کی میز کے مندرجات[چھپائیں][دکھائیں]
ڈیٹا آپ کے آس پاس ہر جگہ موجود ہے۔ حقیقی معنوں میں، یہ آپ کے کاروبار کے ہر پہلو کو متاثر کرتا ہے۔ ایسا محسوس ہو سکتا ہے کہ جب آپ اپنے ڈیٹا کو ہینڈل کرنے کے فیصلوں میں مصروف ہوں تو یہ آپ کے کاروبار کی کتنی اچھی طرح سے خدمت کر رہا ہے اس کی تفصیلات کا جائزہ لینے کے لیے کافی وقت نہیں ہے۔
اس کا مشاہدہ کریں۔ آپ کی تنظیم 24 گھنٹے ڈیٹا استعمال کر رہی ہے۔ لہذا یہ سمجھنا کہ یہ کہاں سے آیا، یہ وہاں کیسے پہنچا، اور یہ کمپنی کے ذریعے کیسے آگے بڑھ رہا ہے اس کی قدر کو سمجھنے کے لیے بہت ضروری ہے۔
اس صورت حال میں ڈیٹا نسب اہم ہو جاتا ہے۔ یہ سمجھنا آسان ہے کہ ڈیٹا کیسے بنایا گیا، یہ کہاں سے آیا، اور یہ کہاں جا رہا ہے جب ہم ڈیٹا کی ابتدا، منتقلی اور تبدیلیوں کو ٹریک کر سکتے ہیں۔
اس پوسٹ میں، ہم ڈیٹا لائنیج کو قریب سے دیکھیں گے، یہ کیسے کام کرتا ہے، اس کے استعمال کے معاملات، تکنیک، اور بہت کچھ۔
ڈیٹا نسب کیا ہے؟
ڈیٹا نسب ڈیجیٹل پاسپورٹ کی ایک قسم کا کام کرتا ہے۔ یہ ڈیٹا ٹرپ کا سب سے جامع اکاؤنٹ ہے، جس میں اس کے تمام اسٹاپس، ڈیٹور، اور اس کی اصل سے لے کر اس کی حتمی منزل تک کی تبدیلیوں کی تفصیل ہے۔
In جوہر، ڈیٹا نسب بہت سارے سسٹمز اور پلیٹ فارمز میں ڈیٹا کے ایک ٹکڑے کی ابتدا، ترمیم اور استعمال کی وضاحت کرتا ہے۔ یہ صارفین کو ڈیٹا کیسے تیار کیا گیا، کہاں سے آیا اور اسے کیسے استعمال کیا گیا اس بارے میں معلومات دے کر ایک جاسوس کے ٹول کے طور پر کام کرتا ہے۔ یہ معلومات صارفین کو کسی بھی ممکنہ مسائل کو پہچاننے اور حل کرنے کے قابل بناتی ہے۔
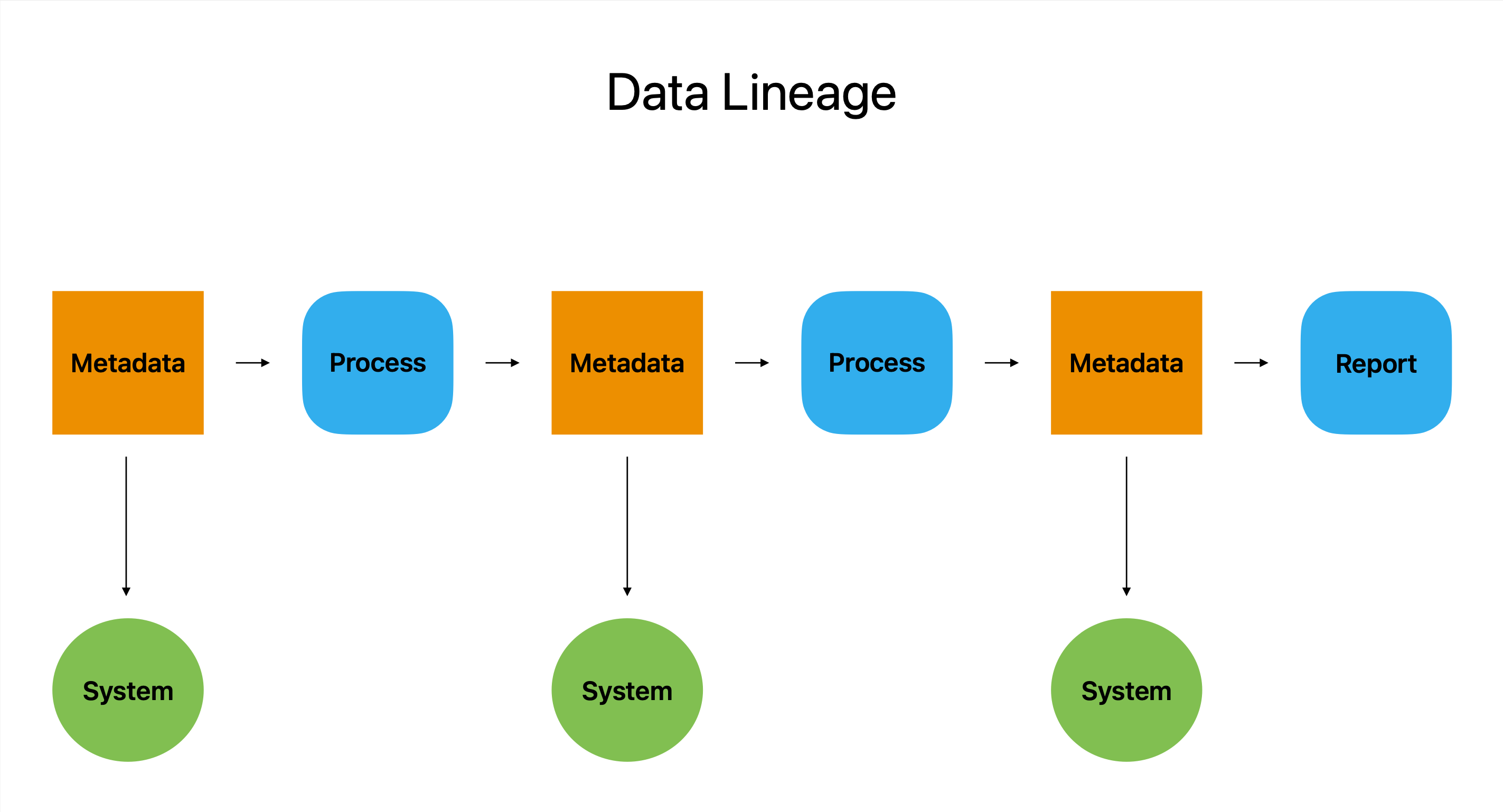
ڈیٹا نسب ان کمپنیوں کے لیے ایک انمول وسیلہ ہے جو اپنے آپریشنز کو چلانے کے لیے ڈیٹا پر انحصار کرتے ہیں کیونکہ یہ صارفین کو اہم سوالات جیسے کہ کون، کیا، کب اور کہاں کے جوابات دینے کی اجازت دیتا ہے۔
