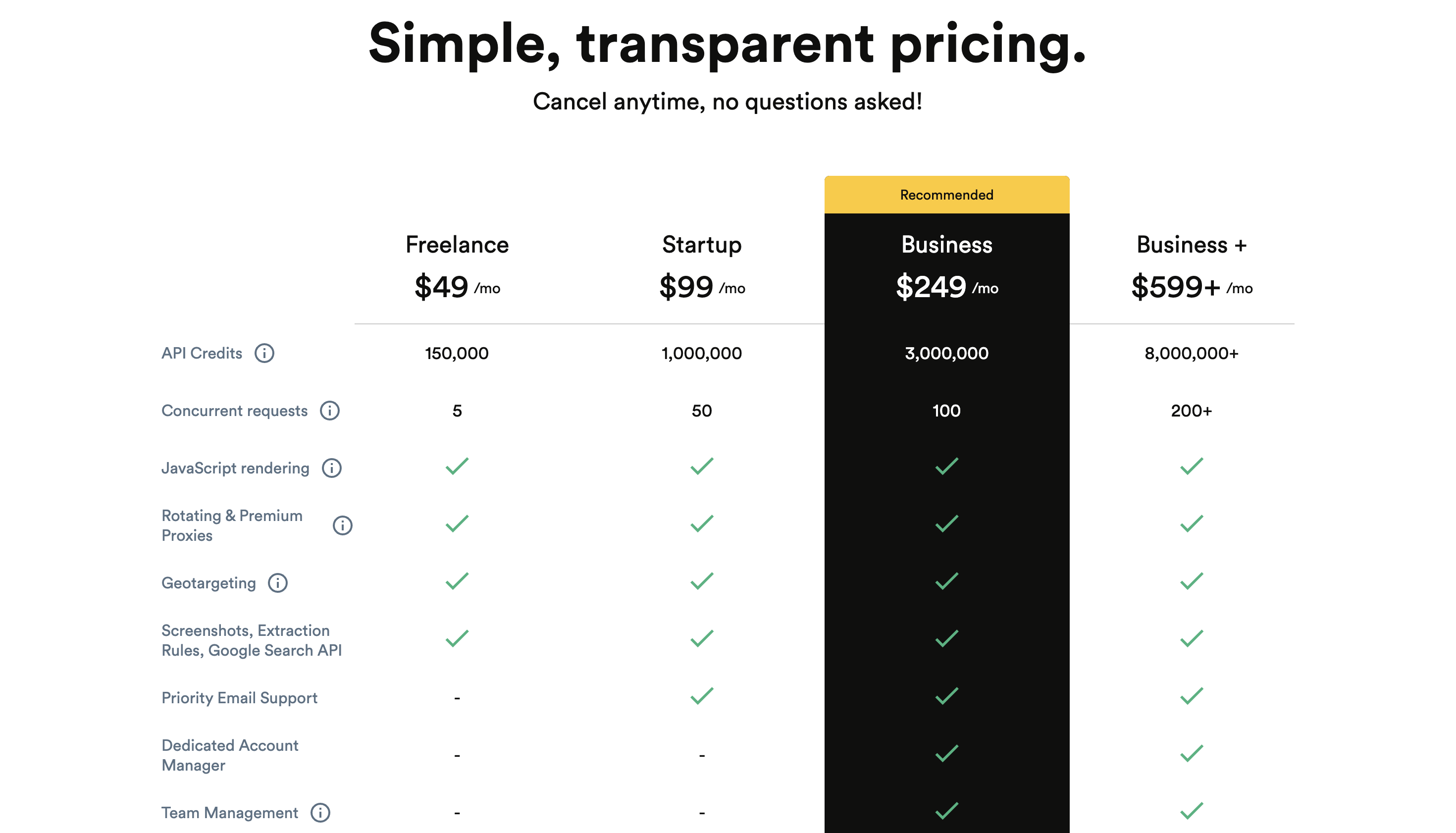
定价
溢价定价从 49 美元/月起。
9. 阿皮菲
Apify 是一个强大的基于云的平台,可以在浏览器中使用,并具有网络抓取和自动化功能。 使用 Apify 将使您能够轻松地自动化耗时的程序并快速从网站中提取数据,让您有更多时间进行其他重要工作。
无需任何代码,可以使用 Apify 的可视化编辑器快速创建复杂的抓取情况。 该网站使用简单,具有拖放式界面,可以直接选择您需要抓取的数据。
在 Apify 的架构上,您的抓取作业可以作为无服务器服务进行设置和执行。 基础架构和服务器维护将不再是您关心的问题。
Apify 会处理一切。 但是,如果您不是特别擅长抓取怎么办? 毫无疑问没有问题。 可以在 Apify 市场上购买预构建的抓取 actor,这些 actor 基本上是配置好且随时可用的抓取流程。
对于一系列网站和用例,例如 社交网络平台 和电子商务网站,市场提供数百名参与者。 因此,您可以利用现成的解决方案,这将节省您的时间和精力。
