AI ہر جگہ ہے، لیکن بعض اوقات اصطلاحات اور اصطلاحات کو سمجھنا مشکل ہو سکتا ہے۔ اس بلاگ پوسٹ میں، ہم AI کی 50 سے زیادہ اصطلاحات اور تعریفیں بیان کرتے ہیں تاکہ آپ اس تیزی سے بڑھتی ہوئی ٹیکنالوجی کو مزید سمجھ سکیں۔
چاہے آپ ابتدائی ہوں یا ماہر، ہم شرط لگاتے ہیں کہ یہاں کچھ شرائط ہیں جو آپ نہیں جانتے!
1. مصنوعی انٹیلی جنس
مصنوعی ذہانت (AI) سے مراد ایسے کمپیوٹر سسٹمز کی ترقی ہے جو اکثر انسانی ذہانت کی تقلید کرتے ہوئے آزادانہ طور پر سیکھنے اور کام کرنے کی صلاحیت رکھتے ہیں۔
یہ نظام ڈیٹا کا تجزیہ کرتے ہیں، نمونوں کو پہچانتے ہیں، فیصلے کرتے ہیں، اور تجربے کی بنیاد پر اپنے طرز عمل کو ڈھالتے ہیں۔ الگورتھم اور ماڈلز کا فائدہ اٹھا کر، AI کا مقصد ذہین مشینیں بنانا ہے جو اپنے اردگرد کے ماحول کو سمجھنے اور سمجھنے کے قابل ہوں۔
حتمی مقصد مشینوں کو کاموں کو مؤثر طریقے سے انجام دینے، ڈیٹا سے سیکھنے، اور انسانوں کی طرح علمی صلاحیتوں کو ظاہر کرنے کے قابل بنانا ہے۔
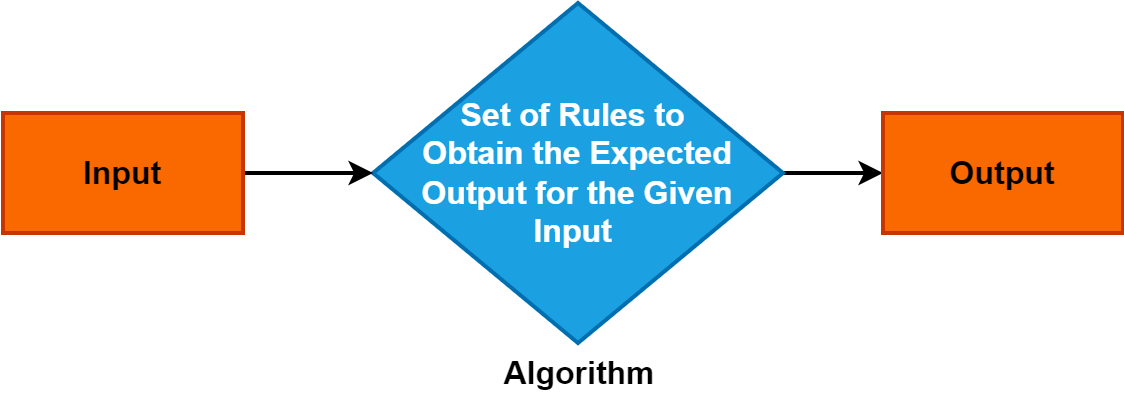
2. الگورتھم
ایک الگورتھم ہدایات یا قواعد کا ایک درست اور منظم مجموعہ ہے جو کسی مسئلے کو حل کرنے یا کسی خاص کام کو پورا کرنے کے عمل کی رہنمائی کرتا ہے۔
یہ مختلف ڈومینز میں ایک بنیادی تصور کے طور پر کام کرتا ہے اور کمپیوٹر سائنس، ریاضی، اور مسائل کو حل کرنے کے شعبوں میں ایک اہم کردار ادا کرتا ہے۔ الگورتھم کو سمجھنا بہت ضروری ہے کیونکہ وہ موثر اور منظم مسئلہ حل کرنے کے طریقوں، ٹیکنالوجی اور فیصلہ سازی کے عمل میں پیشرفت کو آگے بڑھاتے ہیں۔
3. بگ ڈیٹا
بگ ڈیٹا سے مراد انتہائی بڑے اور پیچیدہ ڈیٹاسیٹس ہیں جو روایتی تجزیہ کے طریقوں کی صلاحیتوں سے زیادہ ہیں۔ یہ ڈیٹاسیٹس عام طور پر ان کے حجم، رفتار اور مختلف قسم کے ہوتے ہیں۔
حجم سے مراد مختلف ذرائع سے تیار کردہ ڈیٹا کی وسیع مقدار ہے جیسے سوشل میڈیا، سینسر، اور لین دین۔
رفتار سے مراد وہ تیز رفتاری ہے جس پر ڈیٹا تیار ہوتا ہے اور اسے ریئل ٹائم یا اس کے قریب ریئل ٹائم میں پروسیس کرنے کی ضرورت ہوتی ہے۔ ورائٹی ڈیٹا کی متنوع اقسام اور فارمیٹس کی نشاندہی کرتی ہے، بشمول ساختی، غیر ساختہ، اور نیم ساختہ ڈیٹا۔
4. ڈیٹا مائننگ۔
ڈیٹا مائننگ ایک جامع عمل ہے جس کا مقصد وسیع ڈیٹا سیٹس سے قیمتی بصیرتیں نکالنا ہے۔
اس میں چار اہم مراحل شامل ہیں: ڈیٹا اکٹھا کرنا، جس میں متعلقہ ڈیٹا اکٹھا کرنا شامل ہے۔ ڈیٹا کی تیاری، ڈیٹا کے معیار اور مطابقت کو یقینی بنانا؛ ڈیٹا کی کان کنی، پیٹرن اور تعلقات کو دریافت کرنے کے لیے الگورتھم کا استعمال؛ اور ڈیٹا کا تجزیہ اور تشریح، جہاں نکالے گئے علم کو جانچا اور سمجھا جاتا ہے۔
5. نیورل نیٹ ورک
ایک کمپیوٹر سسٹم کو اس طرح کام کرنے کے لیے ڈیزائن کیا گیا ہے۔ انسانی دماغ، باہم جڑے ہوئے نوڈس یا نیوران پر مشتمل ہے۔ آئیے اس کو تھوڑا اور سمجھیں کیونکہ زیادہ تر AI پر مبنی ہے۔ نیند نیٹ ورک.
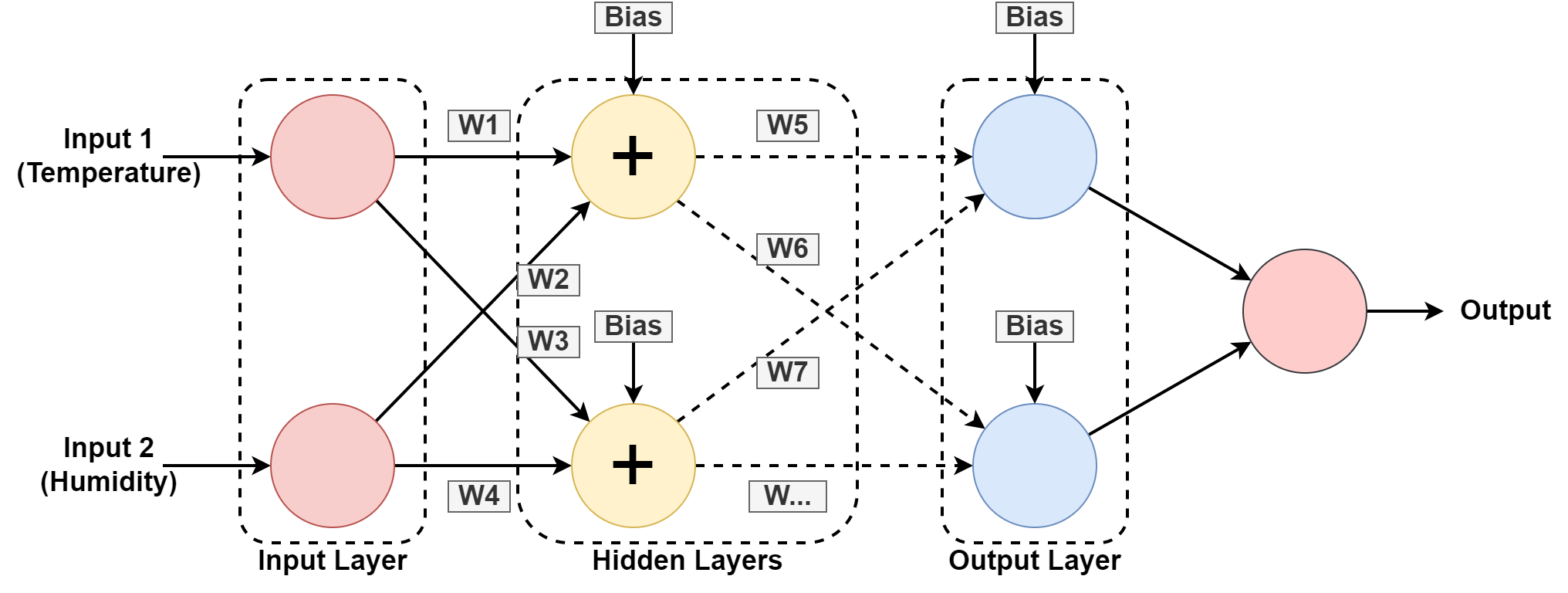
مندرجہ بالا گرافکس میں، ہم ماضی کے پیٹرن سے سیکھ کر جغرافیائی محل وقوع کی نمی اور درجہ حرارت کا اندازہ لگا رہے ہیں۔ ان پٹ ماضی کے ریکارڈ کے لیے ڈیٹا سیٹ ہیں۔
۔ اعصابی نیٹ ورک سیکھتا ہے۔ وزن کے ساتھ کھیل کر اور پوشیدہ تہوں میں تعصب کی اقدار کا اطلاق کرکے پیٹرن۔ W1, W2.... W7 متعلقہ وزن ہیں۔ یہ خود کو فراہم کردہ ڈیٹاسیٹ پر تربیت دیتا ہے اور پیشین گوئی کے طور پر آؤٹ پٹ دیتا ہے۔
آپ اس پیچیدہ معلومات سے مغلوب ہو سکتے ہیں۔ اگر یہ معاملہ ہے، تو آپ ہماری سادہ گائیڈ کے ساتھ شروع کر سکتے ہیں۔ یہاں.