ڈیٹا نسب، سادہ الفاظ میں، حتمی ڈیٹا ٹریل ہے جو ڈیٹا کی درستگی، مکمل ہونے اور مستقل مزاجی کی ضمانت دیتا ہے جبکہ ڈیٹا کے مکمل راستے کا واضح اور مختصر تناظر پیش کرتا ہے۔
ڈیٹا لائنیج کیسے کام کرتا ہے؟
ڈیٹا نسب ایک سڑک کا نقشہ ہے جو ہمیں اعداد و شمار کے ایک ٹکڑے کو اس کے نقطہ آغاز سے اس کے اختتام تک کی پیروی کرنے کے قابل بناتا ہے۔ ایک مسافر کے طور پر ڈیٹا پوائنٹ پر غور کریں، اور اس کے پاسپورٹ کو اس کا ڈیٹا نسب سمجھیں کہ یہ کیسے کام کرتا ہے۔
ڈیٹا کے ذرائع، ڈیٹا ٹرانسفارمیشن، ڈیٹا اسٹوریج، اور ڈیٹا آؤٹ پٹ پاسپورٹ کے چار بنیادی اجزاء بناتے ہیں۔
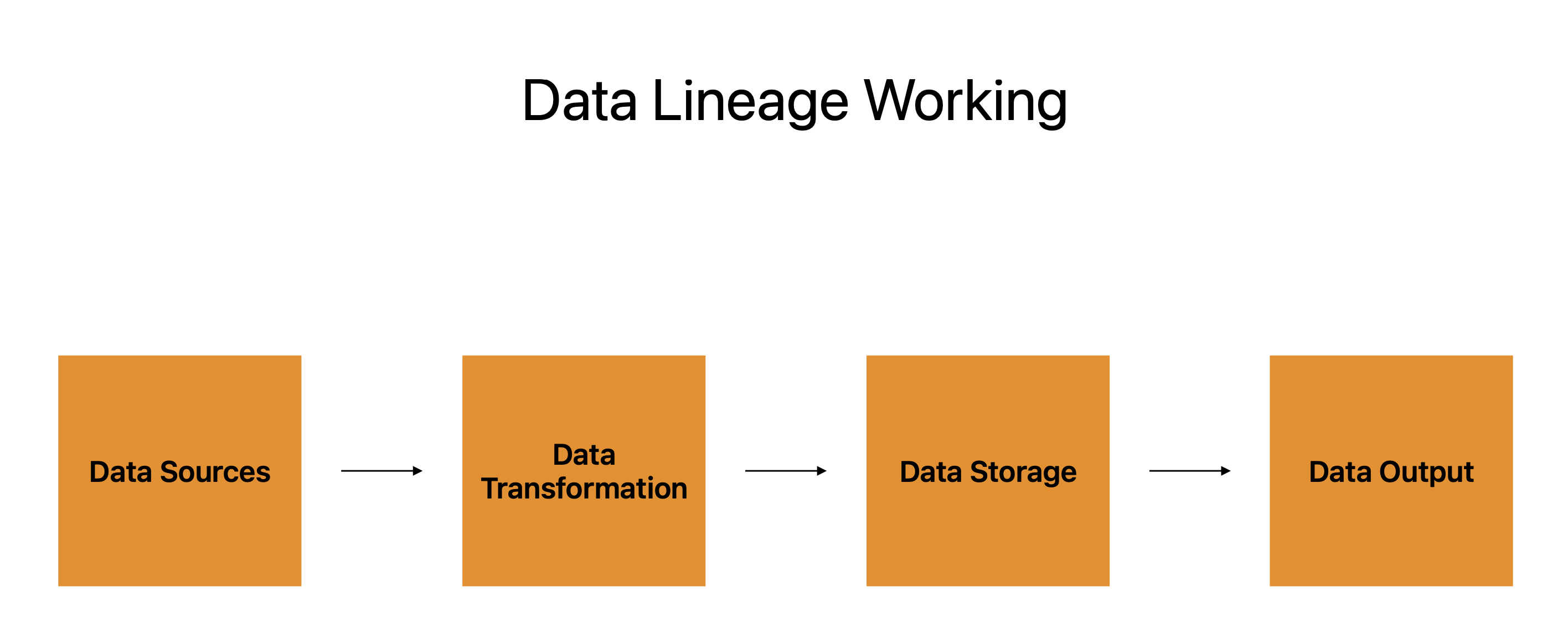
بہت سے سسٹمز، ایپلی کیشنز، اور پلیٹ فارمز جن سے ڈیٹا نکلتا ہے، ڈیٹا کے ذرائع سے ظاہر ہوتا ہے، جو ڈیٹا کے سفر کے لیے نقطہ آغاز کے طور پر کام کرتے ہیں۔ ڈیٹا کی تبدیلی اس کے بعد کا مرحلہ ہے، اور ڈیٹا کا نسب ان ذرائع سے ڈیٹا کی ترقی کو چارٹ کرتا ہے۔
ڈیٹا ٹرانسفارمیشن سے مراد صارف کی ضروریات کو پورا کرنے کے لیے ڈیٹا کی تشکیل، ترمیم اور ہیرا پھیری ہے۔ یہ ڈیٹا کے ٹرپ کے دوران ریسٹ اسٹاپ کے طور پر کام کرتا ہے، اسے اگلی ٹانگ کے لیے تیار کرتا ہے۔
ڈیٹا کو اس کے آخری مقام پر جانے سے پہلے محفوظ کیا جاتا ہے۔ اسے کلاؤڈ سرورز، ڈیٹا بیس، یا کسی اور قسم کے اسٹوریج ڈیوائس پر رکھا جا سکتا ہے۔ ڈیٹا نسب اس بات کا سراغ لگاتا ہے کہ ڈیٹا کہاں محفوظ کیا جاتا ہے، ساتھ ہی یہ کیسے محفوظ، بیک اپ اور بازیافت ہوتا ہے۔
آخری مرحلہ ڈیٹا آؤٹ پٹ ہے، جہاں ڈیٹا کو استعمال کرنے کے لیے بھیجا جاتا ہے۔ رپورٹس، انفوگرافکس، یا کسی دوسرے قسم کے ڈیٹا پروڈکٹ کو اسے پیش کرنے کے لیے استعمال کیا جا سکتا ہے۔ ڈیٹا نسب آؤٹ پٹ پر نظر رکھتا ہے اور ڈیٹا کی مستقل مزاجی، درستگی اور مکمل ہونے کی ضمانت دیتا ہے۔
