Đó là một nhiệm vụ quan trọng và mong muốn trong thị giác máy tính và đồ họa để tạo ra những bộ phim chân dung sáng tạo ở tầm cỡ cao nhất.
Mặc dù một số mô hình hiệu quả cho việc phóng đại hình ảnh chân dung dựa trên StyleGAN mạnh mẽ đã được đề xuất, nhưng các kỹ thuật hướng hình ảnh này có những nhược điểm rõ ràng khi được sử dụng với video, chẳng hạn như kích thước khung hình cố định, yêu cầu căn chỉnh khuôn mặt, thiếu các chi tiết không phải khuôn mặt , và sự không nhất quán theo thời gian.
Một khung VToonify mang tính cách mạng được sử dụng để giải quyết việc chuyển kiểu video chân dung có độ phân giải cao được kiểm soát khó khăn.
Chúng tôi sẽ xem xét nghiên cứu gần đây nhất về VToonify trong bài viết này, bao gồm chức năng, nhược điểm và các yếu tố khác của nó.
Vtoonify là gì?
Khung VToonify cho phép truyền kiểu video chân dung có độ phân giải cao có thể tùy chỉnh.
VToonify sử dụng các lớp có độ phân giải trung bình và cao của StyleGAN để tạo ra các bức chân dung nghệ thuật chất lượng cao dựa trên các đặc điểm nội dung đa tỷ lệ được bộ mã hóa truy xuất để giữ lại chi tiết khung hình.
Kết quả là kiến trúc phức hợp hoàn toàn lấy các khuôn mặt không thẳng hàng trong phim có kích thước thay đổi làm đầu vào, dẫn đến các vùng toàn khuôn mặt có các chuyển động chân thực trong đầu ra.

Khung này tương thích với các mô hình hiển thị quá mức hình ảnh dựa trên StyleGAN hiện tại, cho phép chúng được mở rộng thành quá mức video và kế thừa các đặc điểm hấp dẫn như tùy chỉnh màu sắc và cường độ có thể điều chỉnh.
T nghiên cứu giới thiệu hai phiên bản VToonify dựa trên Toonify và DualStyleGAN để chuyển kiểu video chân dung dựa trên bộ sưu tập và dựa trên mẫu tương ứng.
Các phát hiện thử nghiệm mở rộng cho thấy rằng khung VToonify được đề xuất làm tốt hơn các phương pháp hiện có trong việc tạo phim chân dung nghệ thuật có chất lượng cao, mạch lạc theo thời gian với các thông số kiểu thay đổi.
Các nhà nghiên cứu cung cấp Sổ ghi chép Google Colab, vì vậy bạn có thể bị bẩn tay vào nó.
Học như thế nào?
Để thực hiện chuyển kiểu video chân dung có độ phân giải cao có thể điều chỉnh, VToonify kết hợp các ưu điểm của khung dịch hình ảnh với khung dựa trên StyleGAN.
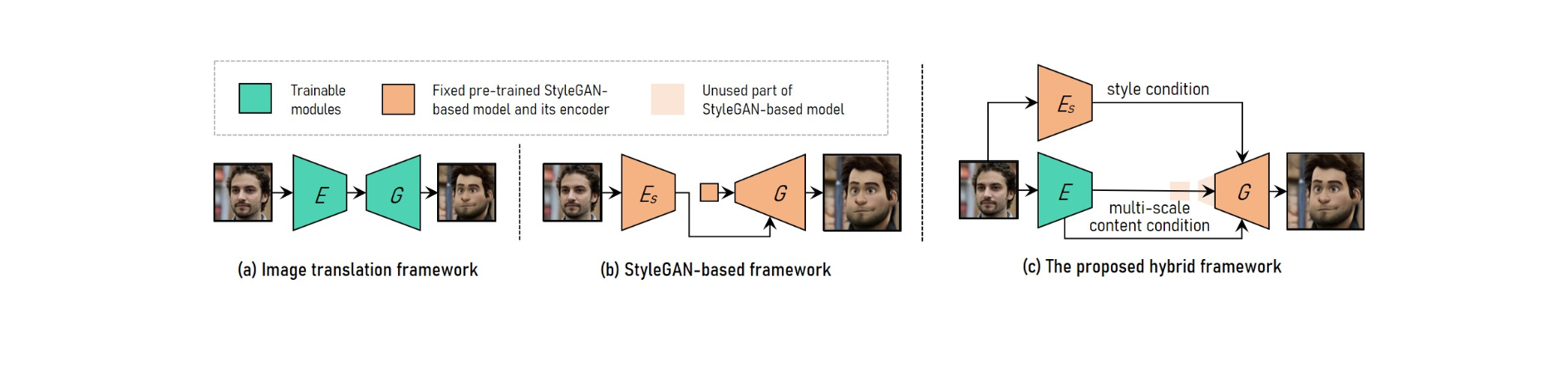
Để phù hợp với các kích thước đầu vào khác nhau, hệ thống dịch hình ảnh sử dụng các mạng tích hợp đầy đủ. Mặt khác, đào tạo từ đầu khiến cho việc truyền kiểu có độ phân giải cao và được kiểm soát là không thể.