6. مشین لرننگ
مشین لرننگ الگورتھم اور ماڈلز کو تیار کرنے پر مرکوز ہے جو ڈیٹا سے خود بخود سیکھنے اور وقت کے ساتھ ساتھ ان کی کارکردگی کو بہتر بنانے کے قابل ہے۔
اس میں شماریاتی تکنیکوں کا استعمال شامل ہے تاکہ کمپیوٹرز کو پیٹرن کی شناخت کرنے، پیشین گوئیاں کرنے، اور واضح طور پر پروگرام کیے بغیر ڈیٹا پر مبنی فیصلے کرنے کے قابل بنائے۔
مشین لرننگ الگورتھم تجزیہ کریں اور بڑے ڈیٹا سیٹس سے سیکھیں، جس سے سسٹمز کو ان معلومات کی بنیاد پر اپنے رویے کو اپنانے اور بہتر بنانے کی اجازت دی جائے جو وہ کارروائی کرتے ہیں۔
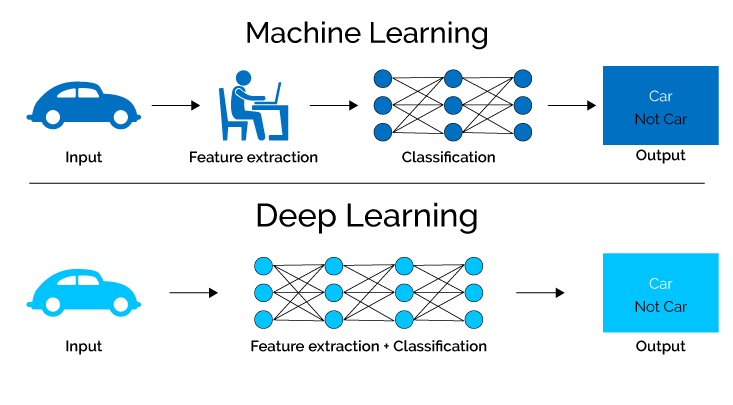
7. گہری تعلیم
گہرے سیکھنے، مشین لرننگ اور نیورل نیٹ ورکس کا ایک ذیلی فیلڈ، انسانی دماغ کے پیچیدہ عمل کو نقل کرتے ہوئے ڈیٹا سے علم حاصل کرنے کے لیے جدید ترین الگورتھم کا فائدہ اٹھاتا ہے۔
متعدد پوشیدہ پرتوں کے ساتھ عصبی نیٹ ورکس کو استعمال کرنے سے، گہری سیکھنے کے ماڈل خود مختار طور پر پیچیدہ خصوصیات اور نمونوں کو نکال سکتے ہیں، جو انہیں غیر معمولی درستگی اور کارکردگی کے ساتھ پیچیدہ کاموں سے نمٹنے کے قابل بناتے ہیں۔
8. پیٹرن کی شناخت
پیٹرن کی شناخت، ڈیٹا کے تجزیہ کی ایک تکنیک، مشین لرننگ الگورتھم کی طاقت کو استعمال کرتی ہے تاکہ ڈیٹا سیٹس کے اندر پیٹرن اور ریگولیٹیز کو خود مختار طریقے سے پتہ لگایا جا سکے۔
کمپیوٹیشنل ماڈلز اور شماریاتی طریقوں سے فائدہ اٹھاتے ہوئے، پیٹرن کی شناخت کے الگورتھم پیچیدہ اور متنوع ڈیٹا میں بامعنی ڈھانچے، ارتباط اور رجحانات کی شناخت کر سکتے ہیں۔
یہ عمل قابل قدر بصیرت کو نکالنے، ڈیٹا کی الگ الگ زمروں میں درجہ بندی، اور تسلیم شدہ نمونوں کی بنیاد پر مستقبل کے نتائج کی پیشین گوئی کے قابل بناتا ہے۔ پیٹرن کی شناخت مختلف ڈومینز میں ایک اہم ٹول ہے، فیصلہ سازی کو بااختیار بنانے، بے ضابطگیوں کا پتہ لگانے، اور پیش گوئی کرنے والی ماڈلنگ۔
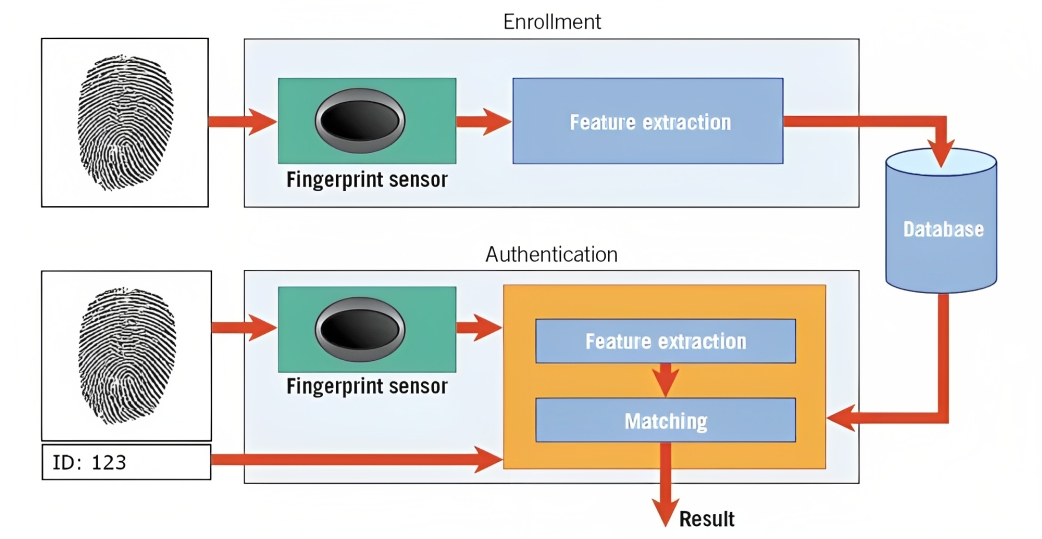
بائیو میٹرکس اس کی ایک مثال ہے۔ مثال کے طور پر، فنگر پرنٹ کی شناخت میں، الگورتھم کسی شخص کے فنگر پرنٹ کے ریزوں، منحنی خطوط اور منفرد خصوصیات کا تجزیہ کرتا ہے تاکہ ایک ڈیجیٹل نمائیندگی بنائی جا سکے جسے ٹیمپلیٹ کہتے ہیں۔
جب آپ اپنے سمارٹ فون کو غیر مقفل کرنے یا کسی محفوظ سہولت تک رسائی حاصل کرنے کی کوشش کرتے ہیں، تو پیٹرن کی شناخت کا نظام پکڑے گئے بائیو میٹرک ڈیٹا (مثلاً، فنگر پرنٹ) کا اس کے ڈیٹا بیس میں ذخیرہ شدہ ٹیمپلیٹس سے موازنہ کرتا ہے۔
نمونوں کو ملا کر اور مماثلت کی سطح کا اندازہ لگا کر، نظام اس بات کا تعین کر سکتا ہے کہ آیا فراہم کردہ بائیو میٹرک ڈیٹا ذخیرہ شدہ ٹیمپلیٹ سے میل کھاتا ہے اور اس کے مطابق رسائی فراہم کرتا ہے۔
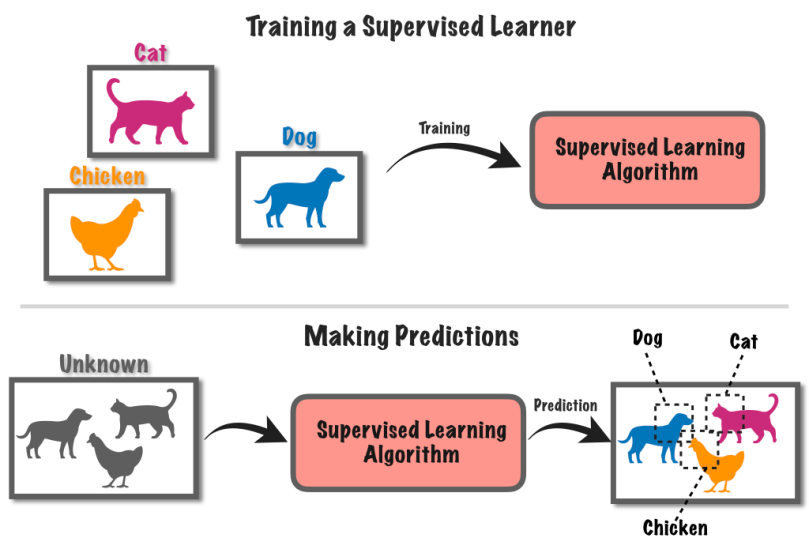
9. زیر نگرانی سیکھنا
سپروائزڈ لرننگ ایک مشین لرننگ اپروچ ہے جس میں لیبل لگا ڈیٹا استعمال کرتے ہوئے کمپیوٹر سسٹم کی تربیت شامل ہوتی ہے۔ اس طریقہ کار میں، کمپیوٹر کو متعلقہ معلوم لیبلز یا نتائج کے ساتھ ان پٹ ڈیٹا کا ایک سیٹ فراہم کیا جاتا ہے۔
ہم کہتے ہیں کہ آپ کے پاس تصویروں کا ایک گروپ ہے، کچھ کتوں کے ساتھ اور کچھ بلیوں کے ساتھ۔
آپ کمپیوٹر کو بتائیں کہ کن تصویروں میں کتے ہیں اور کن میں بلیاں ہیں۔ کمپیوٹر پھر تصویروں میں پیٹرن تلاش کرکے کتوں اور بلیوں کے درمیان فرق کو پہچاننا سیکھتا ہے۔
اس کے سیکھنے کے بعد، آپ کمپیوٹر کو نئی تصویریں دے سکتے ہیں، اور وہ یہ جاننے کی کوشش کرے گا کہ آیا ان کے پاس کتے یا بلیاں ہیں جو اس نے لیبل والی مثالوں سے سیکھی ہیں۔ یہ معلوم معلومات کا استعمال کرتے ہوئے پیشین گوئیاں کرنے کے لیے کمپیوٹر کو تربیت دینے جیسا ہے۔
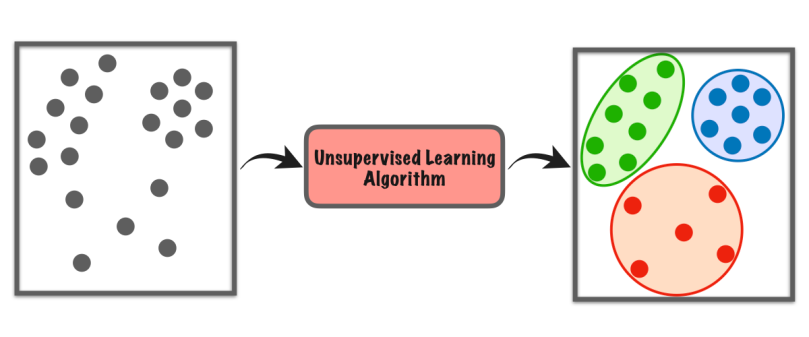
10. غیر زیر نگرانی سیکھنا
غیر زیر نگرانی لرننگ مشین لرننگ کی ایک قسم ہے جہاں کمپیوٹر بغیر کسی مخصوص ہدایات کے پیٹرن یا مماثلتیں تلاش کرنے کے لیے اپنے طور پر ڈیٹاسیٹ کو تلاش کرتا ہے۔
یہ لیبل شدہ مثالوں پر بھروسہ نہیں کرتا ہے جیسے زیر نگرانی سیکھنے میں۔ اس کے بجائے، یہ ڈیٹا میں پوشیدہ ڈھانچے یا گروپس کو تلاش کرتا ہے۔ ایسا لگتا ہے کہ کمپیوٹر خود ہی چیزوں کو دریافت کر رہا ہے، بغیر کسی استاد کے یہ بتائے کہ کیا تلاش کرنا ہے۔
اس قسم کے سیکھنے سے ہمیں نئی بصیرتیں تلاش کرنے، ڈیٹا کو منظم کرنے، یا پیشگی معلومات یا واضح رہنمائی کی ضرورت کے بغیر غیر معمولی چیزوں کی نشاندہی کرنے میں مدد ملتی ہے۔
11. قدرتی زبان پروسیسنگ (این ایل پی)
نیچرل لینگویج پروسیسنگ اس بات پر مرکوز ہے کہ کمپیوٹر کس طرح انسانی زبان کو سمجھتے اور ان کے ساتھ تعامل کرتے ہیں۔ یہ کمپیوٹرز کو انسانی زبان کا تجزیہ کرنے، تشریح کرنے اور جواب دینے میں اس طرح مدد کرتا ہے جو ہمارے لیے زیادہ فطری محسوس ہوتا ہے۔
NLP وہی ہے جو ہمارے لیے صوتی معاونین، اور چیٹ بوٹس کے ساتھ بات چیت کرنا ممکن بناتا ہے، اور یہاں تک کہ ہماری ای میلز کو خود بخود فولڈرز میں ترتیب دیا جاتا ہے۔
اس میں کمپیوٹرز کو الفاظ، جملوں، اور یہاں تک کہ پورے متن کے پیچھے معنی سمجھنا سکھانا شامل ہے، تاکہ وہ مختلف کاموں میں ہماری مدد کر سکیں اور ٹیکنالوجی کے ساتھ ہمارے تعامل کو مزید ہموار بنا سکیں۔
12. کمپیوٹر ویژن
کمپیوٹر کے نقطہ نظر ایک دلچسپ ٹیکنالوجی ہے جو کمپیوٹرز کو تصاویر اور ویڈیوز دیکھنے اور سمجھنے کی اجازت دیتی ہے، بالکل اسی طرح جیسے ہم انسان اپنی آنکھوں سے کرتے ہیں۔ یہ سب کچھ کمپیوٹرز کو بصری معلومات کا تجزیہ کرنے اور جو کچھ وہ دیکھتے ہیں اس کا احساس دلانے کے بارے میں ہے۔
آسان الفاظ میں، کمپیوٹر ویژن کمپیوٹر کو بصری دنیا کو پہچاننے اور اس کی تشریح کرنے میں مدد کرتا ہے۔ اس میں انہیں تصاویر میں مخصوص اشیاء کی شناخت کرنا، تصاویر کو مختلف زمروں میں درجہ بندی کرنا، یا تصاویر کو بامعنی حصوں میں تقسیم کرنے جیسے کام شامل ہیں۔
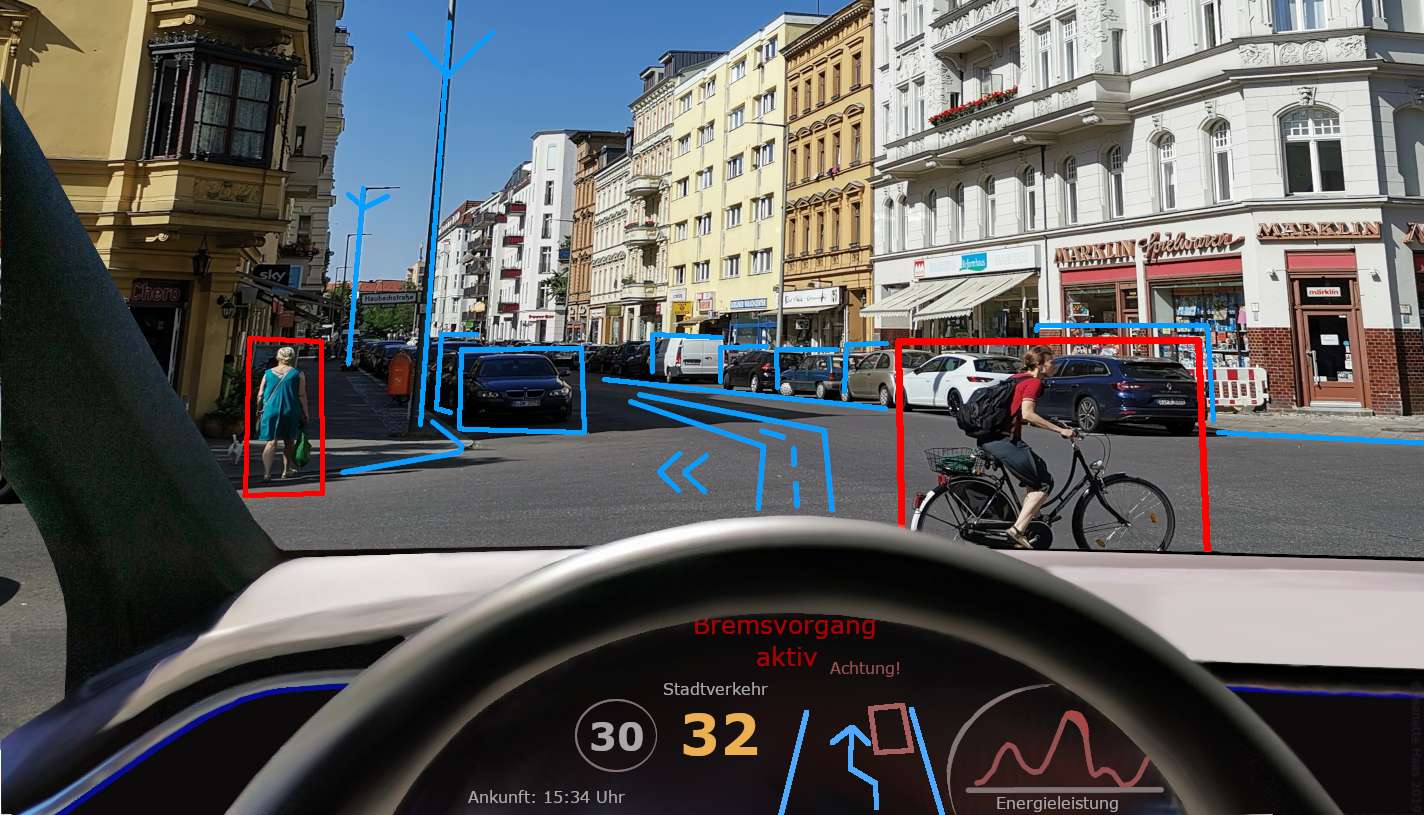
سڑک اور اس کے آس پاس کی ہر چیز کو "دیکھنے" کے لیے کمپیوٹر ویژن کا استعمال کرتے ہوئے خود چلانے والی کار کا تصور کریں۔
یہ پیدل چلنے والوں، ٹریفک کے نشانات اور دیگر گاڑیوں کا پتہ لگا سکتا ہے اور انہیں محفوظ طریقے سے نیویگیٹ کرنے میں مدد کرتا ہے۔ یا اس بارے میں سوچیں کہ چہرے کی شناخت کی ٹیکنالوجی کس طرح ہمارے اسمارٹ فونز کو غیر مقفل کرنے کے لیے کمپیوٹر وژن کا استعمال کرتی ہے یا ہمارے چہرے کی منفرد خصوصیات کو پہچان کر ہماری شناخت کی تصدیق کرتی ہے۔
اس کا استعمال نگرانی کے نظام میں بھیڑ بھری جگہوں کی نگرانی اور کسی بھی مشکوک سرگرمیوں کو دیکھنے کے لیے بھی کیا جاتا ہے۔
کمپیوٹر ویژن ایک طاقتور ٹیکنالوجی ہے جو امکانات کی دنیا کو کھولتی ہے۔ کمپیوٹرز کو بصری معلومات کو دیکھنے اور سمجھنے کے قابل بنا کر، ہم ایسے ایپلی کیشنز اور سسٹمز تیار کر سکتے ہیں جو ہمارے ارد گرد کی دنیا کو سمجھ سکیں اور اس کی تشریح کر سکیں، ہماری زندگیوں کو آسان، محفوظ اور زیادہ موثر بنا سکیں۔
13. چیٹ بوٹ
چیٹ بوٹ ایک کمپیوٹر پروگرام کی طرح ہوتا ہے جو لوگوں سے اس انداز میں بات کر سکتا ہے جو کہ حقیقی انسانی گفتگو کی طرح لگتا ہے۔
یہ اکثر آن لائن کسٹمر سروس میں صارفین کی مدد کرنے اور انہیں یہ محسوس کرنے کے لیے استعمال کیا جاتا ہے کہ وہ کسی شخص سے بات کر رہے ہیں، حالانکہ یہ دراصل کمپیوٹر پر چلنے والا پروگرام ہے۔
چیٹ بوٹ صارفین کے پیغامات یا سوالات کو سمجھ سکتا ہے اور ان کا جواب دے سکتا ہے، جس طرح ایک انسانی کسٹمر سروس کے نمائندے کی طرح مددگار معلومات اور مدد فراہم کرتا ہے۔
14. آواز کی شناخت