ڈیٹا نسب بنیادی طور پر ڈیٹا کے سفر کے ہر مرحلے کو، اس کے آغاز سے لے کر اس کے آؤٹ پٹ تک، اور اس بات کو یقینی بنا کر کام کرتا ہے کہ یہ ہر طرح سے قابل اعتماد، مستقل اور درست رہے۔ ڈیٹا نسب تنظیموں کو ڈیٹا کے وجود کا مکمل نظریہ دے کر تعلیم یافتہ فیصلے کرنے، مسائل کو حل کرنے اور قانونی ذمہ داریوں پر عمل کرنے میں مدد کرتا ہے۔
ڈیٹا اثاثوں کو سمجھنے کے لیے اور وہ ڈیٹا پائپ لائن کے ذریعے کیسے منتقل ہوتے ہیں، میٹا ڈیٹا ڈیٹا نسب کے عمل کا ایک اہم حصہ ہے۔
آپ دیکھ سکتے ہیں کہ ڈیٹا لائنیج ٹولز کا استعمال کرتے ہوئے تنظیم کے اندر ڈیٹا کو کس طرح تبدیل اور استعمال کیا جاتا ہے، جو ڈیٹا کے بہاؤ کی بصری عکاسی فراہم کرنے کے لیے میٹا ڈیٹا کا فائدہ اٹھاتے ہیں۔ یہ صارفین کو اعداد و شمار کی صلاحیت کا اندازہ لگانے کے قابل بناتا ہے جس سے انہیں بہتر طور پر باخبر فیصلے کرنے میں مدد ملتی ہے۔
ڈیٹا نسب کی اقسام
ڈیٹا نسب کی تین بنیادی شکلیں ہیں: فارورڈ ڈیٹا نسب، پسماندہ ڈیٹا نسب، اور دو طرفہ ڈیٹا نسب۔
فارورڈ ڈیٹا نسب
ایک طرفہ گلی کی طرح، فارورڈ ڈیٹا نسب میں ڈیٹا کے ایک ٹکڑے کو اس کے نقطہ آغاز سے اس کے اختتامی مقام تک ٹریک کرنا شامل ہے۔ ڈیٹا کے منبع سے شروع ہو کر، یہ ڈیٹا کی پیروی کرتا ہے کیونکہ یہ اپنے آؤٹ پٹ تک پہنچنے کے لیے کئی تبدیلیوں اور اسٹوریج سسٹم سے گزرتا ہے۔
ڈیٹا کی پروسیسنگ اور تبدیلی کے ساتھ ساتھ راستے میں پیدا ہونے والی کسی بھی پریشانی کو سمجھنا اس قسم کا ڈیٹا نسب رکھنے سے آسان ہے۔ ہر قدم اگلے کی طرف لے جاتا ہے۔ یہ روٹی کے ٹکڑوں کی پگڈنڈی کی پیروی کرنے جیسا ہے۔
پسماندہ ڈیٹا نسب
پسماندہ ڈیٹا نسب ریورس میں سفر کی طرح ہے جہاں ہم ڈیٹا کے آؤٹ پٹ کو اس کے ماخذ پر واپس ٹریس کرتے ہیں۔ یہ عمل ڈیٹا کے آخری مقام سے شروع ہوتا ہے اور ڈیٹا کے منبع تک پہنچنے تک مختلف اسٹوریج اور تبدیلی کی تکنیکوں کے ذریعے پیچھے کی طرف جاتا ہے۔
