Talaan ng nilalaman[Tago][Ipakita]
Malaking text-to-image na mga modelo ang gumawa ng makabuluhang pag-unlad sa pagbuo ng AI sa pamamagitan ng paggawa ng mataas na kalidad at sari-saring picture synthesis mula sa isang naibigay na text prompt.
Ang mga modelong ito ay hindi makapag-synthesize ng mga natatanging representasyon ng mga paksa sa iba't ibang setting o upang kopyahin ang hitsura ng mga paksa sa isang ibinigay na hanay ng sanggunian.
Mga bagong inilabas na teknolohiya tulad ng OpenAI's DALL.E2 o StabilityAI's Matatag na Pagsasabog at Midjourney ay kumukuha na ng internet sa pamamagitan ng bagyo. Oras na para i-customize ang mga resulta. Ngunit paano?
Dumating na ang Google DreamBooth AI.
Ang DreamBooth ay may kakayahang kilalanin ang paksa ng isang larawan, i-deconstruct ito mula sa orihinal nitong konteksto, at pagkatapos ay tiyak na i-synthesize ito sa isang bagong gustong konteksto. Bilang karagdagan, maaari itong magamit sa kasalukuyang mga generator ng larawan ng AI.
Sa artikulong ito, titingnan natin nang malalim ang DreamBooth, ang paggamit nito, ang tutorial nito, ang mga limitasyon nito, at marami pang iba.
Ano ang Dreambooth?
dreambooth, isang bagong-bagong text-to-image diffusion model, ay ipinakita ng Google. Maaaring gamitin ang nakasulat na prompt bilang gabay ng Google DreamBooth AI upang makabuo ng malawak na hanay ng mga larawan ng napiling paksa ng user sa iba't ibang setting.
Isang pangkat ng pananaliksik mula sa Boston University at Google ang bumuo ng DreamBooth, isang cutting-edge na pamamaraan para sa pagbabago ng text-to-image na mga modelo na sumailalim sa malawak na pre-training.
Ang pangkalahatang konsepto ay medyo diretso: gusto nilang dagdagan ang diksyunaryo ng pananaw sa wika upang ang mga hindi karaniwang token ID ay nauugnay sa mga custom na paksa na maaaring tukuyin ng mga user.
Ang pangunahing layunin ng modelo ay ikonekta ang mga user sa modelo ng pagsasabog ng text-to-image sa pamamagitan ng pagbibigay sa kanila ng mga mapagkukunang kailangan nila upang makagawa ng mga photorealistic na representasyon ng mga pagkakataon ng kanilang napiling paksa.
Bilang kinahinatnan, ang pamamaraan na ito ay tila gumagana nang maayos para sa pagbubuod ng mga hamon sa isang hanay ng mga sitwasyon.
Ang DreamBooth ng Google ay naiiba sa mga dating tool na text-to-image, gaya ng DALL-E2, Matatag na Pagsasabog, at kalagitnaan ng paglalakbay, dahil binibigyan nito ang mga user ng higit na kontrol sa larawan ng paksa bago hayaan silang manipulahin ang diffusion model gamit ang mga text-based na input.
Mga tampok
- Maaaring mapabuti ng DreamBooth AI ang isang text-to-image na modelo na may 3-5 na larawan.
- Ang mga orihinal na photorealistic na larawan ay maaaring gawin gamit ang DreamBooth AI.
- Bilang karagdagan, ang DreamBooth AI ay maaaring lumikha ng mga larawan ng isang paksa mula sa maraming anggulo.
application
Mga Art Rendition
Ang gawaing ito ay partikular na naiiba sa paglipat ng istilo, na nagpapanatili sa mga semantika ng pinanggagalingan ng eksena habang isinasama ang istilo ng isa pang larawan sa orihinal na eksena.

Batay sa malikhaing diskarte, ang AI ay makakagawa ng mga makabuluhang pagbabago sa eksena habang pinapanatili ang pagkakakilanlan at mga partikular na halimbawa ng paksa.
Pagbabago ng Ari-arian
Maaaring baguhin ng DreamBooth AI ang mga katangian ng instance ng paksa.