آواز کی شناخت سے مراد کمپیوٹر سسٹم کی انسانی تقریر کو سمجھنے اور اس کی تشریح کرنے کی صلاحیت ہے۔ اس میں وہ ٹیکنالوجی شامل ہے جو کمپیوٹر یا ڈیوائس کو بولنے والے الفاظ کو "سننے" کے قابل بناتی ہے اور انہیں متن یا کمانڈ میں تبدیل کرتی ہے جسے وہ سمجھ سکتا ہے۔
ساتھ آواز کی پہچان، آپ آلات یا ایپلیکیشنز کے ساتھ ٹائپ کرنے یا دوسرے ان پٹ طریقوں کو استعمال کرنے کے بجائے صرف ان سے بات کر کے بات چیت کر سکتے ہیں۔
یہ نظام بولے جانے والے الفاظ کا تجزیہ کرتا ہے، نمونوں اور آوازوں کو پہچانتا ہے، اور پھر انہیں قابل فہم متن یا اعمال میں ترجمہ کرتا ہے۔ یہ ٹیکنالوجی کے ساتھ ہینڈز فری اور قدرتی مواصلت کی اجازت دیتا ہے، جس سے صوتی کمانڈ، ڈکٹیشن، یا صوتی کنٹرول والے تعاملات کو ممکن بنایا جا سکتا ہے۔ سب سے عام مثالیں AI معاون ہیں جیسے سری اور گوگل اسسٹنٹ۔
15. جذبات کا تجزیہ
احساس تجزیہ متن یا تقریر میں بیان کیے گئے جذبات، آراء اور رویوں کو سمجھنے اور اس کی ترجمانی کرنے کے لیے استعمال ہونے والی تکنیک ہے۔ اس میں تحریری یا بولی جانے والی زبان کا تجزیہ کرنا شامل ہے تاکہ اس بات کا تعین کیا جا سکے کہ آیا اظہار کردہ جذبات مثبت، منفی یا غیر جانبدار ہیں۔
مشین لرننگ الگورتھم کا استعمال کرتے ہوئے، جذبات کا تجزیہ کرنے والے الگورتھم الفاظ کے پیچھے بنیادی جذبات کی نشاندہی کرنے کے لیے ٹیکسٹ ڈیٹا کی بڑی مقدار، جیسے کسٹمر کے جائزے، سوشل میڈیا پوسٹس، یا کسٹمر فیڈ بیک کو اسکین اور تجزیہ کرسکتے ہیں۔
الگورتھم مخصوص الفاظ، جملے، یا پیٹرن تلاش کرتے ہیں جو جذبات یا رائے کی نشاندہی کرتے ہیں۔
یہ تجزیہ کاروباروں یا افراد کو یہ سمجھنے میں مدد کرتا ہے کہ لوگ کسی پروڈکٹ، سروس یا موضوع کے بارے میں کیسا محسوس کرتے ہیں اور اسے ڈیٹا پر مبنی فیصلے کرنے یا کسٹمر کی ترجیحات میں بصیرت حاصل کرنے کے لیے استعمال کیا جا سکتا ہے۔
مثال کے طور پر، ایک کمپنی کسٹمر کی اطمینان کو ٹریک کرنے، بہتری کے لیے علاقوں کی نشاندہی کرنے، یا اپنے برانڈ کے بارے میں عوامی رائے کی نگرانی کے لیے جذباتی تجزیہ کا استعمال کر سکتی ہے۔
16. مشینی ترجمہ
مشینی ترجمہ، AI کے تناظر میں، کمپیوٹر الگورتھم اور مصنوعی ذہانت کے استعمال سے مراد متن یا تقریر کا خود بخود ایک زبان سے دوسری زبان میں ترجمہ کرنا ہے۔
اس میں کمپیوٹر کو انسانی زبانوں کو سمجھنے اور اس پر کارروائی کرنے کی تعلیم دینا شامل ہے تاکہ درست ترجمہ فراہم کیا جا سکے۔ سب سے عام مثال ہے گوگل مترجم.
مشینی ترجمہ کے ساتھ، آپ ایک زبان میں متن یا تقریر داخل کر سکتے ہیں، اور نظام ان پٹ کا تجزیہ کرے گا اور دوسری زبان میں متعلقہ ترجمہ تیار کرے گا۔ یہ خاص طور پر اس وقت مفید ہوتا ہے جب مختلف زبانوں میں معلومات تک بات چیت یا رسائی حاصل ہو۔
مشینی ترجمہ کے نظام لسانی اصولوں، شماریاتی ماڈلز، اور مشین لرننگ الگورتھم کے امتزاج پر انحصار کرتے ہیں۔ وہ وقت کے ساتھ ترجمے کی درستگی کو بہتر بنانے کے لیے زبان کے وسیع ڈیٹا سے سیکھتے ہیں۔ کچھ مشینی ترجمے کے طریقوں میں ترجمے کے معیار کو بڑھانے کے لیے عصبی نیٹ ورکس بھی شامل ہوتے ہیں۔
17. روبوٹکس
روبوٹکس مصنوعی ذہانت اور مکینیکل انجینئرنگ کا امتزاج ہے جو روبوٹ کہلانے والی ذہین مشینیں بناتی ہے۔ یہ روبوٹ خود مختاری سے یا کم سے کم انسانی مداخلت کے ساتھ کام انجام دینے کے لیے بنائے گئے ہیں۔
روبوٹ وہ جسمانی ہستیاں ہیں جو اپنے ماحول کو سمجھ سکتی ہیں، اس حسی ان پٹ کی بنیاد پر فیصلے کر سکتی ہیں، اور مخصوص اعمال یا کام انجام دے سکتی ہیں۔
وہ مختلف سینسرز سے لیس ہیں، جیسے کیمرے، مائیکروفون، یا ٹچ سینسر، جو انہیں اپنے ارد گرد کی دنیا سے معلومات اکٹھا کرنے کی اجازت دیتے ہیں۔ AI الگورتھم اور پروگرامنگ کی مدد سے روبوٹ اس ڈیٹا کا تجزیہ کر سکتے ہیں، اس کی تشریح کر سکتے ہیں اور اپنے مقرر کردہ کاموں کو انجام دینے کے لیے ذہین فیصلے کر سکتے ہیں۔
روبوٹ کو ان کے تجربات سے سیکھنے اور مختلف حالات کے مطابق ڈھالنے کے قابل بنا کر AI روبوٹکس میں ایک اہم کردار ادا کرتا ہے۔
مشین لرننگ الگورتھم کا استعمال روبوٹ کو اشیاء کو پہچاننے، ماحول کو نیویگیٹ کرنے، یا انسانوں کے ساتھ بات چیت کرنے کی تربیت دینے کے لیے کیا جا سکتا ہے۔ یہ روبوٹ کو زیادہ ورسٹائل، لچکدار اور پیچیدہ کاموں کو سنبھالنے کے قابل بناتا ہے۔
18 ڈرون
ڈرون ایک قسم کا روبوٹ ہے جو کسی انسانی پائلٹ کے بغیر ہوا میں اڑ سکتا ہے یا منڈلا سکتا ہے۔ انہیں بغیر پائلٹ کے فضائی گاڑیاں (UAVs) بھی کہا جاتا ہے۔ ڈرون مختلف سینسرز سے لیس ہوتے ہیں، جیسے کیمرے، جی پی ایس، اور جائروسکوپس، جو انہیں ڈیٹا اکٹھا کرنے اور اپنے اردگرد نیویگیٹ کرنے کی اجازت دیتے ہیں۔
انہیں انسانی آپریٹر کے ذریعے دور سے کنٹرول کیا جاتا ہے یا پہلے سے پروگرام شدہ ہدایات کا استعمال کرتے ہوئے خود مختار طور پر کام کر سکتے ہیں۔
ڈرونز وسیع پیمانے پر مقاصد کی تکمیل کرتے ہیں، بشمول فضائی فوٹو گرافی اور ویڈیو گرافی، سروے اور نقشہ سازی، ترسیل کی خدمات، تلاش اور بچاؤ مشن، زراعت کی نگرانی، اور یہاں تک کہ تفریحی استعمال۔ وہ دور دراز یا خطرناک علاقوں تک رسائی حاصل کر سکتے ہیں جو انسانوں کے لیے مشکل یا خطرناک ہیں۔
19. بڑھا ہوا حقیقت (AR)
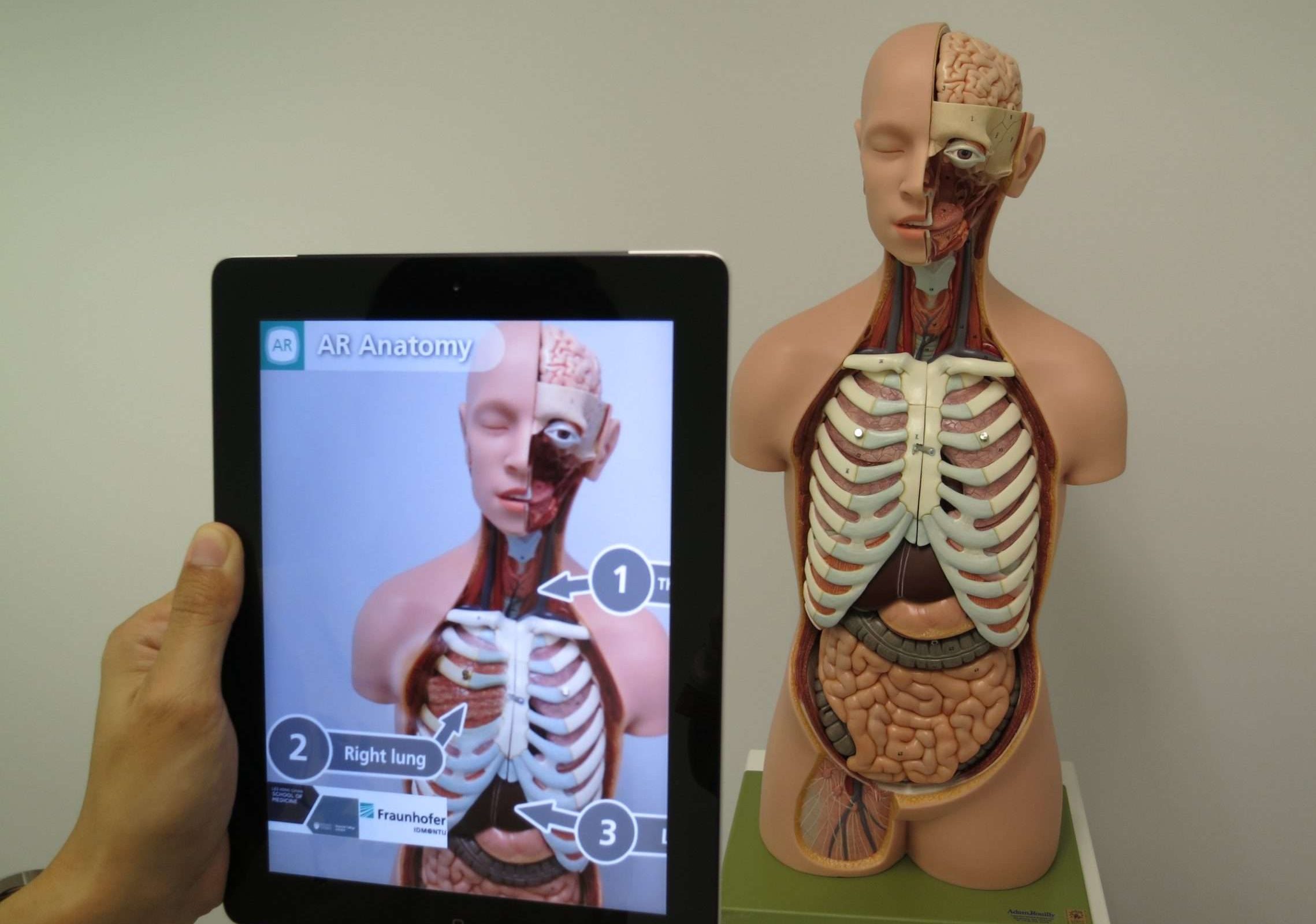
Augmented reality (AR) ایک ایسی ٹیکنالوجی ہے جو حقیقی دنیا کو ورچوئل اشیاء یا معلومات کے ساتھ جوڑتی ہے تاکہ ماحول کے ساتھ ہمارے ادراک اور تعامل کو بہتر بنایا جا سکے۔ یہ کمپیوٹر سے تیار کردہ تصاویر، آوازوں، یا دیگر حسی آدانوں کو حقیقی دنیا پر چڑھا دیتا ہے، جس سے ایک عمیق اور متعامل تجربہ ہوتا ہے۔
سیدھے الفاظ میں، تصور کریں کہ خصوصی چشمہ پہننا یا اپنے آس پاس کی دنیا کو دیکھنے کے لیے اپنے اسمارٹ فون کا استعمال کرنا، لیکن اضافی ورچوئل عناصر کے ساتھ۔
مثال کے طور پر، آپ اپنے سمارٹ فون کو شہر کی سڑک پر لے جا سکتے ہیں اور ورچوئل سائن پوسٹس کو دیکھ سکتے ہیں جس میں ڈائریکشنز، ریٹنگز، اور قریبی ریستورانوں کے لیے جائزے یا یہاں تک کہ حقیقی ماحول سے تعامل کرنے والے ورچوئل کردار بھی دکھائی دیتے ہیں۔
یہ ورچوئل عناصر حقیقی دنیا کے ساتھ بغیر کسی رکاوٹ کے گھل مل جاتے ہیں، جو آپ کے ماحول کے بارے میں آپ کی سمجھ اور تجربے کو بڑھاتے ہیں۔ Augmented reality کو مختلف شعبوں جیسے گیمنگ، تعلیم، فن تعمیر، اور یہاں تک کہ روزمرہ کے کاموں جیسے نیویگیشن یا اپنے گھر میں نیا فرنیچر خریدنے سے پہلے آزمانے میں استعمال کیا جا سکتا ہے۔
20. مجازی حقیقت (VR)
ورچوئل رئیلٹی (VR) ایک ایسی ٹیکنالوجی ہے جو کمپیوٹر سے تیار کردہ سمیلیشنز کا استعمال کرتے ہوئے ایک مصنوعی ماحول پیدا کرتی ہے جسے کوئی شخص دریافت کر سکتا ہے اور اس کے ساتھ تعامل کر سکتا ہے۔ یہ صارف کو ایک ورچوئل دنیا میں غرق کرتا ہے، حقیقی دنیا کو روکتا ہے اور اسے ڈیجیٹل دائرے سے بدل دیتا ہے۔
سیدھے الفاظ میں، ایک خاص ہیڈسیٹ لگانے کا تصور کریں جو آپ کی آنکھوں اور کانوں کو ڈھانپے اور آپ کو بالکل مختلف جگہ پر لے جائے۔ اس مجازی دنیا میں، جو کچھ بھی آپ دیکھتے اور سنتے ہیں وہ ناقابل یقین حد تک حقیقی محسوس ہوتا ہے، حالانکہ یہ سب کمپیوٹر کے ذریعے تخلیق کیا گیا ہے۔
آپ گھوم سکتے ہیں، کسی بھی سمت دیکھ سکتے ہیں، اور اشیاء یا کرداروں کے ساتھ اس طرح بات چیت کر سکتے ہیں جیسے وہ جسمانی طور پر موجود ہوں۔
مثال کے طور پر، ایک ورچوئل رئیلٹی گیم میں، آپ اپنے آپ کو قرون وسطی کے قلعے کے اندر پا سکتے ہیں، جہاں آپ اس کی راہداریوں سے گزر سکتے ہیں، ہتھیار اٹھا سکتے ہیں اور ورچوئل مخالفین کے ساتھ تلوار کی لڑائی میں مشغول ہو سکتے ہیں۔ ورچوئل رئیلٹی ماحول آپ کی حرکات و سکنات کا جواب دیتا ہے، جس سے آپ اپنے تجربے میں پوری طرح غرق اور مصروف محسوس ہوتے ہیں۔
