Trò chơi điện tử tiếp tục thách thức hàng tỷ người chơi trên khắp thế giới. Có thể bạn chưa biết, nhưng các thuật toán học máy cũng đã bắt đầu trở thành thách thức.
Hiện có rất nhiều nghiên cứu trong lĩnh vực AI để xem liệu các phương pháp học máy có thể được áp dụng cho các trò chơi điện tử hay không. Tiến bộ đáng kể trong lĩnh vực này cho thấy rằng học máy tác nhân có thể được sử dụng để mô phỏng hoặc thậm chí thay thế trình phát của con người.
Điều này có ý nghĩa gì đối với tương lai của trò chơi video?
Những dự án này chỉ đơn giản là để giải trí, hay có những lý do sâu xa hơn tại sao rất nhiều nhà nghiên cứu đang tập trung vào trò chơi?
Bài viết này sẽ khám phá ngắn gọn lịch sử của AI trong trò chơi điện tử. Sau đó, chúng tôi sẽ cung cấp cho bạn tổng quan nhanh về một số kỹ thuật máy học mà chúng tôi có thể sử dụng để học cách đánh bại trò chơi. Sau đó, chúng tôi sẽ xem xét một số ứng dụng thành công của lưới thần kinh để tìm hiểu và thành thạo các trò chơi điện tử cụ thể.
Lịch sử tóm tắt của AI trong trò chơi
Trước khi tìm hiểu lý do tại sao lưới thần kinh lại trở thành thuật toán lý tưởng để giải quyết các trò chơi điện tử, hãy cùng tìm hiểu sơ qua về cách các nhà khoa học máy tính đã sử dụng trò chơi điện tử để thúc đẩy nghiên cứu của họ trong AI.
Bạn có thể lập luận rằng, ngay từ khi ra đời, trò chơi điện tử đã là một lĩnh vực nghiên cứu nóng bỏng đối với các nhà nghiên cứu quan tâm đến AI.
Mặc dù nguồn gốc không phải là một trò chơi điện tử, nhưng cờ vua đã là một trọng tâm lớn trong những ngày đầu của AI. Năm 1951, Tiến sĩ Dietrich Prinz đã viết một chương trình chơi cờ vua bằng máy tính kỹ thuật số Ferranti Mark 1. Đây là cách trở lại thời kỳ mà những chiếc máy tính cồng kềnh này phải đọc các chương trình trên băng giấy.

Bản thân chương trình không phải là một AI cờ vua hoàn chỉnh. Vì những hạn chế của máy tính, Prinz chỉ có thể tạo ra một chương trình giải quyết các bài toán cờ vua đôi. Trung bình, chương trình mất 15-20 phút để tính toán mọi nước đi có thể cho người chơi Trắng và Đen.
Công việc cải tiến cờ vua và cờ caro AI đã được cải thiện đều đặn trong suốt nhiều thập kỷ. Sự tiến bộ lên đến đỉnh điểm vào năm 1997 khi Deep Blue của IBM đánh bại kiện tướng cờ vua người Nga Garry Kasparov trong một cặp đấu sáu ván. Ngày nay, các công cụ cờ vua bạn có thể tìm thấy trên điện thoại di động có thể đánh bại Deep Blue.
Các đối thủ AI bắt đầu trở nên phổ biến trong thời kỳ hoàng kim của trò chơi điện tử. Những kẻ xâm lược không gian năm 1978 và Pac-Man những năm 1980 là một số trong những người tiên phong trong ngành trong việc tạo ra AI có thể đủ sức thách thức ngay cả những game thủ arcade kỳ cựu nhất.
Đặc biệt, Pac-Man là một trò chơi phổ biến để các nhà nghiên cứu AI thử nghiệm. Nhiều cuộc thi vì Bà Pac-Man đã được tổ chức để xác định đội nào có thể đưa ra AI tốt nhất để đánh bại trò chơi.
Game AI và các thuật toán heuristic tiếp tục phát triển khi nhu cầu về những đối thủ thông minh hơn xuất hiện. Ví dụ: AI chiến đấu ngày càng phổ biến khi các thể loại như game bắn súng góc nhìn thứ nhất trở nên phổ biến hơn.
Học máy trong trò chơi điện tử
Khi các kỹ thuật máy học nhanh chóng trở nên phổ biến, các dự án nghiên cứu khác nhau đã cố gắng sử dụng những kỹ thuật mới này để chơi trò chơi điện tử.