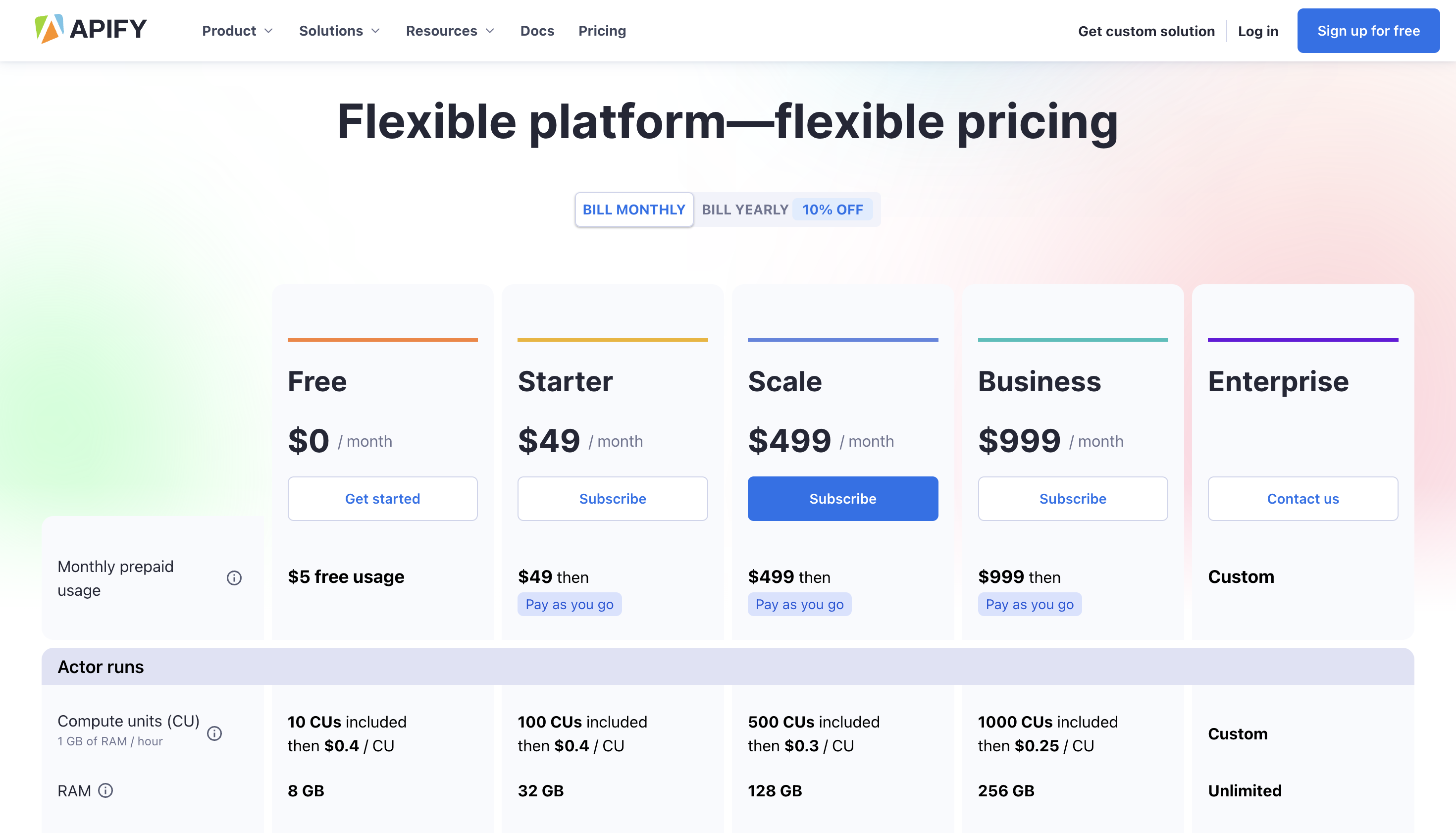
定价
您可以开始免费使用它,高级定价从每月 49 美元起。
10. 刮痧狗
Scrapingdog 是一款功能强大的基于浏览器的网页抓取软件。 无需复杂的代码或基础设施设置,您就可以使用 Scrapingdog 快速有效地从网站收集数据。 这就像拥有一个强大的刮刀供您使用。
Scrapingdog 使网络抓取变得简单的关键功能使其在竞争对手中脱颖而出。 第一个好处是它提供了一个用户友好的界面,使浏览网站和选择需要提取的数据变得简单。
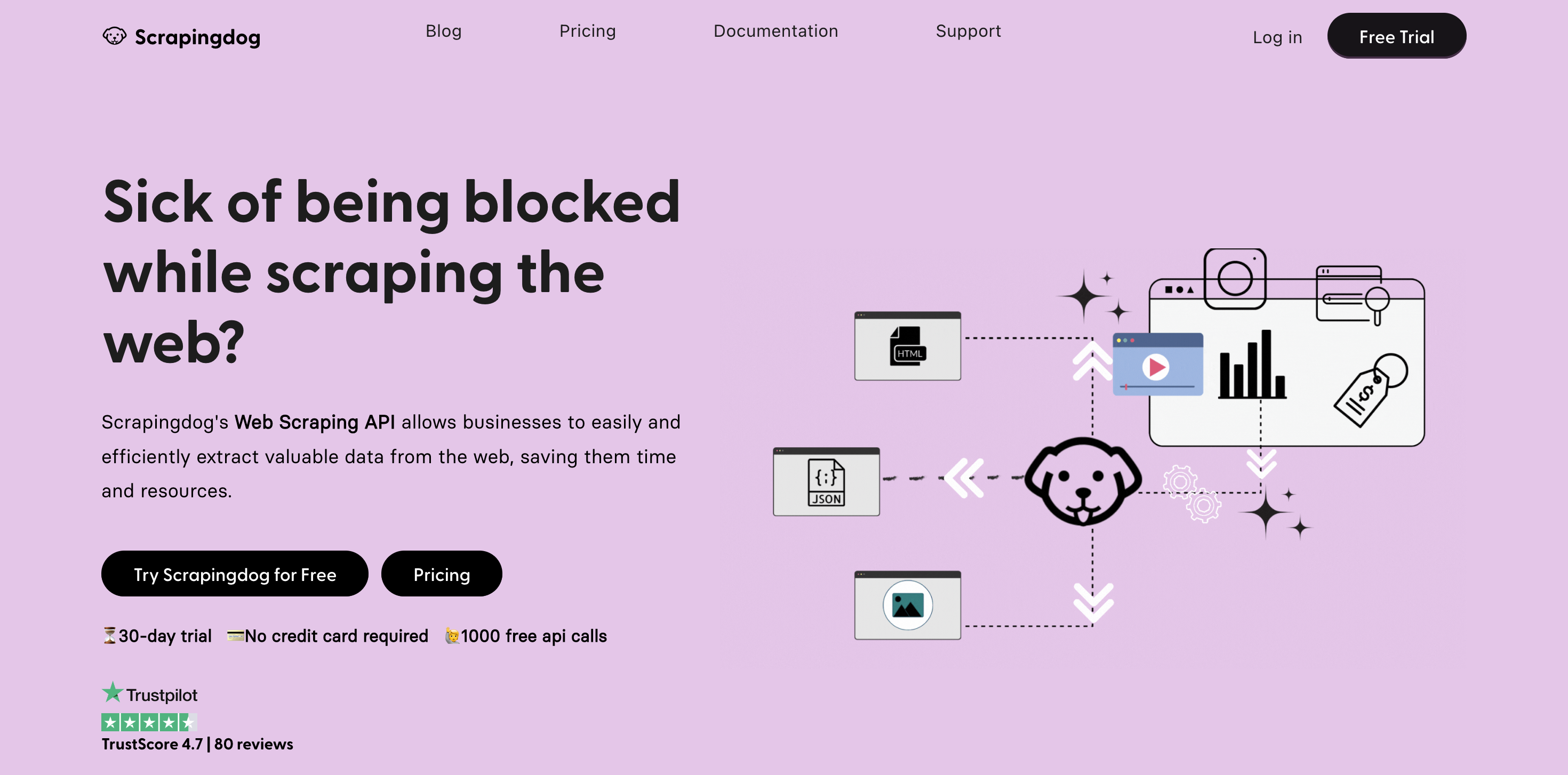
无论您需要抓取什么信息——产品信息、新闻报道或其他任何东西——Scrapingdog 都能满足您的要求。 其次,Scrapingdog 提供了巧妙的 JavaScript 呈现,允许您从主要依赖 JavaScript 显示内容的网站上抓取信息。
这确保即使从动态网页,您也可以访问和检索全部内容。 此外,Scrapingdog 还提供 CAPTCHA 处理,为您解决那些恼人的障碍。