ورچوئل رئیلٹی نہ صرف گیمنگ کے لیے استعمال ہوتی ہے بلکہ مختلف دیگر ایپلی کیشنز جیسے کہ پائلٹوں، سرجنوں، یا فوجی اہلکاروں کے لیے تربیتی سمیلیشنز، آرکیٹیکچرل واک تھرو، ورچوئل ٹورازم، اور یہاں تک کہ بعض نفسیاتی حالات کے لیے علاج کے لیے بھی استعمال ہوتی ہے۔ یہ موجودگی کا احساس پیدا کرتا ہے اور صارفین کو نئی اور پرجوش ورچوئل دنیاوں میں لے جاتا ہے، جس سے تجربے کو حقیقت کے زیادہ سے زیادہ قریب محسوس ہوتا ہے۔
21. ڈیٹا سائنس
ڈیٹا سائنس ایک ایسا شعبہ ہے جس میں ڈیٹا سے قیمتی علم اور بصیرت نکالنے کے لیے سائنسی طریقوں، ٹولز اور الگورتھم کا استعمال شامل ہے۔ یہ بڑے اور پیچیدہ ڈیٹاسیٹس کا تجزیہ کرنے کے لیے ریاضی، شماریات، پروگرامنگ، اور ڈومین کی مہارت کے عناصر کو یکجا کرتا ہے۔
آسان الفاظ میں، ڈیٹا سائنس ڈیٹا کے ایک گروپ میں چھپی ہوئی بامعنی معلومات اور نمونوں کو تلاش کرنے کے بارے میں ہے۔ اس میں ڈیٹا اکٹھا کرنا، صفائی کرنا اور منظم کرنا، پھر اسے دریافت کرنے اور تجزیہ کرنے کے لیے مختلف تکنیکوں کا استعمال کرنا شامل ہے۔ ڈیٹا سائنسدان رجحانات سے پردہ اٹھانے، پیشین گوئیاں کرنے اور مسائل کو حل کرنے کے لیے شماریاتی ماڈلز اور الگورتھم استعمال کریں۔
مثال کے طور پر، صحت کی دیکھ بھال کے شعبے میں، ڈیٹا سائنس کا استعمال مریضوں کے ریکارڈ اور طبی ڈیٹا کا تجزیہ کرنے کے لیے کیا جا سکتا ہے تاکہ بیماریوں کے خطرے کے عوامل کی نشاندہی کی جا سکے، مریض کے نتائج کی پیشن گوئی کی جا سکے، یا علاج کے منصوبوں کو بہتر بنایا جا سکے۔ کاروبار میں، ڈیٹا سائنس کو کسٹمر کے ڈیٹا پر ان کی ترجیحات کو سمجھنے، مصنوعات کی سفارش کرنے، یا مارکیٹنگ کی حکمت عملیوں کو بہتر بنانے کے لیے لاگو کیا جا سکتا ہے۔
22. ڈیٹا رینگلنگ
ڈیٹا رینگلنگ، جسے ڈیٹا منگنگ بھی کہا جاتا ہے، خام ڈیٹا کو جمع کرنے، صاف کرنے اور اسے ایک ایسی شکل میں تبدیل کرنے کا عمل ہے جو تجزیہ کے لیے زیادہ مفید اور موزوں ہے۔ اس میں ڈیٹا کو سنبھالنا اور تیار کرنا شامل ہے تاکہ تجزیہ کے ٹولز یا ماڈلز کے ساتھ اس کے معیار، مستقل مزاجی اور مطابقت کو یقینی بنایا جا سکے۔
آسان الفاظ میں، ڈیٹا کا جھگڑا کھانا پکانے کے لیے اجزاء کی تیاری جیسا ہے۔ اس میں مختلف ذرائع سے ڈیٹا اکٹھا کرنا، اسے چھانٹنا، اور کسی بھی خامی، عدم مطابقت یا غیر متعلقہ معلومات کو دور کرنے کے لیے اسے صاف کرنا شامل ہے۔
مزید برآں، ڈیٹا کو تبدیل کرنے، دوبارہ ترتیب دینے، یا جمع کرنے کی ضرورت ہو سکتی ہے تاکہ اس کے ساتھ کام کرنا اور اس سے بصیرت حاصل کرنا آسان ہو۔
مثال کے طور پر، ڈیٹا رینگلنگ میں ڈپلیکیٹ اندراجات کو ہٹانا، غلط ہجے یا فارمیٹنگ کے مسائل کو درست کرنا، گمشدہ اقدار کو سنبھالنا، اور ڈیٹا کی اقسام کو تبدیل کرنا شامل ہو سکتا ہے۔ اس میں مختلف ڈیٹاسیٹس کو ایک ساتھ ملانا یا ان میں شامل ہونا، ڈیٹا کو سب سیٹس میں تقسیم کرنا، یا موجودہ ڈیٹا کی بنیاد پر نئے متغیرات بنانا شامل ہو سکتا ہے۔
23. ڈیٹا اسٹوری ٹیلنگ
ڈیٹا کہانی سنانا ایک بیانیہ یا پیغام کو مؤثر طریقے سے بات چیت کرنے کے لیے ایک زبردست اور پرکشش انداز میں ڈیٹا پیش کرنے کا فن ہے۔ اس میں استعمال کرنا شامل ہے۔ ڈیٹا تصوربصیرت اور نتائج کو اس انداز میں پہنچانے کے لیے بیانیے، اور سیاق و سباق جو سامعین کے لیے قابل فہم اور یادگار ہو۔
آسان الفاظ میں، ڈیٹا کہانی سنانے کا مطلب کہانی سنانے کے لیے ڈیٹا کا استعمال کرنا ہے۔ یہ صرف نمبرز اور چارٹ پیش کرنے سے آگے ہے۔ اس میں ڈیٹا کے ارد گرد ایک بیانیہ تیار کرنا، بصری عناصر اور کہانی سنانے کی تکنیکوں کا استعمال کرتے ہوئے ڈیٹا کو زندہ کرنا اور اسے سامعین کے لیے قابلِ رشک بنانا شامل ہے۔
مثال کے طور پر، صرف فروخت کے اعداد و شمار کا ایک جدول پیش کرنے کے بجائے، ڈیٹا کہانی سنانے میں ایک انٹرایکٹو ڈیش بورڈ بنانا شامل ہوسکتا ہے جو صارفین کو فروخت کے رجحانات کو بصری طور پر دریافت کرنے کی اجازت دیتا ہے۔
اس میں ایک بیانیہ شامل ہوسکتا ہے جو کلیدی نتائج کو نمایاں کرتا ہے، رجحانات کے پیچھے وجوہات کی وضاحت کرتا ہے، اور اعداد و شمار کی بنیاد پر قابل عمل سفارشات تجویز کرتا ہے۔
24. ڈیٹا پر مبنی فیصلہ سازی۔
ڈیٹا پر مبنی فیصلہ سازی متعلقہ ڈیٹا کے تجزیہ اور تشریح کی بنیاد پر انتخاب کرنے یا اقدامات کرنے کا عمل ہے۔ اس میں فیصلہ سازی کے عمل کی رہنمائی اور مدد کے لیے ڈیٹا کو بنیاد کے طور پر استعمال کرنا شامل ہے نہ کہ مکمل طور پر وجدان یا ذاتی فیصلے پر انحصار کرنے کے۔
آسان الفاظ میں، ڈیٹا پر مبنی فیصلہ سازی کا مطلب ہے کہ ہم جو انتخاب کرتے ہیں ان کو مطلع کرنے اور رہنمائی کرنے کے لیے ڈیٹا سے حقائق اور شواہد کا استعمال کرنا۔ اس میں نمونوں، رجحانات اور رشتوں کو سمجھنے کے لیے ڈیٹا اکٹھا کرنا اور اس کا تجزیہ کرنا اور اس علم کو باخبر فیصلے کرنے اور مسائل کو حل کرنے کے لیے استعمال کرنا شامل ہے۔
مثال کے طور پر، کاروباری ترتیب میں، ڈیٹا پر مبنی فیصلہ سازی میں سیلز ڈیٹا، کسٹمر فیڈ بیک، اور مارکیٹ کے رجحانات کا تجزیہ کرنا شامل ہو سکتا ہے تاکہ قیمتوں کا تعین کرنے کی سب سے مؤثر حکمت عملی کا تعین کیا جا سکے یا مصنوعات کی ترقی میں بہتری کے لیے شعبوں کی نشاندہی کی جا سکے۔
صحت کی دیکھ بھال میں، اس میں علاج کے منصوبوں کو بہتر بنانے یا بیماری کے نتائج کی پیشن گوئی کرنے کے لیے مریض کے ڈیٹا کا تجزیہ کرنا شامل ہو سکتا ہے۔
25. ڈیٹا لیک
ڈیٹا لیک ایک مرکزی اور توسیع پذیر ڈیٹا ریپوزٹری ہے جو اپنی خام اور غیر پروسیس شدہ شکل میں ڈیٹا کی وسیع مقدار کو ذخیرہ کرتی ہے۔ اسے پہلے سے طے شدہ اسکیموں یا ڈیٹا کی تبدیلیوں کی ضرورت کے بغیر ڈیٹا کی اقسام، فارمیٹس، اور ڈھانچے، جیسے سٹرکچرڈ، نیم سٹرکچرڈ، اور غیر ساختہ ڈیٹا رکھنے کے لیے ڈیزائن کیا گیا ہے۔
مثال کے طور پر، ایک کمپنی ڈیٹا لیک میں مختلف ذرائع سے ڈیٹا اکٹھا اور ذخیرہ کر سکتی ہے، جیسے ویب سائٹ لاگ، کسٹمر کے لین دین، سوشل میڈیا فیڈز، اور IoT ڈیوائسز۔
اس کے بعد اس ڈیٹا کو مختلف مقاصد کے لیے استعمال کیا جا سکتا ہے، جیسے کہ جدید تجزیات کا انعقاد، مشین لرننگ الگورتھم کو انجام دینا، یا کسٹمر کے رویے میں پیٹرن اور رجحانات کو تلاش کرنا۔
26. ڈیٹا گودام
ڈیٹا گودام ایک خصوصی ڈیٹا بیس سسٹم ہے جو خاص طور پر مختلف ذرائع سے ڈیٹا کی بڑی مقدار کو ذخیرہ کرنے، ترتیب دینے اور تجزیہ کرنے کے لیے ڈیزائن کیا گیا ہے۔ یہ اس طرح سے تشکیل دیا گیا ہے جو موثر ڈیٹا کی بازیافت اور پیچیدہ تجزیاتی سوالات کی حمایت کرتا ہے۔
یہ ایک مرکزی ذخیرے کے طور پر کام کرتا ہے جو مختلف آپریشنل سسٹمز سے ڈیٹا کو ضم کرتا ہے، جیسے کہ لین دین کے ڈیٹا بیس، CRM سسٹم، اور کسی تنظیم کے اندر ڈیٹا کے دیگر ذرائع۔
ڈیٹا کو تبدیل کیا جاتا ہے، صاف کیا جاتا ہے، اور ڈیٹا گودام میں لوڈ کیا جاتا ہے جو کہ تجزیاتی مقاصد کے لیے بہتر بنایا گیا ہے۔
27. بزنس انٹیلی جنس (BI)
کاروباری ذہانت سے مراد ڈیٹا اکٹھا کرنے، تجزیہ کرنے اور پیش کرنے کا عمل ہے جس سے کاروبار کو باخبر فیصلے کرنے اور قیمتی بصیرت حاصل کرنے میں مدد ملتی ہے۔ اس میں خام ڈیٹا کو بامعنی، قابل عمل معلومات میں تبدیل کرنے کے لیے مختلف ٹولز، ٹیکنالوجیز اور تکنیکوں کا استعمال شامل ہے۔
مثال کے طور پر، ایک کاروباری انٹیلی جنس سسٹم سب سے زیادہ منافع بخش مصنوعات کی شناخت، انوینٹری کی سطحوں کی نگرانی، اور کسٹمر کی ترجیحات کو ٹریک کرنے کے لیے سیلز ڈیٹا کا تجزیہ کر سکتا ہے۔