Accessorization
Ang malakas na komposisyon bago ang henerasyong modelo ay ang dahilan kung bakit ang kakayahan ng DreamBooth AI na magpalamuti ng mga bagay ay lubhang kawili-wili.

Recontextualization
Ang DreamBooth AI ay maaaring gumawa ng mga natatanging larawan para sa isang partikular na halimbawa ng paksa sa pamamagitan ng pagbibigay sa isang sinanay na modelo ng isang pangungusap na kinabibilangan ng natatanging identifier at pangngalan ng klase.

Maaari itong makabuo ng paksa sa natatangi, dati nang hindi naririnig na mga postura, mga artikulasyon, at istraktura ng eksena sa halip na baguhin ang paligid. Makatotohanang mga pagmuni-muni at anino, pati na rin ang mga pakikipag-ugnayan sa pagitan ng paksa at mga nakapalibot na bagay.
Tutorial sa Dreambooth
Sa tutorial na ito, susundan natin ang Google Collab notebook, at ituturo ko sa iyo ito, na magpapaunawa sa iyo at magagamit mo ito sa iyong sarili.
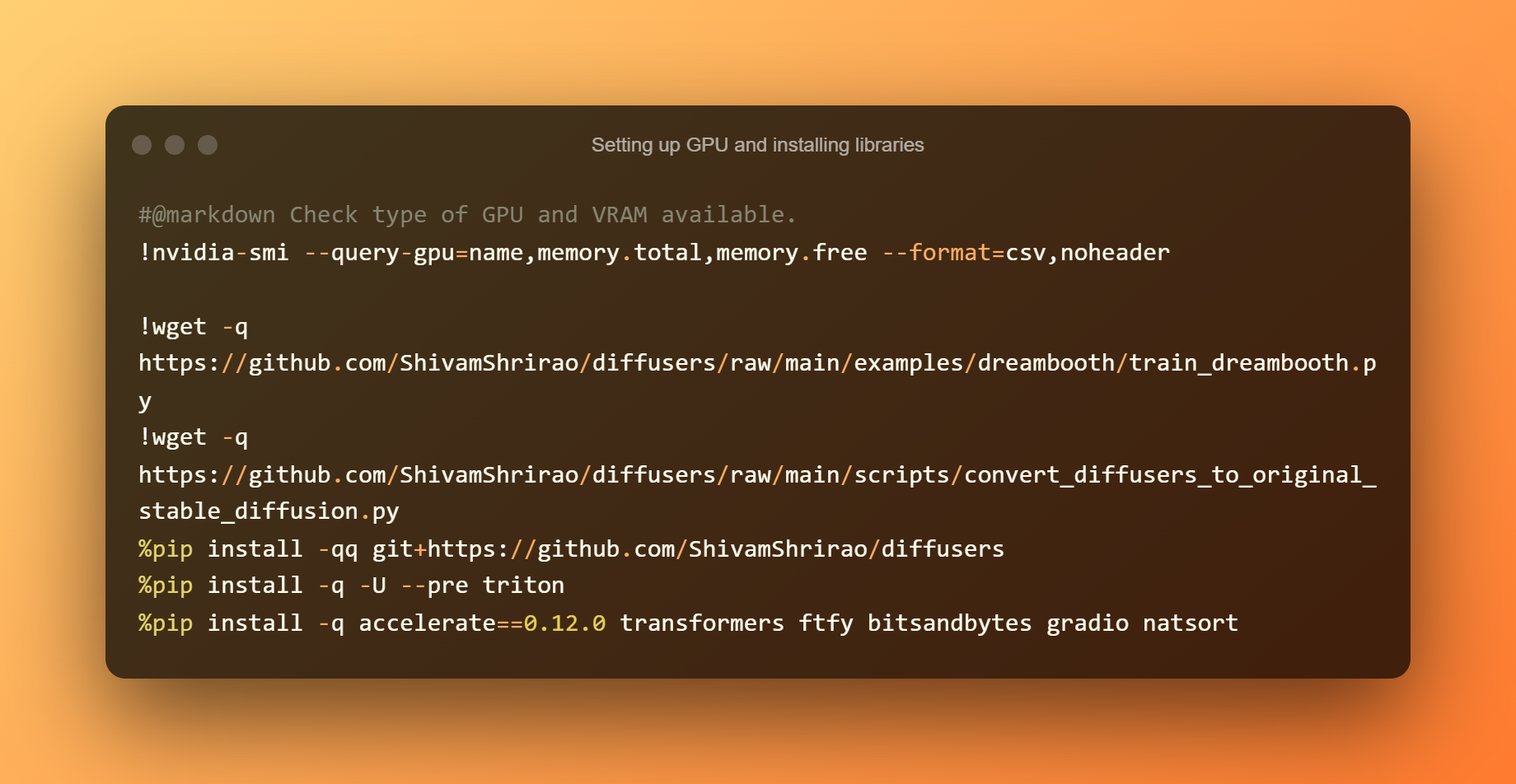
Pag-set up ng GPU at pag-install ng mga library
Ang pag-alam kung anong mga uri ng GPU at VRAM ang available ang unang hakbang. Ang pag-install ng ilang mga kinakailangan at dependencies ay kinakailangan din. Pindutin lang ang play button, pagkatapos ay hintayin itong matapos.