它会自动回答验证码,为您节省时间和精力。 此外,Scrapingdog 使用 IP 轮换,这涉及更改 IP 地址,以避免网站阻止您的抓取操作。 因此,抓取将顺利进行。
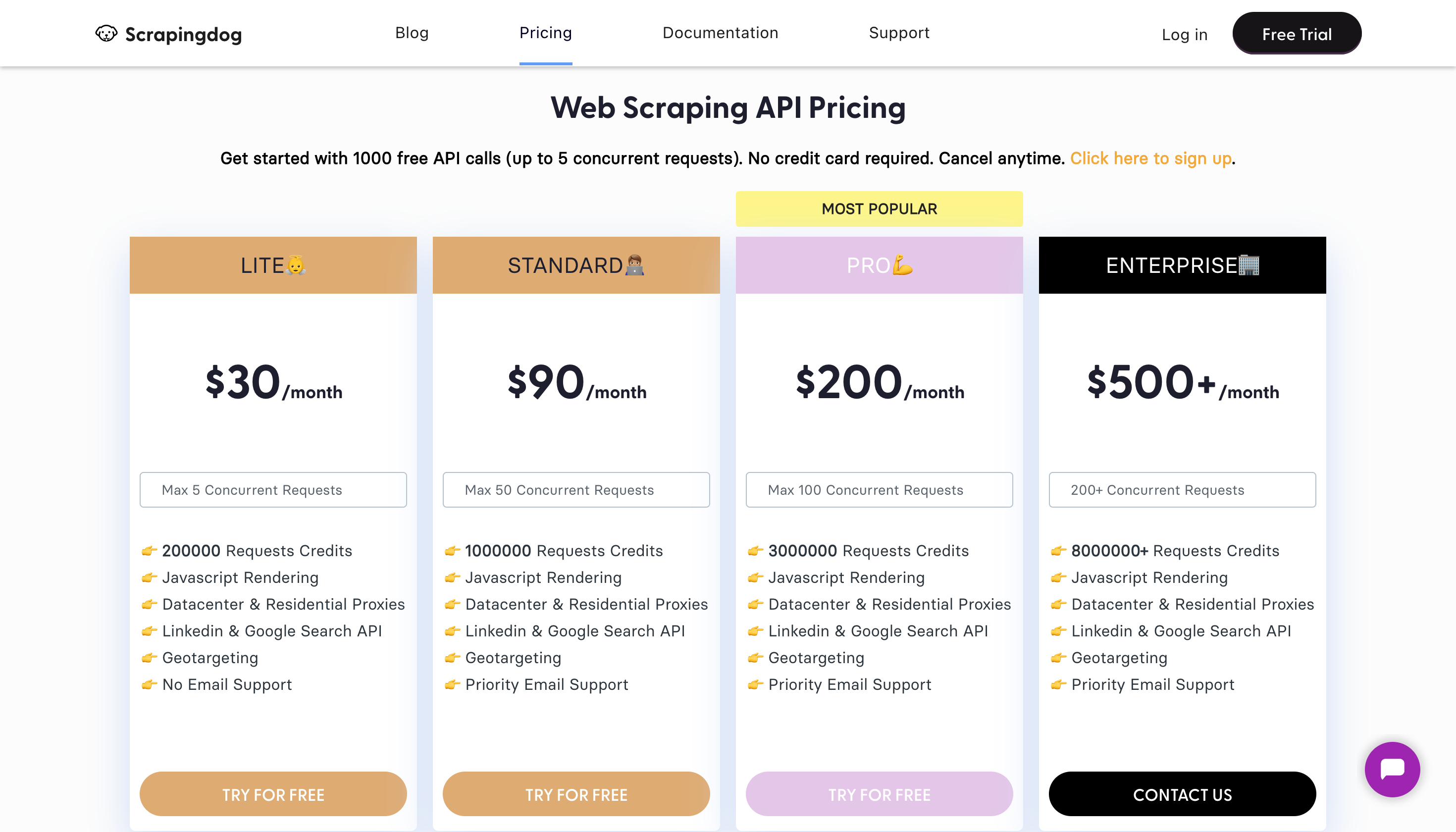
定价
溢价定价从 30 美元/月起。
11. 字节线
Byteline 是一款出色的基于浏览器的工具,专为网络抓取而创建。 无需冗长的脚本或复杂的设置,您可以使用 Byteline 快速轻松地从网站中提取数据。
它提供了一个用户友好的界面,使您可以轻松浏览网站并选择要抓取的数据。 Byteline 可以帮助您获取任何类型的数据,包括价格明细、客户评价和其他信息。
它可以轻松处理动态网页。 您可以从很大程度上依赖动态内容的网站中提取数据,因为它借助复杂的方法处理 JavaScript 呈现。 这意味着您可以获取并抓取最新的可访问数据。