ڈیٹا کے اصل ماخذ کی شناخت، اس کی تبدیلی کی تفہیم، اور اس کی درستگی اور مکمل ہونے کی تصدیق اس قسم کے ڈیٹا نسب کی مدد سے ممکن ہے۔ یہ ایک جاسوس کے آلے کی طرح کام کرتا ہے، جو ہمیں ڈیٹا کے پیچھے کی راہ پر چلنے کی اجازت دیتا ہے۔
دو طرفہ ڈیٹا نسب
دو طرفہ گلی، دو طرفہ ڈیٹا نسب آگے اور پیچھے والے ڈیٹا نسب کے فوائد کو یکجا کرتا ہے۔ یہ ڈیٹا کے روٹ کا اس کے ماخذ سے اس کی منزل تک کے ساتھ ساتھ اس مقام سے اس کے نقطہ آغاز تک کا سراغ لگا کر اس کا ایک جامع نظارہ فراہم کرتا ہے۔
ڈیٹا کے اصل ماخذ کا تعین کرنے کے لیے، یہ سمجھنے کے لیے کہ اس میں کس طرح تبدیلی کی گئی، اور اس کے معیار، مستقل مزاجی اور پورے راستے میں مکمل ہونے کی ضمانت دینے کے لیے، ڈیٹا کے نسب کو ٹریک کرنا مددگار ہے۔ اس کے مقام اور حیثیت کے بارے میں حقیقی وقت کی معلومات کے ساتھ، یہ ڈیٹا کے لیے GPS ٹریکر رکھنے جیسا ہے۔
ڈیٹا نسب کا نفاذ
کسی تنظیم میں ڈیٹا نسب کو لاگو کرنے میں اکثر درج ذیل مراحل شامل ہوتے ہیں۔
ڈیٹا کے ذرائع کی وضاحت کریں۔
وہ سسٹم اور ڈیٹابیس جو ڈیٹا رکھتے ہیں جس کو آپ ٹریک کرنا چاہتے ہیں ان سب کی شناخت ہونی چاہیے۔ ایسا کرنے کے لیے، آپ کو پہلے ڈیٹا کے مختلف ذرائع کی شناخت کرنی ہوگی، بشمول فائلز، APIs، اور کلاؤڈ سروسز۔
میٹا ڈیٹا اکٹھا کریں۔
اگلا مرحلہ ڈیٹا کے بارے میں تفصیلات حاصل کرنا ہے، بشمول اس کے مقام، شکل اور تنظیم۔ ڈیٹا کی خصوصیات کو سمجھنا اور اسے کیسے استعمال کیا جاتا ہے اس میٹا ڈیٹا سے ممکن ہوا ہے۔
ڈیٹا کی خامیوں کی نشاندہی کریں۔
یہ سمجھنا آسان ہے کہ تنظیم کے اندر ڈیٹا کو کس طرح اپ ڈیٹ کیا جاتا ہے اور استعمال کیا جاتا ہے اگر ڈیٹا کے بہاؤ کو اس کے ماخذ سے اس کی منزل تک نقشہ بنایا جاتا ہے، بشمول راستے میں ہونے والی کوئی تبدیلی یا پروسیسنگ۔
ڈیٹا تک رسائی کو ٹریک کریں۔