Các trò chơi như Dota 2, StarCraft và Doom có thể đóng vai trò là vấn đề thuật toán học máy để giải quyết. Thuật toán học sâuđặc biệt, đã có thể đạt được và thậm chí vượt qua hiệu suất ở cấp độ con người.
Sản phẩm Môi trường học tập Arcade hoặc ALE đã cung cấp cho các nhà nghiên cứu một giao diện cho hơn một trăm trò chơi Atari 2600. Nền tảng mã nguồn mở cho phép các nhà nghiên cứu đánh giá hiệu suất của các kỹ thuật máy học trên các trò chơi điện tử Atari cổ điển. Google thậm chí còn xuất bản giấy sử dụng bảy trò chơi từ ALE

Trong khi đó, các dự án như VizDoom đã cho các nhà nghiên cứu AI cơ hội đào tạo các thuật toán máy học để chơi game bắn súng góc nhìn thứ nhất 3D.

Nó hoạt động như thế nào: Một số khái niệm chính
Mạng lưới thần kinh
Hầu hết các cách tiếp cận để giải quyết trò chơi điện tử bằng máy học đều liên quan đến một loại thuật toán được gọi là mạng nơ-ron.
Bạn có thể nghĩ về mạng lưới thần kinh như một chương trình cố gắng bắt chước cách thức hoạt động của bộ não. Tương tự như cách bộ não của chúng ta bao gồm các tế bào thần kinh truyền tín hiệu, một mạng lưới thần kinh cũng chứa các tế bào thần kinh nhân tạo.
Các tế bào thần kinh nhân tạo này cũng truyền tín hiệu cho nhau, với mỗi tín hiệu là một con số thực tế. Một mạng nơ-ron chứa nhiều lớp giữa các lớp đầu vào và đầu ra, được gọi là mạng nơ-ron sâu.
Học tăng cường
Một kỹ thuật học máy phổ biến khác có liên quan đến việc học trò chơi điện tử là ý tưởng về học tăng cường.
Kỹ thuật này là quá trình đào tạo một đại lý sử dụng phần thưởng hoặc hình phạt. Với cách tiếp cận này, đại lý sẽ có thể đưa ra giải pháp cho một vấn đề thông qua thử và sai.
Giả sử chúng tôi muốn một AI tìm ra cách chơi trò chơi Snake. Mục tiêu của trò chơi rất đơn giản: nhận được càng nhiều điểm càng tốt bằng cách tiêu thụ các vật phẩm và tránh cái đuôi đang phát triển của bạn.
Với việc học củng cố, chúng ta có thể xác định một chức năng phần thưởng R. Chức năng này cộng điểm khi Rắn tiêu thụ một vật phẩm và trừ điểm khi Rắn gặp chướng ngại vật. Với môi trường hiện tại và một loạt các hành động có thể xảy ra, mô hình học tập củng cố của chúng tôi sẽ cố gắng tính toán 'chính sách' tối ưu để tối đa hóa chức năng khen thưởng của chúng tôi.
tiến hóa thần kinh
Giữ chủ đề với cảm hứng từ thiên nhiên, các nhà nghiên cứu cũng đã tìm thấy thành công trong việc áp dụng ML vào trò chơi điện tử thông qua một kỹ thuật được gọi là sự tiến hóa thần kinh.
Thay vì sử dụng xuống dốc để cập nhật các nơ-ron trong mạng, chúng ta có thể sử dụng các thuật toán tiến hóa để đạt được kết quả tốt hơn.
Các thuật toán tiến hóa thường bắt đầu bằng cách tạo ra một quần thể ban đầu gồm các cá thể ngẫu nhiên. Sau đó, chúng tôi đánh giá những cá nhân này bằng cách sử dụng các tiêu chí nhất định. Những cá thể tốt nhất được chọn làm “bố mẹ” và được lai tạo với nhau để tạo thành một thế hệ cá thể mới. Những cá thể này sau đó sẽ thay thế những cá thể kém phù hợp nhất trong quần thể.
Các thuật toán này cũng thường giới thiệu một số dạng hoạt động đột biến trong quá trình trao đổi chéo hoặc bước “lai tạo” để duy trì sự đa dạng di truyền.
Nghiên cứu mẫu về Học máy trong trò chơi điện tử
Năm OpenAI

Năm OpenAI là một chương trình máy tính của OpenAI nhằm mục đích chơi DOTA 2, một trò chơi đấu trường chiến đấu trên điện thoại di động nhiều người chơi (MOBA) phổ biến.