یہ ریونیو، کسٹمر کے حصول، یا پروڈکٹ کی کارکردگی جیسے اہم کارکردگی کے اشارے (KPIs) کے بارے میں حقیقی وقت کی بصیرت فراہم کر سکتا ہے، جس سے کاروبار کو ڈیٹا پر مبنی فیصلے کرنے اور اپنے کام کو بہتر بنانے کے لیے مناسب اقدامات کرنے کی اجازت مل سکتی ہے۔
بزنس انٹیلی جنس ٹولز میں اکثر ڈیٹا ویژولائزیشن، ایڈہاک استفسار، اور ڈیٹا ایکسپلوریشن کی صلاحیتیں شامل ہوتی ہیں۔ یہ ٹولز صارفین کو قابل بناتے ہیں، جیسے کاروباری تجزیہ کار یا مینیجرز، ڈیٹا کے ساتھ تعامل کرنے کے لیے، اس کو ٹکڑے ٹکڑے کر کے اسے کاٹتے ہیں، اور رپورٹس یا بصری نمائندگی تیار کرتے ہیں جو اہم بصیرت اور رجحانات کو نمایاں کرتی ہیں۔
28. پیش گوئی والے تجزیات
پیشین گوئی کا تجزیہ مستقبل کے واقعات یا نتائج کے بارے میں باخبر پیشین گوئیاں یا پیشین گوئیاں کرنے کے لیے اعداد و شمار اور شماریاتی تکنیکوں کو استعمال کرنے کا عمل ہے۔ اس میں تاریخی اعداد و شمار کا تجزیہ کرنا، نمونوں کی شناخت کرنا، اور مستقبل کے رجحانات، رویے، یا واقعات کا تخمینہ لگانے کے لیے ماڈلز بنانا شامل ہے۔
اس کا مقصد متغیرات کے درمیان تعلقات کو ننگا کرنا اور اس معلومات کو پیشین گوئیاں کرنے کے لیے استعمال کرنا ہے۔ یہ صرف ماضی کے واقعات کو بیان کرنے سے باہر ہے۔ اس کے بجائے، یہ تاریخی اعداد و شمار سے فائدہ اٹھاتا ہے تاکہ مستقبل میں کیا ہونے کا امکان ہو اسے سمجھنے اور اندازہ لگایا جا سکے۔
مثال کے طور پر، فنانس کے میدان میں، پیشن گوئی کے تجزیہ کا استعمال پیشین گوئی کے لیے کیا جا سکتا ہے۔ اسٹاک تاریخی مارکیٹ کے اعداد و شمار، اقتصادی اشارے، اور دیگر متعلقہ عوامل پر مبنی قیمتیں۔
مارکیٹنگ میں، اسے گاہک کے رویے اور ترجیحات کی پیشن گوئی کرنے کے لیے استعمال کیا جا سکتا ہے، ہدف بنائے گئے اشتہارات اور ذاتی نوعیت کی مارکیٹنگ کی مہمات کو فعال کرنا۔
صحت کی دیکھ بھال میں، پیشن گوئی کا تجزیہ بعض بیماریوں کے زیادہ خطرے والے مریضوں کی شناخت میں مدد کر سکتا ہے یا طبی تاریخ اور دیگر عوامل کی بنیاد پر دوبارہ داخلے کے امکان کی پیش گوئی کر سکتا ہے۔
29. نسخے کے تجزیات
نسخہ جاتی تجزیات کسی خاص صورتحال یا فیصلہ سازی کے منظر نامے میں اٹھائے جانے والے بہترین ممکنہ اقدامات کا تعین کرنے کے لیے ڈیٹا اور تجزیات کا اطلاق ہے۔
یہ وضاحتی اور پیش گوئی تجزیات مستقبل میں کیا ہو سکتا ہے اس کے بارے میں نہ صرف بصیرت فراہم کر کے بلکہ مطلوبہ نتیجہ حاصل کرنے کے لیے بہترین طریقہ کار کی سفارش بھی کرتا ہے۔
یہ تاریخی اعداد و شمار، پیشین گوئی کرنے والے ماڈلز، اور اصلاح کی تکنیکوں کو یکجا کرتا ہے تاکہ مختلف منظرناموں کی تقلید اور مختلف فیصلوں کے ممکنہ نتائج کا اندازہ لگایا جا سکے۔ یہ متعدد رکاوٹوں، مقاصد اور عوامل پر غور کرتا ہے تاکہ قابل عمل سفارشات تیار کی جا سکیں جو مطلوبہ نتائج کو زیادہ سے زیادہ یا خطرات کو کم سے کم کرتی ہیں۔
مثال کے طور پر، میں فراہمی کا سلسلہ انتظام، نسخہ جات کے تجزیات انوینٹری کی سطحوں، پیداواری صلاحیتوں، نقل و حمل کے اخراجات، اور کسٹمر کی مانگ کا تجزیہ کر سکتے ہیں تاکہ سب سے زیادہ موثر ڈسٹری بیوشن پلان کا تعین کیا جا سکے۔
یہ اخراجات کو کم کرنے اور بروقت فراہمی کو یقینی بنانے کے لیے وسائل کی مثالی تقسیم کی سفارش کر سکتا ہے، جیسے کہ انوینٹری ذخیرہ کرنے کے مقامات یا نقل و حمل کے راستے۔
30. ڈیٹا پر مبنی مارکیٹنگ
ڈیٹا سے چلنے والی مارکیٹنگ سے مراد مارکیٹنگ کی حکمت عملیوں، مہمات اور فیصلہ سازی کے عمل کو چلانے کے لیے ڈیٹا اور تجزیات کے استعمال کی مشق ہے۔
اس میں گاہک کے رویے، ترجیحات اور رجحانات کے بارے میں بصیرت حاصل کرنے کے لیے ڈیٹا کے مختلف ذرائع سے فائدہ اٹھانا اور اس معلومات کو مارکیٹنگ کی کوششوں کو بہتر بنانے کے لیے استعمال کرنا شامل ہے۔
یہ متعدد ٹچ پوائنٹس سے ڈیٹا اکٹھا کرنے اور اس کا تجزیہ کرنے پر توجہ مرکوز کرتا ہے، جیسے کہ ویب سائٹ کے تعاملات، سوشل میڈیا کی مصروفیت، کسٹمر ڈیموگرافکس، خریداری کی تاریخ، اور بہت کچھ۔ اس کے بعد اس ڈیٹا کو ہدف کے سامعین، ان کی ترجیحات اور ان کی ضروریات کے بارے میں ایک جامع تفہیم پیدا کرنے کے لیے استعمال کیا جاتا ہے۔
ڈیٹا کو بروئے کار لا کر، مارکیٹرز گاہک کی تقسیم، ہدف بندی، اور ذاتی نوعیت کے بارے میں باخبر فیصلے کر سکتے ہیں۔
وہ مخصوص کسٹمر سیگمنٹس کی نشاندہی کر سکتے ہیں جو مارکیٹنگ کی مہمات کے لیے مثبت جواب دینے کا زیادہ امکان رکھتے ہیں اور اس کے مطابق اپنے پیغامات اور پیشکشوں کو تیار کرتے ہیں۔
مزید برآں، ڈیٹا سے چلنے والی مارکیٹنگ مارکیٹنگ چینلز کو بہتر بنانے، سب سے مؤثر مارکیٹنگ مکس کا تعین کرنے، اور مارکیٹنگ کے اقدامات کی کامیابی کی پیمائش کرنے میں مدد کرتی ہے۔
مثال کے طور پر، ڈیٹا پر مبنی مارکیٹنگ کے نقطہ نظر میں خریداری کے رویے اور ترجیحات کے نمونوں کی شناخت کے لیے کسٹمر کے ڈیٹا کا تجزیہ کرنا شامل ہو سکتا ہے۔ ان بصیرت کی بنیاد پر، مارکیٹرز ذاتی نوعیت کے مواد اور پیشکشوں کے ساتھ ٹارگٹڈ مہمات بنا سکتے ہیں جو مخصوص گاہک کے حصوں کے ساتھ گونجتی ہوں۔
مسلسل تجزیہ اور اصلاح کے ذریعے، وہ اپنی مارکیٹنگ کی کوششوں کی تاثیر کی پیمائش کر سکتے ہیں اور وقت کے ساتھ ساتھ حکمت عملیوں کو بہتر بنا سکتے ہیں۔
31. ڈیٹا گورننس
ڈیٹا گورننس ایک فریم ورک اور طریقوں کا مجموعہ ہے جسے تنظیمیں اپنی زندگی بھر ڈیٹا کے مناسب انتظام، تحفظ اور سالمیت کو یقینی بنانے کے لیے اپناتی ہیں۔ اس میں ان عملوں، پالیسیوں اور طریقہ کاروں کو شامل کیا گیا ہے جو اس بات پر حکمرانی کرتے ہیں کہ کس طرح ڈیٹا اکٹھا کیا جاتا ہے، ذخیرہ کیا جاتا ہے، اس تک رسائی حاصل کی جاتی ہے، استعمال کیا جاتا ہے اور کسی تنظیم کے اندر اشتراک کیا جاتا ہے۔
اس کا مقصد ڈیٹا اثاثوں پر احتساب، ذمہ داری اور کنٹرول قائم کرنا ہے۔ یہ یقینی بناتا ہے کہ ڈیٹا درست، مکمل، مستقل اور قابل اعتماد ہے، جو تنظیموں کو باخبر فیصلے کرنے، ڈیٹا کے معیار کو برقرار رکھنے، اور ریگولیٹری تقاضوں کو پورا کرنے کے قابل بناتا ہے۔
ڈیٹا گورننس میں ڈیٹا مینجمنٹ کے لیے کردار اور ذمہ داریوں کی وضاحت، ڈیٹا کے معیارات اور پالیسیاں قائم کرنا، اور تعمیل کی نگرانی اور نفاذ کے لیے عمل کو نافذ کرنا شامل ہے۔ یہ ڈیٹا مینجمنٹ کے مختلف پہلوؤں پر توجہ دیتا ہے، بشمول ڈیٹا پرائیویسی، ڈیٹا سیکیورٹی، ڈیٹا کوالٹی، ڈیٹا کی درجہ بندی، اور ڈیٹا لائف سائیکل مینجمنٹ۔
مثال کے طور پر، ڈیٹا گورننس میں اس بات کو یقینی بنانے کے لیے طریقہ کار کو نافذ کرنا شامل ہو سکتا ہے کہ ذاتی یا حساس ڈیٹا کو قابل اطلاق رازداری کے ضوابط، جیسے جنرل ڈیٹا پروٹیکشن ریگولیشن (GDPR) کی تعمیل میں ہینڈل کیا جائے۔
اس میں ڈیٹا کے معیار کے معیارات قائم کرنا اور ڈیٹا کی توثیق کے عمل کو لاگو کرنا بھی شامل ہو سکتا ہے تاکہ یہ یقینی بنایا جا سکے کہ ڈیٹا درست اور قابل اعتماد ہے۔
32. ڈیٹا سیکیورٹی
ڈیٹا سیکیورٹی ہماری قیمتی معلومات کو غیر مجاز رسائی یا چوری سے محفوظ رکھنے کے بارے میں ہے۔ اس میں ڈیٹا کی رازداری، سالمیت اور دستیابی کے تحفظ کے لیے اقدامات کرنا شامل ہے۔
بنیادی طور پر، اس کا مطلب یہ یقینی بنانا ہے کہ صرف صحیح لوگ ہی ہمارے ڈیٹا تک رسائی حاصل کر سکتے ہیں، کہ یہ درست اور غیر تبدیل شدہ رہے، اور ضرورت پڑنے پر یہ دستیاب ہو۔
ڈیٹا سیکیورٹی کے حصول کے لیے مختلف حکمت عملیوں اور ٹیکنالوجیز کا استعمال کیا جاتا ہے۔ مثال کے طور پر، رسائی کے کنٹرول اور خفیہ کاری کے طریقے مجاز افراد یا سسٹمز تک رسائی کو محدود کرنے میں مدد کرتے ہیں، جس سے باہر کے لوگوں کے لیے ہمارے ڈیٹا تک رسائی مشکل ہو جاتی ہے۔