ڈیٹا کی حفاظت اور تعمیل کو برقرار رکھنے کے لیے، ڈیٹا تک رسائی کرنے والے کو ٹریک کریں اور ریکارڈ کریں۔
نسب کو ذخیرہ اور تصور کریں۔
سادہ فہم اور تجزیہ کے لیے نسب کو پیش کرنے کے لیے تصور کے اوزار استعمال کریں۔ جمع کردہ میٹا ڈیٹا اور ڈیٹا کے بہاؤ کی معلومات کو ایک ہی ذخیرہ میں محفوظ کریں۔
خودکار حل کو لاگو کریں۔
آپ تصدیق کر سکتے ہیں کہ ڈیٹا نسب کو اکٹھا کیا جا رہا ہے اور آٹومیشن کے ذریعے اس کی نگرانی کی جا رہی ہے، جس سے غلطیوں کو کم کرنے اور پیداواری صلاحیت کو بڑھانے میں بھی مدد ملے گی۔
جائزہ لیں اور اپ ڈیٹ کریں۔
اس بات کو یقینی بنائیں کہ نسب کے ریکارڈ مستقل بنیادوں پر درست اور موجودہ ہیں، اور اسے مناسب طور پر اپ ڈیٹ کریں۔
نفاذ کے عمل میں ہر تنظیم کی منفرد ضروریات اور حدود کے لحاظ سے ترمیم کرنے یا مراحل میں شامل کرنے کی ضرورت پڑ سکتی ہے۔
ڈیٹا نسب کی تکنیک
پیٹرن پر مبنی نسب
اس طریقہ کے ساتھ، نسب اس پروگرامنگ کے ساتھ تعامل کیے بغیر انجام دیا جاتا ہے جس نے ڈیٹا کو تخلیق یا تبدیل کیا۔ میزوں، کالموں، اور کاروباری رپورٹوں کے لیے میٹا ڈیٹا کی تشخیص سب اس کا حصہ ہیں۔ یہ اس میٹا ڈیٹا کا استعمال کرتے ہوئے رجحانات کو تلاش کر کے نسب کو تلاش کرتا ہے۔
مثال کے طور پر، یہ کافی امکان ہے کہ ایک ہی نام اور ایک جیسی ڈیٹا ویلیوز کے ساتھ دو ڈیٹاسیٹس میں ایک کالم اپنے وجود کے مختلف مراحل میں ایک ہی ڈیٹا کی نمائندگی کرتا ہے۔ پھر ان دو کالموں کو جوڑنے کے لیے ڈیٹا نسب کا چارٹ استعمال کیا جاتا ہے۔
پیٹرن پر مبنی نسب کو ٹیکنالوجی کے آزاد ہونے کا اہم فائدہ ہے کیونکہ یہ صرف ڈیٹا کو چیک کرتا ہے، ڈیٹا پروسیسنگ کے طریقوں کی نہیں۔ کوئی بھی ڈیٹا بیس ٹیکنالوجی، بشمول Oracle، MySQL، اور Spark، اسے اسی طرح نافذ کر سکتی ہے۔ خرابی یہ ہے کہ یہ نقطہ نظر ہمیشہ درست نہیں ہوتا ہے۔