Chương trình tận dụng các kỹ thuật học tăng cường hiện có, được mở rộng để học từ hàng triệu khung hình mỗi giây. Nhờ hệ thống đào tạo phân tán, OpenAI có thể chơi các trò chơi có giá trị 180 năm mỗi ngày.
Sau thời gian đào tạo, OpenAI Five đã có thể đạt được thành tích ở cấp độ chuyên gia và thể hiện sự hợp tác với những người chơi là con người. Năm 2019, OpenAI năm có thể đánh bại 99.4% người chơi trong các trận đấu công khai.
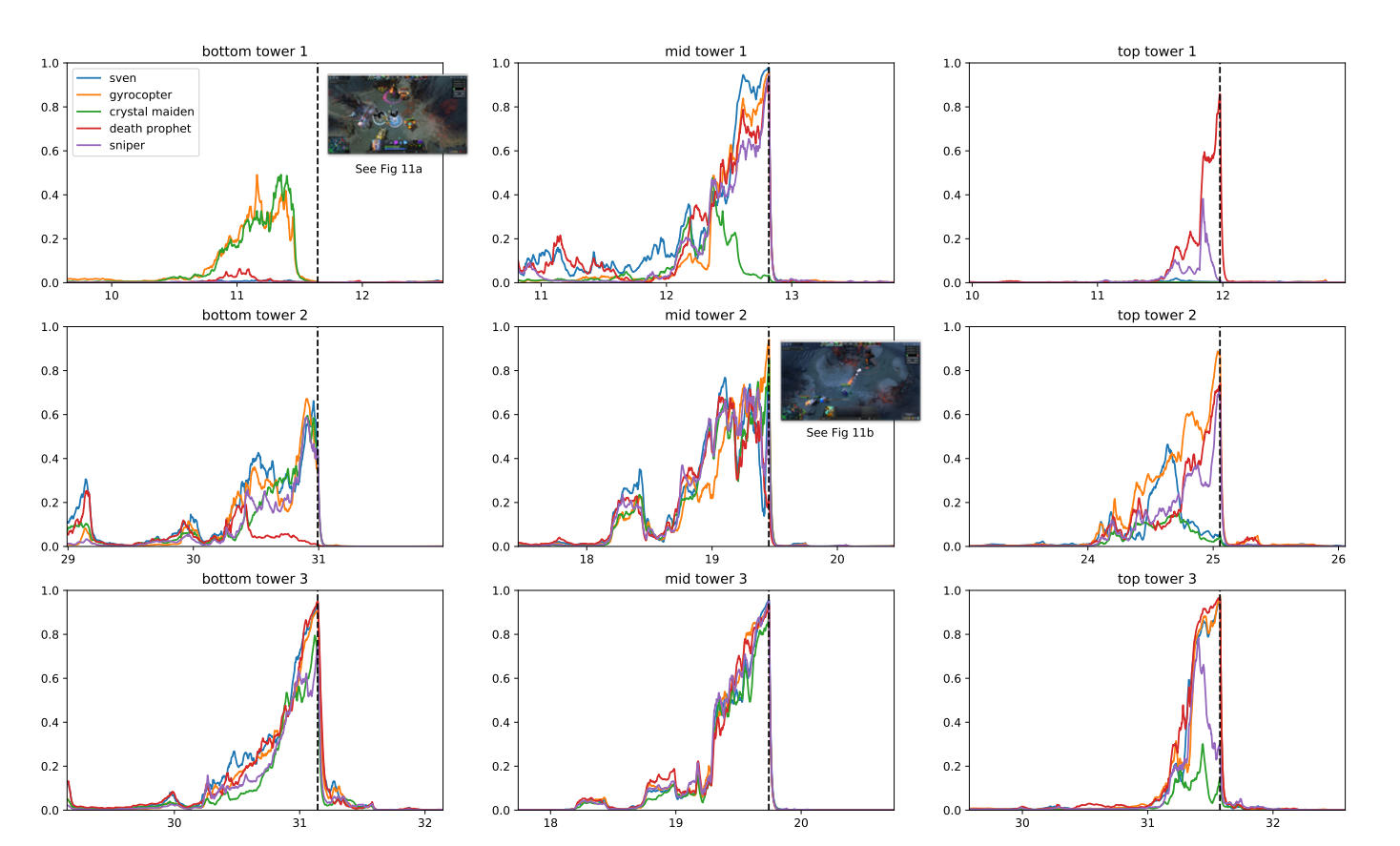
Tại sao OpenAI lại quyết định chọn trò chơi này? Theo các nhà nghiên cứu, DOTA 2 có cơ chế phức tạp nằm ngoài tầm với của các chuyên gia sâu hiện có. học tăng cường các thuật toán.