此外,Byteline 具有强大的代理和 IP 轮换功能,可让您广泛抓取而不会与任何过滤器发生冲突。 它确保您的抓取操作继续不受阻碍且完全匿名。 此外,Byteline 还提供数据导出选项,让您可以将检索到的数据保存为 CSV 或 Excel 等其他格式,以便进行额外分析或系统集成。
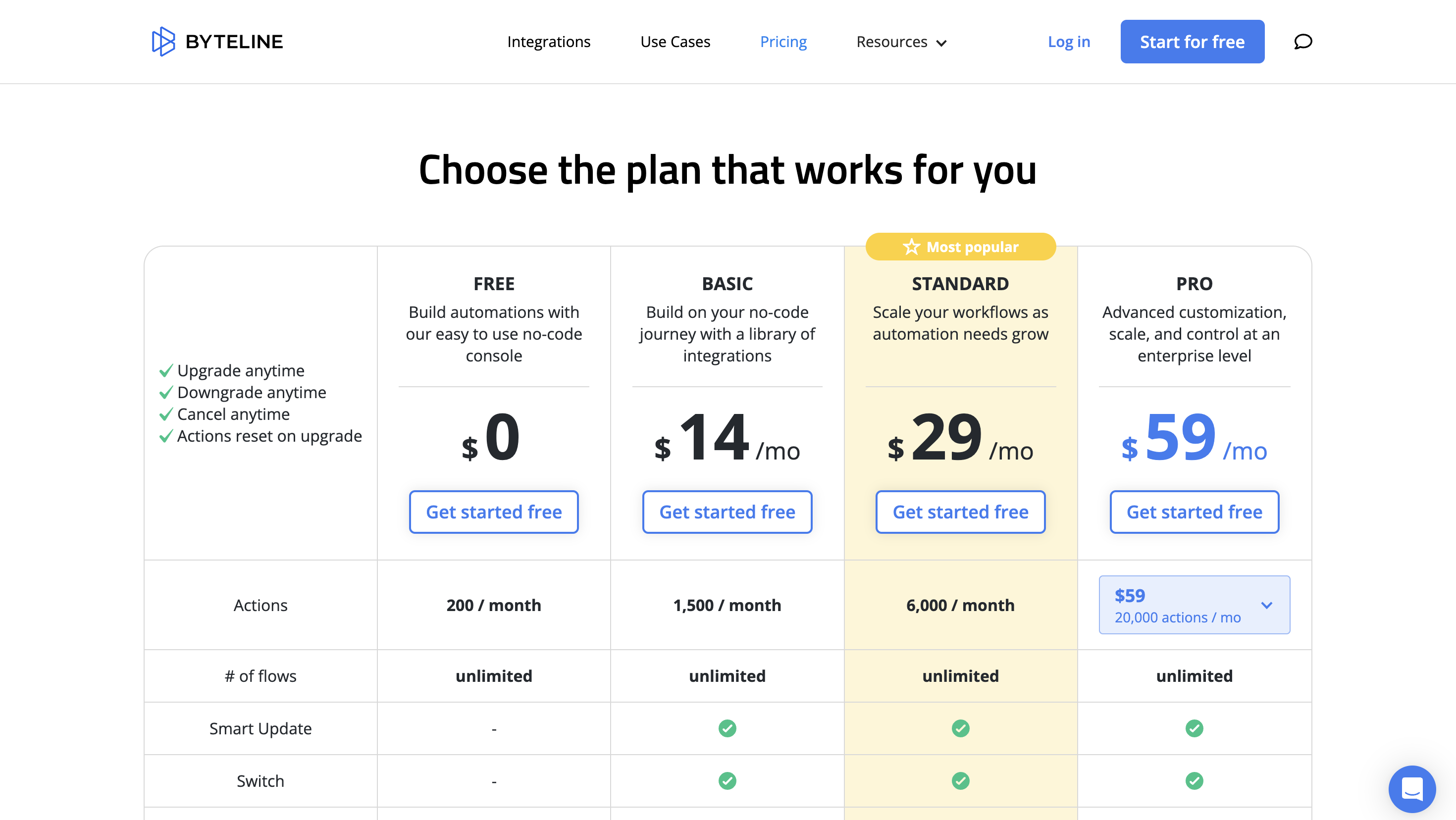
定价
您可以开始免费使用它,高级定价从每月 14 美元起。
12. 格雷普斯
Grepsr 是一款出色的网络抓取软件,可在浏览器内运行。 Grepsr 对公司和研究人员来说都是一个有用的工具,因为它使您能够高效、轻松地从网站中提取数据。
使用 Grepsr 时,您不必担心复杂的代码或基础设施设置。 您可以通过互联网连接从任何位置访问和管理您的抓取项目,因为它具有基于云的设计。
它利用复杂的在线抓取技术,例如智能数据识别和解析算法,以确保精确可靠的数据提取。 Grepsr 还具有调度功能,使您能够自动执行抓取过程并以预定的时间间隔获取更新的数据。
此外,还支持 CSV、Excel、JSON 和 XML 等多种数据导出格式,让您可以自由地使用所选格式的数据。