جب ڈیٹا پروسیسنگ منطق کو کمپیوٹر کوڈ میں چھپایا جاتا ہے اور انسانی پڑھنے کے قابل میٹا ڈیٹا میں آسانی سے واضح نہیں ہوتا ہے، تو یہ کبھی کبھار ڈیٹا سیٹس کے درمیان تعلقات کو نظر انداز کر سکتا ہے۔
ڈیٹا ٹیگنگ کے ذریعہ نسب
یہ طریقہ اس تصور پر پیش گوئی کی گئی ہے کہ ٹرانسفارمیشن انجن ٹیگ کرتا ہے یا بصورت دیگر مارکر ڈیٹا۔ یہ سلسلہ نسب تلاش کرنے کے لیے شروع سے آخر تک ٹیگ کا سراغ لگاتا ہے۔ یہ نقطہ نظر صرف اس صورت میں کامیاب ہو سکتا ہے جب آپ کے پاس ایک قابل اعتماد ٹرانسفارمیشن ٹول ہو جو تمام ڈیٹا کی منتقلی کا انتظام کرتا ہے اور آپ اس ٹول کے استعمال کردہ ٹیگنگ ڈھانچے سے واقف ہیں۔
یہاں تک کہ اگر ایسا کوئی ٹول موجود ہوتا، کوئی بھی ڈیٹا جو اس کے بغیر تخلیق یا تبدیل کیا گیا ہو ڈیٹا ٹیگنگ کے ذریعے نسب کا نشانہ نہیں بن سکتا۔ اس سلسلے میں یہ بند ڈیٹا سسٹمز پر ڈیٹا نسب کو انجام دینے تک محدود ہے۔
خود ساختہ نسب
کچھ کاروباروں میں ڈیٹا کا ماحول ہوتا ہے جس میں میٹا ڈیٹا اسٹوریج، پروسیسنگ لاجک، اور ماسٹر ڈیٹا مینجمنٹ (MDM) شامل ہوتا ہے۔ ان ترتیبات میں اکثر شامل ہوتے ہیں a ڈیٹا جھیل جہاں تمام ڈیٹا کو اس کی پوری زندگی میں رکھا جاتا ہے۔
نسب قدرتی طور پر اس قسم کے خود ساختہ نظام کے ذریعے اضافی وسائل کی ضرورت کے بغیر فراہم کیا جا سکتا ہے۔ تاہم، بالکل اسی طرح جیسے ڈیٹا ٹیگنگ کے طریقہ کار کے ساتھ، نسب اس ریگولیٹڈ ماحول سے باہر ہونے والی کسی بھی چیز سے واقف نہیں ہوگا۔
ڈیٹا نسب بذریعہ تجزیہ
نسب کی سب سے نفیس قسم وہ ہے جو ڈیٹا پروسیسنگ منطق کو خود بخود پڑھتی ہے۔ مکمل، اینڈ ٹو اینڈ ٹریسنگ کے لیے، یہ طریقہ ڈیٹا ٹرانسفارمیشن منطق کو ریورس انجینئر کرتا ہے۔
چونکہ اس حل کو سبھی کو سمجھنا چاہئے۔ پروگرامنگ زبانوں اور ڈیٹا کو تبدیل کرنے اور منتقل کرنے کے لیے استعمال ہونے والے ٹولز، اس کی تعیناتی پیچیدہ ہے۔ یہ extract-transform-load (ETL) منطق، SQL- اور Java پر مبنی حل، پرانے ڈیٹا فارمیٹس، XML پر مبنی حل، اور دیگر تکنیکوں کا استعمال کر سکتا ہے۔