Super Mario Bros
Một ứng dụng thú vị khác của mạng lưới thần kinh trong trò chơi điện tử là việc sử dụng sự tiến hóa thần kinh để chơi các trò chơi xếp hình như Super Mario Bros.
Ví dụ, cái này mục hackathon bắt đầu với việc không có kiến thức về trò chơi và từ từ xây dựng nền tảng về những gì cần thiết để tiến bộ qua một cấp độ.
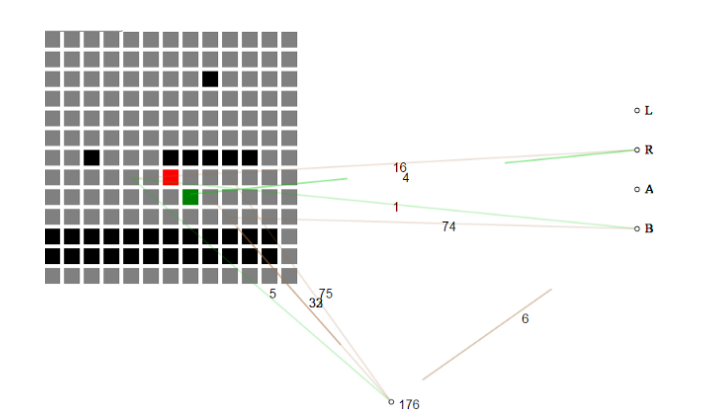
Mạng thần kinh tự phát triển ở trạng thái hiện tại của trò chơi như một lưới ô vuông. Lúc đầu, mạng lưới thần kinh không hiểu ý nghĩa của từng ô, chỉ biết rằng ô “không khí” khác với “ô trên mặt đất” và “ô kẻ thù”.
Dự án hackathon thực hiện một cuộc tiến hóa thần kinh đã sử dụng thuật toán di truyền NEAT để tạo ra các mạng thần kinh khác nhau một cách có chọn lọc.
Tầm quan trọng
Bây giờ bạn đã xem một số ví dụ về mạng lưới thần kinh chơi trò chơi điện tử, bạn có thể tự hỏi mục đích của tất cả điều này là gì.
Vì trò chơi điện tử liên quan đến các tương tác phức tạp giữa các tác nhân và môi trường của họ, nên đó là nền tảng thử nghiệm hoàn hảo để tạo ra AI. Môi trường ảo an toàn và có thể kiểm soát được và cung cấp nguồn dữ liệu vô hạn.
Nghiên cứu được thực hiện trong lĩnh vực này đã cung cấp cho các nhà nghiên cứu cái nhìn sâu sắc về cách mạng thần kinh có thể được tối ưu hóa để tìm hiểu cách giải quyết các vấn đề trong thế giới thực.
Mạng lưới thần kinh được truyền cảm hứng từ cách bộ não hoạt động trong thế giới tự nhiên. Bằng cách nghiên cứu cách các tế bào thần kinh nhân tạo hoạt động khi học cách chơi trò chơi điện tử, chúng tôi cũng có thể hiểu sâu hơn về cách bộ não con người công trình.
Kết luận
Sự tương đồng giữa mạng lưới thần kinh và não bộ đã dẫn đến những hiểu biết sâu sắc trong cả hai lĩnh vực. Việc tiếp tục nghiên cứu về cách mạng lưới thần kinh có thể giải quyết các vấn đề, một ngày nào đó có thể dẫn đến các hình thức nâng cao hơn trí tuệ nhân tạo.
Hãy tưởng tượng sử dụng một AI phù hợp với thông số kỹ thuật của bạn có thể chơi toàn bộ trò chơi điện tử trước khi bạn mua nó để cho bạn biết liệu nó có xứng đáng với thời gian của bạn hay không. Các công ty trò chơi điện tử có sử dụng mạng lưới thần kinh để cải thiện thiết kế trò chơi, mức độ tinh chỉnh và độ khó của đối thủ không?
Bạn nghĩ điều gì sẽ xảy ra khi mạng lưới thần kinh trở thành những game thủ cuối cùng?





Bình luận