Gumawa ng account sa Huggingface at bumuo ng token
Ang susunod na hakbang ay ang magparehistro para sa isang Huggingface account. Kapag tapos ka na, i-click ang mga setting sa kanang sulok sa itaas. Darating ka sa susunod na pahina.
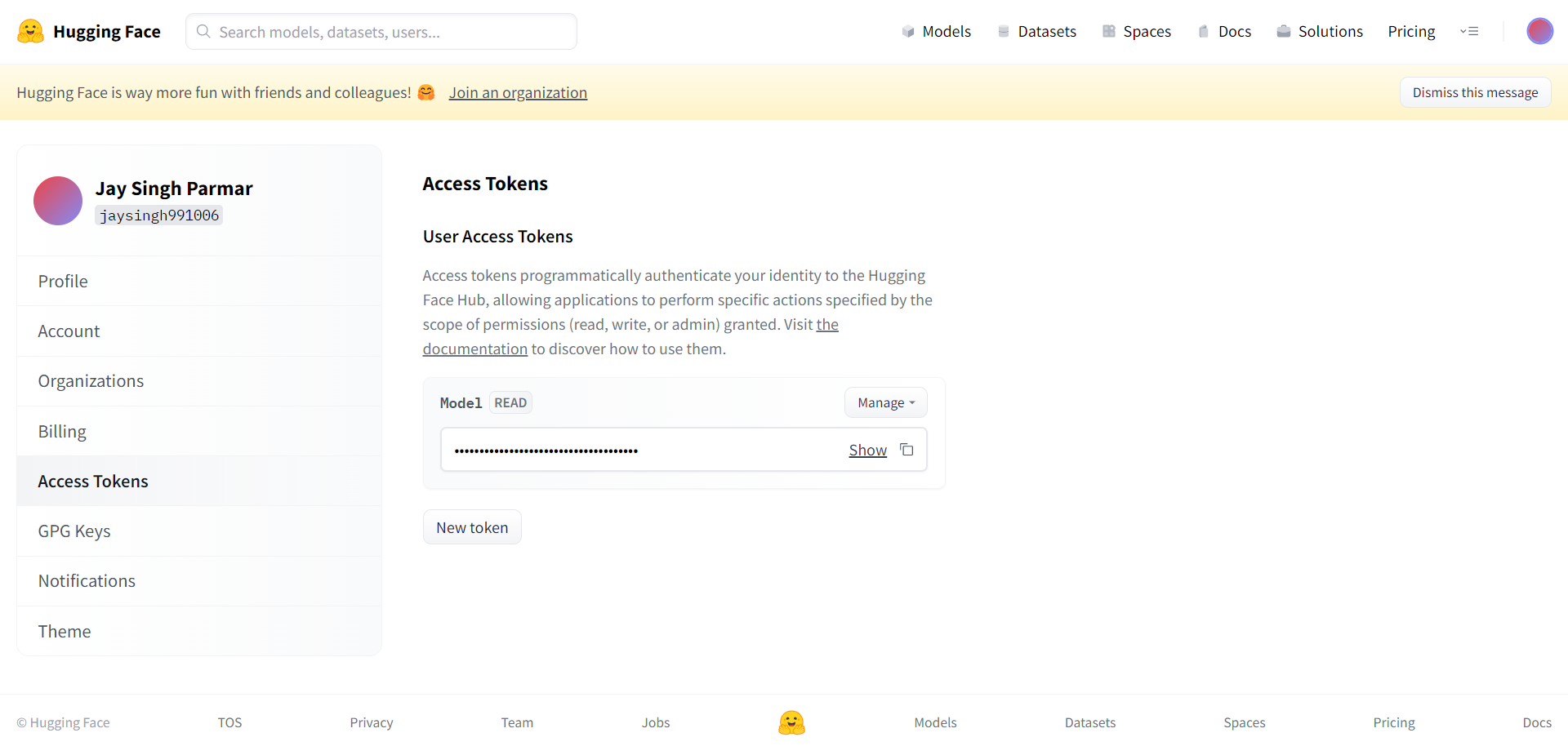
Lumikha ng token at pangalan gaya ng hiniling mula rito. Dapat na kopyahin at i-paste ang token sa Google collab sa cell sa ibaba.

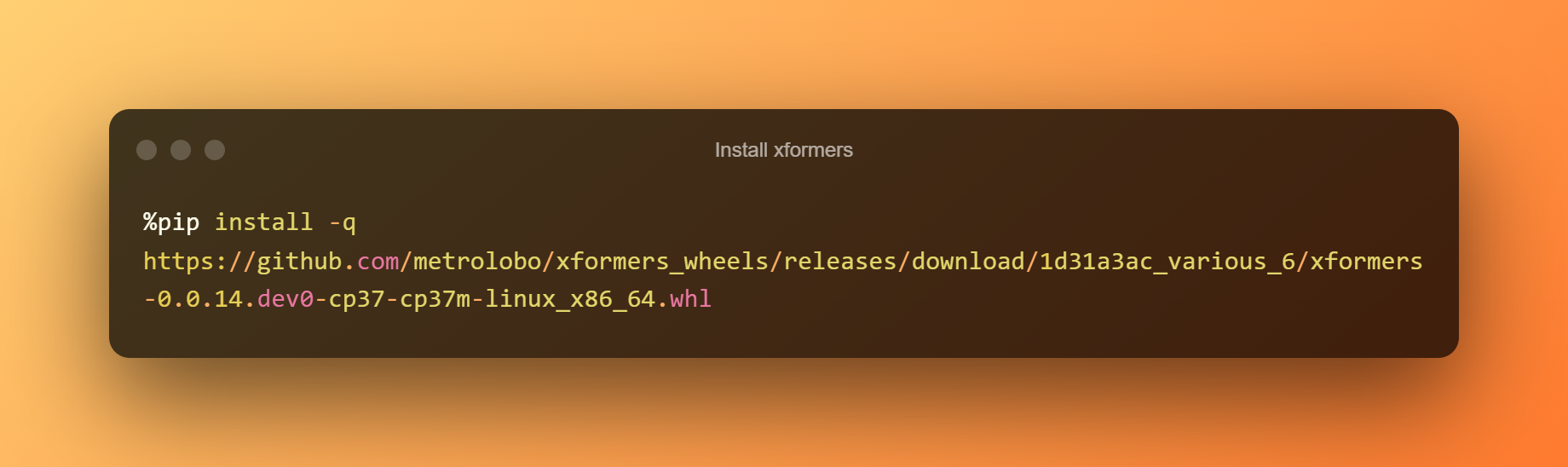
I-install ang xformers
Sa yugtong ito, maaari mo lamang pindutin ang play button upang i-install ang xformers sa pamamagitan ng pag-click sa runtime.