ڈیٹا نسب کے استعمال کے معاملات
ڈیٹا ماڈلنگ
کمپنیوں کو ڈیٹا کے بنیادی ڈھانچے قائم کرنے چاہئیں جو کمپنی کے اندر بہت سے ڈیٹا آئٹمز اور ان کے درمیان رابطوں کو دیکھنے کے لیے ان کی حمایت کرتے ہیں۔ یہ کنکشن ڈیٹا نسب کا استعمال کرتے ہوئے ماڈل بنائے گئے ہیں، جو ڈیٹا ایکو سسٹم میں موجود بہت سے انحصار کو بھی ظاہر کرتا ہے۔
چونکہ وقت کے ساتھ ڈیٹا میں تبدیلی آتی ہے، اس لیے ڈیٹا کے نئے ذرائع مسلسل ظاہر ہوتے ہیں، جن کے لیے نئے ڈیٹا انضمام وغیرہ کی ضرورت ہوتی ہے۔ اس وجہ سے، اپنے ڈیٹا کو منظم کرنے کے لیے فرموں کے عمومی ڈیٹا ماڈلز کو بھی ماحول کی عکاسی کرنے کے لیے تبدیل ہونا چاہیے۔
تعمیل
ڈیٹا نسب آڈیٹنگ، رسک مینجمنٹ کو بڑھانے، اور ڈیٹا کو ڈیٹا گورننس کی پالیسیوں اور قوانین کے مطابق رکھا اور ہینڈل کرنے کو یقینی بنانے کے لیے ایک تعمیل کا طریقہ پیش کرتا ہے۔
اثر تجزیہ
بعض کاروباری تبدیلیوں کے اثرات، جیسے کسی بھی بہاو کی رپورٹنگ، کو ڈیٹا نسب کے ٹولز کا استعمال کرتے ہوئے دیکھا جا سکتا ہے۔ مثال کے طور پر، ڈیٹا نسب یہ تعین کرنے میں ایگزیکٹوز کی مدد کر سکتا ہے کہ نام کی تبدیلی سے کتنے ڈیش بورڈز پر اثر پڑے گا اور اس کے نتیجے میں، کتنے لوگ اس رپورٹنگ تک رسائی حاصل کرتے ہیں۔
ڈیٹا کی منتقلی
تنظیمیں یہ سمجھنے کے لیے ڈیٹا کی منتقلی کا کام کرتی ہیں کہ ڈیٹا کہاں واقع ہے اور اسے کسی نئے اسٹوریج سسٹم میں منتقل کرنے یا نئے سافٹ ویئر کو لاگو کرنے سے پہلے یہ وہاں کتنا عرصہ رہا ہے۔
ڈیٹا کا سلسلہ ٹیموں کو سسٹم کے اپ گریڈ یا منتقلی کے لیے تیار کرنے میں مدد کرتا ہے اور انہیں اس بات کا جائزہ دے کر کہ ڈیٹا کس طرح پوری تنظیم میں منتقل ہوا ہے۔ یہ مجموعی طور پر نئے اسٹوریج ماحول میں منتقلی کو تیز کرتا ہے۔