نگرانی کے نظام، فائر والز، اور دخل اندازی کا پتہ لگانے کے نظام سرپرست کے طور پر کام کرتے ہیں، ہمیں مشکوک سرگرمیوں سے آگاہ کرتے ہیں اور غیر مجاز رسائی کو روکتے ہیں۔
33 چیزیں انٹرنیٹ
چیزوں کا انٹرنیٹ (IoT) جسمانی اشیاء یا "چیزوں" کے نیٹ ورک سے مراد ہے جو انٹرنیٹ سے جڑے ہوئے ہیں اور ایک دوسرے کے ساتھ بات چیت کر سکتے ہیں۔ یہ روزمرہ کی چیزوں، آلات اور مشینوں کے ایک بڑے جال کی طرح ہے جو انٹرنیٹ کے ذریعے بات چیت کرکے معلومات کا اشتراک اور کام انجام دینے کے قابل ہے۔
آسان الفاظ میں، IoT میں مختلف اشیاء یا آلات کو "سمارٹ" صلاحیتیں دینا شامل ہے جو روایتی طور پر انٹرنیٹ سے منسلک نہیں تھے۔ ان اشیاء میں گھریلو آلات، پہننے کے قابل آلات، تھرموسٹیٹ، کاریں اور یہاں تک کہ صنعتی مشینری بھی شامل ہو سکتی ہے۔
ان اشیاء کو انٹرنیٹ سے جوڑ کر، وہ ڈیٹا اکٹھا اور شیئر کر سکتے ہیں، ہدایات وصول کر سکتے ہیں، اور خود مختاری سے یا صارف کے حکم کے جواب میں کام انجام دے سکتے ہیں۔
مثال کے طور پر، ایک سمارٹ تھرموسٹیٹ درجہ حرارت کی نگرانی کر سکتا ہے، ترتیبات کو ایڈجسٹ کر سکتا ہے، اور اسمارٹ فون ایپ کو توانائی کے استعمال کی رپورٹس بھیج سکتا ہے۔ پہننے کے قابل فٹنس ٹریکر آپ کی جسمانی سرگرمیوں کا ڈیٹا اکٹھا کر سکتا ہے اور تجزیہ کے لیے اسے کلاؤڈ بیسڈ پلیٹ فارم سے ہم آہنگ کر سکتا ہے۔
34. فیصلہ کن درخت
فیصلے کا درخت ایک بصری نمائندگی یا خاکہ ہے جو ہمیں فیصلے کرنے میں مدد کرتا ہے یا انتخاب یا شرائط کی ایک سیریز کی بنیاد پر عمل کا طریقہ طے کرتا ہے۔
یہ ایک فلو چارٹ کی طرح ہے جو مختلف اختیارات اور ان کے ممکنہ نتائج پر غور کرکے فیصلہ سازی کے عمل میں ہماری رہنمائی کرتا ہے۔
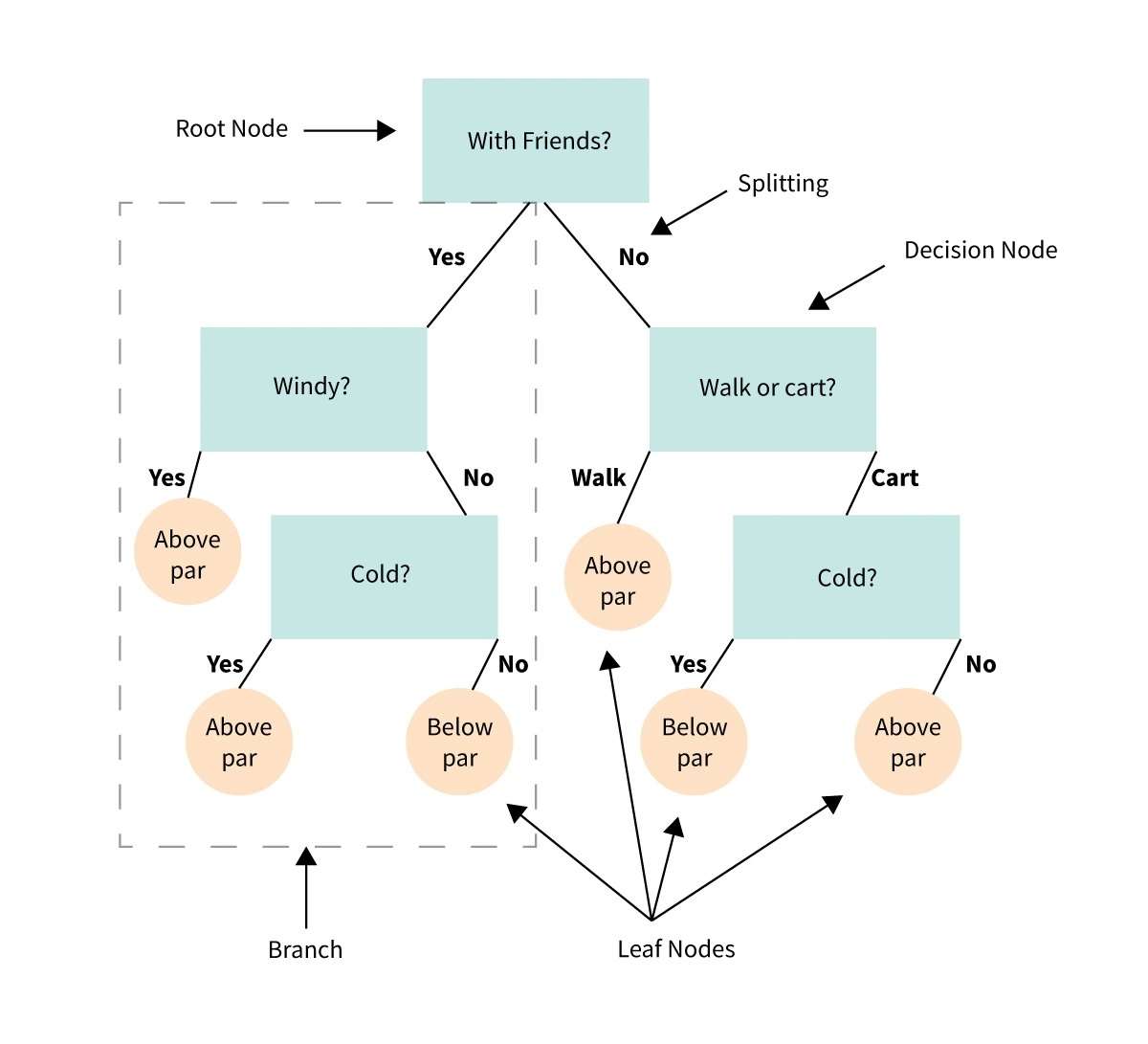
تصور کریں کہ آپ کو کوئی مسئلہ یا سوال ہے، اور آپ کو انتخاب کرنے کی ضرورت ہے۔
فیصلہ کا درخت فیصلہ کو چھوٹے مراحل میں تقسیم کرتا ہے، ایک ابتدائی سوال سے شروع ہوتا ہے اور ہر قدم پر حالات یا معیار کی بنیاد پر مختلف ممکنہ جوابات یا اعمال میں شاخیں ڈالتا ہے۔
35. علمی کمپیوٹنگ
سنجشتھاناتمک کمپیوٹنگ، سادہ الفاظ میں، کمپیوٹر سسٹمز یا ٹیکنالوجیز سے مراد ہے جو انسانی علمی صلاحیتوں کی نقل کرتی ہے، جیسے سیکھنا، استدلال، سمجھنا، اور مسئلہ حل کرنا۔
اس میں کمپیوٹر سسٹم بنانا شامل ہے جو معلومات کو اس طرح پروسیس اور تشریح کر سکے جو انسانی سوچ سے مشابہ ہو۔
علمی کمپیوٹنگ کا مقصد ایسی مشینیں تیار کرنا ہے جو زیادہ فطری اور ذہین انداز میں انسانوں کو سمجھ سکیں اور ان کے ساتھ تعامل کر سکیں۔ یہ سسٹم ڈیٹا کی وسیع مقدار کا تجزیہ کرنے، نمونوں کو پہچاننے، پیشین گوئیاں کرنے اور بامعنی بصیرت فراہم کرنے کے لیے بنائے گئے ہیں۔
کمپیوٹر کو انسانوں کی طرح سوچنے اور کام کرنے کی کوشش کے طور پر علمی کمپیوٹنگ کے بارے میں سوچئے۔
اس میں مصنوعی ذہانت، مشین لرننگ، قدرتی لینگویج پروسیسنگ، اور کمپیوٹر ویژن جیسی ٹیکنالوجیز کا فائدہ اٹھانا شامل ہے تاکہ کمپیوٹر کو ان کاموں کو انجام دینے کے قابل بنایا جا سکے جو روایتی طور پر انسانی ذہانت سے وابستہ تھے۔
36. کمپیوٹیشنل لرننگ تھیوری
کمپیوٹیشنل لرننگ تھیوری مصنوعی ذہانت کے دائرے میں ایک خصوصی شاخ ہے جو خاص طور پر ڈیٹا سے سیکھنے کے لیے بنائے گئے الگورتھم کی ترقی اور جانچ کے گرد گھومتی ہے۔
یہ فیلڈ الگورتھم بنانے کے لیے مختلف تکنیکوں اور طریقہ کاروں کی کھوج کرتا ہے جو بڑی مقدار میں معلومات کا تجزیہ اور پروسیسنگ کرکے اپنی کارکردگی کو خود مختار طور پر بہتر بناسکتے ہیں۔
ڈیٹا کی طاقت کو بروئے کار لاتے ہوئے، کمپیوٹیشنل لرننگ تھیوری کا مقصد ایسے نمونوں، رشتوں اور بصیرت کو سامنے لانا ہے جو مشینوں کو فیصلہ سازی کی صلاحیتوں کو بڑھانے اور کاموں کو زیادہ مؤثر طریقے سے انجام دینے کے قابل بناتی ہے۔
حتمی مقصد ایسے الگورتھم بنانا ہے جو مصنوعی ذہانت اور اس کے عملی استعمال کی ترقی میں اپنا کردار ادا کرتے ہوئے ان کے سامنے آنے والے ڈیٹا کی بنیاد پر موافقت، عمومی اور درست پیشین گوئیاں کر سکیں۔
37. ٹیورنگ ٹیسٹ
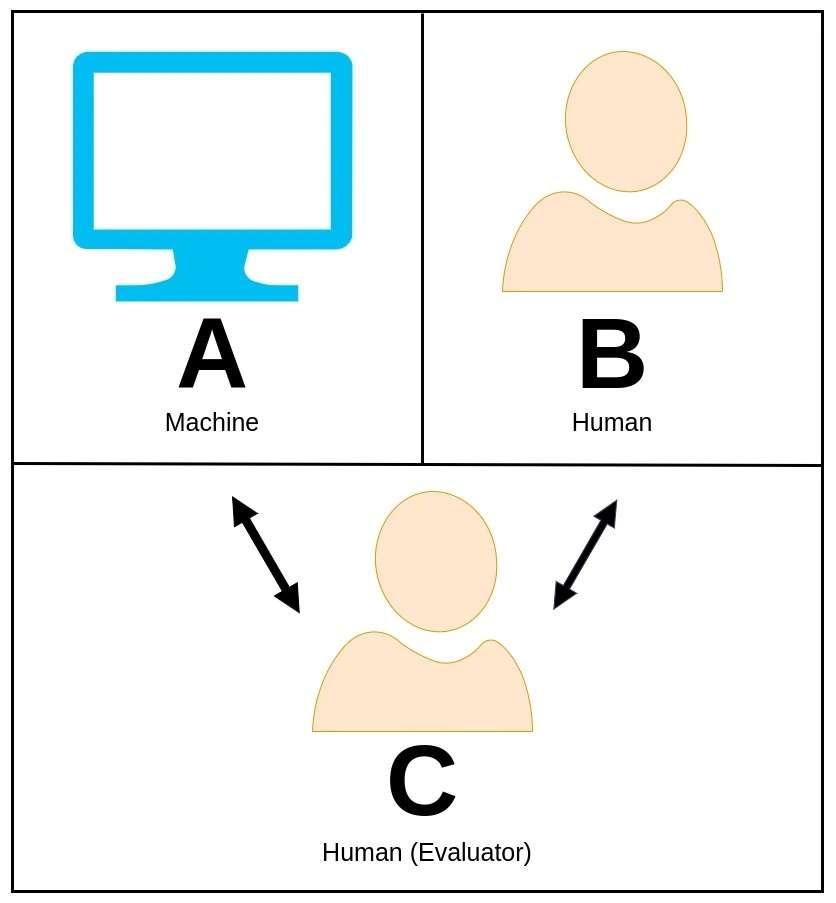
ٹورنگ ٹیسٹ، اصل میں شاندار ریاضی دان اور کمپیوٹر سائنس دان ایلن ٹورنگ نے تجویز کیا تھا، ایک دلکش تصور ہے جو اس بات کا اندازہ لگانے کے لیے استعمال کیا جاتا ہے کہ آیا کوئی مشین کسی انسان کے مقابلے میں ذہین رویے کی نمائش کر سکتی ہے، یا عملی طور پر اس سے الگ نہیں ہو سکتی۔
ٹیورنگ ٹیسٹ میں، ایک انسانی تشخیص کار مشین اور دوسرے انسانی شریک دونوں کے ساتھ فطری زبان میں گفتگو میں مشغول ہوتا ہے یہ جانے بغیر کہ کون سی مشین ہے۔
جانچ کرنے والے کا کردار یہ معلوم کرنا ہے کہ کون سا ادارہ مکمل طور پر ان کے جوابات کی بنیاد پر مشین ہے۔ اگر مشین جانچ کرنے والے کو قائل کرنے میں کامیاب ہو جاتی ہے کہ یہ انسانی ہم منصب ہے، تو کہا جاتا ہے کہ اس نے ٹورنگ ٹیسٹ پاس کر لیا ہے، اس طرح ذہانت کی ایک سطح کا مظاہرہ کرتی ہے جو انسان جیسی صلاحیتوں کا آئینہ دار ہے۔
ایلن ٹورنگ نے اس ٹیسٹ کو مشینی ذہانت کے تصور کو دریافت کرنے اور یہ سوال پیدا کرنے کے لیے پیش کیا کہ آیا مشینیں انسانی سطح کے ادراک کو حاصل کر سکتی ہیں۔
انسانی امتیاز کے لحاظ سے ٹیسٹ کو ترتیب دے کر، ٹورنگ نے مشینوں کے لیے ایسے رویے کو ظاہر کرنے کی صلاحیت کو اجاگر کیا جو اس قدر قابل یقین حد تک ذہین ہے کہ انھیں انسانوں سے الگ کرنا مشکل ہو جاتا ہے۔
ٹیورنگ ٹیسٹ نے مصنوعی ذہانت اور علمی سائنس کے شعبوں میں وسیع بحث اور تحقیق کو جنم دیا۔ اگرچہ ٹورنگ ٹیسٹ پاس کرنا ایک اہم سنگ میل ہے، لیکن یہ ذہانت کا واحد پیمانہ نہیں ہے۔
بہر حال، یہ ٹیسٹ ایک فکر انگیز معیار کے طور پر کام کرتا ہے، ایسی مشینوں کو تیار کرنے کے لیے جاری کوششوں کو تحریک دیتا ہے جو انسان جیسی ذہانت اور رویے کی تقلید کرنے کے قابل ہو اور ذہین ہونے کے معنی کی وسیع تر تحقیق میں تعاون کرے۔
38. کمک سیکھنا
کمک سیکھنا سیکھنے کی ایک قسم ہے جو آزمائش اور غلطی کے ذریعے ہوتی ہے، جہاں ایک "ایجنٹ" (جو کمپیوٹر پروگرام یا روبوٹ ہو سکتا ہے) اچھے برتاؤ کے لیے انعامات حاصل کرکے اور برے برتاؤ کے نتائج یا سزاؤں کا سامنا کرکے کام انجام دینا سیکھتا ہے۔
ایک ایسے منظر نامے کا تصور کریں جہاں ایجنٹ ایک مخصوص کام کو مکمل کرنے کی کوشش کر رہا ہو، جیسے کہ بھولبلییا کو نیویگیٹ کرنا۔ پہلے پہل، ایجنٹ کو صحیح راستہ معلوم نہیں ہوتا ہے، اس لیے وہ مختلف اقدامات آزماتا ہے اور مختلف راستوں کو تلاش کرتا ہے۔
جب یہ ایک اچھی کارروائی کا انتخاب کرتا ہے جو اسے مقصد کے قریب لے جاتا ہے، تو اسے ایک انعام ملتا ہے، جیسے کہ ایک ورچوئل "پیٹھ پر تھپکی۔" تاہم، اگر یہ ایک ناقص فیصلہ کرتا ہے جو ایک مردہ انجام کی طرف لے جاتا ہے یا اسے مقصد سے دور لے جاتا ہے، تو اسے سزا یا منفی رائے ملتی ہے۔
آزمائش اور غلطی کے اس عمل کے ذریعے، ایجنٹ کچھ اعمال کو مثبت یا منفی نتائج سے جوڑنا سیکھتا ہے۔ یہ آہستہ آہستہ اپنے انعامات کو زیادہ سے زیادہ کرنے اور سزاؤں کو کم کرنے کے لیے اعمال کی بہترین ترتیب کا پتہ لگاتا ہے، بالآخر اس کام میں زیادہ ماہر ہوتا ہے۔
کمک سیکھنے سے متاثر ہوتا ہے کہ کیسے انسان اور جانور ماحول سے رائے حاصل کرکے سیکھتے ہیں۔
اس تصور کو مشینوں پر لاگو کرنے سے، محققین کا مقصد ذہین نظام تیار کرنا ہے جو مثبت کمک اور منفی نتائج کے عمل کے ذریعے خود مختار طور پر موثر ترین طرز عمل کو دریافت کرکے مختلف حالات میں سیکھ سکتے ہیں اور ان کے مطابق ڈھال سکتے ہیں۔
39. ہستی نکالنا
