Ito ay isang mahalaga at kanais-nais na gawain sa computer vision at graphics upang makagawa ng mga malikhaing portrait na pelikula ng pinakamataas na kalibre.
Bagama't ilang mabisang modelo para sa portrait image toonification batay sa makapangyarihang StyleGAN ang iminungkahi, ang mga diskarteng ito na nakatuon sa imahe ay may malinaw na mga disbentaha kapag ginamit sa mga video, tulad ng nakapirming laki ng frame, ang kinakailangan para sa pag-align ng mukha, ang kawalan ng mga detalyeng hindi pangmukha. , at temporal na hindi pagkakapare-pareho.
Ang isang rebolusyonaryong VToonify framework ay ginagamit upang harapin ang mahirap na kontroladong high-resolution na portrait na paglipat ng istilo ng video.
Susuriin namin ang pinakahuling pag-aaral sa VToonify sa artikulong ito, kasama ang functionality nito, mga kakulangan, at iba pang mga salik.
Ano ang Vtoonify?
Nagbibigay-daan ang VToonify framework para sa nako-customize na high-resolution na portrait na pagpapadala ng istilo ng video.
Gumagamit ang VToonify ng mga mid-at high-resolution na layer ng StyleGAN upang lumikha ng mga de-kalidad na artistikong portrait batay sa mga multi-scale na katangian ng content na nakuha ng isang encoder upang mapanatili ang mga detalye ng frame.
Ang resultang ganap na convolutional na arkitektura ay kumukuha ng mga hindi nakahanay na mukha sa mga pelikulang may variable na laki bilang input, na nagreresulta sa mga buong mukha na rehiyon na may makatotohanang paggalaw sa output.

Tugma ang framework na ito sa kasalukuyang mga modelo ng toonification ng imahe na nakabatay sa StyleGAN, na nagbibigay-daan sa mga ito na ma-extend sa video toonification, at magmana ng mga kaakit-akit na katangian tulad ng adjustable na kulay at intensity customization.
ito pag-aralan nagpapakilala ng dalawang instantiation ng VToonify batay sa Toonify at DualStyleGAN para sa paglilipat ng istilo ng portrait na video na nakabatay sa koleksyon at nakabatay sa halimbawa.
Ang malawak na mga natuklasang pang-eksperimento ay nagpapakita na ang iminungkahing VToonify framework ay higit na gumaganap sa mga kasalukuyang diskarte sa paggawa ng mataas na kalidad, temporal na magkakaugnay na artistikong portrait na mga pelikula na may variable na mga parameter ng istilo.
Ang mga mananaliksik ay nagbibigay ng Google Colab notebook, para madumihan mo ang iyong mga kamay dito.
Paano ito gumagana?
Para magawa ang adjustable na high-resolution na portrait na paglipat ng istilo ng video, pinagsasama ng VToonify ang mga pakinabang ng balangkas ng pagsasalin ng larawan sa balangkas na nakabatay sa StyleGAN.
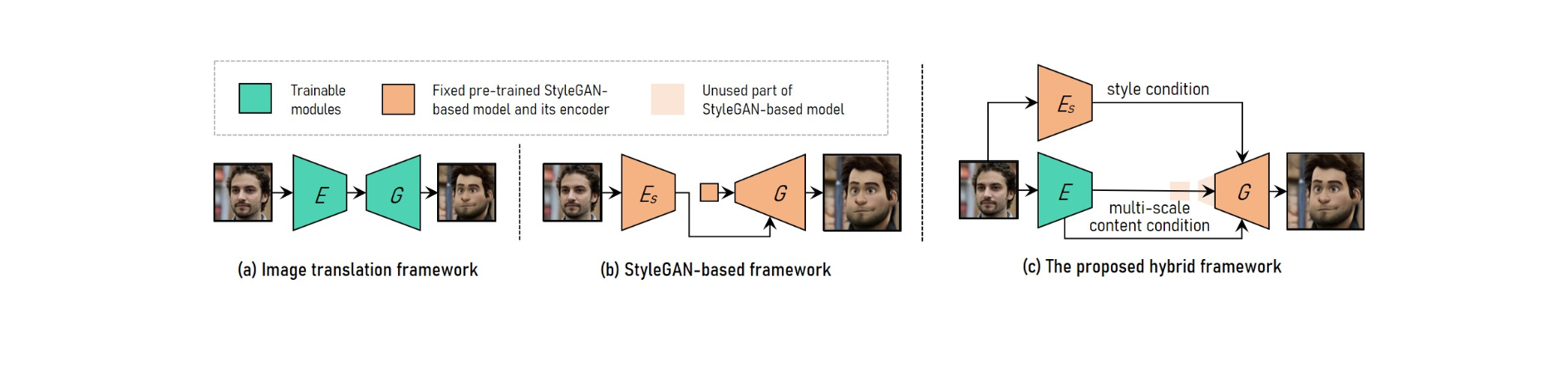
Upang mapaunlakan ang iba't ibang laki ng input, ang sistema ng pagsasalin ng imahe ay gumagamit ng ganap na convolutional network. Ang pagsasanay mula sa simula, sa kabilang banda, ay ginagawang imposible ang high-resolution at kontroladong istilo ng paghahatid.