مزید برآں، یہ ٹیموں کو یہ موقع فراہم کرتا ہے کہ وہ پرانے یا بیکار ڈیٹا کو آرکائیو یا ختم کر کے ڈیٹا سسٹم کو ختم کر دیں۔ ایسا کرنے سے، ڈیٹا سسٹم مجموعی طور پر بہتر کارکردگی کا مظاہرہ کرے گا اور ڈیٹا کے کم انتظام کی ضرورت ہے۔
ڈیٹا نسب کو لاگو کرنے کے چیلنجز
- ڈیٹا سیکیورٹی: ڈیٹا کی حفاظت ڈیٹا نسب کی تعمیر کے دوران بنیادی تشویش ہے۔ ڈیٹا کے سفر کے نقطہ آغاز سے اس کی آخری منزل تک جانے کے لیے، حساس ڈیٹا تک رسائی کی اجازت دی جانی چاہیے، اور اس ڈیٹا کو غیر مجاز رسائی اور خلاف ورزیوں سے محفوظ رکھا جانا چاہیے۔
- معیاری کاری کی کمی: ڈیٹا نسب کو اپنانے میں بنیادی رکاوٹوں میں سے ایک معیار کی کمی ہے۔ چونکہ بہت سے پلیٹ فارمز، ایپس، اور سسٹمز ڈیٹا پرووینس کو ٹریک کرنے اور ریکارڈ کرنے کے لیے منفرد طریقے استعمال کرتے ہیں، اس لیے ڈیٹا کے سفر کی ایک مربوط تصویر کو اکٹھا کرنا مشکل ہو سکتا ہے۔
- ڈیٹا سائلوس: ڈیٹا سائلوس ایک اور مسئلہ ہے جو ڈیٹا نسب کو لاگو کرتے وقت پیدا ہوتا ہے۔ جب ڈیٹا کئی ایپلی کیشنز اور سسٹمز میں پھیلا ہوا ہے، تو اس کے سفر کو ایک سے دوسرے تک ٹریک کرنا مشکل ہو سکتا ہے۔ یہ غلط یا نامکمل ڈیٹا نسب کا باعث بن سکتا ہے۔
نتیجہ
آخر میں، ڈیٹا نسب ہر ڈیٹا سے چلنے والے انٹرپرائز کا ایک لازمی حصہ ہے۔ یہ ڈیٹا کے نقطہ آغاز سے اس کے اختتامی نقطہ تک کے راستے کا ایک جامع تناظر پیش کرتا ہے، اس کی درستگی، مکمل ہونے اور مستقل مزاجی کی ضمانت دیتا ہے۔
مستقبل کے ڈیٹا نسب کی آٹومیشن اور معیاری کاری میں اضافہ متوقع ہے، جس سے تنظیموں کے لیے عمل درآمد اور دیکھ بھال آسان ہو جائے گی۔ آخر میں، ڈیٹا نسب کی اہمیت پر زور نہیں دیا جا سکتا۔
یہ کمپنیوں کو وہ اوزار فراہم کرتا ہے جن کی انہیں دانشمندانہ انتخاب کرنے، اپنے کام کو زیادہ موثر طریقے سے چلانے اور کامیابی حاصل کرنے کے لیے درکار ہوتی ہے۔





جواب دیجئے