您甚至可以从最动态的网站上抓取数据,因为它是为处理复杂的网页而构建的,包括那些具有基于 JavaScript 的内容呈现的网页。
定价
请联系供应商了解其定价。
13. 专业网页抓取工具
ProWebScraper 是一种用户友好的基于浏览器的网络抓取技术,使用户能够快速、简单地从网站中提取数据。 用户可以使用其点击式界面提取数据,而无需编写任何代码。
此外,该平台还有一个智能数据提取工具,可以从复杂的网站中识别和提取数据。 ProWebScraper 还为需要复杂数据提取的网站提供定制的抓取工具。 从需要登录的网站中提取数据是 ProWebScraper 的强项。
输入登录信息后,个人可以使用该平台从他们有权访问的任何页面上抓取数据。 ProWebScraper 还提供了计划和自动化抓取的能力,以及多种导出选择,包括 CSV、Excel 和 JSON 格式。
ProWebScraper 使用网络爬虫从网站上抓取信息。 爬虫可以跨多个页面导航并可以处理复杂的网站。 ProWebScraper进一步支持 代理服务器,允许用户秘密抓取数据并绕过 IP 限制。 该软件还提供自动数据验证以确保提取数据的准确性。
定价
您可以开始免费使用它,40 个积分的高级定价从 5000 美元起。
14. 抓取 API
Scraping API 平台是一个出色的基于浏览器的解决方案,专为满足网络抓取需求而设计。 得益于其用户友好的 UI,您可以使用 Scraping API 快速简单地从网站中提取数据。
无论您是新手还是网络爬虫专家,Scraping API 都能满足您的需求。 在现代网络浏览器引擎的帮助下,它使用无头浏览器技术来呈现网站、运行 JavaScript 并获取所需的数据。 因此,即使在材料不断变化的复杂网站上,也能保证精确可靠的抓取结果。
此外,您可以通过 Scraping API 使用您最喜欢的编码技能,因为它支持多种编程语言,例如 Python、JavaScript 和 PHP。
得益于其强大的功能(包括分页处理、表单提交和会话管理),您可以像真正的用户一样浏览网站并与之交互。 此外,Scraping API 提供无缝的代理轮换,使您能够大规模地抓取网页,同时隐藏您的 IP 地址并避免任何禁令。