ہستی نکالنے سے مراد ایک ایسا عمل ہے جس میں ہم متن کے ایک بلاک سے معلومات کے اہم ٹکڑوں کی شناخت اور نکالتے ہیں، جسے اداروں کے نام سے جانا جاتا ہے۔ یہ ادارے مختلف چیزیں ہو سکتی ہیں جیسے لوگوں کے نام، جگہوں کے نام، تنظیموں کے نام وغیرہ۔
آئیے تصور کریں کہ آپ کے پاس ایک خبر کے مضمون کو بیان کرنے والا پیراگراف ہے۔
ہستی نکالنے میں متن کا تجزیہ کرنا اور مخصوص بٹس کو چننا شامل ہوگا جو مختلف اداروں کی نمائندگی کرتے ہیں۔ مثال کے طور پر، اگر متن میں "جان سمتھ"، مقام "نیو یارک سٹی"، یا تنظیم "اوپن اے آئی" جیسے کسی شخص کے نام کا تذکرہ کیا گیا ہے، تو یہ وہ ہستی ہوں گی جن کی شناخت اور نکالنا ہمارا مقصد ہے۔
ہستی نکال کر، ہم بنیادی طور پر ایک کمپیوٹر پروگرام کو متن سے اہم عناصر کو پہچاننے اور الگ کرنے کی تعلیم دے رہے ہیں۔ یہ عمل ہمیں معلومات کو زیادہ مؤثر طریقے سے ترتیب دینے اور درجہ بندی کرنے کے قابل بناتا ہے، جس سے متنی ڈیٹا کی بڑی مقدار سے بصیرت کو تلاش کرنا، تجزیہ کرنا اور اخذ کرنا آسان ہو جاتا ہے۔
مجموعی طور پر، ہستی نکالنے سے ہمیں متن کے اندر اہم اداروں، جیسے لوگوں، مقامات اور تنظیموں کی نشاندہی کرنے، قیمتی معلومات کے اخراج کو ہموار کرنے اور متنی ڈیٹا کو پروسیس کرنے اور سمجھنے کی ہماری صلاحیت کو بڑھانے کے کام کو خودکار بنانے میں مدد ملتی ہے۔
40. لسانی تشریح
لسانی تشریح میں استعمال شدہ زبان کے بارے میں ہماری سمجھ اور تجزیہ کو بڑھانے کے لیے اضافی لسانی معلومات کے ساتھ متن کی افزودگی شامل ہے۔ یہ کسی متن کے مختلف حصوں میں مددگار لیبلز یا ٹیگز شامل کرنے جیسا ہے۔
جب ہم لسانی تشریح کرتے ہیں، تو ہم متن میں بنیادی الفاظ اور جملوں سے آگے بڑھ جاتے ہیں اور مخصوص عناصر کو لیبل لگانا یا ٹیگ کرنا شروع کر دیتے ہیں۔ مثال کے طور پر، ہم پارٹ آف سپیچ ٹیگز شامل کر سکتے ہیں، جو ہر لفظ کے گرائمیکل زمرے کی نشاندہی کرتے ہیں (جیسے اسم، فعل، صفت، وغیرہ)۔ اس سے ہمیں یہ سمجھنے میں مدد ملتی ہے کہ ہر لفظ جملے میں کیا کردار ادا کرتا ہے۔
لسانی تشریح کی ایک اور شکل کو ہستی کی شناخت کا نام دیا گیا ہے، جہاں ہم مخصوص نام شدہ اداروں کی شناخت اور لیبل لگاتے ہیں، جیسے لوگوں، مقامات، تنظیموں یا تاریخوں کے نام۔ یہ ہمیں متن سے اہم معلومات کو تیزی سے تلاش کرنے اور نکالنے کی اجازت دیتا ہے۔
ان طریقوں سے متن کی تشریح کرتے ہوئے، ہم زبان کی زیادہ منظم اور منظم نمائندگی بناتے ہیں۔ یہ مختلف قسم کی ایپلی کیشنز میں بے حد مفید ہو سکتا ہے۔ مثال کے طور پر، یہ صارف کے سوالات کے پیچھے کے ارادے کو سمجھ کر سرچ انجنوں کی درستگی کو بہتر بنانے میں مدد کرتا ہے۔ یہ مشینی ترجمہ، جذبات کا تجزیہ، معلومات نکالنے، اور بہت سے دوسرے قدرتی زبان کی پروسیسنگ کے کاموں میں بھی مدد کرتا ہے۔
لسانی تشریح محققین، ماہر لسانیات، اور ڈویلپرز کے لیے ایک اہم ٹول کے طور پر کام کرتی ہے، جو انہیں زبان کے نمونوں کا مطالعہ کرنے، زبان کے ماڈل بنانے، اور جدید ترین الگورتھم تیار کرنے کے قابل بناتی ہے جو متن کا بہتر تجزیہ اور سمجھ سکیں۔
41. ہائپر پیرامیٹر
In مشین لرننگ، ایک ہائپر پیرامیٹر ایک خاص ترتیب یا ترتیب کی طرح ہے جس کے بارے میں ہمیں ماڈل کو تربیت دینے سے پہلے فیصلہ کرنے کی ضرورت ہے۔ یہ ایسی چیز نہیں ہے جسے ماڈل ڈیٹا سے خود سیکھ سکتا ہے۔ اس کے بجائے، ہمیں اسے پہلے سے طے کرنا ہوگا۔
اسے ایک نوب یا سوئچ کے طور پر سوچیں جسے ہم ٹھیک ٹیون میں ایڈجسٹ کر سکتے ہیں کہ ماڈل کس طرح سیکھتا ہے اور پیش گوئیاں کرتا ہے۔ یہ ہائپر پیرامیٹر سیکھنے کے عمل کے مختلف پہلوؤں کو کنٹرول کرتے ہیں، جیسے کہ ماڈل کی پیچیدگی، تربیت کی رفتار، اور درستگی اور عام کرنے کے درمیان تجارت۔
مثال کے طور پر، آئیے ایک نیورل نیٹ ورک پر غور کریں۔ ایک اہم ہائپر پیرامیٹر نیٹ ورک میں پرتوں کی تعداد ہے۔ ہمیں اس بات کا انتخاب کرنا ہے کہ ہم نیٹ ورک کو کتنا گہرا بنانا چاہتے ہیں، اور یہ فیصلہ ڈیٹا میں پیچیدہ نمونوں کو حاصل کرنے کی اس کی صلاحیت کو متاثر کرتا ہے۔
دیگر عام ہائپر پیرامیٹرس میں سیکھنے کی شرح شامل ہوتی ہے، جو اس بات کا تعین کرتی ہے کہ ٹریننگ ڈیٹا کی بنیاد پر ماڈل اپنے اندرونی پیرامیٹرز کو کتنی جلدی ایڈجسٹ کرتا ہے، اور ریگولرائزیشن کی طاقت، جو یہ کنٹرول کرتی ہے کہ اوور فٹنگ کو روکنے کے لیے ماڈل پیچیدہ نمونوں پر کتنا جرمانہ عائد کرتا ہے۔
ان ہائپر پیرامیٹرز کو درست طریقے سے ترتیب دینا بہت ضروری ہے کیونکہ وہ ماڈل کی کارکردگی اور طرز عمل کو نمایاں طور پر متاثر کر سکتے ہیں۔ اس میں اکثر تھوڑا سا آزمائش اور غلطی شامل ہوتی ہے، مختلف اقدار کے ساتھ تجربہ کرنا اور یہ مشاہدہ کرنا کہ وہ توثیق ڈیٹاسیٹ پر ماڈل کی کارکردگی کو کیسے متاثر کرتے ہیں۔
42. میٹا ڈیٹا
میٹا ڈیٹا سے مراد اضافی معلومات ہے جو دوسرے ڈیٹا کے بارے میں تفصیلات فراہم کرتی ہے۔ یہ ٹیگز یا لیبلز کے سیٹ کی طرح ہے جو ہمیں مزید سیاق و سباق فراہم کرتے ہیں یا مرکزی ڈیٹا کی خصوصیات کو بیان کرتے ہیں۔
جب ہمارے پاس ڈیٹا ہوتا ہے، چاہے وہ دستاویز ہو، تصویر ہو، ویڈیو ہو، یا کسی اور قسم کی معلومات ہو، میٹا ڈیٹا اس ڈیٹا کے اہم پہلوؤں کو سمجھنے میں ہماری مدد کرتا ہے۔
مثال کے طور پر، کسی دستاویز میں، میٹا ڈیٹا میں مصنف کا نام، اس کی تخلیق کی تاریخ، یا فائل کی شکل جیسی تفصیلات شامل ہو سکتی ہیں۔ تصویر کی صورت میں، میٹا ڈیٹا ہمیں وہ مقام بتا سکتا ہے جہاں اسے لیا گیا تھا، کیمرے کی سیٹنگز استعمال کی گئی تھیں، یا یہاں تک کہ اسے کس تاریخ اور وقت کیپچر کیا گیا تھا۔
میٹا ڈیٹا ڈیٹا کو زیادہ مؤثر طریقے سے ترتیب دینے، تلاش کرنے اور اس کی تشریح کرنے میں ہماری مدد کرتا ہے۔ معلومات کے ان وضاحتی ٹکڑوں کو شامل کرنے سے، ہم پورے مواد کو کھودنے کے بغیر فوری طور پر مخصوص فائلوں کو تلاش کر سکتے ہیں یا ان کی اصلیت، مقصد یا سیاق و سباق کو سمجھ سکتے ہیں۔
43. جہتی کمی
جہت میں کمی ایک ایسی تکنیک ہے جو ڈیٹاسیٹ کو آسان بنانے کے لیے اس میں موجود خصوصیات یا متغیرات کی تعداد کو کم کر کے استعمال کرتی ہے۔ یہ ڈیٹا سیٹ میں معلومات کو کم کرنے یا اس کا خلاصہ کرنے جیسا ہے تاکہ اسے مزید قابل انتظام اور اس کے ساتھ کام کرنا آسان ہو۔
تصور کریں کہ آپ کے پاس ڈیٹاسیٹ ہے جس میں متعدد کالم یا صفات موجود ہیں جو ڈیٹا پوائنٹس کی مختلف خصوصیات کی نمائندگی کرتے ہیں۔ ہر کالم مشین لرننگ الگورتھم کی پیچیدگی اور کمپیوٹیشنل تقاضوں میں اضافہ کرتا ہے۔
کچھ معاملات میں، زیادہ تعداد میں طول و عرض ڈیٹا میں معنی خیز نمونوں یا رشتوں کو تلاش کرنا مشکل بنا سکتا ہے۔
جہت میں کمی ڈیٹاسیٹ کو کم جہتی نمائندگی میں تبدیل کر کے اس مسئلے کو حل کرنے میں مدد کرتی ہے جبکہ زیادہ سے زیادہ متعلقہ معلومات کو برقرار رکھتی ہے۔ اس کا مقصد بے کار یا کم معلوماتی جہتوں کو ترک کرتے ہوئے ڈیٹا میں سب سے اہم پہلوؤں یا تغیرات کو حاصل کرنا ہے۔
44. متن کی درجہ بندی
متن کی درجہ بندی ایک ایسا عمل ہے جس میں متن کے بلاکس کو ان کے مواد یا معنی کی بنیاد پر مخصوص لیبل یا زمرے تفویض کرنا شامل ہے۔ یہ مزید تجزیہ یا فیصلہ سازی کی سہولت کے لیے متنی معلومات کو مختلف گروپوں یا کلاسوں میں ترتیب دینے یا ترتیب دینے جیسا ہے۔
آئیے ای میل کی درجہ بندی کی ایک مثال پر غور کریں۔ اس منظر نامے میں، ہم اس بات کا تعین کرنا چاہتے ہیں کہ آیا آنے والا ای میل اسپام ہے یا غیر اسپام (جسے ہیم بھی کہا جاتا ہے)۔ متن کی درجہ بندی الگورتھم ای میل کے مواد کا تجزیہ کرتے ہیں اور اس کے مطابق اسے ایک لیبل تفویض کرتے ہیں۔