Ang pre-trained na modelo ng StyleGAN ay ginagamit sa StyleGAN-based na framework para sa mataas na resolution at kontroladong paglipat ng istilo, bagama't ito ay limitado sa nakapirming laki ng larawan at mga pagkawala ng detalye.
Ang StyleGAN ay binago sa hybrid na framework sa pamamagitan ng pagtanggal sa fixed-sized na input feature at low-resolution na mga layer, na nagreresulta sa isang ganap na convolutional encoder-generator architecture na katulad ng sa image translation framework.
Upang mapanatili ang mga detalye ng frame, sanayin ang isang encoder na mag-extract ng mga multi-scale na katangian ng content ng input frame bilang karagdagang kinakailangan sa content sa generator. Namana ng Vtoonify ang style control flexibility ng StyleGAN model sa pamamagitan ng paglalagay nito sa generator para ma-disstill ang data at modelo nito.
Mga Limitasyon ng StyleGAN at Iminungkahing Vtoonify
Ang mga artistikong larawan ay karaniwan sa ating pang-araw-araw na buhay gayundin sa mga malikhaing negosyo tulad ng sining, social media avatar, pelikula, entertainment advertising, at iba pa.
Sa pagbuo ng malalim na pag-aaral teknolohiya, posible na ngayong lumikha ng mga de-kalidad na artistikong portrait mula sa totoong buhay na mga larawan ng mukha gamit ang awtomatikong paglipat ng istilo ng portrait.
Mayroong iba't ibang matagumpay na paraan na nilikha para sa paglipat ng istilong nakabatay sa imahe, na marami sa mga ito ay madaling ma-access ng mga nagsisimulang user sa anyo ng mga mobile application. Mabilis na naging mainstay ang materyal ng video sa aming mga social media feed sa nakalipas na ilang taon.
Ang pagtaas ng social media at mga ephemeral na pelikula ay nagpapataas ng pangangailangan para sa makabagong pag-edit ng video, tulad ng portrait video style transfer, upang makabuo ng matagumpay at kawili-wiling mga video.
Ang mga kasalukuyang diskarteng nakatuon sa imahe ay may mga makabuluhang disadvantage kapag inilapat sa mga pelikula, na nililimitahan ang kanilang pagiging kapaki-pakinabang sa automated na portrait video stylization.
Ang StyleGAN ay isang karaniwang backbone para sa pagbuo ng portrait picture style transfer model dahil sa kapasidad nitong lumikha ng mga de-kalidad na mukha na may adjustable style management.
Ang isang StyleGAN-based system (kilala rin bilang picture toonification) ay nag-e-encode ng isang tunay na mukha sa StyleGAN latent space at pagkatapos ay inilalapat ang resultang style code sa isa pang StyleGAN na pinong-tune sa artistikong portrait dataset upang lumikha ng isang naka-istilong bersyon.
Gumagawa ang StyleGAN ng mga larawan na may nakahanay na mga mukha at sa isang nakapirming laki, na hindi pinapaboran ang mga dynamic na mukha sa real-world footage. Ang pag-crop at pag-align ng mukha sa video kung minsan ay nagreresulta sa bahagyang mukha at mga awkward na galaw. Tinatawag ng mga mananaliksik ang isyung ito na 'fixed-crop restriction' ng StyleGAN.
Para sa mga hindi nakahanay na mukha, ang StyleGAN3 ay iminungkahi; gayunpaman, sinusuportahan lamang nito ang isang nakatakdang laki ng larawan.
Higit pa rito, natuklasan ng isang kamakailang pag-aaral na ang pag-encode ng mga hindi naka-align na mukha ay mas mahirap kaysa sa mga naka-align na mukha. Ang maling pag-encode ng mukha ay nakakapinsala sa paglilipat ng istilo ng portrait, na nagreresulta sa mga isyu gaya ng pagbabago ng pagkakakilanlan at nawawalang mga bahagi sa mga binago at naka-istilong frame.
Gaya ng tinalakay, ang isang mahusay na pamamaraan para sa paglipat ng istilo ng portrait na video ay dapat pangasiwaan ang mga sumusunod na isyu:
- Upang mapanatili ang mga makatotohanang paggalaw, ang diskarte ay dapat na kayang harapin ang mga hindi nakahanay na mukha at iba't ibang laki ng video. Ang isang malaking sukat ng video, o isang malawak na anggulo ng view, ay maaaring makakuha ng higit pang impormasyon habang pinipigilan ang mukha mula sa pag-alis sa frame.
- Upang makipagkumpitensya sa mga karaniwang ginagamit ngayon na mga HD na gadget, kailangan ang high-resolution na video.