为了保证准确的数据提取,该平台还提供了强大的错误管理和重试选项。 通过使用抓取 API,您可以毫不费力地将多种形式的数据(例如 HTML、JSON 和 XML)合并到您的应用程序或数据库中。
定价
溢价定价从 49 美元/月起。
15. 合特
Zyte 是一个基于浏览器的平台,专为网络抓取而设计。 由于其用户友好的界面,用户可以快速浏览网站并检索有用的数据,这消除了复杂编码或基础设施设置的需要。
该平台采用无头浏览器策略,并利用当前的网络浏览器引擎来呈现网页、运行 JavaScript 并从动态内容中提取数据。 这提供了精确和彻底的抓取结果,即使是从复杂的网站。
此外,Zyte 还提供多种功能,例如复杂的数据验证、智能数据提取和强大的错误处理方法,以改进抓取过程。
此外,Zyte 支持多种代码语言,包括 Python、JavaScript 和 Ruby,因此用户可以发挥自己喜欢的编程技能。
您无需管理服务器或担心 Zyte 的可扩展性,因为您可以利用他们的云基础设施轻松管理和发展您的抓取项目。
此外,Zyte 具有内置的代理管理功能,使用户能够通过各种代理来引导他们的请求,以保持匿名并避免 IP 禁令。 它还提供与各种数据存储格式和系统(包括数据库和 API)的无缝交互,使存储和处理收集的数据变得简单。
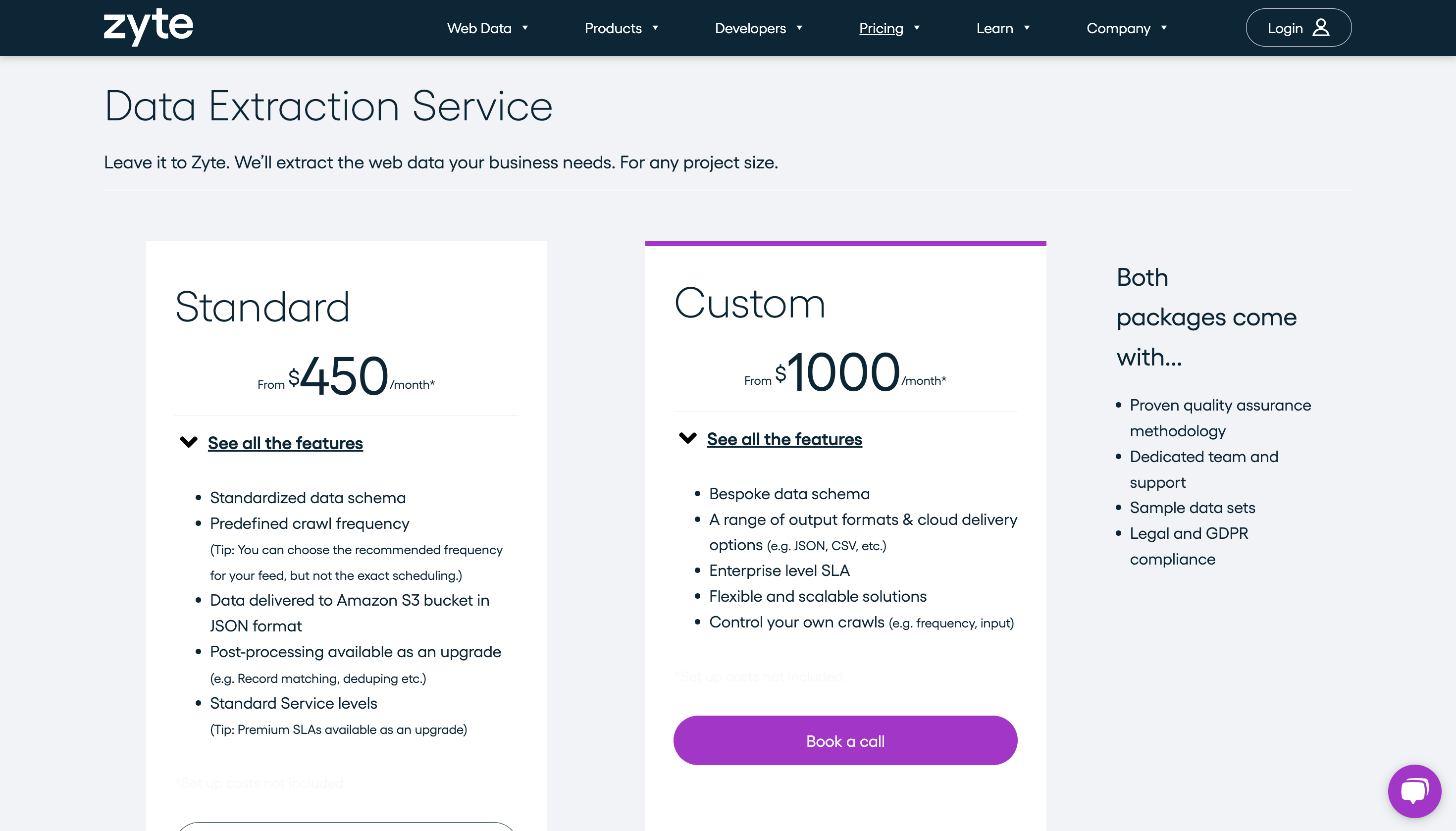
定价
溢价定价从 450 美元/月起。
结论
总之,释放在线抓取的潜力并产生数据驱动的见解取决于选择适合您独特需求的合适的网络抓取平台。 有这么多可供选择的选择,考虑可用性、数据提取能力、API 集成等方面至关重要。
Bright Data 是一个脱颖而出的平台,因为它具有强大的代理网络、直观的用户界面和包括自动数据提取、数据验证和反封锁方法在内的尖端功能。 企业可以使用 Bright Data 轻松访问大量在线数据,并利用它在市场上获得竞争优势。
因此,如果您正在寻找完整且可靠的网络抓取解决方案,请务必查看 Bright Data 并了解它如何帮助您实现数据目标。





发表评论