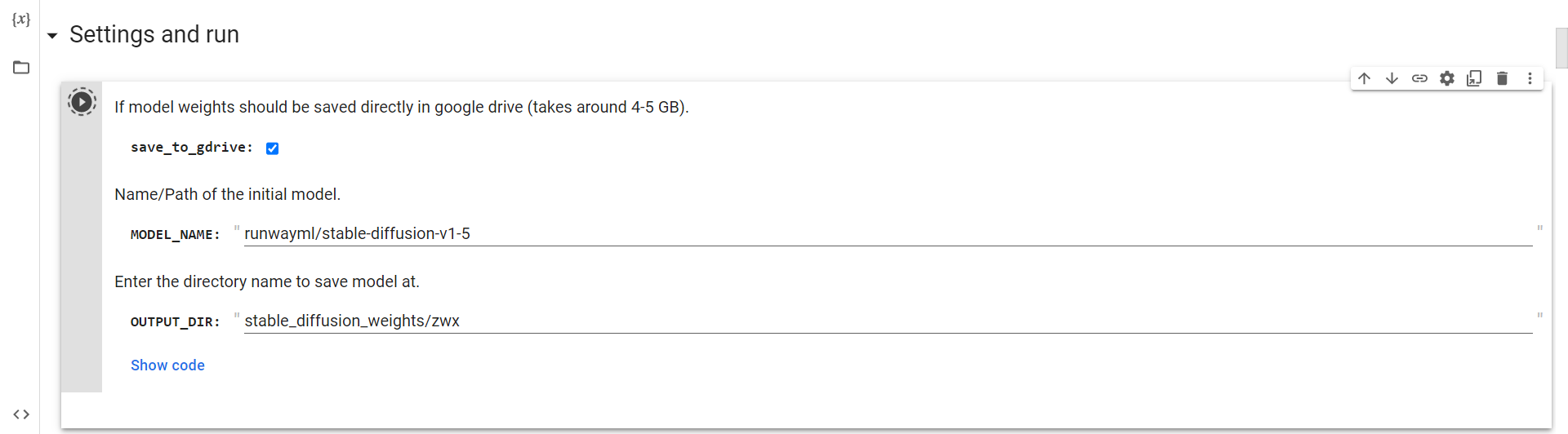
Kumonekta sa Drive
Ngayon, kailangan mo lang patakbuhin ang cell na ito upang kumonekta sa google drive.
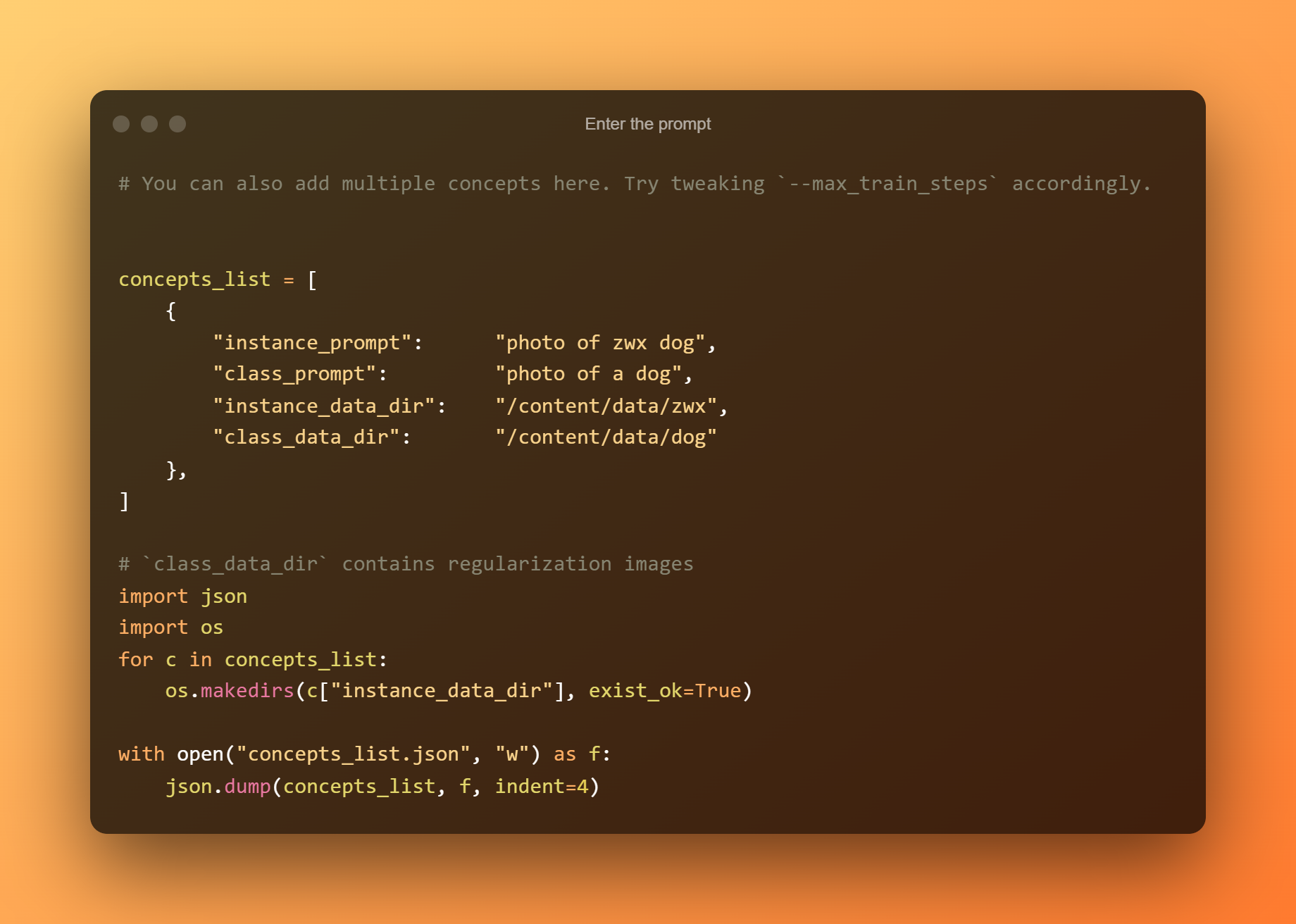
Ipasok ang prompt
Sa sumusunod na cell, kailangan mo lamang ipasok ang prompt.
Pag-upload ng mga larawan
Sa hakbang na ito, kailangan mo lang i-upload ang mga larawan na gusto mong sanayin.

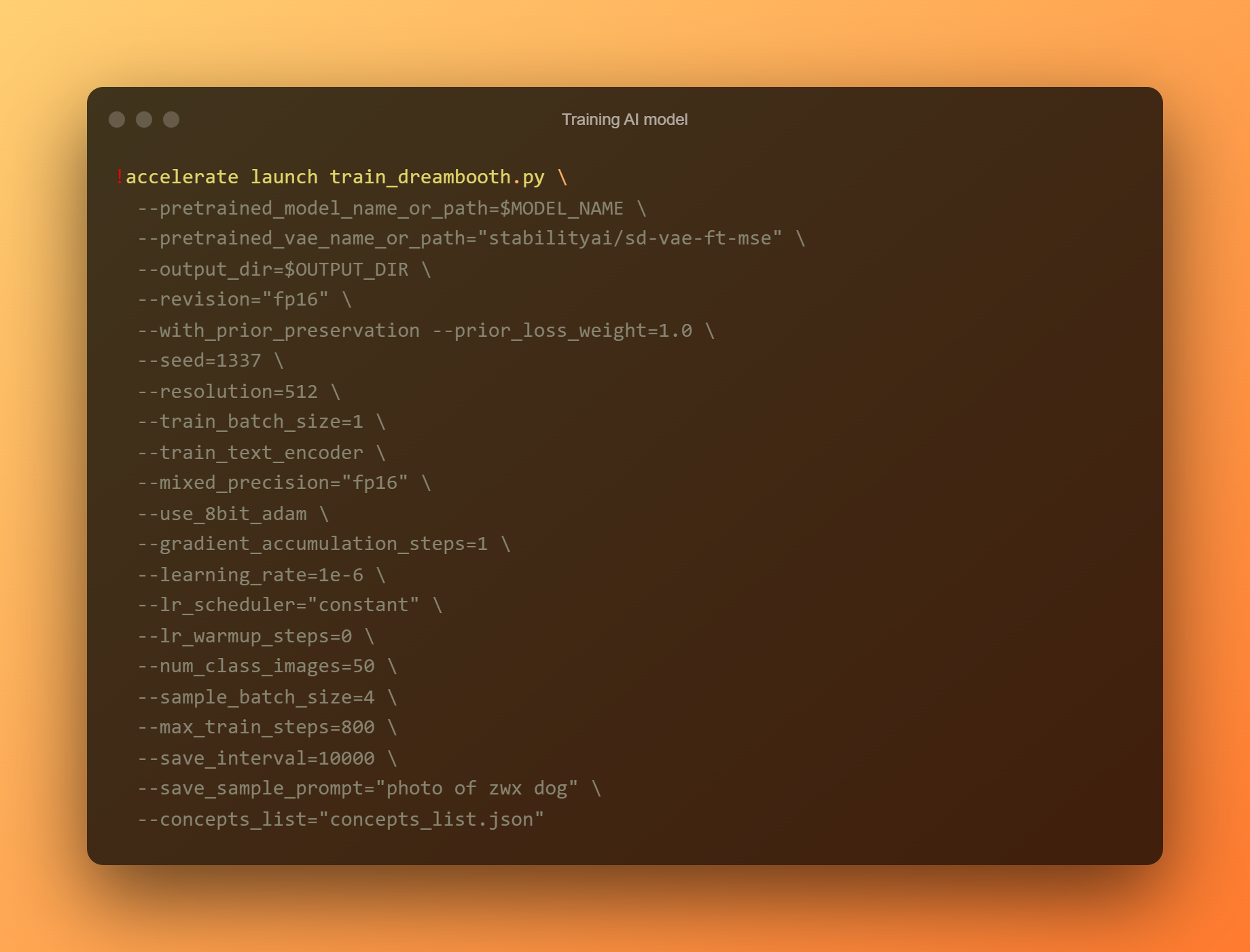
Sanayin ang modelo ng AI
Ito ang pinakamahalagang yugto, dahil gagamitin mo ang DreamBooth upang sanayin ang isang bagong modelo ng AI batay sa lahat ng iyong isinumiteng reference na litrato. Dapat mong limitahan ang iyong pansin sa dalawang input field. Ang "—instance prompt" ay ang unang parameter. Dapat kang magbigay ng lubos na natatanging pangalan dito.