- Dapat mag-alok ng flexible na kontrol sa istilo para sa mga user na baguhin at piliin ang kanilang pinili kapag bumubuo ng isang makatotohanang sistema ng pakikipag-ugnayan ng user.
Para sa layuning iyon, iminumungkahi ng mga mananaliksik ang VToonify, isang nobelang hybrid framework para sa video toonification. Upang malampasan ang nakapirming crop constraint, pinag-aaralan muna ng mga mananaliksik ang equivariance ng pagsasalin sa StyleGAN.
Pinagsasama-sama ng VToonify ang mga benepisyo ng arkitektura na nakabatay sa StyleGAN at ang framework ng pagsasalin ng imahe upang makamit ang adjustable na high-resolution na portrait video style transfer.
Ang mga sumusunod ay ang mga pangunahing kontribusyon:
- Sinisiyasat ng mga mananaliksik ang fixed-crop na hadlang ng StyleGAN at nagmumungkahi ng solusyon batay sa equivariance ng pagsasalin.
- Nagpapakita ang mga mananaliksik ng isang natatanging fully convolutional VToonify framework para sa kinokontrol na high-resolution na portrait na paglipat ng istilo ng video na sumusuporta sa mga hindi magkatugmang mukha at iba't ibang laki ng video.
- Binubuo ng mga mananaliksik ang VToonify sa mga backbone ng Toonify at DualStyleGAN at i-condense ang mga backbone sa mga tuntunin ng parehong data at modelo upang paganahin ang paglilipat ng istilo ng portrait na video na nakabatay sa koleksyon at nakabatay sa halimbawa.
Paghahambing ng Vtoonify sa iba pang mga makabagong modelo
Palagay
Nagsisilbi itong pundasyon para sa paglilipat ng istilo na nakabatay sa koleksyon sa mga naka-align na mukha gamit ang StyleGAN. Upang makuha ang mga style code, dapat i-align ng mga mananaliksik ang mga mukha at i-crop ang 256256 na larawan para sa PSP. Ginagamit ang Toonify para makabuo ng naka-istilong resulta na may 1024*1024 na mga style code.
Sa wakas, muling inihanay nila ang resulta sa video sa orihinal nitong lokasyon. Ang hindi naka-istilong lugar ay itinakda sa itim.

DualStyleGAN
Ito ay isang backbone para sa exemplar-based na paglipat ng istilo batay sa StyleGAN. Ginagamit nila ang parehong mga diskarte sa pre-at post-processing ng data gaya ng Toonify.
Pix2pixHD
Isa itong modelo ng pagsasalin ng imahe-sa-imahe na karaniwang ginagamit upang i-condense ang mga pre-trained na modelo para sa pag-edit na may mataas na resolution. Ito ay sinanay gamit ang ipinares na data.
Ginagamit ng mga mananaliksik ang pix2pixHD bilang mga karagdagang instance ng mapa nito dahil gumagamit ito ng na-extract na parsing map.
First Order Motion
Ang FOM ay isang tipikal na modelo ng animation ng imahe. Ito ay sinanay sa 256256 na mga larawan at hindi maganda ang pagganap sa iba pang laki ng larawan. Bilang resulta, ini-scale muna ng mga mananaliksik ang mga video frame sa 256*256 para sa FOM sa animation at pagkatapos ay i-resize ang mga resulta sa kanilang orihinal na laki.
Para sa isang patas na paghahambing, ginagamit ng FOM ang unang naka-istilong frame ng diskarte nito bilang imahe ng istilo ng sanggunian nito.
DaGAN
Isa itong 3D face animation model. Ginagamit nila ang parehong paghahanda ng data at mga pamamaraan ng postprocessing gaya ng FOM.

Bentahe
- Maaari itong gamitin sa sining, mga avatar sa social media, mga pelikula, advertising sa entertainment, at iba pa.
- Ang Vtoonify ay maaari ding gamitin sa metaverse.
Mga hangganan
- Kinukuha ng pamamaraang ito ang data at ang modelo mula sa mga backbone na nakabatay sa StyleGAN, na nagreresulta sa bias ng data at modelo.
- Ang mga artifact ay kadalasang sanhi ng mga pagkakaiba sa laki sa pagitan ng inilarawang rehiyon ng mukha at ng iba pang mga seksyon.
- Ang diskarte na ito ay hindi gaanong matagumpay kapag nakikitungo sa mga bagay sa rehiyon ng mukha.
Konklusyon
Panghuli, ang VToonify ay isang framework para sa high-resolution na video toonification na kinokontrol ng istilo.
Nakakamit ng framework na ito ang mahusay na pagganap sa paghawak ng mga video at nagbibigay-daan sa malawak na kontrol sa istilo ng istruktura, istilo ng kulay, at antas ng istilo sa pamamagitan ng pag-condense ng mga modelo ng toonification ng imahe na nakabatay sa StyleGAN sa mga tuntunin ng kanilang sintetikong data at mga istruktura ng network.





Mag-iwan ng Sagot