اگر الگورتھم اس بات کا تعین کرتا ہے کہ ای میل عام طور پر اسپام سے وابستہ خصوصیات کو ظاہر کرتا ہے، تو یہ لیبل "سپیم" تفویض کرتا ہے۔ اس کے برعکس، اگر ای میل جائز اور غیر سپیمی دکھائی دیتی ہے، تو یہ "غیر سپیم" یا "ہیم" کا لیبل تفویض کرتی ہے۔
متن کی درجہ بندی ای میل فلٹرنگ کے علاوہ مختلف ڈومینز میں ایپلیکیشنز کو تلاش کرتی ہے۔ اس کا استعمال جذباتی تجزیہ میں کسٹمر کے جائزوں (مثبت، منفی، یا غیر جانبدار) میں اظہار خیال کرنے کے لیے کیا جاتا ہے۔
خبروں کے مضامین کو مختلف عنوانات یا زمروں میں درجہ بندی کیا جا سکتا ہے جیسے کھیل، سیاست، تفریح وغیرہ۔ کسٹمر سپورٹ چیٹ لاگز کو حل کیے جانے والے ارادے یا مسئلے کی بنیاد پر درجہ بندی کیا جا سکتا ہے۔
45. کمزور AI
کمزور AI، جسے تنگ AI بھی کہا جاتا ہے، سے مراد مصنوعی ذہانت کے نظام ہیں جو مخصوص کاموں یا افعال کو انجام دینے کے لیے ڈیزائن اور پروگرام کیے گئے ہیں۔ انسانی ذہانت کے برعکس، جس میں علمی صلاحیتوں کی ایک وسیع رینج شامل ہے، کمزور AI کسی خاص ڈومین یا کام تک محدود ہے۔
کمزور AI کو خصوصی سافٹ ویئر یا مشینوں کے طور پر سوچیں جو مخصوص ملازمتوں کو انجام دینے میں بہترین ہیں۔ مثال کے طور پر، ایک شطرنج کھیلنے والا AI پروگرام کھیل کے حالات کا تجزیہ کرنے، چالوں کو حکمت عملی بنانے اور انسانی کھلاڑیوں کے خلاف مقابلہ کرنے کے لیے بنایا جا سکتا ہے۔
ایک اور مثال تصویر کی شناخت کا نظام ہے جو تصاویر یا ویڈیوز میں اشیاء کی شناخت کر سکتا ہے۔
یہ AI نظام اپنی مہارت کے مخصوص شعبوں میں بہترین کارکردگی کے لیے تربیت یافتہ اور بہتر بنائے گئے ہیں۔ وہ اپنے کاموں کو مؤثر طریقے سے انجام دینے کے لیے الگورتھم، ڈیٹا، اور پہلے سے طے شدہ اصولوں پر انحصار کرتے ہیں۔
تاہم، ان کے پاس عمومی ذہانت نہیں ہے جو انہیں اپنے مقرر کردہ ڈومین سے باہر کاموں کو سمجھنے یا انجام دینے کی اجازت دیتی ہے۔
46. مضبوط AI
مضبوط AI، جسے جنرل AI یا مصنوعی جنرل انٹیلی جنس (AGI) کے نام سے بھی جانا جاتا ہے، مصنوعی ذہانت کی ایک شکل سے مراد ہے جو کسی بھی دانشورانہ کام کو سمجھنے، سیکھنے اور انجام دینے کی صلاحیت رکھتی ہے جسے انسان کر سکتا ہے۔
کمزور AI کے برعکس، جو مخصوص کاموں کے لیے ڈیزائن کیا گیا ہے، مضبوط AI کا مقصد انسان جیسی ذہانت اور علمی صلاحیتوں کو نقل کرنا ہے۔ یہ ایسی مشینیں یا سافٹ ویئر بنانے کی کوشش کرتا ہے جو نہ صرف خصوصی کاموں میں سبقت لے بلکہ وسیع تر فکری چیلنجوں سے نمٹنے کے لیے وسیع تر فہم اور موافقت کے حامل ہوں۔
مضبوط AI کا مقصد ایسے نظاموں کو تیار کرنا ہے جو استدلال کر سکیں، پیچیدہ معلومات کو سمجھ سکیں، تجربے سے سیکھ سکیں، فطری زبان کی گفتگو میں مشغول ہو سکیں، تخلیقی صلاحیتوں کو ظاہر کر سکیں، اور انسانی ذہانت سے وابستہ دیگر خصوصیات کو ظاہر کر سکیں۔
جوہر میں، یہ ایسے AI سسٹمز بنانے کی خواہش رکھتا ہے جو انسانی سطح کی سوچ اور متعدد ڈومینز میں مسائل کو حل کرنے کی نقل یا نقل کر سکے۔
47. فارورڈ چیننگ
فارورڈ چیننگ استدلال یا منطق کا ایک طریقہ ہے جو دستیاب اعداد و شمار سے شروع ہوتا ہے اور اسے نئے نتائج اخذ کرنے کے لیے استعمال کرتا ہے۔ یہ آگے بڑھنے اور اضافی بصیرت تک پہنچنے کے لیے ہاتھ میں موجود معلومات کا استعمال کرکے نقطوں کو جوڑنے جیسا ہے۔
تصور کریں کہ آپ کے پاس اصول یا حقائق کا ایک مجموعہ ہے، اور آپ نئی معلومات حاصل کرنا چاہتے ہیں یا ان کی بنیاد پر مخصوص نتائج پر پہنچنا چاہتے ہیں۔ فارورڈ چیننگ ابتدائی ڈیٹا کی جانچ کرکے اور اضافی حقائق یا نتائج اخذ کرنے کے لیے منطقی اصولوں کو لاگو کرکے کام کرتی ہے۔
آسان بنانے کے لیے، آئیے اس بات کا تعین کرنے کے ایک سادہ منظر نامے پر غور کریں کہ موسمی حالات کی بنیاد پر کیا پہننا ہے۔ آپ کے پاس ایک اصول ہے جو کہتا ہے، "اگر بارش ہو رہی ہے تو چھتری لائیں،" اور ایک اور قاعدہ جو کہتا ہے کہ "اگر سردی ہو تو جیکٹ پہنیں۔" اب، اگر آپ دیکھتے ہیں کہ واقعی بارش ہو رہی ہے، تو آپ یہ اندازہ لگانے کے لیے فارورڈ چیننگ کا استعمال کر سکتے ہیں کہ آپ کو چھتری لانی چاہیے۔
48. پسماندہ زنجیر
پسماندہ سلسلہ بندی ایک استدلال کا طریقہ ہے جو کسی مطلوبہ نتیجے یا مقصد سے شروع ہوتا ہے اور اس نتیجے پر پہنچنے کے لیے درکار ڈیٹا یا حقائق کا تعین کرنے کے لیے پیچھے کی طرف کام کرتا ہے۔ یہ مطلوبہ نتائج سے لے کر اسے حاصل کرنے کے لیے درکار ابتدائی معلومات تک اپنے قدموں کا سراغ لگانے کے مترادف ہے۔
پیچھے کی زنجیر کو سمجھنے کے لیے، آئیے ایک سادہ مثال پر غور کریں۔ فرض کریں کہ آپ یہ طے کرنا چاہتے ہیں کہ آیا تیراکی کے لیے جانا مناسب ہے۔ مطلوبہ نتیجہ یہ ہے کہ آیا کچھ شرائط کی بنیاد پر تیراکی مناسب ہے یا نہیں۔
حالات کے ساتھ شروع کرنے کے بجائے، پسماندہ سلسلہ بندی اختتام کے ساتھ شروع ہوتی ہے اور معاون ڈیٹا کو تلاش کرنے کے لیے پیچھے کی طرف کام کرتی ہے۔
اس صورت میں، پسماندہ زنجیروں میں "کیا موسم گرم ہے؟" جیسے سوالات پوچھنا شامل ہوگا۔ اگر جواب ہاں میں ہے، تو آپ پوچھیں گے، "کیا کوئی تالاب دستیاب ہے؟" اگر جواب دوبارہ ہاں میں ہے، تو آپ مزید سوالات پوچھیں گے جیسے، "کیا تیراکی کے لیے کافی وقت ہے؟"
بار بار ان سوالات کے جوابات دے کر اور پیچھے کی طرف کام کرتے ہوئے، آپ ان ضروری شرائط کا تعین کر سکتے ہیں جن کو پورا کرنے کی ضرورت ہے تاکہ تیراکی کے لیے جانے کے نتیجے میں مدد ملے۔
49. تحقیقی
ہوورسٹک، سادہ الفاظ میں، ایک عملی اصول یا حکمت عملی ہے جو ہمیں فیصلے کرنے یا مسائل کو حل کرنے میں مدد کرتی ہے، عام طور پر ہمارے ماضی کے تجربات یا وجدان کی بنیاد پر۔ یہ ایک ذہنی شارٹ کٹ کی طرح ہے جو ہمیں کسی طویل یا مکمل عمل سے گزرے بغیر فوری طور پر ایک معقول حل تلاش کرنے کی اجازت دیتا ہے۔
جب پیچیدہ حالات یا کاموں کا سامنا کرنا پڑتا ہے تو، ہیورسٹکس رہنما اصولوں یا "انگوٹھے کے اصول" کے طور پر کام کرتے ہیں جو فیصلہ سازی کو آسان بناتے ہیں۔ وہ ہمیں عمومی رہنما خطوط یا حکمت عملی فراہم کرتے ہیں جو بعض حالات میں اکثر کارآمد ہوتے ہیں، حالانکہ وہ بہترین حل کی ضمانت نہیں دے سکتے ہیں۔
مثال کے طور پر، آئیے ایک پرہجوم علاقے میں پارکنگ کی جگہ تلاش کرنے کے لیے ایک جائزہ پر غور کریں۔ ہر دستیاب جگہ کا باریک بینی سے تجزیہ کرنے کے بجائے، آپ پارک کی گئی گاڑیوں کے انجنوں کے ساتھ تلاش کرنے کے ہورسٹک پر انحصار کر سکتے ہیں۔
اس سے اندازہ لگایا گیا ہے کہ یہ کاریں جانے والی ہیں، جس سے دستیاب جگہ تلاش کرنے کے امکانات بڑھ جاتے ہیں۔
50. قدرتی زبان کی ماڈلنگ
قدرتی زبان کی ماڈلنگ، سادہ الفاظ میں، کمپیوٹر ماڈلز کو انسانی زبان کو سمجھنے اور تخلیق کرنے کی تربیت دینے کا عمل ہے جو کہ انسانوں کے بات چیت کے طریقے سے ملتا جلتا ہے۔ اس میں کمپیوٹر کو فطری اور بامعنی انداز میں پروسیسنگ، تشریح، اور ٹیکسٹ تیار کرنا سکھانا شامل ہے۔
قدرتی زبان کی ماڈلنگ کا مقصد کمپیوٹرز کو انسانی زبان کو اس طرح سمجھنے اور تخلیق کرنے کے قابل بنانا ہے جو روانی، مربوط اور سیاق و سباق کے لحاظ سے متعلقہ ہو۔
اس میں متنی اعداد و شمار، جیسے کتابیں، مضامین، یا بات چیت، زبان کے نمونوں، ڈھانچے اور اصطلاحات کو سیکھنے کے لیے تربیتی ماڈلز شامل ہیں۔
ایک بار تربیت حاصل کرنے کے بعد، یہ ماڈلز زبان سے متعلق مختلف کام انجام دے سکتے ہیں، جیسے زبان کا ترجمہ، متن کا خلاصہ، سوال کا جواب دینا، چیٹ بوٹ کے تعاملات وغیرہ۔
وہ جملوں کے معنی اور سیاق و سباق کو سمجھ سکتے ہیں، متعلقہ معلومات نکال سکتے ہیں، اور ایسا متن تیار کر سکتے ہیں جو گرائمر کے لحاظ سے درست اور مربوط ہو۔





جواب دیجئے