Mô hình StyleGAN được đào tạo trước được sử dụng trong khuôn khổ dựa trên StyleGAN để truyền kiểu có độ phân giải cao và được kiểm soát, mặc dù nó bị giới hạn ở kích thước hình ảnh cố định và tổn thất chi tiết.
StyleGAN được sửa đổi trong khuôn khổ kết hợp bằng cách xóa tính năng đầu vào có kích thước cố định và các lớp có độ phân giải thấp, dẫn đến kiến trúc bộ tạo bộ mã hóa tích hợp hoàn toàn tương tự như của khung dịch hình ảnh.
Để duy trì các chi tiết của khung, hãy đào tạo một bộ mã hóa để trích xuất các đặc điểm nội dung đa tỷ lệ của khung đầu vào như một yêu cầu nội dung bổ sung cho trình tạo. Vtoonify kế thừa tính linh hoạt điều khiển kiểu của mô hình StyleGAN bằng cách đưa nó vào trình tạo để chắt lọc cả dữ liệu và mô hình của nó.
Hạn chế của StyleGAN & Vtoonify được đề xuất
Tranh chân dung nghệ thuật rất phổ biến trong cuộc sống hàng ngày của chúng ta cũng như trong các lĩnh vực kinh doanh sáng tạo như nghệ thuật, truyền thông xã hội hình đại diện, phim, quảng cáo giải trí, v.v.
Với sự phát triển của học kĩ càng công nghệ, giờ đây có thể tạo ra những bức chân dung nghệ thuật chất lượng cao từ những bức ảnh khuôn mặt ngoài đời thực bằng cách sử dụng tính năng chuyển kiểu chân dung tự động.
Có nhiều cách thành công được tạo ra để chuyển kiểu dựa trên hình ảnh, nhiều cách trong số đó có thể dễ dàng truy cập cho người dùng mới bắt đầu dưới dạng ứng dụng di động. Tài liệu video đã nhanh chóng trở thành nguồn cấp dữ liệu chính trên mạng xã hội của chúng tôi trong vài năm qua.
Sự gia tăng của mạng xã hội và các bộ phim phù du đã làm tăng nhu cầu chỉnh sửa video sáng tạo, chẳng hạn như chuyển kiểu video chân dung, để tạo ra các video thành công và thú vị.
Các kỹ thuật hướng hình ảnh hiện tại có những nhược điểm đáng kể khi áp dụng cho phim, hạn chế tính hữu dụng của chúng trong việc cách điệu video chân dung tự động.
StyleGAN là xương sống chung để phát triển mô hình chuyển kiểu ảnh chân dung nhờ khả năng tạo khuôn mặt chất lượng cao với khả năng quản lý kiểu dáng có thể điều chỉnh.
Hệ thống dựa trên StyleGAN (còn được gọi là quá rõ hình ảnh) mã hóa một khuôn mặt thực vào không gian tiềm ẩn StyleGAN và sau đó áp dụng mã kiểu kết quả cho một StyleGAN khác đã được tinh chỉnh trên tập dữ liệu chân dung nghệ thuật để tạo ra một phiên bản cách điệu.
StyleGAN tạo ảnh với các khuôn mặt được căn chỉnh và ở kích thước cố định, không ưu tiên các khuôn mặt động trong cảnh quay trong thế giới thực. Việc cắt và căn chỉnh khuôn mặt trong video đôi khi dẫn đến một phần khuôn mặt và cử chỉ khó xử. Các nhà nghiên cứu gọi vấn đề này là 'hạn chế cây trồng cố định' của StyleGAN.
Đối với các khuôn mặt không được căn chỉnh, StyleGAN3 đã được đề xuất; tuy nhiên, nó chỉ hỗ trợ một kích thước hình ảnh đã đặt.
Hơn nữa, một nghiên cứu gần đây đã phát hiện ra rằng việc mã hóa các khuôn mặt không được căn chỉnh là thách thức hơn so với các khuôn mặt được căn chỉnh. Mã hóa khuôn mặt không chính xác có hại cho việc chuyển kiểu dọc, dẫn đến các vấn đề như thay đổi danh tính và thiếu các thành phần trong khung được tạo lại và tạo kiểu.
Như đã thảo luận, một kỹ thuật hiệu quả để chuyển kiểu video dọc phải xử lý các vấn đề sau:
- Để bảo tồn các chuyển động thực tế, phương pháp tiếp cận phải có khả năng xử lý các khuôn mặt không thẳng hàng và các kích thước video khác nhau. Kích thước video lớn hoặc góc xem rộng có thể thu được nhiều thông tin hơn trong khi vẫn giữ cho khuôn mặt không di chuyển ra khỏi khung hình.