Ang argumentong '–concept list' ay ang pangalawang kritikal na field ng input. Dapat itong palitan ng pangalan upang tumugma sa ginamit sa seksyong 'Baguhin ang prompt'.
Bumuo ng mga imahe ng AI
Ang mga larawan ng AI ay malilikha sa yugtong ito, kung saan maaari mong ipasok ang mga tagubilin sa teksto.

Mga Limitasyon sa Dreambooth
- Nagiging hadlang ang command prompt sa paggawa ng mga pag-ulit sa paksang may mataas na antas ng detalye. Maaaring baguhin ng DreamBooth ang konteksto ng paksa, ngunit kung nais ng modelo na baguhin ang paksa mismo, may mga isyu sa frame.
- Ang isa pang isyu ay ang overfitting ng output na larawan sa input na imahe. Kung walang sapat na mga larawang ibinigay, ang paksa ay maaaring hindi isaalang-alang o maaaring ihalo sa konteksto ng mga isinumiteng larawan. Kapag tinanong ang isang konteksto para sa isang kakaibang henerasyon, ang parehong bagay ay nagaganap.
Konklusyon
Upang makagawa ng mga output mula sa isang input ng text, ang karamihan sa mga modelo ng text-to-image ay nangangailangan ng milyun-milyong parameter at library.
Pinapasimple ng DreamBooth ang pagkuha at paggamit ng nilalaman para sa mga mamimili sa pamamagitan ng pag-aatas lamang ng input ng tatlo hanggang limang larawan ng paksa kasama ng isang textual na background.





Mag-iwan ng Sagot