- Để cạnh tranh với các thiết bị HD được sử dụng phổ biến hiện nay, video có độ phân giải cao là cần thiết.
- Kiểm soát phong cách linh hoạt nên được cung cấp để người dùng thay đổi và lựa chọn của họ khi phát triển một hệ thống tương tác người dùng thực tế.
Với mục đích đó, các nhà nghiên cứu đề xuất VToonify, một khuôn khổ kết hợp mới cho quá trình xử lý video. Để vượt qua hạn chế cắt cố định, trước tiên các nhà nghiên cứu nghiên cứu sự tương đương của bản dịch trong StyleGAN.
VToonify kết hợp những lợi ích của kiến trúc dựa trên StyleGAN và khung dịch hình ảnh để đạt được khả năng truyền kiểu video chân dung có độ phân giải cao có thể điều chỉnh được.
Sau đây là những đóng góp chính:
- Các nhà nghiên cứu điều tra hạn chế cắt cố định của StyleGAN và đề xuất một giải pháp dựa trên tương đương dịch.
- Các nhà nghiên cứu trình bày một khung VToonify hoàn toàn phức hợp độc đáo để truyền kiểu video chân dung có độ phân giải cao được kiểm soát, hỗ trợ các khuôn mặt không được căn chỉnh và các kích thước video khác nhau.
- Các nhà nghiên cứu xây dựng VToonify dựa trên xương sống của Toonify và DualStyleGAN và cô đọng xương sống về cả dữ liệu và mô hình để cho phép chuyển kiểu video chân dung dựa trên bộ sưu tập và dựa trên mẫu.
So sánh Vtoonify với các mô hình hiện đại khác
toonify
Nó đóng vai trò là nền tảng cho việc chuyển kiểu dựa trên bộ sưu tập trên các mặt được căn chỉnh bằng cách sử dụng StyleGAN. Để lấy mã kiểu dáng, các nhà nghiên cứu phải căn chỉnh các khuôn mặt và cắt 256256 ảnh cho PSP. Toonify được sử dụng để tạo kết quả cách điệu với mã kiểu 1024 * 1024.
Cuối cùng, họ căn chỉnh lại kết quả trong video về vị trí ban đầu. Khu vực chưa được cách điệu đã được đặt thành màu đen.

DualStyleGAN
Nó là xương sống cho việc chuyển kiểu dựa trên mẫu dựa trên StyleGAN. Họ sử dụng các kỹ thuật xử lý trước và sau dữ liệu giống như Toonify.
Pix2pixHD
Đó là mô hình dịch từ ảnh sang ảnh thường được sử dụng để cô đọng các mô hình đã được đào tạo trước để chỉnh sửa độ phân giải cao. Nó được đào tạo bằng cách sử dụng dữ liệu được ghép nối.
Các nhà nghiên cứu sử dụng pix2pixHD làm đầu vào bản đồ phiên bản bổ sung của nó vì nó sử dụng bản đồ phân tích cú pháp được trích xuất.
Chuyển động đơn hàng đầu tiên
FOM là một mô hình hoạt hình ảnh điển hình. Nó đã được đào tạo trên 256256 hình ảnh và hoạt động kém hơn với các kích thước hình ảnh khác. Do đó, các nhà nghiên cứu đầu tiên chia tỷ lệ khung hình video thành 256 * 256 cho FOM thành hoạt ảnh và sau đó thay đổi kích thước kết quả thành kích thước ban đầu của chúng.
Để so sánh công bằng, FOM sử dụng khung cách điệu đầu tiên của phương pháp tiếp cận làm hình ảnh kiểu tham chiếu.
đại gan
Nó là một mô hình hoạt hình khuôn mặt 3D. Họ sử dụng các phương pháp chuẩn bị và xử lý dữ liệu tương tự như FOM.

Ưu điểm
- Nó có thể được sử dụng trong nghệ thuật, hình đại diện trên mạng xã hội, phim ảnh, quảng cáo giải trí, v.v.
- Vtoonify cũng có thể được sử dụng trong metaverse.
Hạn chế
- Phương pháp luận này trích xuất cả dữ liệu và mô hình từ xương sống dựa trên StyleGAN, dẫn đến độ lệch dữ liệu và mô hình.
- Các hiện vật được tạo ra chủ yếu là do sự khác biệt về kích thước giữa vùng mặt cách điệu và các phần khác.
- Chiến lược này ít thành công hơn khi giải quyết những vấn đề ở vùng đối mặt.
Kết luận
Cuối cùng, VToonify là một khuôn khổ cho quá trình xử lý video độ phân giải cao được kiểm soát theo phong cách.
Khung này đạt được hiệu suất tuyệt vời trong việc xử lý video và cho phép kiểm soát rộng rãi kiểu cấu trúc, kiểu màu và mức độ kiểu bằng cách cô đọng các mô hình quá mức hình ảnh dựa trên StyleGAN về cả dữ liệu tổng hợp và các cấu trúc mạng.





Bình luận